
| | |  Visualizza l'origine su GitHub Visualizza l'origine su GitHub |
Documentazione API: tf.RaggedTensor tf.ragged
Impostare
import math
import tensorflow as tf
Panoramica
I tuoi dati hanno molte forme; dovrebbero farlo anche i tuoi tensori. I tensori irregolari sono l'equivalente TensorFlow degli elenchi a lunghezza variabile nidificati. Semplificano l'archiviazione e l'elaborazione dei dati con forme non uniformi, tra cui:
- Caratteristiche a lunghezza variabile, come il set degli attori in un film.
- Lotti di input sequenziali di lunghezza variabile, come frasi o clip video.
- Input gerarchici, come documenti di testo suddivisi in sezioni, paragrafi, frasi e parole.
- Singoli campi in input strutturati, come i buffer di protocollo.
Cosa puoi fare con un tensore irregolare
I tensori irregolari sono supportati da più di cento operazioni TensorFlow, incluse operazioni matematiche (come tf.add e tf.reduce_mean ), operazioni di array (come tf.concat e tf.tile ), operazioni di manipolazione delle stringhe (come tf.substr ), operazioni di controllo del flusso (come tf.while_loop e tf.map_fn ) e molti altri:
digits = tf.ragged.constant([[3, 1, 4, 1], [], [5, 9, 2], [6], []])
words = tf.ragged.constant([["So", "long"], ["thanks", "for", "all", "the", "fish"]])
print(tf.add(digits, 3))
print(tf.reduce_mean(digits, axis=1))
print(tf.concat([digits, [[5, 3]]], axis=0))
print(tf.tile(digits, [1, 2]))
print(tf.strings.substr(words, 0, 2))
print(tf.map_fn(tf.math.square, digits))
<tf.RaggedTensor [[6, 4, 7, 4], [], [8, 12, 5], [9], []]> tf.Tensor([2.25 nan 5.33333333 6. nan], shape=(5,), dtype=float64) <tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9, 2], [6], [], [5, 3]]> <tf.RaggedTensor [[3, 1, 4, 1, 3, 1, 4, 1], [], [5, 9, 2, 5, 9, 2], [6, 6], []]> <tf.RaggedTensor [[b'So', b'lo'], [b'th', b'fo', b'al', b'th', b'fi']]> <tf.RaggedTensor [[9, 1, 16, 1], [], [25, 81, 4], [36], []]>
Esistono anche numerosi metodi e operazioni specifici per i tensori irregolari, inclusi metodi di fabbrica, metodi di conversione e operazioni di mappatura del valore. Per un elenco delle operazioni supportate, vedere la documentazione del pacchetto tf.ragged .
I tensori irregolari sono supportati da molte API TensorFlow, inclusi Keras , Datasets , tf.function , SavedModels e tf.Example . Per ulteriori informazioni, controlla la sezione sulle API TensorFlow di seguito.
Come con i normali tensori, puoi usare l'indicizzazione in stile Python per accedere a sezioni specifiche di un tensore irregolare. Per ulteriori informazioni, fare riferimento alla sezione sull'indicizzazione di seguito.
print(digits[0]) # First row
tf.Tensor([3 1 4 1], shape=(4,), dtype=int32)
print(digits[:, :2]) # First two values in each row.
<tf.RaggedTensor [[3, 1], [], [5, 9], [6], []]>
print(digits[:, -2:]) # Last two values in each row.
<tf.RaggedTensor [[4, 1], [], [9, 2], [6], []]>
E proprio come i normali tensori, puoi usare Python aritmetici e operatori di confronto per eseguire operazioni elementwise. Per ulteriori informazioni, controlla la sezione sugli operatori sovraccarichi di seguito.
print(digits + 3)
<tf.RaggedTensor [[6, 4, 7, 4], [], [8, 12, 5], [9], []]>
print(digits + tf.ragged.constant([[1, 2, 3, 4], [], [5, 6, 7], [8], []]))
<tf.RaggedTensor [[4, 3, 7, 5], [], [10, 15, 9], [14], []]>
Se è necessario eseguire una trasformazione a livello di elemento nei valori di un RaggedTensor , è possibile utilizzare tf.ragged.map_flat_values , che accetta una funzione più uno o più argomenti e applica la funzione per trasformare i valori di RaggedTensor .
times_two_plus_one = lambda x: x * 2 + 1
print(tf.ragged.map_flat_values(times_two_plus_one, digits))
<tf.RaggedTensor [[7, 3, 9, 3], [], [11, 19, 5], [13], []]>
I tensori irregolari possono essere convertiti in list Python nidificati e array NumPy s:
digits.to_list()
[[3, 1, 4, 1], [], [5, 9, 2], [6], []]
digits.numpy()
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/ops/ragged/ragged_tensor.py:2063: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
return np.array(rows)
array([array([3, 1, 4, 1], dtype=int32), array([], dtype=int32),
array([5, 9, 2], dtype=int32), array([6], dtype=int32),
array([], dtype=int32)], dtype=object)
Costruire un tensore irregolare
Il modo più semplice per costruire un tensore irregolare è usare tf.ragged.constant , che costruisce il RaggedTensor corrispondente a un dato list Python annidato o array NumPy :
sentences = tf.ragged.constant([
["Let's", "build", "some", "ragged", "tensors", "!"],
["We", "can", "use", "tf.ragged.constant", "."]])
print(sentences)
<tf.RaggedTensor [[b"Let's", b'build', b'some', b'ragged', b'tensors', b'!'], [b'We', b'can', b'use', b'tf.ragged.constant', b'.']]>
paragraphs = tf.ragged.constant([
[['I', 'have', 'a', 'cat'], ['His', 'name', 'is', 'Mat']],
[['Do', 'you', 'want', 'to', 'come', 'visit'], ["I'm", 'free', 'tomorrow']],
])
print(paragraphs)
<tf.RaggedTensor [[[b'I', b'have', b'a', b'cat'], [b'His', b'name', b'is', b'Mat']], [[b'Do', b'you', b'want', b'to', b'come', b'visit'], [b"I'm", b'free', b'tomorrow']]]>
I tensori irregolari possono anche essere costruiti accoppiando tensori di valori piatti con tensori di partizionamento di riga che indicano come tali valori devono essere divisi in righe, utilizzando metodi di classe di fabbrica come tf.RaggedTensor.from_value_rowids , tf.RaggedTensor.from_row_lengths e tf.RaggedTensor.from_row_splits .
