
| | |  Ver fonte no GitHub Ver fonte no GitHub | |
Este tutorial demonstra como pré-processar arquivos de áudio no formato WAV e construir e treinar um modelo básico de reconhecimento automático de fala (ASR) para reconhecer dez palavras diferentes. Você usará uma parte do conjunto de dados Comandos de fala ( Warden, 2018 ), que contém clipes de áudio curtos (um segundo ou menos) de comandos, como "para baixo", "ir", "esquerda", "não", " direita", "parar", "para cima" e "sim".
Os sistemas de reconhecimento de voz e áudio do mundo real são complexos. Mas, assim como a classificação de imagens com o conjunto de dados MNIST , este tutorial deve fornecer uma compreensão básica das técnicas envolvidas.
Configurar
Importe os módulos e dependências necessários. Observe que você usará o seaborn para visualização neste tutorial.
import os
import pathlib
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import models
from IPython import display
# Set the seed value for experiment reproducibility.
seed = 42
tf.random.set_seed(seed)
np.random.seed(seed)
Importar o conjunto de dados mini Speech Commands
Para economizar tempo com o carregamento de dados, você trabalhará com uma versão menor do conjunto de dados de Comandos de Fala. O conjunto de dados original consiste em mais de 105.000 arquivos de áudio no formato de arquivo de áudio WAV (Waveform) de pessoas dizendo 35 palavras diferentes. Esses dados foram coletados pelo Google e liberados sob uma licença CC BY.
Baixe e extraia o arquivo mini_speech_commands.zip contendo os conjuntos de dados menores de Comandos de Fala com tf.keras.utils.get_file :
DATASET_PATH = 'data/mini_speech_commands'
data_dir = pathlib.Path(DATASET_PATH)
if not data_dir.exists():
tf.keras.utils.get_file(
'mini_speech_commands.zip',
origin="http://storage.googleapis.com/download.tensorflow.org/data/mini_speech_commands.zip",
extract=True,
cache_dir='.', cache_subdir='data')
Downloading data from http://storage.googleapis.com/download.tensorflow.org/data/mini_speech_commands.zip 182083584/182082353 [==============================] - 1s 0us/step 182091776/182082353 [==============================] - 1s 0us/step
Os clipes de áudio do conjunto de dados são armazenados em oito pastas correspondentes a cada comando de fala: no , yes , down , go , left , up , right e stop :
commands = np.array(tf.io.gfile.listdir(str(data_dir)))
commands = commands[commands != 'README.md']
print('Commands:', commands)
Commands: ['stop' 'left' 'no' 'go' 'yes' 'down' 'right' 'up']
Extraia os clipes de áudio em uma lista chamada filenames e embaralhe-a:
filenames = tf.io.gfile.glob(str(data_dir) + '/*/*')
filenames = tf.random.shuffle(filenames)
num_samples = len(filenames)
print('Number of total examples:', num_samples)
print('Number of examples per label:',
len(tf.io.gfile.listdir(str(data_dir/commands[0]))))
print('Example file tensor:', filenames[0])
Number of total examples: 8000 Number of examples per label: 1000 Example file tensor: tf.Tensor(b'data/mini_speech_commands/yes/db72a474_nohash_0.wav', shape=(), dtype=string)
Divida os nomes dos filenames em conjuntos de treinamento, validação e teste usando uma proporção de 80:10:10, respectivamente:
train_files = filenames[:6400]
val_files = filenames[6400: 6400 + 800]
test_files = filenames[-800:]
print('Training set size', len(train_files))
print('Validation set size', len(val_files))
print('Test set size', len(test_files))
Training set size 6400 Validation set size 800 Test set size 800
Leia os arquivos de áudio e seus rótulos
Nesta seção você irá pré-processar o conjunto de dados, criando tensores decodificados para as formas de onda e os rótulos correspondentes. Observe que:
- Cada arquivo WAV contém dados de séries temporais com um número definido de amostras por segundo.
- Cada amostra representa a amplitude do sinal de áudio naquele momento específico.
- Em um sistema de 16 bits , como os arquivos WAV no conjunto de dados mini Speech Commands, os valores de amplitude variam de -32.768 a 32.767.
