
| | |  عرض المصدر على جيثب عرض المصدر على جيثب | |
ملخص
يوضح هذا البرنامج التعليمي زيادة البيانات: تقنية لزيادة تنوع مجموعة التدريب الخاصة بك عن طريق تطبيق تحويلات عشوائية (لكن واقعية) ، مثل تدوير الصورة.
سوف تتعلم كيفية تطبيق زيادة البيانات بطريقتين:
- استخدم طبقات المعالجة المسبقة لـ Keras ، مثل
tf.keras.layers.Resizingوtf.keras.layers.Rescalingوtf.keras.layers.RandomFlipوtf.keras.layers.RandomRotation. - استخدم طرق
tf.image، مثلtf.image.flip_left_rightوtf.image.rgb_to_grayscaleوtf.image.adjust_brightnessوtf.image.central_cropوtf.image.stateless_random*.
يثبت
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow.keras import layers
تنزيل مجموعة البيانات
يستخدم هذا البرنامج التعليمي مجموعة بيانات tf_flowers . للراحة ، قم بتنزيل مجموعة البيانات باستخدام مجموعات بيانات TensorFlow . إذا كنت ترغب في التعرف على طرق أخرى لاستيراد البيانات ، فراجع البرنامج التعليمي لتحميل الصور .
(train_ds, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
تتكون مجموعة بيانات الزهور من خمس فئات.
num_classes = metadata.features['label'].num_classes
print(num_classes)
5
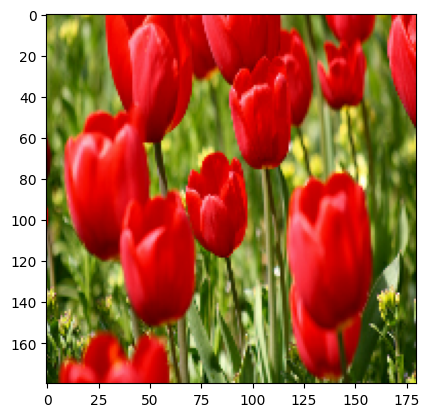
دعنا نسترجع صورة من مجموعة البيانات ونستخدمها لتوضيح زيادة البيانات.
get_label_name = metadata.features['label'].int2str
image, label = next(iter(train_ds))
_ = plt.imshow(image)
_ = plt.title(get_label_name(label))
2022-01-26 05:09:18.712477: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.

استخدام طبقات Keras المعالجة المسبقة
تغيير الحجم وإعادة القياس
يمكنك استخدام طبقات معالجة Keras لتغيير حجم صورك إلى شكل متناسق (باستخدام tf.keras.layers.Resizing ) ، وإعادة قياس قيم البكسل (باستخدام tf.keras.layers.Rescaling ).
IMG_SIZE = 180
resize_and_rescale = tf.keras.Sequential([
layers.Resizing(IMG_SIZE, IMG_SIZE),
layers.Rescaling(1./255)
])
يمكنك تصور نتيجة تطبيق هذه الطبقات على صورة.
result = resize_and_rescale(image)
_ = plt.imshow(result)
تحقق من أن وحدات البكسل في النطاق [0, 1] :
print("Min and max pixel values:", result.numpy().min(), result.numpy().max())
Min and max pixel values: 0.0 1.0
زيادة البيانات
يمكنك استخدام طبقات المعالجة المسبقة لـ Keras لزيادة البيانات أيضًا ، مثل tf.keras.layers.RandomFlip و tf.keras.layers.RandomRotation .
لنقم بإنشاء بعض طبقات المعالجة المسبقة ونطبقها بشكل متكرر على نفس الصورة.
data_augmentation = tf.keras.Sequential([
layers.RandomFlip("horizontal_and_vertical"),
layers.RandomRotation(0.2),
])
# Add the image to a batch.
image = tf.expand_dims(image, 0)
plt.figure(figsize=(10, 10))
for i in range(9):
augmented_image = data_augmentation(image)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_image[0])
plt.axis("off")
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

هناك مجموعة متنوعة من طبقات المعالجة المسبقة التي يمكنك استخدامها لزيادة البيانات بما في ذلك tf.keras.layers.RandomContrast و tf.keras.layers.RandomCrop و tf.keras.layers.RandomZoom وغيرها.
خياران لاستخدام طبقات Keras المسبقة
هناك طريقتان يمكنك من خلالهما استخدام طبقات المعالجة المسبقة هذه ، مع مقايضات مهمة.