tf.RaggedTensor.from_value_rowids
Se sai a quale riga appartiene ciascun valore, puoi creare un RaggedTensor usando un tensore di partizionamento di riga value_rowids :
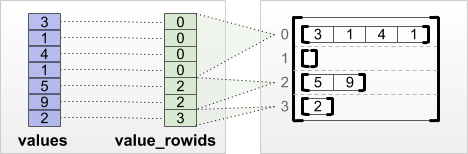
print(tf.RaggedTensor.from_value_rowids(
values=[3, 1, 4, 1, 5, 9, 2],
value_rowids=[0, 0, 0, 0, 2, 2, 3]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
tf.RaggedTensor.from_row_lengths
Se sai quanto è lunga ogni riga, puoi usare un tensore di partizionamento di riga row_lengths :
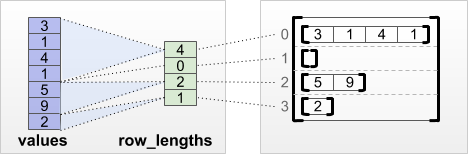
print(tf.RaggedTensor.from_row_lengths(
values=[3, 1, 4, 1, 5, 9, 2],
row_lengths=[4, 0, 2, 1]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
tf.RaggedTensor.from_row_splits
Se conosci l'indice in cui ogni riga inizia e finisce, puoi usare un tensore di partizionamento di riga row_splits :
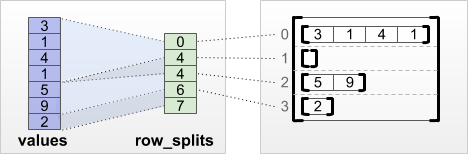
print(tf.RaggedTensor.from_row_splits(
values=[3, 1, 4, 1, 5, 9, 2],
row_splits=[0, 4, 4, 6, 7]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
Consulta la documentazione della classe tf.RaggedTensor per un elenco completo dei metodi di fabbrica.
Cosa puoi memorizzare in un tensore irregolare
Come con i normali Tensor , i valori in un RaggedTensor devono avere tutti lo stesso tipo; e i valori devono essere tutti alla stessa profondità di annidamento (il rango del tensore):
print(tf.ragged.constant([["Hi"], ["How", "are", "you"]])) # ok: type=string, rank=2
<tf.RaggedTensor [[b'Hi'], [b'How', b'are', b'you']]>
print(tf.ragged.constant([[[1, 2], [3]], [[4, 5]]])) # ok: type=int32, rank=3
<tf.RaggedTensor [[[1, 2], [3]], [[4, 5]]]>
try:
tf.ragged.constant([["one", "two"], [3, 4]]) # bad: multiple types
except ValueError as exception:
print(exception)
Can't convert Python sequence with mixed types to Tensor.
try:
tf.ragged.constant(["A", ["B", "C"]]) # bad: multiple nesting depths
except ValueError as exception:
print(exception)
all scalar values must have the same nesting depth
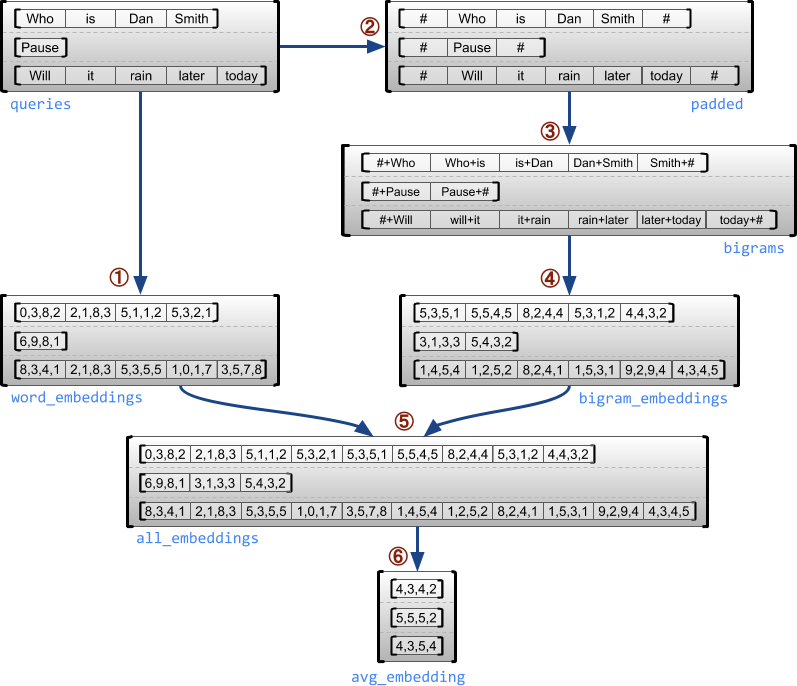
Esempio di caso d'uso
L'esempio seguente mostra come RaggedTensor s può essere usato per costruire e combinare incorporamenti unigram e bigram per un batch di query a lunghezza variabile, usando marcatori speciali per l'inizio e la fine di ogni frase. Per maggiori dettagli sulle operazioni utilizzate in questo esempio, controlla la documentazione del pacchetto tf.ragged .
queries = tf.ragged.constant([['Who', 'is', 'Dan', 'Smith'],
['Pause'],
['Will', 'it', 'rain', 'later', 'today']])
# Create an embedding table.
num_buckets = 1024
embedding_size = 4
embedding_table = tf.Variable(
tf.random.truncated_normal([num_buckets, embedding_size],
stddev=1.0 / math.sqrt(embedding_size)))
# Look up the embedding for each word.
word_buckets = tf.strings.to_hash_bucket_fast(queries, num_buckets)
word_embeddings = tf.nn.embedding_lookup(embedding_table, word_buckets) # ①
# Add markers to the beginning and end of each sentence.
marker = tf.fill([queries.nrows(), 1], '#')
padded = tf.concat([marker, queries, marker], axis=1) # ②
# Build word bigrams and look up embeddings.
bigrams = tf.strings.join([padded[:, :-1], padded[:, 1:]], separator='+') # ③
bigram_buckets = tf.strings.to_hash_bucket_fast(bigrams, num_buckets)
bigram_embeddings = tf.nn.embedding_lookup(embedding_table, bigram_buckets) # ④
# Find the average embedding for each sentence
all_embeddings = tf.concat([word_embeddings, bigram_embeddings], axis=1) # ⑤
avg_embedding = tf.reduce_mean(all_embeddings, axis=1) # ⑥
print(avg_embedding)
tf.Tensor( [[-0.14285272 0.02908629 -0.16327512 -0.14529026] [-0.4479212 -0.35615516 0.17110227 0.2522229 ] [-0.1987868 -0.13152348 -0.0325102 0.02125177]], shape=(3, 4), dtype=float32)
Dimensioni irregolari e uniformi
Una dimensione irregolare è una dimensione le cui fette possono avere lunghezze diverse. Ad esempio, la dimensione interna (colonna) di rt=[[3, 1, 4, 1], [], [5, 9, 2], [6], []] è irregolare, poiché le sezioni della colonna ( rt[0, :] , ..., rt[4, :] ) hanno lunghezze diverse. Le dimensioni le cui fette hanno tutte la stessa lunghezza sono dette dimensioni uniformi .