- A taxa de amostragem para este conjunto de dados é de 16kHz.
A forma do tensor retornado por tf.audio.decode_wav é [samples, channels] , onde channels é 1 para mono ou 2 para estéreo. O conjunto de dados mini Speech Commands contém apenas gravações mono.
test_file = tf.io.read_file(DATASET_PATH+'/down/0a9f9af7_nohash_0.wav')
test_audio, _ = tf.audio.decode_wav(contents=test_file)
test_audio.shape
TensorShape([13654, 1])
Agora, vamos definir uma função que pré-processa os arquivos de áudio WAV brutos do conjunto de dados em tensores de áudio:
def decode_audio(audio_binary):
# Decode WAV-encoded audio files to `float32` tensors, normalized
# to the [-1.0, 1.0] range. Return `float32` audio and a sample rate.
audio, _ = tf.audio.decode_wav(contents=audio_binary)
# Since all the data is single channel (mono), drop the `channels`
# axis from the array.
return tf.squeeze(audio, axis=-1)
Defina uma função que cria rótulos usando os diretórios pai para cada arquivo:
- Divida os caminhos de arquivo em
tf.RaggedTensors (tensores com dimensões irregulares — com fatias que podem ter comprimentos diferentes).
def get_label(file_path):
parts = tf.strings.split(
input=file_path,
sep=os.path.sep)
# Note: You'll use indexing here instead of tuple unpacking to enable this
# to work in a TensorFlow graph.
return parts[-2]
Defina outra função auxiliar— get_waveform_and_label —que junte tudo:
- A entrada é o nome do arquivo de áudio WAV.
- A saída é uma tupla contendo os tensores de áudio e rótulo prontos para aprendizado supervisionado.
def get_waveform_and_label(file_path):
label = get_label(file_path)
audio_binary = tf.io.read_file(file_path)
waveform = decode_audio(audio_binary)
return waveform, label
Crie o conjunto de treinamento para extrair os pares de rótulo de áudio:
- Crie um
tf.data.DatasetcomDataset.from_tensor_sliceseDataset.map, usandoget_waveform_and_labeldefinido anteriormente.
Você construirá os conjuntos de validação e teste usando um procedimento semelhante posteriormente.
AUTOTUNE = tf.data.AUTOTUNE
files_ds = tf.data.Dataset.from_tensor_slices(train_files)
waveform_ds = files_ds.map(
map_func=get_waveform_and_label,
