
| |
 GitHub でソースを表示 GitHub でソースを表示 |
|
このガイドでは、スニーカーやシャツなど、身に着けるものの画像を分類するニューラルネットワークのモデルをトレーニングします。すべての詳細を理解できなくても問題ありません。ここでは、完全な TensorFlow プログラムについて概説し、細かいところはその過程において見ていきます。
このガイドでは、TensorFlowのモデルを構築し訓練するためのハイレベルのAPIである tf.kerasを使用します。
# TensorFlow and tf.keras
import tensorflow as tf
# Helper libraries
import numpy as np
import matplotlib.pyplot as plt
print(tf.__version__)
2022-12-15 00:31:21.895161: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory 2022-12-15 00:31:21.895268: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory 2022-12-15 00:31:21.895278: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly. 2.11.0
Fashion MNIST データセットをインポートする
このガイドでは、Fashion MNIST データセットを使用します。このデータセットには、10 カテゴリの 70,000 のグレースケール画像が含まれています。次のように、画像は低解像度(28 x 28 ピクセル)で個々の衣料品を示しています。
| |
| 図 1. Fashion-MNIST サンプル (作成者:Zalando、MIT ライセンス) |
Fashion MNISTは、画像処理のための機械学習での"Hello, World"としてしばしば登場するMNIST データセットの代替として開発されたものです。MNISTデータセットは手書きの数字(0, 1, 2 など)から構成されており、そのフォーマットはこれから使うFashion MNISTと全く同じです。
Fashion MNIST を使うのは、目先を変える意味もありますが、普通の MNIST よりも少しだけ手応えがあるからでもあります。どちらのデータセットも比較的小さく、アルゴリズムが期待したとおりに機能するかどうかを確認するために使われます。プログラムのテストやデバッグのためには、よい出発点になります。
ここでは、60,000 枚の画像を使用してネットワークをトレーニングし、10,000 枚の画像を使用して、ネットワークが画像の分類をどの程度正確に学習したかを評価します。Tensor Flow から直接 Fashion MNIST にアクセスできます。Tensor Flow から直接 Fashion MNIST データをインポートして読み込みます。
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
読み込んだデータセットは、NumPy 配列になります。
train_imagesとtrain_labelsの 2 つの配列は、モデルのトレーニングに使用されるトレーニング用データセットです。- モデルは、テストセット、
test_imagesおよびtest_labels配列に対してテストされます。
画像は 28×28 の NumPy 配列から構成されています。それぞれのピクセルの値は 0 から 255 の間です。ラベルは、0 から 9 までの整数の配列です。それぞれの数字が下表のように、衣料品のクラスに対応しています。
| Label | Class |
|---|---|
| 0 | T-shirt/top |
| 1 | Trouser |
| 2 | Pullover |
| 3 | Dress |
| 4 | Coat |
| 5 | Sandal |
| 6 | Shirt |
| 7 | Sneaker |
| 8 | Bag |
| 9 | Ankle boot |