La dimensione più esterna di un tensore irregolare è sempre uniforme, poiché è costituita da un'unica fetta (e, quindi, non c'è possibilità per diverse lunghezze della fetta). Le dimensioni rimanenti possono essere irregolari o uniformi. Ad esempio, puoi memorizzare gli incorporamenti di parole per ogni parola in un batch di frasi utilizzando un tensore irregolare con forma [num_sentences, (num_words), embedding_size] , dove le parentesi intorno (num_words) indicano che la dimensione è irregolare.

I tensori irregolari possono avere più dimensioni irregolari. Ad esempio, è possibile memorizzare un batch di documenti di testo strutturato utilizzando un tensore con forma [num_documents, (num_paragraphs), (num_sentences), (num_words)] (dove di nuovo le parentesi vengono utilizzate per indicare dimensioni irregolari).
Come con tf.Tensor , il rango di un tensore irregolare è il suo numero totale di dimensioni (comprese le dimensioni irregolari e uniformi). Un tensore potenzialmente irregolare è un valore che potrebbe essere un tf.Tensor o un tf.RaggedTensor .
Quando si descrive la forma di un RaggedTensor, le dimensioni irregolari sono convenzionalmente indicate racchiudendole tra parentesi. Ad esempio, come hai visto sopra, la forma di un RaggedTensor 3D che memorizza gli incorporamenti di parole per ogni parola in un batch di frasi può essere scritta come [num_sentences, (num_words), embedding_size] .
L'attributo RaggedTensor.shape restituisce un tf.TensorShape per un tensore irregolare in cui le dimensioni irregolari hanno dimensione None :
tf.ragged.constant([["Hi"], ["How", "are", "you"]]).shape
TensorShape([2, None])
Il metodo tf.RaggedTensor.bounding_shape può essere utilizzato per trovare una forma di delimitazione stretta per un dato RaggedTensor :
print(tf.ragged.constant([["Hi"], ["How", "are", "you"]]).bounding_shape())
tf.Tensor([2 3], shape=(2,), dtype=int64)
Frastagliato vs scarso
Un tensore irregolare non dovrebbe essere considerato un tipo di tensore sparso. In particolare, i tensori sparsi sono codifiche efficienti per tf.Tensor che modellano gli stessi dati in un formato compatto; ma il tensore irregolare è un'estensione di tf.Tensor che modella una classe estesa di dati. Questa differenza è fondamentale quando si definiscono le operazioni:
- L'applicazione di un'operazione a un tensore sparso o denso dovrebbe dare sempre lo stesso risultato.
- L'applicazione di un'operazione a un tensore irregolare o sparso può dare risultati diversi.
Come esempio illustrativo, considera come le operazioni di array come concat , stack e tile sono definite per tensori irregolari o sparsi. La concatenazione di tensori irregolari unisce ogni riga per formare una singola riga con la lunghezza combinata:

ragged_x = tf.ragged.constant([["John"], ["a", "big", "dog"], ["my", "cat"]])
ragged_y = tf.ragged.constant([["fell", "asleep"], ["barked"], ["is", "fuzzy"]])
print(tf.concat([ragged_x, ragged_y], axis=1))
<tf.RaggedTensor [[b'John', b'fell', b'asleep'], [b'a', b'big', b'dog', b'barked'], [b'my', b'cat', b'is', b'fuzzy']]>
Tuttavia, concatenare tensori sparsi equivale a concatenare i corrispondenti tensori densi, come illustrato dal seguente esempio (dove Ø indica valori mancanti):
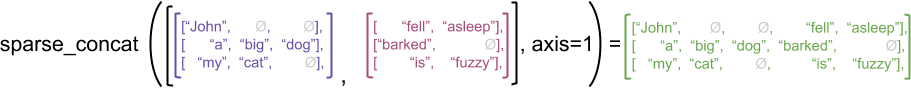
sparse_x = ragged_x.to_sparse()
sparse_y = ragged_y.to_sparse()
sparse_result = tf.sparse.concat(sp_inputs=[sparse_x, sparse_y], axis=1)
print(tf.sparse.to_dense(sparse_result, ''))
tf.Tensor( [[b'John' b'' b'' b'fell' b'asleep'] [b'a' b'big' b'dog' b'barked' b''] [b'my' b'cat' b'' b'is' b'fuzzy']], shape=(3, 5), dtype=string)
Per un altro esempio dell'importanza di questa distinzione, si consideri la definizione di "valore medio di ogni riga" per un'operazione come tf.reduce_mean . Per un tensore irregolare, il valore medio di una riga è la somma dei valori della riga divisa per la larghezza della riga. Ma per un tensore sparso, il valore medio di una riga è la somma dei valori della riga divisa per la larghezza complessiva del tensore sparso (che è maggiore o uguale alla larghezza della riga più lunga).
API TensorFlow
Cheras
tf.keras è l'API di alto livello di TensorFlow per la creazione e il training di modelli di deep learning. I tensori irregolari possono essere passati come input a un modello Keras impostando ragged=True su tf.keras.Input o tf.keras.layers.InputLayer . I tensori irregolari possono anche essere passati tra i livelli Keras e restituiti dai modelli Keras. L'esempio seguente mostra un modello LSTM giocattolo che viene addestrato utilizzando tensori irregolari.
# Task: predict whether each sentence is a question or not.
sentences = tf.constant(
['What makes you think she is a witch?',
'She turned me into a newt.',
'A newt?',
'Well, I got better.'])
is_question = tf.constant([True, False, True, False])
# Preprocess the input strings.
hash_buckets = 1000
words = tf.strings.split(sentences, ' ')
hashed_words = tf.strings.to_hash_bucket_fast(words, hash_buckets)
# Build the Keras model.
keras_model = tf.keras.Sequential([
tf.keras.layers.Input(shape=[None], dtype=tf.int64, ragged=True),
tf.keras.layers.Embedding(hash_buckets, 16),
tf.keras.layers.LSTM(32, use_bias=False),
tf.keras.layers.Dense(32),
tf.keras.layers.Activation(tf.nn.relu),
tf.keras.layers.Dense(1)
])
keras_model.compile(loss='binary_crossentropy', optimizer='rmsprop')
keras_model.fit(hashed_words, is_question, epochs=5)
print(keras_model.predict(hashed_words))
WARNING:tensorflow:Layer lstm will not use cuDNN kernels since it doesn't meet the criteria. It will use a generic GPU kernel as fallback when running on GPU.
