
 GitHub でソースを表示 GitHub でソースを表示 |
このノートブックでは、「周期的構成の敵対的ネットワークを使った対となっていない画像から画像への変換」で説明されているように、条件付き GAN を使用して対になっていない画像から画像への変換を実演します。周期的構成の敵対的ネットワークは、CycleGAN としても知られています。この論文では、対になっているトレーニングサンプルを使用せずに、1 つの画像領域の特性をキャプチャして、それらの特性を別の画像領域にどのように変換できるのかを見つけ出す方法が提案されています。
このノートブックは、Pix2Pix の知識があることを前提としています。Pix2Pix については、Pix2Pix チュートリアルをご覧ください。CycleGAN のコードは類似していますが、主な違いは、追加の損失関数があり、対になっていないトレーニングデータを使用する点にあります。
CycleGAN では、周期的に一貫した損失を使用して、対になっているデータを必要とせずにトレーニングすることができます。言い換えると、ソースとターゲット領域で 1 対 1 のマッピングを行わずに、1 つの領域から別の領域に変換することができます。
この方法により、写真補正、カラー画像化、画風変換といった興味深い多様なタスクが可能となります。これらのタスクに必要となるのは、ソースとターゲットデータセット(単純な画像ディレクトリ)のみです。


入力パイプラインをセットアップする
ジェネレータとディスクリミネータのインポートを実行する tensorflow_examples パッケージをインストールします。
pip install git+https://github.com/tensorflow/examples.gitimport tensorflow as tf
2024-01-12 00:09:45.111080: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered 2024-01-12 00:09:45.111127: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered 2024-01-12 00:09:45.112808: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
import tensorflow_datasets as tfds
from tensorflow_examples.models.pix2pix import pix2pix
import os
import time
import matplotlib.pyplot as plt
from IPython.display import clear_output
AUTOTUNE = tf.data.AUTOTUNE
入力パイプライン
このチュートリアルでは、馬の画像からシマウマの画像に変換できるようにモデルをトレーニングします。このデータセットとこれに類似したほかのデータセットは、こちらにあります。
論文に記載されているように、トレーニングデータセットに、ランダムジッタリングとミラーリングを適用します。これらは、過学習を避ける画像認識精度向上テクニックです。
これは、pix2pix で行われていたものに似ています。
- ランダムジッタリングでは、画像サイズは
286 x 286に変換されてから、256 x 256にランダムにクロップされます。 - ランダムミラーリングでは、画像はランダムに水平方向(左から右)に反転されます。
dataset, metadata = tfds.load('cycle_gan/horse2zebra',
with_info=True, as_supervised=True)
train_horses, train_zebras = dataset['trainA'], dataset['trainB']
test_horses, test_zebras = dataset['testA'], dataset['testB']
BUFFER_SIZE = 1000
BATCH_SIZE = 1
IMG_WIDTH = 256
IMG_HEIGHT = 256
def random_crop(image):
cropped_image = tf.image.random_crop(
