
সাধারণ
একটি EvalSavedModel এখনও প্রয়োজন?
পূর্বে TFMA-এর প্রয়োজন ছিল একটি বিশেষ EvalSavedModel ব্যবহার করে একটি tensorflow গ্রাফের মধ্যে সমস্ত মেট্রিক্স সংরক্ষণ করা। এখন, beam.CombineFn বাস্তবায়ন ব্যবহার করে TF গ্রাফের বাইরে মেট্রিক্স গণনা করা যেতে পারে।
কিছু প্রধান পার্থক্য হল:
- একটি
EvalSavedModelজন্য প্রশিক্ষকের কাছ থেকে একটি বিশেষ রপ্তানির প্রয়োজন হয় যেখানে একটি পরিবেশন মডেল প্রশিক্ষণ কোডে প্রয়োজনীয় কোনো পরিবর্তন ছাড়াই ব্যবহার করা যেতে পারে। - যখন একটি
EvalSavedModelব্যবহার করা হয়, প্রশিক্ষণের সময় যোগ করা যেকোন মেট্রিক মূল্যায়নের সময় স্বয়ংক্রিয়ভাবে উপলব্ধ হয়। একটিEvalSavedModelছাড়া এই মেট্রিক্স পুনরায় যোগ করা আবশ্যক.- এই নিয়মের ব্যতিক্রম হল যদি একটি কেরাস মডেল ব্যবহার করা হয় তবে মেট্রিকগুলি স্বয়ংক্রিয়ভাবে যোগ করা যেতে পারে কারণ কেরাস সংরক্ষিত মডেলের পাশে মেট্রিক তথ্য সংরক্ষণ করে।
TFMA কি ইন-গ্রাফ মেট্রিক্স এবং এক্সটার্নাল মেট্রিক্স উভয়ের সাথে কাজ করতে পারে?
TFMA একটি হাইব্রিড পদ্ধতি ব্যবহার করার অনুমতি দেয় যেখানে কিছু মেট্রিক্স ইন-গ্রাফে গণনা করা যেতে পারে যেখানে অন্যদের বাইরে গণনা করা যেতে পারে। আপনার যদি বর্তমানে একটি EvalSavedModel থাকে তাহলে আপনি এটি ব্যবহার করা চালিয়ে যেতে পারেন।
দুটি ক্ষেত্রে আছে:
- বৈশিষ্ট্য নিষ্কাশন এবং মেট্রিক গণনা উভয়ের জন্য TFMA
EvalSavedModelব্যবহার করুন তবে অতিরিক্ত কম্বাইনার-ভিত্তিক মেট্রিক্সও যোগ করুন। এই ক্ষেত্রে আপনিEvalSavedModelথেকে সমস্ত ইন-গ্রাফ মেট্রিক এবং কম্বাইনার-ভিত্তিক যেকোন অতিরিক্ত মেট্রিক্স পাবেন যা আগে সমর্থিত ছিল না। - বৈশিষ্ট্য/পূর্বাভাস নিষ্কাশনের জন্য TFMA
EvalSavedModelব্যবহার করুন কিন্তু সমস্ত মেট্রিক্স গণনার জন্য কম্বাইনার-ভিত্তিক মেট্রিক্স ব্যবহার করুন। এই মোডটি উপযোগী যদিEvalSavedModelএ বৈশিষ্ট্যের রূপান্তর উপস্থিত থাকে যা আপনি স্লাইস করার জন্য ব্যবহার করতে চান, কিন্তু গ্রাফের বাইরে সমস্ত মেট্রিক গণনা করতে পছন্দ করেন।
সেটআপ
কি ধরনের মডেল সমর্থিত?
TFMA কেরাস মডেল, জেনেরিক TF2 স্বাক্ষর API-এর উপর ভিত্তি করে মডেল, সেইসাথে TF অনুমানক ভিত্তিক মডেলগুলিকে সমর্থন করে (যদিও ব্যবহারের ক্ষেত্রে অনুমানকারী ভিত্তিক মডেলগুলির জন্য একটি EvalSavedModel ব্যবহার করার প্রয়োজন হতে পারে)।
সমর্থিত মডেল প্রকারের সম্পূর্ণ তালিকা এবং যেকোনো বিধিনিষেধের জন্য get_started গাইড দেখুন।
একটি নেটিভ কেরাস ভিত্তিক মডেলের সাথে কাজ করার জন্য আমি কীভাবে TFMA সেটআপ করব?
