
| |
 GitHub에서 소스 보기 GitHub에서 소스 보기 |
|
API 설명서: tf.RaggedTensor tf.ragged
설정
!pip install --pre -U tensorflow
import math
import tensorflow as tf
2022-12-14 22:02:07.978356: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory 2022-12-14 22:02:07.978450: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory 2022-12-14 22:02:07.978460: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
개요
데이터는 다양한 형태로 제공됩니다. 텐서도 마찬가지입니다. 비정형 텐서는 중첩된 가변 길이 목록에 해당하는 TensorFlow입니다. 이를 통해 다음을 포함하여 균일하지 않은 형상을 가진 데이터를 쉽게 저장하고 처리할 수 있습니다.
- 영화의 출연 배우진과 같은 가변 길이 요소
- 문장 또는 비디오 클립과 같은 가변 길이 순차 입력의 배치
- 여러 섹션, 단락, 문장 및 단어로 세분화된 텍스트 문서와 같은 계층화된 입력
- 프로토콜 버퍼와 같은 구조화된 입력의 개별 필드
비정형 텐서로 할 수 있는 작업
비정형 텐서는 수학 연산(tf.add 및 tf.reduce_mean 등), 배열 연산(tf.concat 및 tf.tile 등), 문자열 조작 연산(tf.substr 등), 제어 흐름 연산(tf.while_loop 및 tf.map_fn 등) 및 기타 연산 등 백 가지 이상의 TensorFlow 연산에서 지원됩니다.
digits = tf.ragged.constant([[3, 1, 4, 1], [], [5, 9, 2], [6], []])
words = tf.ragged.constant([["So", "long"], ["thanks", "for", "all", "the", "fish"]])
print(tf.add(digits, 3))
print(tf.reduce_mean(digits, axis=1))
print(tf.concat([digits, [[5, 3]]], axis=0))
print(tf.tile(digits, [1, 2]))
print(tf.strings.substr(words, 0, 2))
print(tf.map_fn(tf.math.square, digits))
<tf.RaggedTensor [[6, 4, 7, 4], [], [8, 12, 5], [9], []]> tf.Tensor([2.25 nan 5.33333333 6. nan], shape=(5,), dtype=float64) <tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9, 2], [6], [], [5, 3]]> <tf.RaggedTensor [[3, 1, 4, 1, 3, 1, 4, 1], [], [5, 9, 2, 5, 9, 2], [6, 6], []]> <tf.RaggedTensor [[b'So', b'lo'], [b'th', b'fo', b'al', b'th', b'fi']]> <tf.RaggedTensor [[9, 1, 16, 1], [], [25, 81, 4], [36], []]>
팩토리 메서드, 변환 메서드 및 값-매핑 연산을 포함하여 비정형 텐서에만 해당하는 여러 메서드와 연산도 있습니다. 지원되는 연산 목록은 tf.ragged 패키지 설명서를 참조하세요.
비정형 텐서는 Keras, Datasets, tf.function, SavedModels 및 tf.Example 등 많은 TensorFlow API에서 지원됩니다. 자세한 내용은 아래 TensorFlow API 섹션을 참조하세요.
일반 텐서와 마찬가지로 Python 스타일 인덱싱을 사용하여 비정형 텐서의 특정 슬라이스에 액세스할 수 있습니다. 자세한 내용은 아래 인덱싱 섹션을 참조하세요.
print(digits[0]) # First row
tf.Tensor([3 1 4 1], shape=(4,), dtype=int32)
print(digits[:, :2]) # First two values in each row.
<tf.RaggedTensor [[3, 1], [], [5, 9], [6], []]>
print(digits[:, -2:]) # Last two values in each row.
<tf.RaggedTensor [[4, 1], [], [9, 2], [6], []]>
그리고 일반 텐서와 마찬가지로 Python 산술 및 비교 연산자를 사용하여 요소별 연산을 수행할 수 있습니다. 자세한 내용은 아래 오버로드 연산자 섹션을 참조하세요.
print(digits + 3)
<tf.RaggedTensor [[6, 4, 7, 4], [], [8, 12, 5], [9], []]>
print(digits + tf.ragged.constant([[1, 2, 3, 4], [], [5, 6, 7], [8], []]))
<tf.RaggedTensor [[4, 3, 7, 5], [], [10, 15, 9], [14], []]>
RaggedTensor의 값으로 요소 별 변환을 수행해야하는 경우, 함수와 하나 이상의 매개변수를 갖는 tf.ragged.map_flat_values를 사용할 수 있고, RaggedTensor의 값을 변환할 때 적용할 수 있습니다.
times_two_plus_one = lambda x: x * 2 + 1
print(tf.ragged.map_flat_values(times_two_plus_one, digits))
<tf.RaggedTensor [[7, 3, 9, 3], [], [11, 19, 5], [13], []]>
비정형 텐서는 중첩된 Python list 및 NumPy array로 변환할 수 있습니다.
digits.to_list()
[[3, 1, 4, 1], [], [5, 9, 2], [6], []]
digits.numpy()
array([array([3, 1, 4, 1], dtype=int32), array([], dtype=int32),
array([5, 9, 2], dtype=int32), array([6], dtype=int32),
array([], dtype=int32)], dtype=object)
비정형 텐서 생성하기
비정형 텐서를 구성하는 가장 간단한 방법은 주어진 중첩된 Python list 또는 NumPy array에 해당하는 RaggedTensor를 빌드하는 tf.ragged.constant를 사용하는 것입니다.
sentences = tf.ragged.constant([
["Let's", "build", "some", "ragged", "tensors", "!"],
["We", "can", "use", "tf.ragged.constant", "."]])
print(sentences)
<tf.RaggedTensor [[b"Let's", b'build', b'some', b'ragged', b'tensors', b'!'], [b'We', b'can', b'use', b'tf.ragged.constant', b'.']]>
paragraphs = tf.ragged.constant([
[['I', 'have', 'a', 'cat'], ['His', 'name', 'is', 'Mat']],
[['Do', 'you', 'want', 'to', 'come', 'visit'], ["I'm", 'free', 'tomorrow']],
])
print(paragraphs)
<tf.RaggedTensor [[[b'I', b'have', b'a', b'cat'], [b'His', b'name', b'is', b'Mat']], [[b'Do', b'you', b'want', b'to', b'come', b'visit'], [b"I'm", b'free', b'tomorrow']]]>
비정형 텐서는 tf.RaggedTensor.from_value_rowids, tf.RaggedTensor.from_row_lengths 및 tf.RaggedTensor.from_row_splits와 tf.RaggedTensor.from_row_splits와 같은 팩토리 클래스 메서드를 사용하여 플랫 values 텐서와 행 분할 텐서를 쌍을 지어 해당 값을 행으로 분할하는 방법을 표시하는 방식으로도 생성할 수 있습니다.
tf.RaggedTensor.from_value_rowids
각 값이 어느 행에 속하는지 알고 있다면 value_rowids 행 분할 텐서를 사용하여 RaggedTensor를 빌드할 수 있습니다.
