
يوضح هذا الدليل كيفية استخدام الأدوات المتاحة مع TensorFlow Profiler لتتبع أداء نماذج TensorFlow الخاصة بك. سوف تتعلم كيفية فهم كيفية أداء النموذج الخاص بك على المضيف (CPU)، أو الجهاز (GPU)، أو على مزيج من كل من المضيف والجهاز (الأجهزة).
يساعد إنشاء ملفات التعريف على فهم استهلاك موارد الأجهزة (الوقت والذاكرة) لعمليات TensorFlow (ops) المتنوعة في النموذج الخاص بك وحل اختناقات الأداء، وفي النهاية، تنفيذ النموذج بشكل أسرع.
سيرشدك هذا الدليل إلى كيفية تثبيت ملف التعريف، والأدوات المتنوعة المتاحة، والأوضاع المختلفة لكيفية جمع ملف التعريف لبيانات الأداء، وبعض أفضل الممارسات الموصى بها لتحسين أداء النموذج.
إذا كنت تريد تحديد ملف تعريف أداء الطراز الخاص بك على وحدات TPU السحابية، فارجع إلى دليل Cloud TPU .
قم بتثبيت المتطلبات الأساسية لملف التعريف ووحدة معالجة الرسومات
قم بتثبيت البرنامج المساعد Profiler لـ TensorBoard باستخدام النقطة. لاحظ أن ملف التعريف يتطلب أحدث الإصدارات من TensorFlow وTensorBoard (>=2.2).
pip install -U tensorboard_plugin_profile
لإنشاء ملف تعريف على وحدة معالجة الرسومات، يجب عليك:
- تلبية برامج تشغيل NVIDIA® GPU ومتطلبات CUDA® Toolkit المدرجة في متطلبات برنامج دعم TensorFlow GPU .
تأكد من وجود واجهة أدوات التوصيف NVIDIA® CUDA® (CUPTI) على المسار:
/sbin/ldconfig -N -v $(sed 's/:/ /g' <<< $LD_LIBRARY_PATH) | \ grep libcupti
إذا لم يكن لديك CUPTI على المسار، قم بإضافة دليل التثبيت الخاص به إلى متغير البيئة $LD_LIBRARY_PATH عن طريق تشغيل:
export LD_LIBRARY_PATH=/usr/local/cuda/extras/CUPTI/lib64:$LD_LIBRARY_PATH
ثم قم بتشغيل الأمر ldconfig أعلاه مرة أخرى للتحقق من العثور على مكتبة CUPTI.
حل مشاكل الامتياز
عند تشغيل ملفات التعريف باستخدام CUDA® Toolkit في بيئة Docker أو على Linux، قد تواجه مشكلات تتعلق بامتيازات CUPTI غير الكافية ( CUPTI_ERROR_INSUFFICIENT_PRIVILEGES ). انتقل إلى NVIDIA Developer Docs لمعرفة المزيد حول كيفية حل هذه المشكلات على Linux.
لحل مشكلات امتياز CUPTI في بيئة Docker، قم بتشغيل
docker run option '--privileged=true'
أدوات التعريف
قم بالوصول إلى ملف التعريف من علامة التبويب ملف التعريف في TensorBoard، والتي تظهر فقط بعد التقاط بعض بيانات النموذج.
يحتوي ملف التعريف على مجموعة مختارة من الأدوات للمساعدة في تحليل الأداء:
- صفحة نظرة عامة
- محلل خط أنابيب الإدخال
- إحصائيات TensorFlow
- عارض التتبع
- إحصائيات نواة وحدة معالجة الرسومات
- أداة ملف تعريف الذاكرة
- عارض جراب
صفحة نظرة عامة
توفر صفحة النظرة العامة عرضًا عالي المستوى لكيفية أداء النموذج الخاص بك أثناء تشغيل ملف التعريف. تعرض لك الصفحة صفحة نظرة عامة مجمعة لمضيفك وجميع الأجهزة، وبعض التوصيات لتحسين أداء تدريب النموذج الخاص بك. يمكنك أيضًا تحديد مضيفين فرديين في القائمة المنسدلة للمضيف.
تعرض صفحة النظرة العامة البيانات كما يلي:
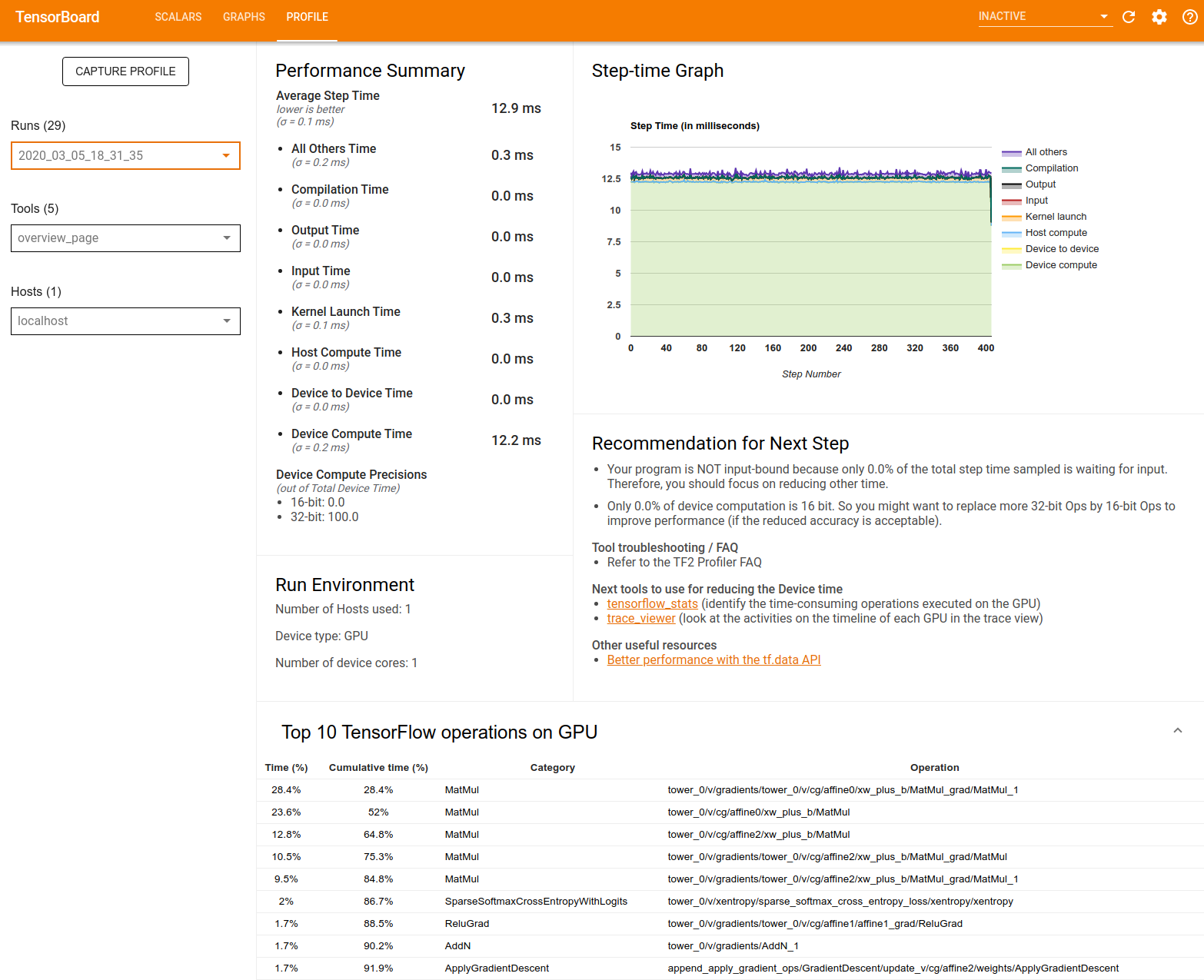
ملخص الأداء : يعرض ملخصًا عالي المستوى لأداء النموذج الخاص بك. يتكون ملخص الأداء من جزأين:
تفصيل وقت الخطوة: يقسم متوسط وقت الخطوة إلى فئات متعددة حيث يتم قضاء الوقت:
- التجميع: الوقت المستغرق في تجميع النوى.
- الإدخال: الوقت المستغرق في قراءة البيانات المدخلة.
- الإخراج: الوقت المستغرق في قراءة بيانات الإخراج.
- إطلاق النواة: الوقت الذي يقضيه المضيف في إطلاق النواة
- مضيف حساب الوقت ..
- وقت الاتصال من جهاز إلى جهاز.
- وقت الحساب على الجهاز.
- جميع الآخرين، بما في ذلك بيثون النفقات العامة.
دقة حساب الجهاز - يُبلغ عن النسبة المئوية لوقت حساب الجهاز الذي يستخدم حسابات 16 و32 بت.
الرسم البياني لوقت الخطوة : يعرض رسمًا بيانيًا لوقت خطوة الجهاز (بالمللي ثانية) على جميع الخطوات التي تم أخذ عينات منها. يتم تقسيم كل خطوة إلى فئات متعددة (بألوان مختلفة) حيث يتم قضاء الوقت. تتوافق المنطقة الحمراء مع الجزء من وقت الخطوة الذي كانت فيه الأجهزة في وضع الخمول في انتظار إدخال البيانات من المضيف. توضح المنطقة الخضراء مقدار الوقت الذي كان الجهاز يعمل فيه بالفعل.
أهم 10 عمليات TensorFlow على الجهاز (مثل وحدة معالجة الرسومات) : تعرض العمليات التي تتم على الجهاز والتي تم تشغيلها لفترة أطول.
يعرض كل صف الوقت الذاتي للعملية (كنسبة مئوية من الوقت الذي تستغرقه جميع العمليات)، والوقت التراكمي، والفئة، والاسم.
بيئة التشغيل : يعرض ملخصًا عالي المستوى لبيئة تشغيل النموذج بما في ذلك:
- عدد المضيفين المستخدمة
- نوع الجهاز (GPU/TPU).
- عدد نوى الجهاز.
توصية للخطوة التالية : الإبلاغ عندما يكون النموذج مرتبطًا بالإدخال ويوصي بالأدوات التي يمكنك استخدامها لتحديد موقع اختناقات أداء النموذج وحلها.
محلل خط أنابيب الإدخال
عندما يقرأ برنامج TensorFlow البيانات من ملف، فإنه يبدأ في الجزء العلوي من الرسم البياني TensorFlow بطريقة متصلة. تنقسم عملية القراءة إلى مراحل معالجة بيانات متعددة متصلة في سلسلة، حيث يكون ناتج مرحلة واحدة هو المدخل إلى المرحلة التالية. يُسمى نظام قراءة البيانات هذا بخط أنابيب الإدخال .
يحتوي المسار النموذجي لقراءة السجلات من الملفات على المراحل التالية:
- قراءة الملف.
- المعالجة المسبقة للملف (اختياري).
- نقل الملفات من المضيف إلى الجهاز.
يمكن أن يؤدي خط أنابيب الإدخال غير الفعال إلى إبطاء تطبيقك بشدة. يعتبر التطبيق مرتبطًا بالإدخال عندما يقضي جزءًا كبيرًا من الوقت في مسار الإدخال. استخدم الرؤى التي تم الحصول عليها من محلل خط أنابيب الإدخال لفهم الأماكن التي يكون فيها خط أنابيب الإدخال غير فعال.
يخبرك محلل مسار الإدخال على الفور ما إذا كان برنامجك مقيدًا بالإدخال ويرشدك خلال التحليل من جانب الجهاز والمضيف لتصحيح اختناقات الأداء في أي مرحلة في مسار الإدخال.
تحقق من الإرشادات الخاصة بأداء مسارات الإدخال للحصول على أفضل الممارسات الموصى بها لتحسين مسارات إدخال البيانات الخاصة بك.
لوحة معلومات خط أنابيب الإدخال
لفتح محلل مسار الإدخال، حدد ملف التعريف ، ثم حدد input_pipeline_analyzer من القائمة المنسدلة "الأدوات" .