Epoch 1/5
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/framework/indexed_slices.py:449: UserWarning: Converting sparse IndexedSlices(IndexedSlices(indices=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/boolean_mask_1/GatherV2:0", shape=(None,), dtype=int32), values=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/boolean_mask/GatherV2:0", shape=(None, 16), dtype=float32), dense_shape=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/Shape:0", shape=(2,), dtype=int32))) to a dense Tensor of unknown shape. This may consume a large amount of memory.
"shape. This may consume a large amount of memory." % value)
1/1 [==============================] - 2s 2s/step - loss: 3.1269
Epoch 2/5
1/1 [==============================] - 0s 18ms/step - loss: 2.1197
Epoch 3/5
1/1 [==============================] - 0s 19ms/step - loss: 2.0196
Epoch 4/5
1/1 [==============================] - 0s 20ms/step - loss: 1.9371
Epoch 5/5
1/1 [==============================] - 0s 18ms/step - loss: 1.8857
[[0.02800461]
[0.00945962]
[0.02283431]
[0.00252927]]
tf.Esempio
tf.Example è una codifica protobuf standard per i dati TensorFlow. I dati codificati con tf.Example s spesso includono funzioni a lunghezza variabile. Ad esempio, il codice seguente definisce un batch di quattro messaggi tf.Example con diverse lunghezze di funzionalità:
import google.protobuf.text_format as pbtext
def build_tf_example(s):
return pbtext.Merge(s, tf.train.Example()).SerializeToString()
example_batch = [
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["red", "blue"]} } }
feature {key: "lengths" value {int64_list {value: [7]} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["orange"]} } }
feature {key: "lengths" value {int64_list {value: []} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["black", "yellow"]} } }
feature {key: "lengths" value {int64_list {value: [1, 3]} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["green"]} } }
feature {key: "lengths" value {int64_list {value: [3, 5, 2]} } } }''')]
Puoi analizzare questi dati codificati usando tf.io.parse_example , che accetta un tensore di stringhe serializzate e un dizionario delle specifiche delle funzionalità e restituisce un dizionario che mappa i nomi delle funzionalità ai tensori. Per leggere le funzionalità a lunghezza variabile in tensori irregolari, è sufficiente utilizzare tf.io.RaggedFeature nel dizionario delle specifiche delle funzionalità:
feature_specification = {
'colors': tf.io.RaggedFeature(tf.string),
'lengths': tf.io.RaggedFeature(tf.int64),
}
feature_tensors = tf.io.parse_example(example_batch, feature_specification)
for name, value in feature_tensors.items():
print("{}={}".format(name, value))
colors=<tf.RaggedTensor [[b'red', b'blue'], [b'orange'], [b'black', b'yellow'], [b'green']]> lengths=<tf.RaggedTensor [[7], [], [1, 3], [3, 5, 2]]>
tf.io.RaggedFeature può essere utilizzato anche per leggere feature con più dimensioni irregolari. Per i dettagli, fare riferimento alla documentazione dell'API .
Set di dati
tf.data è un'API che consente di creare pipeline di input complesse da parti semplici e riutilizzabili. La sua struttura di dati di base è tf.data.Dataset , che rappresenta una sequenza di elementi, in cui ogni elemento è costituito da uno o più componenti.
# Helper function used to print datasets in the examples below.
def print_dictionary_dataset(dataset):
for i, element in enumerate(dataset):
print("Element {}:".format(i))
for (feature_name, feature_value) in element.items():
print('{:>14} = {}'.format(feature_name, feature_value))
Creazione di set di dati con tensori irregolari
I set di dati possono essere creati da tensori irregolari utilizzando gli stessi metodi utilizzati per costruirli da tf.Tensor s o NumPy array s, come Dataset.from_tensor_slices :
dataset = tf.data.Dataset.from_tensor_slices(feature_tensors)
print_dictionary_dataset(dataset)
Element 0:
colors = [b'red' b'blue']
lengths = [7]
Element 1:
colors = [b'orange']
lengths = []
Element 2:
colors = [b'black' b'yellow']
lengths = [1 3]
Element 3:
colors = [b'green']
lengths = [3 5 2]
Batch e unbatching di set di dati con tensori irregolari
I set di dati con tensori irregolari possono essere raggruppati in batch (che combina n elementi consecutivi in un unico elemento) utilizzando il metodo Dataset.batch .
batched_dataset = dataset.batch(2)
print_dictionary_dataset(batched_dataset)
Element 0:
colors = <tf.RaggedTensor [[b'red', b'blue'], [b'orange']]>
lengths = <tf.RaggedTensor [[7], []]>
Element 1:
colors = <tf.RaggedTensor [[b'black', b'yellow'], [b'green']]>
lengths = <tf.RaggedTensor [[1, 3], [3, 5, 2]]>
Al contrario, un set di dati in batch può essere trasformato in un set di dati flat utilizzando Dataset.unbatch .
