
簡介
TFX 是奠基於 TensorFlow 的機器學習 (ML) 平台,具備 Google 的實際工作環境規模。這個平台提供了設定架構和共用程式庫,可用來整合定義、啟動及監控機器學習系統所需的通用元件。
TFX 1.0
我們很高興宣布推出 TFX 1.0.0。這是 TFX 的第一個後 Beta 版,提供穩定的公用 API 和構件。只要在本 RFC 中定義的相容性範圍內進行升級,您就能確保日後的 TFX 管線能夠持續運作。
安裝

![]()
pip install tfx
夜間套件
TFX 還透過 Google Cloud 在 https://pypi-nightly.tensorflow.org 代管了夜間套件。如要安裝最新的夜間套件,請使用以下指令:
pip install -i https://pypi-nightly.tensorflow.org/simple --pre tfx
這個指令會安裝 TFX 的主要依附元件 (例如 TensorFlow Model Analysis (TFMA)、TensorFlow Data Validation (TFDV), TensorFlow Transform (TFT)、TFX Basic Shared Libraries (TFX-BSL)、ML Metadata (MLMD)) 所適用的夜間套件。
關於 TFX
TFX 平台可讓你在實際工作環境中,建構及管理機器學習工作流程。TFX 提供以下功能:
用於建構機器學習管線的工具包。TFX 管線可讓您自動化調度管理多個平台 (例如 Apache Airflow、Apache Beam 和 Kubeflow 管線) 上的機器學習工作流程。
你可以在管線或是機器學習訓練指令碼中使用的標準元件組。TFX 標準元件提供經驗證的功能,協助您輕鬆開始建構機器學習程序。
為許多標準元件提供基本功能的程式庫。您可以使用 TFX 程式庫將這項功能新增至自訂元件,也可以單獨使用 TFX 程式庫。
TFX 是奠基於 TensorFlow 的機器學習工具包,具備 Google 的實際工作環境規模。這個工具包提供了設定架構和共用程式庫,可用來整合定義、啟動及監控機器學習系統所需的通用元件。
TFX 標準元件
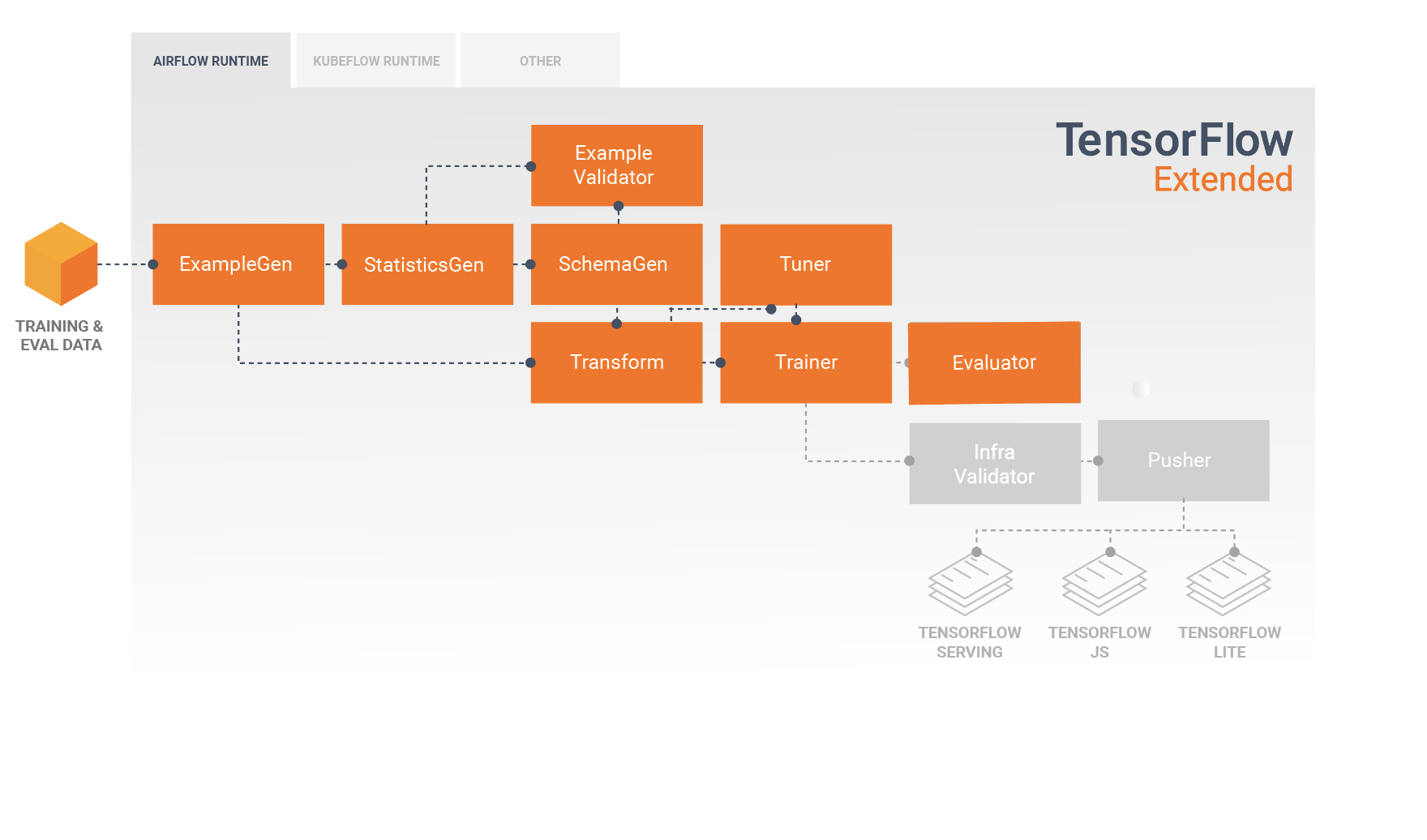