image, size=[IMG_HEIGHT, IMG_WIDTH, 3])
return cropped_image
# normalizing the images to [-1, 1]
def normalize(image):
image = tf.cast(image, tf.float32)
image = (image / 127.5) - 1
return image
def random_jitter(image):
# resizing to 286 x 286 x 3
image = tf.image.resize(image, [286, 286],
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
# randomly cropping to 256 x 256 x 3
image = random_crop(image)
# random mirroring
image = tf.image.random_flip_left_right(image)
return image
def preprocess_image_train(image, label):
image = random_jitter(image)
image = normalize(image)
return image
def preprocess_image_test(image, label):
image = normalize(image)
return image
train_horses = train_horses.cache().map(
preprocess_image_train, num_parallel_calls=AUTOTUNE).shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
train_zebras = train_zebras.cache().map(
preprocess_image_train, num_parallel_calls=AUTOTUNE).shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
test_horses = test_horses.map(
preprocess_image_test, num_parallel_calls=AUTOTUNE).cache().shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
test_zebras = test_zebras.map(
preprocess_image_test, num_parallel_calls=AUTOTUNE).cache().shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
sample_horse = next(iter(train_horses))
sample_zebra = next(iter(train_zebras))
2024-01-12 00:09:52.376722: W tensorflow/core/kernels/data/cache_dataset_ops.cc:858] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead. 2024-01-12 00:09:53.408850: W tensorflow/core/kernels/data/cache_dataset_ops.cc:858] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
plt.subplot(121)
plt.title('Horse')
plt.imshow(sample_horse[0] * 0.5 + 0.5)
plt.subplot(122)
plt.title('Horse with random jitter')
plt.imshow(random_jitter(sample_horse[0]) * 0.5 + 0.5)
<matplotlib.image.AxesImage at 0x7feb4c3b8670>
plt.subplot(121)
plt.title('Zebra')