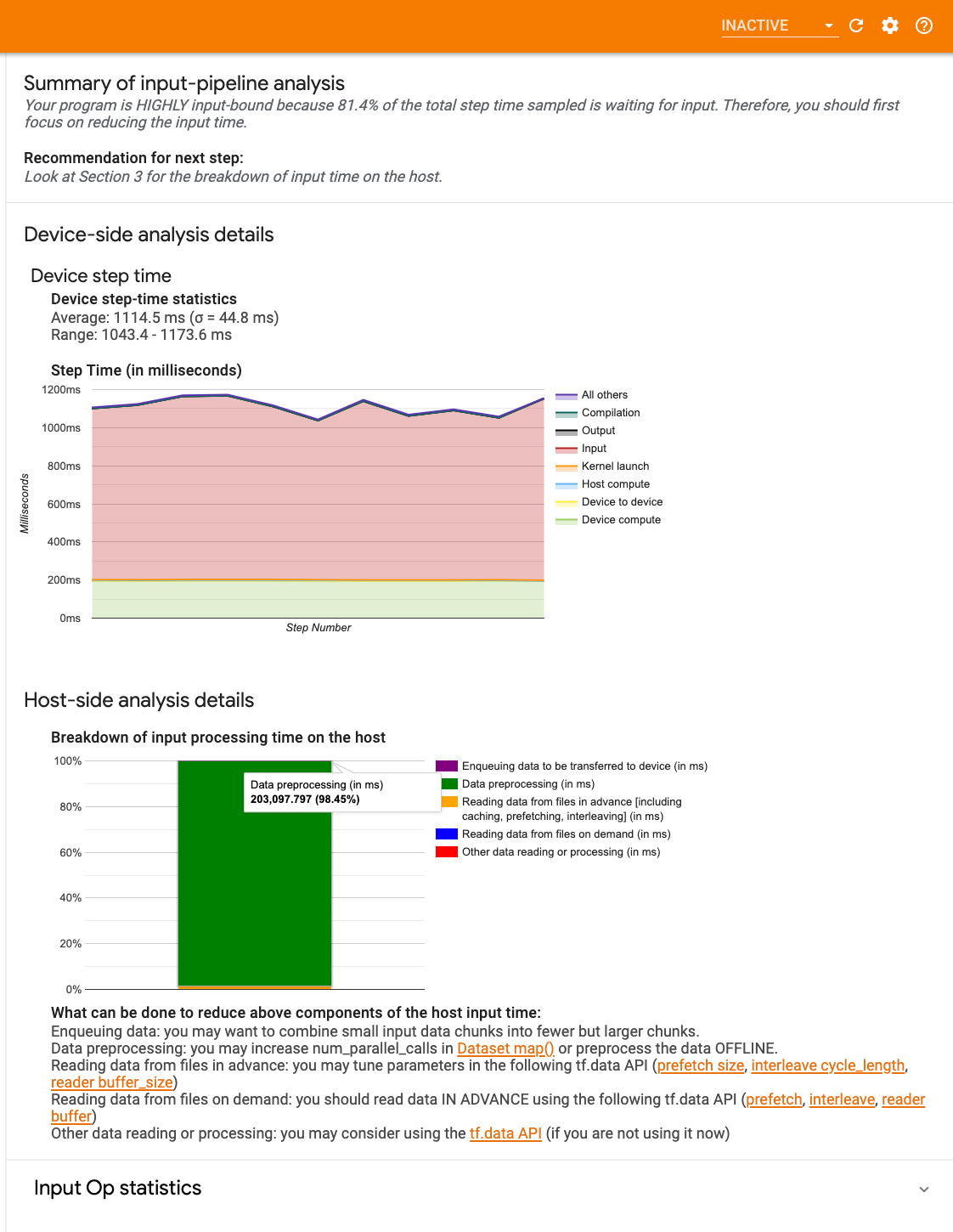
تحتوي لوحة التحكم على ثلاثة أقسام:
- الملخص : يلخص مسار الإدخال الإجمالي بمعلومات حول ما إذا كان تطبيقك مرتبطًا بالإدخال، وإذا كان الأمر كذلك، فبأي مقدار.
- التحليل على جانب الجهاز : يعرض نتائج التحليل التفصيلية على جانب الجهاز، بما في ذلك وقت خطوة الجهاز ونطاق الوقت الذي يقضيه الجهاز في انتظار بيانات الإدخال عبر النوى في كل خطوة.
- التحليل من جانب المضيف : يعرض تحليلاً تفصيليًا من جانب المضيف، بما في ذلك تفاصيل وقت معالجة الإدخال على المضيف.
ملخص خط الإدخال
يُبلغ الملخص عما إذا كان برنامجك مقيدًا بالإدخال من خلال عرض النسبة المئوية لوقت الجهاز الذي يقضيه في انتظار الإدخال من المضيف. إذا كنت تستخدم مسار إدخال قياسي تم تجهيزه، فستقوم الأداة بالإبلاغ عن المكان الذي تم قضاء معظم وقت معالجة الإدخال فيه.
تحليل جانب الجهاز
يوفر التحليل من جانب الجهاز رؤى حول الوقت الذي يقضيه على الجهاز مقابل المضيف ومقدار الوقت الذي يقضيه الجهاز في انتظار بيانات الإدخال من المضيف.
- وقت الخطوة المرسوم مقابل رقم الخطوة : يعرض رسمًا بيانيًا لوقت خطوة الجهاز (بالملي ثانية) على جميع الخطوات التي تم أخذ عينات منها. يتم تقسيم كل خطوة إلى فئات متعددة (بألوان مختلفة) حيث يتم قضاء الوقت. تتوافق المنطقة الحمراء مع الجزء من وقت الخطوة الذي كانت فيه الأجهزة في وضع الخمول في انتظار إدخال البيانات من المضيف. توضح المنطقة الخضراء مقدار الوقت الذي كان فيه الجهاز يعمل فعليًا.
- إحصائيات وقت الخطوة : يُبلغ عن المتوسط والانحراف المعياري والنطاق ([الحد الأدنى والحد الأقصى]) لوقت خطوة الجهاز.
تحليل الجانب المضيف
يُبلغ التحليل من جانب المضيف عن تفاصيل وقت معالجة الإدخال (الوقت المستغرق في عمليات tf.data API) على المضيف إلى عدة فئات:
- قراءة البيانات من الملفات حسب الطلب : الوقت المستغرق في قراءة البيانات من الملفات دون التخزين المؤقت والجلب المسبق والتشذير.
- قراءة البيانات من الملفات مقدمًا : الوقت المستغرق في قراءة الملفات، بما في ذلك التخزين المؤقت والجلب المسبق والتشذير.
- المعالجة المسبقة للبيانات : الوقت المستغرق في عمليات المعالجة المسبقة، مثل ضغط الصور.
- وضع البيانات في قائمة الانتظار ليتم نقلها إلى الجهاز : الوقت المستغرق في وضع البيانات في قائمة انتظار التغذية قبل نقل البيانات إلى الجهاز.
قم بتوسيع إحصائيات عمليات الإدخال لفحص إحصائيات عمليات الإدخال الفردية وفئاتها مقسمة حسب وقت التنفيذ.
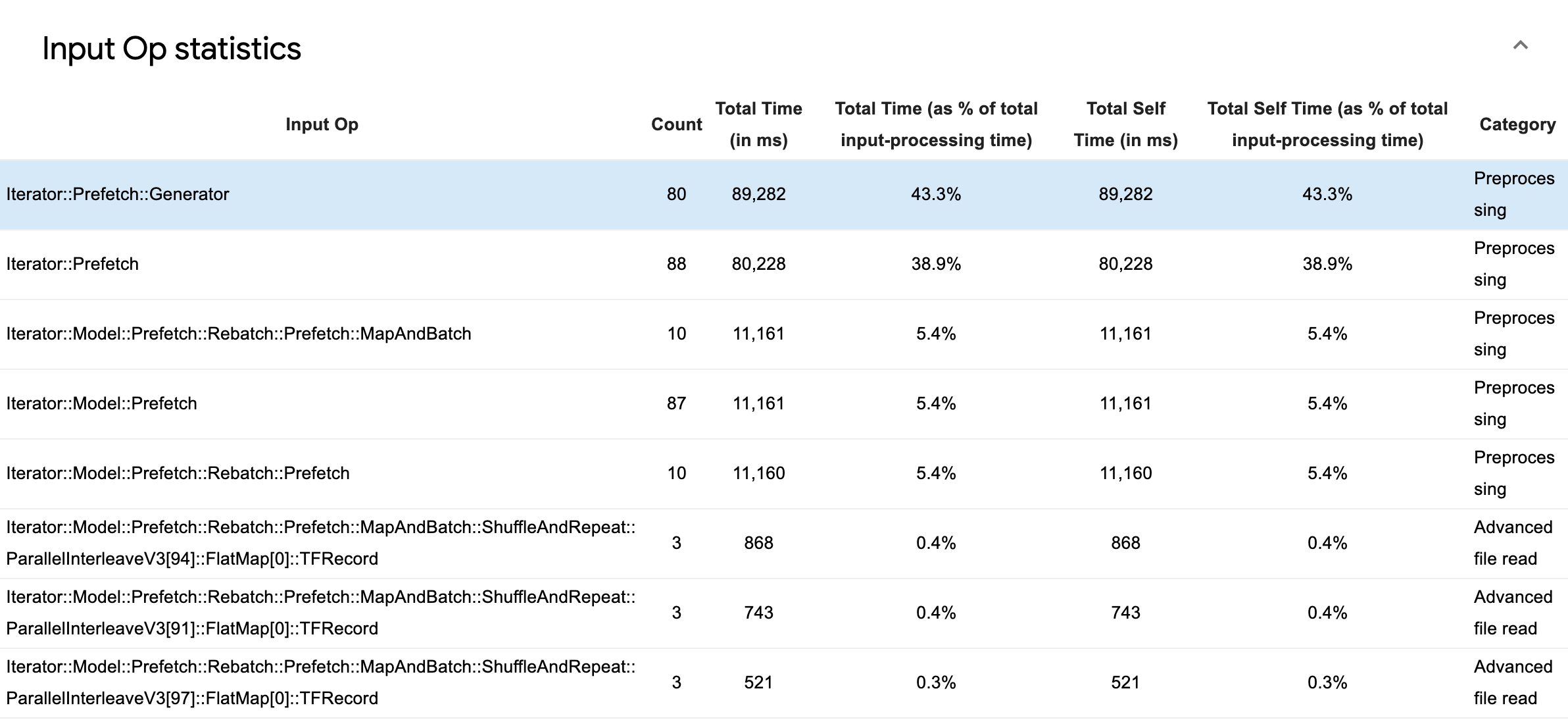
سيظهر جدول بيانات المصدر مع كل إدخال يحتوي على المعلومات التالية:
- Input Op : يعرض اسم TensorFlow op الخاص بعملية الإدخال.
- العدد : يعرض العدد الإجمالي لمثيلات تنفيذ العملية خلال فترة التوصيف.
- إجمالي الوقت (بالمللي ثانية) : يعرض المجموع التراكمي للوقت المنقضي في كل من هذه الحالات.
- إجمالي الوقت % : يُظهر إجمالي الوقت المستغرق في عملية ما كجزء صغير من إجمالي الوقت المستغرق في معالجة الإدخال.
- إجمالي الوقت الذاتي (بالمللي ثانية) : يعرض المجموع التراكمي للوقت الذاتي المنقضي في كل من هذه الحالات. يقيس الوقت الذاتي هنا الوقت الذي يقضيه داخل جسم الوظيفة، باستثناء الوقت الذي يقضيه في الوظيفة التي تستدعيها.
- إجمالي الوقت الذاتي % . يُظهر إجمالي الوقت الذاتي كجزء صغير من إجمالي الوقت المنقضي في معالجة المدخلات.
- فئة . يُظهر فئة معالجة عملية الإدخال.
إحصائيات TensorFlow
تعرض أداة TensorFlow Stats أداء كل عملية TensorFlow (op) يتم تنفيذها على المضيف أو الجهاز أثناء جلسة التوصيف.