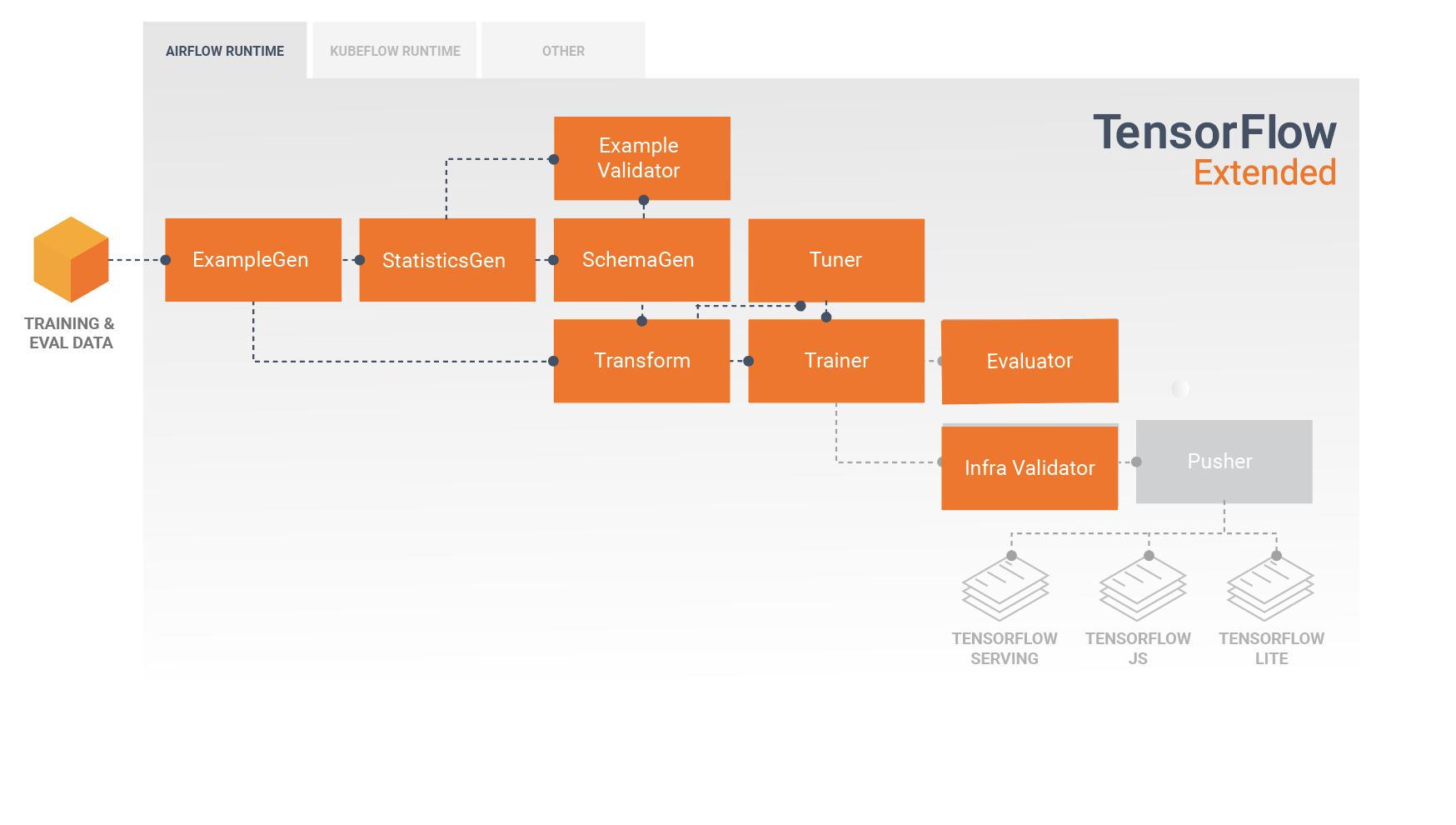
TFX 管線是實作機器學習管線的一系列元件,專門用於可擴充的高效能機器學習工作,包括建立模型、進行訓練、提供推論,以及管理線上、原生行動裝置和 JavaScript 目標的部署。
TFX 管線通常包含下列元件:
ExampleGen:這是管線的初始輸入元件,會擷取輸入資料集並視需要加以分割。
StatisticsGen:可計算資料集的統計資料。
SchemaGen:可檢驗統計資料並建立資料結構定義。
ExampleValidator:可查看資料集內是否有異常狀況和遺漏的值。
Transform:可對資料集執行特徵工程。
Trainer:可訓練模型。
Tuner:可調整模型的超參數。
Evaluator:可針對訓練結果執行深入分析,並協助您驗證匯出的模型,確保這些模型達到要求,可推送至生產環境。
InfraValidator:可檢查模型是否確實可從基礎架構提供,並避免推送未達到要求的模型。
Pusher:可在提供服務的基礎架構上部署模型。
BulkInferrer:可針對包含未標示推論要求的模型執行批次處理。
這些元件之間的資料流向如下圖所示:
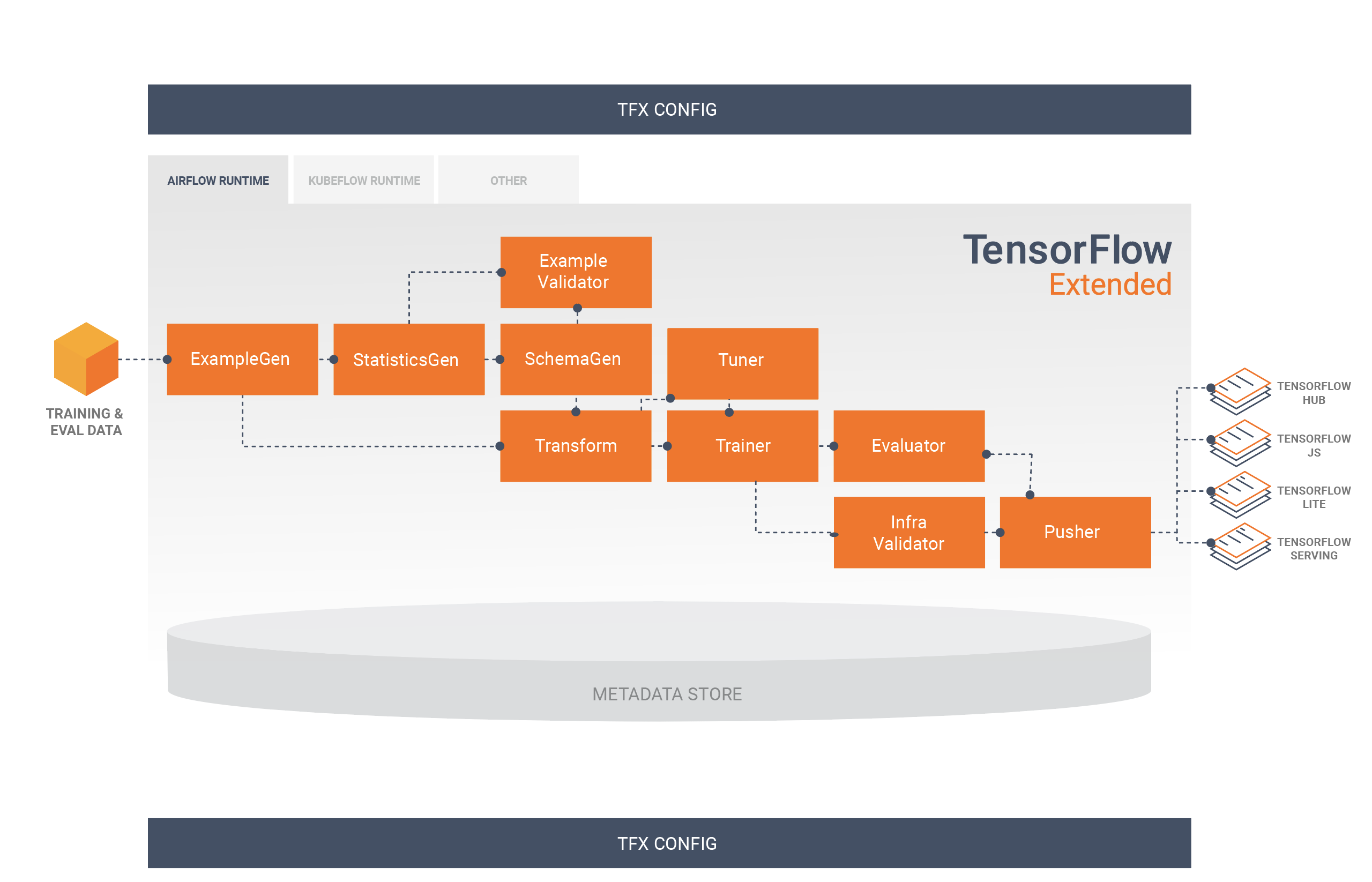
TFX 程式庫
TFX 包含程式庫和管線元件。TFX 程式庫與管線元件之間的關係如下圖所示:
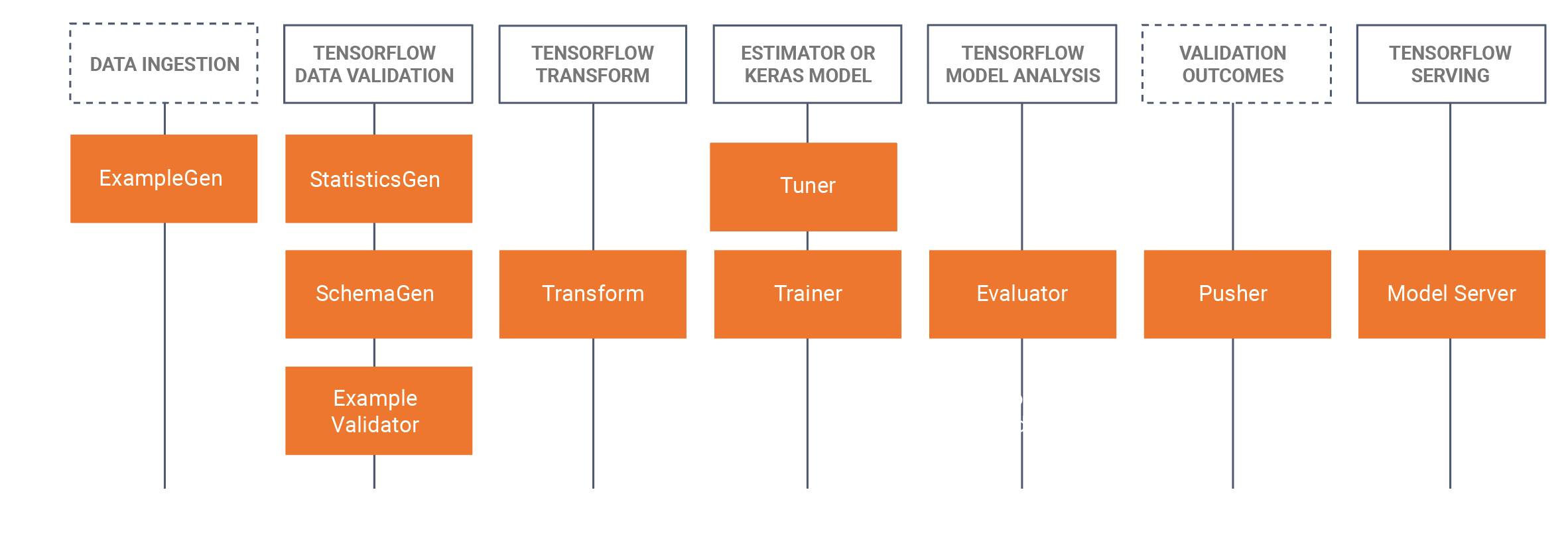
TFX 提供多個 Python 套件,這些套件是用來建立管線元件的程式庫。您將使用這些程式庫來建立管線元件,如此一來,便可將程式碼的重點放在管線的特點。
TFX 程式庫包含:
TensorFlow Data Validation (TFDV):這是用於分析及驗證機器學習資料的程式庫,其設計具備高擴充性,適合與 TensorFlow 和 TFX 搭配使用。TFDV 包含:
- 可擴充的訓練和測試資料統計資料摘要計算功能。
整合資料分布和統計資料的檢視器,以及資料集組合 (Facet) 的多面向比較。
自動產生資料結構定義以描述對於資料的預期,例如所需值、範圍和詞彙等。
可協助您檢查結構定義的結構定義檢視器。
可識別異常情況的異常偵測功能,例如:識別遺漏特徵、超出範圍的值或錯誤特徵類型等等。
