
מדריך זה מראה לך כיצד להשתמש ב- TensorFlow Transform (ספריית tf.Transform ) כדי ליישם עיבוד מקדים של נתונים עבור למידת מכונה (ML). ספריית tf.Transform עבור TensorFlow מאפשרת לך להגדיר גם טרנספורמציות נתונים ברמת המופע וגם במעבר מלא באמצעות צינורות עיבוד מקדים של נתונים. צינורות אלו מבוצעים ביעילות עם Apache Beam והם יוצרים כתוצרי לוואי גרף TensorFlow כדי להחיל את אותן טרנספורמציות במהלך חיזוי כמו בעת הגשת המודל.
מדריך זה מספק דוגמה מקצה לקצה באמצעות Dataflow כרץ עבור Apache Beam. זה מניח שאתה מכיר את BigQuery , Dataflow, Vertex AI ו- TensorFlow Keras API. זה גם מניח שיש לך ניסיון מסוים בשימוש במחשבי Jupyter, כגון עם Vertex AI Workbench .
מדריך זה גם מניח שאתה מכיר את המושגים של סוגי עיבוד מקדים, אתגרים ואפשרויות ב-Google Cloud, כפי שמתואר בעיבוד מקדים של נתונים עבור ML: אפשרויות והמלצות .
מטרות
- הטמע את צינור Apache Beam באמצעות ספריית
tf.Transform. - הפעל את הצינור ב-Dataflow.
- הטמע את מודל TensorFlow באמצעות ספריית
tf.Transform. - אימון והשתמש במודל לתחזיות.
עלויות
מדריך זה משתמש ברכיבים הבאים לחיוב של Google Cloud:
כדי להעריך את העלות להפעלת מדריך זה, בהנחה שאתה משתמש בכל משאב במשך יום שלם, השתמש במחשבון התמחור המוגדר מראש.
לפני שתתחיל
במסוף Google Cloud, בדף בורר הפרויקטים, בחר או צור פרויקט של Google Cloud .
ודא שהחיוב מופעל עבור פרויקט הענן שלך. למד כיצד לבדוק אם החיוב מופעל בפרויקט .
הפעל את ממשקי ה-API של Dataflow, Vertex AI ו-Notebooks. הפעל את ממשקי ה-API
מחברות Jupyter לפתרון זה
מחברות Jupyter הבאות מציגות את דוגמה ליישום:
- מחברת 1 מכסה עיבוד מקדים של נתונים. פרטים מסופקים בסעיף יישום צינור Apache Beam בהמשך.
- מחברת 2 מכסה הדרכת דגמים. פרטים מסופקים בסעיף יישום מודל TensorFlow בהמשך.
בסעיפים הבאים, אתה משכפל את המחברות הללו, ולאחר מכן אתה מפעיל את המחברות כדי ללמוד כיצד פועלת דוגמה היישום.
הפעל מופע מחברות בניהול משתמש
במסוף Google Cloud, עבור לדף Vertex AI Workbench .
בכרטיסייה מחברות מנוהלות על ידי משתמשים , לחץ על +מחברת חדשה .
בחר TensorFlow Enterprise 2.8 (עם LTS) ללא GPUs עבור סוג המופע.
לחץ על צור .
לאחר יצירת המחברת, המתן עד שה-proxy ל-JupyterLab יסיים את האתחול. כשהוא מוכן, Open JupyterLab מוצג ליד שם המחברת.
שכפל את המחברת
בכרטיסייה מחברות מנוהלות על ידי משתמש , ליד שם המחברת, לחץ על פתח את JupyterLab . ממשק JupyterLab נפתח בכרטיסייה חדשה.
אם JupyterLab מציג תיבת דו-שיח Build Recommended , לחץ על ביטול כדי לדחות את ה-Build המוצע.
בכרטיסייה מפעיל , לחץ על מסוף .
בחלון הטרמינל, שכבו את המחברת:
git clone https://github.com/GoogleCloudPlatform/training-data-analyst
יישם את צינור Apache Beam
סעיף זה והסעיף הבא הפעל את הצינור ב-Dataflow מספקים סקירה כללית והקשר עבור Notebook 1. המחברת מספקת דוגמה מעשית לתיאור כיצד להשתמש בספריית tf.Transform כדי לעבד נתונים מראש. דוגמה זו משתמשת במערך הנתונים Natality, המשמש לניבוי משקלים של תינוקות בהתבסס על תשומות שונות. הנתונים מאוחסנים בטבלת הלידה הציבורית ב-BigQuery.
הפעל את Notebook 1
בממשק JupyterLab, לחץ על קובץ > פתח מנתיב ולאחר מכן הזן את הנתיב הבא:
training-data-analyst/blogs/babyweight_tft/babyweight_tft_keras_01.ipynbלחץ על ערוך > נקה את כל הפלטים .
בקטע התקן חבילות נדרשות , הפעל את התא הראשון להפעלת הפקודה
pip install apache-beam.החלק האחרון של הפלט הוא הבא:
Successfully installed ...אתה יכול להתעלם משגיאות תלות בפלט. אינך צריך עדיין להפעיל מחדש את הקרנל.
בצע את התא השני כדי להפעיל את הפקודה
pip install tensorflow-transform. החלק האחרון של הפלט הוא הבא:Successfully installed ... Note: you may need to restart the kernel to use updated packages.אתה יכול להתעלם משגיאות תלות בפלט.
לחץ על ליבה > הפעל מחדש את ליבה .
בצע את התאים במקטעים אשר את החבילות המותקנות וצור setup.py כדי להתקין חבילות למכולות Dataflow .