画像はそれぞれ単一のラベルに分類されます。データセットには上記のクラス名が含まれていないため、後ほど画像を出力するときのために、クラス名を保存しておきます。
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
データの観察
モデルのトレーニングを行う前に、データセットの形式を見てみましょう。下記のように、トレーニング用データセットには 28 × 28 ピクセルの画像が 60,000 含まれています。
train_images.shape
(60000, 28, 28)
同様に、トレーニング用データセットには 60,000 のラベルが含まれています。
len(train_labels)
60000
ラベルはそれぞれ、0 から 9 までの間の整数です。
train_labels
array([9, 0, 0, ..., 3, 0, 5], dtype=uint8)
テスト用データセットには、10,000 の画像が含まれます。画像は 28 × 28 ピクセルで構成されています。
test_images.shape
(10000, 28, 28)
テスト用データセットには 10,000 のラベルが含まれます。
len(test_labels)
10000
データの前処理
ネットワークをトレーニングする前に、データを前処理する必要があります。最初の画像を調べてみればわかるように、ピクセルの値は 0 から 255 の間の数値です。
plt.figure()
plt.imshow(train_images[0])
plt.colorbar()
plt.grid(False)
plt.show()
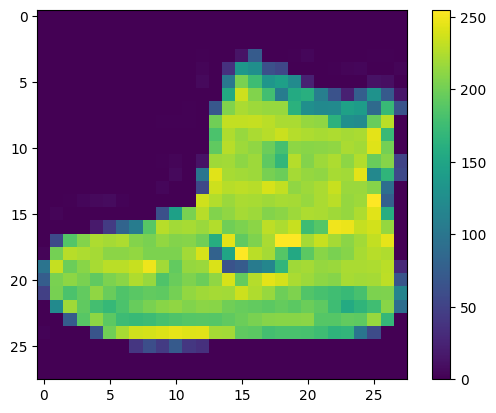
これらの値をニューラルネットワークモデルに供給する前に、0 から 1 の範囲にスケーリングします。これを行うには、値を 255 で割ります。トレーニングセットとテストセットを同じ方法で前処理することが重要です。
train_images = train_images / 255.0
test_images = test_images / 255.0
訓練用データセットの最初の25枚の画像を、クラス名付きで表示してみましょう。ネットワークを構築・訓練する前に、データが正しいフォーマットになっていることを確認します。
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
plt.show()

モデルの構築
ニューラルネットワークを構築するには、まずモデルのレイヤーを定義し、その後モデルをコンパイルします。
レイヤーの設定
ニューラルネットワークの基本的な構成要素は、レイヤーです。レイヤーは、レイヤーに入力されたデータから表現を抽出します。 これらの表現は解決しようとする問題に有用であることが望まれます。
ディープラーニングモデルのほとんどは、単純なレイヤーの積み重ねで構成されています。tf.keras.layers.Dense のようなレイヤーのほとんどには、トレーニング中に学習されるパラメータが存在します。
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10)
])
このネットワークの最初のレイヤーは、tf.keras.layers.Flatten です。このレイヤーは、画像を(28 × 28 ピクセルの)2 次元配列から、28×28=784 ピクセルの、1 次元配列に変換します。このレイヤーが、画像の中に積まれているピクセルの行を取り崩し、横に並べると考えてください。このレイヤーには学習すべきパラメータはなく、ただデータのフォーマット変換を行うだけです。
ピクセルが1次元化されたあと、ネットワークは 2 つの tf.keras.layers.Dense レイヤーとなります。これらのレイヤーは、密結合あるいは全結合されたニューロンのレイヤーとなります。最初の Dense レイヤーには、128 個のノード(あるはニューロン)があります。最後のレイヤーでもある 2 番めのレイヤーは、長さが 10 のロジット配列を返します。それぞれのノードは、今見ている画像が 10 個のクラスのひとつひとつに属する確率を出力します。
