
| | |  Xem nguồn trên GitHub Xem nguồn trên GitHub | |
Tổng quat
Hướng dẫn này là tổng quan về các ràng buộc và bộ điều chỉnh được cung cấp bởi thư viện TensorFlow Lattice (TFL). Ở đây chúng tôi sử dụng công cụ ước tính đóng hộp TFL trên tập dữ liệu tổng hợp, nhưng lưu ý rằng mọi thứ trong hướng dẫn này cũng có thể được thực hiện với các mô hình được xây dựng từ các lớp TFL Keras.
Trước khi tiếp tục, hãy đảm bảo rằng thời gian chạy của bạn đã cài đặt tất cả các gói bắt buộc (như được nhập trong các ô mã bên dưới).
Thành lập
Cài đặt gói TF Lattice:
pip install -q tensorflow-lattice
Nhập các gói bắt buộc:
import tensorflow as tf
from IPython.core.pylabtools import figsize
import itertools
import logging
import matplotlib
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
import sys
import tensorflow_lattice as tfl
logging.disable(sys.maxsize)
Các giá trị mặc định được sử dụng trong hướng dẫn này:
NUM_EPOCHS = 1000
BATCH_SIZE = 64
LEARNING_RATE=0.01
Tập dữ liệu đào tạo để xếp hạng nhà hàng
Hãy tưởng tượng một tình huống đơn giản trong đó chúng ta muốn xác định xem liệu người dùng có nhấp vào kết quả tìm kiếm nhà hàng hay không. Nhiệm vụ là dự đoán tỷ lệ nhấp (CTR) cho các tính năng đầu vào:
- Xếp hạng trung bình (
avg_rating): một tính năng số với các giá trị trong khoảng [1,5]. - Số ý kiến (
num_reviews): một tính năng số với các giá trị giới hạn ở mức 200, mà chúng tôi sử dụng như một biện pháp của trendiness. - Giá Dollar (
dollar_rating): một tính năng phân loại với giá trị chuỗi trong tập { "D", "DD", "DDD", "dddd"}.
Ở đây, chúng tôi tạo một tập dữ liệu tổng hợp trong đó CTR thực sự được cung cấp bởi công thức:
\[ CTR = 1 / (1 + exp\{\mbox{b(dollar_rating)}-\mbox{avg_rating}\times log(\mbox{num_reviews}) /4 \}) \]
nơi \(b(\cdot)\) dịch mỗi dollar_rating đến một giá trị cơ bản:
\[ \mbox{D}\to 3,\ \mbox{DD}\to 2,\ \mbox{DDD}\to 4,\ \mbox{DDDD}\to 4.5. \]
Công thức này phản ánh các mẫu người dùng điển hình. Ví dụ: khi mọi thứ khác đã được khắc phục, người dùng thích nhà hàng có xếp hạng sao cao hơn và nhà hàng "\ $ \ $" sẽ nhận được nhiều nhấp chuột hơn "\ $", tiếp theo là "\ $ \ $ \ $" và "\ $ \ $ \ $ \ $ ".
def click_through_rate(avg_ratings, num_reviews, dollar_ratings):
dollar_rating_baseline = {"D": 3, "DD": 2, "DDD": 4, "DDDD": 4.5}
return 1 / (1 + np.exp(
np.array([dollar_rating_baseline[d] for d in dollar_ratings]) -
avg_ratings * np.log1p(num_reviews) / 4))
Chúng ta hãy xem các biểu đồ đường bao của hàm CTR này.
def color_bar():
bar = matplotlib.cm.ScalarMappable(
norm=matplotlib.colors.Normalize(0, 1, True),
cmap="viridis",
)
bar.set_array([0, 1])
return bar
def plot_fns(fns, split_by_dollar=False, res=25):
"""Generates contour plots for a list of (name, fn) functions."""
