
이 가이드는 TensorFlow Profiler와 함께 이용할 수 있는 도구를 사용하여 TensorFlow 모델의 성능을 추적하는 방법을 보여줍니다. 모델이 호스트(CPU), 장치(GPU) 또는 호스트와 장치의 조합에서 어떻게 작동하는지 이해하는 방법을 배웁니다.
프로파일링을 통해 모델에서 다양한 TensorFlow 연산(ops)이 사용하는 하드웨어 리소스(시간 및 메모리)를 이해하고 성능 병목 현상을 해결함으로써 궁극적으로 모델의 실행 속도를 높일 수 있습니다.
이 안내서는 프로파일러의 설치 방법, 사용 가능한 다양한 도구, 프로파일러에서 성능 데이터를 수집하는 다양한 모드 및 모델 성능을 최적화하기위한 권장 모범 사례를 안내합니다.
Cloud TPU의 모델 성능을 프로파일링하려면 Cloud TPU 가이드를 참조하세요.
Profiler 및 GPU 필수 구성 요소 설치
pip를 사용하여 TensorBoard용 Profiler 플러그인을 설치합니다. Profiler에는 최신 버전의 TensorFlow와 TensorBoard(>=2.2)가 필요합니다.
pip install -U tensorboard_plugin_profile
GPU를 프로파일링하려면 다음을 수행해야 합니다.
TensorFlow GPU 지원 소프트웨어 요구 사항에 나열된 NVIDIA® GPU 드라이버 및 CUDA® 툴킷 요구 사항을 충족합니다.
NVIDIA® CUDA® 프로파일링 도구 인터페이스(CUPTI)가 경로에 있는지 확인합니다.
/sbin/ldconfig -N -v $(sed 's/:/ /g' <<< $LD_LIBRARY_PATH) | \ grep libcupti
경로에 CUPTI가 없으면, 다음을 실행하여 설치 디렉토리를 $LD_LIBRARY_PATH 환경 변수에 추가합니다.
export LD_LIBRARY_PATH=/usr/local/cuda/extras/CUPTI/lib64:$LD_LIBRARY_PATH
그런 다음, 위의 ldconfig 명령을 다시 실행하여 CUPTI 라이브러리가 있는지 확인하세요.
권한 문제 해결하기
Docker 환경 또는 Linux에서 CUDA® Toolkit으로 프로파일링을 실행할 때 불충분한 CUPTI 권한(CUPTI_ERROR_INSUFFICIENT_PRIVILEGES)과 관련된 문제가 발생할 수 있습니다. Linux에서 이러한 문제를 해결하는 방법에 대한 자세한 내용은 NVIDIA 개발자 설명서를 참조하세요.
Docker 환경에서 CUPTI 권한 문제를 해결하려면 다음을 실행합니다.
docker run option '--privileged=true'
Profiler 도구
일부 모델 데이터를 캡처한 후에만 표시되는 TensorBoard의 Profile 탭에서 Profiler에 액세스합니다.
참고: Profiler에서 Google 차트 라이브러리를 로드하려면 인터넷에 연결되어 있어야 합니다. 로컬 컴퓨터, 회사 방화벽 뒤 또는 데이터 센터에서 TensorBoard를 완전히 오프라인으로 실행하면 일부 차트와 표가 누락될 수 있습니다.
Profiler에는 성능 분석에 도움이 되는 다양한 도구가 있습니다.
- 개요 페이지
- 입력 파이프라인 분석기
- TensorFlow 통계
- 추적 뷰어
- GPU 커널 통계
- 메모리 프로파일 도구
- Pod 뷰어
개요 페이지
개요 페이지는 프로파일 실행 중에 모델의 성능 상태를 최상위 수준에서 보여줍니다. 이 페이지에는 호스트 및 모든 기기에 대한 종합적인 개요 페이지와 모델 훈련 성능을 향상하기 위한 몇 가지 권장 사항이 표시됩니다. 호스트 드롭다운 메뉴에서 개별 호스트를 선택할 수도 있습니다.
개요 페이지에는 다음과 같은 데이터가 표시됩니다.

성능 요약: 모델 성능에 대한 높은 수준의 요약을 표시합니다. 성능 요약은 두 부분으로 구성됩니다.
스텝 시간 분석: 평균 스텝 시간을 시간이 사용된 여러 범주로 나눕니다.
- 컴파일: 커널 컴파일에 소요된 시간
- 입력: 입력 데이터를 읽는 데 소요된 시간
- 출력: 출력 데이터를 읽는 데 소요된 시간
- 커널 시작: 호스트가 커널을 시작하는 데 소요된 시간
- 호스트 컴퓨팅 시간
- 장치 간 통신 시간
- 장치 내 컴퓨팅 시간
- Python 오버헤드를 포함한 기타
장치 컴퓨팅 정밀도 - 16bit 및 32bit 계산을 사용하는 장치 컴퓨팅 시간의 백분율을 보고합니다.
스텝-시간 그래프: 샘플링한 모든 스텝에서 기기 스텝 시간(밀리 초)의 그래프를 표시합니다. 각 스텝은 시간이 사용된 여러 범주(서로 다른 색상)로 세분됩니다. 빨간색 영역은 기기가 호스트로부터 입력 데이터를 기다리는 동안 유휴 상태로 있었던 스텝 시간 부분에 해당합니다. 녹색 영역은 기기가 실제로 작동한 시간을 나타냅니다.
기기 내 상위 10개의 TensorFlow 연산(예: GPU): 가장 오래 실행된 기기 연산을 표시합니다.
각 행에는 연산의 자체 시간(모든 연산에 소요된 시간의 백분율), 누적 시간, 범주 및 이름이 표시됩니다.
실행 환경: 다음을 포함하여 모델 실행 환경에 대한 높은 수준의 요약을 표시합니다.
- 사용된 호스트 수
- 장치 유형(GPU/TPU)
- 장치 코어 수
다음 단계를 위한 권장 사항: 모델이 입력 바운드될 때 보고하고, 모델의 성능 병목 현상을 찾아 해결하는 데 사용할 수 있는 도구를 권장합니다.
입력 파이프라인 분석기
TensorFlow 프로그램이 파일에서 데이터를 읽을 때 파이프라인 방식으로 TensorFlow 그래프의 맨 위에서 시작합니다. 읽기 프로세스는 직렬로 연결된 다수의 데이터 처리 스텝으로 나누어지며, 한 스텝의 출력은 다음 스텝의 입력이 됩니다. 이러한 데이터 읽기 방식을 입력 파이프라인이라고 합니다.
파일에서 레코드를 읽는 일반적인 파이프라인에는 다음 단계가 있습니다.
- 파일 읽기
- 파일 전처리(선택 사항)
- 호스트에서 기기로 파일 전송
비효율적인 입력 파이프라인으로 인해 애플리케이션 속도가 크게 느려질 수 있습니다. 애플리케이션이 입력 파이프라인에서 상당한 시간을 소비하면 입력 바운드로 간주합니다. 입력 파이프라인 분석기에서 얻은 통찰력을 사용하여 입력 파이프라인이 비효율적인 위치를 파악하세요.
입력 파이프라인 분석기는 프로그램의 입력 바운드 여부를 즉시 알려주고 입력 파이프라인의 모든 단계에서 성능 병목 현상을 디버깅하기 위해 기기 및 호스트 쪽 분석을 안내합니다.
데이터 입력 파이프라인을 최적화하기 위한 권장 모범 사례는 입력 파이프라인 성능 지침을 참조하세요.
입력 파이프라인 대시보드
입력 파이프라인 분석기를 열려면 프로파일을 선택한 다음 도구 드롭다운 메뉴에서 input_pipeline_analyzer를 선택하세요.

대시보드에는 세 개의 섹션이 있습니다.
- 요약: 애플리케이션이 입력 바운드인지 여부, 입력 바운드인 경우 그 정도에 관한 정보를 포함하여 전체 입력 파이프라인을 요약합니다.
- 기기 쪽 분석: 기기 스텝 시간 및 각 스텝의 전체 코어에서 입력 데이터를 기다리는 데 소요된 기기 시간 범위를 포함하여 자세한 기기 쪽 분석 결과를 표시합니다.
- 호스트 쪽 분석: 호스트의 입력 처리 시간 분석을 포함하여 호스트 쪽 분석을 자세히 보여줍니다.
입력 파이프라인 요약
요약에서는 호스트로부터 입력을 기다리는 데 소요된 기기 시간의 백분율을 보여줌으로써 프로그램이 입력 바운드인지 보고합니다. 계측된 표준 입력 파이프라인을 사용하는 경우에는 도구에서 대부분의 입력 처리 시간이 소비된 위치를 보고합니다.
기기 쪽 분석
기기 쪽 분석은 기기와 호스트에 소요된 시간 및 호스트로부터 입력 데이터를 기다리는 데 소요된 기기 시간에 대한 통찰력을 제공합니다.
- 스텝 수에 따른 스텝-시간 그래프: 샘플링한 모든 스텝에서 기기 스텝 시간(밀리 초)의 그래프를 표시합니다. 각 스텝은 시간이 사용된 여러 범주(서로 다른 색상)로 세분됩니다. 빨간색 영역은 기기가 호스트로부터 입력 데이터를 기다리는 동안 유휴 상태로 있었던 스텝 시간 부분에 해당합니다. 녹색 영역은 기기가 실제로 작동한 시간을 나타냅니다.
- 스텝 시간 통계: 기기 스텝 시간의 평균, 표준 편차 및 범위([최소, 최대])를 보고합니다.
호스트 쪽 분석
호스트 쪽 분석은 호스트의 입력 처리 시간(tf.data API 연산에 소요된 시간)을 여러 범주로 분류하여 보고합니다.
- 요청 시 파일에서 데이터 읽기: 캐싱, 프리페치 및 인터리빙 없이 파일에서 데이터를 읽는 데 소요된 시간입니다.
- 파일에서 데이터 미리 읽기: 캐싱, 프리페치, 인터리빙을 포함하여 파일을 읽는 데 소요된 시간입니다.
- 데이터 전처리: 이미지 압축 풀기와 같은 사전 처리 연산에 소요된 시간입니다.