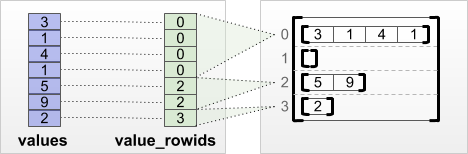
print(tf.RaggedTensor.from_value_rowids(
values=[3, 1, 4, 1, 5, 9, 2],
value_rowids=[0, 0, 0, 0, 2, 2, 3]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
tf.RaggedTensor.from_row_lengths
각 행의 길이를 알고 있으면 row_lengths 행 분할 텐서를 사용할 수 있습니다:
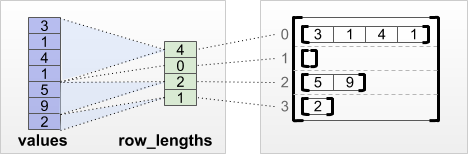
print(tf.RaggedTensor.from_row_lengths(
values=[3, 1, 4, 1, 5, 9, 2],
row_lengths=[4, 0, 2, 1]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
tf.RaggedTensor.from_row_splits
각 행의 시작과 끝 인덱스를 알고 있다면 row_splits 행 분할 텐서를 사용할 수 있습니다:
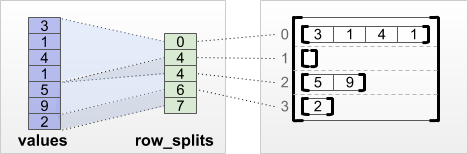
print(tf.RaggedTensor.from_row_splits(
values=[3, 1, 4, 1, 5, 9, 2],
row_splits=[0, 4, 4, 6, 7]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
팩토리 메서드의 전체 목록은 tf.RaggedTensor 클래스 문서를 참조하세요.
참고: 기본적으로, 이러한 팩토리 메서드는 행 파티션 텐서가 잘 구성되고 값의 수와 일치한다는 어설션을 추가합니다. validate=False 매개변수는 입력이 올바른 형식이고 일관성이 있음을 보장할 수 있는 경우 이러한 검사를 건너뛰는 데 사용할 수 있습니다.
비정형 텐서에 저장할 수 있는 것
일반 텐서와 마찬가지로, RaggedTensor의 값은 모두 같은 유형이어야 합니다; 값은 모두 동일한 중첩 깊이 (텐서의 랭크)에 있어야 합니다:
print(tf.ragged.constant([["Hi"], ["How", "are", "you"]])) # ok: type=string, rank=2
<tf.RaggedTensor [[b'Hi'], [b'How', b'are', b'you']]>
print(tf.ragged.constant([[[1, 2], [3]], [[4, 5]]])) # ok: type=int32, rank=3
<tf.RaggedTensor [[[1, 2], [3]], [[4, 5]]]>
try:
tf.ragged.constant([["one", "two"], [3, 4]]) # bad: multiple types
except ValueError as exception:
print(exception)
Can't convert Python sequence with mixed types to Tensor.
try:
tf.ragged.constant(["A", ["B", "C"]]) # bad: multiple nesting depths
except ValueError as exception:
print(exception)
all scalar values must have the same nesting depth
사용 사례 예시
다음 예제는 각 문장의 시작과 끝에 특수 마커를 사용하여 가변 길이 쿼리 배치에 대해 유니그램과 바이그램 임베딩을 구성하고 결합하는 데 RaggedTensor를 어떻게 사용할 수 있는지 보여줍니다. 이 예제에서 사용된 연산에 대한 자세한 내용은 tf.ragged 패키지 설명서를 참조하세요.
queries = tf.ragged.constant([['Who', 'is', 'Dan', 'Smith'],
['Pause'],
['Will', 'it', 'rain', 'later', 'today']])
# Create an embedding table.
num_buckets = 1024
embedding_size = 4
embedding_table = tf.Variable(
tf.random.truncated_normal([num_buckets, embedding_size],
stddev=1.0 / math.sqrt(embedding_size)))
# Look up the embedding for each word.
word_buckets = tf.strings.to_hash_bucket_fast(queries, num_buckets)
word_embeddings = tf.nn.embedding_lookup(embedding_table, word_buckets) # ①
# Add markers to the beginning and end of each sentence.
marker = tf.fill([queries.nrows(), 1], '#')
padded = tf.concat([marker, queries, marker], axis=1) # ②
# Build word bigrams and look up embeddings.
bigrams = tf.strings.join([padded[:, :-1], padded[:, 1:]], separator='+') # ③
bigram_buckets = tf.strings.to_hash_bucket_fast(bigrams, num_buckets)
bigram_embeddings = tf.nn.embedding_lookup(embedding_table, bigram_buckets) # ④
# Find the average embedding for each sentence
all_embeddings = tf.concat([word_embeddings, bigram_embeddings], axis=1) # ⑤
avg_embedding = tf.reduce_mean(all_embeddings, axis=1) # ⑥
print(avg_embedding)
tf.Tensor( [[-0.12602341 0.05363512 0.35813528 -0.11965103] [ 0.01294664 0.37780145 -0.2047603 0.03864591] [ 0.06504168 -0.09205849 -0.03208091 -0.21662359]], shape=(3, 4), dtype=float32)
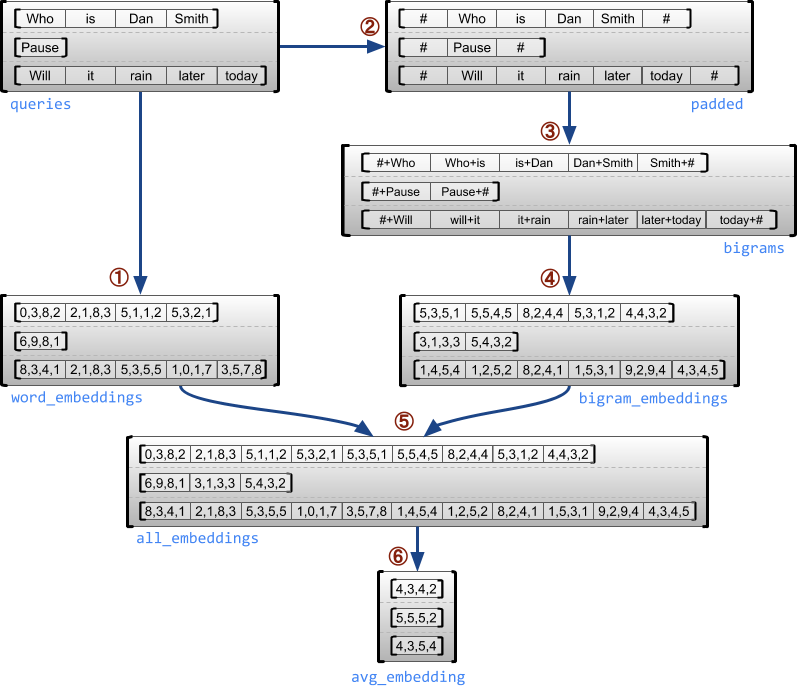
비정형 텐서: 정의
비정형 텐서는 슬라이스의 길이가 다를 수 있는 하나 이상의 비정형 크기를 갖는 텐서입니다. 예를 들어, rt=[[3, 1, 4, 1], [], [5, 9, 2], [6], []] 의 내부 (열) 크기는 열 슬라이스(rt[0, :], ..., rt[4, :])의 길이가 다르기 때문에 비정형입니다. 부분의 길이가 모두 같은 차원을 정형차원이라고 합니다.
비정형 텐서의 가장 바깥쪽 차원은 단일 슬라이스로 구성되므로 항상 균일합니다(따라서 슬라이스 길이가 다를 가능성이 없음). 나머지 치수는 불규칙하거나 균일할 수 있습니다. 예를 들어, 형상이 [num_sentences, (num_words), embedding_size]인 비전형 텐서를 사용하여 문장 배치의 각 단어에 대해 단어 임베딩을 저장할 수 있습니다. 여기서 (num_words) 주변의 괄호는 차원이 비정형임을 나타냅니다.
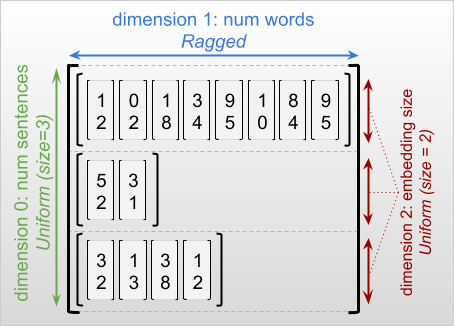
비정형 텐서는 여러 개의 비정형 차원을 가질 수 있습니다. 예를 들어, [num_documents, (num_paragraphs), (num_sentences), (num_words)] 형상을 가진 텐서를 사용하여 구조화된 텍스트 문서 배치를 저장할 수 있습니다(여기서도 마찬가지로 괄호는 비정형 차원을 나타내기 위해 사용됨).
tf.Tensor와 마찬가지로 비정형 텐서의 순위는 전체 차원 수입니다(비정형 차원과 균일한 차원 모두 포함). 잠재적 비정형 텐서는 tf.Tensor 또는 tf.RaggedTensor일 수 있는 값입니다.