num_reviews, avg_ratings = np.meshgrid(
np.linspace(0, 200, num=res),
np.linspace(1, 5, num=res),
)
if split_by_dollar:
dollar_rating_splits = ["D", "DD", "DDD", "DDDD"]
else:
dollar_rating_splits = [None]
if len(fns) == 1:
fig, axes = plt.subplots(2, 2, sharey=True, tight_layout=False)
else:
fig, axes = plt.subplots(
len(dollar_rating_splits), len(fns), sharey=True, tight_layout=False)
axes = axes.flatten()
axes_index = 0
for dollar_rating_split in dollar_rating_splits:
for title, fn in fns:
if dollar_rating_split is not None:
dollar_ratings = np.repeat(dollar_rating_split, res**2)
values = fn(avg_ratings.flatten(), num_reviews.flatten(),
dollar_ratings)
title = "{}: dollar_rating={}".format(title, dollar_rating_split)
else:
values = fn(avg_ratings.flatten(), num_reviews.flatten())
subplot = axes[axes_index]
axes_index += 1
subplot.contourf(
avg_ratings,
num_reviews,
np.reshape(values, (res, res)),
vmin=0,
vmax=1)
subplot.title.set_text(title)
subplot.set(xlabel="Average Rating")
subplot.set(ylabel="Number of Reviews")
subplot.set(xlim=(1, 5))
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
figsize(11, 11)
plot_fns([("CTR", click_through_rate)], split_by_dollar=True)
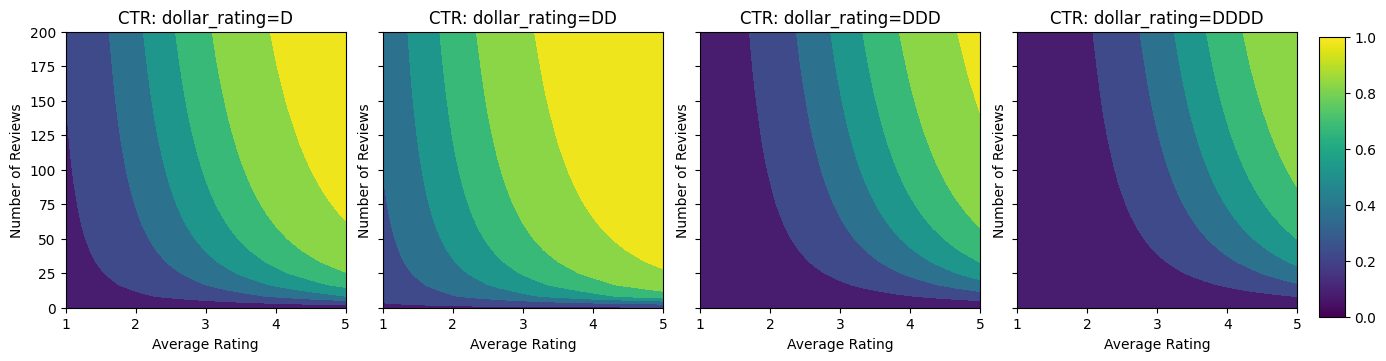
Chuẩn bị dữ liệu
Bây giờ chúng ta cần tạo bộ dữ liệu tổng hợp của mình. Chúng tôi bắt đầu bằng cách tạo một tập dữ liệu mô phỏng về các nhà hàng và các tính năng của chúng.