- 기기로 전송될 데이터 큐에 넣기: 데이터를 기기로 전송하기 전에 데이터를 인피드 큐에 넣는 데 소요된 시간입니다.
입력 연산 통계를 확장하여 개별 입력 연산 및 해당 범주에 대한 통계를 실행 시간별로 분류하여 볼 수 있습니다.
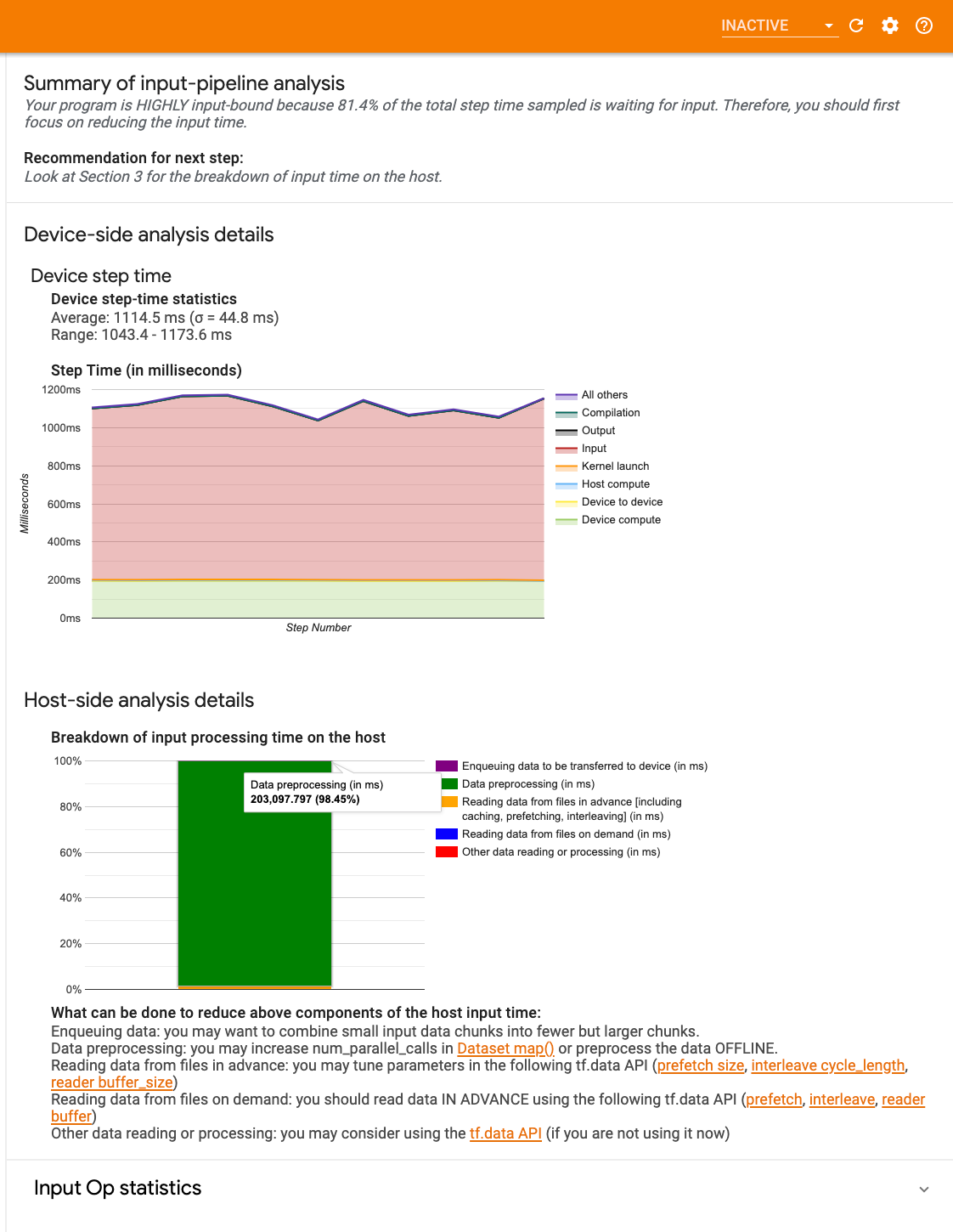
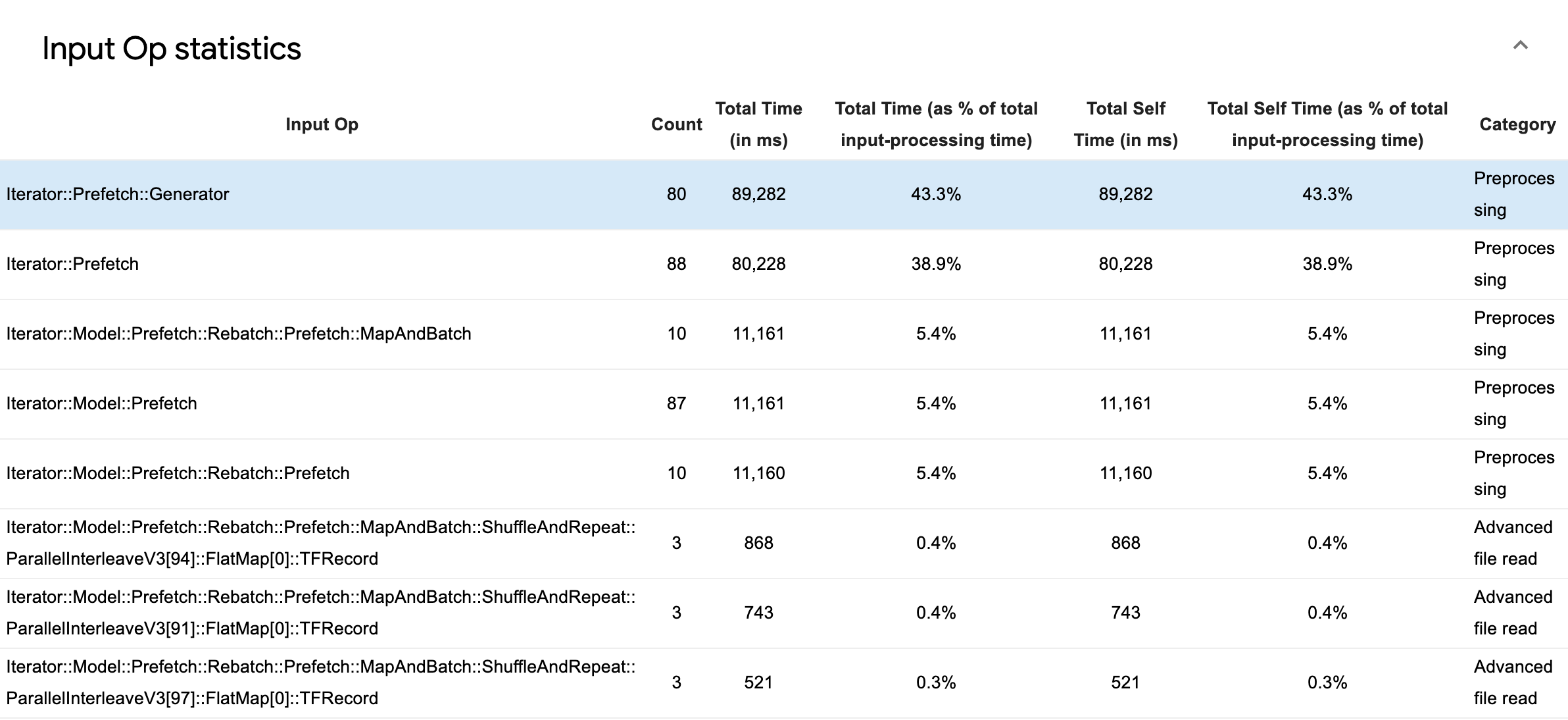
소스 데이터 표가 표시되고 각 항목에는 다음 정보가 포함됩니다.
- 입력 연산: 입력 연산의 TensorFlow 연산 이름을 표시합니다.
- 카운트: 프로파일링 기간 동안 연산 실행의 총 인스턴스 수를 표시합니다.
- 총 시간(밀리 초): 이러한 각 인스턴스에 소요된 시간의 누적 합계를 보여줍니다.
- 총 시간 %: 연산에 소요된 총 시간을 입력 처리에 소요된 총 시간의 분율로 표시합니다.
- 총 자체 시간(밀리 초) - 각 인스턴스에 소요된 자체 시간의 누적 합계를 표시합니다. 여기에서 자체 시간은 호출하는 함수에서 소비한 시간을 제외하고 함수 본문 내에서 소비된 시간을 측정합니다.
- 총 자체 시간 %. 총 자체 시간을 입력 처리에 소요 된 총 시간의 일부로 표시합니다.
- 범주: 입력 연산의 처리 범주를 표시합니다.