モデルのコンパイル
モデルのトレーニングの準備が整う前に、さらにいくつかの設定が必要です。これらは、モデルのコンパイルステップ中に追加されます。
- 損失関数 —これは、トレーニング中のモデルの正解率を測定します。この関数を最小化して、モデルを正しい方向に「操縦」する必要があります。
- オプティマイザ —これは、モデルが表示するデータとその損失関数に基づいてモデルが更新される方法です。
- 指標 —トレーニングとテストの手順を監視するために使用されます。次の例では、正しく分類された画像の率である正解率を使用しています。
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
モデルの訓練
ニューラルネットワークモデルのトレーニングには、次の手順が必要です。
- モデルトレーニング用データを投入します。この例では、トレーニングデータは
train_imagesおよびtrain_labels配列にあります。 - モデルは、画像とラベルの対応関係を学習します。
- モデルにテスト用データセットの予測(分類)を行わせます。この例では
test_images配列です。その後、予測結果とtest_labels配列を照合します。 - 予測が
test_labels配列のラベルと一致することを確認します。
モデルに投入する
トレーニングを開始するには、model.fit メソッドを呼び出します。
model.fit(train_images, train_labels, epochs=10)
Epoch 1/10 1875/1875 [==============================] - 5s 2ms/step - loss: 0.5022 - accuracy: 0.8239 Epoch 2/10 1875/1875 [==============================] - 4s 2ms/step - loss: 0.3784 - accuracy: 0.8636 Epoch 3/10 1875/1875 [==============================] - 4s 2ms/step - loss: 0.3419 - accuracy: 0.8745 Epoch 4/10 1875/1875 [==============================] - 4s 2ms/step - loss: 0.3157 - accuracy: 0.8838 Epoch 5/10 1875/1875 [==============================] - 4s 2ms/step - loss: 0.2996 - accuracy: 0.8889 Epoch 6/10 1875/1875 [==============================] - 4s 2ms/step - loss: 0.2831 - accuracy: 0.8948 Epoch 7/10 1875/1875 [==============================] - 4s 2ms/step - loss: 0.2700 - accuracy: 0.8989 Epoch 8/10 1875/1875 [==============================] - 4s 2ms/step - loss: 0.2583 - accuracy: 0.9038 Epoch 9/10 1875/1875 [==============================] - 4s 2ms/step - loss: 0.2489 - accuracy: 0.9079 Epoch 10/10 1875/1875 [==============================] - 4s 2ms/step - loss: 0.2407 - accuracy: 0.9096 <keras.callbacks.History at 0x7f659e338ee0>
モデルのトレーニングの進行とともに、損失値と正解率が表示されます。このモデルの場合、トレーニング用データでは 0.91 (すなわち 91%) の正解率に達します。
正解率を評価する