異常狀況檢視器:讓您查看有異常狀況的特徵,並瞭解詳情以修正問題。
TensorFlow Transform (TFT):這是用來搭配 TensorFlow 預先處理資料的程式庫。TensorFlow Transform 很適合用於需要完整傳送的資料,例如:
- 依平均值和標準差將輸入值正規化。
- 產生所有輸入值的詞彙,藉此將字串轉換為整數。
- 根據觀測到的資料分布情形將浮點值指派至特徵分塊,藉此將浮點值轉換為整數。
TensorFlow:用於搭配 TFX 訓練模型。TensorFlow 可擷取訓練資料和建模程式碼,並建立 SavedModel 結果。此外,TensorFlow 還整合了 TensorFlow Transform 為預先處理輸入資料所建立的特徵工程管線。
KerasTuner:可用於調整模型的超參數。
TensorFlow Model Analysis (TFMA):這是用來評估 TensorFlow 模型的程式庫,可搭配 TensorFlow 來建立 EvalSavedModel,做為分析的依據。使用者可透過這個程式庫,使用訓練程式中定義的相同指標,以分散的方式評估大量資料的模型。這些指標可根據不同的資料片段運算得出,並在 Jupyter 筆記本中以視覺化的方式呈現。
TensorFlow Metadata (TFMD):提供中繼資料的標準表示法,在使用 TensorFlow 訓練機器學習模型時相當實用。中繼資料可由手動產生,也可以在輸入資料分析期間自動產生,並可用於資料驗證、探索和轉換。中繼資料序列化格式包括:
- 說明表格資料的結構定義 (例如 tf.Examples)。
- 這類資料集的統計資料摘要集合。
ML Metadata (MLMD):這是一種程式庫,用於記錄和擷取有關機器學習開發人員和數據資料學家工作流程的中繼資料。多數中繼資料都使用 TFMD 表示法。MLMD 使用 SQL-Lite、MySQL 以及其他類似的資料儲存庫來管理穩定性。
支援技術
必要
- Apache Beam 是開放原始碼形式的整合式模型,用於定義批次和串流資料平行處理管線。TFX 使用 Apache Beam 來實作資料平行管線。然後,管線會由 Beam 支援的其中一個分散式處理後端執行,這些後端包括 Apache Flink、Apache Spark、Google Cloud Dataflow 等等。
