
| | |  Xem nguồn trên GitHub Xem nguồn trên GitHub | |
Tổng quat
TFL Premade tổng hợp Chức năng mô hình là cách nhanh chóng và dễ dàng để xây dựng TFL tf.keras.model hợp cho việc học tập hợp các chức năng phức tạp. Hướng dẫn này phác thảo các bước cần thiết để xây dựng Mô hình chức năng tổng hợp tạo sẵn TFL và đào tạo / kiểm tra nó.
Thành lập
Cài đặt gói TF Lattice:
pip install -q tensorflow-lattice pydot
Nhập các gói bắt buộc:
import tensorflow as tf
import collections
import logging
import numpy as np
import pandas as pd
import sys
import tensorflow_lattice as tfl
logging.disable(sys.maxsize)
Tải xuống tập dữ liệu Câu đố:
train_dataframe = pd.read_csv(
'https://raw.githubusercontent.com/wbakst/puzzles_data/master/train.csv')
train_dataframe.head()
test_dataframe = pd.read_csv(
'https://raw.githubusercontent.com/wbakst/puzzles_data/master/test.csv')
test_dataframe.head()
Trích xuất và chuyển đổi các tính năng và nhãn
# Features:
# - star_rating rating out of 5 stars (1-5)
# - word_count number of words in the review
# - is_amazon 1 = reviewed on amazon; 0 = reviewed on artifact website
# - includes_photo if the review includes a photo of the puzzle
# - num_helpful number of people that found this review helpful
# - num_reviews total number of reviews for this puzzle (we construct)
#
# This ordering of feature names will be the exact same order that we construct
# our model to expect.
feature_names = [
'star_rating', 'word_count', 'is_amazon', 'includes_photo', 'num_helpful',
'num_reviews'
]
def extract_features(dataframe, label_name):
# First we extract flattened features.
flattened_features = {
feature_name: dataframe[feature_name].values.astype(float)
for feature_name in feature_names[:-1]
}
# Construct mapping from puzzle name to feature.
star_rating = collections.defaultdict(list)
word_count = collections.defaultdict(list)
is_amazon = collections.defaultdict(list)
includes_photo = collections.defaultdict(list)
num_helpful = collections.defaultdict(list)
labels = {}
# Extract each review.
for i in range(len(dataframe)):
row = dataframe.iloc[i]
puzzle_name = row['puzzle_name']
star_rating[puzzle_name].append(float(row['star_rating']))
word_count[puzzle_name].append(float(row['word_count']))
is_amazon[puzzle_name].append(float(row['is_amazon']))
includes_photo[puzzle_name].append(float(row['includes_photo']))
num_helpful[puzzle_name].append(float(row['num_helpful']))
labels[puzzle_name] = float(row[label_name])
# Organize data into list of list of features.
names = list(star_rating.keys())
star_rating = [star_rating[name] for name in names]
word_count = [word_count[name] for name in names]
is_amazon = [is_amazon[name] for name in names]
includes_photo = [includes_photo[name] for name in names]
num_helpful = [num_helpful[name] for name in names]
num_reviews = [[len(ratings)] * len(ratings) for ratings in star_rating]
labels = [labels[name] for name in names]
# Flatten num_reviews
flattened_features['num_reviews'] = [len(reviews) for reviews in num_reviews]
# Convert data into ragged tensors.
star_rating = tf.ragged.constant(star_rating)
word_count = tf.ragged.constant(word_count)
is_amazon = tf.ragged.constant(is_amazon)
includes_photo = tf.ragged.constant(includes_photo)
num_helpful = tf.ragged.constant(num_helpful)
num_reviews = tf.ragged.constant(num_reviews)
labels = tf.constant(labels)
# Now we can return our extracted data.
return (star_rating, word_count, is_amazon, includes_photo, num_helpful,
num_reviews), labels, flattened_features
train_xs, train_ys, flattened_features = extract_features(train_dataframe, 'Sales12-18MonthsAgo')
test_xs, test_ys, _ = extract_features(test_dataframe, 'SalesLastSixMonths')
# Let's define our label minimum and maximum.
min_label, max_label = float(np.min(train_ys)), float(np.max(train_ys))
min_label, max_label = float(np.min(train_ys)), float(np.max(train_ys))
Đặt các giá trị mặc định được sử dụng để đào tạo trong hướng dẫn này:
LEARNING_RATE = 0.1
BATCH_SIZE = 128
NUM_EPOCHS = 500
MIDDLE_DIM = 3
MIDDLE_LATTICE_SIZE = 2
MIDDLE_KEYPOINTS = 16
OUTPUT_KEYPOINTS = 8
Cấu hình tính năng
Tính năng hiệu chỉnh và cấu hình cho mỗi tính năng được thiết lập sử dụng tfl.configs.FeatureConfig . Cấu hình tính năng bao gồm các ràng buộc đơn điệu, quy tắc cho mỗi tính năng (xem tfl.configs.RegularizerConfig ), và kích thước lưới cho các mô hình mạng.