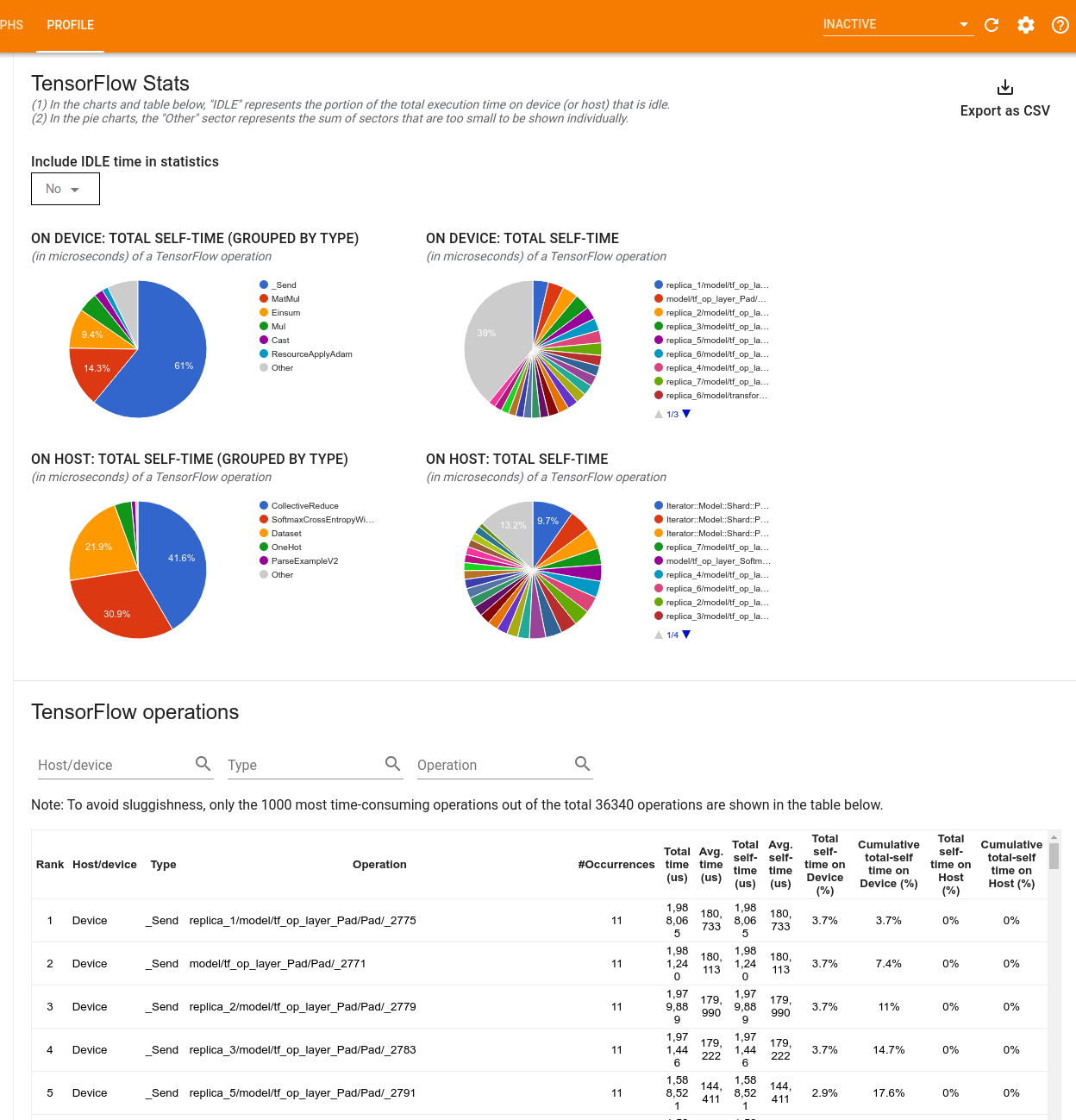
TensorFlow 통계
TensorFlow 통계 도구는 프로파일링 세션 동안 호스트 또는 기기에서 실행되는 모든 TensorFlow 연산(op)의 성능을 표시합니다.
이 도구는 성능 정보를 두 개의 창에서 표시합니다.
상단 창에는 최대 4개의 파이 차트가 표시됩니다.
- 호스트에서 각 연산의 자체 실행 시간 분포
- 호스트에서 각 연산 유형의 자체 실행 시간 분포
- 기기에서 각 연산의 자체 실행 시간 분포
- 기기에서 각 연산 유형의 자체 실행 시간 분포
하단 창에 표시되는 표에는 TensorFlow 연산에 대한 데이터를 보고합니다. 행에는 연산별로, 열에는 데이터 유형별로 표시됩니다(열의 제목을 클릭하여 정렬). 상단 창의 오른쪽에 있는 CSV로 내보내기 버튼을 클릭하여 테이블의 데이터를 CSV 파일로 내보낼 수 있습니다.
참고:
어떤 연산이 하위 연산을 포함하는 경우:
- 연산의 총 "누적" 시간에는 하위 연산 내부에서 보낸 시간이 포함됩니다.
- 연산의 총 "자체" 시간에는 하위 연산 내부에서 보낸 시간이 포함되지 않습니다.
호스트에서 연산이 실행되는 경우:
- 연산에 의해 발생한 기기의 총 자체 시간 백분율은 0입니다.
- 이 연산을 포함하여 기기의 총 자체 시간 누적 백분율은 0입니다.
기기에서 연산이 실행되는 경우:
- 이 연산에 의해 발생한 호스트의 총 자체 시간 백분율은 0입니다.
- 이 연산을 포함하여 호스트의 총 자체 시간 누적 백분율은 0입니다.
파이 차트 및 테이블에서 유휴 시간을 포함하거나 제외하도록 선택할 수 있습니다.
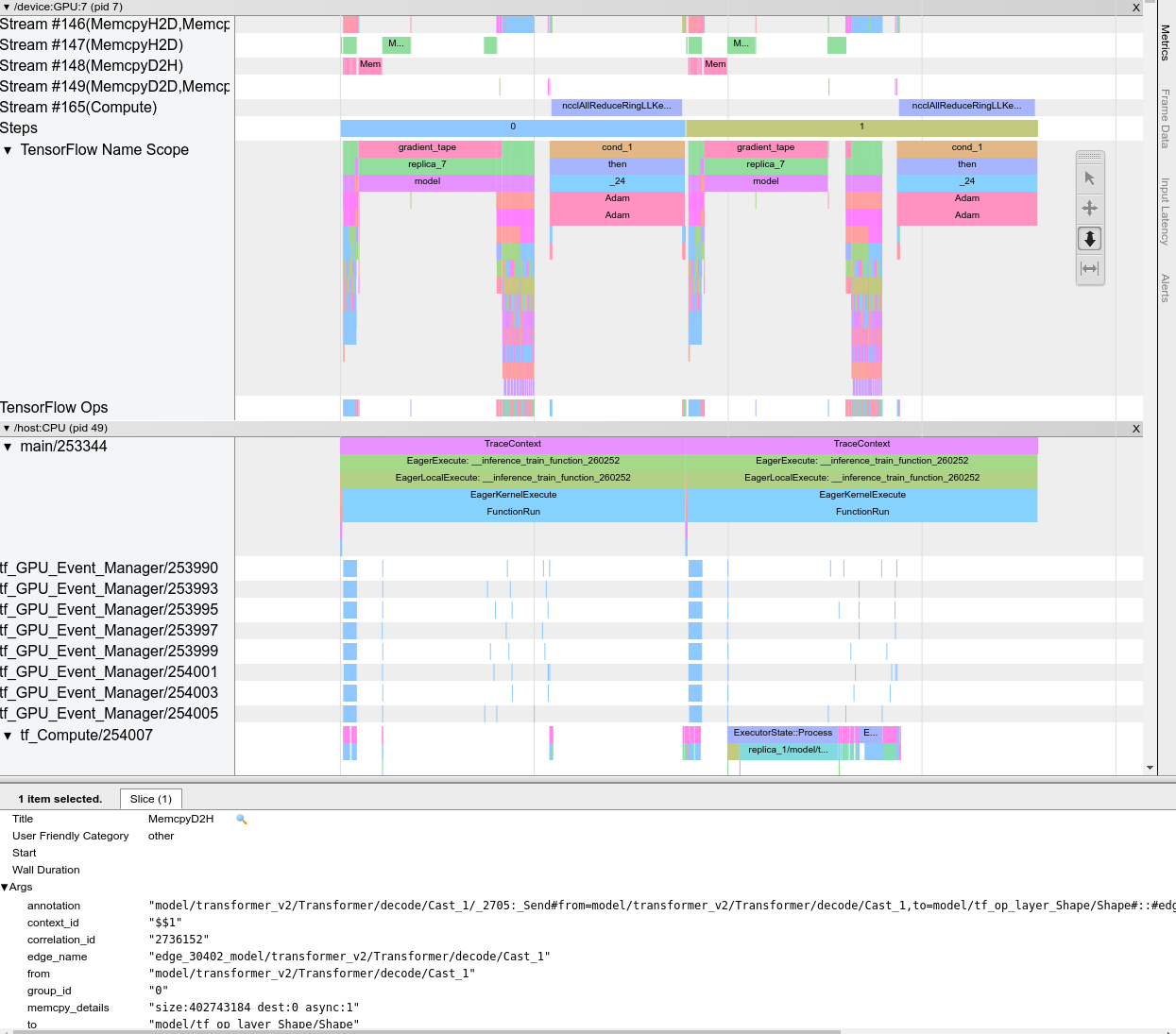
추적 뷰어
추적 뷰어의 타임라인을 통해 다음을 알 수 있습니다.
- TensorFlow 모델에 의해 실행된 연산의 기간
- 시스템의 어느 부분(호스트 또는 기기)에서 연산을 실행했는지 알 수 있습니다. 일반적으로 호스트는 입력 연산을 실행하고 학습 데이터를 사전 처리하여 기기로 전송하는 반면, 기기는 실제 모델 학습을 실행합니다.
추적 뷰어를 사용하면 모델의 성능 문제를 식별한 다음 해결을 위한 단계를 수행할 수 있습니다. 예를 들어, 입력 또는 모델 훈련에 많은 시간이 소요되는지 높은 수준에서 확인할 수 있습니다. 드릴다운하면 실행하는 데 가장 오래 걸리는 연산을 식별할 수 있습니다. 추적 뷰어는 기기당 백만 개의 이벤트로 제한됩니다.