次に、モデルがテストデータセットでどのように機能するかを比較します。
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('\nTest accuracy:', test_acc)
313/313 - 1s - loss: 0.3393 - accuracy: 0.8804 - 635ms/epoch - 2ms/step Test accuracy: 0.8804000020027161
ご覧の通り、テスト用データセットでの正解率は、トレーニング用データセットでの正解率よりも少し低くなります。このトレーニング時の正解率とテスト時の正解率の差は、過適合の一例です。過適合とは、新しいデータに対する機械学習モデルの性能が、トレーニング時と比較して低下する現象です。過適合モデルは、トレーニングデータセットのノイズと詳細を「記憶」するため、新しいデータでのモデルのパフォーマンスに悪影響を及ぼします。詳細については、以下を参照してください。
予測する
トレーニングされたモデルを使用して、いくつかの画像に関する予測を行うことができます。ソフトマックスレイヤーをアタッチして、モデルの線形出力であるロジットを解釈しやすい確率に変換します。
probability_model = tf.keras.Sequential([model,
tf.keras.layers.Softmax()])
predictions = probability_model.predict(test_images)
313/313 [==============================] - 0s 1ms/step
これは、モデルがテスト用データセットの画像のひとつひとつを分類予測した結果です。最初の予測を見てみましょう。
predictions[0]
array([5.6910987e-09, 2.4519869e-07, 5.8553162e-08, 3.0318517e-08,
3.1033121e-08, 3.6219638e-04, 2.5309854e-08, 1.5150005e-02,
8.6693162e-06, 9.8447871e-01], dtype=float32)
予測結果は、10個の数字の配列です。これは、その画像が10の衣料品の種類のそれぞれに該当するかの「確信度」を表しています。どのラベルが一番確信度が高いかを見てみましょう。
np.argmax(predictions[0])
9
このモデルは、この画像が、アンクルブーツ、class_names[9]である可能性が最も高いと判断したことになります。これが正しいかどうか、テスト用ラベルを見てみましょう。
test_labels[0]
9
これをグラフ化して、10 クラスの予測の完全なセットを確認します。
def plot_image(i, predictions_array, true_label, img):
true_label, img = true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label],
100*np.max(predictions_array),
class_names[true_label]),
color=color)
def plot_value_array(i, predictions_array, true_label):
true_label = true_label[i]
plt.grid(False)
plt.xticks(range(10))
plt.yticks([])
thisplot = plt.bar(range(10), predictions_array, color="#777777")
plt.ylim([0, 1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')
予測を検証する
トレーニングされたモデルを使用して、いくつかの画像に関する予測を行うことができます。
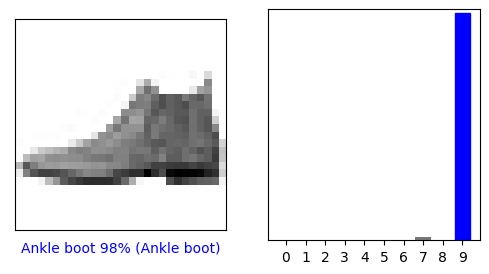
0 番目の画像、予測、および予測配列を見てみましょう。 正しい予測ラベルは青で、間違った予測ラベルは赤です。 数値は、予測されたラベルのパーセンテージ (/100) を示します。