בקטע הגדר דגלים גלובליים , לצד
PROJECTו-BUCKET, החלףyour-projectבמזהה פרויקט הענן שלך ולאחר מכן הפעל את התא.בצע את כל התאים הנותרים דרך התא האחרון במחברת. למידע על מה לעשות בכל תא, עיין בהוראות במחברת.
סקירה כללית של הצינור
בדוגמה של המחברת, Dataflow מפעיל את צינור tf.Transform בקנה מידה כדי להכין את הנתונים ולייצר את חפצי הטרנספורמציה. סעיפים מאוחרים יותר במסמך זה מתארים את הפונקציות המבצעות כל שלב בצנרת. השלבים הכוללים של הצינור הם כדלקמן:
- קרא נתוני הדרכה מ-BigQuery.
- ניתוח והמרת נתוני אימון באמצעות ספריית
tf.Transform. - כתוב נתוני אימון שהשתנו ל-Cloud Storage בפורמט TFRecord .
- קרא נתוני הערכה מ-BigQuery.
- הפוך נתוני הערכה באמצעות גרף
transform_fnשהופק בשלב 2. - כתוב נתוני אימון שהשתנו ל-Cloud Storage בפורמט TFRecord.
- כתוב חפצי טרנספורמציה ל-Cloud Storage שישמשו מאוחר יותר ליצירה וייצוא של המודל.
הדוגמה הבאה מציגה את קוד Python עבור הצינור הכולל. הסעיפים הבאים מספקים הסברים ורשימות קוד עבור כל שלב.
def run_transformation_pipeline(args):
pipeline_options = beam.pipeline.PipelineOptions(flags=[], **args)
runner = args['runner']
data_size = args['data_size']
transformed_data_location = args['transformed_data_location']
transform_artefact_location = args['transform_artefact_location']
temporary_dir = args['temporary_dir']
debug = args['debug']
# Instantiate the pipeline
with beam.Pipeline(runner, options=pipeline_options) as pipeline:
with impl.Context(temporary_dir):
# Preprocess train data
step = 'train'
# Read raw train data from BigQuery
raw_train_dataset = read_from_bq(pipeline, step, data_size)
# Analyze and transform raw_train_dataset
transformed_train_dataset, transform_fn = analyze_and_transform(raw_train_dataset, step)
# Write transformed train data to sink as tfrecords
write_tfrecords(transformed_train_dataset, transformed_data_location, step)
# Preprocess evaluation data
step = 'eval'
# Read raw eval data from BigQuery
raw_eval_dataset = read_from_bq(pipeline, step, data_size)
# Transform eval data based on produced transform_fn
transformed_eval_dataset = transform(raw_eval_dataset, transform_fn, step)
# Write transformed eval data to sink as tfrecords
write_tfrecords(transformed_eval_dataset, transformed_data_location, step)
# Write transformation artefacts
write_transform_artefacts(transform_fn, transform_artefact_location)
# (Optional) for debugging, write transformed data as text
step = 'debug'
# Write transformed train data as text if debug enabled
if debug == True:
write_text(transformed_train_dataset, transformed_data_location, step)
קרא נתוני אימון גולמיים מ-BigQuery
הצעד הראשון הוא לקרוא את נתוני ההדרכה הגולמיים מ-BigQuery באמצעות הפונקציה read_from_bq . פונקציה זו מחזירה אובייקט raw_dataset שחולץ מ-BigQuery. אתה מעביר ערך data_size ומעביר ערך step של train או eval . שאילתת המקור של BigQuery נבנית באמצעות הפונקציה get_source_query , כפי שמוצג בדוגמה הבאה:
def read_from_bq(pipeline, step, data_size):
source_query = get_source_query(step, data_size)
raw_data = (
pipeline
| '{} - Read Data from BigQuery'.format(step) >> beam.io.Read(
beam.io.BigQuerySource(query=source_query, use_standard_sql=True))
| '{} - Clean up Data'.format(step) >> beam.Map(prep_bq_row)
)
raw_metadata = create_raw_metadata()
raw_dataset = (raw_data, raw_metadata)
return raw_dataset
לפני שתבצע את העיבוד המקדים tf.Transform , ייתכן שיהיה עליך לבצע עיבוד טיפוסי מבוסס Apache Beam, כולל עיבוד מפה, מסנן, קבוצה וחלון. בדוגמה, הקוד מנקה את הרשומות הנקראות מ-BigQuery באמצעות שיטת beam.Map(prep_bq_row) , כאשר prep_bq_row היא פונקציה מותאמת אישית. פונקציה מותאמת אישית זו ממירה את הקוד המספרי עבור תכונה קטגורית לתוויות הניתנות לקריאה על ידי אדם.