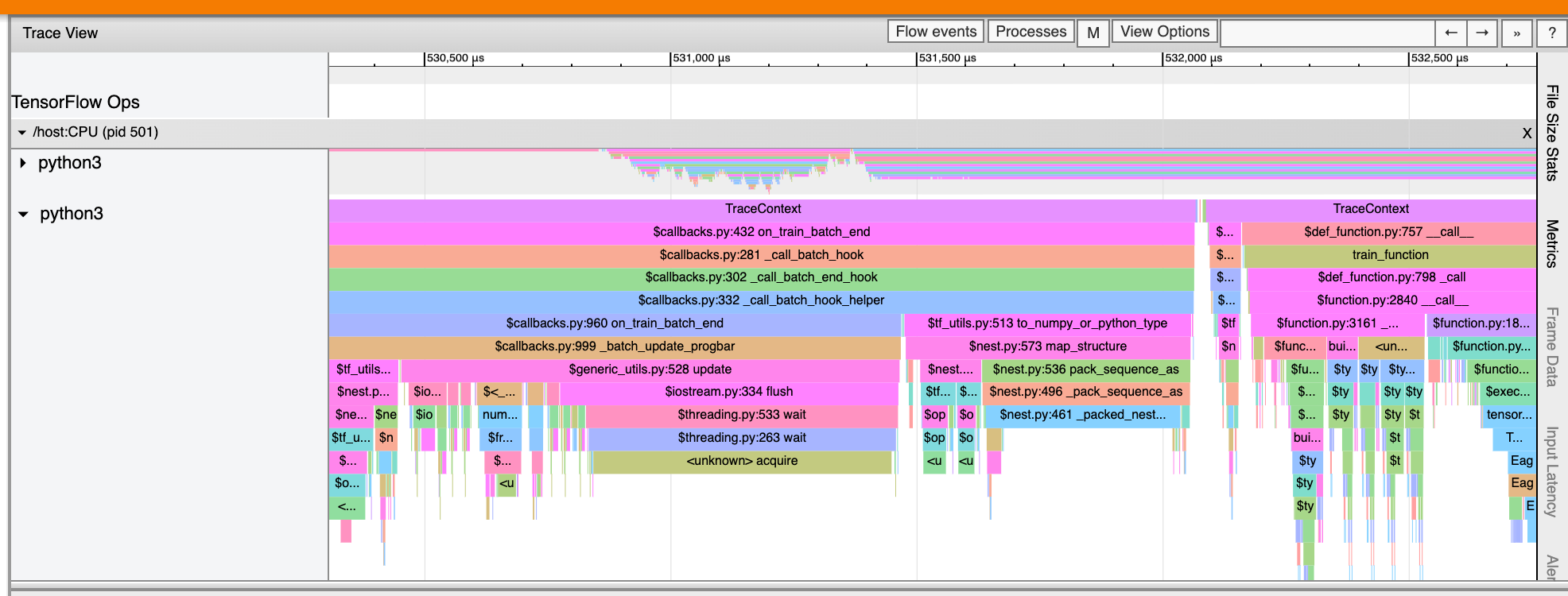
추적 뷰어 인터페이스
추적 뷰어를 열면 가장 최근에 실행된 내용이 표시됩니다.
이 화면에는 다음과 같은 주요 요소가 포함되어 있습니다.
- 타임라인 창: 기기와 호스트가 시간 경과에 따라 실행한 연산을 보여줍니다.
- 세부 정보 창: 타임라인 창에서 선택한 연산에 대해 추가 정보를 표시합니다.
타임라인 창에는 다음 요소가 포함되어 있습니다.
- 상단 바: 다양한 보조 컨트롤이 포함되어 있습니다.
- 시간 축: 추적 시작에 상대적인 시간을 표시합니다.
- 섹션 및 트랙 레이블: 각 섹션에는 여러 트랙이 있으며 왼쪽에 있는 삼각형을 클릭하여 섹션을 확장하거나 축소할 수 있습니다. 시스템의 모든 처리 요소마다 하나의 섹션이 있습니다.
- 도구 선택기: 줌, 팬, 선택 및 타이밍과 같은 추적 뷰어를 조작하기 위한 다양한 도구가 포함되어 있습니다. 타이밍 도구를 사용하여 시간 간격을 표시하세요.
- 이벤트: 여기에는 연산이 실행된 기간 또는 훈련 스텝과 같은 메타 이벤트의 기간이 표시됩니다.
섹션과 트랙
추적 뷰어에는 다음 섹션이 포함되어 있습니다.
- 장치 노드별 섹션 하나, 장치 칩 번호와 칩 내 기기 노드로 표시됩니다(예를 들어,
/device:GPU:0 (pid 0)). 각 장치 노드 섹션에는 다음 트랙이 포함되어 있습니다.- 스텝: 기기에서 실행 중인 학습 스텝의 기간을 표시합니다.
- TensorFlow 연산: 기기에서 실행된 연산을 표시합니다.
- XLA 연산 - XLA 컴파일러가 사용된 경우에는 기기에서 실행된 XLA 연산(ops)을 표시합니다. (각 TensorFlow 연산은 하나 또는 여러 개의 XLA 연산으로 변환됩니다. XLA 컴파일러는 XLA 연산을 기기에서 실행되는 코드로 변환합니다.)
- 호스트 머신의 CPU에서 실행되는 스레드에 대한 섹션 하나, "Host Threads"로 표시됩니다. 이 섹션에는 CPU 스레드마다 하나의 트랙이 있습니다. 섹션 레이블과 함께 표시되는 정보는 무시해도 됩니다.
이벤트
타임라인 내의 이벤트는 다른 색상으로 표시됩니다. 색상 자체는 특별한 의미가 없습니다.
추적 뷰어는 TensorFlow 프로그램에서 Python 함수 호출의 추적을 표시할 수도 있습니다. tf.profiler.experimental.start() API를 사용하는 경우 프로파일링을 시작할 때 ProfilerOptions라는 튜플을 사용하여 Python 추적을 사용할 수 있습니다. 또는 프로파일링에 샘플링 모드를 사용하는 경우, Capture Profile 대화 상자의 드롭다운 옵션을 사용하여 추적 수준을 선택할 수 있습니다.
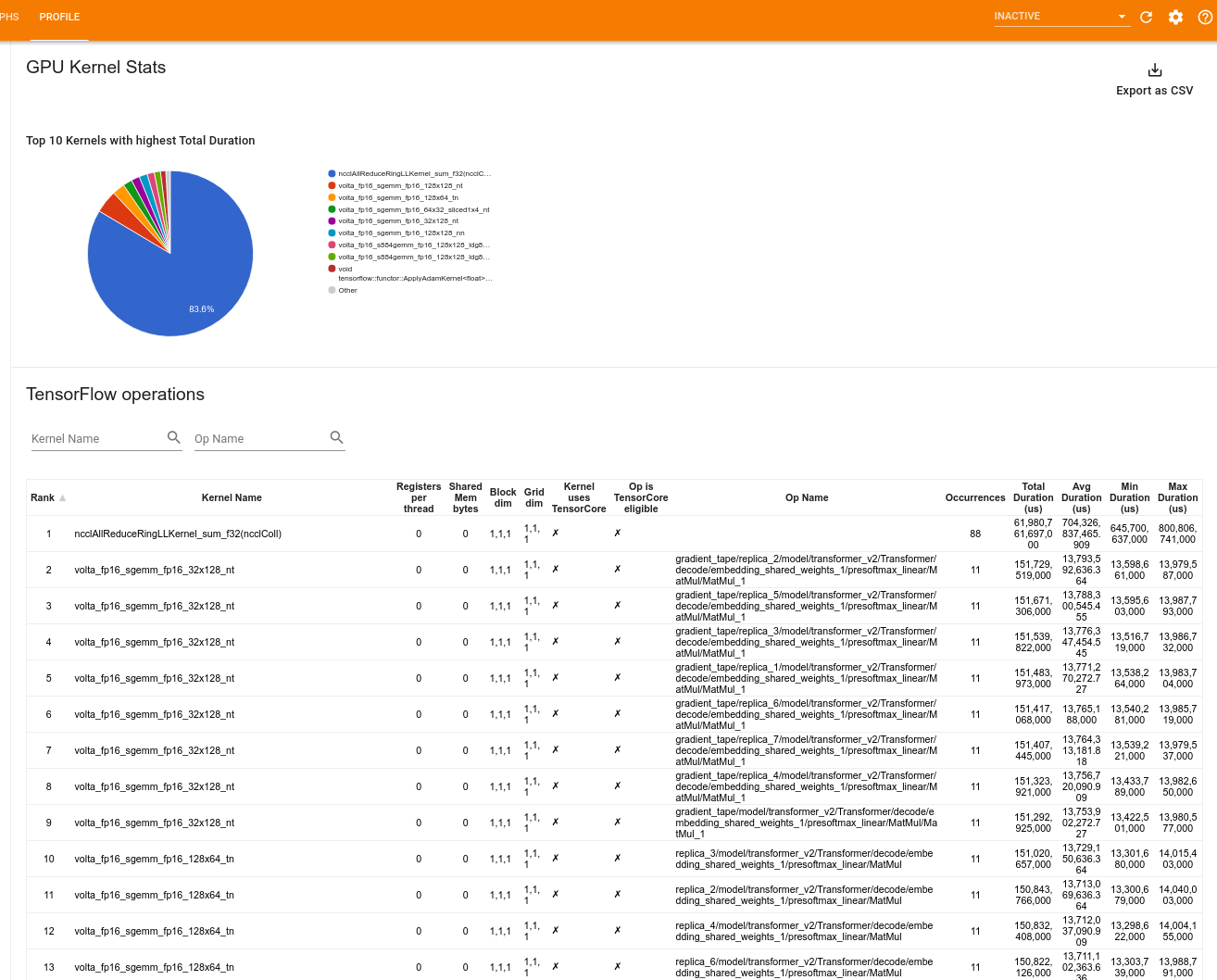
GPU 커널 통계
이 도구는 모든 GPU 가속 커널에 대한 성능 통계 및 원래 op를 보여줍니다.
이 도구는 두 개의 창에서 정보를 표시합니다.
상단 창에는 총 시간이 가장 높은 CUDA 커널을 보여주는 파이 차트가 표시됩니다.
하단 창에 표시되는 표에서는 각 고유 커널-연산 쌍에 대한 다음 데이터가 표시됩니다.
- 총 경과 GPU 기간을 kernel-op 쌍으로 그룹화하여 내림차순으로 나타낸 순위
- 시작된 커널의 이름
- 커널이 사용하는 GPU 레지스터의 수
- 사용된 공유(정적 + 동적 공유) 메모리의 총 크기(바이트 단위)
blockDim.x, blockDim.y, blockDim.z로 표현된 블록 차원- code0}gridDim.x, gridDim.y, gridDim.z로 표현된 그리드 차원
- 연산이 Tensor Cores를 사용할 수 있는지 여부
- 커널에 TensorCore 명령어가 포함되어 있는지 여부
- 이 커널을 시작한 연산의 이름
- 이 커널-연산 쌍의 발생 횟수
- 총 GPU 경과 시간(마이크로 초)
- 평균 GPU 경과 시간(마이크로 초)
- 최소 GPU 경과 시간(마이크로 초)
- 최대 GPU 경과 시간(마이크로 초)
메모리 프로파일 도구
메모리 프로파일 도구는 프로파일링 기간 동안 기기의 메모리 사용량을 모니터링합니다. 이 도구를 사용하여 다음을 수행할 수 있습니다.