RaggedTensor의 형상을 설명할 때 비정형 차원은 일반적으로 괄호로 묶어 표시합니다. 예를 들어, 위에서 보았듯이 문장 배치에서 각 단어에 대한 단어 임베딩을 저장하는 3D RaggedTensor의 형상은 [num_sentences, (num_words), embedding_size]로 작성할 수 있습니다.
RaggedTensor.shape 특성은 비정형 차원의 크기가 None인 비정형 텐서에 대해 tf.TensorShape를 반환합니다.
tf.ragged.constant([["Hi"], ["How", "are", "you"]]).shape
TensorShape([2, None])
tf.RaggedTensor.bounding_shape 메서드를 사용하여 지정된 RaggedTensor에 대한 빈틈이 없는 경계 형태를 찾을 수 있습니다:
print(tf.ragged.constant([["Hi"], ["How", "are", "you"]]).bounding_shape())
tf.Tensor([2 3], shape=(2,), dtype=int64)
비정형 대 희소
비정형 텐서는 희소 텐서의 일종으로 생각하지 않아야 합니다. 특히, 희소 텐서는 동일한 데이터를 컴팩트한 형식으로 모델링하는 tf.Tensor에 대한 효율적인 인코딩입니다. 그러나 비정형 텐서는 확장된 데이터 클래스를 모델링하는 tf.Tensor의 확장입니다. 이 차이는 연산을 정의할 때 매우 중요합니다.
- 희소 또는 밀집 텐서에 연산을 적용하면 항상 동일한 결과가 얻어집니다.
- 비정형 텐서 또는 희소 텐서에 연산을 적용하면 다른 결과가 얻어질 수 있습니다.
예를 들어, 비정형 vs 희소 텐서에 대해 concat, stack 및 tile과 같은 배열 연산이 어떻게 정의되는지 고려하십시오. 비정형 텐서들을 연결하면 각 행을 결합하여 단일 행을 형성합니다:

ragged_x = tf.ragged.constant([["John"], ["a", "big", "dog"], ["my", "cat"]])
ragged_y = tf.ragged.constant([["fell", "asleep"], ["barked"], ["is", "fuzzy"]])
print(tf.concat([ragged_x, ragged_y], axis=1))
<tf.RaggedTensor [[b'John', b'fell', b'asleep'], [b'a', b'big', b'dog', b'barked'], [b'my', b'cat', b'is', b'fuzzy']]>
그러나 희소 텐서를 연결하는 것은 다음 예(여기서 Ø는 결측 값을 나타냄)와 같이 해당하는 밀집 텐서를 연결하는 것과 같습니다.
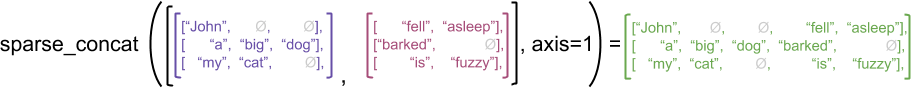
sparse_x = ragged_x.to_sparse()
sparse_y = ragged_y.to_sparse()
sparse_result = tf.sparse.concat(sp_inputs=[sparse_x, sparse_y], axis=1)
print(tf.sparse.to_dense(sparse_result, ''))
tf.Tensor( [[b'John' b'' b'' b'fell' b'asleep'] [b'a' b'big' b'dog' b'barked' b''] [b'my' b'cat' b'' b'is' b'fuzzy']], shape=(3, 5), dtype=string)
이 구별이 중요한 이유의 다른 예를 보려면, tf.reduce_mean과 같은 연산에 대한 “각 행의 평균값”의 정의를 고려하십시오. 비정형 텐서의 경우, 행의 평균값은 행 값을 행 너비로 나눈 값의 합입니다. 그러나 희소 텐서의 경우 행의 평균값은 행 값의 합계롤 희소 텐서의 전체 너비(가장 긴 행의 너비 이상)로 나눈 값입니다.
TensorFlow API
Keras
tf.keras는 딥 러닝 모델을 구축하고 훈련하기 위한 TensorFlow의 고급 API입니다. tf.keras.Input 또는 tf.keras.layers.InputLayer에서 ragged=True를 설정하여 비정형 텐서를 Keras 모델에 대한 입력으로 전달할 수 있습니다. 비정형 텐서는 Keras 계층 간에 전달되고 Keras 모델에서 반환될 수도 있습니다. 다음 예는 비정형 텐서를 사용하여 훈련된 장난감 LSTM 모델을 보여줍니다.
# Task: predict whether each sentence is a question or not.
sentences = tf.constant(
['What makes you think she is a witch?',
'She turned me into a newt.',
'A newt?',
'Well, I got better.'])
is_question = tf.constant([True, False, True, False])
# Preprocess the input strings.
hash_buckets = 1000
words = tf.strings.split(sentences, ' ')
hashed_words = tf.strings.to_hash_bucket_fast(words, hash_buckets)
# Build the Keras model.
keras_model = tf.keras.Sequential([
tf.keras.layers.Input(shape=[None], dtype=tf.int64, ragged=True),
tf.keras.layers.Embedding(hash_buckets, 16),
tf.keras.layers.LSTM(32, use_bias=False),
tf.keras.layers.Dense(32),
tf.keras.layers.Activation(tf.nn.relu),
tf.keras.layers.Dense(1)
])
keras_model.compile(loss='binary_crossentropy', optimizer='rmsprop')
keras_model.fit(hashed_words, is_question, epochs=5)
print(keras_model.predict(hashed_words))
WARNING:tensorflow:Layer lstm will not use cuDNN kernels since it doesn't meet the criteria. It will use a generic GPU kernel as fallback when running on GPU. Epoch 1/5 1/1 [==============================] - 3s 3s/step - loss: 7.7125 Epoch 2/5 1/1 [==============================] - 0s 16ms/step - loss: 7.7125 Epoch 3/5 1/1 [==============================] - 0s 15ms/step - loss: 7.7125 Epoch 4/5 1/1 [==============================] - 0s 15ms/step - loss: 7.7125 Epoch 5/5 1/1 [==============================] - 0s 16ms/step - loss: 7.7125 1/1 [==============================] - 0s 181ms/step [[-0.00071245] [-0.00576008] [-0.00501249] [-0.00205732]]
tf.Example
tf.Example은 TensorFlow 데이터에 대한 표준 protobuf 인코딩입니다. tf.Example로 인코딩된 데이터에는 종종 가변 길이 특성이 포함됩니다. 예를 들어 다음 코드는 특성 길이가 상이한 네 개의 tf.Example 메시지 배치를 정의합니다.
import google.protobuf.text_format as pbtext
def build_tf_example(s):
return pbtext.Merge(s, tf.train.Example()).SerializeToString()
example_batch = [
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["red", "blue"]} } }
feature {key: "lengths" value {int64_list {value: [7]} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["orange"]} } }
feature {key: "lengths" value {int64_list {value: []} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["black", "yellow"]} } }
feature {key: "lengths" value {int64_list {value: [1, 3]} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["green"]} } }
feature {key: "lengths" value {int64_list {value: [3, 5, 2]} } } }''')]
직렬화된 문자열 텐서와 특성 사양 사전을 받아서 특성 이름을 텐서에 매핑하는 사전을 반환하는 tf.io.parse_example을 사용하여 이 인코딩된 데이터를 구문 분석할 수 있습니다. 가변 길이 특성을 비정형 텐서로 읽으려면 특성 사양 사전에서 tf.io.RaggedFeature만 사용하면 됩니다.
feature_specification = {
'colors': tf.io.RaggedFeature(tf.string),
'lengths': tf.io.RaggedFeature(tf.int64),
}
feature_tensors = tf.io.parse_example(example_batch, feature_specification)
for name, value in feature_tensors.items():
print("{}={}".format(name, value))
colors=<tf.RaggedTensor [[b'red', b'blue'], [b'orange'], [b'black', b'yellow'], [b'green']]> lengths=<tf.RaggedTensor [[7], [], [1, 3], [3, 5, 2]]>
tf.io.RaggedFeature는 비정형 차원이 여러 개인 특성을 읽는 데에도 사용할 수 있습니다. 자세한 내용은 API 설명서를 참조하세요.