בנוסף, כדי להשתמש בספריית tf.Transform כדי לנתח ולהמיר את האובייקט raw_data שחולץ מ-BigQuery, עליך ליצור אובייקט raw_dataset , שהוא שילוב של אובייקטי raw_data ו- raw_metadata . האובייקט raw_metadata נוצר באמצעות הפונקציה create_raw_metadata , באופן הבא:
CATEGORICAL_FEATURE_NAMES = ['is_male', 'mother_race']
NUMERIC_FEATURE_NAMES = ['mother_age', 'plurality', 'gestation_weeks']
TARGET_FEATURE_NAME = 'weight_pounds'
def create_raw_metadata():
feature_spec = dict(
[(name, tf.io.FixedLenFeature([], tf.string)) for name in CATEGORICAL_FEATURE_NAMES] +
[(name, tf.io.FixedLenFeature([], tf.float32)) for name in NUMERIC_FEATURE_NAMES] +
[(TARGET_FEATURE_NAME, tf.io.FixedLenFeature([], tf.float32))])
raw_metadata = dataset_metadata.DatasetMetadata(
schema_utils.schema_from_feature_spec(feature_spec))
return raw_metadata
כאשר אתה מפעיל את התא במחברת שעוקב מיד אחרי התא שמגדיר שיטה זו, התוכן של האובייקט raw_metadata.schema מוצג. הוא כולל את העמודות הבאות:
-
gestation_weeks(סוג:FLOAT) -
is_male(סוג:BYTES) -
mother_age(סוג:FLOAT) -
mother_race(סוג:BYTES) -
plurality(סוג:FLOAT) -
weight_pounds(סוג:FLOAT)
שינוי נתוני אימון גולמיים
תאר לעצמך שאתה רוצה להחיל טרנספורמציות טיפוסיות של עיבוד מקדים על תכונות הקלט הגולמיות של נתוני האימון כדי להכין אותם ל-ML. טרנספורמציות אלו כוללות הן פעולות במעבר מלא והן פעולות ברמת המופע, כפי שמוצג בטבלה הבאה:
| תכונת קלט | טרנספורמציה | צריך סטטיסטיקות | סוּג | תכונת פלט |
|---|---|---|---|---|
weight_pound | אַף לֹא אֶחָד | אַף לֹא אֶחָד | NA | weight_pound |
mother_age | נרמל | מתכוון, var | מעבר מלא | mother_age_normalized |
mother_age | דליית בגודל שווה | quantiles | מעבר מלא | mother_age_bucketized |
mother_age | מחשב את היומן | אַף לֹא אֶחָד | ברמת המופע | mother_age_log |
plurality | ציין אם מדובר בתינוקות בודדים או מרובים | אַף לֹא אֶחָד | ברמת המופע | is_multiple |
is_multiple | המרת ערכים נומינליים לאינדקס מספרי | ווקאב | מעבר מלא | is_multiple_index |
gestation_weeks | קנה מידה בין 0 ל-1 | דקה, מקסימום | מעבר מלא | gestation_weeks_scaled |
mother_race | המרת ערכים נומינליים לאינדקס מספרי | ווקאב | מעבר מלא | mother_race_index |
is_male | המרת ערכים נומינליים לאינדקס מספרי | ווקאב | מעבר מלא | is_male_index |
טרנספורמציות אלו מיושמות בפונקציה preprocess_fn , אשר מצפה למילון של טנזורים ( input_features ) ומחזירה מילון של תכונות מעובדות ( output_features ).
הקוד הבא מציג את היישום של הפונקציה preprocess_fn , באמצעות פעולות ה-API של טרנספורמציה מלאה tf.Transform (עם קידומת tft. ), ו- TensorFlow (עם קידומת tf. ) ברמת המופעים:
def preprocess_fn(input_features):
output_features = {}
# target feature
output_features['weight_pounds'] = input_features['weight_pounds']
# normalization
output_features['mother_age_normalized'] = tft.scale_to_z_score(input_features['mother_age'])
# scaling
output_features['gestation_weeks_scaled'] = tft.scale_to_0_1(input_features['gestation_weeks'])
# bucketization based on quantiles
output_features['mother_age_bucketized'] = tft.bucketize(input_features['mother_age'], num_buckets=5)
# you can compute new features based on custom formulas
output_features['mother_age_log'] = tf.math.log(input_features['mother_age'])
# or create flags/indicators
is_multiple = tf.as_string(input_features['plurality'] > tf.constant(1.0))
# convert categorical features to indexed vocab
output_features['mother_race_index'] = tft.compute_and_apply_vocabulary(input_features['mother_race'], vocab_filename='mother_race')
output_features['is_male_index'] = tft.compute_and_apply_vocabulary(input_features['is_male'], vocab_filename='is_male')
output_features['is_multiple_index'] = tft.compute_and_apply_vocabulary(is_multiple, vocab_filename='is_multiple')
return output_features
למסגרת tf.Transform יש כמה טרנספורמציות נוספות בנוסף לאלו שבדוגמה הקודמת, כולל אלו המפורטות בטבלה הבאה:
| טרנספורמציה | חל על | תֵאוּר |
|---|---|---|
scale_by_min_max | תכונות מספריות | שינוי קנה מידה של עמודה מספרית לטווח [ output_min , output_max ] |
scale_to_0_1 | תכונות מספריות | מחזירה עמודה שהיא עמודת הקלט שהותאמה לטווח [ 0 , 1 ] |
scale_to_z_score | תכונות מספריות | מחזירה עמודה סטנדרטית עם ממוצע 0 ושונות 1 |
tfidf | תכונות טקסט | ממפה את המונחים ב- x לתדירות המונחים שלהם * תדירות מסמך הפוכה |
compute_and_apply_vocabulary | תכונות קטגוריות | מייצר אוצר מילים עבור תכונה קטגורית וממפה אותו למספר שלם עם אוצר זה |
ngrams | תכונות טקסט | יוצר SparseTensor של n-גרם |
hash_strings | תכונות קטגוריות | גיבוב מחרוזות לדליים |
pca | תכונות מספריות | מחשב PCA על מערך הנתונים באמצעות שיתופיות מוטה |
bucketize | תכונות מספריות | מחזירה עמודה בגודל שווה (מבוסס על כמות), עם אינדקס דלי שהוקצה לכל קלט |
על מנת להחיל את הטרנספורמציות שהוטמעו בפונקציה preprocess_fn על אובייקט raw_train_dataset שהופק בשלב הקודם של הצינור, אתה משתמש בשיטת AnalyzeAndTransformDataset . שיטה זו מצפה לאובייקט raw_dataset כקלט, מיישמת את הפונקציה preprocess_fn , והיא מייצרת את האובייקט transformed_dataset ואת הגרף transform_fn . הקוד הבא ממחיש את העיבוד הזה:
def analyze_and_transform(raw_dataset, step):
transformed_dataset, transform_fn = (
raw_dataset
| '{} - Analyze & Transform'.format(step) >> tft_beam.AnalyzeAndTransformDataset(
preprocess_fn, output_record_batches=True)
)
return transformed_dataset, transform_fn
הטרנספורמציות מיושמות על הנתונים הגולמיים בשני שלבים: שלב הניתוח ושלב הטרנספורמציה. איור 3 בהמשך מסמך זה מראה כיצד שיטת AnalyzeAndTransformDataset מפורקת לשיטת AnalyzeDataset ולשיטת TransformDataset .