num_parallel_calls=AUTOTUNE)
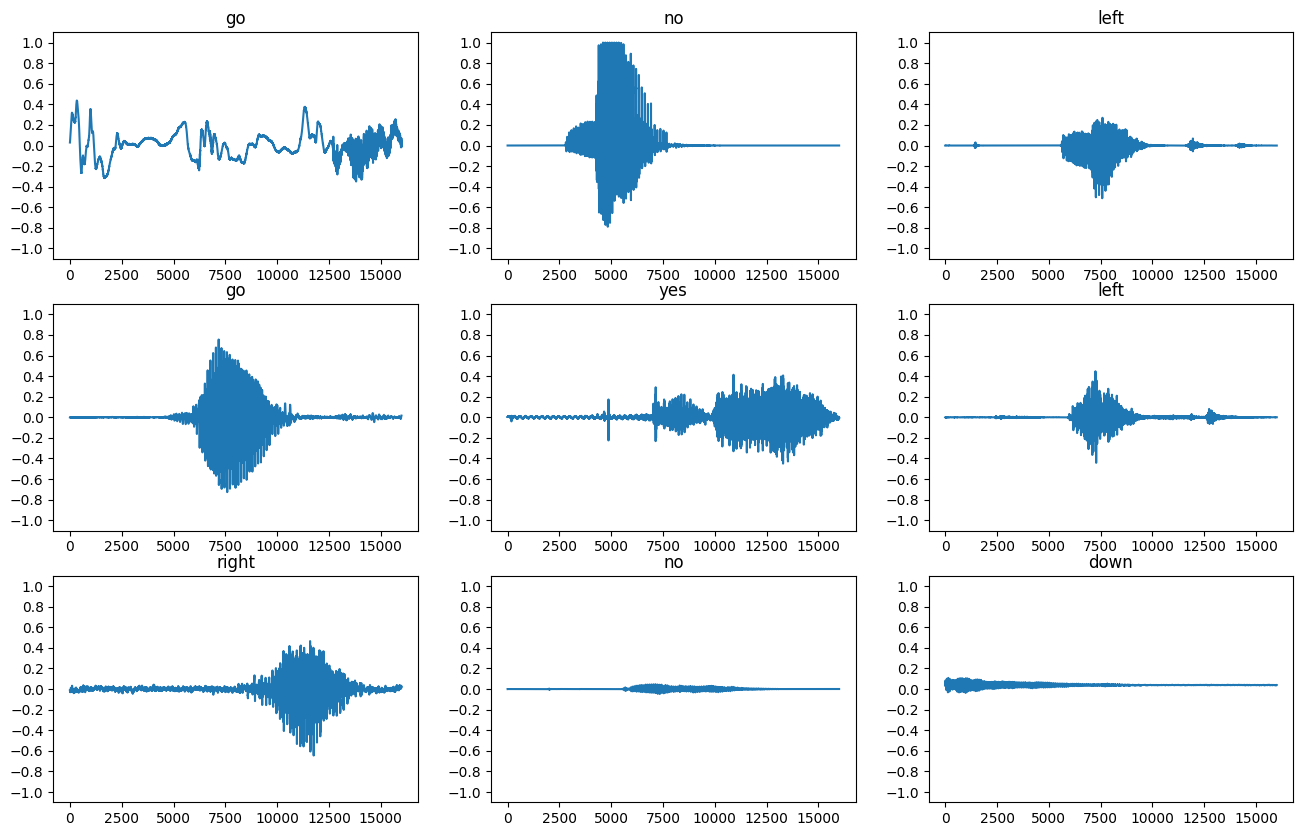
Vamos traçar algumas formas de onda de áudio:
rows = 3
cols = 3
n = rows * cols
fig, axes = plt.subplots(rows, cols, figsize=(10, 12))
for i, (audio, label) in enumerate(waveform_ds.take(n)):
r = i // cols
c = i % cols
ax = axes[r][c]
ax.plot(audio.numpy())
ax.set_yticks(np.arange(-1.2, 1.2, 0.2))
label = label.numpy().decode('utf-8')
ax.set_title(label)
plt.show()
Converter formas de onda em espectrogramas
As formas de onda no conjunto de dados são representadas no domínio do tempo. Em seguida, você transformará as formas de onda dos sinais no domínio do tempo em sinais no domínio da frequência do tempo calculando a transformada de Fourier de curta duração (STFT) para converter as formas de onda em espectrogramas , que mostram mudanças de frequência ao longo do tempo e podem ser representados como imagens 2D. Você alimentará as imagens do espectrograma em sua rede neural para treinar o modelo.
Uma transformada de Fourier ( tf.signal.fft ) converte um sinal para suas frequências componentes, mas perde todas as informações de tempo. Em comparação, STFT ( tf.signal.stft ) divide o sinal em janelas de tempo e executa uma transformada de Fourier em cada janela, preservando algumas informações de tempo e retornando um tensor 2D no qual você pode executar convoluções padrão.
Crie uma função utilitária para converter formas de onda em espectrogramas:
- As formas de onda precisam ter o mesmo comprimento, para que, ao convertê-las em espectrogramas, os resultados tenham dimensões semelhantes. Isso pode ser feito simplesmente zerando os clipes de áudio com menos de um segundo (usando
tf.zeros). - Ao chamar
tf.signal.stft, escolha os parâmetrosframe_lengtheframe_stepde forma que a "imagem" do espectrograma gerado seja quase quadrada. Para obter mais informações sobre a escolha dos parâmetros STFT, consulte este vídeo do Coursera sobre processamento de sinal de áudio e STFT. - A STFT produz uma matriz de números complexos representando magnitude e fase. No entanto, neste tutorial você usará apenas a magnitude, que pode ser derivada aplicando
tf.absna saída detf.signal.stft.