unbatched_dataset = batched_dataset.unbatch()
print_dictionary_dataset(unbatched_dataset)
Element 0:
colors = [b'red' b'blue']
lengths = [7]
Element 1:
colors = [b'orange']
lengths = []
Element 2:
colors = [b'black' b'yellow']
lengths = [1 3]
Element 3:
colors = [b'green']
lengths = [3 5 2]
Batching di set di dati con tensori non irregolari a lunghezza variabile
Se hai un set di dati che contiene tensori non irregolari e le lunghezze dei tensori variano tra gli elementi, puoi raggruppare quei tensori non irregolari in tensori irregolari applicando la trasformazione dense_to_ragged_batch :
non_ragged_dataset = tf.data.Dataset.from_tensor_slices([1, 5, 3, 2, 8])
non_ragged_dataset = non_ragged_dataset.map(tf.range)
batched_non_ragged_dataset = non_ragged_dataset.apply(
tf.data.experimental.dense_to_ragged_batch(2))
for element in batched_non_ragged_dataset:
print(element)
<tf.RaggedTensor [[0], [0, 1, 2, 3, 4]]> <tf.RaggedTensor [[0, 1, 2], [0, 1]]> <tf.RaggedTensor [[0, 1, 2, 3, 4, 5, 6, 7]]>
Trasformazione di set di dati con tensori irregolari
Puoi anche creare o trasformare tensori irregolari nei set di dati usando Dataset.map :
def transform_lengths(features):
return {
'mean_length': tf.math.reduce_mean(features['lengths']),
'length_ranges': tf.ragged.range(features['lengths'])}
transformed_dataset = dataset.map(transform_lengths)
print_dictionary_dataset(transformed_dataset)
Element 0: mean_length = 7 length_ranges = <tf.RaggedTensor [[0, 1, 2, 3, 4, 5, 6]]> Element 1: mean_length = 0 length_ranges = <tf.RaggedTensor []> Element 2: mean_length = 2 length_ranges = <tf.RaggedTensor [[0], [0, 1, 2]]> Element 3: mean_length = 3 length_ranges = <tf.RaggedTensor [[0, 1, 2], [0, 1, 2, 3, 4], [0, 1]]>
tf.funzione
tf.function è un decoratore che precalcola i grafici TensorFlow per le funzioni Python, che possono migliorare sostanzialmente le prestazioni del codice TensorFlow. I tensori irregolari possono essere utilizzati in modo trasparente con @tf.function -decorated functions. Ad esempio, la seguente funzione funziona con tensori irregolari e non irregolari:
@tf.function
def make_palindrome(x, axis):
return tf.concat([x, tf.reverse(x, [axis])], axis)
make_palindrome(tf.constant([[1, 2], [3, 4], [5, 6]]), axis=1)
<tf.Tensor: shape=(3, 4), dtype=int32, numpy=
array([[1, 2, 2, 1],
[3, 4, 4, 3],
[5, 6, 6, 5]], dtype=int32)>
make_palindrome(tf.ragged.constant([[1, 2], [3], [4, 5, 6]]), axis=1)
2021-09-22 20:36:51.018367: W tensorflow/core/grappler/optimizers/loop_optimizer.cc:907] Skipping loop optimization for Merge node with control input: RaggedConcat/assert_equal_1/Assert/AssertGuard/branch_executed/_9 <tf.RaggedTensor [[1, 2, 2, 1], [3, 3], [4, 5, 6, 6, 5, 4]]>
Se desideri specificare in modo esplicito input_signature per tf.function , puoi farlo usando tf.RaggedTensorSpec .
@tf.function(
input_signature=[tf.RaggedTensorSpec(shape=[None, None], dtype=tf.int32)])
def max_and_min(rt):
return (tf.math.reduce_max(rt, axis=-1), tf.math.reduce_min(rt, axis=-1))
max_and_min(tf.ragged.constant([[1, 2], [3], [4, 5, 6]]))
(<tf.Tensor: shape=(3,), dtype=int32, numpy=array([2, 3, 6], dtype=int32)>, <tf.Tensor: shape=(3,), dtype=int32, numpy=array([1, 3, 4], dtype=int32)>)
Funzioni concrete
Le funzioni concrete incapsulano i singoli grafici tracciati che sono costruiti da tf.function . I tensori irregolari possono essere utilizzati in modo trasparente con funzioni concrete.
@tf.function
def increment(x):
return x + 1
rt = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
cf = increment.get_concrete_function(rt)
print(cf(rt))
<tf.RaggedTensor [[2, 3], [4], [5, 6, 7]]>
Modelli salvati
Un SavedModel è un programma TensorFlow serializzato, che include sia i pesi che il calcolo. Può essere costruito da un modello Keras o da un modello personalizzato. In entrambi i casi, i tensori irregolari possono essere utilizzati in modo trasparente con le funzioni ei metodi definiti da un SavedModel.
Esempio: salvataggio di un modello Keras
import tempfile
keras_module_path = tempfile.mkdtemp()
tf.saved_model.save(keras_model, keras_module_path)
imported_model = tf.saved_model.load(keras_module_path)
imported_model(hashed_words)
2021-09-22 20:36:52.069689: W tensorflow/python/util/util.cc:348] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
WARNING:absl:Function `_wrapped_model` contains input name(s) args_0 with unsupported characters which will be renamed to args_0_1 in the SavedModel.
INFO:tensorflow:Assets written to: /tmp/tmp114axtt7/assets
INFO:tensorflow:Assets written to: /tmp/tmp114axtt7/assets
<tf.Tensor: shape=(4, 1), dtype=float32, numpy=
array([[0.02800461],
[0.00945962],
[0.02283431],
[0.00252927]], dtype=float32)>
Esempio: salvataggio di un modello personalizzato
class CustomModule(tf.Module):
def __init__(self, variable_value):
super(CustomModule, self).__init__()
self.v = tf.Variable(variable_value)
@tf.function
def grow(self, x):
return x * self.v
module = CustomModule(100.0)
# Before saving a custom model, you must ensure that concrete functions are
# built for each input signature that you will need.
module.grow.get_concrete_function(tf.RaggedTensorSpec(shape=[None, None],
dtype=tf.float32))
custom_module_path = tempfile.mkdtemp()
tf.saved_model.save(module, custom_module_path)
imported_model = tf.saved_model.load(custom_module_path)
imported_model.grow(tf.ragged.constant([[1.0, 4.0, 3.0], [2.0]]))
INFO:tensorflow:Assets written to: /tmp/tmpnn4u8dy5/assets INFO:tensorflow:Assets written to: /tmp/tmpnn4u8dy5/assets <tf.RaggedTensor [[100.0, 400.0, 300.0], [200.0]]>
Operatori sovraccarichi
La classe RaggedTensor sovraccarica gli operatori aritmetici e di confronto standard di Python, semplificando l'esecuzione di calcoli matematici di base:
x = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
y = tf.ragged.constant([[1, 1], [2], [3, 3, 3]])
print(x + y)
<tf.RaggedTensor [[2, 3], [5], [7, 8, 9]]>
Poiché gli operatori sovraccaricati eseguono calcoli elementwise, gli input per tutte le operazioni binarie devono avere la stessa forma o essere trasmessi alla stessa forma. Nel caso di trasmissione più semplice, un singolo scalare è combinato per elemento con ciascun valore in un tensore irregolare:
x = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
print(x + 3)
<tf.RaggedTensor [[4, 5], [6], [7, 8, 9]]>
Per una discussione su casi più avanzati, controlla la sezione sulle trasmissioni .
I tensori irregolari sovraccaricano lo stesso insieme di operatori dei normali Tensor s: gli operatori unari - , ~ e abs() ; e gli operatori binari + , - , * , / , // , % , ** , & , | , ^ , == , < , <= , > e >= .
Indicizzazione
I tensori irregolari supportano l'indicizzazione in stile Python, inclusi l'indicizzazione e lo slicing multidimensionali. Gli esempi seguenti dimostrano l'indicizzazione del tensore irregolare con un tensore irregolare 2D e 3D.