plt.imshow(sample_zebra[0] * 0.5 + 0.5)
plt.subplot(122)
plt.title('Zebra with random jitter')
plt.imshow(random_jitter(sample_zebra[0]) * 0.5 + 0.5)
<matplotlib.image.AxesImage at 0x7feb303e3460>
Pix2Pix モデルをインポートしてサイズ変更する
インストールした tensorflow_examples を介して Pix2Pix で使用したジェネレータとディスクリミネータをインポートします。
このチュートリアルで使用されるモデルアーキテクチャは、pix2pix で使用されたものに非常によく似ていますが、以下のような違いがあります。
- Cyclegan は、バッチ正規化ではなくインスタンス正規化を使用します。
- CycleGAN の論文では、変更が適用された
resnetベースのジェネレータが使用されています。このチュートリアルでは、単純化するために、変更を適用したunetジェネレータを使用しています。
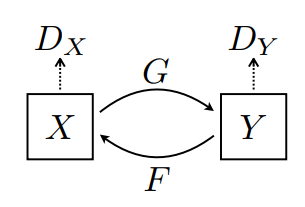
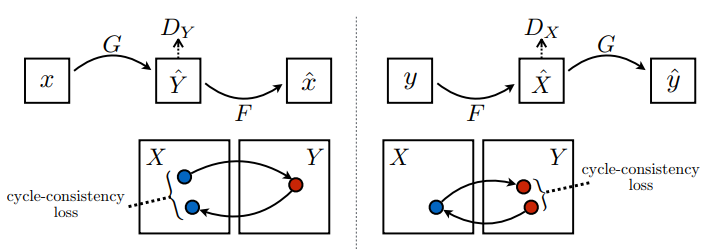
ここでトレーニングされるのは、以下のような 2 つのジェネレータ(G と F)と 2 つのディスクリミネータ(X と Y)です。
- ジェネレータ
Gは、画像Xを画像Yに変換する方法を学習します。\((G: X -> Y)\) - ジェネレータ
Fは、画像Yを画像Xに変換する方法を学習します。\((F: Y -> X)\) - ディスクリミネータ
D_Xは、画像Xと生成された画像X(F(Y))を区別する方法を学習します。 - ディスクリミネータ
D_Yは、画像Yと生成された画像Y(G(X))を区別する方法を学習します。
OUTPUT_CHANNELS = 3
generator_g = pix2pix.unet_generator(OUTPUT_CHANNELS, norm_type='instancenorm')
generator_f = pix2pix.unet_generator(OUTPUT_CHANNELS, norm_type='instancenorm')
discriminator_x = pix2pix.discriminator(norm_type='instancenorm', target=False)
discriminator_y = pix2pix.discriminator(norm_type='instancenorm', target=False)
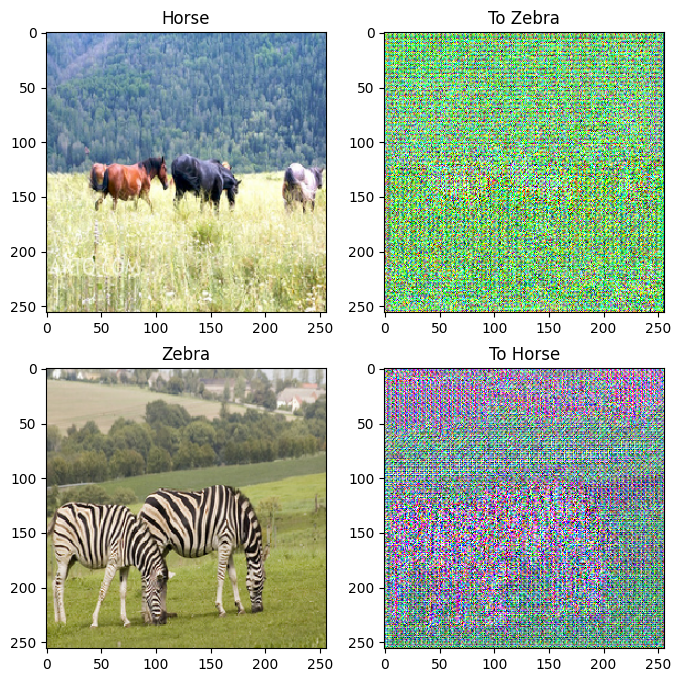
to_zebra = generator_g(sample_horse)
to_horse = generator_f(sample_zebra)
plt.figure(figsize=(8, 8))
contrast = 8
imgs = [sample_horse, to_zebra, sample_zebra, to_horse]
title = ['Horse', 'To Zebra', 'Zebra', 'To Horse']
for i in range(len(imgs)):
plt.subplot(2, 2, i+1)
plt.title(title[i])
if i % 2 == 0:
plt.imshow(imgs[i][0] * 0.5 + 0.5)
else:
plt.imshow(imgs[i][0] * 0.5 * contrast + 0.5)
plt.show()
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
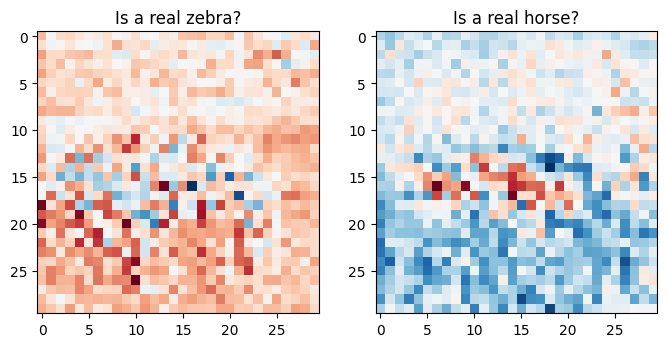
plt.figure(figsize=(8, 8))
plt.subplot(121)
plt.title('Is a real zebra?')
plt.imshow(discriminator_y(sample_zebra)[0, ..., -1], cmap='RdBu_r')
plt.subplot(122)
plt.title('Is a real horse?')