שלב הניתוח
בשלב הניתוח, נתוני האימון הגולמיים מנותחים בתהליך מלא כדי לחשב את הנתונים הסטטיסטיים הדרושים לשינויים. זה כולל חישוב הממוצע, השונות, המינימום, המקסימום, הקוונטילים ואוצר המילים. תהליך הניתוח מצפה למערך נתונים גולמי (נתונים גולמיים בתוספת מטא נתונים גולמיים), והוא מייצר שני פלטים:
-
transform_fn: גרף TensorFlow המכיל את הנתונים הסטטיסטיים המחושבים משלב הניתוח ואת לוגיקית הטרנספורמציה (המשתמשת בסטטיסטיקה) כפעולות ברמת המופע. כפי שנדון בהמשך ב- Save the graph , הגרףtransform_fnנשמר לצירוף לפונקציית המודלserving_fn. זה מאפשר להחיל את אותה טרנספורמציה על נקודות נתוני החיזוי המקוונות. -
transform_metadata: אובייקט המתאר את הסכימה הצפויה של הנתונים לאחר השינוי.
שלב הניתוח מודגם בתרשים הבא, איור 1:

tf.Transform . מנתחי tf.Transform כוללים min , max , sum , size , mean , var , covariance , quantiles , vocabulary ו- pca .
שלב הטרנספורמציה
בשלב הטרנספורמציה, גרף ה- transform_fn המופק משלב הניתוח משמש כדי להפוך את נתוני האימון הגולמיים בתהליך ברמת המופע על מנת להפיק את נתוני האימון שעברו טרנספורמציה. נתוני האימון שעברו טרנספורמציה מוצמדים למטא-נתונים שעברו טרנספורמציה (המיוצרים על ידי שלב הניתוח) כדי לייצר את מערך הנתונים transformed_train_dataset .
שלב ההמרה מודגם בתרשים הבא, איור 2:

tf.Transform . כדי לעבד מראש את התכונות, אתה קורא לטרנספורמציות tensorflow_transform הנדרשות (מיובאות כ- tft בקוד) ביישום שלך של הפונקציה preprocess_fn . לדוגמה, כאשר אתה קורא לפעולות tft.scale_to_z_score , ספריית tf.Transform מתרגמת את קריאת הפונקציה הזו למנתחי ממוצע ושונות, מחשבת את הנתונים הסטטיסטיים בשלב הניתוח, ולאחר מכן מיישמת את הנתונים הסטטיסטיים הללו כדי לנרמל את התכונה המספרית בשלב ההמרה. כל זה נעשה באופן אוטומטי על ידי קריאה לשיטת AnalyzeAndTransformDataset(preprocess_fn) .
הישות transformed_metadata.schema שנוצרה על ידי קריאה זו כוללת את העמודות הבאות:
-
gestation_weeks_scaled(סוג:FLOAT) -
is_male_index(סוג:INT, is_categorical:True) -
is_multiple_index(סוג:INT, is_categorical:True) -
mother_age_bucketized(סוג:INT, is_categorical:True) -
mother_age_log(סוג:FLOAT) -
mother_age_normalized(סוג:FLOAT) -
mother_race_index(סוג:INT, is_categorical:True) -
weight_pounds(סוג:FLOAT)
כפי שהוסבר בפעולות עיבוד מקדים בחלק הראשון של סדרה זו, טרנספורמציה של תכונה ממירה תכונות קטגוריות לייצוג מספרי. לאחר השינוי, התכונות הקטגוריות מיוצגות על ידי ערכי מספר שלמים. בישות transformed_metadata.schema , הדגל is_categorical עבור עמודות מסוג INT מציין אם העמודה מייצגת תכונה קטגורית או תכונה מספרית אמיתית.
כתוב נתוני אימון שעברו שינוי
לאחר שנתוני האימון מעובדים מראש עם הפונקציה preprocess_fn דרך שלבי הניתוח והטרנספורמציה, ניתן לכתוב את הנתונים ל-Sink שישמש לאימון מודל TensorFlow. כאשר אתה מבצע את צינור Apache Beam באמצעות Dataflow, ה-Sink הוא Cloud Storage. אחרת, הכיור הוא הדיסק המקומי. למרות שאתה יכול לכתוב את הנתונים כקובץ CSV של קבצים בפורמט ברוחב קבוע, פורמט הקובץ המומלץ עבור מערכי נתונים של TensorFlow הוא פורמט TFRecord. זהו פורמט בינארי פשוט מכוון רשומות המורכב מהודעות מאגר פרוטוקול tf.train.Example .