def sample_restaurants(n):
avg_ratings = np.random.uniform(1.0, 5.0, n)
num_reviews = np.round(np.exp(np.random.uniform(0.0, np.log(200), n)))
dollar_ratings = np.random.choice(["D", "DD", "DDD", "DDDD"], n)
ctr_labels = click_through_rate(avg_ratings, num_reviews, dollar_ratings)
return avg_ratings, num_reviews, dollar_ratings, ctr_labels
np.random.seed(42)
avg_ratings, num_reviews, dollar_ratings, ctr_labels = sample_restaurants(2000)
figsize(5, 5)
fig, axs = plt.subplots(1, 1, sharey=False, tight_layout=False)
for rating, marker in [("D", "o"), ("DD", "^"), ("DDD", "+"), ("DDDD", "x")]:
plt.scatter(
x=avg_ratings[np.where(dollar_ratings == rating)],
y=num_reviews[np.where(dollar_ratings == rating)],
c=ctr_labels[np.where(dollar_ratings == rating)],
vmin=0,
vmax=1,
marker=marker,
label=rating)
plt.xlabel("Average Rating")
plt.ylabel("Number of Reviews")
plt.legend()
plt.xlim((1, 5))
plt.title("Distribution of restaurants")
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
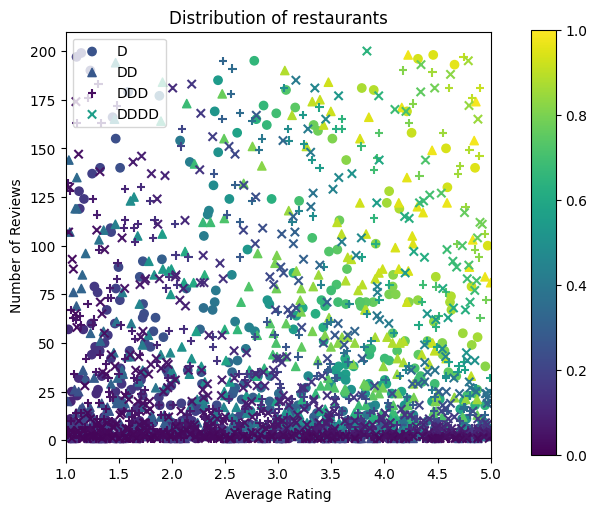
Hãy tạo tập dữ liệu đào tạo, xác nhận và thử nghiệm. Khi một nhà hàng được xem trong kết quả tìm kiếm, chúng tôi có thể ghi lại mức độ tương tác của người dùng (nhấp chuột hoặc không nhấp chuột) như một điểm mẫu.
Trong thực tế, người dùng thường không xem qua tất cả các kết quả tìm kiếm. Điều này có nghĩa là người dùng có thể sẽ chỉ nhìn thấy các nhà hàng đã được coi là "tốt" theo mô hình xếp hạng hiện tại đang được sử dụng. Kết quả là, các nhà hàng "tốt" thường bị ấn tượng và được thể hiện nhiều hơn trong bộ dữ liệu đào tạo. Khi sử dụng nhiều tính năng hơn, tập dữ liệu huấn luyện có thể có khoảng trống lớn trong các phần "xấu" của không gian tính năng.
Khi mô hình được sử dụng để xếp hạng, nó thường được đánh giá dựa trên tất cả các kết quả có liên quan với sự phân bổ đồng đều hơn mà không được đại diện tốt bởi tập dữ liệu đào tạo. Trong trường hợp này, một mô hình linh hoạt và phức tạp có thể không thành công do trang bị quá nhiều các điểm dữ liệu được đại diện quá mức và do đó thiếu tính tổng quát hóa. Chúng tôi xử lý vấn đề này bằng cách áp dụng kiến thức miền nhằm bổ sung những hạn chế hình dạng mà hướng dẫn các mô hình để đưa ra dự đoán hợp lý khi nó không thể chọn chúng từ tập dữ liệu huấn luyện.
Trong ví dụ này, tập dữ liệu đào tạo chủ yếu bao gồm các tương tác của người dùng với các nhà hàng tốt và nổi tiếng. Tập dữ liệu thử nghiệm có một phân phối đồng nhất để mô phỏng cài đặt đánh giá được thảo luận ở trên. Lưu ý rằng tập dữ liệu thử nghiệm như vậy sẽ không khả dụng trong cài đặt vấn đề thực sự.
def sample_dataset(n, testing_set):
(avg_ratings, num_reviews, dollar_ratings, ctr_labels) = sample_restaurants(n)
if testing_set:
# Testing has a more uniform distribution over all restaurants.
num_views = np.random.poisson(lam=3, size=n)
else:
# Training/validation datasets have more views on popular restaurants.
num_views = np.random.poisson(lam=ctr_labels * num_reviews / 50.0, size=n)
return pd.DataFrame({
"avg_rating": np.repeat(avg_ratings, num_views),
"num_reviews": np.repeat(num_reviews, num_views),
"dollar_rating": np.repeat(dollar_ratings, num_views),
"clicked": np.random.binomial(n=1, p=np.repeat(ctr_labels, num_views))
})