plt.imshow(discriminator_x(sample_horse)[0, ..., -1], cmap='RdBu_r')
plt.show()
損失関数
CycleGAN では、トレーニングできる、対になったデータが存在しないため、トレーニング中の入力 x とターゲット y のペアに意味がある保証はありません。したがって、ネットワークによる的確なマッピングを強化するために、論文の執筆者は 周期的に一貫性のある損失を提案しています。
ディスクリミネータ損失とジェネレータ損失は pix2pix で使用されているものに似ています。
LAMBDA = 10
loss_obj = tf.keras.losses.BinaryCrossentropy(from_logits=True)
def discriminator_loss(real, generated):
real_loss = loss_obj(tf.ones_like(real), real)
generated_loss = loss_obj(tf.zeros_like(generated), generated)
total_disc_loss = real_loss + generated_loss
return total_disc_loss * 0.5
def generator_loss(generated):
return loss_obj(tf.ones_like(generated), generated)
周期的一貫性とは、結果が元の入力に近いことを指します。たとえば、ある文を英語からフランス語に翻訳してから、フランス語から英語に戻す場合、結果として得られる文は元の文と同じになるということです。
周期的一貫性損失は、以下のように行われます。
- 画像 \(X\) はジェネレータ \(G\) を介して渡され、画像 \(\hat{Y}\) を生成します。
- 生成された画像 \(\hat{Y}\) はジェネレータ \(F\) を介して渡され、周期後の画像 \(\hat{X}\) を生成します。
- \(X\) と \(\hat{X}\) 間の平均絶対誤差が計算されます。
\[forward\ cycle\ consistency\ loss: X -> G(X) -> F(G(X)) \sim \hat{X}\]
\[backward\ cycle\ consistency\ loss: Y -> F(Y) -> G(F(Y)) \sim \hat{Y}\]
def calc_cycle_loss(real_image, cycled_image):
loss1 = tf.reduce_mean(tf.abs(real_image - cycled_image))
return LAMBDA * loss1
上記に示す通り、画像 \(X\) から画像 \(Y\) への変換は、ジェネレータ \(G\) が行います。 アイデンティティ損失は、画像 \(Y\) をジェネレータ \(G\) にフィードした場合、実際の \(Y\) または画像 \(Y\) に近い画像を生成すると記述できます。
馬に対してシマウマから馬モデルを実行するか、シマウマに対して馬からシマウマモデルを実行する場合、画像にはすでにターゲットクラスが含まれるため、画像はそれほど変更されません。
\[Identity\ loss = |G(Y) - Y| + |F(X) - X|\]
def identity_loss(real_image, same_image):
loss = tf.reduce_mean(tf.abs(real_image - same_image))
return LAMBDA * 0.5 * loss
すべてのジェネレータとディスクリミネータのオプティマイザを初期化します。
generator_g_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
generator_f_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_x_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_y_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
チェックポイント
checkpoint_path = "./checkpoints/train"
ckpt = tf.train.Checkpoint(generator_g=generator_g,
generator_f=generator_f,
discriminator_x=discriminator_x,
discriminator_y=discriminator_y,
generator_g_optimizer=generator_g_optimizer,
generator_f_optimizer=generator_f_optimizer,
discriminator_x_optimizer=discriminator_x_optimizer,
discriminator_y_optimizer=discriminator_y_optimizer)
ckpt_manager = tf.train.CheckpointManager(ckpt, checkpoint_path, max_to_keep=5)
# if a checkpoint exists, restore the latest checkpoint.
if ckpt_manager.latest_checkpoint:
ckpt.restore(ckpt_manager.latest_checkpoint)
print ('Latest checkpoint restored!!')
トレーニング
注意: このサンプルモデルは、このチュートリアルのトレーニング時間を合理的にするために、論文(200 回)よりも少ないエポック数(10)でトレーニングされています。生成された画像の品質は大幅に低下します。
EPOCHS = 10
def generate_images(model, test_input):
prediction = model(test_input)
plt.figure(figsize=(12, 12))
display_list = [test_input[0], prediction[0]]
title = ['Input Image', 'Predicted Image']
for i in range(2):
plt.subplot(1, 2, i+1)
plt.title(title[i])
# getting the pixel values between [0, 1] to plot it.
plt.imshow(display_list[i] * 0.5 + 0.5)
plt.axis('off')
plt.show()
トレーニングループは複雑に見えるかもしれませんが、以下の 4 つの基本ループで構成されています。
- 予測を取得する。
- 損失を計算する。
- バックプロパゲーションを使用して勾配を計算する。
- 勾配をオプティマイザに適用する。
@tf.function
def train_step(real_x, real_y):