def get_spectrogram(waveform):
# Zero-padding for an audio waveform with less than 16,000 samples.
input_len = 16000
waveform = waveform[:input_len]
zero_padding = tf.zeros(
[16000] - tf.shape(waveform),
dtype=tf.float32)
# Cast the waveform tensors' dtype to float32.
waveform = tf.cast(waveform, dtype=tf.float32)
# Concatenate the waveform with `zero_padding`, which ensures all audio
# clips are of the same length.
equal_length = tf.concat([waveform, zero_padding], 0)
# Convert the waveform to a spectrogram via a STFT.
spectrogram = tf.signal.stft(
equal_length, frame_length=255, frame_step=128)
# Obtain the magnitude of the STFT.
spectrogram = tf.abs(spectrogram)
# Add a `channels` dimension, so that the spectrogram can be used
# as image-like input data with convolution layers (which expect
# shape (`batch_size`, `height`, `width`, `channels`).
spectrogram = spectrogram[..., tf.newaxis]
return spectrogram
Em seguida, comece a explorar os dados. Imprima as formas da forma de onda tensorizada de um exemplo e o espectrograma correspondente e reproduza o áudio original:
for waveform, label in waveform_ds.take(1):
label = label.numpy().decode('utf-8')
spectrogram = get_spectrogram(waveform)
print('Label:', label)
print('Waveform shape:', waveform.shape)
print('Spectrogram shape:', spectrogram.shape)
print('Audio playback')
display.display(display.Audio(waveform, rate=16000))
Label: yes Waveform shape: (16000,) Spectrogram shape: (124, 129, 1) Audio playback
Agora, defina uma função para exibir um espectrograma:
def plot_spectrogram(spectrogram, ax):
if len(spectrogram.shape) > 2:
assert len(spectrogram.shape) == 3
spectrogram = np.squeeze(spectrogram, axis=-1)