# Generate datasets.
np.random.seed(42)
data_train = sample_dataset(500, testing_set=False)
data_val = sample_dataset(500, testing_set=False)
data_test = sample_dataset(500, testing_set=True)
# Plotting dataset densities.
figsize(12, 5)
fig, axs = plt.subplots(1, 2, sharey=False, tight_layout=False)
for ax, data, title in [(axs[0], data_train, "training"),
(axs[1], data_test, "testing")]:
_, _, _, density = ax.hist2d(
x=data["avg_rating"],
y=data["num_reviews"],
bins=(np.linspace(1, 5, num=21), np.linspace(0, 200, num=21)),
density=True,
cmap="Blues",
)
ax.set(xlim=(1, 5))
ax.set(ylim=(0, 200))
ax.set(xlabel="Average Rating")
ax.set(ylabel="Number of Reviews")
ax.title.set_text("Density of {} examples".format(title))
_ = fig.colorbar(density, ax=ax)

Định nghĩa input_fns được sử dụng để đào tạo và đánh giá:
train_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
shuffle=False,
)
# feature_analysis_input_fn is used for TF Lattice estimators.
feature_analysis_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
val_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_val,
y=data_val["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
test_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_test,
y=data_test["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
Phù hợp với cây tăng cường Gradient
Hãy bắt đầu với chỉ có hai tính năng: avg_rating và num_reviews .
Chúng tôi tạo ra một số hàm hỗ trợ để vẽ và tính toán các chỉ số xác nhận và kiểm tra.
def analyze_two_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def two_d_pred(avg_ratings, num_reviews):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
def two_d_click_through_rate(avg_ratings, num_reviews):
return np.mean([
click_through_rate(avg_ratings, num_reviews,
np.repeat(d, len(avg_ratings)))
for d in ["D", "DD", "DDD", "DDDD"]
],
axis=0)
figsize(11, 5)
plot_fns([("{} Estimated CTR".format(name), two_d_pred),
("CTR", two_d_click_through_rate)],
split_by_dollar=False)
Chúng tôi có thể phù hợp với cây quyết định tăng cường độ dốc TensorFlow trên tập dữ liệu:
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
gbt_estimator = tf.estimator.BoostedTreesClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
n_batches_per_layer=1,
max_depth=2,
n_trees=50,
learning_rate=0.05,
config=tf.estimator.RunConfig(tf_random_seed=42),
)
gbt_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(gbt_estimator, "GBT")
Validation AUC: 0.6333084106445312 Testing AUC: 0.774649977684021

Mặc dù mô hình đã nắm bắt được hình dạng chung của CTR thực và có các chỉ số xác thực phù hợp, nhưng nó có hành vi phản trực giác ở một số phần của không gian đầu vào: CTR ước tính giảm khi xếp hạng trung bình hoặc số lượng đánh giá tăng lên. Điều này là do thiếu các điểm mẫu ở các khu vực chưa được bộ dữ liệu đào tạo bao quát. Mô hình chỉ đơn giản là không có cách nào để suy ra hành vi chính xác chỉ từ dữ liệu.
Để giải quyết vấn đề này, chúng tôi thực thi ràng buộc hình dạng rằng mô hình phải xuất các giá trị tăng đơn điệu liên quan đến cả xếp hạng trung bình và số lượng đánh giá. Sau đó chúng ta sẽ xem cách thực hiện điều này trong TFL.
Phù hợp với một DNN
Chúng ta có thể lặp lại các bước tương tự với bộ phân loại DNN. Chúng ta có thể quan sát một mô hình tương tự: không có đủ điểm mẫu với số lượng đánh giá nhỏ dẫn đến ngoại suy vô nghĩa. Lưu ý rằng mặc dù chỉ số xác thực tốt hơn giải pháp dạng cây, nhưng chỉ số thử nghiệm lại kém hơn nhiều.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
dnn_estimator = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
hidden_units=[16, 8, 8],
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
dnn_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(dnn_estimator, "DNN")
Validation AUC: 0.6696228981018066 Testing AUC: 0.750156044960022

Các ràng buộc về hình dạng
TensorFlow Lattice (TFL) tập trung vào việc thực thi các ràng buộc về hình dạng để bảo vệ hành vi của mô hình ngoài dữ liệu huấn luyện. Các ràng buộc hình dạng này được áp dụng cho các lớp TFL Keras. Chi tiết của họ có thể được tìm thấy trong giấy JMLR của chúng tôi .