데이터세트
tf.data는 간단하고 재사용 가능한 부분으로 복잡한 입력 파이프라인을 구축할 수 있는 API입니다. 핵심 데이터 구조는 tf.data.Dataset이며, 이는 각 요소가 하나 이상의 구성 요소로 이루어진 일련의 요소를 나타냅니다.
# Helper function used to print datasets in the examples below.
def print_dictionary_dataset(dataset):
for i, element in enumerate(dataset):
print("Element {}:".format(i))
for (feature_name, feature_value) in element.items():
print('{:>14} = {}'.format(feature_name, feature_value))
비정형 텐서로 데이터세트 빌드하기
tf.Tensor 또는 Dataset.from_tensor_slices와 같은 NumPy array로부터 데이터세트를 빌드하는 데 사용되는 메서드를 동일하게 사용하여 비정형 텐서로부터 데이터세트를 빌드할 수 있습니다.
dataset = tf.data.Dataset.from_tensor_slices(feature_tensors)
print_dictionary_dataset(dataset)
Element 0:
colors = [b'red' b'blue']
lengths = [7]
Element 1:
colors = [b'orange']
lengths = []
Element 2:
colors = [b'black' b'yellow']
lengths = [1 3]
Element 3:
colors = [b'green']
lengths = [3 5 2]
참고: Dataset.from_generator는 아직 비정형 텐서를 지원하지 않지만 곧 지원이 추가될 예정입니다.
비정형 텐서를 사용한 데이터세트 일괄 처리 및 일괄 해제
Dataset.batch 메서드를 사용하여 비정형 텐서가 있는 데이터세트를 일괄 처리할 수 있습니다(n개의 연속된 요소를 단일 요소로 결합).
batched_dataset = dataset.batch(2)
print_dictionary_dataset(batched_dataset)
Element 0:
colors = <tf.RaggedTensor [[b'red', b'blue'], [b'orange']]>
lengths = <tf.RaggedTensor [[7], []]>
Element 1:
colors = <tf.RaggedTensor [[b'black', b'yellow'], [b'green']]>
lengths = <tf.RaggedTensor [[1, 3], [3, 5, 2]]>
반대로, Dataset.unbatch를 사용하여 일괄 처리된 데이터세트를 보통의 데이터세트로 변환할 수 있습니다.
unbatched_dataset = batched_dataset.unbatch()
print_dictionary_dataset(unbatched_dataset)
Element 0:
colors = [b'red' b'blue']
lengths = [7]
Element 1:
colors = [b'orange']
lengths = []
Element 2:
colors = [b'black' b'yellow']
lengths = [1 3]
Element 3:
colors = [b'green']
lengths = [3 5 2]
비정형이 아닌 가변 길이 텐서를 사용하여 데이터세트 일괄 처리하기
비정형이 아닌 텐서를 포함하는 데이터세트가 있고 텐서 길이가 요소마다 다른 경우, dense_to_ragged_batch 변환을 적용하여 이러한 비정형이 아닌 텐서를 비정형 텐서로 일괄 처리할 수 있습니다.
non_ragged_dataset = tf.data.Dataset.from_tensor_slices([1, 5, 3, 2, 8])
non_ragged_dataset = non_ragged_dataset.map(tf.range)
batched_non_ragged_dataset = non_ragged_dataset.apply(
tf.data.experimental.dense_to_ragged_batch(2))
for element in batched_non_ragged_dataset:
print(element)
<tf.RaggedTensor [[0], [0, 1, 2, 3, 4]]> <tf.RaggedTensor [[0, 1, 2], [0, 1]]> <tf.RaggedTensor [[0, 1, 2, 3, 4, 5, 6, 7]]>
비정형 텐서를 사용하여 데이터세트 변환하기
Dataset.map을 사용하여 데이터세트에서 비정형 텐서를 생성하거나 변환할 수도 있습니다.
def transform_lengths(features):
return {
'mean_length': tf.math.reduce_mean(features['lengths']),
'length_ranges': tf.ragged.range(features['lengths'])}
transformed_dataset = dataset.map(transform_lengths)
print_dictionary_dataset(transformed_dataset)
Element 0: mean_length = 7 length_ranges = <tf.RaggedTensor [[0, 1, 2, 3, 4, 5, 6]]> Element 1: mean_length = 0 length_ranges = <tf.RaggedTensor []> Element 2: mean_length = 2 length_ranges = <tf.RaggedTensor [[0], [0, 1, 2]]> Element 3: mean_length = 3 length_ranges = <tf.RaggedTensor [[0, 1, 2], [0, 1, 2, 3, 4], [0, 1]]>
tf.function
tf.function은 Python 함수용 TensorFlow 그래프를 미리 계산하는 데코레이터로, 이후 TensorFlow 코드의 성능을 크게 향상시킬 수 있습니다. @tf.function 데코레이트된 함수로 비정형 텐서를 투명하게 사용할 수 있습니다. 예를 들어 다음 함수는 비정형 텐서와 비정형이 아닌 텐서 모두에서 작동합니다.
@tf.function
def make_palindrome(x, axis):
return tf.concat([x, tf.reverse(x, [axis])], axis)
make_palindrome(tf.constant([[1, 2], [3, 4], [5, 6]]), axis=1)
<tf.Tensor: shape=(3, 4), dtype=int32, numpy=
array([[1, 2, 2, 1],
[3, 4, 4, 3],
[5, 6, 6, 5]], dtype=int32)>
make_palindrome(tf.ragged.constant([[1, 2], [3], [4, 5, 6]]), axis=1)
2022-12-14 22:02:16.103151: W tensorflow/core/grappler/optimizers/loop_optimizer.cc:907] Skipping loop optimization for Merge node with control input: RaggedConcat/assert_equal_1/Assert/AssertGuard/branch_executed/_9 <tf.RaggedTensor [[1, 2, 2, 1], [3, 3], [4, 5, 6, 6, 5, 4]]>
tf.function에 대한 input_signature를 명시적으로 지정하려면 tf.RaggedTensorSpec을 사용할 수 있습니다.
@tf.function(
input_signature=[tf.RaggedTensorSpec(shape=[None, None], dtype=tf.int32)])
def max_and_min(rt):
return (tf.math.reduce_max(rt, axis=-1), tf.math.reduce_min(rt, axis=-1))
max_and_min(tf.ragged.constant([[1, 2], [3], [4, 5, 6]]))
(<tf.Tensor: shape=(3,), dtype=int32, numpy=array([2, 3, 6], dtype=int32)>, <tf.Tensor: shape=(3,), dtype=int32, numpy=array([1, 3, 4], dtype=int32)>)
구체적인 함수
구체적인 함수는 tf.function에 의해 빌드된 개별 추적 그래프를 캡슐화합니다. 비정형 텐서는 구체적인 함수와 함께 투명하게 사용할 수 있습니다.