# Convert the frequencies to log scale and transpose, so that the time is
# represented on the x-axis (columns).
# Add an epsilon to avoid taking a log of zero.
log_spec = np.log(spectrogram.T + np.finfo(float).eps)
height = log_spec.shape[0]
width = log_spec.shape[1]
X = np.linspace(0, np.size(spectrogram), num=width, dtype=int)
Y = range(height)
ax.pcolormesh(X, Y, log_spec)
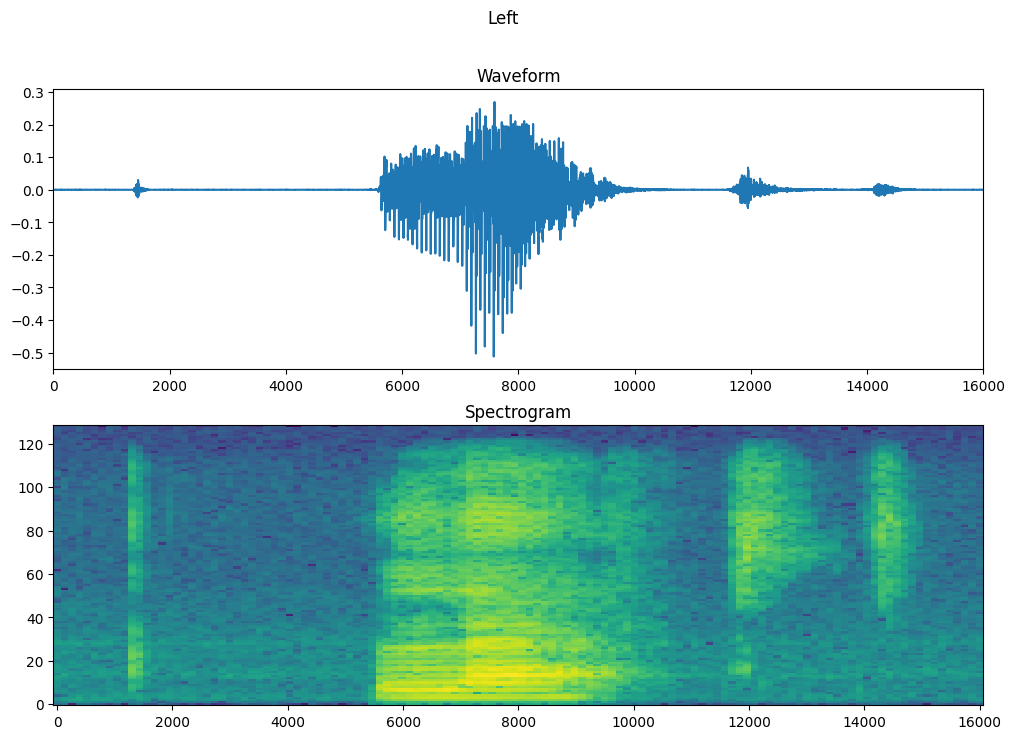
Plote a forma de onda do exemplo ao longo do tempo e o espectrograma correspondente (frequências ao longo do tempo):
fig, axes = plt.subplots(2, figsize=(12, 8))
timescale = np.arange(waveform.shape[0])
axes[0].plot(timescale, waveform.numpy())
axes[0].set_title('Waveform')
axes[0].set_xlim([0, 16000])
plot_spectrogram(spectrogram.numpy(), axes[1])
axes[1].set_title('Spectrogram')
plt.show()
Agora, defina uma função que transforma o conjunto de dados da forma de onda em espectrogramas e seus rótulos correspondentes como IDs inteiros:
def get_spectrogram_and_label_id(audio, label):
spectrogram = get_spectrogram(audio)
label_id = tf.argmax(label == commands)
return spectrogram, label_id
Mapeie get_spectrogram_and_label_id entre os elementos do conjunto de dados com Dataset.map :
spectrogram_ds = waveform_ds.map(
map_func=get_spectrogram_and_label_id,
num_parallel_calls=AUTOTUNE)
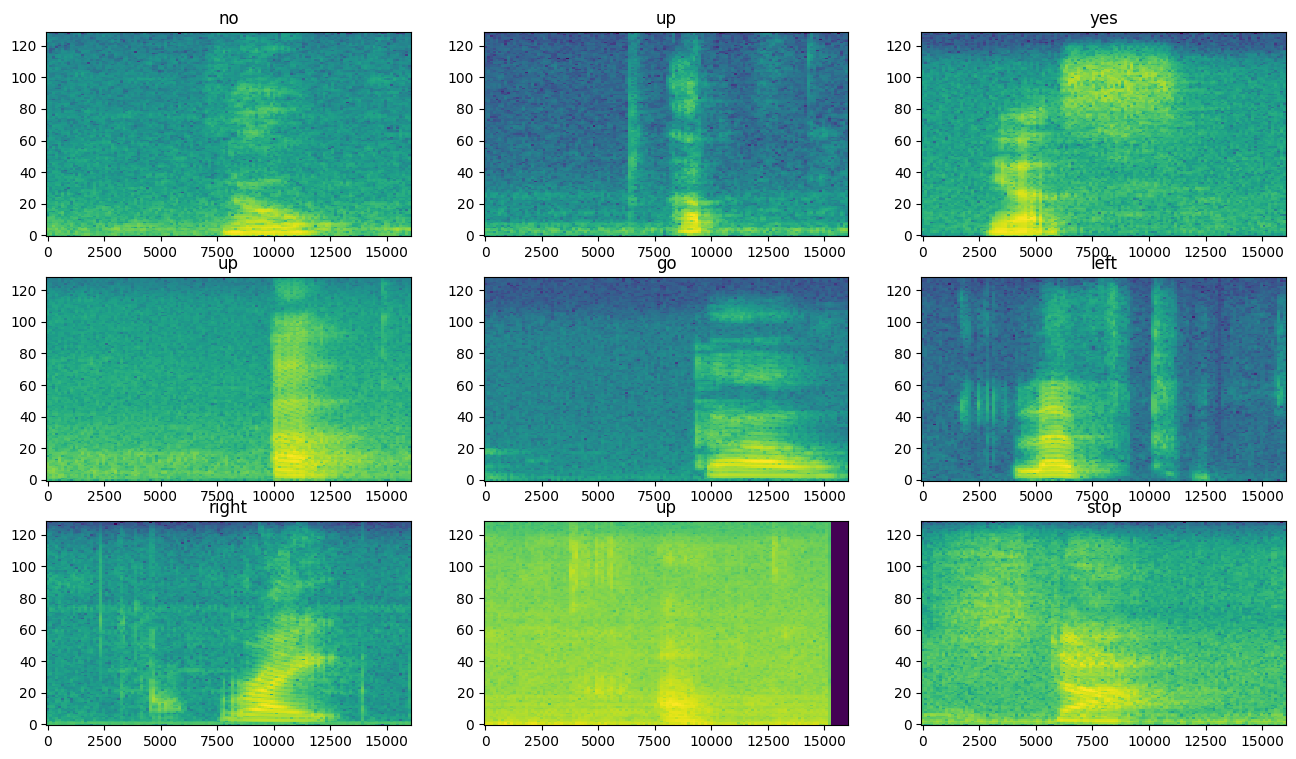
Examine os espectrogramas para diferentes exemplos do conjunto de dados:
rows = 3
cols = 3
n = rows*cols
fig, axes = plt.subplots(rows, cols, figsize=(10, 10))
for i, (spectrogram, label_id) in enumerate(spectrogram_ds.take(n)):
r = i // cols
c = i % cols
ax = axes[r][c]
plot_spectrogram(spectrogram.numpy(), ax)
ax.set_title(commands[label_id.numpy()])
ax.axis('off')
plt.show()
Construir e treinar o modelo
Repita o pré-processamento do conjunto de treinamento nos conjuntos de validação e teste:
