
|
|
|
 View source on GitHub View source on GitHub
|
|
前のチュートリアルでは、機械学習の基本構成ブロックの1つである自動微分について TensorFlow の API を学習しました。 このチュートリアルでは、これまでのチュートリアルに出てきた TensorFlow の基本要素を使って、単純な機械学習を実行します。
TensorFlow には tf.keras が含まれています。tf.kerasは、抽象化により決まり切った記述を削減し、柔軟さと性能を犠牲にすることなく TensorFlow をやさしく使えるようにする、高度なニューラルネットワーク API です。開発には tf.Keras API を使うことを強くおすすめします。しかしながら、この短いチュートリアルでは、しっかりした基礎を身につけていただくために、ニューラルネットワークの訓練についていちから学ぶことにします。
設定
import tensorflow as tf
変数
TensorFlow のテンソルはイミュータブルでステートレスなオブジェクトです。しかしながら、機械学習モデルには変化する状態が必要です。モデルの訓練が進むにつれて、推論を行うおなじコードが異なる振る舞いをする必要があります(望むべくはより損失の少なくなるように)。この計算が進むにつれて変化する必要がある状態を表現するために、Python が状態を保つプログラミング言語であることを利用することができます。
# Python の状態を使う
x = tf.zeros([10, 10])
x += 2 # これは x = x + 2 と等価で, x の元の値を変えているわけではない
print(x)
tf.Tensor( [[2. 2. 2. 2. 2. 2. 2. 2. 2. 2.] [2. 2. 2. 2. 2. 2. 2. 2. 2. 2.] [2. 2. 2. 2. 2. 2. 2. 2. 2. 2.] [2. 2. 2. 2. 2. 2. 2. 2. 2. 2.] [2. 2. 2. 2. 2. 2. 2. 2. 2. 2.] [2. 2. 2. 2. 2. 2. 2. 2. 2. 2.] [2. 2. 2. 2. 2. 2. 2. 2. 2. 2.] [2. 2. 2. 2. 2. 2. 2. 2. 2. 2.] [2. 2. 2. 2. 2. 2. 2. 2. 2. 2.] [2. 2. 2. 2. 2. 2. 2. 2. 2. 2.]], shape=(10, 10), dtype=float32)
TensorFlow にはステートフルな演算が組み込まれているので、状態を表現するのに低レベルの Python による表現を使うよりは簡単なことがしばしばあります。
tf.Variableオブジェクトは値を保持し、何も指示しなくともこの保存された値を読み出します。TensorFlow の変数に保持された値を操作する演算(tf.assign_sub, tf.scatter_update, など)が用意されています。
v = tf.Variable(1.0)
# Python の `assert` を条件をテストするデバッグ文として使用
assert v.numpy() == 1.0
# `v` に値を再代入
v.assign(3.0)
assert v.numpy() == 3.0
# `v` に TensorFlow の `tf.square()` 演算を適用し再代入
v.assign(tf.square(v))
assert v.numpy() == 9.0
tf.Variableを使った計算は、勾配計算の際に自動的にトレースされます。埋め込みを表す変数では、TensorFlow は既定でスパースな更新を行います。これは計算量やメモリ使用量においてより効率的です。
tf.Variableはあなたのコードを読む人にその状態の一部がミュータブルであることを示す方法でもあります。
線形モデルの適合
これまでに学んだ Tensor、 Variable、 そして GradientTapeという概念を使って、簡単なモデルの構築と訓練を行ってみましょう。通常、これには次のようないくつかの手順が含まれます。
- モデルの定義
- 損失関数の定義
- 訓練データの取得
- 訓練データを使って実行し、"optimizer" を使って変数をデータに適合
ここでは、f(x) = x * W + bという簡単な線形モデルを作ります。このモデルには W (重み) と b (バイアス) の2つの変数があります。十分訓練されたモデルが W = 3.0 と b = 2.0 になるようなデータを人工的に作ります。
モデルの定義
変数と計算をカプセル化する単純なクラスを定義してみましょう。
class Model(object):
def __init__(self):
# 重みを `5.0` に、バイアスを `0.0` に初期化
# 実際には、これらの値は乱数で初期化するべき(例えば `tf.random.normal` を使って)
self.W = tf.Variable(5.0)
self.b = tf.Variable(0.0)
def __call__(self, x):
return self.W * x + self.b
model = Model()
assert model(3.0).numpy() == 15.0
損失関数の定義
損失関数は、ある入力値に対するモデルの出力がどれだけ出力の目的値に近いかを測るものです。訓練を通じて、この差異を最小化するのがゴールとなります。最小二乗誤差とも呼ばれる L2 損失を使ってみましょう。