Lưu ý rằng chúng ta phải chỉ định đầy đủ cấu hình tính năng cho bất kỳ tính năng nào mà chúng ta muốn mô hình của mình nhận ra. Nếu không, mô hình sẽ không có cách nào để biết rằng một tính năng như vậy tồn tại. Đối với các mô hình tổng hợp, các tính năng này sẽ tự động được xem xét và xử lý thích hợp là bị rách nát.
Tính toán lượng tử
Mặc dù các thiết lập mặc định cho pwl_calibration_input_keypoints trong tfl.configs.FeatureConfig là 'quantiles', cho các mô hình premade chúng ta phải tự xác định keypoint đầu vào. Để làm như vậy, trước tiên chúng tôi xác định chức năng trợ giúp của riêng mình cho các lượng tử tính toán.
def compute_quantiles(features,
num_keypoints=10,
clip_min=None,
clip_max=None,
missing_value=None):
# Clip min and max if desired.
if clip_min is not None:
features = np.maximum(features, clip_min)
features = np.append(features, clip_min)
if clip_max is not None:
features = np.minimum(features, clip_max)
features = np.append(features, clip_max)
# Make features unique.
unique_features = np.unique(features)
# Remove missing values if specified.
if missing_value is not None:
unique_features = np.delete(unique_features,
np.where(unique_features == missing_value))
# Compute and return quantiles over unique non-missing feature values.
return np.quantile(
unique_features,
np.linspace(0., 1., num=num_keypoints),
interpolation='nearest').astype(float)
Xác định cấu hình tính năng của chúng tôi
Bây giờ chúng ta có thể tính toán lượng tử của mình, chúng ta xác định cấu hình tính năng cho từng tính năng mà chúng ta muốn mô hình của mình lấy làm đầu vào.
# Feature configs are used to specify how each feature is calibrated and used.
feature_configs = [
tfl.configs.FeatureConfig(
name='star_rating',
lattice_size=2,
monotonicity='increasing',
pwl_calibration_num_keypoints=5,
pwl_calibration_input_keypoints=compute_quantiles(
flattened_features['star_rating'], num_keypoints=5),
),
tfl.configs.FeatureConfig(
name='word_count',
lattice_size=2,
monotonicity='increasing',
pwl_calibration_num_keypoints=5,
pwl_calibration_input_keypoints=compute_quantiles(
flattened_features['word_count'], num_keypoints=5),
),
tfl.configs.FeatureConfig(
name='is_amazon',
lattice_size=2,
num_buckets=2,
),
tfl.configs.FeatureConfig(
name='includes_photo',
lattice_size=2,
num_buckets=2,
),
tfl.configs.FeatureConfig(
name='num_helpful',
lattice_size=2,
monotonicity='increasing',
pwl_calibration_num_keypoints=5,
pwl_calibration_input_keypoints=compute_quantiles(
flattened_features['num_helpful'], num_keypoints=5),
# Larger num_helpful indicating more trust in star_rating.
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="star_rating", trust_type="trapezoid"),
],
),
tfl.configs.FeatureConfig(
name='num_reviews',
lattice_size=2,
monotonicity='increasing',
pwl_calibration_num_keypoints=5,
pwl_calibration_input_keypoints=compute_quantiles(
flattened_features['num_reviews'], num_keypoints=5),
)
]
Mô hình chức năng tổng hợp
Để xây dựng một mô hình premade TFL, đầu tiên xây dựng một cấu hình mô hình từ tfl.configs . Một mô hình chức năng tổng hợp được xây dựng bằng cách sử dụng tfl.configs.AggregateFunctionConfig . Nó áp dụng hiệu chuẩn từng đoạn tuyến tính và phân loại, theo sau là mô hình mạng tinh thể trên mỗi kích thước của đầu vào bị rách. Sau đó, nó áp dụng một lớp tổng hợp trên đầu ra cho mỗi thứ nguyên. Sau đó, tiếp theo là hiệu chuẩn tuyến tính từng mảnh đầu ra tùy chọn.