নিম্নলিখিত অনুমানের উপর ভিত্তি করে একটি কেরাস মডেলের জন্য নিম্নলিখিত একটি উদাহরণ কনফিগারেশন:
- সংরক্ষিত মডেলটি পরিবেশনের জন্য এবং স্বাক্ষর নামটি ব্যবহার করে
serving_default(এটিmodel_specs[0].signature_nameব্যবহার করে পরিবর্তন করা যেতে পারে)। -
model.compile(...)থেকে বিল্ট ইন মেট্রিক্সের মূল্যায়ন করা উচিত (এটি tfma.EvalConfig এর মধ্যেoptions.include_default_metricএর মাধ্যমে নিষ্ক্রিয় করা যেতে পারে)।
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here. For example:
# metrics { class_name: "ConfusionMatrixPlot" }
# metrics { class_name: "CalibrationPlot" }
}
slicing_specs {}
""", tfma.EvalConfig())
কনফিগার করা যেতে পারে এমন অন্যান্য ধরনের মেট্রিক্স সম্পর্কে আরও তথ্যের জন্য মেট্রিক্স দেখুন।
আমি কিভাবে একটি জেনেরিক TF2 স্বাক্ষর ভিত্তিক মডেলের সাথে কাজ করার জন্য TFMA সেটআপ করব?
নিম্নলিখিত একটি জেনেরিক TF2 মডেলের জন্য একটি উদাহরণ কনফিগারেশন। নীচে, signature_name হল নির্দিষ্ট স্বাক্ষরের নাম যা মূল্যায়নের জন্য ব্যবহার করা উচিত।
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "<signature-name>"
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here. For example:
# metrics { class_name: "BinaryCrossentropy" }
# metrics { class_name: "ConfusionMatrixPlot" }
# metrics { class_name: "CalibrationPlot" }
}
slicing_specs {}
""", tfma.EvalConfig())
কনফিগার করা যেতে পারে এমন অন্যান্য ধরনের মেট্রিক্স সম্পর্কে আরও তথ্যের জন্য মেট্রিক্স দেখুন।
একটি অনুমান ভিত্তিক মডেলের সাথে কাজ করার জন্য আমি কিভাবে TFMA সেটআপ করব?
এই ক্ষেত্রে তিনটি পছন্দ আছে।
বিকল্প 1: পরিবেশন মডেল ব্যবহার করুন
যদি এই বিকল্পটি ব্যবহার করা হয় তাহলে প্রশিক্ষণের সময় যোগ করা কোনো মেট্রিক মূল্যায়নে অন্তর্ভুক্ত করা হবে না।
নিম্নোক্ত একটি উদাহরণ কনফিগারেশন অনুমান করে serving_default ব্যবহৃত স্বাক্ষর নাম:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
কনফিগার করা যেতে পারে এমন অন্যান্য ধরনের মেট্রিক্স সম্পর্কে আরও তথ্যের জন্য মেট্রিক্স দেখুন।
বিকল্প 2: অতিরিক্ত কম্বাইনার-ভিত্তিক মেট্রিক্স সহ EvalSavedModel ব্যবহার করুন
এই ক্ষেত্রে, বৈশিষ্ট্য / পূর্বাভাস নিষ্কাশন এবং মূল্যায়ন উভয়ের জন্য EvalSavedModel ব্যবহার করুন এবং অতিরিক্ত কম্বাইনার ভিত্তিক মেট্রিক্স যোগ করুন।
নিম্নলিখিত একটি উদাহরণ কনফিগারেশন:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "eval"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
কনফিগার করা যেতে পারে এমন অন্যান্য ধরনের মেট্রিক সম্পর্কে আরও তথ্যের জন্য মেট্রিক্স দেখুন এবং EvalSavedModel সেট আপ করার বিষয়ে আরও তথ্যের জন্য EvalSavedModel দেখুন।
বিকল্প 3: শুধুমাত্র বৈশিষ্ট্য / পূর্বাভাস নিষ্কাশনের জন্য EvalSavedModel মডেল ব্যবহার করুন
বিকল্প(2) এর মতো, কিন্তু শুধুমাত্র বৈশিষ্ট্য/পূর্বাভাস নিষ্কাশনের জন্য EvalSavedModel ব্যবহার করুন। এই বিকল্পটি উপযোগী যদি শুধুমাত্র বাহ্যিক মেট্রিক্স পছন্দ করা হয়, তবে এমন বৈশিষ্ট্য রূপান্তর রয়েছে যা আপনি স্লাইস করতে চান। বিকল্পের অনুরূপ (1) প্রশিক্ষণের সময় যোগ করা কোনো মেট্রিক মূল্যায়নে অন্তর্ভুক্ত করা হবে না।
এই ক্ষেত্রে কনফিগার উপরের মত একই শুধুমাত্র include_default_metrics নিষ্ক্রিয় করা হয়েছে।
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
signature_name: "eval"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
options {
include_default_metrics { value: false }
}
""", tfma.EvalConfig())
কনফিগার করা যেতে পারে এমন অন্যান্য ধরনের মেট্রিক সম্পর্কে আরও তথ্যের জন্য মেট্রিক্স দেখুন এবং EvalSavedModel সেট আপ করার বিষয়ে আরও তথ্যের জন্য EvalSavedModel দেখুন।
কেরাস মডেল-টু-এস্টিমেটর ভিত্তিক মডেলের সাথে কাজ করার জন্য আমি কীভাবে TFMA সেটআপ করব?