الخيار 1: اجعل طبقات المعالجة المسبقة جزءًا من نموذجك
model = tf.keras.Sequential([
# Add the preprocessing layers you created earlier.
resize_and_rescale,
data_augmentation,
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
# Rest of your model.
])
هناك نقطتان مهمتان يجب الانتباه لهما في هذه الحالة:
سيتم تشغيل زيادة البيانات على الجهاز ، بشكل متزامن مع بقية طبقاتك ، والاستفادة من تسريع وحدة معالجة الرسومات.
عند تصدير النموذج الخاص بك باستخدام
model.save، سيتم حفظ طبقات المعالجة المسبقة مع باقي نموذجك. إذا قمت بنشر هذا النموذج لاحقًا ، فسيقوم تلقائيًا بتوحيد الصور (وفقًا لتكوين طبقاتك). يمكن أن يوفر لك هذا الجهد المبذول لإعادة تنفيذ هذا المنطق من جانب الخادم.
الخيار 2: تطبيق طبقات المعالجة المسبقة على مجموعة البيانات الخاصة بك
aug_ds = train_ds.map(
lambda x, y: (resize_and_rescale(x, training=True), y))
باستخدام هذا الأسلوب ، يمكنك استخدام Dataset.map لإنشاء مجموعة بيانات تنتج دفعات من الصور المدمجة. في هذه الحالة:
- ستحدث زيادة البيانات بشكل غير متزامن على وحدة المعالجة المركزية ، ولا يتم حظرها. يمكنك تداخل تدريب النموذج الخاص بك على وحدة معالجة الرسومات مع المعالجة المسبقة للبيانات ، باستخدام
Dataset.prefetch، كما هو موضح أدناه. - في هذه الحالة ، لن يتم تصدير طبقات المعالجة المسبقة مع النموذج عند استدعاء
Model.save. ستحتاج إلى إرفاقهم بالنموذج الخاص بك قبل حفظه أو إعادة تطبيقهم من جانب الخادم. بعد التدريب ، يمكنك إرفاق طبقات المعالجة المسبقة قبل التصدير.
يمكنك العثور على مثال على الخيار الأول في البرنامج التعليمي لتصنيف الصور . دعنا نوضح الخيار الثاني هنا.
قم بتطبيق طبقات المعالجة المسبقة على مجموعات البيانات
قم بتكوين مجموعات بيانات التدريب والتحقق من الصحة والاختبار باستخدام طبقات معالجة Keras التي قمت بإنشائها مسبقًا. ستقوم أيضًا بتكوين مجموعات البيانات للأداء ، باستخدام القراءات المتوازية والجلب المسبق المخزن لإنتاج دفعات من القرص دون أن يصبح الإدخال / الإخراج محظورًا. (تعرف على المزيد من أداء مجموعة البيانات في الأداء الأفضل باستخدام دليل tf.data API .)
batch_size = 32
AUTOTUNE = tf.data.AUTOTUNE
def prepare(ds, shuffle=False, augment=False):
# Resize and rescale all datasets.
ds = ds.map(lambda x, y: (resize_and_rescale(x), y),
num_parallel_calls=AUTOTUNE)
if shuffle:
ds = ds.shuffle(1000)
# Batch all datasets.
ds = ds.batch(batch_size)
# Use data augmentation only on the training set.
if augment:
ds = ds.map(lambda x, y: (data_augmentation(x, training=True), y),
num_parallel_calls=AUTOTUNE)
# Use buffered prefetching on all datasets.
return ds.prefetch(buffer_size=AUTOTUNE)
train_ds = prepare(train_ds, shuffle=True, augment=True)
val_ds = prepare(val_ds)
test_ds = prepare(test_ds)
تدريب نموذج
من أجل الاكتمال ، ستقوم الآن بتدريب نموذج باستخدام مجموعات البيانات التي أعددتها للتو.
يتكون النموذج التسلسلي من ثلاث كتل التفاف ( tf.keras.layers.Conv2D ) مع أقصى طبقة تجميع ( tf.keras.layers.MaxPooling2D ) في كل منها. هناك طبقة متصلة بالكامل ( tf.keras.layers.Dense ) مع 128 وحدة فوقها يتم تنشيطها بواسطة وظيفة تنشيط ReLU ( 'relu' ). لم يتم ضبط هذا النموذج من أجل الدقة (الهدف هو إظهار الميكانيكا).
model = tf.keras.Sequential([
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes)
])
اختر وظيفة محسن tf.keras.optimizers.Adam و tf.keras.losses.SparseCategoricalCrossentropy . لعرض دقة التدريب والتحقق من الصحة لكل فترة تدريب ، قم بتمرير وسيطة metrics إلى Model.compile .