Esempi di indicizzazione: tensore irregolare 2D
queries = tf.ragged.constant(
[['Who', 'is', 'George', 'Washington'],
['What', 'is', 'the', 'weather', 'tomorrow'],
['Goodnight']])
print(queries[1]) # A single query
tf.Tensor([b'What' b'is' b'the' b'weather' b'tomorrow'], shape=(5,), dtype=string)
print(queries[1, 2]) # A single word
tf.Tensor(b'the', shape=(), dtype=string)
print(queries[1:]) # Everything but the first row
<tf.RaggedTensor [[b'What', b'is', b'the', b'weather', b'tomorrow'], [b'Goodnight']]>
print(queries[:, :3]) # The first 3 words of each query
<tf.RaggedTensor [[b'Who', b'is', b'George'], [b'What', b'is', b'the'], [b'Goodnight']]>
print(queries[:, -2:]) # The last 2 words of each query
<tf.RaggedTensor [[b'George', b'Washington'], [b'weather', b'tomorrow'], [b'Goodnight']]>
Esempi di indicizzazione: tensore irregolare 3D
rt = tf.ragged.constant([[[1, 2, 3], [4]],
[[5], [], [6]],
[[7]],
[[8, 9], [10]]])
print(rt[1]) # Second row (2D RaggedTensor)
<tf.RaggedTensor [[5], [], [6]]>
print(rt[3, 0]) # First element of fourth row (1D Tensor)
tf.Tensor([8 9], shape=(2,), dtype=int32)
print(rt[:, 1:3]) # Items 1-3 of each row (3D RaggedTensor)
<tf.RaggedTensor [[[4]], [[], [6]], [], [[10]]]>
print(rt[:, -1:]) # Last item of each row (3D RaggedTensor)
<tf.RaggedTensor [[[4]], [[6]], [[7]], [[10]]]>
RaggedTensor supporta l'indicizzazione multidimensionale e lo slicing con una restrizione: l'indicizzazione in una dimensione irregolare non è consentita. Questo caso è problematico perché il valore indicato può esistere in alcune righe ma non in altre. In questi casi, non è ovvio se dovresti (1) sollevare un IndexError ; (2) utilizzare un valore predefinito; o (3) salta quel valore e restituisce un tensore con meno righe di quelle con cui hai iniziato. Seguendo i principi guida di Python ("Di fronte all'ambiguità, rifiuta la tentazione di indovinare"), questa operazione è attualmente non consentita.
Conversione del tipo di tensore
La classe RaggedTensor definisce metodi che possono essere utilizzati per convertire tra RaggedTensor s e tf.Tensor s o tf.SparseTensors :
ragged_sentences = tf.ragged.constant([
['Hi'], ['Welcome', 'to', 'the', 'fair'], ['Have', 'fun']])
# RaggedTensor -> Tensor
print(ragged_sentences.to_tensor(default_value='', shape=[None, 10]))
tf.Tensor( [[b'Hi' b'' b'' b'' b'' b'' b'' b'' b'' b''] [b'Welcome' b'to' b'the' b'fair' b'' b'' b'' b'' b'' b''] [b'Have' b'fun' b'' b'' b'' b'' b'' b'' b'' b'']], shape=(3, 10), dtype=string)
# Tensor -> RaggedTensor
x = [[1, 3, -1, -1], [2, -1, -1, -1], [4, 5, 8, 9]]
print(tf.RaggedTensor.from_tensor(x, padding=-1))
<tf.RaggedTensor [[1, 3], [2], [4, 5, 8, 9]]>
#RaggedTensor -> SparseTensor
print(ragged_sentences.to_sparse())
SparseTensor(indices=tf.Tensor( [[0 0] [1 0] [1 1] [1 2] [1 3] [2 0] [2 1]], shape=(7, 2), dtype=int64), values=tf.Tensor([b'Hi' b'Welcome' b'to' b'the' b'fair' b'Have' b'fun'], shape=(7,), dtype=string), dense_shape=tf.Tensor([3 4], shape=(2,), dtype=int64))
# SparseTensor -> RaggedTensor
st = tf.SparseTensor(indices=[[0, 0], [2, 0], [2, 1]],
values=['a', 'b', 'c'],
dense_shape=[3, 3])
print(tf.RaggedTensor.from_sparse(st))
<tf.RaggedTensor [[b'a'], [], [b'b', b'c']]>
Valutazione dei tensori irregolari
Per accedere ai valori in un tensore irregolare, puoi:
- Usa
tf.RaggedTensor.to_listper convertire il tensore irregolare in un elenco Python annidato. - Utilizzare
tf.RaggedTensor.numpyper convertire il tensore irregolare in una matrice NumPy i cui valori sono matrici NumPy nidificate. - Scomponi il tensore irregolare nei suoi componenti, utilizzando le proprietà
tf.RaggedTensor.valuesetf.RaggedTensor.row_splitso metodi di ripartizione delle righe cometf.RaggedTensor.row_lengthsetf.RaggedTensor.value_rowids. - Usa l'indicizzazione Python per selezionare i valori dal tensore irregolare.
rt = tf.ragged.constant([[1, 2], [3, 4, 5], [6], [], [7]])
print("Python list:", rt.to_list())
print("NumPy array:", rt.numpy())
print("Values:", rt.values.numpy())
print("Splits:", rt.row_splits.numpy())
print("Indexed value:", rt[1].numpy())
Python list: [[1, 2], [3, 4, 5], [6], [], [7]] NumPy array: [array([1, 2], dtype=int32) array([3, 4, 5], dtype=int32) array([6], dtype=int32) array([], dtype=int32) array([7], dtype=int32)] Values: [1 2 3 4 5 6 7] Splits: [0 2 5 6 6 7] Indexed value: [3 4 5] /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/ops/ragged/ragged_tensor.py:2063: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray return np.array(rows)
Trasmissione
La trasmissione è il processo per fare in modo che tensori con forme diverse abbiano forme compatibili per operazioni a livello di elemento. Per ulteriori informazioni sulla trasmissione, fare riferimento a:
I passaggi di base per trasmettere due y x avere forme compatibili sono:
Se
xyhanno lo stesso numero di dimensioni, aggiungi le dimensioni esterne (con dimensione 1) finché non lo fanno.Per ogni dimensione in cui
xeyhanno dimensioni diverse:
- Se
xoyhanno dimensione1nella dimensioned, ripeti i suoi valori attraverso la dimensionedin modo che corrispondano alla dimensione dell'altro input. - In caso contrario, solleva un'eccezione (
xysono compatibili con la trasmissione).
