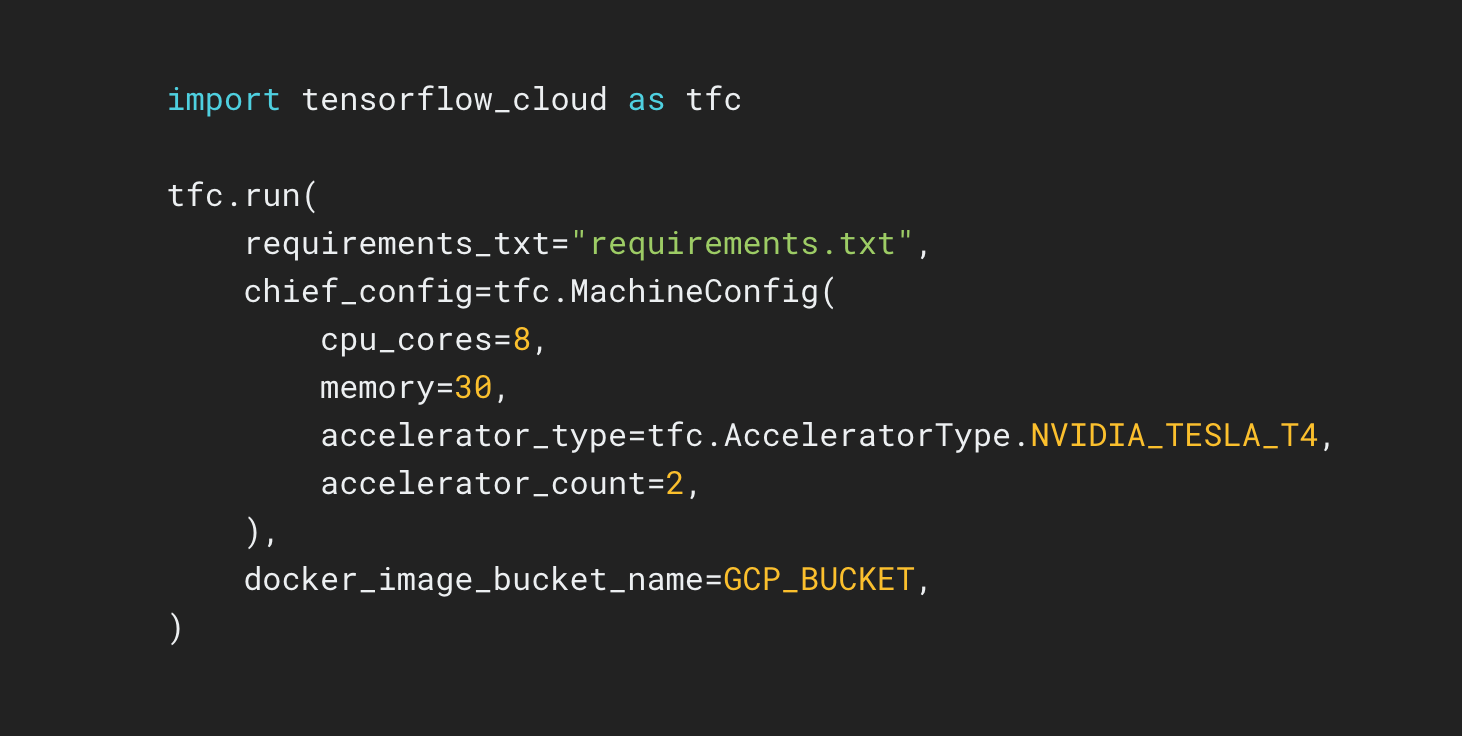
TensorFlow Cloud เป็นไลบรารีสำหรับเชื่อมต่อสภาพแวดล้อมในพื้นที่ของคุณกับ Google Cloud
import tensorflow_cloud as tfc TF_GPU_IMAGE = "tensorflow/tensorflow:latest-gpu" run_parameters = { distribution_strategy='auto', requirements_txt='requirements.txt', docker_config=tfc.DockerConfig( parent_image=TF_GPU_IMAGE, image_build_bucket=GCS_BUCKET ), chief_config=tfc.COMMON_MACHINE_CONFIGS['K80_1X'], worker_config=tfc.COMMON_MACHINE_CONFIGS['K80_1X'], worker_count=3, job_labels={'job': "my_job"} } tfc.run(**run_parameters) # Runs your training on Google Cloud!
พื้นที่เก็บข้อมูล TensorFlow Cloud มี API ที่ช่วยให้เปลี่ยนจากการสร้างโมเดลในเครื่องและการแก้ไขจุดบกพร่องไปเป็นการฝึกอบรมแบบกระจายและการปรับแต่งไฮเปอร์พารามิเตอร์บน Google Cloud ได้อย่างง่ายดาย จากภายใน Colab หรือ Kaggle Notebook หรือไฟล์สคริปต์ในเครื่อง คุณสามารถส่งโมเดลเพื่อปรับแต่งหรือฝึกบน Cloud ได้โดยตรง โดยไม่จำเป็นต้องใช้ Cloud Console