選用
Apache Airflow 和 Kubeflow 等自動化調度管理工具可讓您更輕鬆地設定、操作、監控及維護機器學習管線。
Apache Airflow 是一個平台,可讓您透過程式輔助的方式編寫、排程及監控工作流程。TFX 使用 Airflow 將工作流程編寫為工作的有向非循環圖 (DAG),而 Airflow 排程器會執行工作站陣列的工作,並且遵循指定的相依性。多樣化的指令列公用程式可讓您輕鬆在 DAG 上執行複雜的程序。豐富的使用者介面方便您以視覺化的方式呈現在生產環境中執行的管線、監控進度,並視需要進行疑難排解。將工作流程定義為程式碼,即可更輕鬆地進行維護、建立版本、測試和協同合作。
Kubeflow 旨在方便您於 Kubernetes 中部署機器學習 (ML) 工作流程,並提高其可攜性與可擴充性。Kubeflow 的目標並非重新建立其他服務,而是讓您能以輕鬆直接的方式,將業界最佳的機器學習開放原始碼系統部署至不同基礎架構。Kubeflow Pipelines 可讓您在 Kubeflow 上撰寫和執行可重現的工作流程,並整合實驗功能和筆記本式的體驗。Kubernetes 上的 Kubeflow Pipelines 服務包括託管中繼資料儲存庫、容器型自動化調度管理引擎、筆記本伺服器和使用者介面,可協助使用者大規模開發、執行及管理複雜的機器學習管線。Kubeflow Pipelines SDK 可讓您透過程式輔助的方式,來建立和共用管線的元件與組合。
可攜性和互通性
TFX 經過特別設計,可攜至多種環境和自動化調度管理架構,包括 Apache Airflow、Apache Beam 和 Kubeflow。此外,TFX 還能攜至不同的運算平台,包括內部部署平台和 Google Cloud Platform (GCP) 等雲端平台。特別的是,TFX 可與多個受管理的 GCP 服務互通,例如用於訓練和預測的 Cloud AI 平台,以及用於分散式資料處理的 Cloud Dataflow (適用於機器學習生命週期的其他多個層面)。
模型與 SavedModel 的比較
模型
模型是訓練程序的輸出內容,是在訓練過程中學習到的權重序列化記錄。這些權重之後可用於計算新輸入範例的預測結果。對於 TFX 和 TensorFlow 而言,「模型」是指包含到目前為止所學權重的查核點。