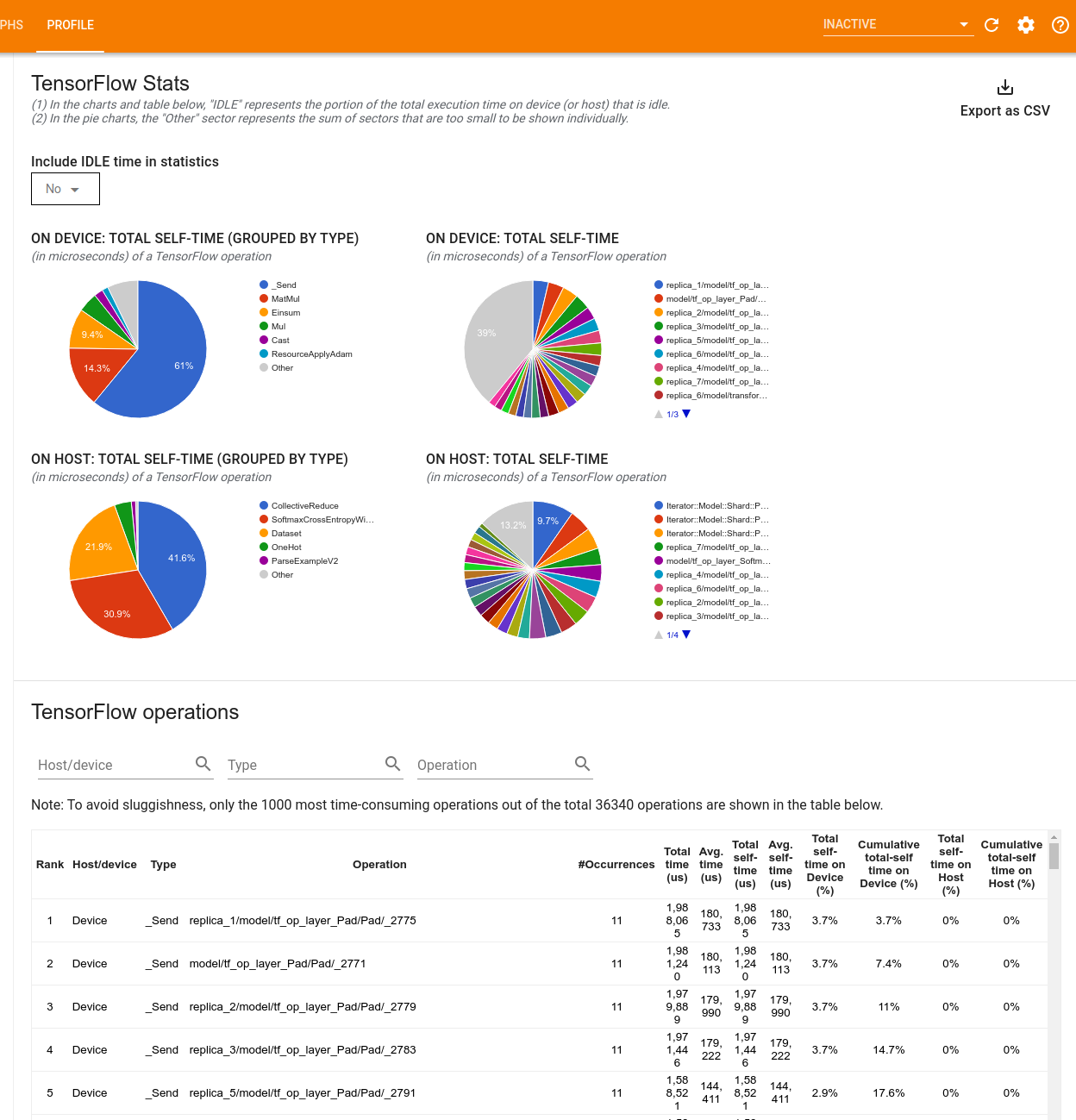
تعرض الأداة معلومات الأداء في جزأين:
يعرض الجزء العلوي ما يصل إلى أربعة مخططات دائرية:
- توزيع وقت التنفيذ الذاتي لكل عملية على المضيف.
- توزيع وقت التنفيذ الذاتي لكل نوع من العمليات على المضيف.
- توزيع زمن التنفيذ الذاتي لكل عملية على الجهاز.
- توزيع زمن التنفيذ الذاتي لكل نوع من العمليات على الجهاز.
يعرض الجزء السفلي جدولًا يُبلغ عن بيانات حول عمليات TensorFlow مع صف واحد لكل عملية وعمود واحد لكل نوع من البيانات (افرز الأعمدة بالنقر فوق عنوان العمود). انقر فوق الزر تصدير كملف CSV على الجانب الأيمن من الجزء العلوي لتصدير البيانات من هذا الجدول كملف CSV.
لاحظ أن:
إذا كانت هناك أي عمليات لها عمليات فرعية:
- يشمل إجمالي الوقت "التراكمي" للعملية الوقت الذي يقضيه داخل العمليات الفرعية.
- إجمالي الوقت "الذاتي" للعملية لا يشمل الوقت الذي يقضيه داخل العمليات الفرعية.
في حالة تنفيذ عملية على المضيف:
- ستكون النسبة المئوية لإجمالي الوقت الذاتي الذي يقضيه الجهاز أثناء العملية هي 0.
- ستكون النسبة المئوية التراكمية لإجمالي الوقت الذاتي على الجهاز حتى هذه العملية متضمنة 0.
في حالة تنفيذ عملية على الجهاز:
- ستكون النسبة المئوية لإجمالي الوقت الذاتي الذي يقضيه المضيف بسبب هذه العملية 0.
- ستكون النسبة المئوية التراكمية لإجمالي الوقت الذاتي على المضيف حتى هذه العملية متضمنة 0.
يمكنك اختيار تضمين وقت الخمول أو استبعاده في المخططات الدائرية والجدول.
تتبع المشاهد
يعرض عارض التتبع مخططًا زمنيًا يعرض:
- فترات العمليات التي تم تنفيذها بواسطة نموذج TensorFlow الخاص بك
- أي جزء من النظام (المضيف أو الجهاز) قام بتنفيذ العملية. عادةً، ينفذ المضيف عمليات الإدخال، ويعالج بيانات التدريب مسبقًا وينقلها إلى الجهاز، بينما ينفذ الجهاز تدريب النموذج الفعلي
يتيح لك عارض التتبع تحديد مشكلات الأداء في النموذج الخاص بك، ثم اتخاذ الخطوات اللازمة لحلها. على سبيل المثال، على مستوى عالٍ، يمكنك تحديد ما إذا كان التدريب على المدخلات أو النموذج يستغرق معظم الوقت. وبالتعمق أكثر، يمكنك تحديد العمليات التي تستغرق وقتًا أطول في تنفيذها. لاحظ أن عارض التتبع يقتصر على مليون حدث لكل جهاز.
تتبع واجهة المشاهد
عند فتح عارض التتبع، يظهر وهو يعرض أحدث عملية تشغيل قمت بها:
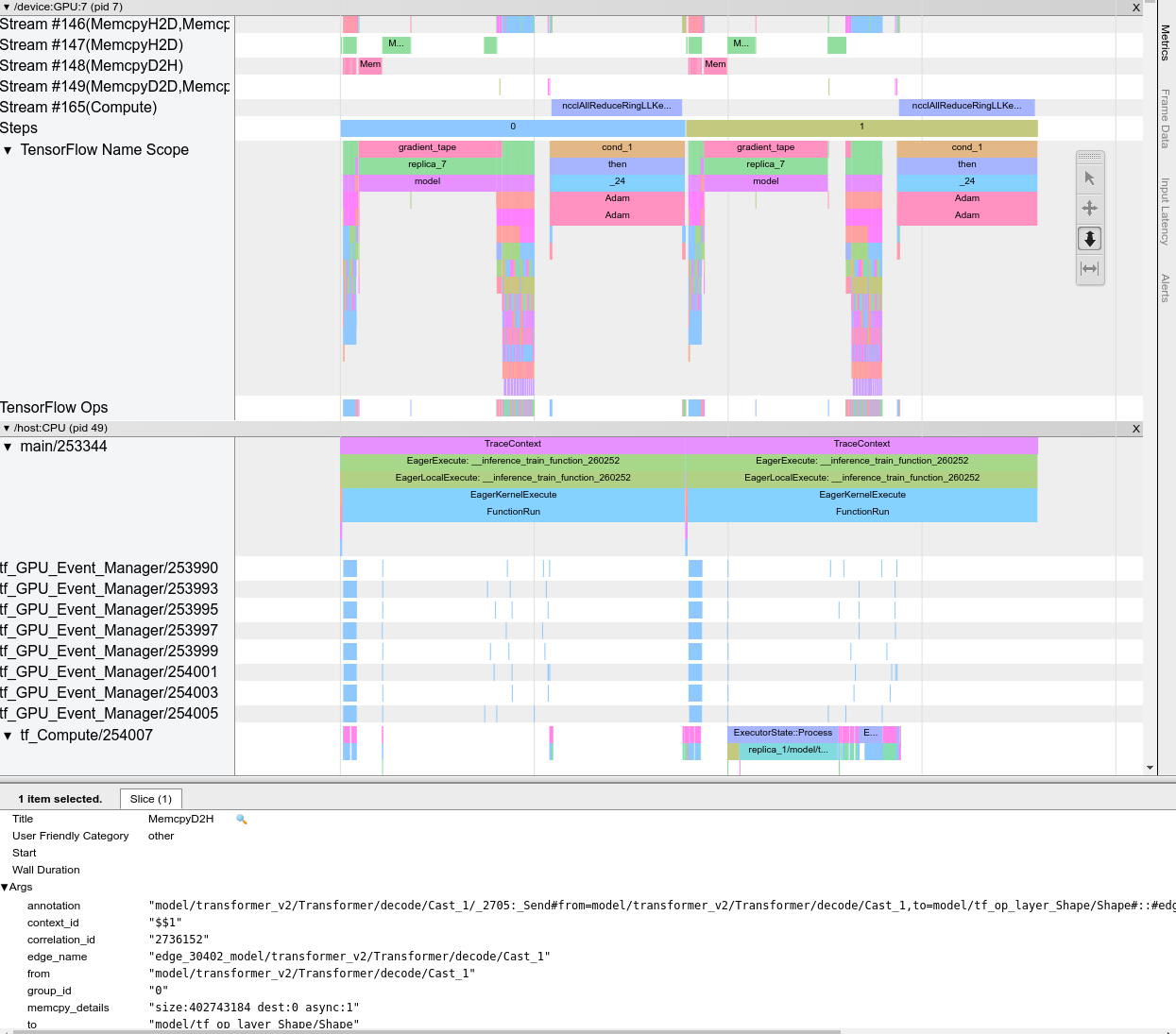
تحتوي هذه الشاشة على العناصر الرئيسية التالية:
- جزء المخطط الزمني : يعرض العمليات التي نفذها الجهاز والمضيف بمرور الوقت.
- جزء التفاصيل : يعرض معلومات إضافية للعمليات المحددة في جزء المخطط الزمني.
يحتوي جزء المخطط الزمني على العناصر التالية:
- الشريط العلوي : يحتوي على عناصر تحكم مساعدة مختلفة.
- محور الوقت : يعرض الوقت بالنسبة لبداية التتبع.
- تسميات الأقسام والمسارات : يحتوي كل قسم على مسارات متعددة ويحتوي على مثلث على اليسار يمكنك النقر فوقه لتوسيع القسم وطيه. يوجد قسم واحد لكل عنصر معالجة في النظام.
- محدد الأدوات : يحتوي على أدوات متنوعة للتفاعل مع عارض التتبع مثل التكبير/التصغير والتحريك والتحديد والتوقيت. استخدم أداة التوقيت لتحديد الفاصل الزمني.
- الأحداث : تعرض الوقت الذي تم خلاله تنفيذ العملية أو مدة الأحداث الوصفية، مثل خطوات التدريب.
الأقسام والمسارات
يحتوي عارض التتبع على الأقسام التالية:
- قسم واحد لكل عقدة جهاز ، معنون برقم شريحة الجهاز وعقدة الجهاز داخل الشريحة (على سبيل المثال،
/device:GPU:0 (pid 0)). يحتوي كل قسم من عقدة الجهاز على المسارات التالية:- الخطوة : تظهر مدة خطوات التدريب التي كانت تعمل على الجهاز
- TensorFlow Ops : يعرض العمليات التي تم تنفيذها على الجهاز
- XLA Ops : يعرض عمليات XLA (ops) التي تم تشغيلها على الجهاز إذا كان XLA هو المترجم المستخدم (تتم ترجمة كل عملية TensorFlow إلى عملية واحدة أو أكثر من عمليات XLA. يقوم مترجم XLA بترجمة عمليات XLA إلى كود يتم تشغيله على الجهاز).
- قسم واحد للخيوط التي تعمل على وحدة المعالجة المركزية للجهاز المضيف، يسمى "Host Threads" . يحتوي القسم على مسار واحد لكل مؤشر ترابط وحدة المعالجة المركزية. لاحظ أنه يمكنك تجاهل المعلومات المعروضة بجانب تسميات الأقسام.