כל רשומת tf.train.Example מכילה תכונה אחת או יותר. אלה מומרים לטנזורים כאשר הם מוזנים לדגם לצורך אימון. הקוד הבא כותב את מערך הנתונים שעבר טרנספורמציה לקבצי TFRecord במיקום שצוין:
def write_tfrecords(transformed_dataset, location, step):
from tfx_bsl.coders import example_coder
transformed_data, transformed_metadata = transformed_dataset
(
transformed_data
| '{} - Encode Transformed Data'.format(step) >> beam.FlatMapTuple(
lambda batch, _: example_coder.RecordBatchToExamples(batch))
| '{} - Write Transformed Data'.format(step) >> beam.io.WriteToTFRecord(
file_path_prefix=os.path.join(location,'{}'.format(step)),
file_name_suffix='.tfrecords')
)
קרא, הפוך וכתוב נתוני הערכה
לאחר שתהפוך את נתוני האימון והפקת את גרף transform_fn , תוכל להשתמש בו כדי לשנות את נתוני ההערכה. ראשית, אתה קורא ומנקה את נתוני ההערכה מ-BigQuery באמצעות הפונקציה read_from_bq שתוארה קודם לכן ב- Cread נתוני אימון גולמיים מ-BigQuery , והעברת ערך של eval עבור פרמטר step . לאחר מכן, אתה משתמש בקוד הבא כדי להפוך את מערך הנתונים של ההערכה הגולמית ( raw_dataset ) לפורמט הצפוי שעבר טרנספורמציה ( transformed_dataset ):
def transform(raw_dataset, transform_fn, step):
transformed_dataset = (
(raw_dataset, transform_fn)
| '{} - Transform'.format(step) >> tft_beam.TransformDataset(output_record_batches=True)
)
return transformed_dataset
כאשר אתה ממיר את נתוני ההערכה, חלות רק פעולות ברמת המופע, תוך שימוש הן בלוגיקה בגרף transform_fn והן בסטטיסטיקה המחושבת משלב הניתוח בנתוני האימון. במילים אחרות, אינך מנתח את נתוני ההערכה באופן מלא כדי לחשב נתונים סטטיסטיים חדשים, כמו הממוצע והשונות לנורמליזציה של ציון z של תכונות מספריות בנתוני הערכה. במקום זאת, אתה משתמש בסטטיסטיקה המחושבת מנתוני האימון כדי לשנות את נתוני ההערכה בצורה ברמת המופע.
לכן, אתה משתמש בשיטת AnalyzeAndTransform בהקשר של נתוני אימון כדי לחשב את הנתונים הסטטיסטיים ולהמיר את הנתונים. במקביל, אתה משתמש בשיטת TransformDataset בהקשר של שינוי נתוני הערכה כדי להפוך את הנתונים רק באמצעות הנתונים הסטטיסטיים המחושבים על נתוני האימון.
לאחר מכן אתה כותב את הנתונים ל-Sink (Cloud Storage או דיסק מקומי, תלוי ברץ) בפורמט TFRecord להערכת מודל TensorFlow במהלך תהליך האימון. כדי לעשות זאת, אתה משתמש בפונקציה write_tfrecords הנדונה בכתוב נתוני אימון שעברו טרנספורמציה . התרשים הבא, איור 3, מראה כיצד גרף transform_fn המופק בשלב הניתוח של נתוני האימון משמש כדי להפוך את נתוני ההערכה.

transform_fn .שמור את הגרף
שלב אחרון בצינור העיבוד המקדים tf.Transform הוא אחסון החפצים, הכוללים את גרף transform_fn שמופק בשלב הניתוח בנתוני האימון. הקוד לאחסון החפצים מוצג בפונקציית write_transform_artefacts הבאה:
def write_transform_artefacts(transform_fn, location):
(
transform_fn
| 'Write Transform Artifacts' >> transform_fn_io.WriteTransformFn(location)
)
חפצים אלה ישמשו מאוחר יותר להכשרת מודלים וייצוא להגשה. גם החפצים הבאים מיוצרים, כפי שמוצג בסעיף הבא:
-
saved_model.pb: מייצג את גרף TensorFlow הכולל את לוגיקת הטרנספורמציה (גרףtransform_fn), אשר יש לצרף לממשק הגשת המודל כדי להפוך את נקודות הנתונים הגולמיות לפורמט שעבר טרנספורמציה. -
variables: כולל את הנתונים הסטטיסטיים שחושבו במהלך שלב הניתוח של נתוני האימון, ומשמש בלוגיקת הטרנספורמציה ב-saved_model.pbartifact. -
assets: כולל קבצי אוצר מילים, אחד עבור כל תכונה קטגורית המעובדת בשיטתcompute_and_apply_vocabulary, לשימוש במהלך ההגשה כדי להמיר ערך נומינלי גולמי של קלט לאינדקס מספרי. -
transformed_metadata: ספרייה המכילה את הקובץschema.jsonשמתאר את הסכימה של הנתונים שעברו טרנספורמציה.
הפעל את הצינור ב-Dataflow
לאחר שתגדיר את צינור tf.Transform , תפעיל את הצינור באמצעות Dataflow. התרשים הבא, איור 4, מציג את גרף ביצוע Dataflow של צינור tf.Transform המתואר בדוגמה.
