
| |
 GitHub에서 소스 보기 GitHub에서 소스 보기 |
개요
이 가이드는 TensorFlow의 TensorFlow 및 Keras의 내부를 살펴봄으로써 TensorFlow의 동작 방식을 설명합니다. 대신 Keras를 바로 시작하려면 Keras 가이드 모음을 확인하세요.
이 가이드에서는 TensorFlow를 사용하여 코드를 간단하게 변경하고 그래프를 가져오는 방법, 그래프를 저장하고 표시하는 방법, 그리고 이를 사용하여 모델을 가속화하는 방법을 배웁니다.
참고: TensorFlow 1.x에만 익숙한 사용자를 위해 이 가이드는 매우 다른 그래프 뷰를 보여줍니다.
본 내용은 tf.function을 사용하여 즉시 실행에서 그래프 실행으로 전환하는 방법을 개괄적으로 설명합니다. tf.function의 전반적인 사용에 대한 내용은 tf.function으로 성능 향상하기 가이드를 참조하세요.
그래프란 무엇인가요?
In the previous three guides, you ran TensorFlow eagerly. This means TensorFlow operations are executed by Python, operation by operation, and returning results back to Python.
즉시 실행에는 몇 가지 고유한 장점이 있지만 그래프 실행은 Python 외부에서 이식성을 가능하게 하며 성능이 더 우수한 경향이 있습니다. 그래프 실행은 텐서 계산이 tf.Graph 또는 간단히 "그래프"라고도 하는 TensorFlow 그래프로 실행됨을 의미합니다.
그래프는 계산의 단위를 나타내는 tf.Operation 객체와 연산 간에 흐르는 데이터의 단위를 나타내는 tf.Tensor 객체의 세트를 포함합니다. 데이터 구조는 tf.Graph 컨텍스트에서 정의됩니다. 그래프는 데이터 구조이므로 원래 Python 코드 없이 모두 저장, 실행 및 복원할 수 있습니다.
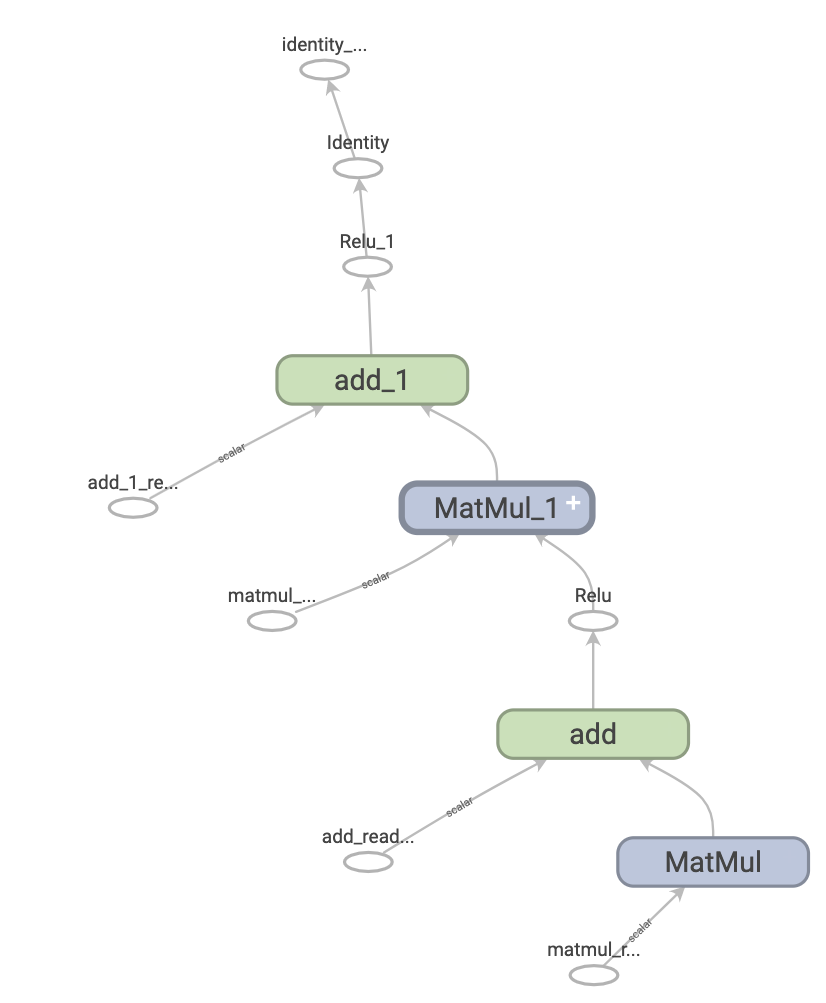
이것은 TensorBoard에서 시각화했을 때 2계층 신경망을 나타내는 TensorFlow 그래프의 모습입니다.