الأحداث
يتم عرض الأحداث ضمن المخطط الزمني بألوان مختلفة؛ الألوان نفسها ليس لها معنى محدد.
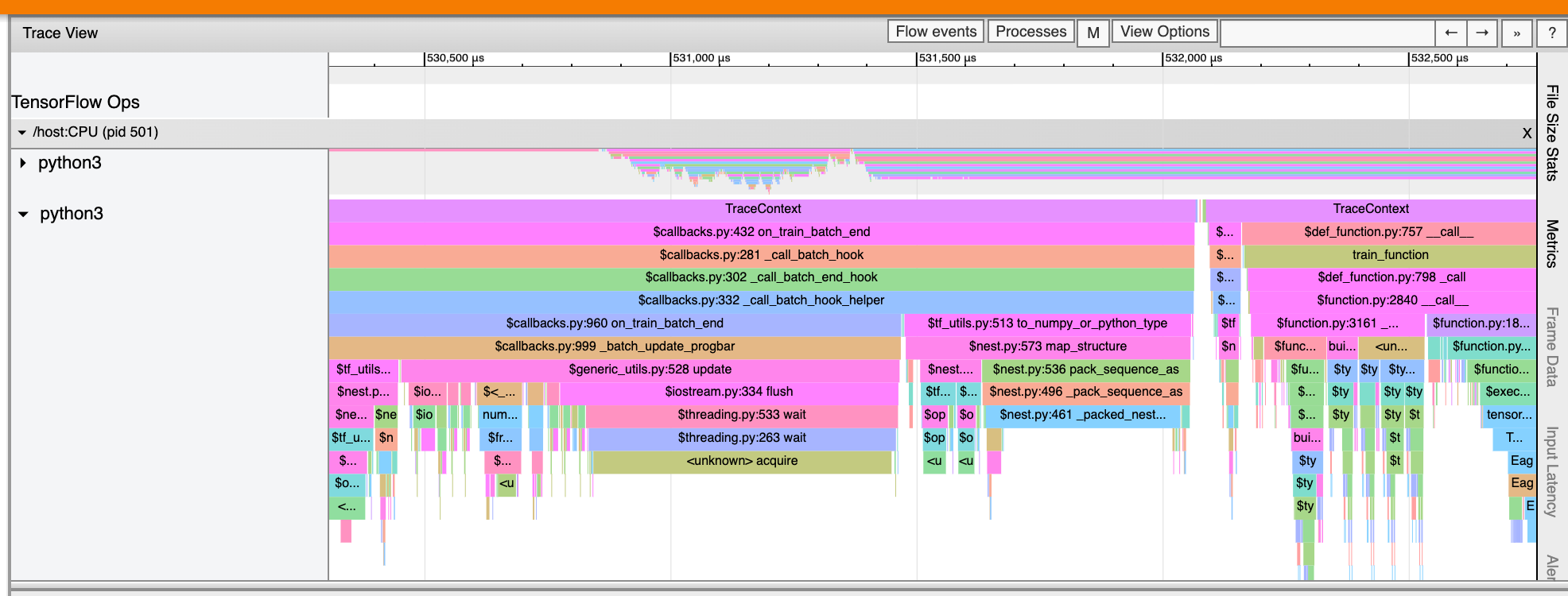
يمكن لعارض التتبع أيضًا عرض آثار استدعاءات دالة Python في برنامج TensorFlow الخاص بك. إذا كنت تستخدم واجهة برمجة التطبيقات tf.profiler.experimental.start ، فيمكنك تمكين تتبع Python باستخدام ProfilerOptions المسمىtuple عند بدء التوصيف. وبدلاً من ذلك، إذا كنت تستخدم وضع أخذ العينات لملف التعريف، فيمكنك تحديد مستوى التتبع باستخدام خيارات القائمة المنسدلة في مربع حوار ملف تعريف الالتقاط .
إحصائيات نواة GPU
تعرض هذه الأداة إحصائيات الأداء والعملية الأصلية لكل نواة مسرعة لوحدة معالجة الرسومات.
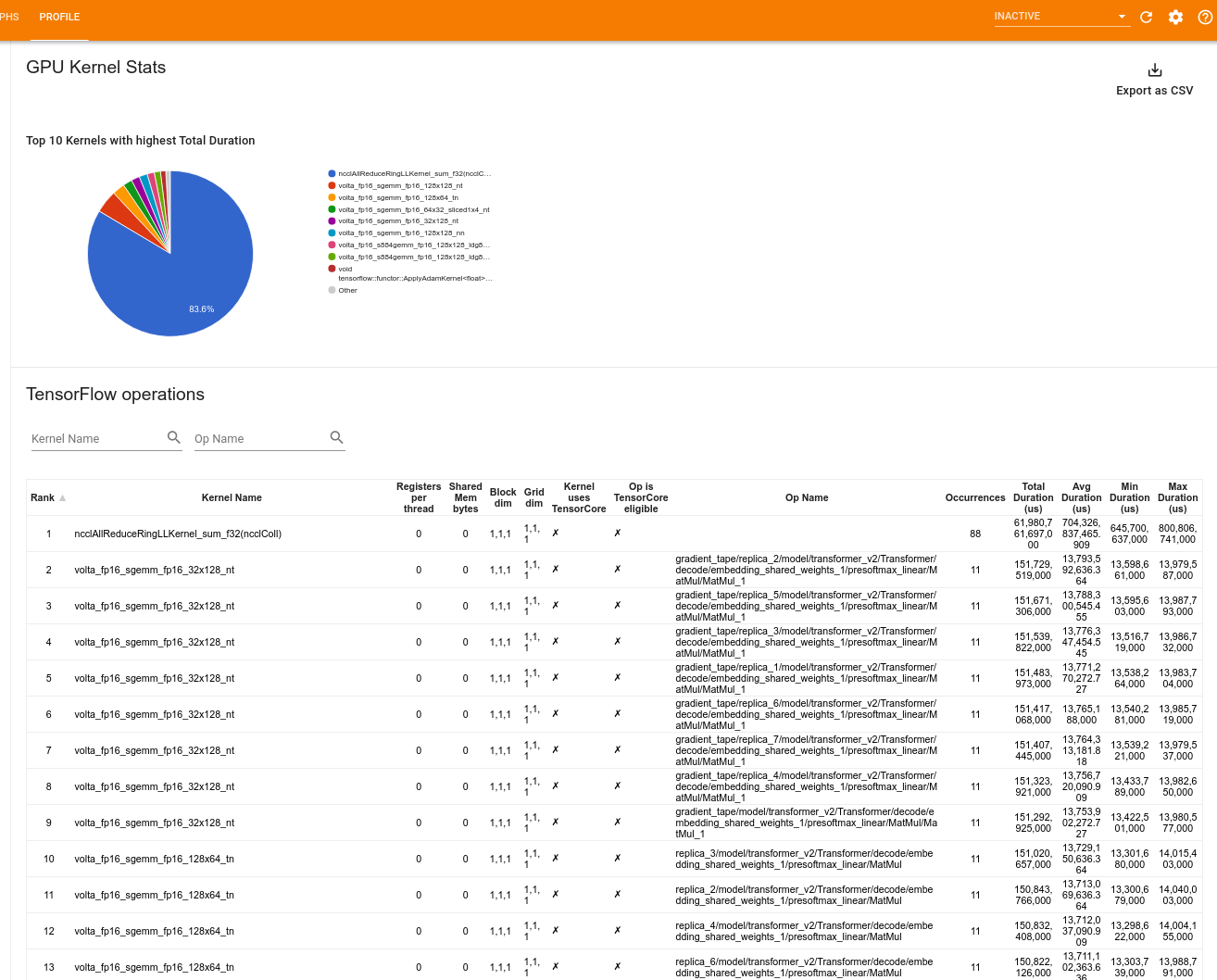
تعرض الأداة المعلومات في جزأين:
يعرض الجزء العلوي مخططًا دائريًا يُظهر حبات CUDA التي لديها أعلى إجمالي وقت منقضي.
يعرض الجزء السفلي جدولاً يحتوي على البيانات التالية لكل زوج فريد من عمليات kernel:
- ترتيب تنازلي لإجمالي المدة المنقضية لوحدة معالجة الرسومات مجمعة حسب زوج kernel-op.
- اسم النواة التي تم إطلاقها.
- عدد سجلات GPU التي تستخدمها النواة.
- الحجم الإجمالي للذاكرة المشتركة (الثابتة + الديناميكية المشتركة) المستخدمة بالبايت.
- بُعد الكتلة المعبر عنه بـ
blockDim.x, blockDim.y, blockDim.z. - يتم التعبير عن أبعاد الشبكة كـ
gridDim.x, gridDim.y, gridDim.z. - ما إذا كان المرجع مؤهلاً لاستخدام Tensor Cores .
- ما إذا كانت النواة تحتوي على تعليمات Tensor Core.
- اسم العملية التي أطلقت هذه النواة.
- عدد مرات ظهور زوج kernel-op هذا.
- إجمالي الوقت المنقضي لوحدة معالجة الرسومات بالميكروثانية.
- متوسط الوقت المنقضي لوحدة معالجة الرسومات بالميكروثانية.
- الحد الأدنى لوقت GPU المنقضي بالميكروثانية.
- الحد الأقصى لوقت GPU المنقضي بالميكروثانية.
أداة ملف تعريف الذاكرة
تقوم أداة ملف تعريف الذاكرة بمراقبة استخدام ذاكرة جهازك أثناء الفاصل الزمني للتوصيف. يمكنك استخدام هذه الأداة من أجل:
- تصحيح مشكلات نفاد الذاكرة (OOM) من خلال تحديد ذروة استخدام الذاكرة وتخصيص الذاكرة المقابل لعمليات TensorFlow. يمكنك أيضًا تصحيح مشكلات OOM التي قد تنشأ عند تشغيل الاستدلال متعدد الإيجارات .
- تصحيح مشكلات تجزئة الذاكرة.
تعرض أداة ملف تعريف الذاكرة البيانات في ثلاثة أقسام:
- ملخص ملف تعريف الذاكرة
- الرسم البياني للخط الزمني للذاكرة
- جدول انهيار الذاكرة
ملخص ملف تعريف الذاكرة
يعرض هذا القسم ملخصًا عالي المستوى لملف تعريف الذاكرة لبرنامج TensorFlow الخاص بك كما هو موضح أدناه:
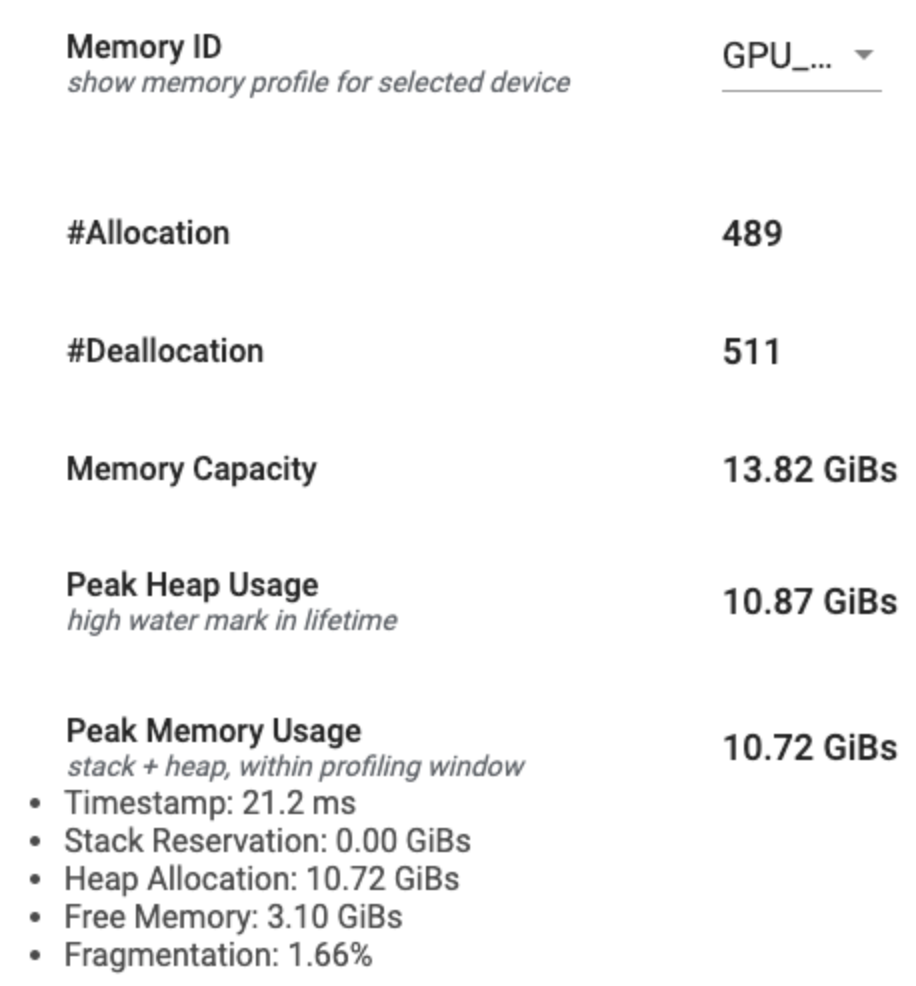
يحتوي ملخص ملف تعريف الذاكرة على ستة حقول:
- معرف الذاكرة : القائمة المنسدلة التي تسرد جميع أنظمة ذاكرة الجهاز المتوفرة. حدد نظام الذاكرة الذي تريد عرضه من القائمة المنسدلة.