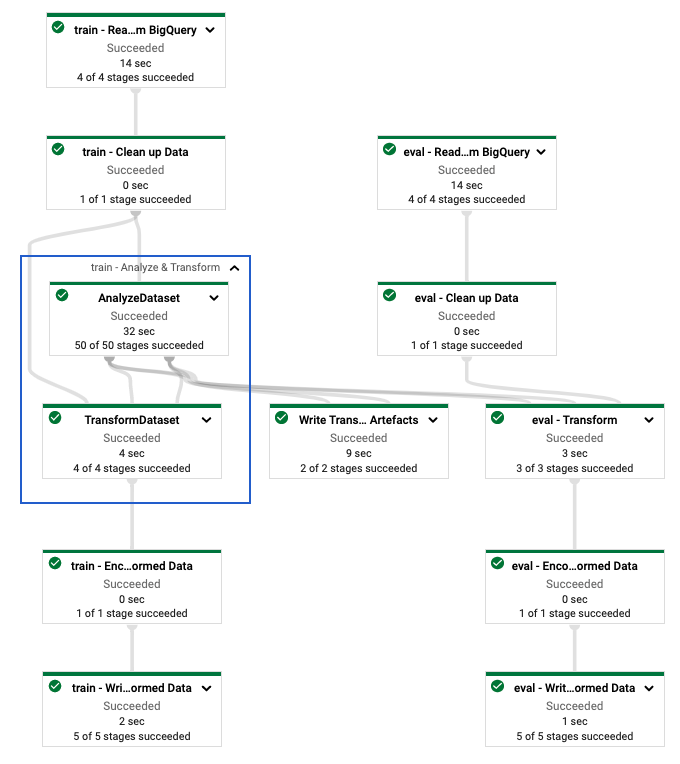
tf.Transform . לאחר שתבצע את צינור ה-Dataflow לעיבוד מקדים של נתוני ההדרכה וההערכה, תוכל לחקור את האובייקטים שנוצרו ב-Cloud Storage על ידי הפעלת התא האחרון במחברת. קטעי הקוד בקטע זה מציגים את התוצאות, כאשר YOUR_BUCKET_NAME הוא השם של דלי ה-Cloud Storage שלך.
נתוני האימון וההערכה שעברו שינוי בפורמט TFRecord מאוחסנים במיקום הבא:
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed
חפצי הטרנספורמציה מיוצרים במיקום הבא:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform
הרשימה הבאה היא הפלט של הצינור, המציגה את אובייקטי הנתונים והחפצים שנוצרו:
transformed data:
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/eval-00000-of-00001.tfrecords
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/train-00000-of-00002.tfrecords
gs://YOUR_BUCKET_NAME/babyweight_tft/transformed/train-00001-of-00002.tfrecords
transformed metadata:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/asset_map
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transformed_metadata/schema.pbtxt
transform artefact:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/saved_model.pb
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/variables/
transform assets:
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/is_male
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/is_multiple
gs://YOUR_BUCKET_NAME/babyweight_tft/transform/transform_fn/assets/mother_race
הטמעת מודל TensorFlow
חלק זה והחלק הבא, אימון והשתמש במודל לחיזויים , מספקים סקירה כללית והקשר עבור מחברת 2. המחברת מספקת מודל ML לדוגמה לניבוי משקלי תינוק. בדוגמה זו, מודל TensorFlow מיושם באמצעות ה-API של Keras. המודל משתמש בנתונים ובחפצים המיוצרים על ידי צינור העיבוד המקדים tf.Transform שהוסבר קודם לכן.
הפעל את Notebook 2
בממשק JupyterLab, לחץ על קובץ > פתח מנתיב ולאחר מכן הזן את הנתיב הבא:
training-data-analyst/blogs/babyweight_tft/babyweight_tft_keras_02.ipynbלחץ על ערוך > נקה את כל הפלטים .
בקטע התקן חבילות נדרשות , הפעל את התא הראשון להפעלת הפקודה
pip install tensorflow-transform.החלק האחרון של הפלט הוא הבא:
Successfully installed ... Note: you may need to restart the kernel to use updated packages.אתה יכול להתעלם משגיאות תלות בפלט.
בתפריט Kernel , בחר הפעל מחדש את ליבה .
בצע את התאים במקטעים אשר את החבילות המותקנות וצור setup.py כדי להתקין חבילות למכולות Dataflow .
במקטע הגדר דגלים גלובליים , ליד
PROJECTו-BUCKET, החלףyour-projectבמזהה פרויקט הענן שלך ולאחר מכן הפעל את התא.בצע את כל התאים הנותרים דרך התא האחרון במחברת. למידע על מה לעשות בכל תא, עיין בהוראות במחברת.
סקירה כללית של יצירת המודל
השלבים ליצירת המודל הם כדלקמן:
- צור עמודות תכונה באמצעות מידע הסכימה המאוחסן בספריית
transformed_metadata. - צור את המודל הרחב והעמוק עם ה-API של Keras באמצעות עמודות התכונות כקלט למודל.
- צור את הפונקציה
tfrecords_input_fnכדי לקרוא ולנתח את נתוני האימון וההערכה באמצעות חפצי הטרנספורמציה. - אימון והערכת המודל.
- ייצא את המודל המאומן על ידי הגדרת פונקציית
serving_fnשמצורפת אליה גרףtransform_fn. - בדוק את המודל המיוצא באמצעות הכלי
saved_model_cli. - השתמש במודל המיוצא לחיזוי.
מסמך זה אינו מסביר כיצד לבנות את המודל, ולכן הוא אינו דן בפירוט כיצד המודל נבנה או הוכשר. עם זאת, הסעיפים הבאים מראים כיצד המידע המאוחסן בספריית transform_metadata - אשר מיוצר על ידי תהליך tf.Transform - משמש ליצירת עמודות התכונות של המודל. המסמך גם מראה כיצד גרף transform_fn — שגם הוא מיוצר על ידי תהליך tf.Transform — משמש בפונקציה serving_fn כאשר המודל מיוצא להגשה.
השתמש בחפצי הטרנספורמציה שנוצרו באימון מודלים
כאשר אתה מאמן את מודל TensorFlow, אתה משתמש train שעברה טרנספורמציה ובאובייקטים eval שהופקו בשלב עיבוד הנתונים הקודם. אובייקטים אלה מאוחסנים כקבצים מרוסקים בפורמט TFRecord. מידע הסכימה בספריית transformed_metadata שנוצר בשלב הקודם יכול להיות שימושי בניתוח הנתונים (אובייקטים tf.train.Example ) כדי להזין את המודל לצורך אימון והערכה.