그래프의 이점
그래프를 사용하면 유연성이 크게 향상됩니다. 모바일 애플리케이션, 임베디드 기기 및 백엔드 서버와 같은 Python 인터프리터가 없는 환경에서 TensorFlow 그래프를 사용할 수 있습니다. TensorFlow는 그래프를 Python에서 내보낼 때 저장된 모델의 형식으로 그래프를 사용합니다.
그래프는 쉽게 최적화되어 컴파일러가 다음과 같은 변환을 수행할 수 있습니다.
- 계산에서 상수 노드를 접어 텐서의 값을 정적으로 추론합니다("일정한 접기").
- 독립적인 계산의 하위 부분을 분리하여 스레드 또는 기기 간에 분할합니다.
- 공통 하위 표현식을 제거하여 산술 연산을 단순화합니다.
위와 같은 변환 및 기타 속도 향상을 수행하기 위한 전체 최적화 시스템으로 Grappler가 있습니다.
요약하면, 그래프는 TensorFlow가 빠르게, 병렬로, 그리고 효율적으로 여러 기기에서 실행할 때 아주 유용합니다.
그러나 편의를 위해 Python에서 머신러닝 모델(또는 기타 계산)을 정의한 다음 필요할 때 자동으로 그래프를 구성하려고 합니다.
설정하기
필요한 라이브러리를 가져옵니다.
import tensorflow as tf
import timeit
from datetime import datetime
2022-12-14 21:18:29.138089: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory 2022-12-14 21:18:29.138197: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory 2022-12-14 21:18:29.138208: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
그래프 이용하기
tf.function을 직접 호출 또는 데코레이터로 사용하여 TensorFlow에서 그래프를 만들고 실행합니다. tf.function은 일반 함수를 입력으로 받아 Function을 반환합니다. Function은 Python 함수로부터 TensorFlow 그래프를 빌드하는 Python callable입니다. Python의 경우와 동일한 방식으로 Function를 사용합니다.
# Define a Python function.
def a_regular_function(x, y, b):
x = tf.matmul(x, y)
x = x + b
return x
# `a_function_that_uses_a_graph` is a TensorFlow `Function`.
a_function_that_uses_a_graph = tf.function(a_regular_function)
# Make some tensors.
x1 = tf.constant([[1.0, 2.0]])
y1 = tf.constant([[2.0], [3.0]])
b1 = tf.constant(4.0)
orig_value = a_regular_function(x1, y1, b1).numpy()
# Call a `Function` like a Python function.
tf_function_value = a_function_that_uses_a_graph(x1, y1, b1).numpy()
assert(orig_value == tf_function_value)
겉보기에 Function은 TensorFlow 연산을 사용하여 작성하는 일반 함수처럼 보입니다. 하지만 그 안을 들여다 보면 매우 다릅니다. Function는 하나의 API 뒤에서 여러 tf.Graph를 캡슐화합니다(다형성 섹션에서 자세히 알아볼 수 있습니다). 이것이 Function이 속도 및 배포 가능성과 같은 그래프 실행의 이점을 제공하는 방식입니다(위의 그래프의 이점 참조).