- 최대 메모리 사용량과 TensorFlow 연산에 대한 해당 메모리 할당량을 정확히 찾아내 메모리 부족(OOM) 문제를 디버그합니다. 다중 테넌시 추론을 실행할 때 발생할 수 있는 OOM 문제를 디버깅할 수도 있습니다.
- 메모리 조각화 문제를 디버깅합니다.
메모리 프로파일 도구는 다음 세 섹션으로 데이터를 표시합니다.
- 메모리 프로파일 요약
- 메모리 타임라인 그래프
- 메모리 분석 표
메모리 프로파일 요약
이 섹션에는 아래와 같이 TensorFlow 프로그램의 메모리 프로파일에 대한 높은 수준의 요약이 표시됩니다.
<img src="./images/tf_profiler/memory_profile_summary.png" width="400", height="450">
메모리 프로파일 요약에는 6개의 필드가 있습니다.
- 메모리 ID: 사용 가능한 모든 기기 메모리 시스템을 나열하는 드롭다운입니다. 드롭다운에서 보려는 메모리 시스템을 선택합니다.
- #할당: 프로파일링 기간 동안 이루어진 메모리 할당의 수입니다.
- #할당 해제: 프로파일링 기간에 메모리 할당이 해제된 수입니다.
- 메모리 용량: 선택한 메모리 시스템의 총 용량(GiB)입니다.
- 최대 힙 사용량: 모델 실행을 시작한 이후의 최대 메모리 사용량(GiB)입니다.
- 최대 메모리 사용량: 프로파일링 기간의 최대 메모리 사용량(GiB)입니다. 이 필드에는 다음 하위 필드가 있습니다.
- 타임스탬프: 타임라인 그래프에서 최대 메모리 사용량이 발생한 타임스탬프입니다.
- 스택 예약: 스택에 예약된 메모리의 양(GiB)입니다.
- 힙 할당: 힙에 할당된 메모리 양(GiB)입니다.
- 사용 가능한 메모리: 사용 가능한 메모리의 양(GiB)입니다. 메모리 용량은 스택 예약, 힙 할당 및 사용 가능한 메모리의 합계입니다.
- 조각화: 조각화 비율입니다(낮을수록 좋음). (1 - 여유 메모리의 가장 큰 청크 크기/총 여유 메모리)의 백분율로 계산됩니다.
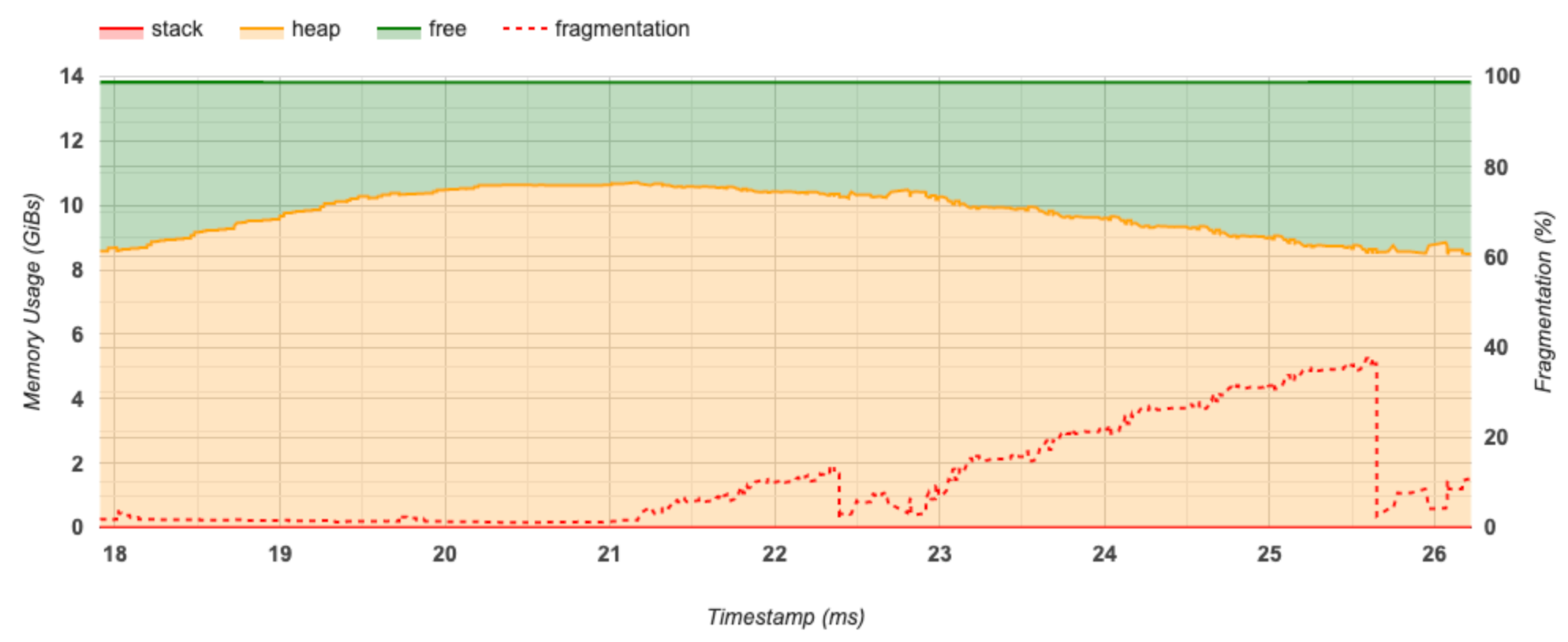
메모리 타임라인 그래프
이 섹션에는 메모리 사용량(GiB) 및 시간에 따른 조각화 비율(ms)이 표시됩니다.
X축은 프로파일링 기간의 타임라인(ms)을 나타냅니다. 왼쪽의 Y축은 메모리 사용량(GiB)을 나타내고 오른쪽의 Y축은 조각화 비율을 나타냅니다. X축의 각 시점에서 총 메모리는 스택(빨간색), 힙(주황색) 및 여유(녹색)의 세 가지 범주로 분류됩니다. 특정 타임스탬프 위로 마우스를 가져가면 아래와 같이 해당 시점의 메모리 할당/할당 해제 이벤트에 대한 세부 정보를 볼 수 있습니다.
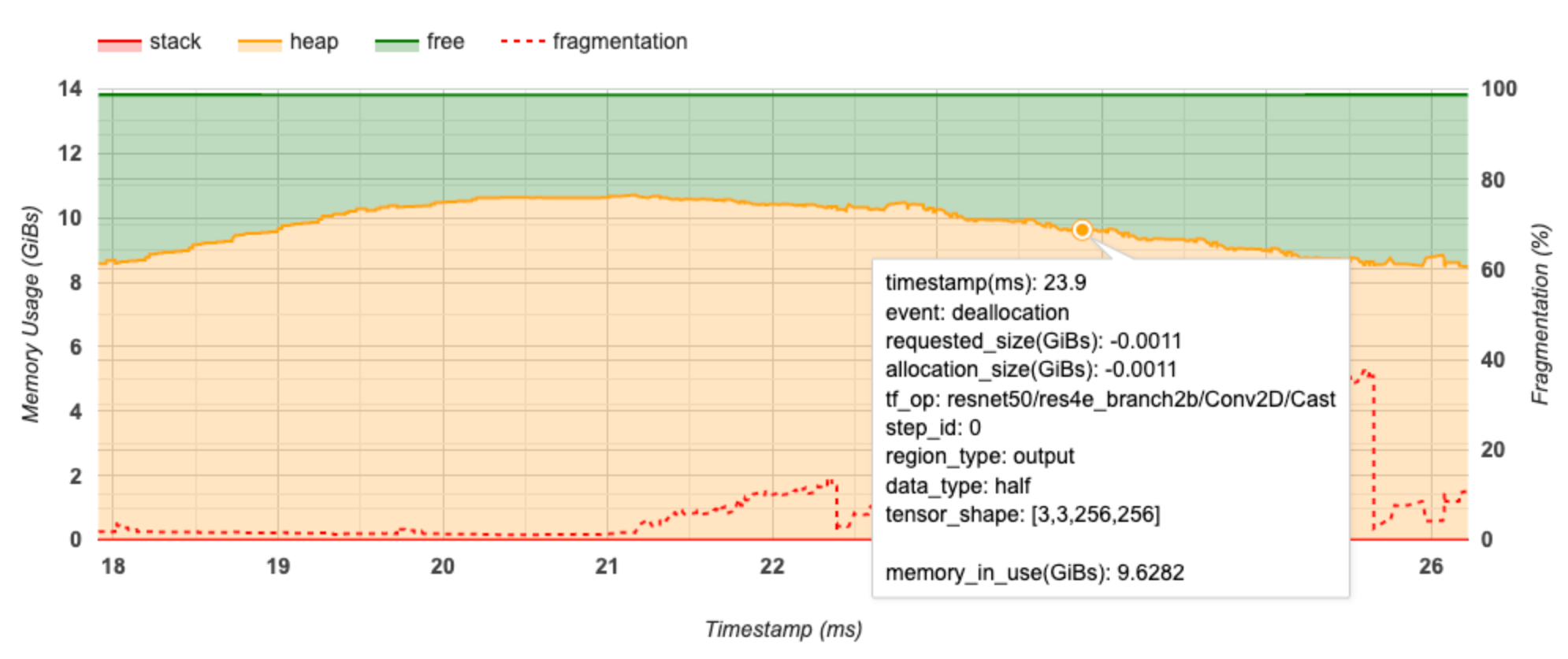
팝업 창에 다음 정보가 표시됩니다.
- 타임스탬프(ms): 타임라인에서 선택한 이벤트의 위치입니다.
- 이벤트: 이벤트 유형(할당 또는 할당 해제)입니다.
- 요청된 크기(GiB): 요청된 메모리의 양입니다. 할당 해제 이벤트의 경우 음수가 됩니다.