נתח את הנתונים
מכיוון שאתה קורא קבצים בפורמט TFRecord כדי להזין את המודל בנתוני אימון והערכה, עליך לנתח כל אובייקט tf.train.Example בקבצים כדי ליצור מילון של תכונות (טנסורים). זה מבטיח שהתכונות ממופות לשכבת הקלט של המודל באמצעות עמודות התכונות, המשמשות כממשק הדרכה והערכה של המודל. כדי לנתח את הנתונים, אתה משתמש באובייקט TFTransformOutput שנוצר מהחפצים שנוצרו בשלב הקודם:
צור אובייקט
TFTransformOutputמהחפצים שנוצרים ונשמרים בשלב העיבוד המקדים הקודם, כמתואר בסעיף שמור את הגרף :tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)חלץ אובייקט
feature_specמהאובייקטTFTransformOutput:tf_transform_output.transformed_feature_spec()השתמש באובייקט
feature_specכדי לציין את התכונות הכלולות באובייקטtf.train.Exampleכמו בפונקציהtfrecords_input_fn:def tfrecords_input_fn(files_name_pattern, batch_size=512): tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR) TARGET_FEATURE_NAME = 'weight_pounds' batched_dataset = tf.data.experimental.make_batched_features_dataset( file_pattern=files_name_pattern, batch_size=batch_size, features=tf_transform_output.transformed_feature_spec(), reader=tf.data.TFRecordDataset, label_key=TARGET_FEATURE_NAME, shuffle=True).prefetch(tf.data.experimental.AUTOTUNE) return batched_dataset
צור את עמודות התכונה
הצינור מייצר את מידע הסכימה בספריית transformed_metadata המתארת את הסכימה של הנתונים שעברו טרנספורמציה שצפויה על ידי המודל להדרכה והערכה. הסכימה מכילה את שם התכונה וסוג הנתונים, כגון:
-
gestation_weeks_scaled(סוג:FLOAT) -
is_male_index(סוג:INT, is_categorical:True) -
is_multiple_index(סוג:INT, is_categorical:True) -
mother_age_bucketized(סוג:INT, is_categorical:True) -
mother_age_log(סוג:FLOAT) -
mother_age_normalized(סוג:FLOAT) -
mother_race_index(סוג:INT, is_categorical:True) -
weight_pounds(סוג:FLOAT)
כדי לראות מידע זה, השתמש בפקודות הבאות:
transformed_metadata = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR).transformed_metadata
transformed_metadata.schema
הקוד הבא מראה כיצד אתה משתמש בשם התכונה ליצירת עמודות תכונה:
def create_wide_and_deep_feature_columns():
deep_feature_columns = []
wide_feature_columns = []
inputs = {}
categorical_columns = {}
# Select features you've checked from the metadata
# Categorical features are associated with the vocabulary size (starting from 0)
numeric_features = ['mother_age_log', 'mother_age_normalized', 'gestation_weeks_scaled']
categorical_features = [('is_male_index', 1), ('is_multiple_index', 1),
('mother_age_bucketized', 4), ('mother_race_index', 10)]
for feature in numeric_features:
deep_feature_columns.append(tf.feature_column.numeric_column(feature))
inputs[feature] = layers.Input(shape=(), name=feature, dtype='float32')
for feature, vocab_size in categorical_features:
categorical_columns[feature] = (
tf.feature_column.categorical_column_with_identity(feature, num_buckets=vocab_size+1))
wide_feature_columns.append(tf.feature_column.indicator_column(categorical_columns[feature]))
inputs[feature] = layers.Input(shape=(), name=feature, dtype='int64')
mother_race_X_mother_age_bucketized = tf.feature_column.crossed_column(
[categorical_columns['mother_age_bucketized'],
categorical_columns['mother_race_index']], 55)
wide_feature_columns.append(tf.feature_column.indicator_column(mother_race_X_mother_age_bucketized))
mother_race_X_mother_age_bucketized_embedded = tf.feature_column.embedding_column(
mother_race_X_mother_age_bucketized, 5)
deep_feature_columns.append(mother_race_X_mother_age_bucketized_embedded)
return wide_feature_columns, deep_feature_columns, inputs
הקוד יוצר עמודת tf.feature_column.numeric_column עבור תכונות מספריות, ועמודת tf.feature_column.categorical_column_with_identity עבור תכונות קטגוריות.
ניתן גם ליצור עמודות תכונות מורחבות, כמתואר באפשרות C: TensorFlow בחלק הראשון של סדרה זו. בדוגמה המשמשת לסדרה זו, נוצרת תכונה חדשה, mother_race_X_mother_age_bucketized , על ידי חציית התכונות mother_race ו- mother_age_bucketized באמצעות עמודת התכונה tf.feature_column.crossed_column . ייצוג צפוף בממד נמוך של תכונה מוצלבת זו נוצר באמצעות עמודת התכונה tf.feature_column.embedding_column .