請注意,「模型」也可能是指 TensorFlow 運算圖形 (即 Python 檔案) 的定義,用於表示預測結果的運算方式。這兩種意思可能會根據情境交替使用。
SavedModel
- SavedModel 的定義:TensorFlow 模型的序列化格式,具有通用、適用於各語言、密封且可復原的特性。
- SavedModel 的重要性:可讓更高階的系統透過單一抽象層來產生、轉換及使用 TensorFlow 模型。
SavedModel 是我們推薦使用的序列化格式,適用於在生產環境中提供 TensorFlow 模型,或是為原生行動裝置或 JavaScript 應用程式匯出經過訓練的模型。舉例來說,如果您要將模型轉換為 REST 服務進行預測,可以將模型序列化為 SavedModel,並透過 Tensorflow Serving 來提供。詳情請參閱提供 TensorFlow 模型。
結構定義
部分 TFX 元件會使用名為「結構定義」的輸入資料說明。結構定義是 schema.proto 的執行個體,屬於一種通訊協定緩衝區,通常稱為「protobuf」。結構定義可以指定特徵值的資料類型、是否要在所有範例中顯示特徵、允許的值範圍以及其他屬性。使用 TensorFlow Data Validation (TFDV) 的其中一項優點是,它會根據訓練資料推論出類型、類別和範圍,進而自動產生結構定義。
以下是結構定義 protobuf 的摘錄:
...
feature {
name: "age"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_fraction: 1
min_count: 1
}
}
feature {
name: "capital-gain"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_fraction: 1
min_count: 1
}
}
...
下列元件使用結構定義:
- TensorFlow Data Validation
- TensorFlow Transform
在一般 TFX 管線中,TensorFlow Data Validation 會產生結構定義,並提供其他元件使用。