tf.function은 함수 및 이 함수가 호출하는 다른 모든 함수에 적용됩니다.
def inner_function(x, y, b):
x = tf.matmul(x, y)
x = x + b
return x
# Use the decorator to make `outer_function` a `Function`.
@tf.function
def outer_function(x):
y = tf.constant([[2.0], [3.0]])
b = tf.constant(4.0)
return inner_function(x, y, b)
# Note that the callable will create a graph that
# includes `inner_function` as well as `outer_function`.
outer_function(tf.constant([[1.0, 2.0]])).numpy()
array([[12.]], dtype=float32)
TensorFlow 1.x를 사용한 경우 Placeholder 또는 tf.Sesssion을 정의할 필요가 없었음을 알 수 있습니다.
Python 함수를 그래프로 변환하기
TensorFlow를 사용하여 작성하는 모든 함수에는 if-then 절, 루프, break, return, continue 등과 같은 내장된 TF 연산과 Python 논리가 혼합되어 있습니다. TensorFlow 연산은 tf.Graph에 의해 쉽게 캡처되지만 Python 관련 논리는 그래프의 일부가 되기 위해 추가 단계를 거쳐야 합니다. tf.function은 AutoGraph(tf.autograph)라는 라이브러리를 사용하여 Python 코드를 그래프 생성 코드로 변환합니다.
def simple_relu(x):
if tf.greater(x, 0):
return x
else:
return 0
# `tf_simple_relu` is a TensorFlow `Function` that wraps `simple_relu`.
tf_simple_relu = tf.function(simple_relu)
print("First branch, with graph:", tf_simple_relu(tf.constant(1)).numpy())
print("Second branch, with graph:", tf_simple_relu(tf.constant(-1)).numpy())
First branch, with graph: 1 Second branch, with graph: 0
그래프를 직접 볼 필요는 없겠지만 결과를 검사하여 정확한 결과를 확인할 수 있습니다. 읽기가 쉽지 않으므로 너무 주의 깊게 볼 필요는 없습니다!
# This is the graph-generating output of AutoGraph.
print(tf.autograph.to_code(simple_relu))
def tf__simple_relu(x):
with ag__.FunctionScope('simple_relu', 'fscope', ag__.ConversionOptions(recursive=True, user_requested=True, optional_features=(), internal_convert_user_code=True)) as fscope:
do_return = False
retval_ = ag__.UndefinedReturnValue()
def get_state():
return (do_return, retval_)
def set_state(vars_):
nonlocal retval_, do_return
(do_return, retval_) = vars_
def if_body():
nonlocal retval_, do_return
try:
do_return = True
retval_ = ag__.ld(x)
except:
do_return = False
raise
def else_body():
nonlocal retval_, do_return
try:
do_return = True
retval_ = 0
except:
do_return = False
raise
ag__.if_stmt(ag__.converted_call(ag__.ld(tf).greater, (ag__.ld(x), 0), None, fscope), if_body, else_body, get_state, set_state, ('do_return', 'retval_'), 2)
return fscope.ret(retval_, do_return)