- 할당 크기(GiB): 할당된 메모리의 실제 양입니다. 할당 해제 이벤트의 경우 음수가 됩니다.
- tf_op: 할당/할당 해제를 요청하는 TensorFlow 연산입니다.
- 스텝 ID: 이 이벤트가 발생한 학습 스텝입니다.
- 영역 유형: 이 할당된 메모리의 대상인 데이터 엔터티 유형입니다. 가능한 값은 임시의 경우
temp, 활성화와 그래디언트의 경우output, 가중치와 상수의 경우persist/dynamic입니다. - 데이터 유형: 텐서 요소의 유형(예: 8bit 부호없는 정수의 경우 uint8)입니다.
- 텐서 형상: 할당/할당 해제되는 텐서의 형상입니다.
- 사용 중 메모리(GiB): 이 시점에서 사용 중인 총 메모리의 양입니다.
메모리 분석 표
이 표에는 프로파일링 기간 동안 최대 메모리 사용량 시점에서 활성 메모리 할당량이 표시됩니다.

TensorFlow 연산마다 하나의 행이 있으며 각 행에는 다음 열이 있습니다.
- 연산 이름: TensorFlow 연산의 이름입니다.
- 할당 크기(GiB): 이 연산에 할당된 총 메모리의 양입니다.
- 요청된 크기(GiB): 이 연산에 대해 요청된 총 메모리의 양입니다.
- 발생 수: 이 연산에 대한 할당 수입니다.
- 영역 유형: 이 할당된 메모리의 대상인 데이터 엔터티 유형입니다. 가능한 값은 임시의 경우
temp, 활성화와 그래디언트의 경우output, 가중치와 상수의 경우persist/dynamic입니다. - 데이터 유형: 텐서 요소의 유형입니다.
- 형상: 할당된 텐서의 형상입니다.
참고: 테이블의 모든 열을 정렬하고 op 이름을 기준으로 행을 필터링할 수도 있습니다.
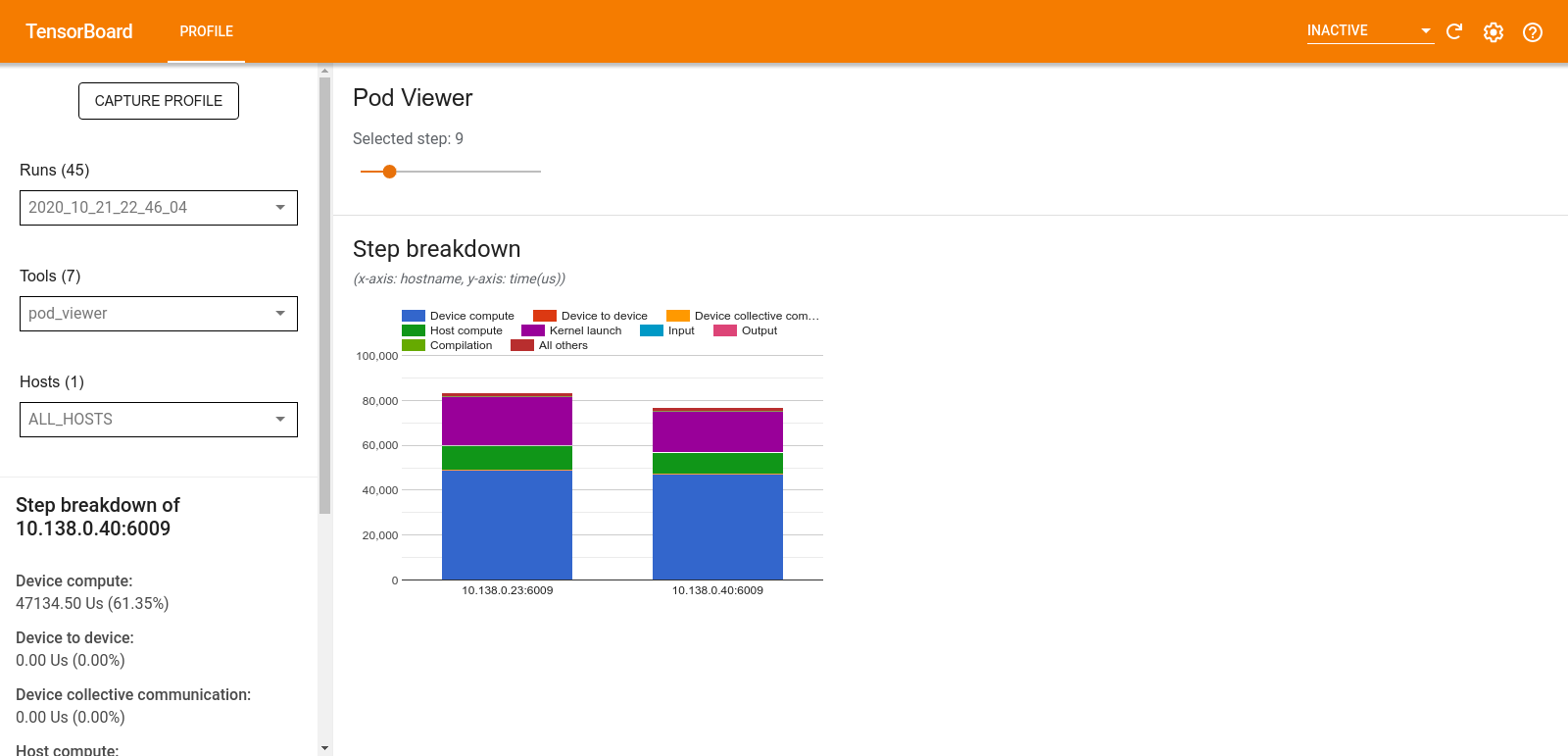
Pod 뷰어
Pod 뷰어 도구는 모든 작업자의 학습 스텝 분석을 보여줍니다.
- 상단 창에는 스텝 번호를 선택하는 슬라이더가 있습니다.
- 아래쪽 창에는 누적 세로 막대형 차트가 표시됩니다. 이것은 분류된 스텝 시간 범주를 서로의 위에 배치한 고차원적인 보기입니다. 누적된 각 열은 고유한 작업자를 나타냅니다.
- 누적된 열 위로 마우스를 가져가면 왼쪽의 카드에 스텝 분류에 대한 자세한 내용이 표시됩니다.
tf.data 병목 현상 분석
경고: 이 도구는 실험적입니다. 분석 결과가 잘못된 것 같으면 GitHub 이슈를 개설해 주세요.
tf.data 병목 현상 분석 도구는 프로그램의 tf.data 입력 파이프라인에서 병목 현상을 자동으로 감지하고, 이를 해결하는 방법에 대한 권장 사항을 제공합니다. 플랫폼(CPU/GPU/TPU)에 관계없이 tf.data를 사용하는 모든 프로그램에서 작동합니다. 분석 및 권장 사항은 이 가이드를 바탕으로 합니다.
다음 단계에 따라 병목 현상을 감지합니다.
- 입력된 가장 많은 호스트를 찾습니다.
tf.data입력 파이프라인의 가장 느린 실행을 찾습니다.- 프로파일러 추적에서 입력 파이프라인 그래프를 재구성합니다.
- 입력 파이프라인 그래프에서 임계 경로를 찾습니다.
- 중요 경로에서 가장 느린 변환을 병목 현상으로 식별합니다.
UI는 성능 분석 요약, 모든 입력 파이프라인 요약 및 입력 파이프라인 그래프의 세 부분으로 나뉩니다.
성능 분석 요약
이 섹션에서는 분석 요약을 제공합니다. 프로파일에서 느린 tf.data 입력 파이프라인이 감지되는지 여부가 보고됩니다. 이 섹션에는 또한 입력 바운드가 가장 큰 호스트와 지연 시간이 가장 큰 가장 느린 입력 파이프라인이 표시됩니다. 그리고 가장 중요한 부분으로, 입력 파이프라인의 어느 부분이 병목인지, 이 병목을 해결할 방법을 알려줍니다. 병목 현상 정보는 반복기 유형과 해당하는 긴 이름과 함께 제공됩니다.
tf.data 반복기의 긴 이름을 읽는 방법
긴 이름은 Iterator::<Dataset_1>::...::<Dataset_n> 형식으로 지정됩니다. 긴 이름에서 <Dataset_n>은 반복기 유형과 일치하고, 긴 이름의 다른 데이터세트는 다운스트림 변환을 나타냅니다.
예를 들어 다음 입력 파이프라인 데이터세트를 고려해 보겠습니다.
dataset = tf.data.Dataset.range(10).map(lambda x: x).repeat(2).batch(5)
위 데이터세트의 반복기에 대한 긴 이름은 다음과 같습니다.
| 반복기 유형 | 긴 이름 |
|---|---|
| 범위 | Iterator::Batch::Repeat::Map::Range |
| 맵 | Iterator::Batch::Repeat::Map |
| 반복 | Iterator::Batch::Repeat |
| 배치 | Iterator::Batch |
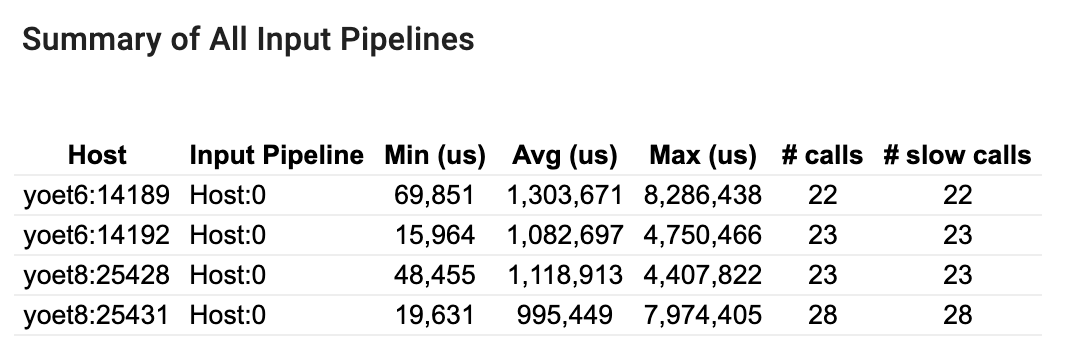
모든 입력 파이프라인 요약
이 섹션에서는 모든 호스트의 모든 입력 파이프라인에 대한 요약을 제공합니다. 일반적으로 하나의 입력 파이프라인이 있습니다. 배포 전략을 사용하는 경우, 프로그램의 tf.data 코드를 실행하는 하나의 호스트 입력 파이프라인과 호스트 입력 파이프라인에서 데이터를 검색하여 장치로 전송하는 여러 개의 장치 입력 파이프라인이 있습니다.