使用 TFX 進行開發
TFX 是適用於機器學習專案所有階段的強大平台,協助您在本機上研究、實驗、開發並進行部署。為了避免程式碼重複,並排除發生訓練/應用偏差的可能,我們強烈建議您為模型訓練和訓練模型部署實作 TFX 管線,並透過運用 TensorFlow Transform 程式庫的 Transform 元件來進行訓練和推論。如此一來,您就能一致地使用相同的預先處理和分析程式碼,避免用於訓練的資料與在生產環境中提供給訓練模型的資料有差異,而且只需撰寫一次程式碼即可。
資料探索、視覺化和清除
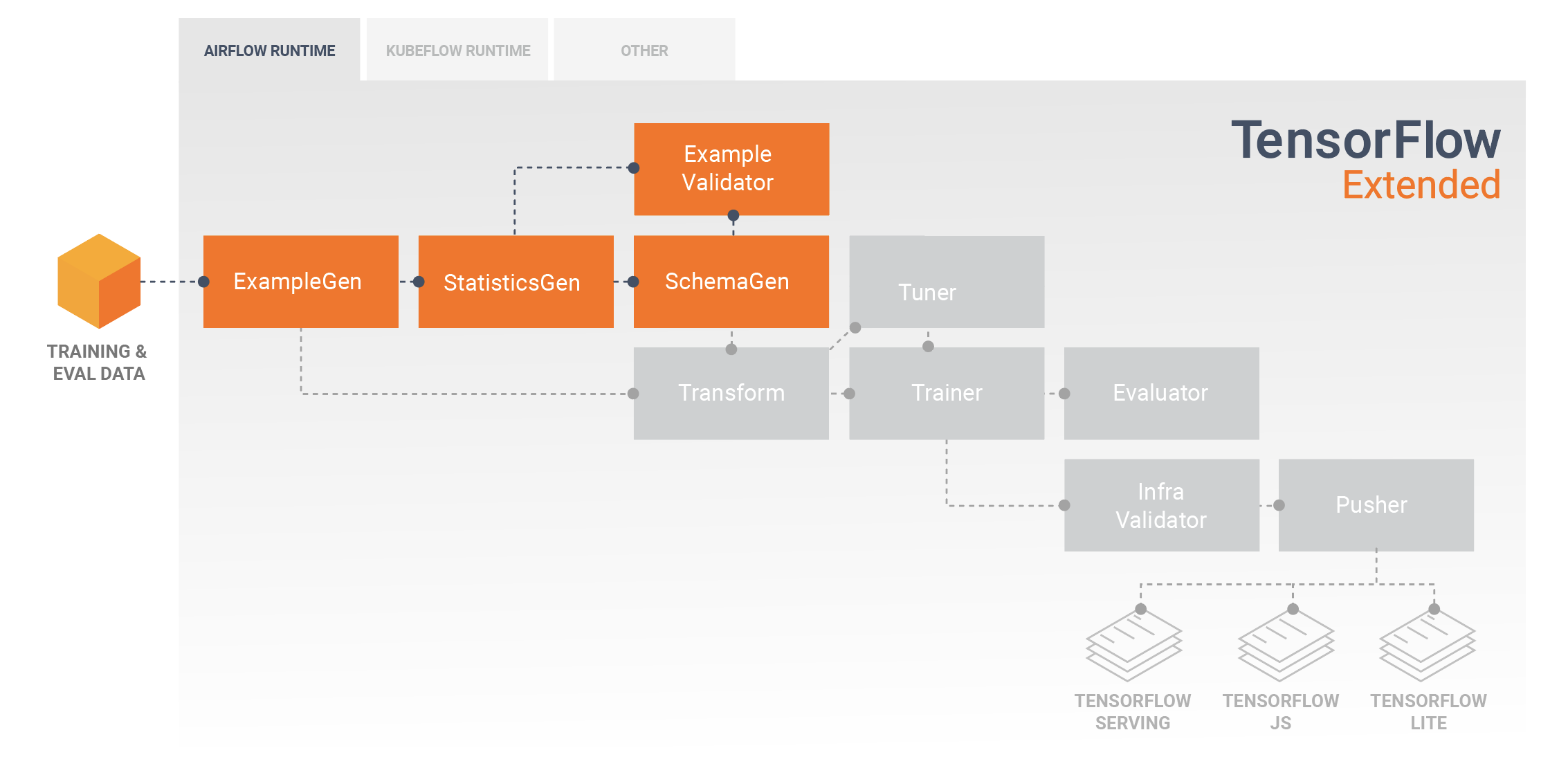
TFX 管線通常是以 ExampleGen 元件做為開頭,這個元件會接受輸入資料,並將資料轉換為 tf.Examples 的格式。這項作業一般是在資料分割成訓練資料集和評估資料集後才進行,因此實際上會有兩個 ExampleGen 元件副本,分別用於訓練和評估。通常後面會接著 StatisticsGen 元件和 SchemaGen 元件,負責檢查您的資料並推論資料結構定義和統計資料。ExampleValidator 元件將會使用結構定義和統計資料,藉此查看資料中是否有異常情況、遺漏的值以及不正確的資料類型。所有上述元件都會運用 TensorFlow Data Validation 程式庫的功能。
TensorFlow Data Validation (TFDV) 是用來對資料集執行初始探索、視覺化及清除作業的重要工具。TFDV 會檢驗您的資料並推論資料類型、類別和範圍,然後自動協助您識別異常狀況和遺漏的值。TFDV 也提供了視覺化工具,協助您檢查及瞭解資料集。管線建立完成後,您可以從 MLMD 讀取中繼資料,並在 Jupyter 筆記本中使用 TFDV 視覺化工具來分析資料。
在您完成初始模型訓練和部署作業之後,可以使用 TFDV 監控部署模型推論要求的新資料,並查看是否有異常狀況和/或偏移。這項功能特別適合用於隨著趨勢或季節而變化的時間序列資料,可協助您掌握資料問題,或是需要使用新資料重新訓練模型的時機。
資料視覺化
在您透過使用 TFDV 的管線區段 (一般是 StatisticsGen、SchemaGen 及 ExampleValidator) 完成第一次資料執行後,即可在 Jupyter 樣式筆記本中以視覺化的方式呈現結果。對於之後的執行作業,您可以一邊進行調整一邊對照結果,直到資料符合模型和應用程式的需求為止。