- #Allocation : عدد عمليات تخصيص الذاكرة التي تم إجراؤها أثناء الفاصل الزمني للتوصيف.
- #Deallocation : عدد عمليات إلغاء تخصيص الذاكرة في الفاصل الزمني للتوصيف
- سعة الذاكرة : السعة الإجمالية (بالجيجابايت) لنظام الذاكرة الذي تحدده.
- ذروة استخدام الكومة : ذروة استخدام الذاكرة (بالجيجابايت) منذ بدء تشغيل النموذج.
- ذروة استخدام الذاكرة : ذروة استخدام الذاكرة (بالجيجابايت) في الفاصل الزمني للتوصيف. يحتوي هذا الحقل على الحقول الفرعية التالية:
- الطابع الزمني : الطابع الزمني للوقت الذي حدث فيه استخدام الذاكرة الأقصى على الرسم البياني للخط الزمني.
- حجز المكدس : مقدار الذاكرة المحجوزة على المكدس (بالجيجابايت).
- تخصيص الكومة : مقدار الذاكرة المخصصة في الكومة (بالجيجابايت).
- الذاكرة الحرة : مقدار الذاكرة الحرة (بالجيجابايت). سعة الذاكرة هي مجموع حجز المكدس وتخصيص الكومة والذاكرة الحرة.
- التجزئة : نسبة التجزئة (الأقل هو الأفضل). ويتم حسابها كنسبة مئوية من
(1 - Size of the largest chunk of free memory / Total free memory).
الرسم البياني للخط الزمني للذاكرة
يعرض هذا القسم مخططًا لاستخدام الذاكرة (بالجيجابايت) والنسبة المئوية للتجزئة مقابل الوقت (بالمللي ثانية).
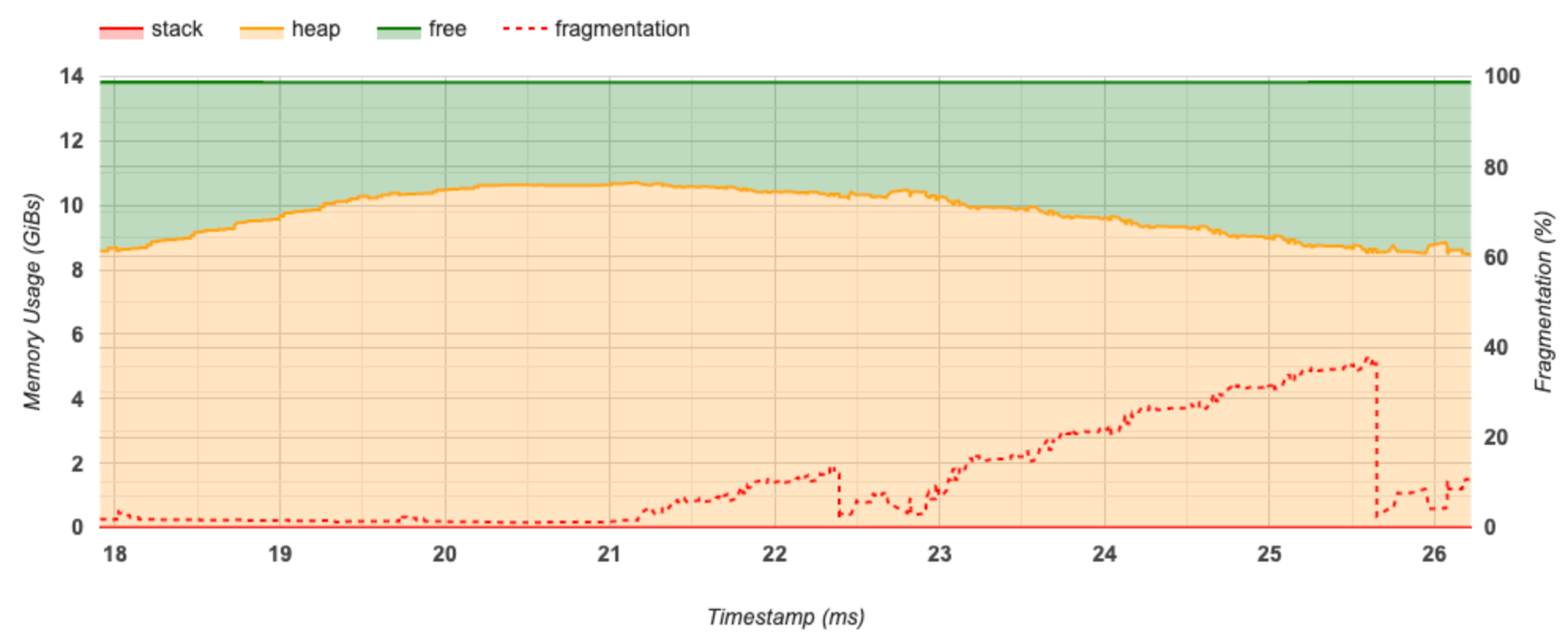
يمثل المحور السيني الجدول الزمني (بالمللي ثانية) للفاصل الزمني للتوصيف. يمثل المحور Y الموجود على اليسار استخدام الذاكرة (بالجيجابايت) ويمثل المحور Y الموجود على اليمين النسبة المئوية للتجزئة. في كل نقطة زمنية على المحور السيني، يتم تقسيم الذاكرة الإجمالية إلى ثلاث فئات: المكدس (باللون الأحمر)، والكومة (باللون البرتقالي)، والمجانية (باللون الأخضر). قم بالتمرير فوق طابع زمني محدد لعرض التفاصيل حول أحداث تخصيص/إلغاء تخصيص الذاكرة في تلك المرحلة كما هو موضح أدناه:
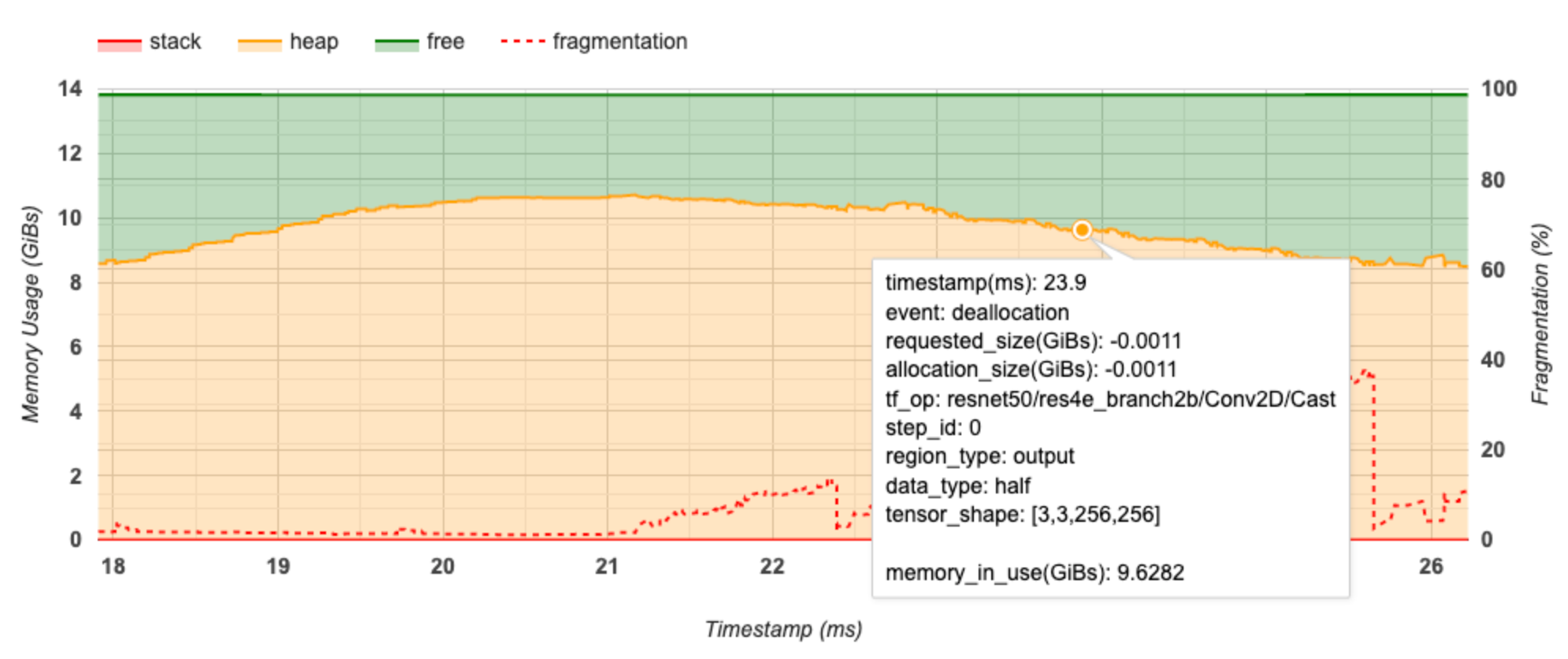
تعرض النافذة المنبثقة المعلومات التالية:
- الطابع الزمني (مللي ثانية) : موقع الحدث المحدد على المخطط الزمني.
- الحدث : نوع الحدث (تخصيص أو إلغاء تخصيص).
- request_size(GiBs) : مقدار الذاكرة المطلوبة. سيكون هذا رقمًا سالبًا لأحداث إلغاء التخصيص.
- تخصيص_الحجم (GiBs) : المقدار الفعلي للذاكرة المخصصة. سيكون هذا رقمًا سالبًا لأحداث إلغاء التخصيص.
- tf_op : عملية TensorFlow التي تطلب التخصيص/إلغاء التخصيص.
- step_id : خطوة التدريب التي وقع فيها هذا الحدث.
- Region_type : نوع كيان البيانات المخصص لهذه الذاكرة المخصصة. القيم المحتملة هي
tempللمؤقتات،outputللتنشيط والتدرجات،persist/dynamicللأوزان والثوابت. - data_type : نوع عنصر الموتر (على سبيل المثال، uint8 لعدد صحيح غير موقّع ذو 8 بت).
- Tensor_shape : شكل الموتر الذي يتم تخصيصه/إلغاء تخصيصه.
- Memory_in_use(GiBs) : إجمالي الذاكرة المستخدمة في هذا الوقت.
جدول انهيار الذاكرة
يوضح هذا الجدول عمليات تخصيص الذاكرة النشطة عند نقطة استخدام الذاكرة القصوى في الفاصل الزمني للتوصيف.