keras model_to_estimator সেটআপ অনুমানকারী কনফিগারেশনের অনুরূপ। তবে মডেল থেকে অনুমানকারী কীভাবে কাজ করে তার নির্দিষ্ট কিছু পার্থক্য রয়েছে। বিশেষ করে, মডেল-থেকে-এসিমেটর তার আউটপুটগুলিকে একটি ডিক্ট আকারে ফেরত দেয় যেখানে ডিক্ট কীটি যুক্ত কেরাস মডেলের শেষ আউটপুট স্তরের নাম (যদি কোনো নাম দেওয়া না হয়, কেরাস আপনার জন্য একটি ডিফল্ট নাম বেছে নেবে। যেমন dense_1 বা output_1 )। একটি TFMA দৃষ্টিকোণ থেকে, এই আচরণটি একটি মাল্টি-আউটপুট মডেলের জন্য আউটপুট যা হবে তার অনুরূপ যদিও মডেল থেকে অনুমানকারী শুধুমাত্র একটি মডেলের জন্য হতে পারে। এই পার্থক্যের জন্য, আউটপুট নাম সেটআপ করার জন্য একটি অতিরিক্ত পদক্ষেপ প্রয়োজন। যাইহোক, অনুমানকারী হিসাবে একই তিনটি বিকল্প প্রযোজ্য।
অনুমানকারী ভিত্তিক কনফিগারেশনে প্রয়োজনীয় পরিবর্তনগুলির একটি উদাহরণ নিম্নলিখিত:
from google.protobuf import text_format
config = text_format.Parse("""
... as for estimator ...
metrics_specs {
output_names: ["<keras-output-layer>"]
# Add metrics here.
}
... as for estimator ...
""", tfma.EvalConfig())
প্রাক-গণনা করা (যেমন মডেল-অজ্ঞেয়বাদী) ভবিষ্যদ্বাণীগুলির সাথে কাজ করার জন্য আমি কীভাবে TFMA সেটআপ করব? ( TFRecord এবং tf.Example )
প্রাক-গণনা করা ভবিষ্যদ্বাণীগুলির সাথে কাজ করার জন্য TFMA কনফিগার করার জন্য, ডিফল্ট tfma.PredictExtractor অক্ষম করা আবশ্যক এবং tfma.InputExtractor অন্যান্য ইনপুট বৈশিষ্ট্যগুলির সাথে পূর্বাভাসগুলিকে পার্স করার জন্য কনফিগার করা আবশ্যক৷ লেবেল এবং ওজনের পাশাপাশি ভবিষ্যদ্বাণীর জন্য ব্যবহৃত বৈশিষ্ট্য কীটির নামের সাথে একটি tfma.ModelSpec কনফিগার করে এটি সম্পন্ন করা হয়।
নিম্নলিখিত একটি উদাহরণ সেটআপ:
from google.protobuf import text_format
config = text_format.Parse("""
model_specs {
prediction_key: "<prediction-key>"
label_key: "<label-key>"
example_weight_key: "<example-weight-key>"