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
تدرب على فترات قليلة:
epochs=5
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
Epoch 1/5 92/92 [==============================] - 13s 110ms/step - loss: 1.2768 - accuracy: 0.4622 - val_loss: 1.0929 - val_accuracy: 0.5640 Epoch 2/5 92/92 [==============================] - 3s 25ms/step - loss: 1.0579 - accuracy: 0.5749 - val_loss: 0.9711 - val_accuracy: 0.6349 Epoch 3/5 92/92 [==============================] - 3s 26ms/step - loss: 0.9677 - accuracy: 0.6291 - val_loss: 0.9764 - val_accuracy: 0.6431 Epoch 4/5 92/92 [==============================] - 3s 25ms/step - loss: 0.9150 - accuracy: 0.6468 - val_loss: 0.8906 - val_accuracy: 0.6431 Epoch 5/5 92/92 [==============================] - 3s 25ms/step - loss: 0.8636 - accuracy: 0.6604 - val_loss: 0.8233 - val_accuracy: 0.6730
loss, acc = model.evaluate(test_ds)
print("Accuracy", acc)
12/12 [==============================] - 5s 14ms/step - loss: 0.7922 - accuracy: 0.6948 Accuracy 0.6948229074478149
زيادة البيانات المخصصة
يمكنك أيضًا إنشاء طبقات زيادة بيانات مخصصة.
يوضح هذا القسم من البرنامج التعليمي طريقتين للقيام بذلك:
- أولاً ، ستقوم بإنشاء طبقة
tf.keras.layers.Lambda. هذه طريقة جيدة لكتابة تعليمات برمجية موجزة. - بعد ذلك ، ستكتب طبقة جديدة عبر التصنيف الفرعي ، مما يمنحك مزيدًا من التحكم.
ستعكس كلتا الطبقتين الألوان في صورة ما بشكل عشوائي ، وفقًا لبعض الاحتمالات.
def random_invert_img(x, p=0.5):
if tf.random.uniform([]) < p:
x = (255-x)
else:
x
return x
def random_invert(factor=0.5):
return layers.Lambda(lambda x: random_invert_img(x, factor))
random_invert = random_invert()
plt.figure(figsize=(10, 10))
for i in range(9):
augmented_image = random_invert(image)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_image[0].numpy().astype("uint8"))
plt.axis("off")
2022-01-26 05:09:53.045204: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045264: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045312: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045369: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045418: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045467: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045511: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.047630: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module

بعد ذلك ، قم بتنفيذ طبقة مخصصة عن طريق التصنيف الفرعي :
class RandomInvert(layers.Layer):
def __init__(self, factor=0.5, **kwargs):
super().__init__(**kwargs)
self.factor = factor
def call(self, x):
return random_invert_img(x)
_ = plt.imshow(RandomInvert()(image)[0])

يمكن استخدام هاتين الطبقتين على النحو الموصوف في الخيارين 1 و 2 أعلاه.
باستخدام tf.image
تعتبر أدوات المعالجة المسبقة Keras المذكورة أعلاه ملائمة. ولكن ، للحصول على تحكم أكثر دقة ، يمكنك كتابة خطوط أو طبقات زيادة البيانات الخاصة بك باستخدام tf.data و tf.image . (قد ترغب أيضًا في التحقق من TensorFlow Addons Image: Operations و TensorFlow I / O: تحويلات مساحة اللون .)
نظرًا لأن مجموعة بيانات الزهور قد تم تكوينها مسبقًا باستخدام زيادة البيانات ، فلنعد استيرادها للبدء من جديد:
(train_ds, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
استرجع صورة للعمل معها:
image, label = next(iter(train_ds))
_ = plt.imshow(image)
_ = plt.title(get_label_name(label))
2022-01-26 05:09:59.918847: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.