Trong hướng dẫn này, chúng tôi sử dụng công cụ ước lượng đóng hộp TF để bao gồm các ràng buộc hình dạng khác nhau, nhưng lưu ý rằng tất cả các bước này có thể được thực hiện với các mô hình được tạo từ các lớp TFL Keras.
Như với bất kỳ ước lượng TensorFlow khác, TFL đóng hộp ước lượng sử dụng cột tính năng để xác định định dạng đầu vào và sử dụng một input_fn đào tạo để vượt qua trong dữ liệu. Sử dụng công cụ ước tính đóng hộp TFL cũng yêu cầu:
- một mô hình cấu hình: định kiến trúc mô hình và mỗi tính năng hạn chế hình dạng và regularizers.
- một phân tích tính năng input_fn: a TF input_fn thông qua dữ liệu cho TFL khởi tạo.
Để có mô tả kỹ lưỡng hơn, vui lòng tham khảo hướng dẫn công cụ ước tính đóng hộp hoặc tài liệu API.
Tính đơn điệu
Trước tiên, chúng tôi giải quyết các mối quan tâm về tính đơn điệu bằng cách thêm các ràng buộc về tính đơn điệu cho cả hai đối tượng địa lý.
Hướng dẫn TFL để thực thi hạn chế hình thành, chúng tôi xác định những hạn chế trong configs tính năng. Các chương trình mã sau thế nào chúng ta có thể yêu cầu đầu ra là đơn điệu tăng đối với cả hai với num_reviews và avg_rating bằng cách thiết lập monotonicity="increasing" .
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
Validation AUC: 0.6565533876419067 Testing AUC: 0.7784258723258972

Sử dụng một CalibratedLatticeConfig tạo ra một phân loại đóng hộp mà lần đầu tiên áp dụng một calibrator cho mỗi đầu vào (một hàm tuyến tính mảnh-khôn ngoan cho các tính năng số) tiếp theo là một lớp lưới để phi tuyến tính cầu chì các tính năng hiệu chỉnh. Chúng ta có thể sử dụng tfl.visualization để hình dung mô hình. Đặc biệt, biểu đồ sau đây cho thấy hai mẫu chuẩn được đào tạo có trong bộ phân loại đóng hộp.
def save_and_visualize_lattice(tfl_estimator):
saved_model_path = tfl_estimator.export_saved_model(
"/tmp/TensorFlow_Lattice_101/",
tf.estimator.export.build_parsing_serving_input_receiver_fn(
feature_spec=tf.feature_column.make_parse_example_spec(
feature_columns)))
model_graph = tfl.estimators.get_model_graph(saved_model_path)
figsize(8, 8)
tfl.visualization.draw_model_graph(model_graph)
return model_graph
_ = save_and_visualize_lattice(tfl_estimator)

Với các ràng buộc được thêm vào, CTR ước tính sẽ luôn tăng khi xếp hạng trung bình tăng hoặc số lượng đánh giá tăng. Điều này được thực hiện bằng cách đảm bảo rằng các đường chuẩn và mạng tinh thể là đơn ánh.
Lợi nhuận giảm dần
Giảm dần phương tiện mà tăng biên của tăng một giá trị tính năng nhất định sẽ giảm khi chúng ta tăng giá trị. Trong trường hợp của chúng tôi, chúng tôi hy vọng rằng các num_reviews tính năng sau mô hình này, vì vậy chúng tôi có thể cấu hình calibrator của nó cho phù hợp. Lưu ý rằng chúng ta có thể phân tích lợi tức giảm dần thành hai điều kiện đủ:
- bộ hiệu chuẩn đang tăng một cách đơn điệu, và
- bộ hiệu chuẩn bị lõm.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891247272491455

Lưu ý cách cải thiện chỉ số thử nghiệm bằng cách thêm giới hạn ngắn gọn. Cốt truyện dự đoán cũng giống với sự thật trên mặt đất hơn.