i = 0
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions[i], test_labels)
plt.show()
i = 12
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions[i], test_labels)
plt.show()
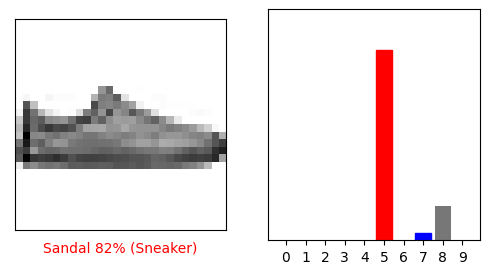
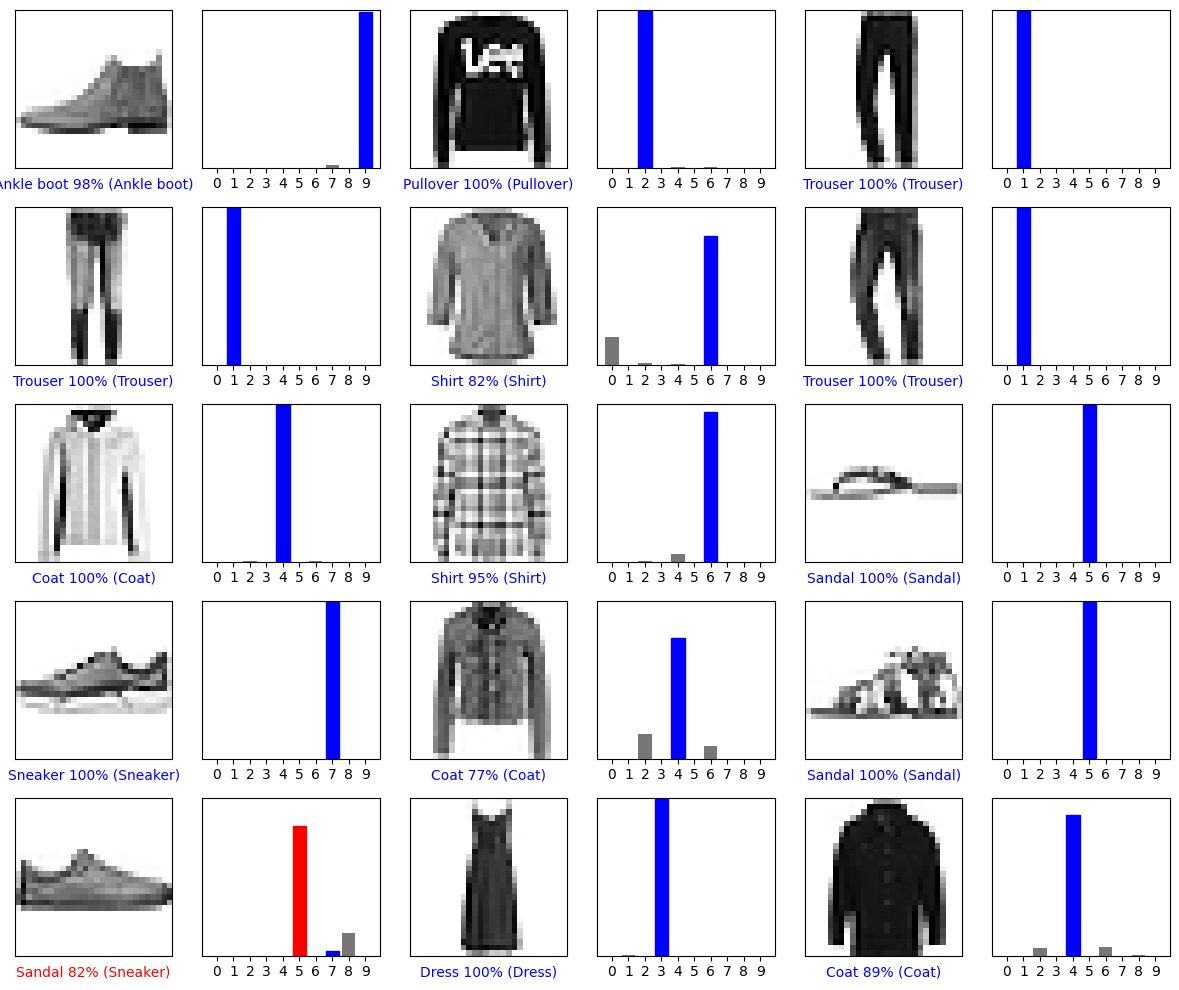
いくつかの画像をそれらの予測とともにプロットしてみましょう。確信度が高い場合でも、モデルが間違っていることがあることに注意してください。
# Plot the first X test images, their predicted labels, and the true labels.
# Color correct predictions in blue and incorrect predictions in red.
num_rows = 5
num_cols = 3
num_images = num_rows*num_cols
plt.figure(figsize=(2*2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, 2*num_cols, 2*i+1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(num_rows, 2*num_cols, 2*i+2)
plot_value_array(i, predictions[i], test_labels)
plt.tight_layout()
plt.show()
トレーニングされたモデルを使用する
最後に、トレーニング済みモデルを使って 1 つの画像に対する予測を行います。
# Grab an image from the test dataset.
img = test_images[1]
print(img.shape)
(28, 28)
tf.keras モデルは、サンプルの中のバッチあるいは「集まり」についてまとめて予測を行うように最適化されています。そのため、1 つの画像を使う場合でも、リスト化する必要があります。
# Add the image to a batch where it's the only member.
img = (np.expand_dims(img,0))
print(img.shape)
(1, 28, 28)
そして、予測を行います。
predictions_single = probability_model.predict(img)
print(predictions_single)
1/1 [==============================] - 0s 24ms/step [[2.4473981e-04 1.2069421e-11 9.9653888e-01 2.1565708e-14 1.3155717e-03 2.2960410e-12 1.9008714e-03 8.9515721e-13 2.3349067e-10 3.9004930e-16]]
plot_value_array(1, predictions_single[0], test_labels)
_ = plt.xticks(range(10), class_names, rotation=45)
plt.show()
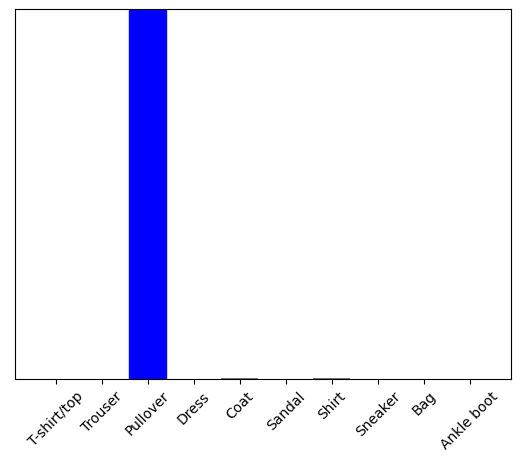
tf.keras.Model.predict は、リストのリストを返します。リストの要素のそれぞれが、バッチの中の画像に対応します。バッチの中から、(といってもバッチの中身は1つだけですが) 予測を取り出します。
np.argmax(predictions_single[0])
2
モデルは期待どおりにラベルを予測しました。
# MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.