您必須先查詢 ML Metadata (MLMD) 找出這些元件的執行結果,然後使用 TFDV 中的視覺化支援 API 在筆記本中建立視覺化內容,其中包括 tfdv.load_statstats() 和 tfdv.videoize_statstats()。透過這項視覺化呈現,您可以進一步瞭解資料集的特性,並視需要進行修改。
開發及訓練模型
![]()
一般 TFX 管線會包含 Transform 元件,這個元件會運用 TensorFlow Transform (TFT) 程式庫的功能執行特徵工程。Transform 元件會使用由 SchemaGene 元件建立的結構定義,並套用資料轉換來建立、組合及轉換將用於訓練模型的特徵。如果傳送至推論要求的資料可能一併顯示遺漏的值和轉換類型,那麼您就也必須在 Transform 元件中清除這些資料。在 TFX 中設計用於訓練的 TensorFlow 程式碼時,必須將某些重要因素納入考量。
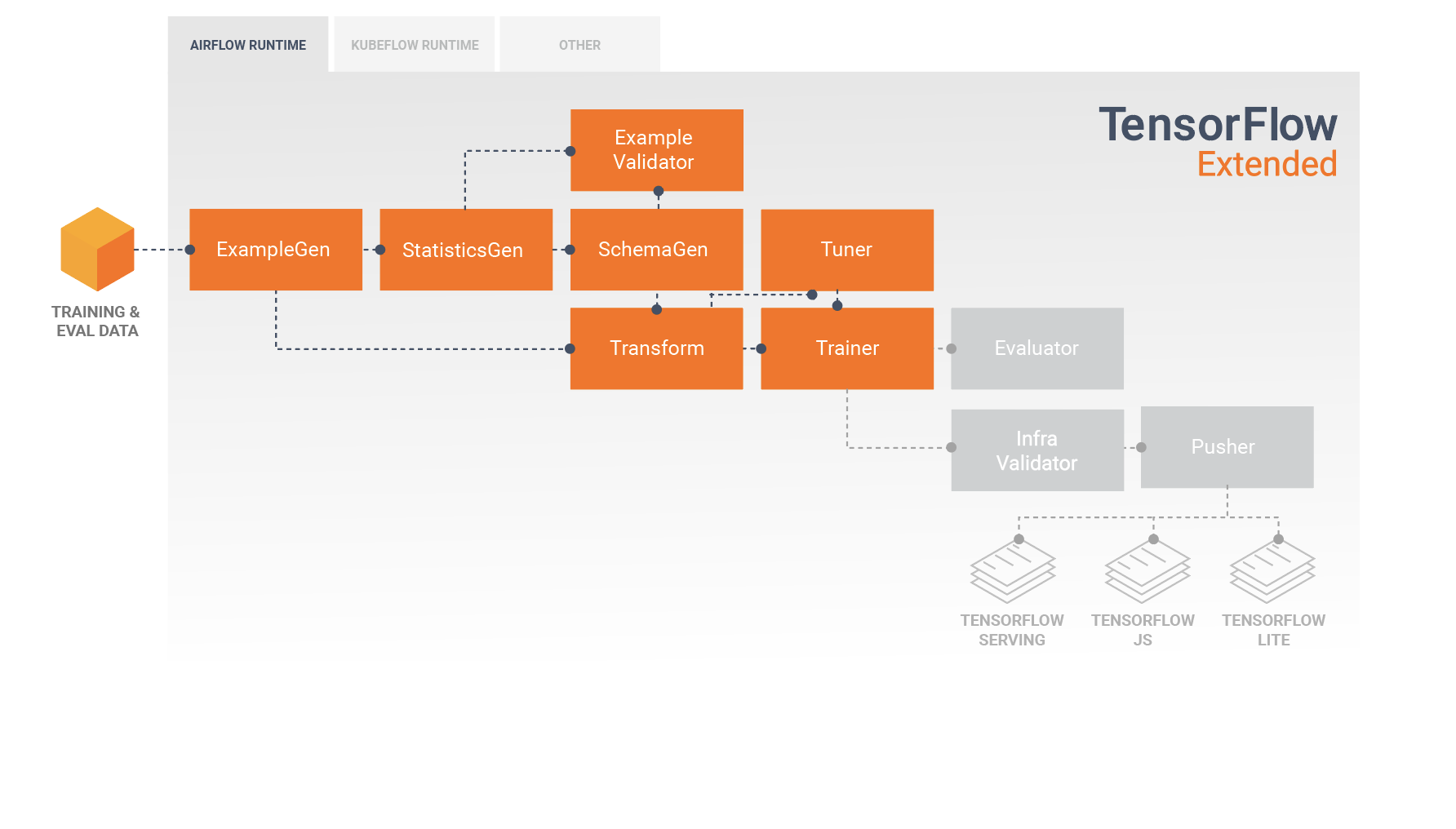
Transform 元件會產生 SavedModel,在 Trainer 元件執行期間匯入並用於 TensorFlow 中的建模程式碼。這個 SavedModel 包含所有在 Transform 元件中建立的資料工程轉換,因此在訓練和推論期間都會使用完全一樣的程式碼執行相同的轉換。您可以透過建模程式碼 (包括 Transform 元件中的 SavedModel) 來使用訓練資料和評估資料,並訓練自己的模型。
使用以 Estimator 為基礎的模型時,建模程式碼的最後一個部分應將模型儲存為 SavedModel 和 EvalSavedModel。只要儲存為 EvalSavedModel,即可確保訓練時使用的指標也可在評估時使用 (請注意,如果是以 Keras 為基礎的模型,則不一定要採取這個做法)。如要儲存為 EvalSavedModel,您必須在 Trainer 元件中匯入 TensorFlow Model Analysis (TFMA) 程式庫。
import tensorflow_model_analysis as tfma
...
