
Rozpoczęcie pracy
TensorFlow Hub to kompleksowe repozytorium wstępnie wytrenowanych modeli gotowych do dostrojenia i wdrożenia w dowolnym miejscu. Pobierz najnowsze wytrenowane modele z minimalną ilością kodu za pomocą biblioteki tensorflow_hub .
Poniższe samouczki powinny pomóc w rozpoczęciu korzystania z modeli z TF Hub i ich stosowaniu do własnych potrzeb. Interaktywne samouczki pozwalają je modyfikować i wykonywać z wprowadzonymi zmianami. Kliknij przycisk Uruchom w Google Colab u góry interaktywnego samouczka, aby przy nim majstrować.
Dla początkujących
Jeśli nie jesteś zaznajomiony z uczeniem maszynowym i TensorFlow, możesz zacząć od uzyskania przeglądu, jak klasyfikować obrazy i tekst, wykrywać obiekty na obrazach lub stylizować własne obrazy, takie jak słynne dzieła sztuki:

Klasyfikacja obrazu
Zbuduj model Keras na podstawie wstępnie wytrenowanego klasyfikatora obrazów, aby rozróżniać kwiaty.
Klasyfikuj tekst za pomocą BERT
Użyj BERT, aby zbudować model Keras, aby rozwiązać zadanie analizy sentymentu klasyfikacji tekstu.Transfer stylu
Pozwól sieci neuronowej na przerysowanie obrazu w stylu Picassa, van Gogha lub jak w Twoim własnym stylu.
Wykrywanie obiektów
Wykrywaj obiekty na obrazach za pomocą modeli takich jak FasterRCNN lub SSD.Dla doświadczonych programistów
Zapoznaj się z bardziej zaawansowanymi samouczkami, aby dowiedzieć się, jak korzystać z NLP, obrazów, audio i modeli wideo z TensorFlow Hub.
Samouczki NLP
Rozwiązuj typowe zadania NLP za pomocą modeli z TensorFlow Hub. Zobacz wszystkie dostępne samouczki NLP w lewym panelu nawigacyjnym.
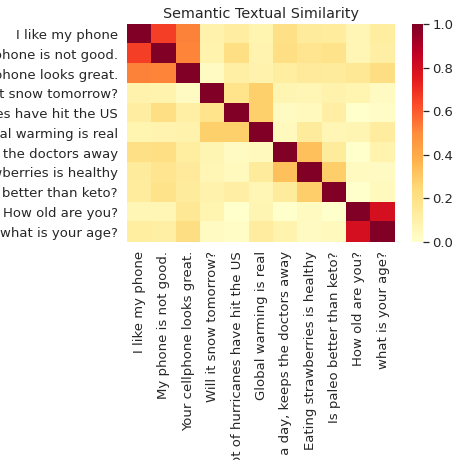
Podobieństwo semantyczne
Klasyfikuj i semantycznie porównuj zdania za pomocą Universal Sentence Encoder.
BERT na TPU
Użyj BERT do rozwiązywania zadań testowych GLUE działających na TPU.Wielojęzyczny uniwersalny koder zdań — pytania i odpowiedzi
Odpowiadaj na wielojęzyczne pytania z zestawu danych SQuAD, korzystając z wielojęzycznego uniwersalnego modelu pytań i odpowiedzi z koderem zdań.Samouczki obrazkowe
Dowiedz się, jak korzystać z sieci GAN, modeli super rozdzielczości i nie tylko. Zobacz wszystkie dostępne samouczki dotyczące obrazów w lewym panelu nawigacyjnym.

GANS do generowania obrazu
Generuj sztuczne twarze i interpoluj między nimi za pomocą GAN.
Super rozdzielczość
Zwiększ rozdzielczość obrazów z próbkowaniem w dół.
Rozszerzenie obrazu
Wypełnij zamaskowaną część podanych obrazów.Samouczki audio
Zapoznaj się z samouczkami wykorzystującymi wytrenowane modele danych dźwiękowych, w tym rozpoznawanie wysokości dźwięku i klasyfikację dźwięku.
Rozpoznawanie tonu
Nagraj swój śpiew i wykryj wysokość swojego głosu za pomocą modelu SPICE.
Klasyfikacja dźwięku
Użyj modelu YAMNet, aby sklasyfikować dźwięki jako 521 klas zdarzeń audio z korpusu AudioSet-YouTube.Samouczki wideo
Wypróbuj wytrenowane modele ML dla danych wideo do rozpoznawania akcji, interpolacji wideo i nie tylko.

Rozpoznawanie działań
Wykryj jedną z 400 akcji w filmie za pomocą modelu Inflated 3D ConvNet.
Interpolacja wideo
Interpoluj między klatkami wideo za pomocą funkcji Inbetweening i Convolutions 3D.