# This is the graph itself.
print(tf_simple_relu.get_concrete_function(tf.constant(1)).graph.as_graph_def())
node {
name: "x"
op: "Placeholder"
attr {
key: "_user_specified_name"
value {
s: "x"
}
}
attr {
key: "dtype"
value {
type: DT_INT32
}
}
attr {
key: "shape"
value {
shape {
}
}
}
}
node {
name: "Greater/y"
op: "Const"
attr {
key: "dtype"
value {
type: DT_INT32
}
}
attr {
key: "value"
value {
tensor {
dtype: DT_INT32
tensor_shape {
}
int_val: 0
}
}
}
}
node {
name: "Greater"
op: "Greater"
input: "x"
input: "Greater/y"
attr {
key: "T"
value {
type: DT_INT32
}
}
}
node {
name: "cond"
op: "StatelessIf"
input: "Greater"
input: "x"
attr {
key: "Tcond"
value {
type: DT_BOOL
}
}
attr {
key: "Tin"
value {
list {
type: DT_INT32
}
}
}
attr {
key: "Tout"
value {
list {
type: DT_BOOL
type: DT_INT32
}
}
}
attr {
key: "_lower_using_switch_merge"
value {
b: true
}
}
attr {
key: "_read_only_resource_inputs"
value {
list {
}
}
}
attr {
key: "else_branch"
value {
func {
name: "cond_false_34"
}
}
}
attr {
key: "output_shapes"
value {
list {
shape {
}
shape {
}
}
}
}
attr {
key: "then_branch"
value {
func {
name: "cond_true_33"
}
}
}
}
node {
name: "cond/Identity"
op: "Identity"
input: "cond"
attr {
key: "T"
value {
type: DT_BOOL
}
}
}
node {
name: "cond/Identity_1"
op: "Identity"
input: "cond:1"
attr {
key: "T"
value {
type: DT_INT32
}
}
}
node {
name: "Identity"
op: "Identity"
input: "cond/Identity_1"
attr {
key: "T"
value {
type: DT_INT32
}
}
}
library {
function {
signature {
name: "cond_false_34"
input_arg {
name: "cond_placeholder"
type: DT_INT32
}
output_arg {
name: "cond_identity"
type: DT_BOOL
}
output_arg {
name: "cond_identity_1"
type: DT_INT32
}
}
node_def {
name: "cond/Const"
op: "Const"
attr {
key: "dtype"
value {
type: DT_BOOL
}
}
attr {
key: "value"
value {
tensor {
dtype: DT_BOOL
tensor_shape {
}
bool_val: true
}
}
}
}
node_def {
name: "cond/Const_1"
op: "Const"
attr {
key: "dtype"
value {
type: DT_BOOL
}
}
attr {
key: "value"
value {
tensor {
dtype: DT_BOOL
tensor_shape {
}
bool_val: true
}
}
}
}
node_def {
name: "cond/Const_2"
op: "Const"
attr {
key: "dtype"
value {
type: DT_INT32
}
}
attr {
key: "value"
value {
tensor {
dtype: DT_INT32
tensor_shape {
}
int_val: 0
}
}
}
}
node_def {
name: "cond/Const_3"
op: "Const"
attr {
key: "dtype"
value {
type: DT_BOOL
}
}
attr {
key: "value"
value {
tensor {
dtype: DT_BOOL
tensor_shape {
}
bool_val: true
}
}
}
}
node_def {
name: "cond/Identity"
op: "Identity"
input: "cond/Const_3:output:0"
attr {
key: "T"
value {
type: DT_BOOL
}
}
}
node_def {
name: "cond/Const_4"
op: "Const"
attr {
key: "dtype"
value {
type: DT_INT32
}
}
attr {
key: "value"
value {
tensor {
dtype: DT_INT32
tensor_shape {
}
int_val: 0
}
}
}
}
node_def {
name: "cond/Identity_1"