Ràng buộc hình dạng 2D: Tin cậy
Xếp hạng 5 sao đối với nhà hàng chỉ có một hoặc hai đánh giá có thể là xếp hạng không đáng tin cậy (nhà hàng có thể không thực sự tốt), trong khi xếp hạng 4 sao đối với nhà hàng có hàng trăm đánh giá thì đáng tin cậy hơn nhiều (nhà hàng đó có khả năng tốt trong trường hợp này). Chúng ta có thể thấy rằng số lượng đánh giá về một nhà hàng ảnh hưởng đến mức độ tin tưởng mà chúng ta đặt vào xếp hạng trung bình của nó.
Chúng ta có thể thực hiện các ràng buộc tin cậy TFL để thông báo cho mô hình rằng giá trị lớn hơn (hoặc nhỏ hơn) của một đối tượng địa lý cho thấy mức độ tin cậy hoặc độ tin cậy cao hơn đối với đối tượng địa lý khác. Này được thực hiện bằng cách thiết lập reflects_trust_in cấu hình trong tính năng config.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
# Larger num_reviews indicating more trust in avg_rating.
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
model_graph = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891043424606323
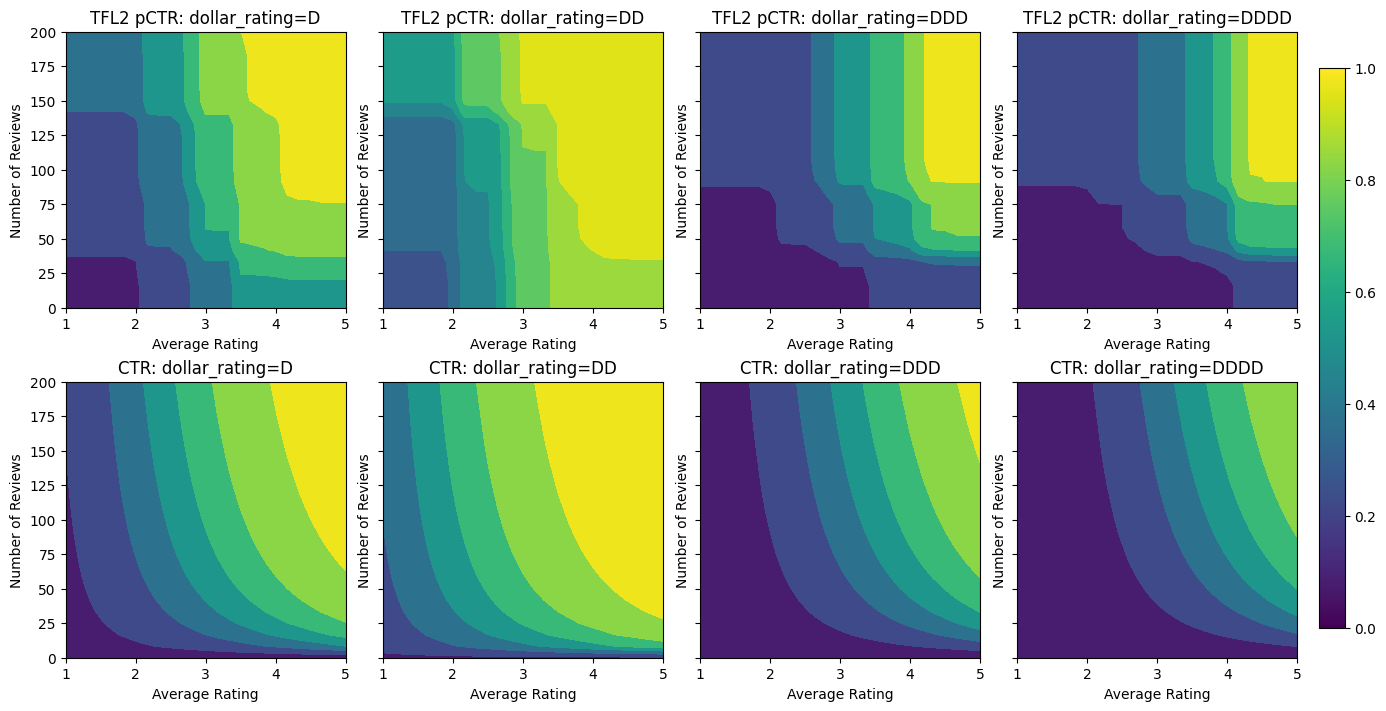

Biểu đồ sau đây trình bày hàm mạng tinh thể được đào tạo. Do sự hạn chế tin cậy, chúng tôi hy vọng rằng giá trị lớn hơn cỡ num_reviews sẽ buộc dốc cao hơn đối với hiệu chuẩn với avg_rating , kết quả là một động thái quan trọng hơn trong đầu ra mạng.