}
metrics_specs {
# Add metrics here.
}
slicing_specs {}
""", tfma.EvalConfig())
কনফিগার করা যেতে পারে এমন মেট্রিক সম্পর্কে আরও তথ্যের জন্য মেট্রিক্স দেখুন।
উল্লেখ্য যে যদিও একটি tfma.ModelSpec কনফিগার করা হচ্ছে একটি মডেল আসলে ব্যবহার করা হচ্ছে না (যেমন কোন tfma.EvalSharedModel নেই)। মডেল বিশ্লেষণ চালানোর জন্য কলটি নিম্নরূপ দেখতে পারে:
eval_result = tfma.run_model_analysis(
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location="/path/to/file/containing/tfrecords",
output_path="/path/for/metrics_for_slice_proto")
প্রাক-গণনা করা (যেমন মডেল-অজ্ঞেয়বাদী) ভবিষ্যদ্বাণীগুলির সাথে কাজ করার জন্য আমি কীভাবে TFMA সেটআপ করব? ( pd.DataFrame )
মেমরিতে ফিট করতে পারে এমন ছোট ডেটাসেটের জন্য, একটি TFRecord এর বিকল্প হল একটি pandas.DataFrame ডেটাফ্রেম। TFMA tfma.analyze_raw_data API ব্যবহার করে pandas.DataFrame এ কাজ করতে পারে। tfma.MetricsSpec এবং tfma.SlicingSpec এর ব্যাখ্যার জন্য, সেটআপ গাইড দেখুন। কনফিগার করা যেতে পারে এমন মেট্রিক সম্পর্কে আরও তথ্যের জন্য মেট্রিক্স দেখুন।
নিম্নলিখিত একটি উদাহরণ সেটআপ:
# Run in a Jupyter Notebook.
df_data = ... # your pd.DataFrame
eval_config = text_format.Parse("""
model_specs {
label_key: 'label'
prediction_key: 'prediction'
}
metrics_specs {
metrics { class_name: "AUC" }
metrics { class_name: "ConfusionMatrixPlot" }
}
slicing_specs {}
slicing_specs {
feature_keys: 'language'
}
""", config.EvalConfig())
eval_result = tfma.analyze_raw_data(df_data, eval_config)
tfma.view.render_slicing_metrics(eval_result)
মেট্রিক্স
কি ধরনের মেট্রিক্স সমর্থিত?
TFMA বিভিন্ন ধরনের মেট্রিক্স সমর্থন করে যার মধ্যে রয়েছে:
- রিগ্রেশন মেট্রিক্স
- বাইনারি শ্রেণিবিন্যাস মেট্রিক্স
- মাল্টি-ক্লাস/মাল্টি-লেবেল ক্লাসিফিকেশন মেট্রিক্স
- মাইক্রো গড় / ম্যাক্রো গড় মেট্রিক্স
- প্রশ্ন / র্যাঙ্কিং ভিত্তিক মেট্রিক্স
মাল্টি-আউটপুট মডেলের মেট্রিক্স কি সমর্থিত?
হ্যাঁ। আরও বিস্তারিত জানার জন্য মেট্রিক্স গাইড দেখুন।
একাধিক মডেল থেকে মেট্রিক সমর্থিত?
হ্যাঁ। আরও বিস্তারিত জানার জন্য মেট্রিক্স গাইড দেখুন।
মেট্রিক সেটিংস (নাম, ইত্যাদি) কাস্টমাইজ করা যাবে?
হ্যাঁ। মেট্রিক কনফিগারেশনে config সেটিংস যোগ করে মেট্রিক্স সেটিংস কাস্টমাইজ করা যেতে পারে (যেমন নির্দিষ্ট থ্রেশহোল্ড সেট করা ইত্যাদি)। মেট্রিক্স গাইড দেখুন আরো বিস্তারিত আছে.
কাস্টম মেট্রিক্স সমর্থিত?
হ্যাঁ। হয় একটি কাস্টম tf.keras.metrics.Metric বাস্তবায়ন লিখে অথবা একটি কাস্টম beam.CombineFn বাস্তবায়ন লিখে৷ মেট্রিক্স গাইডে আরও বিশদ রয়েছে।
কি ধরনের মেট্রিক্স সমর্থিত নয়?