def preprocess_dataset(files):
files_ds = tf.data.Dataset.from_tensor_slices(files)
output_ds = files_ds.map(
map_func=get_waveform_and_label,
num_parallel_calls=AUTOTUNE)
output_ds = output_ds.map(
map_func=get_spectrogram_and_label_id,
num_parallel_calls=AUTOTUNE)
return output_ds
train_ds = spectrogram_ds
val_ds = preprocess_dataset(val_files)
test_ds = preprocess_dataset(test_files)
Agrupe os conjuntos de treinamento e validação para treinamento de modelo:
batch_size = 64
train_ds = train_ds.batch(batch_size)
val_ds = val_ds.batch(batch_size)
Adicione as operações Dataset.cache e Dataset.prefetch para reduzir a latência de leitura durante o treinamento do modelo:
train_ds = train_ds.cache().prefetch(AUTOTUNE)
val_ds = val_ds.cache().prefetch(AUTOTUNE)
Para o modelo, você usará uma rede neural convolucional simples (CNN), pois transformou os arquivos de áudio em imagens de espectrograma.
Seu modelo tf.keras.Sequential usará as seguintes camadas de pré-processamento Keras:
-
tf.keras.layers.Resizing: para reduzir a amostra da entrada para permitir que o modelo treine mais rápido. -
tf.keras.layers.Normalization: para normalizar cada pixel da imagem com base em sua média e desvio padrão.
Para a camada de Normalization , seu método de adapt precisaria primeiro ser chamado nos dados de treinamento para calcular estatísticas agregadas (ou seja, a média e o desvio padrão).
for spectrogram, _ in spectrogram_ds.take(1):
input_shape = spectrogram.shape
print('Input shape:', input_shape)
num_labels = len(commands)
# Instantiate the `tf.keras.layers.Normalization` layer.
norm_layer = layers.Normalization()
# Fit the state of the layer to the spectrograms
# with `Normalization.adapt`.
norm_layer.adapt(data=spectrogram_ds.map(map_func=lambda spec, label: spec))