lat_mesh_n = 12
lat_mesh_x, lat_mesh_y = tfl.test_utils.two_dim_mesh_grid(
lat_mesh_n**2, 0, 0, 1, 1)
lat_mesh_fn = tfl.test_utils.get_hypercube_interpolation_fn(
model_graph.output_node.weights.flatten())
lat_mesh_z = [
lat_mesh_fn([lat_mesh_x.flatten()[i],
lat_mesh_y.flatten()[i]]) for i in range(lat_mesh_n**2)
]
trust_plt = tfl.visualization.plot_outputs(
(lat_mesh_x, lat_mesh_y),
{"Lattice Lookup": lat_mesh_z},
figsize=(6, 6),
)
trust_plt.title("Trust")
trust_plt.xlabel("Calibrated avg_rating")
trust_plt.ylabel("Calibrated num_reviews")
trust_plt.show()
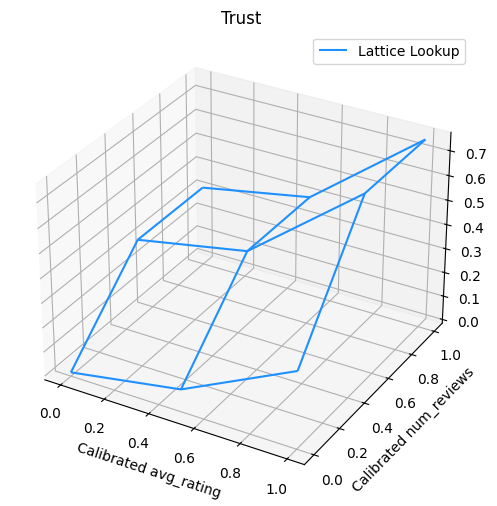
Làm mịn bộ hiệu chuẩn
Hãy để bây giờ có một cái nhìn tại calibrator của avg_rating . Mặc dù nó đang tăng một cách đơn điệu, nhưng những thay đổi về độ dốc của nó rất đột ngột và khó có thể giải thích được. Điều đó cho thấy chúng ta có thể muốn xem xét làm mịn calibrator này sử dụng một thiết lập regularizer trong regularizer_configs .
Ở đây chúng ta áp dụng một wrinkle regularizer để giảm sự thay đổi độ cong. Bạn cũng có thể sử dụng laplacian regularizer để san bằng calibrator và hessian regularizer để làm cho nó thẳng hơn.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6465646028518677 Testing AUC: 0.7948372960090637


Các thiết bị hiệu chuẩn hiện hoạt động trơn tru và CTR ước tính tổng thể phù hợp hơn với sự thật trên mặt đất. Điều này được phản ánh cả trong chỉ số thử nghiệm và trong các đồ thị đường viền.