যতক্ষণ পর্যন্ত আপনার মেট্রিক একটি beam.CombineFn ব্যবহার করে গণনা করা যেতে পারে, tfma.metrics.Metric এর উপর ভিত্তি করে যে ধরনের মেট্রিক্স গণনা করা যেতে পারে তার উপর কোনো সীমাবদ্ধতা নেই। tf.keras.metrics.Metric থেকে প্রাপ্ত একটি মেট্রিক নিয়ে কাজ করলে নিম্নলিখিত মানদণ্ড অবশ্যই সন্তুষ্ট হতে হবে:
- প্রতিটি উদাহরণে মেট্রিকের জন্য পর্যাপ্ত পরিসংখ্যানকে স্বাধীনভাবে গণনা করা সম্ভব হওয়া উচিত, তারপরে সমস্ত উদাহরণ জুড়ে এই পর্যাপ্ত পরিসংখ্যানগুলিকে যুক্ত করে একত্রিত করুন এবং শুধুমাত্র এই পর্যাপ্ত পরিসংখ্যান থেকে মেট্রিকের মান নির্ধারণ করুন।
- উদাহরণস্বরূপ, নির্ভুলতার জন্য পর্যাপ্ত পরিসংখ্যান হল "সম্পূর্ণ সঠিক" এবং "মোট উদাহরণ"। পৃথক উদাহরণের জন্য এই দুটি সংখ্যা গণনা করা সম্ভব, এবং সেই উদাহরণগুলির জন্য সঠিক মান পেতে উদাহরণগুলির একটি গ্রুপের জন্য সেগুলি যোগ করুন। চূড়ান্ত নির্ভুলতা "সম্পূর্ণ সঠিক / মোট উদাহরণ" ব্যবহার করে গণনা করা যেতে পারে।
অ্যাড-অন
আমি কি আমার মডেলে ন্যায্যতা বা পক্ষপাত মূল্যায়ন করার জন্য TFMA ব্যবহার করতে পারি?
TFMA একটি FairnessIndicators অ্যাড-অন অন্তর্ভুক্ত করে যা শ্রেণীবিভাগের মডেলগুলিতে অনিচ্ছাকৃত পক্ষপাতের প্রভাবগুলি মূল্যায়নের জন্য রপ্তানি-পরবর্তী মেট্রিক্স প্রদান করে।
কাস্টমাইজেশন
আমার আরো কাস্টমাইজেশন প্রয়োজন হলে কি হবে?
TFMA খুবই নমনীয় এবং আপনাকে কাস্টম Extractors , Evaluators এবং/অথবা Writers ব্যবহার করে পাইপলাইনের প্রায় সব অংশ কাস্টমাইজ করতে দেয়। এই বিমূর্ততাগুলি আর্কিটেকচার নথিতে আরও বিশদে আলোচনা করা হয়েছে।
সমস্যা সমাধান, ডিবাগিং এবং সাহায্য পাওয়া
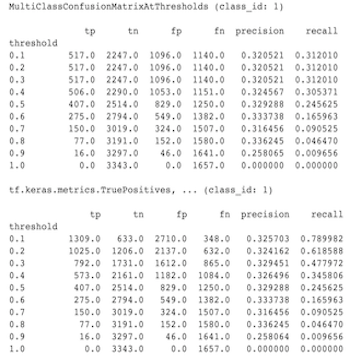
কেন মাল্টিক্লাস কনফিউশনম্যাট্রিক্স মেট্রিক্স বাইনারিকৃত কনফিউশনম্যাট্রিক্স মেট্রিক্সের সাথে মেলে না
এগুলো আসলে ভিন্ন হিসাব। বাইনারাইজেশন প্রতিটি ক্লাস আইডির জন্য স্বাধীনভাবে একটি তুলনা করে (অর্থাৎ প্রতিটি শ্রেণীর জন্য পূর্বাভাস প্রদত্ত থ্রেশহোল্ডের সাথে আলাদাভাবে তুলনা করা হয়)। এই ক্ষেত্রে দুই বা ততোধিক শ্রেণির জন্য ইঙ্গিত করা সম্ভব যে তারা ভবিষ্যদ্বাণীর সাথে মিলেছে কারণ তাদের পূর্বাভাসিত মান থ্রেশহোল্ডের চেয়ে বেশি ছিল (নিম্ন প্রান্তিকে এটি আরও বেশি স্পষ্ট হবে)। মাল্টিক্লাস কনফিউশন ম্যাট্রিক্সের ক্ষেত্রে, এখনও শুধুমাত্র একটি সত্য ভবিষ্যদ্বাণী করা মান