op: "Identity"
input: "cond/Const_4:output:0"
attr {
key: "T"
value {
type: DT_INT32
}
}
}
ret {
key: "cond_identity"
value: "cond/Identity:output:0"
}
ret {
key: "cond_identity_1"
value: "cond/Identity_1:output:0"
}
attr {
key: "_construction_context"
value {
s: "kEagerRuntime"
}
}
arg_attr {
key: 0
value {
attr {
key: "_output_shapes"
value {
list {
shape {
}
}
}
}
}
}
}
function {
signature {
name: "cond_true_33"
input_arg {
name: "cond_identity_1_x"
type: DT_INT32
}
output_arg {
name: "cond_identity"
type: DT_BOOL
}
output_arg {
name: "cond_identity_1"
type: DT_INT32
}
}
node_def {
name: "cond/Const"
op: "Const"
attr {
key: "dtype"
value {
type: DT_BOOL
}
}
attr {
key: "value"
value {
tensor {
dtype: DT_BOOL
tensor_shape {
}
bool_val: true
}
}
}
}
node_def {
name: "cond/Identity"
op: "Identity"
input: "cond/Const:output:0"
attr {
key: "T"
value {
type: DT_BOOL
}
}
}
node_def {
name: "cond/Identity_1"
op: "Identity"
input: "cond_identity_1_x"
attr {
key: "T"
value {
type: DT_INT32
}
}
}
ret {
key: "cond_identity"
value: "cond/Identity:output:0"
}
ret {
key: "cond_identity_1"
value: "cond/Identity_1:output:0"
}
attr {
key: "_construction_context"
value {
s: "kEagerRuntime"
}
}
arg_attr {
key: 0
value {
attr {
key: "_output_shapes"
value {
list {
shape {
}
}
}
}
}
}
}
}
versions {
producer: 1286
min_consumer: 12
}
대부분의 경우 tf.function은 특별한 고려없이 작동합니다. 다만, 몇 가지 주의해야 하는 사항이 있으며 tf.function 가이드와 전체 AutoGraph 참조서가 도움이 될 수 있습니다.
다형성: 하나의 Function, 다수의 그래프
tf.Graph는 특정 유형의 입력에 특화되어 있습니다(예: 특정 dtype을 가진 텐서 또는 동일한 id()를 가진 객체).
기존 그래프에서 처리할 수 없는 인수 세트로 Function을 호출할 때마다(예: 새로운 dtypes 또는 호환되지 않는 형상의 인수) Function은 이러한 새 인수에 특화된 새 tf.Graph를 생성합니다. tf.Graph 입력의 유형 사양을 입력 서명 또는 서명이라고 합니다. 새 tf.Graph가 생성되는 시기와 이를 제어하는 방법에 대한 자세한 정보는 tf.function으로 성능 향상하기 가이드의 추적 규칙 섹션을 참조합니다.
Function은 해당 서명에 대응하는 tf.Graph를 ConcreteFunction에 저장합니다. ConcreteFunction은 tf.Graph를 감싸는 래퍼입니다.
@tf.function
def my_relu(x):
return tf.maximum(0., x)
# `my_relu` creates new graphs as it observes more signatures.
print(my_relu(tf.constant(5.5)))
print(my_relu([1, -1]))
print(my_relu(tf.constant([3., -3.])))
tf.Tensor(5.5, shape=(), dtype=float32) tf.Tensor([1. 0.], shape=(2,), dtype=float32) tf.Tensor([3. 0.], shape=(2,), dtype=float32)
Function이 이 서명으로 이미 호출된 경우, Function은 새 tf.Graph를 생성하지 않습니다.
# These two calls do *not* create new graphs.
print(my_relu(tf.constant(-2.5))) # Signature matches `tf.constant(5.5)`.
print(my_relu(tf.constant([-1., 1.]))) # Signature matches `tf.constant([3., -3.])`.
tf.Tensor(0.0, shape=(), dtype=float32) tf.Tensor([0. 1.], shape=(2,), dtype=float32)
여러 그래프로 뒷받침된다는 점에서 Function은 다형성의 특징을 갖습니다. 그 결과, 단일 tf.Graph로 나타낼 수 있는 것보다 더 많은 입력 유형을 지원하고 tf.Graph가 더 우수한 성능을 갖도록 최적화할 수 있습니다.