# persistent is set to True because the tape is used more than
# once to calculate the gradients.
with tf.GradientTape(persistent=True) as tape:
# Generator G translates X -> Y
# Generator F translates Y -> X.
fake_y = generator_g(real_x, training=True)
cycled_x = generator_f(fake_y, training=True)
fake_x = generator_f(real_y, training=True)
cycled_y = generator_g(fake_x, training=True)
# same_x and same_y are used for identity loss.
same_x = generator_f(real_x, training=True)
same_y = generator_g(real_y, training=True)
disc_real_x = discriminator_x(real_x, training=True)
disc_real_y = discriminator_y(real_y, training=True)
disc_fake_x = discriminator_x(fake_x, training=True)
disc_fake_y = discriminator_y(fake_y, training=True)
# calculate the loss
gen_g_loss = generator_loss(disc_fake_y)
gen_f_loss = generator_loss(disc_fake_x)
total_cycle_loss = calc_cycle_loss(real_x, cycled_x) + calc_cycle_loss(real_y, cycled_y)
# Total generator loss = adversarial loss + cycle loss
total_gen_g_loss = gen_g_loss + total_cycle_loss + identity_loss(real_y, same_y)
total_gen_f_loss = gen_f_loss + total_cycle_loss + identity_loss(real_x, same_x)
disc_x_loss = discriminator_loss(disc_real_x, disc_fake_x)
disc_y_loss = discriminator_loss(disc_real_y, disc_fake_y)
# Calculate the gradients for generator and discriminator
generator_g_gradients = tape.gradient(total_gen_g_loss,
generator_g.trainable_variables)
generator_f_gradients = tape.gradient(total_gen_f_loss,
generator_f.trainable_variables)
discriminator_x_gradients = tape.gradient(disc_x_loss,
discriminator_x.trainable_variables)
discriminator_y_gradients = tape.gradient(disc_y_loss,
discriminator_y.trainable_variables)
# Apply the gradients to the optimizer
generator_g_optimizer.apply_gradients(zip(generator_g_gradients,
generator_g.trainable_variables))
generator_f_optimizer.apply_gradients(zip(generator_f_gradients,
generator_f.trainable_variables))
discriminator_x_optimizer.apply_gradients(zip(discriminator_x_gradients,
discriminator_x.trainable_variables))
discriminator_y_optimizer.apply_gradients(zip(discriminator_y_gradients,
discriminator_y.trainable_variables))
for epoch in range(EPOCHS):
start = time.time()
n = 0
for image_x, image_y in tf.data.Dataset.zip((train_horses, train_zebras)):
train_step(image_x, image_y)
if n % 10 == 0:
print ('.', end='')
n += 1
clear_output(wait=True)
# Using a consistent image (sample_horse) so that the progress of the model
# is clearly visible.
generate_images(generator_g, sample_horse)
if (epoch + 1) % 5 == 0:
ckpt_save_path = ckpt_manager.save()
print ('Saving checkpoint for epoch {} at {}'.format(epoch+1,
ckpt_save_path))
print ('Time taken for epoch {} is {} sec\n'.format(epoch + 1,
time.time()-start))

Saving checkpoint for epoch 10 at ./checkpoints/train/ckpt-2 Time taken for epoch 10 is 467.33630180358887 sec
テストデータセットを使用して生成する
# Run the trained model on the test dataset
for inp in test_horses.take(5):
generate_images(generator_g, inp)





次のステップ
このチュートリアルでは、Pix2Pix チュートリアルで実装されたジェネレータとディスクリミネータを使って CycleGAN を実装する方法を紹介しました。次のステップとして、TensorFlow データセットの別のデータセットを使用して試してみてください。
また、エポック数を増加してトレーニングし、結果がどのように改善されるか確認することもできます。さらに、ここで使用した U-Net ジェネレータの代わりに論文で使用されている変更された ResNet ジェネレータを実装してみるのもよいでしょう。