আছে এবং এটি হয় প্রকৃত মানের সাথে মেলে বা হয় না। থ্রেশহোল্ড শুধুমাত্র থ্রেশহোল্ডের চেয়ে কম হলে কোনো ক্লাসের সাথে মেলে না এমন ভবিষ্যদ্বাণীকে বাধ্য করতে ব্যবহৃত হয়। থ্রেশহোল্ড যত বেশি হবে বাইনারাইজড ক্লাসের ভবিষ্যতবাণী মেলানো তত কঠিন। একইভাবে থ্রেশহোল্ড যত কম হবে একটি বাইনারি করা ক্লাসের ভবিষ্যতবাণী মেলানো তত সহজ। এর মানে হল যে থ্রেশহোল্ড > 0.5 এ বাইনারিকৃত মান এবং মাল্টিক্লাস ম্যাট্রিক্স মান কাছাকাছি সারিবদ্ধ হবে এবং থ্রেশহোল্ড <0.5 এ তারা আরও দূরে থাকবে।
উদাহরণ স্বরূপ, ধরা যাক আমাদের 10টি ক্লাস আছে যেখানে ক্লাস 2 এর সম্ভাব্যতা 0.8 দিয়ে ভবিষ্যদ্বাণী করা হয়েছিল, কিন্তু প্রকৃত ক্লাসটি ক্লাস 1 ছিল যার সম্ভাব্যতা 0.15 ছিল। আপনি যদি ক্লাস 1-এ বাইনারি করেন এবং 0.1-এর থ্রেশহোল্ড ব্যবহার করেন, তাহলে ক্লাস 1 সঠিক বলে বিবেচিত হবে (0.15 > 0.1) তাই এটি একটি TP হিসাবে গণনা করা হবে, তবে, মাল্টিক্লাস ক্ষেত্রে, ক্লাস 2 সঠিক বলে বিবেচিত হবে (0.8 > 0.1) এবং যেহেতু ক্লাস 1 প্রকৃত ছিল, এটি একটি FN হিসাবে গণনা করা হবে৷ কারণ নিম্ন থ্রেশহোল্ডে বেশি মান ধনাত্মক বলে বিবেচিত হবে, সাধারণভাবে মাল্টিক্লাস কনফিউশন ম্যাট্রিক্সের তুলনায় বাইনারিকৃত কনফিউশন ম্যাট্রিক্সের জন্য উচ্চতর TP এবং FP গণনা হবে এবং একইভাবে নিম্ন TN এবং FN হবে।
মাল্টিক্লাস কনফিউশনম্যাট্রিক্সঅ্যাটথ্রেশহোল্ড এবং ক্লাসগুলির একটির বাইনারিকরণ থেকে সংশ্লিষ্ট গণনার মধ্যে পর্যবেক্ষণ করা পার্থক্যের একটি উদাহরণ নিম্নলিখিত।
কেন আমার নির্ভুলতা @ 1 এবং রিকল @ 1 মেট্রিক্স একই মান আছে?
একটি শীর্ষে k মান 1 নির্ভুলতা এবং প্রত্যাহার একই জিনিস। নির্ভুলতা TP / (TP + FP) এর সমান এবং প্রত্যাহার TP / (TP + FN) এর সমান। শীর্ষ ভবিষ্যদ্বাণী সর্বদা ইতিবাচক এবং হয় লেবেলের সাথে মিলবে বা না মিলবে। অন্য কথায়, N উদাহরণ সহ, TP + FP = N যাইহোক, যদি লেবেলটি শীর্ষ ভবিষ্যদ্বাণীর সাথে মেলে না, তাহলে এটিও বোঝায় যে একটি নন-টপ k ভবিষ্যদ্বাণী মিলেছে এবং টপ k 1-এ সেট করা হলে, সমস্ত নন-টপ 1 ভবিষ্যদ্বাণী 0 হবে। এর অর্থ FN হতে হবে (N - TP) বা N = TP + FN । শেষ ফলাফল হল precision@1 = TP / N = recall@1 । মনে রাখবেন যে এটি শুধুমাত্র তখনই প্রযোজ্য যখন প্রতি উদাহরণে একটি একক লেবেল থাকে, বহু-লেবেলের জন্য নয়।
কেন আমার গড়_লেবেল এবং গড়_পূর্বাভাস মেট্রিক সবসময় 0.5 হয়?