# There are three `ConcreteFunction`s (one for each graph) in `my_relu`.
# The `ConcreteFunction` also knows the return type and shape!
print(my_relu.pretty_printed_concrete_signatures())
my_relu(x)
Args:
x: float32 Tensor, shape=()
Returns:
float32 Tensor, shape=()
my_relu(x=[1, -1])
Returns:
float32 Tensor, shape=(2,)
my_relu(x)
Args:
x: float32 Tensor, shape=(2,)
Returns:
float32 Tensor, shape=(2,)
tf.function 사용하기
지금까지 tf.function을 데코레이터 또는 래퍼로 사용하여 Python 함수를 간단히 그래프로 변환하는 방법을 살펴보았습니다. 그러나 실제로 tf.function이 올바르게 작동하도록 만드는 일은 까다로울 수 있습니다! 다음 섹션에서는 tf.function을 사용하여 코드가 예상대로 작동하도록 만드는 방법을 알아봅니다.
그래프 실행 vs 즉시 실행
Function의 코드는 즉시 실행 또는 그래프 실행이 가능합니다. 기본적으로 Function은 코드를 그래프로 실행합니다.
@tf.function
def get_MSE(y_true, y_pred):
sq_diff = tf.pow(y_true - y_pred, 2)
return tf.reduce_mean(sq_diff)
y_true = tf.random.uniform([5], maxval=10, dtype=tf.int32)
y_pred = tf.random.uniform([5], maxval=10, dtype=tf.int32)
print(y_true)
print(y_pred)
tf.Tensor([8 1 3 3 4], shape=(5,), dtype=int32) tf.Tensor([7 0 1 1 4], shape=(5,), dtype=int32)
get_MSE(y_true, y_pred)
<tf.Tensor: shape=(), dtype=int32, numpy=2>
Function의 그래프가 동등한 Python 함수와 같은 계산을 수행하는지 확인하기 위해 tf.config.run_functions_eagerly(True)를 이용해 즉시 실행하도록 할 수 있습니다. 이는 코드를 정상적으로 실행하는 대신 그래프를 생성하고 실행하는 Function의 기능을 해제하는 스위치입니다.
tf.config.run_functions_eagerly(True)
get_MSE(y_true, y_pred)
<tf.Tensor: shape=(), dtype=int32, numpy=2>
# Don't forget to set it back when you are done.
tf.config.run_functions_eagerly(False)
그러나 Function은 그래프 및 즉시 실행에서 서로 다르게 동작할 수 있습니다. Python print 함수는 이 두 모드가 어떻게 다른지 보여주는 한 가지 예제입니다. print 문을 삽입하고 이를 반복적으로 호출할 때 어떤 일이 발생하는지 살펴보겠습니다.
@tf.function
def get_MSE(y_true, y_pred):
print("Calculating MSE!")
sq_diff = tf.pow(y_true - y_pred, 2)
return tf.reduce_mean(sq_diff)
인쇄된 내용을 잘 살펴봅니다.
error = get_MSE(y_true, y_pred)
error = get_MSE(y_true, y_pred)
error = get_MSE(y_true, y_pred)
Calculating MSE!
출력 결과가 놀랍지 않나요? get_MSE는 세 번 호출되었지만 한 번만 인쇄되었습니다.
설명하자면, print 문은 Function이 원래 코드를 실행할 때 실행되며 이 때 "트레이싱"이라는 프로세스를 통해 그래프를 생성합니다(tf.function 가이드의 추적 섹션 참조). 추적은 TensorFlow 연산을 그래프로 캡처하고 print는 그래프로 캡처되지 않습니다. 이 그래프는 세 번의 모든 호출시 실행되지만 Python 코드를 다시 실행하지는 않습니다.
실제로 그런지 검사하기 위해 그래프 실행을 해제하고 비교해 보겠습니다.
# Now, globally set everything to run eagerly to force eager execution.
tf.config.run_functions_eagerly(True)
# Observe what is printed below.
error = get_MSE(y_true, y_pred)
error = get_MSE(y_true, y_pred)
error = get_MSE(y_true, y_pred)
Calculating MSE! Calculating MSE! Calculating MSE!
tf.config.run_functions_eagerly(False)
print는 Python의 부작용이며 함수를 Function으로 변환할 때 알고 있어야 하는 다른 차이점들이 있습니다. tf.function으로 성능 향상하기 가이드의 한계 섹션에서 자세히 알아보세요.