Dove la dimensione di un tensore in una dimensione uniforme è un singolo numero (la dimensione delle fette attraverso quella dimensione); e la dimensione di un tensore in una dimensione irregolare è un elenco di lunghezze di fette (per tutte le fette su quella dimensione).
Esempi di trasmissione
# x (2D ragged): 2 x (num_rows)
# y (scalar)
# result (2D ragged): 2 x (num_rows)
x = tf.ragged.constant([[1, 2], [3]])
y = 3
print(x + y)
<tf.RaggedTensor [[4, 5], [6]]>
# x (2d ragged): 3 x (num_rows)
# y (2d tensor): 3 x 1
# Result (2d ragged): 3 x (num_rows)
x = tf.ragged.constant(
[[10, 87, 12],
[19, 53],
[12, 32]])
y = [[1000], [2000], [3000]]
print(x + y)
<tf.RaggedTensor [[1010, 1087, 1012], [2019, 2053], [3012, 3032]]>
# x (3d ragged): 2 x (r1) x 2
# y (2d ragged): 1 x 1
# Result (3d ragged): 2 x (r1) x 2
x = tf.ragged.constant(
[[[1, 2], [3, 4], [5, 6]],
[[7, 8]]],
ragged_rank=1)
y = tf.constant([[10]])
print(x + y)
<tf.RaggedTensor [[[11, 12], [13, 14], [15, 16]], [[17, 18]]]>
# x (3d ragged): 2 x (r1) x (r2) x 1
# y (1d tensor): 3
# Result (3d ragged): 2 x (r1) x (r2) x 3
x = tf.ragged.constant(
[
[
[[1], [2]],
[],
[[3]],
[[4]],
],
[
[[5], [6]],
[[7]]
]
],
ragged_rank=2)
y = tf.constant([10, 20, 30])
print(x + y)
<tf.RaggedTensor [[[[11, 21, 31], [12, 22, 32]], [], [[13, 23, 33]], [[14, 24, 34]]], [[[15, 25, 35], [16, 26, 36]], [[17, 27, 37]]]]>
Ecco alcuni esempi di forme che non vengono trasmesse:
# x (2d ragged): 3 x (r1)
# y (2d tensor): 3 x 4 # trailing dimensions do not match
x = tf.ragged.constant([[1, 2], [3, 4, 5, 6], [7]])
y = tf.constant([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 1 b'lengths=' 4 b'dim_size=' 2, 4, 1
# x (2d ragged): 3 x (r1)
# y (2d ragged): 3 x (r2) # ragged dimensions do not match.
x = tf.ragged.constant([[1, 2, 3], [4], [5, 6]])
y = tf.ragged.constant([[10, 20], [30, 40], [50]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 1 b'lengths=' 2, 2, 1 b'dim_size=' 3, 1, 2
# x (3d ragged): 3 x (r1) x 2
# y (3d ragged): 3 x (r1) x 3 # trailing dimensions do not match
x = tf.ragged.constant([[[1, 2], [3, 4], [5, 6]],
[[7, 8], [9, 10]]])
y = tf.ragged.constant([[[1, 2, 0], [3, 4, 0], [5, 6, 0]],
[[7, 8, 0], [9, 10, 0]]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 2 b'lengths=' 3, 3, 3, 3, 3 b'dim_size=' 2, 2, 2, 2, 2
Codifica RaggedTensor
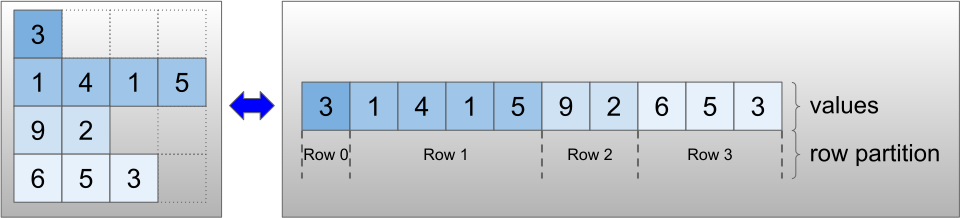
I tensori irregolari vengono codificati utilizzando la classe RaggedTensor . Internamente, ogni RaggedTensor è composto da:
- Un tensore di
values, che concatena le righe a lunghezza variabile in un elenco appiattito. - Una
row_partition, che indica come quei valori appiattiti sono divisi in righe.
La row_partition può essere archiviata utilizzando quattro diverse codifiche:
-
row_splitsè un vettore intero che specifica i punti di divisione tra le righe. -
value_rowidsè un vettore intero che specifica l'indice di riga per ogni valore. -
row_lengthsè un vettore intero che specifica la lunghezza di ogni riga. -
uniform_row_lengthè uno scalare intero che specifica una singola lunghezza per tutte le righe.
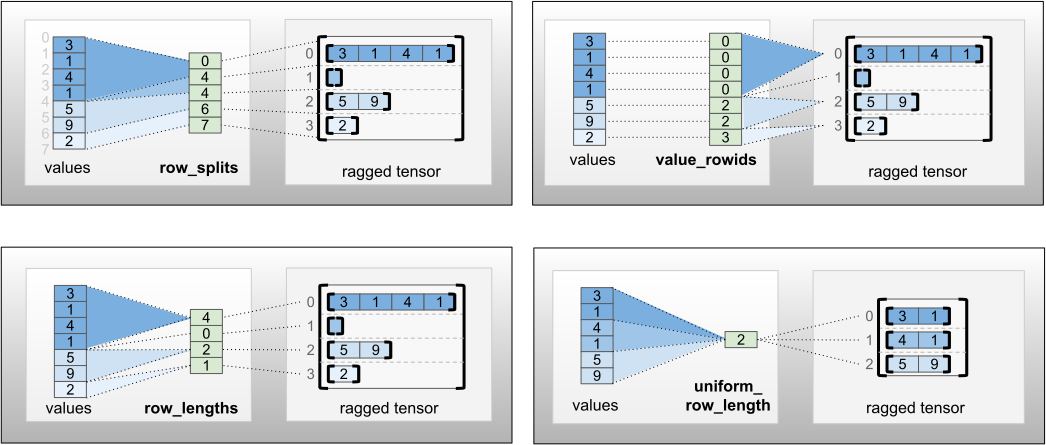
Un numero intero scalare nrows può anche essere incluso nella codifica row_partition per tenere conto delle righe finali vuote con value_rowids o delle righe vuote con uniform_row_length .