הדיאגרמה הבאה, איור 5, מציגה את הנתונים שעברו טרנספורמציה וכיצד משתמשים במטא נתונים שעברו שינוי כדי להגדיר ולאמן את מודל TensorFlow:

ייצא את המודל לחיזוי הגשה
לאחר שתאמן את מודל TensorFlow עם ה-API של Keras, אתה מייצא את המודל המאומן כאובייקט SavedModel, כך שהוא יוכל לשרת נקודות נתונים חדשות לחיזוי. כאשר אתה מייצא את המודל, עליך להגדיר את הממשק שלו - כלומר, סכימת תכונות הקלט שצפויה במהלך ההגשה. סכימת תכונות קלט זו מוגדרת בפונקציה serving_fn , כפי שמוצג בקוד הבא:
def export_serving_model(model, output_dir):
tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)
# The layer has to be saved to the model for Keras tracking purposes.
model.tft_layer = tf_transform_output.transform_features_layer()
@tf.function
def serveing_fn(uid, is_male, mother_race, mother_age, plurality, gestation_weeks):
features = {
'is_male': is_male,
'mother_race': mother_race,
'mother_age': mother_age,
'plurality': plurality,
'gestation_weeks': gestation_weeks
}
transformed_features = model.tft_layer(features)
outputs = model(transformed_features)
# The prediction results have multiple elements in general.
# But we need only the first element in our case.
outputs = tf.map_fn(lambda item: item[0], outputs)
return {'uid': uid, 'weight': outputs}
concrete_serving_fn = serveing_fn.get_concrete_function(
tf.TensorSpec(shape=[None], dtype=tf.string, name='uid'),
tf.TensorSpec(shape=[None], dtype=tf.string, name='is_male'),
tf.TensorSpec(shape=[None], dtype=tf.string, name='mother_race'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='mother_age'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='plurality'),
tf.TensorSpec(shape=[None], dtype=tf.float32, name='gestation_weeks')
)
signatures = {'serving_default': concrete_serving_fn}
model.save(output_dir, save_format='tf', signatures=signatures)
במהלך ההגשה, המודל מצפה לנקודות הנתונים בצורתן הגולמית (כלומר, תכונות גולמיות לפני טרנספורמציות). לכן, הפונקציה serving_fn מקבלת את התכונות הגולמיות ומאחסנת אותן באובייקט features כמילון Python. עם זאת, כפי שצוין קודם לכן, המודל המאומן מצפה לנקודות הנתונים בסכימה שעברה טרנספורמציה. כדי להמיר את התכונות הגולמיות לאובייקטים transformed_features הצפויים על ידי ממשק המודל, אתה מחיל את גרף transform_fn השמור על אובייקט features עם השלבים הבאים:
צור את האובייקט
TFTransformOutputמהחפצים שנוצרו ונשמרו בשלב העיבוד המקדים הקודם:tf_transform_output = tft.TFTransformOutput(TRANSFORM_ARTEFACTS_DIR)צור אובייקט
TransformFeaturesLayerמאובייקטTFTransformOutput:model.tft_layer = tf_transform_output.transform_features_layer()החל את גרף
transform_fnבאמצעות האובייקטTransformFeaturesLayer:transformed_features = model.tft_layer(features)
התרשים הבא, איור 6, ממחיש את השלב האחרון של ייצוא מודל להגשה:

transform_fn מצורף. אימון והשתמש במודל לתחזיות
אתה יכול לאמן את המודל באופן מקומי על ידי הפעלת התאים של המחברת. לדוגמאות כיצד לארוז את הקוד ולאמן את המודל שלך בקנה מידה באמצעות Vertex AI Training, עיין בדוגמאות ובמדריכים במאגר GitHub Cloudml-samples של Google Cloud.
כאשר אתה בודק את האובייקט SavedModel המיוצא באמצעות הכלי saved_model_cli , אתה רואה שרכיבי inputs של הגדרת החתימה signature_def כוללים את התכונות הגולמיות, כפי שמוצג בדוגמה הבאה:
signature_def['serving_default']:
The given SavedModel SignatureDef contains the following input(s):
inputs['gestation_weeks'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_gestation_weeks:0
inputs['is_male'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_is_male:0
inputs['mother_age'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_mother_age:0
inputs['mother_race'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_mother_race:0
inputs['plurality'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_plurality:0
inputs['uid'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_uid:0
The given SavedModel SignatureDef contains the following output(s):
outputs['uid'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: StatefulPartitionedCall_6:0
outputs['weight'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: StatefulPartitionedCall_6:1
Method name is: tensorflow/serving/predict
התאים הנותרים של המחברת מראים לך כיצד להשתמש במודל המיוצא עבור חיזוי מקומי, וכיצד לפרוס את המודל כשירות מיקרו באמצעות חיזוי Vertex AI. חשוב להדגיש שנקודת הקלט (הדגימה) נמצאת בסכימה הגולמית בשני המקרים.
לנקות
כדי להימנע מחיובים נוספים בחשבון Google Cloud שלך עבור המשאבים המשמשים במדריך זה, מחק את הפרויקט שמכיל את המשאבים.
מחק את הפרויקט
במסוף Google Cloud, עבור לדף נהל משאבים .
ברשימת הפרויקטים, בחר את הפרויקט שברצונך למחוק ולאחר מכן לחץ על מחק .
בתיבת הדו-שיח, הקלד את מזהה הפרויקט ולאחר מכן לחץ על כיבוי כדי למחוק את הפרויקט.
מה הלאה
- כדי ללמוד על המושגים, האתגרים והאפשרויות של עיבוד מקדים של נתונים עבור למידת מכונה ב-Google Cloud, עיין במאמר הראשון בסדרה זו, עיבוד מקדים של נתונים עבור ML: אפשרויות והמלצות .
- למידע נוסף על איך ליישם, לארוז ולהפעיל צינור tf.Transform ב-Dataflow, עיין בדוגמה של חיזוי הכנסה עם ערכת נתונים של Census .
- קח את ההתמחות של Coursera ב-ML עם TensorFlow ב-Google Cloud .
- למד על שיטות עבודה מומלצות להנדסת ML ב- Rules of ML .
- לעיון נוסף בארכיטקטורות, דיאגרמות ושיטות עבודה מומלצות, חקור את מרכז ארכיטקטורת הענן .