참고: 즉시 및 그래프 실행 모두에서 값을 인쇄하려면 tf.print를 대신 사용하세요.
비평가(Non-strict) 실행
그래프 실행은 다음을 포함하여 관찰 가능한 효과를 생성하는 데 필요한 작업만 실행합니다.
- 함수의 반환 값
- 다음과 같은 문서화된 잘 알려진 부작용:
tf.print와 같은 입력/출력 작업tf.debugging의 어설션 기능과 같은 디버깅 작업tf.Variable의 변형
이 동작은 일반적으로 "비평가 실행"으로 알려져 있으며 필요하거나 필요하지 않은 모든 프로그램 작업을 단계별로 실행하는 즉시 실행과 구분됩니다.
특히 런타임 오류 검사는 관찰 가능한 효과로 간주되지 않습니다. 작업이 불필요하다는 이유로 건너뛰면 런타임 오류가 발생할 수 없습니다.
다음 예제에서는 그래프 실행 중에 "불필요한" 작업인 tf.gather을 건너뛰므로 즉시 실행에서와 마찬가지로 런타임 오류 InvalidArgumentError가 발생하지 않습니다. 그래프를 실행하는 동안 발생하는 오류에 의존하지 마세요.
def unused_return_eager(x):
# Get index 1 will fail when `len(x) == 1`
tf.gather(x, [1]) # unused
return x
try:
print(unused_return_eager(tf.constant([0.0])))
except tf.errors.InvalidArgumentError as e:
# All operations are run during eager execution so an error is raised.
print(f'{type(e).__name__}: {e}')
tf.Tensor([0.], shape=(1,), dtype=float32)
@tf.function
def unused_return_graph(x):
tf.gather(x, [1]) # unused
return x
# Only needed operations are run during graph execution. The error is not raised.
print(unused_return_graph(tf.constant([0.0])))
tf.Tensor([0.], shape=(1,), dtype=float32)
tf.function 모범 사례
Function의 동작에 익숙해지려면 시간이 걸릴 수 있습니다. 빠르게 시작하려는 처음 사용자는 @tf.function으로 시험용 함수를 사용해 보면서 즉시 실행에서 그래프 실행으로 이동하는 과정을 체험할 수 있습니다.
tf.function 을 위한 디자인은 그래프 호환 TensorFlow 프로그램을 작성하는 가장 좋은 방법일 수 있습니다. 다음은 몇 가지 팁입니다.
tf.config.run_functions_eagerly로 즉시 실행과 그래프 실행 사이를 조기에 자주 전환하여 두 모드가 서로 달라지는지, 언제 달라지는지 정확하게 파악합니다.- Python 함수 외부에서
tf.Variable을 실행하고 수정은 내부에서 수행합니다.keras.layers,keras.Model및tf.optimizers와 같이tf.Variable을 사용하는 객체의 경우도 마찬가지입니다. tf.Variable과 Keras 객체를 제외하고 외부 Python 변수에 의존하는 함수를 작성하지 않는 것이 말아야 합니다. 자세한 내용은tf.function가이드의 Python 전역 및 자유 변수에 의존하기를 참고합니다.- 텐서 및 기타 TensorFlow 유형을 입력으로 사용하는 함수를 작성하는 것이 좋습니다. 다른 객체 유형을 전달할 수 있지만 주의해야 합니다! 자세한 내용은
tf.function가이드의 Python 객체에 의존하기를 참고합니다. - 성능 이점을 극대화하기 위해
tf.function하에서 계산이 가능한 한 많이 포함되도록 합니다. 예를 들어 전체 훈룬 스텝 또는 전체 훈룬 루프를 데코레이션합니다.