def loss(predicted_y, target_y):
return tf.reduce_mean(tf.square(predicted_y - target_y))
訓練データの取得
最初に、入力にランダムなガウス(正規)分布のノイズを加えることで、訓練用データを生成します。
TRUE_W = 3.0
TRUE_b = 2.0
NUM_EXAMPLES = 1000
inputs = tf.random.normal(shape=[NUM_EXAMPLES])
noise = tf.random.normal(shape=[NUM_EXAMPLES])
outputs = inputs * TRUE_W + TRUE_b + noise
モデルを訓練する前に、モデルの予測値を赤で、訓練データを青でプロットすることで、損失を可視化します。
import matplotlib.pyplot as plt
plt.scatter(inputs, outputs, c='b')
plt.scatter(inputs, model(inputs), c='r')
plt.show()
print('Current loss: %1.6f' % loss(model(inputs), outputs).numpy())
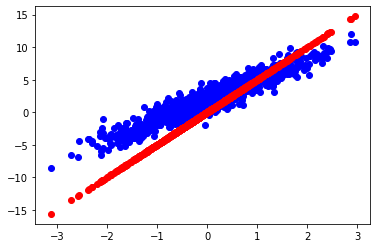
Current loss: 8.123021
訓練ループの定義
ネットワークと訓練データが準備できたところで、損失が少なくなるように、重み変数 (W) とバイアス変数 (b) を更新するために、gradient descent (勾配降下法) を使ってモデルを訓練します。勾配降下法にはさまざまな変種があり、我々の推奨する実装である tf.train.Optimizer にも含まれています。しかし、ここでは基本原理から構築するという精神で、自動微分を行う tf.GradientTape と、値を減少させる tf.assign_sub (これは、tf.assign と tf.sub の組み合わせですが)の力を借りて、この基本計算を実装してみましょう。
def train(model, inputs, outputs, learning_rate):
with tf.GradientTape() as t:
current_loss = loss(model(inputs), outputs)
dW, db = t.gradient(current_loss, [model.W, model.b])
model.W.assign_sub(learning_rate * dW)
model.b.assign_sub(learning_rate * db)
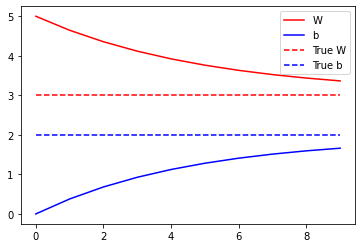
最後に、訓練データ全体に対して繰り返し実行し、W と b がどのように変化するかを見てみましょう。
model = Model()
# 後ほどプロットするために、W 値と b 値の履歴を集める
Ws, bs = [], []
epochs = range(10)
for epoch in epochs:
Ws.append(model.W.numpy())
bs.append(model.b.numpy())
current_loss = loss(model(inputs), outputs)
train(model, inputs, outputs, learning_rate=0.1)
print('Epoch %2d: W=%1.2f b=%1.2f, loss=%2.5f' %
(epoch, Ws[-1], bs[-1], current_loss))
# すべてをプロット
plt.plot(epochs, Ws, 'r',
epochs, bs, 'b')
plt.plot([TRUE_W] * len(epochs), 'r--',
[TRUE_b] * len(epochs), 'b--')
plt.legend(['W', 'b', 'True W', 'True b'])
plt.show()
Epoch 0: W=5.00 b=0.00, loss=8.12302 Epoch 1: W=4.65 b=0.38, loss=5.69242 Epoch 2: W=4.36 b=0.68, loss=4.09065 Epoch 3: W=4.12 b=0.93, loss=3.03475 Epoch 4: W=3.92 b=1.12, loss=2.33847 Epoch 5: W=3.76 b=1.28, loss=1.87918 Epoch 6: W=3.63 b=1.41, loss=1.57614 Epoch 7: W=3.52 b=1.51, loss=1.37612 Epoch 8: W=3.44 b=1.60, loss=1.24407 Epoch 9: W=3.36 b=1.66, loss=1.15686
次のステップ
このチュートリアルでは tf.Variable を使って単純な線形モデルの構築と訓練を行いました。
実際にニューラルネットワークを構築する際には、tf.keras のような高レベルな API のほうが遥かに便利です。tf.keras は、(「レイヤー」と呼ばれる)高レベルの部品、状態を保存・復元するためのユーティリティ、さまざまな損失関数、さまざまな最適化戦略などを提供しています。詳しく知るには TensorFlow Keras guide を参照してください。