# Model config defines the model structure for the aggregate function model.
aggregate_function_model_config = tfl.configs.AggregateFunctionConfig(
feature_configs=feature_configs,
middle_dimension=MIDDLE_DIM,
middle_lattice_size=MIDDLE_LATTICE_SIZE,
middle_calibration=True,
middle_calibration_num_keypoints=MIDDLE_KEYPOINTS,
middle_monotonicity='increasing',
output_min=min_label,
output_max=max_label,
output_calibration=True,
output_calibration_num_keypoints=OUTPUT_KEYPOINTS,
output_initialization=np.linspace(
min_label, max_label, num=OUTPUT_KEYPOINTS))
# An AggregateFunction premade model constructed from the given model config.
aggregate_function_model = tfl.premade.AggregateFunction(
aggregate_function_model_config)
# Let's plot our model.
tf.keras.utils.plot_model(
aggregate_function_model, show_layer_names=False, rankdir='LR')
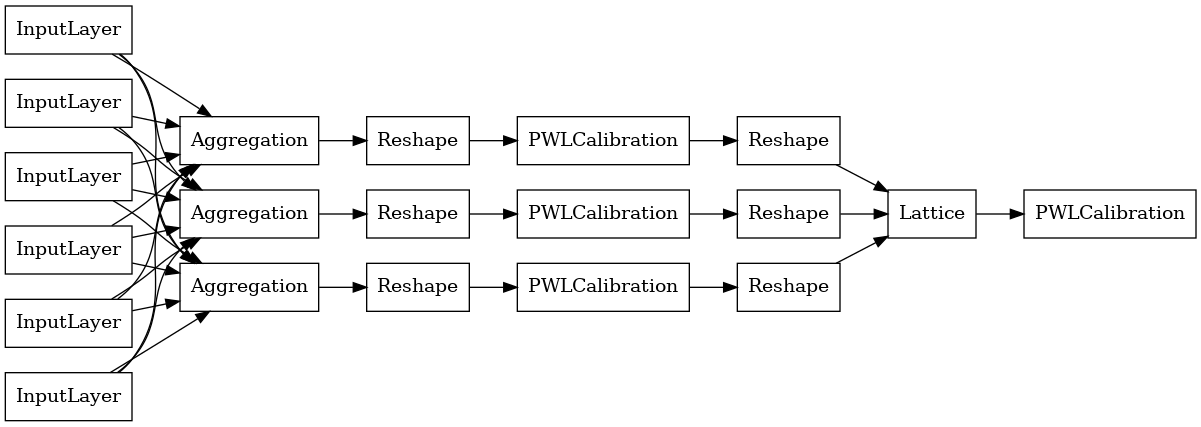
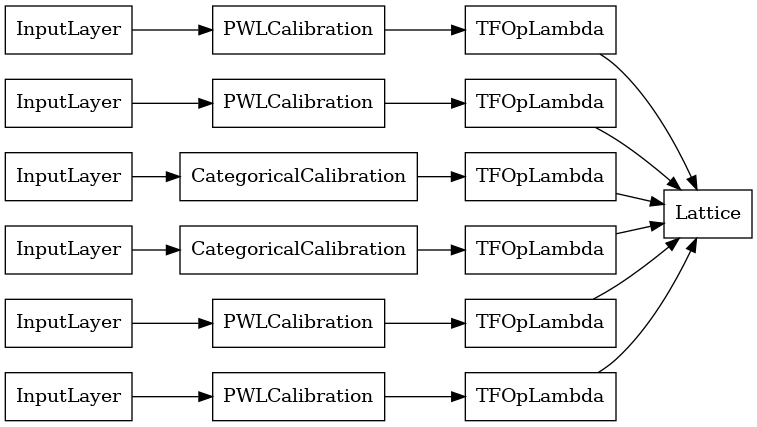
Đầu ra của mỗi lớp Tổng hợp là đầu ra trung bình của một mạng tinh thể đã hiệu chỉnh trên các đầu vào bị rách. Đây là mô hình được sử dụng bên trong lớp Tổng hợp đầu tiên:
aggregation_layers = [
layer for layer in aggregate_function_model.layers
if isinstance(layer, tfl.layers.Aggregation)
]
tf.keras.utils.plot_model(
aggregation_layers[0].model, show_layer_names=False, rankdir='LR')
Bây giờ, như với bất kỳ khác tf.keras.Model , chúng tôi biên soạn và phù hợp với mô hình dữ liệu của chúng tôi.
aggregate_function_model.compile(
loss='mae',
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE))
aggregate_function_model.fit(
train_xs, train_ys, epochs=NUM_EPOCHS, batch_size=BATCH_SIZE, verbose=False)
<tensorflow.python.keras.callbacks.History at 0x7fee7d3033c8>
Sau khi đào tạo mô hình của chúng tôi, chúng tôi có thể đánh giá nó trên bộ thử nghiệm của chúng tôi.
print('Test Set Evaluation...')
print(aggregate_function_model.evaluate(test_xs, test_ys))
Test Set Evaluation... 7/7 [==============================] - 2s 3ms/step - loss: 53.4633 53.4632682800293