model = models.Sequential([
layers.Input(shape=input_shape),
# Downsample the input.
layers.Resizing(32, 32),
# Normalize.
norm_layer,
layers.Conv2D(32, 3, activation='relu'),
layers.Conv2D(64, 3, activation='relu'),
layers.MaxPooling2D(),
layers.Dropout(0.25),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dropout(0.5),
layers.Dense(num_labels),
])
model.summary()
Input shape: (124, 129, 1)
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
resizing (Resizing) (None, 32, 32, 1) 0
normalization (Normalizatio (None, 32, 32, 1) 3
n)
conv2d (Conv2D) (None, 30, 30, 32) 320
conv2d_1 (Conv2D) (None, 28, 28, 64) 18496
max_pooling2d (MaxPooling2D (None, 14, 14, 64) 0
)
dropout (Dropout) (None, 14, 14, 64) 0
flatten (Flatten) (None, 12544) 0
dense (Dense) (None, 128) 1605760
dropout_1 (Dropout) (None, 128) 0
dense_1 (Dense) (None, 8) 1032
=================================================================
Total params: 1,625,611
Trainable params: 1,625,608
Non-trainable params: 3
_________________________________________________________________
Configure o modelo Keras com o otimizador Adam e a perda de entropia cruzada:
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'],
)
Treine o modelo em 10 épocas para fins de demonstração:
EPOCHS = 10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=EPOCHS,
callbacks=tf.keras.callbacks.EarlyStopping(verbose=1, patience=2),
)
Epoch 1/10 100/100 [==============================] - 6s 41ms/step - loss: 1.7503 - accuracy: 0.3630 - val_loss: 1.2850 - val_accuracy: 0.5763 Epoch 2/10 100/100 [==============================] - 0s 5ms/step - loss: 1.2101 - accuracy: 0.5698 - val_loss: 0.9314 - val_accuracy: 0.6913 Epoch 3/10 100/100 [==============================] - 0s 5ms/step - loss: 0.9336 - accuracy: 0.6703 - val_loss: 0.7529 - val_accuracy: 0.7325 Epoch 4/10 100/100 [==============================] - 0s 5ms/step - loss: 0.7503 - accuracy: 0.7397 - val_loss: 0.6721 - val_accuracy: 0.7713 Epoch 5/10 100/100 [==============================] - 0s 5ms/step - loss: 0.6367 - accuracy: 0.7741 - val_loss: 0.6061 - val_accuracy: 0.7975 Epoch 6/10 100/100 [==============================] - 0s 5ms/step - loss: 0.5650 - accuracy: 0.7987 - val_loss: 0.5489 - val_accuracy: 0.8125 Epoch 7/10 100/100 [==============================] - 0s 5ms/step - loss: 0.5099 - accuracy: 0.8183 - val_loss: 0.5344 - val_accuracy: 0.8238 Epoch 8/10 100/100 [==============================] - 0s 5ms/step - loss: 0.4560 - accuracy: 0.8392 - val_loss: 0.5194 - val_accuracy: 0.8288 Epoch 9/10 100/100 [==============================] - 0s 5ms/step - loss: 0.4101 - accuracy: 0.8547 - val_loss: 0.4809 - val_accuracy: 0.8388 Epoch 10/10 100/100 [==============================] - 0s 5ms/step - loss: 0.3905 - accuracy: 0.8589 - val_loss: 0.4973 - val_accuracy: 0.8363