속도 향상 확인하기
tf.function은 일반적으로 코드의 성능을 향상시키지만 속도 향상의 정도는 실행하는 계산의 종류에 따라 다릅니다. 작은 계산의 경우 그래프를 호출하는 오버헤드에 의해 지배될 수 있습니다. 다음과 같이 성능 차이를 측정할 수 있습니다.
x = tf.random.uniform(shape=[10, 10], minval=-1, maxval=2, dtype=tf.dtypes.int32)
def power(x, y):
result = tf.eye(10, dtype=tf.dtypes.int32)
for _ in range(y):
result = tf.matmul(x, result)
return result
print("Eager execution:", timeit.timeit(lambda: power(x, 100), number=1000), "seconds")
Eager execution: 4.194468337000217 seconds
power_as_graph = tf.function(power)
print("Graph execution:", timeit.timeit(lambda: power_as_graph(x, 100), number=1000), "seconds")
Graph execution: 0.7734055519995309 seconds
tf.function은 일반적으로 훈련 루프의 속도를 높이는 데 사용되며, 이에 대한 자세한 내용은 Keras 가이드의 처음부터 훈련 루프 작성하기에 있는 tf.function을 이용해 훈련 단계의 속도 높이기 섹션에서 확인할 수 있습니다.
참고: 특히 코드가 TensorFlow 제어 흐름에서 과중하고 작은 텐서를 많이 사용하는 경우, 성능 개선의 효과를 높이기 위해 tf.function(jit_compile=True)를 시도해볼 수도 있습니다. 자세한 내용은 XLA 개요의 tf.function(jit_compile=True)을 사용한 명시적 컴파일 섹션에서 확인할 수 있습니다.
성능과 상충 관계
그래프는 코드의 속도를 높일 수 있지만 이를 생성하는 프로세스에는 약간의 오버헤드가 있습니다. 일부 함수의 경우 그래프를 생성하는 데 그래프를 실행하는 것보다 더 많은 시간이 걸립니다. 이러한 투자를 할 경우 후속 실행에서 성능이 향상되는 보상이 빠르게 뒤따르지만 대규모 모델 훈련의 처음 몇 단계에서는 트레이싱으로 인해 느려질 수 있다는 점을 알고 있어야 합니다.
모델 크기에 관계없이, 빈번한 추적은 피해야 합니다. tf.function 가이드의 재추적 제어 섹션에는 재추적을 피하기 위해 입력 사양을 설정하고 텐서 인수를 사용하는 방법에 관한 설명이 나와 있습니다. 비정상적으로 성능이 저하되는 것으로 판단되면 실수로 재추적하고 있지 않은지 확인하는 것이 좋습니다.
Function은 언제 트레이싱합니까?
Function이 트레이싱을 수행하는 경우를 알아보려면 코드에 print 문을 추가합니다. 대략적인 규칙으로, Function은 트레이싱할 때마다 print 문을 실행합니다.
@tf.function
def a_function_with_python_side_effect(x):
print("Tracing!") # An eager-only side effect.
return x * x + tf.constant(2)
# This is traced the first time.
print(a_function_with_python_side_effect(tf.constant(2)))
# The second time through, you won't see the side effect.
print(a_function_with_python_side_effect(tf.constant(3)))
Tracing! tf.Tensor(6, shape=(), dtype=int32) tf.Tensor(11, shape=(), dtype=int32)
# This retraces each time the Python argument changes,
# as a Python argument could be an epoch count or other
# hyperparameter.
print(a_function_with_python_side_effect(2))
print(a_function_with_python_side_effect(3))
Tracing! tf.Tensor(6, shape=(), dtype=int32) Tracing! tf.Tensor(11, shape=(), dtype=int32)
새 Python 인수는 항상 새 그래프 생성을 트리거하므로 추가 트레이싱이 발생합니다.
다음 단계
API 참조 페이지와 tf.function으로 성능 향상하기 가이드에서 tf.function에 대한 자세한 내용을 확인할 수 있습니다.