rt = tf.RaggedTensor.from_row_splits(
values=[3, 1, 4, 1, 5, 9, 2],
row_splits=[0, 4, 4, 6, 7])
print(rt)
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
La scelta della codifica da utilizzare per le partizioni di riga è gestita internamente da tensori irregolari per migliorare l'efficienza in alcuni contesti. In particolare, alcuni dei vantaggi e degli svantaggi dei diversi schemi di partizionamento delle righe sono:
- Indicizzazione efficiente : la codifica
row_splitsconsente l'indicizzazione e lo slicing a tempo costante in tensori irregolari. - Concatenazione efficiente : la codifica
row_lengthsè più efficiente quando si concatenano tensori irregolari, poiché le lunghezze delle righe non cambiano quando due tensori vengono concatenati insieme. - Dimensioni di codifica ridotte : la codifica
value_rowidsè più efficiente quando si archiviano tensori irregolari che hanno un numero elevato di righe vuote, poiché la dimensione del tensore dipende solo dal numero totale di valori. D'altra parte, lerow_splitserow_lengthssono più efficienti quando si archiviano tensori irregolari con righe più lunghe, poiché richiedono un solo valore scalare per ogni riga. - Compatibilità : lo schema
value_rowidscorrisponde al formato di segmentazione utilizzato dalle operazioni, ad esempiotf.segment_sum. Lo schemarow_limitscorrisponde al formato utilizzato da operazioni cometf.sequence_mask. - Dimensioni uniformi : come discusso di seguito, la codifica
uniform_row_lengthviene utilizzata per codificare tensori irregolari con dimensioni uniformi.
Dimensioni multiple irregolari
Un tensore irregolare con più dimensioni irregolari viene codificato utilizzando un RaggedTensor nidificato per il tensore dei values . Ogni RaggedTensor nidificato aggiunge una singola dimensione irregolare.
![]()
rt = tf.RaggedTensor.from_row_splits(
values=tf.RaggedTensor.from_row_splits(
values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
row_splits=[0, 3, 3, 5, 9, 10]),
row_splits=[0, 1, 1, 5])
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
<tf.RaggedTensor [[[10, 11, 12]], [], [[], [13, 14], [15, 16, 17, 18], [19]]]> Shape: (3, None, None) Number of partitioned dimensions: 2
La funzione factory tf.RaggedTensor.from_nested_row_splits può essere utilizzata per costruire un RaggedTensor con più dimensioni irregolari direttamente fornendo un elenco di tensori row_splits :
rt = tf.RaggedTensor.from_nested_row_splits(
flat_values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
nested_row_splits=([0, 1, 1, 5], [0, 3, 3, 5, 9, 10]))
print(rt)
<tf.RaggedTensor [[[10, 11, 12]], [], [[], [13, 14], [15, 16, 17, 18], [19]]]>
Rango irregolare e valori piatti
Il rango irregolare di un tensore irregolare è il numero di volte in cui il tensore dei values sottostanti è stato partizionato (cioè la profondità di annidamento degli oggetti RaggedTensor ). Il tensore values più interni è noto come flat_values . Nell'esempio seguente, le conversations hanno ragged_rank=3 e flat_values è un Tensor 1D con 24 stringhe:
# shape = [batch, (paragraph), (sentence), (word)]
conversations = tf.ragged.constant(
[[[["I", "like", "ragged", "tensors."]],
[["Oh", "yeah?"], ["What", "can", "you", "use", "them", "for?"]],
[["Processing", "variable", "length", "data!"]]],
[[["I", "like", "cheese."], ["Do", "you?"]],
[["Yes."], ["I", "do."]]]])
conversations.shape
TensorShape([2, None, None, None])
assert conversations.ragged_rank == len(conversations.nested_row_splits)
conversations.ragged_rank # Number of partitioned dimensions.
3
conversations.flat_values.numpy()
array([b'I', b'like', b'ragged', b'tensors.', b'Oh', b'yeah?', b'What',
b'can', b'you', b'use', b'them', b'for?', b'Processing',
b'variable', b'length', b'data!', b'I', b'like', b'cheese.', b'Do',
b'you?', b'Yes.', b'I', b'do.'], dtype=object)
Dimensioni interne uniformi
I tensori irregolari con dimensioni interne uniformi vengono codificati utilizzando un tf.Tensor multidimensionale per flat_values (cioè i values più interni).
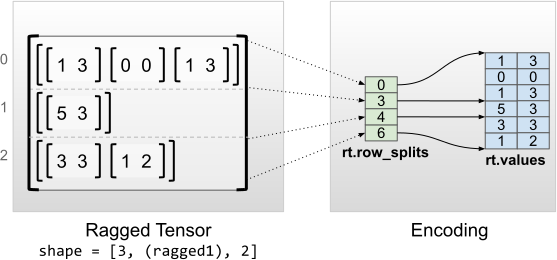
rt = tf.RaggedTensor.from_row_splits(
values=[[1, 3], [0, 0], [1, 3], [5, 3], [3, 3], [1, 2]],
row_splits=[0, 3, 4, 6])
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
print("Flat values shape: {}".format(rt.flat_values.shape))
print("Flat values:\n{}".format(rt.flat_values))
<tf.RaggedTensor [[[1, 3], [0, 0], [1, 3]], [[5, 3]], [[3, 3], [1, 2]]]> Shape: (3, None, 2) Number of partitioned dimensions: 1 Flat values shape: (6, 2) Flat values: [[1 3] [0 0] [1 3] [5 3] [3 3] [1 2]]
Dimensioni non interne uniformi
I tensori irregolari con dimensioni non interne uniformi vengono codificati partizionando le righe con uniform_row_length .
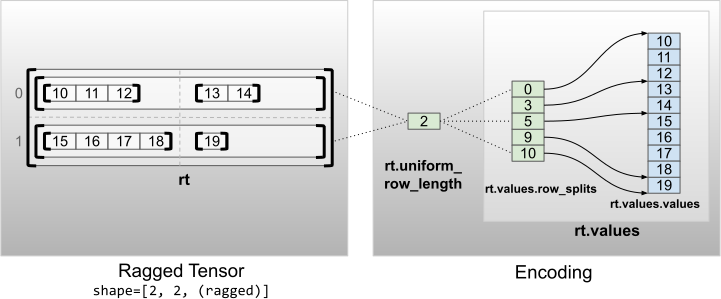
rt = tf.RaggedTensor.from_uniform_row_length(
values=tf.RaggedTensor.from_row_splits(
values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
row_splits=[0, 3, 5, 9, 10]),
uniform_row_length=2)
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
<tf.RaggedTensor [[[10, 11, 12], [13, 14]], [[15, 16, 17, 18], [19]]]> Shape: (2, 2, None) Number of partitioned dimensions: 2