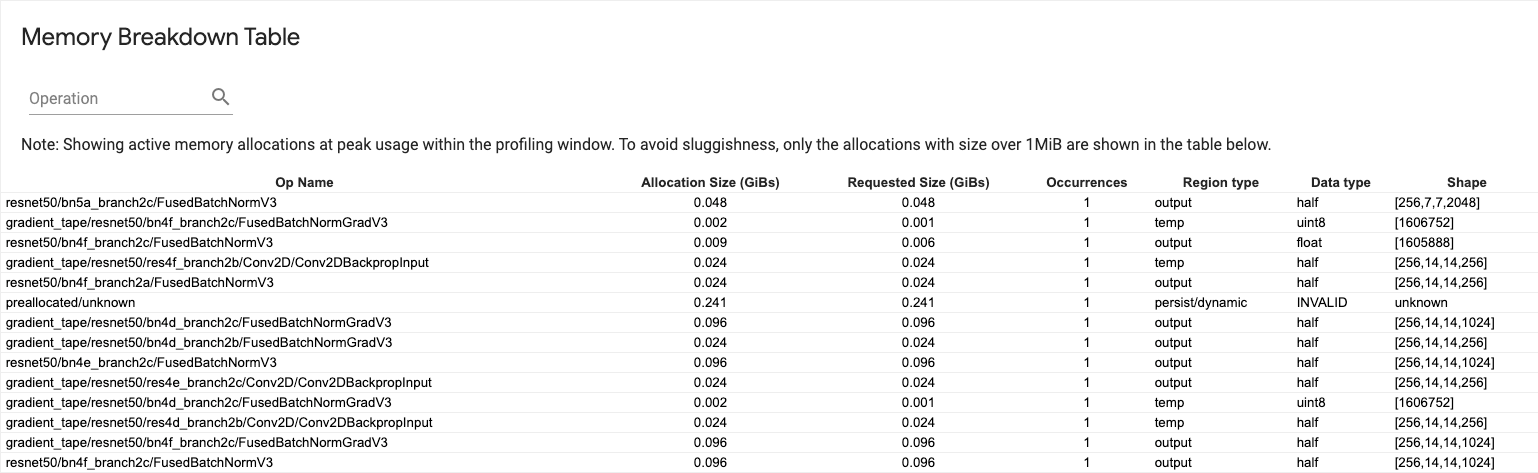
يوجد صف واحد لكل TensorFlow Op وكل صف يحتوي على الأعمدة التالية:
- اسم العملية : اسم عملية TensorFlow.
- حجم التخصيص (GiBs) : إجمالي مقدار الذاكرة المخصصة لهذه العملية.
- الحجم المطلوب (GiBs) : إجمالي مقدار الذاكرة المطلوبة لهذه العملية.
- التكرارات : عدد التخصيصات لهذا المرجع.
- نوع المنطقة : نوع كيان البيانات المخصص لهذه الذاكرة المخصصة. القيم المحتملة هي
tempللمؤقتات،outputللتنشيط والتدرجات،persist/dynamicللأوزان والثوابت. - نوع البيانات : نوع عنصر الموتر.
- الشكل : شكل الموترات المخصصة.
عارض جراب
تُظهر أداة Pod Viewer تفاصيل خطوة التدريب لجميع العاملين.
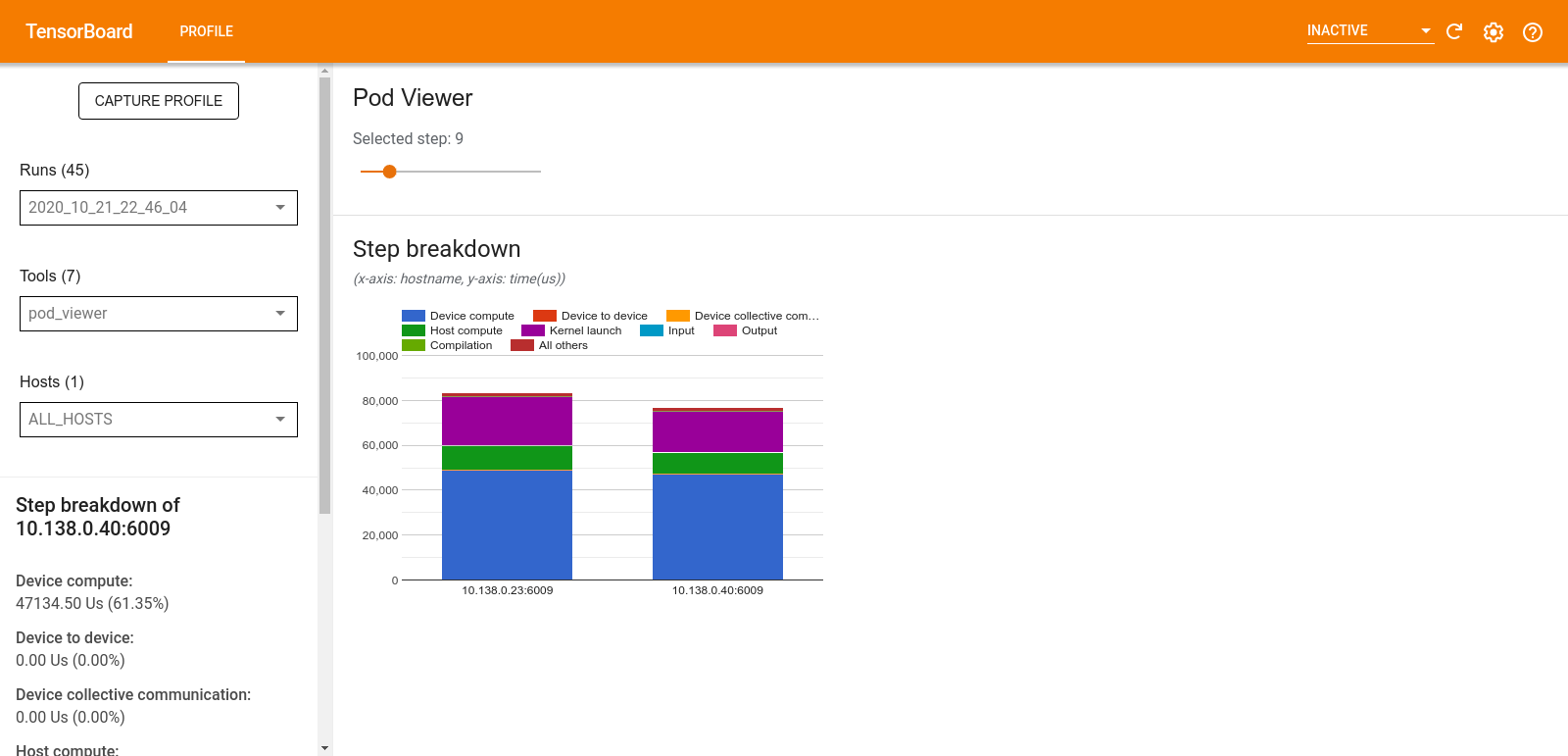
- يحتوي الجزء العلوي على شريط تمرير لتحديد رقم الخطوة.
- يعرض الجزء السفلي مخططًا عموديًا مكدسًا. هذا عرض عالي المستوى لفئات وقت الخطوة المقسمة الموضوعة فوق بعضها البعض. يمثل كل عمود مكدس عاملاً فريدًا.
- عندما تقوم بالتمرير فوق عمود مكدس، تعرض البطاقة الموجودة على الجانب الأيسر مزيدًا من التفاصيل حول تفاصيل الخطوات.
تحليل عنق الزجاجة tf.data
تكتشف أداة تحليل اختناقات tf.data تلقائيًا الاختناقات في مسارات إدخال tf.data في برنامجك وتقدم توصيات حول كيفية إصلاحها. يعمل مع أي برنامج يستخدم tf.data بغض النظر عن النظام الأساسي (CPU/GPU/TPU). ويستند تحليلها وتوصياتها على هذا الدليل .
يكتشف عنق الزجاجة باتباع الخطوات التالية:
- ابحث عن المضيف الأكثر تقييدًا للإدخال.
- ابحث عن أبطأ تنفيذ لخط أنابيب إدخال
tf.data. - إعادة بناء الرسم البياني لخط أنابيب الإدخال من تتبع ملف التعريف.
- ابحث عن المسار الحرج في الرسم البياني لخط أنابيب الإدخال.
- تحديد أبطأ تحويل على المسار الحرج باعتباره عنق الزجاجة.
تنقسم واجهة المستخدم إلى ثلاثة أقسام: ملخص تحليل الأداء ، وملخص جميع خطوط الإدخال ، والرسم البياني لخطوط الإدخال .
ملخص تحليل الأداء

يقدم هذا القسم ملخص التحليل. يقوم بالإبلاغ عن خطوط أنابيب إدخال tf.data البطيئة التي تم اكتشافها في الملف الشخصي. يعرض هذا القسم أيضًا المضيف الأكثر ارتباطًا بالإدخال وأبطأ خط إدخال له مع الحد الأقصى لزمن الاستجابة. والأهم من ذلك، أنه يحدد أي جزء من خط أنابيب الإدخال يمثل عنق الزجاجة وكيفية إصلاحه. يتم توفير معلومات عنق الزجاجة مع نوع المكرر واسمه الطويل.
كيفية قراءة الاسم الطويل لمكرر tf.data
يتم تنسيق الاسم الطويل كـ Iterator::<Dataset_1>::...::<Dataset_n> . في الاسم الطويل، يطابق <Dataset_n> نوع المكرر وتمثل مجموعات البيانات الأخرى في الاسم الطويل التحويلات النهائية.
على سبيل المثال، خذ بعين الاعتبار مجموعة بيانات خط أنابيب الإدخال التالية:
dataset = tf.data.Dataset.range(10).map(lambda x: x).repeat(2).batch(5)
الأسماء الطويلة للمكررات من مجموعة البيانات أعلاه ستكون:
| نوع التكرار | الاسم الطويل |
|---|---|
| يتراوح | التكرار::Batch::Repeat::Map::Range |
| رسم خريطة | المكرر :: الدفعة :: كرر :: الخريطة |
| يكرر | التكرار :: الدفعة :: كرر |
| حزمة | التكرار::دفعة |
ملخص لجميع خطوط أنابيب الإدخال
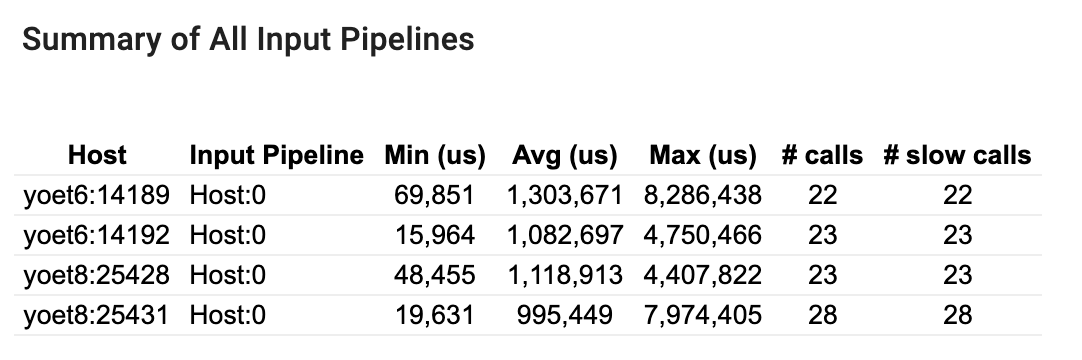
يقدم هذا القسم ملخصًا لجميع مسارات الإدخال عبر جميع الأجهزة المضيفة. عادةً ما يكون هناك خط أنابيب إدخال واحد. عند استخدام استراتيجية التوزيع، يوجد خط أنابيب إدخال مضيف واحد يقوم بتشغيل كود tf.data الخاص بالبرنامج وخطوط أنابيب إدخال متعددة للأجهزة تقوم باسترداد البيانات من خط أنابيب إدخال المضيف ونقلها إلى الأجهزة.
لكل خط أنابيب إدخال، يعرض إحصائيات وقت التنفيذ. يتم احتساب المكالمة على أنها بطيئة إذا استغرقت أكثر من 50 ميكروثانية.
الرسم البياني لخط أنابيب الإدخال

يعرض هذا القسم الرسم البياني لخط أنابيب الإدخال مع معلومات وقت التنفيذ. يمكنك استخدام "المضيف" و"خط أنابيب الإدخال" لاختيار المضيف وخط أنابيب الإدخال الذي تريد رؤيته. يتم فرز عمليات تنفيذ مسار الإدخال حسب وقت التنفيذ بترتيب تنازلي يمكنك اختياره باستخدام القائمة المنسدلة "التصنيف" .