각 입력 파이프라인에 대해 실행 시간의 통계가 표시됩니다. 호출이 50μs 이상 오래 걸리면 느린 것으로 간주됩니다.
입력 파이프라인 그래프

이 섹션에서는 실행 시간 정보와 함께 입력 파이프라인 그래프가 표시됩니다. "호스트" 및 "입력 파이프라인"을 사용하여 보려는 호스트와 입력 파이프라인을 선택할 수 있습니다. 입력 파이프라인의 실행은 실행 시간을 기준으로 정렬되며, Rank 드롭다운을 사용하여 내림차순으로 정렬할 수 있습니다.

중요 경로의 노드에는 굵은 윤곽선이 있습니다. 중요 경로에서 가장 긴 자체 시간을 가진 노드인 병목 노드는 빨간색 윤곽선으로 표시됩니다. 중요하지 않은 다른 노드에는 회색 점선 윤곽선이 있습니다.
각 노드에서 시작 시간은 실행 시작 시간을 나타냅니다. 예를 들어, 입력 파이프라인에 Batch 연산자가 있는 경우 동일한 노드가 여러 번 실행될 수 있습니다. 여러 번 실행되는 경우에 시작 시간은 첫 실행의 시작 시간입니다.
전체 지속 시간은 실행의 벽 시간입니다. 여러 번 실행되는 경우에 전체 지속 시간은 모든 실행의 벽 시간 합계입니다.
자체 시간은 바로 이어진 하위 노드와 겹치는 시간을 제외한 전체 시간입니다.
"# 호출"은 입력 파이프라인이 실행된 횟수입니다.
성능 데이터 수집
TensorFlow 프로파일러는 TensorFlow 모델의 호스트 활동 및 GPU 추적을 수집합니다. 프로그래밍 모드 또는 샘플링 모드를 통해 성능 데이터를 수집하도록 프로파일러를 구성할 수 있습니다.
프로파일링 API
다음 API를 사용하여 프로파일링을 수행할 수 있습니다.
TensorBoard Keras 콜백(
tf.keras.callbacks.TensorBoard)을 사용하는 프로그래밍 모드# Profile from batches 10 to 15 tb_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, profile_batch='10, 15') # Train the model and use the TensorBoard Keras callback to collect # performance profiling data model.fit(train_data, steps_per_epoch=20, epochs=5, callbacks=[tb_callback])tf.profiler함수 API를 사용하는 프로그래밍 모드tf.profiler.experimental.start('logdir') # Train the model here tf.profiler.experimental.stop()컨텍스트 관리자를 사용하는 프로그래밍 모드
with tf.profiler.experimental.Profile('logdir'): # Train the model here pass
참고: 프로파일러를 너무 오래 실행하면 메모리가 부족해질 수 있습니다. 한 번에 10개 스텝을 초과하지 않는 것이 좋습니다. 초기화 오버헤드로 인한 부정확성을 피하려면 처음 몇 개의 배치를 프로파일링하지 마세요.
샘플링 모드:
tf.profiler.experimental.server.start를 사용하여 주문형 프로파일링을 수행하여 TensorFlow 모델이 실행된 상태에서 gRPC 서버를 시작합니다. gRPC 서버를 시작하고 모델을 실행한 후 TensorBoard 프로파일 플러그인의 Capture Profile 버튼을 통해 프로파일을 캡처할 수 있습니다. TensorBoard 인스턴스를 아직 실행하고 있지 않다면 위의 프로파일러 설치 섹션에 있는 스크립트를 사용하여 실행합니다.예를 들면 다음과 같습니다.
# Start a profiler server before your model runs. tf.profiler.experimental.server.start(6009) # (Model code goes here). # Send a request to the profiler server to collect a trace of your model. tf.profiler.experimental.client.trace('grpc://localhost:6009', 'gs://your_tb_logdir', 2000)여러 작업자를 프로파일링하는 예:
# E.g. your worker IP addresses are 10.0.0.2, 10.0.0.3, 10.0.0.4, and you # would like to profile for a duration of 2 seconds. tf.profiler.experimental.client.trace( 'grpc://10.0.0.2:8466,grpc://10.0.0.3:8466,grpc://10.0.0.4:8466', 'gs://your_tb_logdir', 2000)
<img src="./images/tf_profiler/capture_profile.png" width="400", height="450">
Capture Profile 대화 상자를 사용하여 다음을 지정합니다.
- 쉼표로 구분된 프로파일 서비스 URL 또는 TPU 이름의 목록
- 프로파일링 기간
- 기기, 호스트 및 Python 함수 호출 추적의 수준
- 처음에 실패한 경우, Profiler가 프로파일 캡처를 재시도하는 횟수
사용자 정의 훈련 루프 프로파일링
TensorFlow 코드에서 사용자 지정 훈련 루프를 프로파일링하려면 tf.profiler.experimental.Trace API로 훈련 루프를 계측하여 프로파일러의 스텝 경계를 표시합니다.
name 인수는 스텝 이름에 대한 접두사로 사용되고 step_num 키워드 인수는 스텝 이름에 추가되며 _r 키워드 인수는 이 추적 이벤트가 프로파일러에 의해 스텝 이벤트로 처리되도록 합니다.
예를 들면 다음과 같습니다.
for step in range(NUM_STEPS):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_data = next(dataset)
train_step(train_data)
Profiler의 스텝 기반 성능 분석이 활성화되고 스텝 이벤트가 추적 뷰어에 표시됩니다.
입력 파이프라인을 정확히 분석하려면 tf.profiler.experimental.Trace 컨텍스트 내에 데이터세트 반복기를 포함시켜야 합니다.
아래 코드 조각은 안티 패턴입니다.
경고: 이로 인해 입력 파이프라인이 부정확하게 분석됩니다.
for step, train_data in enumerate(dataset):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_step(train_data)
프로파일링 사용 사례
Profiler는 4가지 축을 따라 여러 가지 사용 사례를 다룹니다. 일부 조합은 현재 지원되며 다른 조합은 향후에 추가될 예정입니다. 사용 사례 중 일부는 다음과 같습니다.
- 로컬 및 원격 프로파일링: 프로파일링 환경을 설정하는 일반적인 두 가지 방법입니다. 로컬 프로파일링에서 프로파일링 API는 모델이 실행 중인 같은 시스템(예: GPU가 있는 로컬 워크스테이션)에서 호출됩니다. 원격 프로파일링에서 프로파일링 API는 모델이 실행 중인 다른 시스템(예: Cloud TPU)에서 호출됩니다.
- 여러 작업자 프로파일링: TensorFlow의 분산 훈련 기능을 사용할 때 여러 머신을 프로파일링할 수 있습니다.
- 하드웨어 플랫폼: CPU, GPU 및 TPU를 프로파일링합니다.
아래 표는 위에서 언급한 TensorFlow 지원 사용 사례에 대한 간략한 개요를 제공합니다.
| 프로파일링 API | 로컬 | 원격 | 다중 | 하드웨어 | : : : : 작업자 : 플랫폼 : | :--------------------------- | :-------- | :-------- | :-------- | :-------- | | TensorBoard Keras | 지원됨 | 아님 | 아님 | CPU, GPU | : Callback : : 지원됨 : 지원됨 : : | tf.profiler.experimental | 지원됨 | 아님 | 아님 | CPU, GPU | : start/stop API : : 지원됨 : 지원됨 : : | tf.profiler.experimental | 지원됨 | 지원됨 | 지원됨 | CPU, GPU, | : client.trace API : : : : TPU : | Context manager API | 지원됨 | 아님 | 아님 | CPU, GPU | : : : 지원됨 : 지원됨 : :
최적의 모델 성능을 위한 모범 사례
최적의 성능을 얻으려면 TensorFlow 모델에 적용 가능한 다음 권장 사항을 사용하세요.
일반적으로 기기에서 모든 변환을 수행하고 플랫폼에 맞는 최신 호환 버전의 라이브러리(cuDNN, Intel MKL 등)를 사용해야 합니다.
입력 데이터 파이프라인의 최적화
[#input_pipeline_analyzer]의 데이터를 사용하여 데이터 입력 파이프라인을 최적화하세요. 효율적인 데이터 입력 파이프라인은 장치 유휴 시간을 줄여 모델 실행 속도를 크게 향상시킬 수 있습니다. tf.data API로 성능 향상 가이드와 아래에서 자세히 설명하는 모범 사례를 도입하여 데이터 입력 파이프라인을 보다 효율적으로 만드세요.
일반적으로, 순차적으로 실행할 필요가 없는 연산을 병렬화하면 데이터 입력 파이프라인을 크게 최적화할 수 있습니다.
많은 경우에 해당 모델에 가장 적합하게 일부 호출의 순서를 변경하거나 인수를 조정하는 것이 도움이 됩니다. 입력 데이터 파이프라인을 최적화하는 동안 훈련 및 역전파 단계 없이 데이터 로더만 벤치마킹하여 최적화의 효과를 독립적으로 수량화하세요.
합성 데이터로 모델을 실행하여 입력 파이프라인이 성능 병목인지 확인하세요.
다중 GPU 교육에
tf.data.Dataset.shard를 사용하세요. 처리량 감소를 방지하기 위해 입력 루프에서 매우 초기에 샤딩을 해야 합니다. TFRecord로 작업할 때 TFRecord의 내용이 아니라 TFRecord의 목록을 샤딩해야 합니다.tf.data.AUTOTUNE를 사용하여num_parallel_calls의 값을 동적으로 설정하여 여러 연산을 병렬화합니다.tf.data.Dataset.from_generator는 순수 TensorFlow 연산에 비해 느리므로 사용을 제한하는 것이 좋습니다.tf.py_function은 직렬화할 수 없고 분산된 TensorFlow에서 실행이 지원되지 않으므로 사용을 제한하는 것이 좋습니다.tf.data.Options를 사용하여 입력 파이프라인에 대한 정적 최적화를 제어합니다.