دعنا نستخدم الوظيفة التالية لتصور ومقارنة الصور الأصلية والمُعزَّزة جنبًا إلى جنب:
def visualize(original, augmented):
fig = plt.figure()
plt.subplot(1,2,1)
plt.title('Original image')
plt.imshow(original)
plt.subplot(1,2,2)
plt.title('Augmented image')
plt.imshow(augmented)
زيادة البيانات
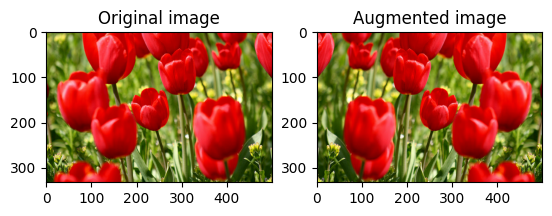
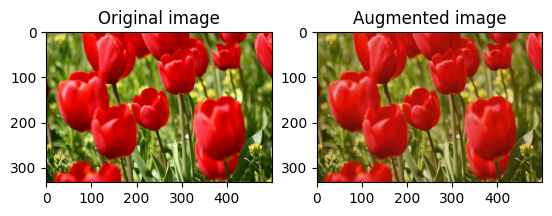
اقلب الصورة
اقلب الصورة رأسيًا أو أفقيًا باستخدام tf.image.flip_left_right :
flipped = tf.image.flip_left_right(image)
visualize(image, flipped)
صورة بتدرج الرمادي
يمكنك تدرج الصورة باستخدام tf.image.rgb_to_grayscale :
grayscaled = tf.image.rgb_to_grayscale(image)
visualize(image, tf.squeeze(grayscaled))
_ = plt.colorbar()

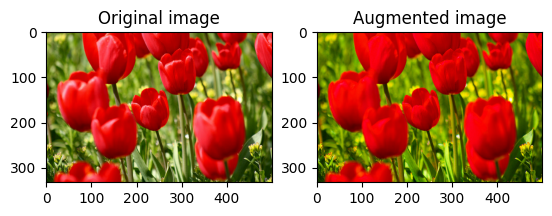
تشبع الصورة
تشبع صورة بـ tf.image.adjust_saturation من خلال توفير عامل تشبع:
saturated = tf.image.adjust_saturation(image, 3)
visualize(image, saturated)
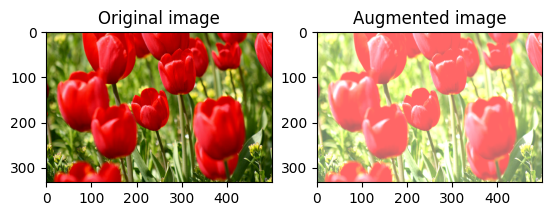
تغيير سطوع الصورة
قم بتغيير سطوع الصورة باستخدام tf.image.adjust_brightness من خلال توفير عامل سطوع:
bright = tf.image.adjust_brightness(image, 0.4)
visualize(image, bright)
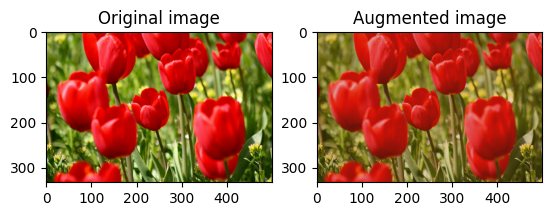
مركز اقتصاص الصورة
قم بقص الصورة من المنتصف إلى جزء الصورة الذي تريده باستخدام tf.image.central_crop :
cropped = tf.image.central_crop(image, central_fraction=0.5)
visualize(image, cropped)
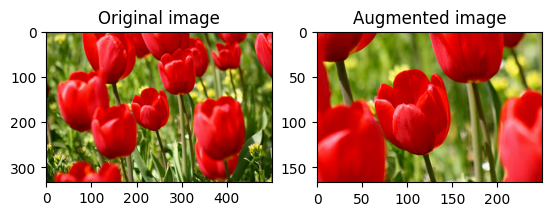
قم بتدوير الصورة
تدوير الصورة بمقدار 90 درجة باستخدام tf.image.rot90 :
rotated = tf.image.rot90(image)
visualize(image, rotated)

تحولات عشوائية
يمكن أن يساعد تطبيق تحويلات عشوائية على الصور في تعميم وتوسيع مجموعة البيانات. توفر واجهة برمجة تطبيقات tf.image الحالية ثماني عمليات صور عشوائية (ops):
-
tf.image.stateless_random_brightness -
tf.image.stateless_random_contrast -
tf.image.stateless_random_crop -
tf.image.stateless_random_flip_left_right -
tf.image.stateless_random_flip_up_down -
tf.image.stateless_random_hue -
tf.image.stateless_random_jpeg_quality -
tf.image.stateless_random_saturation
عمليات الصور العشوائية هذه وظيفية بحتة: يعتمد الإخراج فقط على الإدخال. هذا يجعلها سهلة الاستخدام في خطوط أنابيب الإدخال الحتمية عالية الأداء. تتطلب قيمة seed يتم إدخالها في كل خطوة. بالنظر إلى نفس seed ، فإنهم يعرضون نفس النتائج بغض النظر عن عدد المرات التي يتم استدعاؤها.