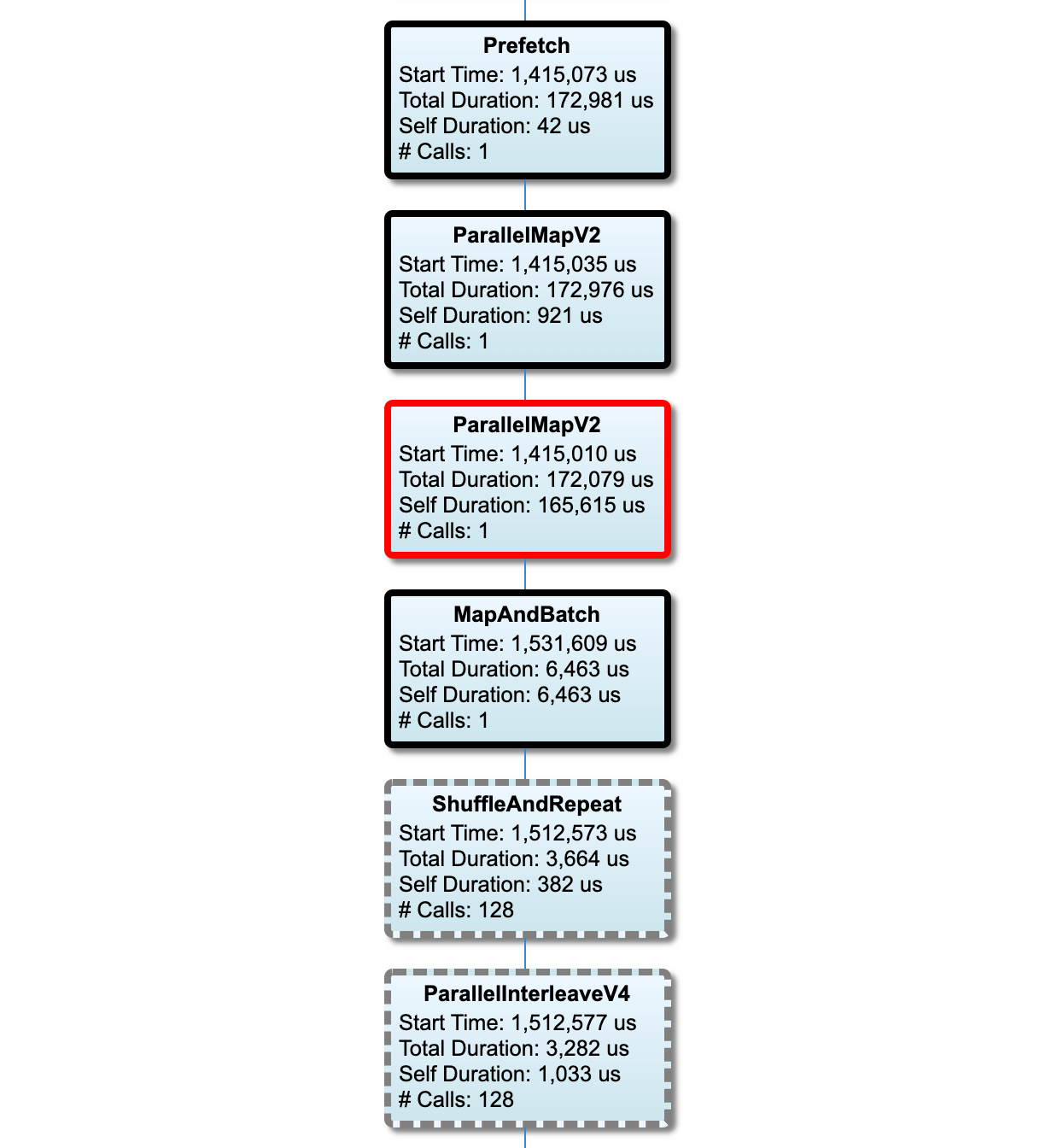
العقد الموجودة على المسار الحرج لها مخططات عريضة. عقدة عنق الزجاجة، وهي العقدة التي تتمتع بأطول وقت ذاتي على المسار الحرج، لها مخطط تفصيلي أحمر. العقد الأخرى غير الحرجة لها حدود رمادية متقطعة.
في كل عقدة، يشير وقت البدء إلى وقت بدء التنفيذ. قد يتم تنفيذ نفس العقدة عدة مرات، على سبيل المثال، إذا كان هناك عملية Batch في مسار الإدخال. إذا تم تنفيذه عدة مرات، فهذا هو وقت بدء التنفيذ الأول.
المدة الإجمالية هي وقت التنفيذ. إذا تم تنفيذها عدة مرات، فهذا هو مجموع أوقات الجدار لجميع عمليات التنفيذ.
الوقت الذاتي هو إجمالي الوقت بدون الوقت المتراكب مع العقد التابعة المباشرة له.
"# المكالمات" هو عدد المرات التي يتم فيها تنفيذ خط أنابيب الإدخال.
جمع بيانات الأداء
يقوم TensorFlow Profiler بجمع أنشطة المضيف وآثار GPU لنموذج TensorFlow الخاص بك. يمكنك تكوين ملف التعريف لجمع بيانات الأداء من خلال الوضع البرمجي أو وضع أخذ العينات.
واجهات برمجة تطبيقات ملفات التعريف
يمكنك استخدام واجهات برمجة التطبيقات التالية لإجراء التوصيف.
الوضع البرمجي باستخدام TensorBoard Keras Callback (
tf.keras.callbacks.TensorBoard)# Profile from batches 10 to 15 tb_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, profile_batch='10, 15') # Train the model and use the TensorBoard Keras callback to collect # performance profiling data model.fit(train_data, steps_per_epoch=20, epochs=5, callbacks=[tb_callback])الوضع البرمجي باستخدام واجهة برمجة تطبيقات وظيفة
tf.profilertf.profiler.experimental.start('logdir') # Train the model here tf.profiler.experimental.stop()الوضع البرمجي باستخدام مدير السياق
with tf.profiler.experimental.Profile('logdir'): # Train the model here pass
وضع أخذ العينات: قم بإجراء التوصيف حسب الطلب باستخدام
tf.profiler.experimental.server.startلبدء خادم gRPC مع تشغيل نموذج TensorFlow. بعد بدء تشغيل خادم gRPC وتشغيل النموذج الخاص بك، يمكنك التقاط ملف تعريف من خلال زر Capture Profile في المكون الإضافي لملف تعريف TensorBoard. استخدم البرنامج النصي الموجود في قسم تثبيت ملف التعريف أعلاه لتشغيل مثيل TensorBoard إذا لم يكن قيد التشغيل بالفعل.على سبيل المثال،
# Start a profiler server before your model runs. tf.profiler.experimental.server.start(6009) # (Model code goes here). # Send a request to the profiler server to collect a trace of your model. tf.profiler.experimental.client.trace('grpc://localhost:6009', 'gs://your_tb_logdir', 2000)مثال لتصنيف العديد من العمال:
# E.g., your worker IP addresses are 10.0.0.2, 10.0.0.3, 10.0.0.4, and you # would like to profile for a duration of 2 seconds. tf.profiler.experimental.client.trace( 'grpc://10.0.0.2:8466,grpc://10.0.0.3:8466,grpc://10.0.0.4:8466', 'gs://your_tb_logdir', 2000)
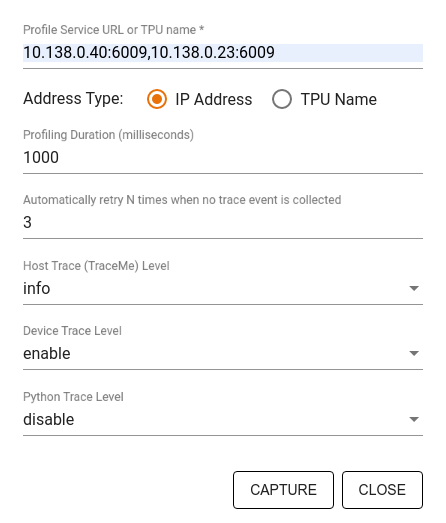
استخدم مربع حوار ملف تعريف الالتقاط لتحديد:
- قائمة مفصولة بفواصل بعناوين URL لخدمة الملف الشخصي أو أسماء TPU.
- مدة التنميط.
- مستوى تتبع مكالمات الجهاز والمضيف ووظيفة بايثون.
- كم مرة تريد أن يقوم منشئ ملفات التعريف بإعادة محاولة التقاط ملفات التعريف إذا لم ينجح في البداية.
تحديد ملامح حلقات التدريب المخصصة
لتكوين ملف تعريف لحلقات التدريب المخصصة في كود TensorFlow الخاص بك، استخدم حلقة التدريب باستخدام واجهة برمجة التطبيقات tf.profiler.experimental.Trace لتحديد حدود الخطوات لملف التعريف.
يتم استخدام وسيطة name كبادئة لأسماء الخطوات، ويتم إلحاق وسيطة الكلمة الأساسية step_num في أسماء الخطوات، وتؤدي وسيطة الكلمة الأساسية _r إلى معالجة حدث التتبع هذا كحدث خطوة بواسطة منشئ ملفات التعريف.
على سبيل المثال،
for step in range(NUM_STEPS):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_data = next(dataset)
train_step(train_data)
سيؤدي هذا إلى تمكين تحليل الأداء المستند إلى الخطوات الخاص بملف التعريف وسيؤدي إلى ظهور أحداث الخطوة في عارض التتبع.
تأكد من تضمين مكرر مجموعة البيانات في سياق tf.profiler.experimental.Trace لإجراء تحليل دقيق لمسار الإدخال.
مقتطف الكود أدناه هو نمط مضاد:
for step, train_data in enumerate(dataset):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_step(train_data)
حالات استخدام التنميط
يغطي ملف التعريف عددًا من حالات الاستخدام على أربعة محاور مختلفة. بعض المجموعات مدعومة حاليًا وسيتم إضافة مجموعات أخرى في المستقبل. بعض حالات الاستخدام هي:
- التوصيف المحلي مقابل التوصيف البعيد : هاتان طريقتان شائعتان لإعداد بيئة التوصيف الخاصة بك. في ملف التعريف المحلي، يتم استدعاء واجهة برمجة تطبيقات ملف التعريف على نفس الجهاز الذي يقوم النموذج الخاص بك بتنفيذه، على سبيل المثال، محطة عمل محلية مع وحدات معالجة الرسومات. في ملف التعريف عن بعد، يتم استدعاء واجهة برمجة تطبيقات ملف التعريف على جهاز مختلف عن المكان الذي يتم فيه تنفيذ النموذج الخاص بك، على سبيل المثال، على Cloud TPU.
- تصنيف العديد من العاملين : يمكنك تعريف عدة أجهزة عند استخدام إمكانات التدريب الموزعة لـ TensorFlow.
- منصة الأجهزة : وحدات المعالجة المركزية (CPUs) ووحدات معالجة الرسومات (GPU) ووحدات TPU (TPU).
يقدم الجدول أدناه نظرة عامة سريعة على حالات الاستخدام المدعومة من TensorFlow المذكورة أعلاه:
| واجهة برمجة تطبيقات ملفات التعريف | محلي | بعيد | عمال متعددون | منصات الأجهزة |
|---|---|---|---|---|
| رد اتصال TensorBoard Keras | المدعومة | غير مدعوم | غير مدعوم | وحدة المعالجة المركزية، وحدة معالجة الرسومات |
tf.profiler.experimental بدء/إيقاف API | المدعومة | غير مدعوم | غير مدعوم | وحدة المعالجة المركزية، وحدة معالجة الرسومات |
tf.profiler.experimental client.trace API | المدعومة | المدعومة | المدعومة | وحدة المعالجة المركزية، وحدة معالجة الرسومات، تي بي يو |
| واجهة برمجة تطبيقات مدير السياق | المدعومة | غير معتمد | غير مدعوم | وحدة المعالجة المركزية، وحدة معالجة الرسومات |
أفضل الممارسات لأداء النموذج الأمثل
استخدم التوصيات التالية حسب ما ينطبق على نماذج TensorFlow الخاصة بك لتحقيق الأداء الأمثل.
بشكل عام، قم بإجراء جميع التحويلات على الجهاز وتأكد من استخدام أحدث إصدار متوافق من المكتبات مثل cuDNN وIntel MKL لنظامك الأساسي.
تحسين خط أنابيب بيانات الإدخال
استخدم البيانات من [#input_pipeline_analyzer] لتحسين مسار إدخال البيانات. يمكن لخط أنابيب إدخال البيانات الفعال أن يحسن بشكل كبير سرعة تنفيذ النموذج الخاص بك عن طريق تقليل وقت خمول الجهاز. حاول دمج أفضل الممارسات المفصلة في الأداء الأفضل مع دليل tf.data API وما يليه لجعل مسار إدخال البيانات الخاص بك أكثر كفاءة.