또한 입력 파이프라인 최적화에 대한 자세한 지침은 tf.data 성능 분석 가이드를 참조하세요.
데이터 증강 최적화
이미지 데이터로 작업할 때 뒤집기, 자르기, 회전 등과 같은 공간 변환을 적용한 후 다른 데이터 유형으로 캐스팅하여 데이터 증강을 보다 효율적으로 만드세요.
참고: tf.image.resize와 같은 일부 연산은 dtype을 fp32로 투명하게 변경합니다. 자동으로 수행되지 않는 경우 0과 1 사이에 있도록 데이터를 정규화하세요. AMP를 활성화한 경우 이 단계를 건너뛰면 NaN 오류가 발생할 수 있습니다.
NVIDIA® DALI 사용하기
GPU 대 CPU 비율이 높은 시스템과 같은 일부의 경우에 위의 모든 최적화가 CPU 주기의 제한으로 인해 발생하는 데이터 로더의 병목 현상을 제거하기에 충분하지 않을 수 있습니다.
컴퓨터 비전 및 오디오 딥러닝 애플리케이션에 NVIDIA® GPU를 사용하는 경우, 데이터 로딩 라이브러리(DALI)를 사용하여 데이터 파이프라인을 가속화하는 것이 좋습니다.
지원되는 DALI 연산 목록은 NVIDIA® DALI: 연산 설명서를 확인하세요.
스레딩 및 병렬 실행 사용하기
tf.config.threading API를 사용하여 여러 CPU 스레드에서 연산을 실행하여 연산을 더 빠르게 실행합니다.
TensorFlow는 기본적으로 병렬 처리 스레드 수를 자동으로 설정합니다. TensorFlow 연산을 실행하는 데 사용할 수 있는 스레드 풀은 사용 가능한 CPU 스레드 수에 따라 다릅니다.
tf.config.threading.set_intra_op_parallelism_threads를 사용하여 단일 연산에 대한 최대 병렬 속도 향상을 제어합니다. 여러 연산을 병렬로 실행하는 경우, 모두 사용 가능한 스레드 풀을 공유합니다.
독립적인 비차단 연산(그래프에서 연산 사이에 방향이 없는 연산)이 있는 경우, tf.config.threading.set_inter_op_parallelism_threads를 사용하여 사용 가능한 스레드 풀을 통해 이러한 연산을 동시에 실행합니다.
기타
NVIDIA® GPU에서 더 작은 모델로 작업하는 경우, tf.compat.v1.ConfigProto.force_gpu_compatible=True를 설정하여 모든 CPU 텐서가 CUDA 고정 메모리와 함께 할당되도록 하여 모델 성능을 크게 향상시킬 수 있습니다. 그러나 호스트(CPU) 성능에 부정적인 영향을 미칠 수 있으므로 알 수 없는/매우 큰 모델에 이 옵션을 사용할 때는 주의를 기울이세요.
기기 성능 향상하기
본 내용과 GPU 성능 최적화 가이드에 자세히 설명된 모범 사례에 따라 장치 내 TensorFlow 모델 성능을 최적화하세요.
NVIDIA GPU를 사용하는 경우, 다음을 실행하여 GPU 및 메모리 사용률을 CSV 파일에 기록합니다.
nvidia-smi
--query-gpu=utilization.gpu,utilization.memory,memory.total,
memory.free,memory.used --format=csv
데이터 레이아웃 구성하기
채널 정보(예: 이미지)가 포함된 데이터로 작업하는 경우, 채널을 마지막으로 선호하도록 데이터 레이아웃 형식을 최적화하세요(NCHW보다 NHWC를 선호).
마지막 채널 데이터 형식은 Tensor Core 활용도를 향상시키고 특히 AMP와 결합 시, 컨볼루션 모델에서 상당한 성능 향상을 제공합니다. NCHW 데이터 레이아웃은 여전히 Tensor Core에 의해 작동할 수 있지만 자동 전치 작업으로 인해 추가 오버헤드가 발생합니다.
tf.keras.layers.Conv2D, tf.keras.layers.Conv3D 및 tf.keras.layers.RandomRotation과 같은 레이어에 대해 data_format="channels_last"를 설정하여 NHWC 레이아웃을 선호하도록 데이터 레이아웃을 최적화할 수 있습니다.
tf.keras.backend.set_image_data_format을 사용하여 Keras 백엔드 API의 기본 데이터 레이아웃 형식을 설정합니다.
L2 캐시 최대화하기
NVIDIA® GPU로 작업할 때 훈련 루프 전에 아래 코드 스니펫을 실행하여 L2 가져오기 단위를 128바이트로 최대화합니다.
import ctypes
_libcudart = ctypes.CDLL('libcudart.so')
# Set device limit on the current device
# cudaLimitMaxL2FetchGranularity = 0x05
pValue = ctypes.cast((ctypes.c_int*1)(), ctypes.POINTER(ctypes.c_int))
_libcudart.cudaDeviceSetLimit(ctypes.c_int(0x05), ctypes.c_int(128))
_libcudart.cudaDeviceGetLimit(pValue, ctypes.c_int(0x05))
assert pValue.contents.value == 128
GPU 스레드 사용량 구성하기
GPU 스레드 모드는 GPU 스레드가 사용되는 방식을 결정합니다.
전처리로 모든 GPU 스레드가 빼앗기지 않도록 스레드 모드를 gpu_private로 설정합니다. 그러면 훈련 중 커널 실행 지연이 줄어듭니다. GPU당 스레드 수를 설정할 수도 있습니다. 환경 변수를 사용하여 이러한 값을 설정합니다.
import os
os.environ['TF_GPU_THREAD_MODE']='gpu_private'
os.environ['TF_GPU_THREAD_COUNT']='1'
GPU 메모리 옵션 구성하기
일반적으로, 배치 크기를 늘리고 모델을 확장하여 GPU를 더 잘 활용하고 더 높은 처리량을 얻습니다. 배치 크기를 늘리면 모델의 정확도가 변경되므로 학습률과 같은 하이퍼파라미터를 조정하여 목표 정확도를 충족하도록 모델을 확장해야 합니다.
또한 tf.config.experimental.set_memory_growth를 사용하여 사용 가능한 모든 메모리가 메모리의 일부만 필요한 연산에 완전히 할당되는 것을 방지하기 위해 GPU 메모리가 증가하도록 허용합니다. 이를 통해 GPU 메모리를 사용하는 다른 프로세스를 동일한 장치에서 실행할 수 있습니다.
자세히 알아보려면 GPU 가이드에서 GPU 메모리 증가 제한 지침을 확인하세요.
기타
GPU의 메모리 부족(OOM) 오류 없이 적합한 최대까지 훈련 미니 배치 크기(훈련 루프의 한 반복에서 장치당 사용되는 훈련 샘플의 수)를 늘립니다. 배치 크기를 늘리면 모델의 정확도에 영향을 미치므로 목표 정확도를 충족하도록 하이퍼파라미터를 조정하여 모델을 확장해야 합니다.
프로덕션 코드에서 텐서 할당 중 OOM 오류 보고를 비활성화합니다.
tf.compat.v1.RunOptions에서report_tensor_allocations_upon_oom=False를 설정합니다.컨볼루션 레이어가 있는 모델에서 배치 정규화를 사용하는 경우 편향 추가를 제거합니다. 배치 정규화로 인해 값이 평균만큼 이동하므로 일정한 편향 항을 가질 필요가 없습니다.
TF 통계를 사용하여 장치 내부 연산이 얼마나 효율적으로 실행되는지 확인합니다.
tf.function을 사용하여 계산을 수행하고 선택적으로jit_compile=True플래그를 지정합니다(tf.function(jit_compile=True). 자세히 알아보려면 XLA tf.function 사용하기로 이동하세요.스텝 간의 호스트 Python 연산을 최소화하고 콜백을 줄입니다. 모든 스텝이 아닌 몇 스텝마다 메트릭을 계산합니다.
기기 컴퓨팅 단위의 사용률을 높게 유지합니다.
여러 기기에 병렬로 데이터를 전송합니다.
IEEE에서 지정한 반정밀도 부동 소수점 형식인
fp16또는 Brain 부동 소수점 bfloat16 형식과 같은 16bit 숫자 표현의 사용을 고려해보세요.
추가 자료
- 이 가이드의 조언을 적용할 수 있는 Keras 및 TensorBoard를 사용한 TensorFlow Profiler: 모델 성능 프로파일링 튜토리얼
- TensorFlow Dev Summit 2020에서 개최된 TensorFlow 2의 성능 프로파일링 대담
- TensorFlow Dev Summit 2020의 TensorFlow Profiler 데모
알려진 제한 사항
TensorFlow 2.2 및 TensorFlow 2.3에서 여러 GPU 프로파일링
TensorFlow 2.2 및 2.3은 단일 호스트 시스템에 대해서만 다중 GPU 프로파일링을 지원합니다. 다중 호스트 시스템에 대한 다중 GPU 프로파일링은 지원되지 않습니다. 다중 작업자 GPU 구성을 프로파일링하려면 각 작업자를 독립적으로 프로파일링해야 합니다. TensorFlow 2.4부터는 tf.profiler.experimental.trace API를 사용하여 여러 작업자를 프로파일링할 수 있습니다.
여러 GPU를 프로파일링하려면 CUDA® Toolkit 10.2 이상이 필요합니다. TensorFlow 2.2 및 2.3은 최대 10.1까지만 CUDA® Toolkit 버전을 지원하므로 libcudart.so.10.1 및 libcupti.so.10.1에 대한 기호 링크를 들어야 합니다.
sudo ln -s /usr/local/cuda/lib64/libcudart.so.10.2 /usr/local/cuda/lib64/libcudart.so.10.1
sudo ln -s /usr/local/cuda/extras/CUPTI/lib64/libcupti.so.10.2 /usr/local/cuda/extras/CUPTI/lib64/libcupti.so.10.1