Vamos plotar as curvas de perda de treinamento e validação para verificar como seu modelo melhorou durante o treinamento:
metrics = history.history
plt.plot(history.epoch, metrics['loss'], metrics['val_loss'])
plt.legend(['loss', 'val_loss'])
plt.show()

Avalie o desempenho do modelo
Execute o modelo no conjunto de teste e verifique o desempenho do modelo:
test_audio = []
test_labels = []
for audio, label in test_ds:
test_audio.append(audio.numpy())
test_labels.append(label.numpy())
test_audio = np.array(test_audio)
test_labels = np.array(test_labels)
y_pred = np.argmax(model.predict(test_audio), axis=1)
y_true = test_labels
test_acc = sum(y_pred == y_true) / len(y_true)
print(f'Test set accuracy: {test_acc:.0%}')
Test set accuracy: 85%
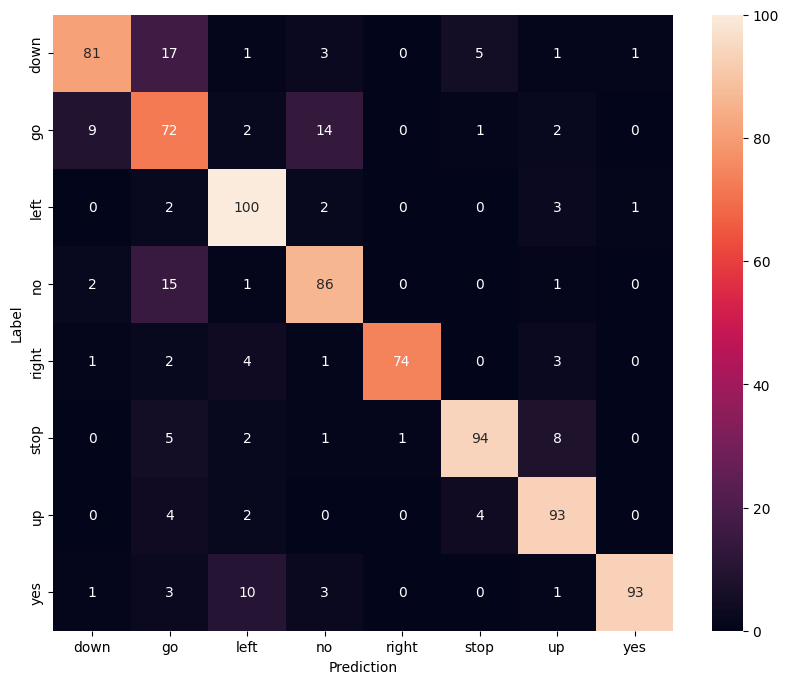
Exibir uma matriz de confusão
Use uma matriz de confusão para verificar quão bem o modelo classificou cada um dos comandos no conjunto de teste:
confusion_mtx = tf.math.confusion_matrix(y_true, y_pred)
plt.figure(figsize=(10, 8))
sns.heatmap(confusion_mtx,
xticklabels=commands,
yticklabels=commands,
annot=True, fmt='g')
plt.xlabel('Prediction')
plt.ylabel('Label')
plt.show()
Executar inferência em um arquivo de áudio
Por fim, verifique a saída de previsão do modelo usando um arquivo de áudio de entrada de alguém dizendo "não". Qual é o desempenho do seu modelo?
sample_file = data_dir/'no/01bb6a2a_nohash_0.wav'
sample_ds = preprocess_dataset([str(sample_file)])
for spectrogram, label in sample_ds.batch(1):
prediction = model(spectrogram)
plt.bar(commands, tf.nn.softmax(prediction[0]))
plt.title(f'Predictions for "{commands[label[0]]}"')
plt.show()
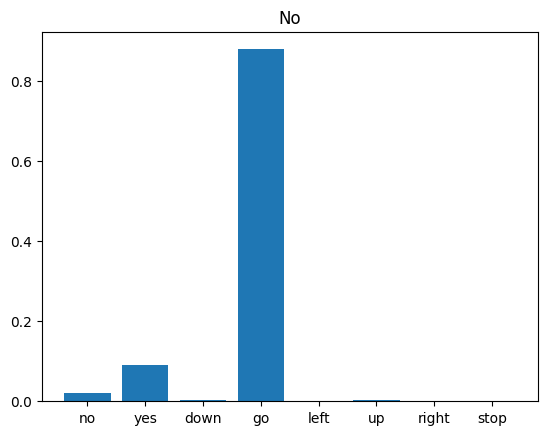
Como a saída sugere, seu modelo deve ter reconhecido o comando de áudio como "não".
Próximos passos
Este tutorial demonstrou como realizar classificação de áudio simples/reconhecimento automático de fala usando uma rede neural convolucional com TensorFlow e Python. Para saber mais, considere os seguintes recursos:
- O tutorial Classificação de som com YAMNet mostra como usar o aprendizado de transferência para classificação de áudio.
- Os notebooks do desafio de reconhecimento de fala TensorFlow da Kaggle .
- O TensorFlow.js - Reconhecimento de áudio usando codelab de aprendizado de transferência ensina como criar seu próprio aplicativo da Web interativo para classificação de áudio.
- Um tutorial sobre aprendizado profundo para recuperação de informações musicais (Choi et al., 2017) no arXiv.
- O TensorFlow também tem suporte adicional para preparação e aumento de dados de áudio para ajudar em seus próprios projetos baseados em áudio.
- Considere usar a biblioteca librosa —um pacote Python para análise de música e áudio.