بشكل عام، يمكن لموازاة أي عمليات لا تحتاج إلى تنفيذها بشكل تسلسلي تحسين مسار إدخال البيانات بشكل كبير.
في العديد من الحالات، من المفيد تغيير ترتيب بعض الاستدعاءات أو ضبط الوسائط بحيث تعمل بشكل أفضل مع النموذج الخاص بك. أثناء تحسين خط أنابيب بيانات الإدخال، قم بقياس أداة تحميل البيانات فقط دون خطوات التدريب والانتشار العكسي لتحديد تأثير التحسينات بشكل مستقل.
حاول تشغيل النموذج الخاص بك باستخدام البيانات الاصطناعية للتحقق مما إذا كان مسار الإدخال يمثل عنق الزجاجة في الأداء.
استخدم
tf.data.Dataset.shardللتدريب على وحدات معالجة الرسومات المتعددة. تأكد من قيامك بالتقسيم مبكرًا جدًا في حلقة الإدخال لمنع حدوث انخفاض في الإنتاجية. عند العمل مع TFRecords، تأكد من تقسيم قائمة TFRecords وليس محتويات TFRecords.موازاة العديد من العمليات عن طريق تعيين قيمة
num_parallel_callsديناميكيًا باستخدامtf.data.AUTOTUNE.فكر في الحد من استخدام
tf.data.Dataset.from_generatorلأنه أبطأ مقارنة بعمليات TensorFlow النقية.ضع في اعتبارك الحد من استخدام
tf.py_functionلأنه لا يمكن إجراء تسلسل لها ولا يتم دعم تشغيلها في TensorFlow الموزع.استخدم
tf.data.Optionsللتحكم في التحسينات الثابتة لخط أنابيب الإدخال.
اقرأ أيضًا دليل تحليل أداء tf.data لمزيد من الإرشادات حول تحسين مسار الإدخال الخاص بك.
تحسين زيادة البيانات
عند العمل مع بيانات الصورة، اجعل زيادة بياناتك أكثر كفاءة عن طريق الإرسال إلى أنواع بيانات مختلفة بعد تطبيق التحويلات المكانية، مثل التقليب، والاقتصاص، والتدوير، وما إلى ذلك.
استخدم نفيديا دالي
في بعض الحالات، كما هو الحال عندما يكون لديك نظام يحتوي على نسبة عالية من وحدة معالجة الرسومات إلى وحدة المعالجة المركزية، قد لا تكون جميع التحسينات المذكورة أعلاه كافية لإزالة الاختناقات في أداة تحميل البيانات الناتجة عن قيود دورات وحدة المعالجة المركزية.
إذا كنت تستخدم وحدات معالجة الرسومات NVIDIA® لرؤية الكمبيوتر وتطبيقات التعلم العميق للصوت، ففكر في استخدام مكتبة تحميل البيانات ( DALI ) لتسريع مسار البيانات.
تحقق من NVIDIA® DALI: وثائق العمليات للحصول على قائمة بعمليات DALI المدعومة.
استخدم الخيوط والتنفيذ المتوازي
قم بتشغيل العمليات على سلاسل عمليات وحدة المعالجة المركزية المتعددة باستخدام tf.config.threading API لتنفيذها بشكل أسرع.
يقوم TensorFlow تلقائيًا بتعيين عدد سلاسل التوازي بشكل افتراضي. يعتمد تجمع مؤشرات الترابط المتاح لتشغيل عمليات TensorFlow على عدد سلاسل رسائل وحدة المعالجة المركزية المتاحة.
يمكنك التحكم في الحد الأقصى للتسريع المتوازي لعملية واحدة باستخدام tf.config.threading.set_intra_op_parallelism_threads . لاحظ أنه إذا قمت بتشغيل عمليات متعددة بالتوازي، فسوف يتشاركون جميعًا في تجمع الخيوط المتاح.
إذا كانت لديك عمليات مستقلة غير محظورة (عمليات ليس لها مسار موجه بينها على الرسم البياني)، فاستخدم tf.config.threading.set_inter_op_parallelism_threads لتشغيلها بشكل متزامن باستخدام تجمع مؤشرات الترابط المتاح.
متنوع
عند العمل مع نماذج أصغر على وحدات معالجة الرسومات NVIDIA®، يمكنك تعيين tf.compat.v1.ConfigProto.force_gpu_compatible=True لإجبار جميع موترات وحدة المعالجة المركزية على التخصيص مع ذاكرة CUDA المثبتة لإعطاء دفعة كبيرة لأداء النموذج. ومع ذلك، توخ الحذر أثناء استخدام هذا الخيار للنماذج غير المعروفة/الكبيرة جدًا لأن ذلك قد يؤثر سلبًا على أداء المضيف (وحدة المعالجة المركزية).
تحسين أداء الجهاز
اتبع أفضل الممارسات المفصلة هنا وفي دليل تحسين أداء وحدة معالجة الرسومات لتحسين أداء نموذج TensorFlow على الجهاز.
إذا كنت تستخدم وحدات معالجة الرسومات NVIDIA، فقم بتسجيل استخدام وحدة معالجة الرسومات والذاكرة في ملف CSV عن طريق تشغيل:
nvidia-smi
--query-gpu=utilization.gpu,utilization.memory,memory.total,
memory.free,memory.used --format=csv
تكوين تخطيط البيانات
عند العمل مع البيانات التي تحتوي على معلومات القناة (مثل الصور)، قم بتحسين تنسيق تخطيط البيانات لتفضيل القنوات الأخيرة (NHWC على NCHW).
تعمل تنسيقات بيانات القناة الأخيرة على تحسين استخدام Tensor Core وتوفير تحسينات كبيرة في الأداء خاصة في النماذج التلافيفية عند اقترانها بـ AMP. لا يزال من الممكن تشغيل تخطيطات بيانات NCHW بواسطة Tensor Cores، ولكنها تقدم حملًا إضافيًا بسبب عمليات النقل التلقائي.
يمكنك تحسين تخطيط البيانات لتفضيل تخطيطات NHWC عن طريق تعيين data_format="channels_last" لطبقات مثل tf.keras.layers.Conv2D و tf.keras.layers.Conv3D و tf.keras.layers.RandomRotation .
استخدم tf.keras.backend.set_image_data_format لتعيين تنسيق تخطيط البيانات الافتراضي لواجهة برمجة تطبيقات الواجهة الخلفية لـ Keras.
الحد الأقصى لذاكرة التخزين المؤقت L2
عند العمل مع وحدات معالجة الرسومات NVIDIA®، قم بتنفيذ مقتطف التعليمات البرمجية أدناه قبل حلقة التدريب لزيادة دقة جلب L2 إلى 128 بايت.
import ctypes
_libcudart = ctypes.CDLL('libcudart.so')
# Set device limit on the current device
# cudaLimitMaxL2FetchGranularity = 0x05
pValue = ctypes.cast((ctypes.c_int*1)(), ctypes.POINTER(ctypes.c_int))
_libcudart.cudaDeviceSetLimit(ctypes.c_int(0x05), ctypes.c_int(128))
_libcudart.cudaDeviceGetLimit(pValue, ctypes.c_int(0x05))
assert pValue.contents.value == 128
تكوين استخدام مؤشر ترابط GPU
يحدد وضع مؤشر ترابط GPU كيفية استخدام مؤشرات ترابط GPU.
اضبط وضع الخيط على gpu_private للتأكد من أن المعالجة المسبقة لا تسرق جميع سلاسل GPU. سيؤدي هذا إلى تقليل تأخير إطلاق النواة أثناء التدريب. يمكنك أيضًا تعيين عدد المواضيع لكل وحدة معالجة الرسومات. اضبط هذه القيم باستخدام متغيرات البيئة.
import os
os.environ['TF_GPU_THREAD_MODE']='gpu_private'
os.environ['TF_GPU_THREAD_COUNT']='1'
تكوين خيارات ذاكرة GPU
بشكل عام ، قم بزيادة حجم الدُفعة وحجم النموذج لاستخدام وحدات معالجة الرسومات بشكل أفضل والحصول على إنتاجية أعلى. لاحظ أن زيادة حجم الدُفعة ستغير دقة النموذج بحيث يجب توسيع نطاق النموذج عن طريق ضبط المقاييس الفائقة مثل معدل التعلم لتلبية الدقة المستهدفة.
أيضًا ، استخدم tf.config.experimental.set_memory_growth للسماح لذاكرة GPU بالنمو لمنع جميع الذاكرة المتاحة من تخصيصها بالكامل إلى OPs التي تتطلب فقط جزءًا من الذاكرة. يتيح ذلك عمليات أخرى تستهلك ذاكرة GPU على نفس الجهاز.
لمعرفة المزيد ، تحقق من إرشادات نمو ذاكرة GPU المحددة في دليل GPU لمعرفة المزيد.
متنوع
قم بزيادة حجم التدريب المصغر حجم (عدد عينات التدريب المستخدمة لكل جهاز في تكرار واحد من حلقة التدريب) إلى الحد الأقصى للمبلغ الذي يناسبها بدون خطأ في الذاكرة (OOM) على وحدة معالجة الرسومات. تؤثر زيادة حجم الدُفعة على دقة النموذج - لذلك تأكد من قيامك بتوسيع نطاق النموذج عن طريق ضبط المقاييس الفائقة لتلبية الدقة المستهدفة.
تعطيل الإبلاغ عن أخطاء OOM أثناء تخصيص الموتر في رمز الإنتاج. set
report_tensor_allocations_upon_oom=Falseفيtf.compat.v1.RunOptions.بالنسبة للنماذج ذات الطبقات الإلزامية ، قم بإزالة إضافة التحيز في حالة استخدام تطبيع الدُفعات. يغير تطبيع الدُفعات القيم بمتوسطها وهذا يزيل الحاجة إلى الحصول على مصطلح تحيز ثابت.
استخدم إحصائيات TF لمعرفة مدى تشغيل OPS على الجهاز بكفاءة.
استخدم
tf.functionلإجراء الحسابات واختياريًا ، قم بتمكينjit_compile=True(tf.function(jit_compile=True). لمعرفة المزيد ، انتقل إلى استخدام xla tf.function .قلل من عمليات Python المضيفة بين الخطوات وتقليل عمليات الاسترجاعات. احسب المقاييس كل خطوات قليلة بدلاً من كل خطوة.
الحفاظ على وحدات حساب الجهاز مشغولة.
إرسال البيانات إلى أجهزة متعددة بالتوازي.
ضع في اعتبارك استخدام تمثيلات رقمية 16 بت ، مثل
fp16تنسيق النقطة العائمة نصف الدقة المحددة بواسطة IEEE-أو تنسيق BFLOAT16 في الدماغ.
موارد إضافية
- TensorFlow Profiler: Profile Model Performance البرنامج التعليمي مع Keras و Tensorboard حيث يمكنك تطبيق النصيحة في هذا الدليل.
- تحديد الأداء في TensorFlow 2 Talk من Tensorflow Dev Summit 2020.
- عرض Tensorflow Profiler من قمة Tensorflow Dev 2020.
القيود المعروفة
التنميط المتعدد وحدات معالجة الرسومات على Tensorflow 2.2 و TensorFlow 2.3
يدعم TensorFlow 2.2 و 2.3 توصيفات GPU متعددة للأنظمة المضيفة المفردة فقط ؛ لا يتم دعم التنميط المتعدد في GPU لأنظمة متعددة المضيف. لتكوينات GPU متعددة العامل ، يجب أن يتم تحديد كل عامل بشكل مستقل. من TensorFlow 2.4 يمكن تحديد العديد من العمال باستخدام tf.profiler.experimental.client.trace API.
مطلوب CUDA® Toolkit 10.2 أو في وقت لاحق لتحديد معالجة وحدات معالجة الرسومات المتعددة. كإصدارات TensorFlow 2.2 و 2.3 تدعم إصدارات مجموعة أدوات CUDA® فقط حتى 10.1 ، تحتاج إلى إنشاء روابط رمزية لـ libcudart.so.10.1 و libcupti.so.10.1 :
sudo ln -s /usr/local/cuda/lib64/libcudart.so.10.2 /usr/local/cuda/lib64/libcudart.so.10.1
sudo ln -s /usr/local/cuda/extras/CUPTI/lib64/libcupti.so.10.2 /usr/local/cuda/extras/CUPTI/lib64/libcupti.so.10.1