في الأقسام التالية سوف:
- راجع أمثلة استخدام عمليات الصورة العشوائية لتحويل صورة.
- اشرح كيفية تطبيق التحويلات العشوائية على مجموعة بيانات التدريب.
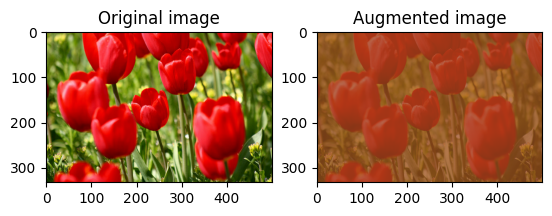
قم بتغيير سطوع الصورة بشكل عشوائي
قم بتغيير سطوع image عشوائيًا باستخدام tf.image.stateless_random_brightness من خلال توفير عامل سطوع seed . يتم اختيار عامل السطوع عشوائيًا في النطاق [-max_delta, max_delta) ويرتبط seed المعطاة.
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_brightness = tf.image.stateless_random_brightness(
image, max_delta=0.95, seed=seed)
visualize(image, stateless_random_brightness)
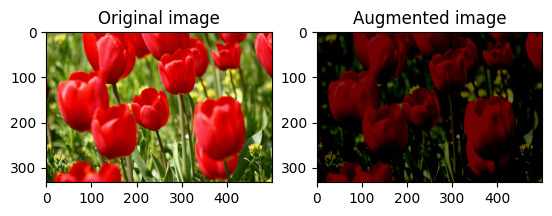
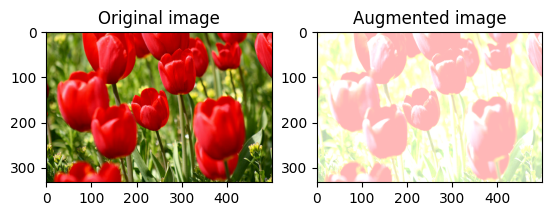
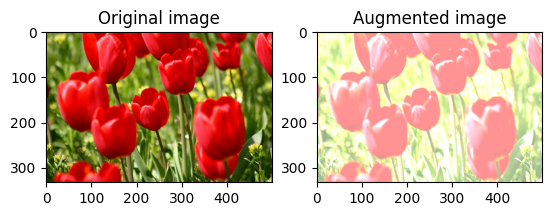
قم بتغيير تباين الصورة بشكل عشوائي
قم بتغيير تباين image عشوائيًا باستخدام tf.image.stateless_random_contrast من خلال توفير نطاق التباين seed . يتم اختيار نطاق التباين عشوائيًا في الفاصل الزمني [lower, upper] ويرتبط seed المعينة.
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_contrast = tf.image.stateless_random_contrast(
image, lower=0.1, upper=0.9, seed=seed)
visualize(image, stateless_random_contrast)
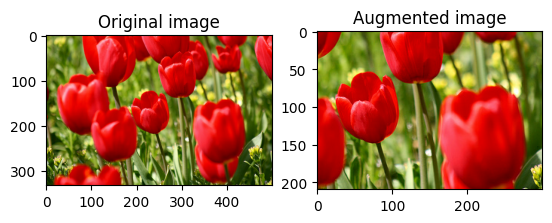
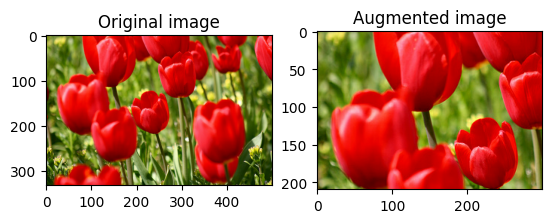
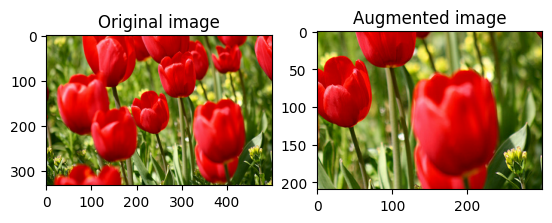
اقتصاص الصورة بشكل عشوائي
اقتصاص image عشوائيًا باستخدام tf.image.stateless_random_crop من خلال توفير size المستهدف seed . الجزء الذي يتم اقتصاصه من image يكون في إزاحة يتم اختيارها عشوائيًا ويرتبط seed المعينة.