@tf.function
def increment(x):
return x + 1
rt = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
cf = increment.get_concrete_function(rt)
print(cf(rt))
<tf.RaggedTensor [[2, 3], [4], [5, 6, 7]]>
SavedModel
SavedModel은 가중치와 계산을 모두 포함하는 직렬화된 TensorFlow 프로그램으로, Keras 모델 또는 사용자 지정 모델로부터 빌드할 수 있습니다. 두 경우 모두, SavedModel에 의해 정의된 함수 및 메서드와 함께 비정형 텐서를 투명하게 사용할 수 있습니다.
예제: Keras 모델 저장
import tempfile
keras_module_path = tempfile.mkdtemp()
tf.saved_model.save(keras_model, keras_module_path)
imported_model = tf.saved_model.load(keras_module_path)
imported_model(hashed_words)
WARNING:absl:Function `_wrapped_model` contains input name(s) args_0 with unsupported characters which will be renamed to args_0_1 in the SavedModel.
INFO:tensorflow:Assets written to: /tmpfs/tmp/tmpcoydmq0s/assets
INFO:tensorflow:Assets written to: /tmpfs/tmp/tmpcoydmq0s/assets
<tf.Tensor: shape=(4, 1), dtype=float32, numpy=
array([[-0.00071245],
[-0.00576008],
[-0.00501249],
[-0.00205732]], dtype=float32)>
예제: 사용자 지정 모델 저장
class CustomModule(tf.Module):
def __init__(self, variable_value):
super(CustomModule, self).__init__()
self.v = tf.Variable(variable_value)
@tf.function
def grow(self, x):
return x * self.v
module = CustomModule(100.0)
# Before saving a custom model, you must ensure that concrete functions are
# built for each input signature that you will need.
module.grow.get_concrete_function(tf.RaggedTensorSpec(shape=[None, None],
dtype=tf.float32))
custom_module_path = tempfile.mkdtemp()
tf.saved_model.save(module, custom_module_path)
imported_model = tf.saved_model.load(custom_module_path)
imported_model.grow(tf.ragged.constant([[1.0, 4.0, 3.0], [2.0]]))
INFO:tensorflow:Assets written to: /tmpfs/tmp/tmpzmuc06d7/assets INFO:tensorflow:Assets written to: /tmpfs/tmp/tmpzmuc06d7/assets <tf.RaggedTensor [[100.0, 400.0, 300.0], [200.0]]>
참고: SavedModel 서명은 구체적인 함수입니다. 위의 구체적인 함수 섹션에서 논의한 것처럼 비정형 텐서는 TensorFlow 2.3 이후부터만 구체적인 함수에 의해 올바르게 처리됩니다. 이전 버전의 TensorFlow에서 SavedModel 서명을 사용해야 하는 경우 비정형 텐서를 개별 구성 텐서로 분해하는 것이 좋습니다.
오버로드된 연산자
RaggedTensor 클래스는 표준 Python 산술 및 비교 연산자를 오버로드하여 기본 요소 별 수학을 쉽게 수행할 수 있습니다:
x = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
y = tf.ragged.constant([[1, 1], [2], [3, 3, 3]])
print(x + y)
<tf.RaggedTensor [[2, 3], [5], [7, 8, 9]]>
오버로드된 연산자는 요소별 계산을 수행하므로 모든 이진 연산에 대한 입력은 동일한 형상을 갖거나 동일한 형상으로 브로드캐스트할 수 있어야 합니다. 가장 단순한 브로드캐스팅의 경우에 단일 스칼라가 비정형 텐서의 각 값과 요소별로 결합됩니다.
x = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
print(x + 3)
<tf.RaggedTensor [[4, 5], [6], [7, 8, 9]]>
고급 사례에 대한 논의는 브로드캐스팅 섹션을 참조하세요.
비정형 텐서는 일반 텐서와 동일한 연산자 세트를 오버로드합니다:단항 연산자 -, ~ 및 abs(); 그리고 이항 연산자 +, -, *, /, //, %, **, &, |, ^, ==, <, <=, > 및 >=.
인덱싱
비정형 텐서는 다차원 인덱싱 및 슬라이싱을 포함하여 Python 스타일의 인덱싱을 지원합니다. 다음 예는 2D 및 3D 비정형 텐서를 사용한 비정형 텐서 인덱싱을 보여줍니다.
인덱싱 예제: 2D 비정형 텐서
queries = tf.ragged.constant(
[['Who', 'is', 'George', 'Washington'],
['What', 'is', 'the', 'weather', 'tomorrow'],
['Goodnight']])
print(queries[1]) # A single query
tf.Tensor([b'What' b'is' b'the' b'weather' b'tomorrow'], shape=(5,), dtype=string)
print(queries[1, 2]) # A single word
tf.Tensor(b'the', shape=(), dtype=string)
print(queries[1:]) # Everything but the first row
<tf.RaggedTensor [[b'What', b'is', b'the', b'weather', b'tomorrow'], [b'Goodnight']]>
print(queries[:, :3]) # The first 3 words of each query
<tf.RaggedTensor [[b'Who', b'is', b'George'], [b'What', b'is', b'the'], [b'Goodnight']]>
print(queries[:, -2:]) # The last 2 words of each query
<tf.RaggedTensor [[b'George', b'Washington'], [b'weather', b'tomorrow'], [b'Goodnight']]>
인덱싱 예제: 3D 비정형 텐서
rt = tf.ragged.constant([[[1, 2, 3], [4]],
[[5], [], [6]],
[[7]],
[[8, 9], [10]]])
print(rt[1]) # Second row (2D RaggedTensor)
<tf.RaggedTensor [[5], [], [6]]>
print(rt[3, 0]) # First element of fourth row (1D Tensor)
tf.Tensor([8 9], shape=(2,), dtype=int32)
print(rt[:, 1:3]) # Items 1-3 of each row (3D RaggedTensor)
<tf.RaggedTensor [[[4]], [[], [6]], [], [[10]]]>
print(rt[:, -1:]) # Last item of each row (3D RaggedTensor)
<tf.RaggedTensor [[[4]], [[6]], [[7]], [[10]]]>
RaggedTensor는 다차원 인덱싱 및 슬라이싱을 지원하지만 한 가지 제한이 있습니다. 바로 비정형 차원으로의 인덱싱은 허용되지 않는 다는 것입니다. 이 경우 표시된 값이 일부 행에는 있지만 다른 행에는 없을 수 있기 때문에 문제가 됩니다. 이러한 경우에 (1) IndexError를 발생시켜야 하는지, (2) 기본값을 사용해야 하는지, 또는 (3) 해당 값을 건너뛰고 처음 시작한 것보다 적은 행을 가진 텐서를 반환해야 하는지 여부가 분명하지 않습니다. Python의 기본 원칙("모호한 상황에서 추측하려는 유혹 거부")에 따라 이 연산은 현재 허용되지 않습니다.