এটি সম্ভবত ঘটছে কারণ মেট্রিকগুলি একটি বাইনারি শ্রেণিবিন্যাসের সমস্যার জন্য কনফিগার করা হয়েছে, কিন্তু মডেলটি শুধুমাত্র একটির পরিবর্তে উভয় শ্রেণীর জন্য সম্ভাব্যতা আউটপুট করছে। tensorflow এর শ্রেণীবিভাগ API ব্যবহার করা হলে এটি সাধারণ। সমাধান হল আপনি যে ক্লাসের উপর ভিত্তি করে ভবিষ্যদ্বাণী করতে চান সেটি বেছে নেওয়া এবং তারপর সেই ক্লাসের উপর বাইনারি করা। যেমন:
eval_config = text_format.Parse("""
...
metrics_specs {
binarize { class_ids: { values: [0] } }
metrics { class_name: "MeanLabel" }
metrics { class_name: "MeanPrediction" }
...
}
...
""", config.EvalConfig())
মাল্টিলেবেল কনফিউশন ম্যাট্রিক্সপ্লট কীভাবে ব্যাখ্যা করবেন?
একটি নির্দিষ্ট লেবেল দেওয়া হলে, MultiLabelConfusionMatrixPlot (এবং সংশ্লিষ্ট MultiLabelConfusionMatrix ) অন্যান্য লেবেলের ফলাফল এবং তাদের ভবিষ্যদ্বাণীর তুলনা করতে ব্যবহার করা যেতে পারে যখন নির্বাচিত লেবেলটি আসলে সত্য ছিল। উদাহরণ স্বরূপ, ধরা যাক আমাদের তিনটি শ্রেণির bird , plane এবং superman রয়েছে এবং আমরা ছবিগুলিকে শ্রেণীবদ্ধ করছি যাতে নির্দেশ করা যায় যে সেগুলিতে এই শ্রেণীর একটি বা একাধিক রয়েছে কিনা। MultiLabelConfusionMatrix প্রতিটি প্রকৃত শ্রেণীর কার্টেসিয়ান পণ্যকে একে অপরের শ্রেণীর (যাকে ভবিষ্যদ্বাণীকৃত শ্রেণী বলা হয়) এর বিপরীতে গণনা করবে। মনে রাখবেন যে পেয়ারিংটি (actual, predicted) হওয়া সত্ত্বেও, predicted শ্রেণীটি অগত্যা একটি ইতিবাচক ভবিষ্যদ্বাণী বোঝায় না, এটি প্রকৃত বনাম পূর্বাভাসিত ম্যাট্রিক্সের পূর্বাভাসিত কলামের প্রতিনিধিত্ব করে। উদাহরণস্বরূপ, ধরা যাক আমরা নিম্নলিখিত ম্যাট্রিক্সগুলি গণনা করেছি:
(bird, bird) -> { tp: 6, fp: 0, fn: 2, tn: 0}
(bird, plane) -> { tp: 2, fp: 2, fn: 2, tn: 2}
(bird, superman) -> { tp: 1, fp: 1, fn: 4, tn: 2}
(plane, bird) -> { tp: 3, fp: 1, fn: 1, tn: 3}
(plane, plane) -> { tp: 4, fp: 0, fn: 4, tn: 0}
(plane, superman) -> { tp: 1, fp: 3, fn: 3, tn: 1}
(superman, bird) -> { tp: 3, fp: 2, fn: 2, tn: 2}
(superman, plane) -> { tp: 2, fp: 3, fn: 2, tn: 2}
(superman, superman) -> { tp: 4, fp: 0, fn: 5, tn: 0}
num_examples: 20
MultiLabelConfusionMatrixPlot ম্যাট্রিক্সপ্লটটিতে এই ডেটা প্রদর্শন করার তিনটি উপায় রয়েছে। সব ক্ষেত্রেই প্রকৃত ক্লাসের দৃষ্টিকোণ থেকে সারি সারি সারি সারি পড়ার উপায়।
1) মোট ভবিষ্যদ্বাণী গণনা