tfma.export.export_eval_savedmodel(
estimator=estimator,
export_dir_base=eval_model_dir,
eval_input_receiver_fn=receiver_fn)
您可以在 Trainer 之前新增選用的 Tuner 元件,藉此調整模型的超參數 (例如層數)。有了指定的模型和超參數的搜尋空間,調整演算法會根據目標找出最佳超參數。
分析及瞭解模型成效
在完成初始模型開發及訓練作業之後,請務必分析及確實瞭解模型的成效。一般的 TFX 管線包含 Evaluator 元件,這個元件會運用 TensorFlow Model Analysis (TFMA) 程式庫所提供的強大工具集,協助進行這個階段的開發作業。Evaluator 元件會使用您先前匯出的模型,並讓您指定 tfma.SlicingSpec 清單,以便在視覺化呈現及分析模型成效時使用。您可以透過每個 SlicingSpec 來定義要檢驗的訓練資料片段,例如類別特徵的特定類別,或是數值特徵的特定範圍。
舉例來說,如果您想瞭解模型用於不同客層的成效 (例如依照年度消費、地理區域資料、年齡層或性別來區分的客層),這項做法就非常重要。這對於具有長尾的資料集而言尤其重要,因為主要群體的成效可能會掩蓋小型重要群體的極端成效。例如,您的模型可能在一般員工群體的成效還不錯,但完全不適用於高階主管,這對您而言可能是重要資訊。
模型分析與視覺化
訓練完模型並針對訓練結果執行 Evaluator 元件 (該元件運用 TFMA) 後,即表示已完成第一次的資料執行作業,這時您可以在 Jupyter 式筆記本中以視覺化的方式呈現結果。對於之後的執行作業,您可以一邊進行調整一邊對照結果,直到結果符合模型和應用程式的需求為止。
您必須先查詢 ML Metadata (MLMD) 找出這些元件的執行結果,然後使用 TFMA 中的視覺化支援 API 在筆記本中建立視覺化內容,其中包括 tfma.load_eval_results 和 tfma.view.render_slicing_metrics。透過這項視覺化內容,您可以進一步瞭解模型的特性,並視需要進行修改。
驗證模型成效
在分析模型的成效時,建議您根據某個基準 (例如目前提供的模型) 驗證成效。如要執行模型驗證作業,請將要驗證的模型和基準模型傳遞至 Evaluator 元件。Evaluator 會為要驗證的模型和基準模型計算各種指標 (例如 AUC、損失),以及一組對應的差異指標,然後套用閾值,用於將達到門檻的模型推送至生產環境。
驗證是否可提供模型
在部署經過訓練的模型之前,建議您先驗證是否確實可在提供服務的基礎架構中提供模型。這個驗證在實際工作環境中尤其重要,可確保新發布的模型不會禁止系統提供預測。InfraValidator 元件會在沙箱環境中建立模型的初期測試部署,並視需要傳送真實要求,以確認模型可正常運作。
部署目標
當您完成模型開發,並訓練出令人滿意的結果後,便可將模型部署到一個以上的部署目標以接收推論要求。TFX 支援三種類型的部署目標。匯出為 SavedModel 的已訓練模型可部署至這其中任一個或所有的部署目標。
推論:Tensorflow Serving
Tensorflow Serving (TFS) 是有彈性且高效能的機器學習模型提供系統,專為生產環境而設計。這個系統使用了 SavedModel,並且會接受透過 REST 或 gRPC 介面提出的推論要求。TFS 會在一個以上的網路伺服器上,以一組程序的形式執行,並使用其中一種進階架構來處理同步和分散式運算。請參閱 TFS 說明文件,進一步瞭解如何開發及部署 TFS 解決方案。
在一般管線中,透過 Trainer 元件完成訓練的 SavedModel 會先在 InfraValidator 元件中進行基礎架構驗證。InfraValidator 會啟動初期測試 TFS 模型伺服器以實際提供 SavedModel。如果通過驗證,Pusher 元件最終會將 SavedModel 部署至 TFS 基礎架構,包括處理多個版本和模型更新。
原生行動應用程式和 IoT 應用程式的推論:TensorFlow Lite
TensorFlow Lite 是一套工具,專門用來協助開發人員在原生行動應用程式和 IoT 應用程式中,使用經過訓練的 TensorFlow 模型。這套工具使用了與 TensorFlow Serving 相同的 SavedModel,並套用量化和修剪等最佳化功能,來改善成品模型的大小和效能,以因應在行動裝置和 IoT 裝置上執行模型的挑戰。請參閱 TensorFlow Lite 說明文件,進一步瞭解如何使用 TensorFlow Lite。
使用 JavaScript 執行推論:TensorFlow JS
TensorFlow JS 是 JavaScript 程式庫,用於在瀏覽器和 Node.js 中訓練及部署機器學習模型。這個程式庫使用了與 TensorFlow Serving 和 TensorFlow Lite 相同的 SavedModel,並且將這些模組轉換成 TensorFlow.js 網頁格式。請參閱 TensorFlow JS 說明文件,進一步瞭解如何使用 TensorFlow JS。
使用 Airflow 建立 TFX 管線
詳情請參閱 Airflow 工作坊
使用 Kubeflow 建立 TFX 管線
設定
Kubeflow 需要 Kubernetes 叢集才能大規模執行管線。請參閱 Kubeflow 部署指南,進一步瞭解部署 Kubeflow 叢集的選項。
設定及執行 TFX 管線
請參閱 Cloud AI 平台管線上的 TFX 教學課程,按照當中的說明透過 Kubeflow 執行 TFX 管線範例。TFX 元件已容器化以組成 Kubeflow 管線。範例中展現了如何設定管線,以讀取大型公開資料集,並在雲端執行大規模的訓練和資料處理步驟。
管線動作的指令列介面
TFX 提供統一的 CLI,可協助您執行各種管線動作,例如在 Apache Airflow、Apache Beam 和 Kubeflow 等多個自動化調度管理工具上建立、更新、執行、列出和刪除管線。詳情請參閱這些指示。