텐서 형 변환
RaggedTensor 클래스는 RaggedTensor와 tf.Tensor 또는 tf.SparseTensors 사이를 변환하는데 사용할 수 있는 메서드를 정의합니다:
ragged_sentences = tf.ragged.constant([
['Hi'], ['Welcome', 'to', 'the', 'fair'], ['Have', 'fun']])
# RaggedTensor -> Tensor
print(ragged_sentences.to_tensor(default_value='', shape=[None, 10]))
tf.Tensor( [[b'Hi' b'' b'' b'' b'' b'' b'' b'' b'' b''] [b'Welcome' b'to' b'the' b'fair' b'' b'' b'' b'' b'' b''] [b'Have' b'fun' b'' b'' b'' b'' b'' b'' b'' b'']], shape=(3, 10), dtype=string)
# Tensor -> RaggedTensor
x = [[1, 3, -1, -1], [2, -1, -1, -1], [4, 5, 8, 9]]
print(tf.RaggedTensor.from_tensor(x, padding=-1))
<tf.RaggedTensor [[1, 3], [2], [4, 5, 8, 9]]>
#RaggedTensor -> SparseTensor
print(ragged_sentences.to_sparse())
SparseTensor(indices=tf.Tensor( [[0 0] [1 0] [1 1] [1 2] [1 3] [2 0] [2 1]], shape=(7, 2), dtype=int64), values=tf.Tensor([b'Hi' b'Welcome' b'to' b'the' b'fair' b'Have' b'fun'], shape=(7,), dtype=string), dense_shape=tf.Tensor([3 4], shape=(2,), dtype=int64))
# SparseTensor -> RaggedTensor
st = tf.SparseTensor(indices=[[0, 0], [2, 0], [2, 1]],
values=['a', 'b', 'c'],
dense_shape=[3, 3])
print(tf.RaggedTensor.from_sparse(st))
<tf.RaggedTensor [[b'a'], [], [b'b', b'c']]>
비정형 텐서 평가
즉시 실행 모드에서는, 비정형 텐서가 즉시 실행됩니다. 포함된 값에 접근하려면 다음을 수행하십시오:
tf.RaggedTensor.to_list를 사용하여 비정형 텐서를 중첩된 Python 목록으로 변환합니다.tf.RaggedTensor.numpy를 사용하여 비정형 텐서를 값이 중첩된 NumPy 배열인 NumPy 배열로 변환합니다.tf.RaggedTensor.values및tf.RaggedTensor.row_splits속성, 또는tf.RaggedTensor.row_lengths및tf.RaggedTensor.value_rowids와 같은 행-분할 메서드를 사용하여 비정형 텐서를 해당 구성 요소로 분해합니다.- Python 인덱싱을 사용하여 비정형 텐서에서 값을 선택합니다.
rt = tf.ragged.constant([[1, 2], [3, 4, 5], [6], [], [7]])
print("Python list:", rt.to_list())
print("NumPy array:", rt.numpy())
print("Values:", rt.values.numpy())
print("Splits:", rt.row_splits.numpy())
print("Indexed value:", rt[1].numpy())
Python list: [[1, 2], [3, 4, 5], [6], [], [7]] NumPy array: [array([1, 2], dtype=int32) array([3, 4, 5], dtype=int32) array([6], dtype=int32) array([], dtype=int32) array([7], dtype=int32)] Values: [1 2 3 4 5 6 7] Splits: [0 2 5 6 6 7] Indexed value: [3 4 5]
비정형 형상
텐서의 형상은 각 축의 크기를 지정합니다. 예를 들어 3개의 행과 2개의 열이 있는 [[1, 2], [3, 4], [5, 6]]의 형상은 [3, 2]입니다. TensorFlow는 독립적이지만 관련이 있는 2가지 방식으로 형상을 설명합니다.
정적 형상: 정적인 것으로 알려진 축 크기에 대한 정보입니다(예:
tf.function추적 과정). 부분적으로 지정할 수도 있습니다.동적 형상: 축 크기에 대한 런타임 정보입니다.
정적 형상
텐서의 정적 형상에는 그래프 구성 시점에 알려진 축 크기에 대한 정보가 포함되어 있습니다. tf.Tensor와 tf.RaggedTensor 모두 .shape 속성을 사용하여 사용할 수 있으며 tf.TensorShape를 사용하여 인코딩됩니다.
x = tf.constant([[1, 2], [3, 4], [5, 6]])
x.shape # shape of a tf.tensor
TensorShape([3, 2])
rt = tf.ragged.constant([[1], [2, 3], [], [4]])
rt.shape # shape of a tf.RaggedTensor
TensorShape([4, None])
비정형 차원의 정적 형상은 항상 None(지정되지 않음)입니다. 그러나 그 반대는 사실이 아닙니다. TensorShape 차원이 None일 경우 해당 차원이 비정형임을 나타내는 것일 수 있습니다. 또는 차원은 정형이지만 크기는 정적으로 알려져 있지 않음을 나타냅니다.
동적 형상
텐서의 동적 형상은 그래프가 실행될 때 알려진 축 크기에 대한 정보를 포함합니다. 이는 tf.shape 연산을 사용하여 구성됩니다. tf.Tensor의 경우 tf.shape는 형상을 1D 정수 Tensor로 반환합니다. 여기서 tf.shape(x)[i ]는 i 축의 크기입니다.
x = tf.constant([['a', 'b'], ['c', 'd'], ['e', 'f']])
tf.shape(x)
<tf.Tensor: shape=(2,), dtype=int32, numpy=array([3, 2], dtype=int32)>
다만 1D Tensor는 tf.RaggedTensor의 형상을 설명하기에 충분하지 않습니다. 대신 비정형 텐서의 동적 형상은 전용 유형인 tf.experimental.DynamicRaggedShape를 사용하여 인코딩됩니다. 다음 예제에서 tf.shape(rt)로 반환한 DynamicRaggedShape는 비정형 텐서에 길이가 1, 3, 0, 2인 4개의 행이 있음을 나타냅니다.
rt = tf.ragged.constant([[1], [2, 3, 4], [], [5, 6]])
rt_shape = tf.shape(rt)
print(rt_shape)
<DynamicRaggedShape lengths=[4, (1, 3, 0, 2)] num_row_partitions=1>
동적 형상: 연산
DynamicRaggedShape는 tf.reshape, tf.zeros, tf.ones, tf.fill, tf.broadcast_dynamic_shape, tf.broadcast_to 등 형상을 예상하는 대부분의 TensorFlow 연산에 사용할 수 있습니다.
print(f"tf.reshape(x, rt_shape) = {tf.reshape(x, rt_shape)}")
print(f"tf.zeros(rt_shape) = {tf.zeros(rt_shape)}")
print(f"tf.ones(rt_shape) = {tf.ones(rt_shape)}")
print(f"tf.fill(rt_shape, 9) = {tf.fill(rt_shape, 'x')}")
tf.reshape(x, rt_shape) = <tf.RaggedTensor [[b'a'], [b'b', b'c', b'd'], [], [b'e', b'f']]> tf.zeros(rt_shape) = <tf.RaggedTensor [[0.0], [0.0, 0.0, 0.0], [], [0.0, 0.0]]> tf.ones(rt_shape) = <tf.RaggedTensor [[1.0], [1.0, 1.0, 1.0], [], [1.0, 1.0]]> tf.fill(rt_shape, 9) = <tf.RaggedTensor [[b'x'], [b'x', b'x', b'x'], [], [b'x', b'x']]>
동적 형상: 인덱싱 및 슬라이싱
DynamicRaggedShape는 균일한 차원 크기로 인덱싱할 수도 있습니다. 예를 들어 tf.shape(rt)[0]을 사용하여 비정형 텐서의 행 수를 확인할 수 있습니다(비정형 텐서가 아닌 경우와 동일.
rt_shape[0]
<tf.Tensor: shape=(), dtype=int32, numpy=4>
그러나 단일 크기를 갖지 않기에 비정형 차원의 크기를 검색하기 위해 인덱싱을 사용할 경우 오류가 발생합니다(RaggedTensor는 비정형 축을 추적하므로 이 오류는 즉시 실행 중이거나 tf.function을 추적하는 경우에만 발생합니다. 콘크리트 함수를실행할 경우에는 발생하지 않습니다).
try:
rt_shape[1]
except ValueError as e:
print("Got expected ValueError:", e)
Got expected ValueError: Index 1 is not uniform
슬라이스가 축 0으로 시작하거나 밀집 차원만 포함하는 경우 DynamicRaggedShape도 슬라이싱할 수 있습니다.
rt_shape[:1]
<DynamicRaggedShape lengths=[4] num_row_partitions=0>
동적 형상: 인코딩
DynamicRaggedShape는 다음 두 필드를 사용하여 인코딩됩니다.
inner_shape: 밀집tf.Tensor의 형상을 제공하는 정수 벡터입니다.row_partitions: 비정형 축을 추가하기 위해 내부 형상의 가장 바깥쪽 차원을 분할하는 방법을 설명하는tf.experimental.RowPartition객체 목록입니다.