এই ক্ষেত্রে, একটি প্রদত্ত সারির জন্য (অর্থাৎ প্রকৃত শ্রেণী) অন্যান্য শ্রেণীর জন্য TP + FP গণনা কি ছিল। উপরের গণনার জন্য, আমাদের প্রদর্শন নিম্নরূপ হবে:
| ভবিষ্যদ্বাণী করা পাখি | পূর্বাভাসিত বিমান | ভবিষ্যদ্বাণী করা সুপারম্যান | |
|---|---|---|---|
| আসল পাখি | 6 | 4 | 2 |
| প্রকৃত বিমান | 4 | 4 | 4 |
| প্রকৃত সুপারম্যান | 5 | 5 | 4 |
ছবিগুলো আসলে একটি bird থাকা অবস্থায় আমরা সঠিকভাবে তাদের মধ্যে ৬টির ভবিষ্যদ্বাণী করেছি। একই সময়ে আমরা plane (সঠিকভাবে বা ভুলভাবে) 4 বার এবং superman (সঠিক বা ভুলভাবে) 2 বার ভবিষ্যদ্বাণী করেছি।
2) ভুল ভবিষ্যদ্বাণী গণনা
এই ক্ষেত্রে, একটি প্রদত্ত সারির জন্য (অর্থাৎ প্রকৃত শ্রেণী) অন্যান্য শ্রেণীর জন্য FP গণনা কি ছিল। উপরের গণনার জন্য, আমাদের প্রদর্শন নিম্নরূপ হবে:
| ভবিষ্যদ্বাণী করা পাখি | পূর্বাভাসিত বিমান | ভবিষ্যদ্বাণী করা সুপারম্যান | |
|---|---|---|---|
| আসল পাখি | 0 | 2 | 1 |
| প্রকৃত বিমান | 1 | 0 | 3 |
| প্রকৃত সুপারম্যান | 2 | 3 | 0 |
যখন ছবিগুলিতে আসলে একটি bird ছিল তখন আমরা ভুলভাবে plane 2 বার এবং superman 1 বার ভবিষ্যদ্বাণী করেছি।
3) মিথ্যা নেতিবাচক গণনা
এই ক্ষেত্রে, একটি প্রদত্ত সারির জন্য (অর্থাৎ প্রকৃত শ্রেণী) অন্যান্য শ্রেণীর জন্য FN গণনা কি ছিল। উপরের গণনার জন্য, আমাদের প্রদর্শন নিম্নরূপ হবে:
| ভবিষ্যদ্বাণী করা পাখি | পূর্বাভাসিত বিমান | ভবিষ্যদ্বাণী করা সুপারম্যান | |
|---|---|---|---|
| আসল পাখি | 2 | 2 | 4 |
| প্রকৃত বিমান | 1 | 4 | 3 |
| প্রকৃত সুপারম্যান | 2 | 2 | 5 |
ছবিগুলিতে যখন একটি bird ছিল তখন আমরা এটি 2 বার ভবিষ্যদ্বাণী করতে ব্যর্থ হয়েছি। একই সময়ে, আমরা 2 বার plane এবং 4 বার superman ভবিষ্যদ্বাণী করতে ব্যর্থ হয়েছি।
আমি কেন ভবিষ্যদ্বাণী কী খুঁজে পাওয়া যায়নি সম্পর্কে একটি ত্রুটি পেতে পারি?
কিছু মডেলের আউটপুট একটি অভিধান আকারে তাদের ভবিষ্যদ্বাণী. উদাহরণস্বরূপ, বাইনারি শ্রেণীবিভাগ সমস্যার জন্য একটি TF অনুমানকারী probabilities , class_ids , ইত্যাদি সম্বলিত একটি অভিধান আউটপুট করে৷ বেশিরভাগ ক্ষেত্রে TFMA-তে সাধারণভাবে ব্যবহৃত কী নামগুলি যেমন predictions , probabilities ইত্যাদি খুঁজে পেতে ডিফল্ট থাকে৷ তবে, যদি আপনার মডেলটি খুব কাস্টমাইজ করা হয় তবে এটি হতে পারে TFMA দ্বারা অজানা নামের অধীনে আউটপুট কী। এইসব ক্ষেত্রে আউটপুটটি যে কী-এর অধীনে সংরক্ষিত হয় তার নাম শনাক্ত করতে tfma.ModelSpec এ একটি prediciton_key সেটিংস যোগ করতে হবে।