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_crop = tf.image.stateless_random_crop(
image, size=[210, 300, 3], seed=seed)
visualize(image, stateless_random_crop)
تطبيق الزيادة على مجموعة البيانات
لنقم أولاً بتنزيل مجموعة بيانات الصورة مرة أخرى في حالة تعديلها في الأقسام السابقة.
(train_datasets, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
بعد ذلك ، حدد وظيفة الأداة المساعدة لتغيير حجم الصور وإعادة قياسها. ستُستخدم هذه الوظيفة في توحيد حجم الصور وحجمها في مجموعة البيانات:
def resize_and_rescale(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, [IMG_SIZE, IMG_SIZE])
image = (image / 255.0)
return image, label
دعنا أيضًا نحدد وظيفة augment التي يمكنها تطبيق التحويلات العشوائية على الصور. سيتم استخدام هذه الوظيفة في مجموعة البيانات في الخطوة التالية.
def augment(image_label, seed):
image, label = image_label
image, label = resize_and_rescale(image, label)
image = tf.image.resize_with_crop_or_pad(image, IMG_SIZE + 6, IMG_SIZE + 6)
# Make a new seed.
new_seed = tf.random.experimental.stateless_split(seed, num=1)[0, :]
# Random crop back to the original size.
image = tf.image.stateless_random_crop(
image, size=[IMG_SIZE, IMG_SIZE, 3], seed=seed)
# Random brightness.
image = tf.image.stateless_random_brightness(
image, max_delta=0.5, seed=new_seed)
image = tf.clip_by_value(image, 0, 1)
return image, label
الخيار 1: استخدام tf.data.experimental.Counter
قم بإنشاء كائن tf.data.experimental.Counter (لنسميه counter ) و Dataset.zip مجموعة البيانات باستخدام (counter, counter) . سيضمن ذلك ربط كل صورة في مجموعة البيانات بقيمة فريدة (للشكل (2,) ) بناءً على counter الذي يمكن لاحقًا augment إلى وظيفة seed كقيمة أولية للتحولات العشوائية.
# Create a `Counter` object and `Dataset.zip` it together with the training set.
counter = tf.data.experimental.Counter()
train_ds = tf.data.Dataset.zip((train_datasets, (counter, counter)))
augment وظيفة الزيادة لمجموعة بيانات التدريب:
train_ds = (
train_ds
.shuffle(1000)
.map(augment, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
val_ds = (
val_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
test_ds = (
test_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
الخيار 2: استخدام tf.random.Generator
- قم بإنشاء كائن
tf.random.Generatorبقيمةseed. يؤدي استدعاء دالةmake_seedsعلى نفس كائن المولد دائمًا إلى إرجاع قيمةseedجديدة وفريدة من نوعها. - حدد دالة مجمعة: 1) تستدعي وظيفة
make_seeds؛ و 2) يمرر القيمةseedالتي تم إنشاؤها حديثًا إلى دالة الزيادةaugmentالعشوائية.
# Create a generator.
rng = tf.random.Generator.from_seed(123, alg='philox')
# Create a wrapper function for updating seeds.
def f(x, y):
seed = rng.make_seeds(2)[0]
image, label = augment((x, y), seed)
return image, label
عيّن وظيفة الغلاف f لمجموعة بيانات التدريب ، ووظيفة resize_and_rescale - لمجموعات التحقق والاختبار:
train_ds = (
train_datasets
.shuffle(1000)
.map(f, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
val_ds = (
val_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
test_ds = (
test_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
يمكن الآن استخدام مجموعات البيانات هذه لتدريب نموذج كما هو موضح سابقًا.
الخطوات التالية
يوضح هذا البرنامج التعليمي زيادة البيانات باستخدام طبقات المعالجة المسبقة لـ Keras و tf.image .
- لمعرفة كيفية تضمين طبقات المعالجة المسبقة داخل النموذج الخاص بك ، راجع البرنامج التعليمي لتصنيف الصور .
- قد تكون مهتمًا أيضًا بمعرفة كيف يمكن أن تساعدك طبقات المعالجة المسبقة في تصنيف النص ، كما هو موضح في البرنامج التعليمي لتصنيف النص الأساسي .
- يمكنك معرفة المزيد حول
tf.dataفي هذا الدليل ، ويمكنك معرفة كيفية تكوين خطوط أنابيب الإدخال الخاصة بك للأداء هنا .