행 분할에 대한 자세한 정보는 아래의 'RaggedTensor 인코딩' 섹션과 tf.experimental.RowPartition에 대한 API 문서를 참고합니다.
동적 형상: 구성
DynamicRaggedShape는 tf.shape를 RaggedTensor에 적용하는 방식을 가장 많이 사용하여 구성하지만 직접 구성할 수도 있습니다.
tf.experimental.DynamicRaggedShape(
row_partitions=[tf.experimental.RowPartition.from_row_lengths([5, 3, 2])],
inner_shape=[10, 8])
<DynamicRaggedShape lengths=[3, (5, 3, 2), 8] num_row_partitions=1>
모든 행의 길이를 정적으로 알고 있는 경우 DynamicRaggedShape.from_lengths를 사용하여 동적 비정형 형상을 구성할 수도 있습니다(비정형 차원의 길이가 정적으로 알려진 경우는 드물기 때문에 주로 테스트 및 데모 코드에 유용합니다).
tf.experimental.DynamicRaggedShape.from_lengths([4, (2, 1, 0, 8), 12])
<DynamicRaggedShape lengths=[4, (2, 1, 0, 8), 12] num_row_partitions=1>
Broadcasting
브로드캐스팅은 여러 형상의 텐서를 요소별 연산에 대해 호환 가능한 형상으로 만드는 프로세스입니다. 브로드캐스팅에 관한 자세한 배경 정보는 다음을 참조하세요.
호환 가능한 형태를 갖도록 두 개의 입력 x 와 y 를 브로드캐스팅하는 기본 단계는 다음과 같습니다:
x와y의 차원 수가 동일하지 않은 경우, 외부 차원 (크기 1)을 차원 수가 동일해질 때까지 추가합니다 .x와y의 크기가 다른 각 차원에 대해:
x또는y가 차원d에서1의 크기를 갖는 경우, 다른 입력 크기와 일치하도록 차원d에 걸쳐 값을 반복합니다.- 그렇지 않으면 예외를 발생시킵니다(
x및y는 브로드캐스트 호환되지 않음).
여기서 균일한 차원의 텐서 크기는 단일 숫자이고(해당 차원 전체의 슬라이스 크기) 비정형 차원의 텐서 크기는 슬라이스 길이 목록입니다(해당 차원의 모든 슬라이스에 대해).
Broadcasting examples
# x (2D ragged): 2 x (num_rows)
# y (scalar)
# result (2D ragged): 2 x (num_rows)
x = tf.ragged.constant([[1, 2], [3]])
y = 3
print(x + y)
<tf.RaggedTensor [[4, 5], [6]]>
# x (2d ragged): 3 x (num_rows)
# y (2d tensor): 3 x 1
# Result (2d ragged): 3 x (num_rows)
x = tf.ragged.constant(
[[10, 87, 12],
[19, 53],
[12, 32]])
y = [[1000], [2000], [3000]]
print(x + y)
<tf.RaggedTensor [[1010, 1087, 1012], [2019, 2053], [3012, 3032]]>
# x (3d ragged): 2 x (r1) x 2
# y (2d ragged): 1 x 1
# Result (3d ragged): 2 x (r1) x 2
x = tf.ragged.constant(
[[[1, 2], [3, 4], [5, 6]],
[[7, 8]]],
ragged_rank=1)
y = tf.constant([[10]])
print(x + y)
<tf.RaggedTensor [[[11, 12], [13, 14], [15, 16]], [[17, 18]]]>
# x (3d ragged): 2 x (r1) x (r2) x 1
# y (1d tensor): 3
# Result (3d ragged): 2 x (r1) x (r2) x 3
x = tf.ragged.constant(
[
[
[[1], [2]],
[],
[[3]],
[[4]],
],
[
[[5], [6]],
[[7]]
]
],
ragged_rank=2)
y = tf.constant([10, 20, 30])
print(x + y)
<tf.RaggedTensor [[[[11, 21, 31], [12, 22, 32]], [], [[13, 23, 33]], [[14, 24, 34]]], [[[15, 25, 35], [16, 26, 36]], [[17, 27, 37]]]]>
브로드캐스트 하지 않는 형태의 예는 다음과 같습니다:
# x (2d ragged): 3 x (r1)
# y (2d tensor): 3 x 4 # trailing dimensions do not match
x = tf.ragged.constant([[1, 2], [3, 4, 5, 6], [7]])
y = tf.constant([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Condition x == y did not hold. Indices of first 3 different values: [[1] [2] [3]] Corresponding x values: [ 4 8 12] Corresponding y values: [2 6 7] First 3 elements of x: [0 4 8] First 3 elements of y: [0 2 6]
# x (2d ragged): 3 x (r1)
# y (2d ragged): 3 x (r2) # ragged dimensions do not match.
x = tf.ragged.constant([[1, 2, 3], [4], [5, 6]])
y = tf.ragged.constant([[10, 20], [30, 40], [50]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Condition x == y did not hold. Indices of first 2 different values: [[1] [3]] Corresponding x values: [3 6] Corresponding y values: [2 5] First 3 elements of x: [0 3 4] First 3 elements of y: [0 2 4]
# x (3d ragged): 3 x (r1) x 2
# y (3d ragged): 3 x (r1) x 3 # trailing dimensions do not match
x = tf.ragged.constant([[[1, 2], [3, 4], [5, 6]],
[[7, 8], [9, 10]]])
y = tf.ragged.constant([[[1, 2, 0], [3, 4, 0], [5, 6, 0]],
[[7, 8, 0], [9, 10, 0]]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Condition x == y did not hold. Indices of first 3 different values: [[1] [2] [3]] Corresponding x values: [2 4 6] Corresponding y values: [3 6 9] First 3 elements of x: [0 2 4] First 3 elements of y: [0 3 6]
RaggedTensor 인코딩
비정형텐서는 RaggedTensor 클래스를 사용하여 인코딩됩니다. 내부적으로, 각 RaggedTensor는 다음으로 구성됩니다:
- 가변 길이 행을 평면화된 목록으로 연결하는
values텐서 - 이러한 평면화된 값이 행으로 분할되는 방식을 나타내는
row_partition
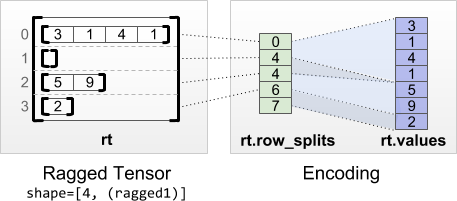
row_partition은 네 가지 인코딩을 사용하여 저장할 수 있습니다.
row_splits는 행 사이의 분할 지점을 지정하는 정수 벡터입니다.value_rowids는 각 값에 대한 행 인덱스를 지정하는 정수 벡터입니다.row_lengths는 각 행의 길이를 지정하는 정수 벡터입니다.uniform_row_length는 모든 행에 대해 단일 길이를 지정하는 정수 스칼라입니다.
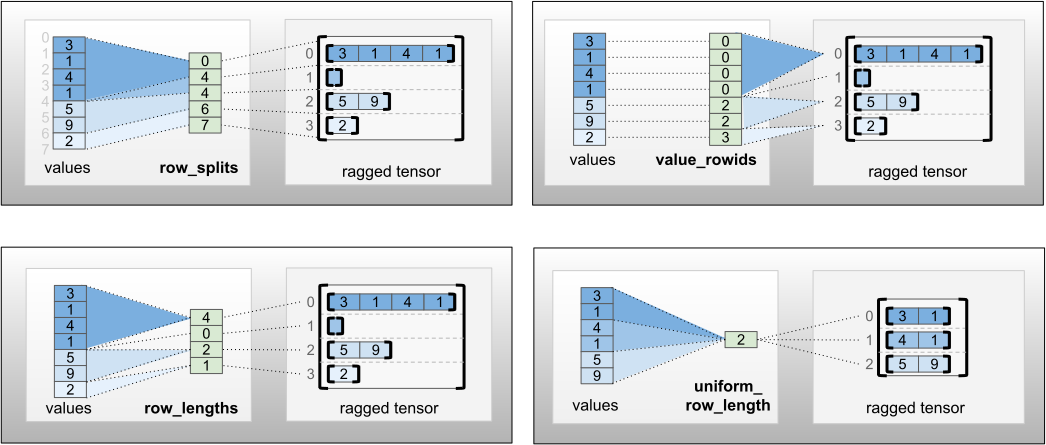
정수 스칼라 nrows는 value_rowids가 있는 빈 후행 행 또는 uniform_row_length가 있는 빈 행을 고려하기 위해 row_partition에 포함될 수도 있습니다.
rt = tf.RaggedTensor.from_row_splits(
values=[3, 1, 4, 1, 5, 9, 2],
row_splits=[0, 4, 4, 6, 7])
print(rt)
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
일부 컨텍스트에서 효율성을 개선하기 위해 비정형 텐서에서 행 파티션에 사용할 인코딩 선택을 내부적으로 관리합니다. 특히, 다양한 행 분할 방식의 일부 장점과 단점을 설명하면 다음과 같습니다.
- 효율적인 인덱싱:
row_splits인코딩은 일정 시간 인덱싱 및 비정형 텐서로의 슬라이싱을 가능하게 합니다. - 효율적인 연결: 두 개의 텐서가 함께 연결될 때 행 길이는 변하지 않기 때문에 비정형 텐서를 연결할 때
row_lengths인코딩의 효율이 향상됩니다. - 작은 인코딩 크기: 빈 행이 많은 비정형 텐서를 저장할 때
value_rowids인코딩의 효율이 향상되는데, 텐서의 크기는 값의 총 개수에만 의존하기 때문입니다. 반면에 행이 긴 비정형 텐서를 저장할 때는row_splits및row_lengths인코딩의 효율이 향상되는데, 각 행에 하나의 스칼라 값만 필요하기 때문입니다. - 호환성:
value_rowids방식은tf.segment_sum과 같은 연산에서 사용하는 세분화 형식과 일치합니다.row_limits방식은tf.sequence_mask와 같은 연산에서 사용하는 형식과 일치합니다. - 균일 차원: 아래에서 설명하는 바와 같이
uniform_row_length인코딩은 균일한 차원으로 비정형 텐서를 인코딩하는 데 사용됩니다.
다수의 비정형 차원
다수의 비정형 차원을 갖는 비정형 텐서는 values 텐서에 대해 중첩된 RaggedTensor를 사용하여 인코딩됩니다. 중첩된 각 RaggedTensor는 단일 비정형 차원을 추가합니다.
![]()
rt = tf.RaggedTensor.from_row_splits(
values=tf.RaggedTensor.from_row_splits(
values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
row_splits=[0, 3, 3, 5, 9, 10]),
row_splits=[0, 1, 1, 5])
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
<tf.RaggedTensor [[[10, 11, 12]], [], [[], [13, 14], [15, 16, 17, 18], [19]]]> Shape: (3, None, None) Number of partitioned dimensions: 2
팩토리 함수 tf.RaggedTensor.from_nested_row_splits는 row_splits 텐서 목록을 제공하여 여러 비정형 차원을 가진 RaggedTensor를 직접 구성하는 데 사용할 수 있습니다.
rt = tf.RaggedTensor.from_nested_row_splits(
flat_values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
nested_row_splits=([0, 1, 1, 5], [0, 3, 3, 5, 9, 10]))
print(rt)
<tf.RaggedTensor [[[10, 11, 12]], [], [[], [13, 14], [15, 16, 17, 18], [19]]]>
비정형 순위 및 평면 값
비정형 텐서의 비정형 순위는 기본 values 텐서가 분할된 횟수입니다(즉, RaggedTensor 객체의 중첩 깊이). 가장 안쪽 values 텐서를 flat_values이라고 합니다. 다음 예에서 conversations는 ragged_rank=3이고 flat_values는 24개의 문자열이 있는 1D Tensor입니다.
# shape = [batch, (paragraph), (sentence), (word)]
conversations = tf.ragged.constant(
[[[["I", "like", "ragged", "tensors."]],
[["Oh", "yeah?"], ["What", "can", "you", "use", "them", "for?"]],
[["Processing", "variable", "length", "data!"]]],
[[["I", "like", "cheese."], ["Do", "you?"]],
[["Yes."], ["I", "do."]]]])
conversations.shape
TensorShape([2, None, None, None])
assert conversations.ragged_rank == len(conversations.nested_row_splits)
conversations.ragged_rank # Number of partitioned dimensions.
3
conversations.flat_values.numpy()
array([b'I', b'like', b'ragged', b'tensors.', b'Oh', b'yeah?', b'What',
b'can', b'you', b'use', b'them', b'for?', b'Processing',
b'variable', b'length', b'data!', b'I', b'like', b'cheese.', b'Do',
b'you?', b'Yes.', b'I', b'do.'], dtype=object)
정형한 내부 차원
내부 차원이 정형한 비정형 텐서는 values에 다차원 tf.Tensor를 사용하여 인코딩됩니다.
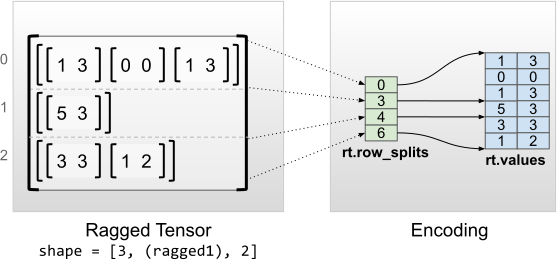
rt = tf.RaggedTensor.from_row_splits(
values=[[1, 3], [0, 0], [1, 3], [5, 3], [3, 3], [1, 2]],
row_splits=[0, 3, 4, 6])
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
print("Flat values shape: {}".format(rt.flat_values.shape))
print("Flat values:\n{}".format(rt.flat_values))
<tf.RaggedTensor [[[1, 3],
[0, 0],
[1, 3]], [[5, 3]], [[3, 3],
[1, 2]]]>
Shape: (3, None, 2)
Number of partitioned dimensions: 1
Flat values shape: (6, 2)
Flat values:
[[1 3]
[0 0]
[1 3]
[5 3]
[3 3]
[1 2]]
균일한 비내부 차원
균일한 비내부 차원을 갖는 비정형 텐서는 uniform_row_length로 행을 분할하여 인코딩됩니다.
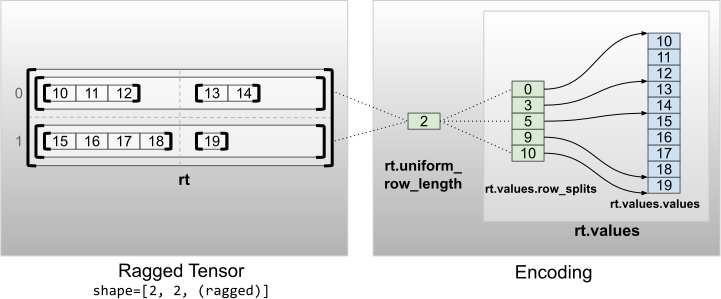
rt = tf.RaggedTensor.from_uniform_row_length(
values=tf.RaggedTensor.from_row_splits(
values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
row_splits=[0, 3, 5, 9, 10]),
uniform_row_length=2)
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
<tf.RaggedTensor [[[10, 11, 12], [13, 14]], [[15, 16, 17, 18], [19]]]> Shape: (2, 2, None) Number of partitioned dimensions: 2