Tính đơn điệu một phần để hiệu chuẩn phân loại
Cho đến nay, chúng tôi chỉ sử dụng hai trong số các tính năng số trong mô hình. Ở đây chúng tôi sẽ thêm một tính năng thứ ba bằng cách sử dụng một lớp hiệu chuẩn phân loại. Một lần nữa, chúng ta bắt đầu bằng cách thiết lập các hàm trợ giúp để vẽ biểu đồ và tính toán số liệu.
def analyze_three_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def three_d_pred(avg_ratings, num_reviews, dollar_rating):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
"dollar_rating": dollar_rating,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
figsize(11, 22)
plot_fns([("{} Estimated CTR".format(name), three_d_pred),
("CTR", click_through_rate)],
split_by_dollar=True)
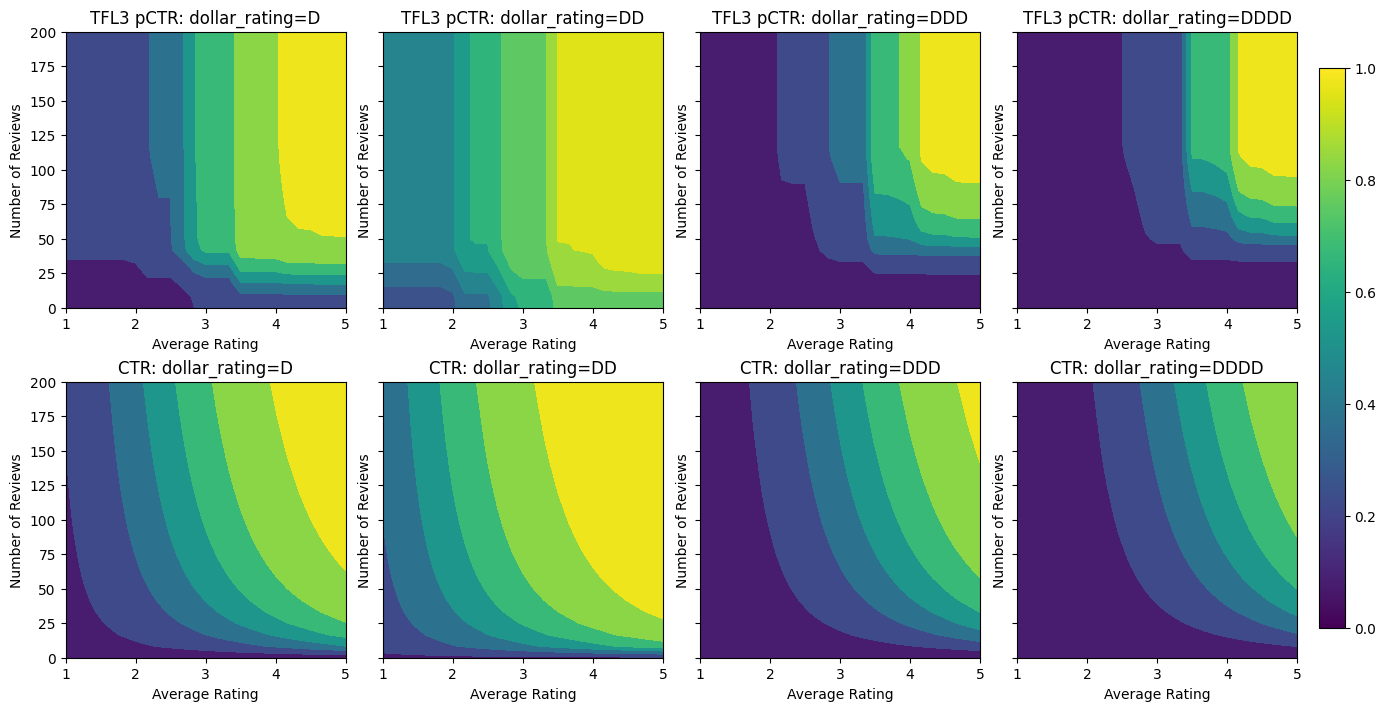
Để tham gia tính năng thứ ba, dollar_rating , chúng ta nên nhớ rằng các đặc tính phân loại yêu cầu xử lý hơi khác nhau trong TFL, cả hai như là một cột tính năng và cấu hình như một tính năng. Ở đây, chúng tôi thực thi ràng buộc tính đơn điệu từng phần rằng đầu ra cho nhà hàng "DD" phải lớn hơn nhà hàng "D" khi tất cả các đầu vào khác được cố định. Này được thực hiện bằng cách sử dụng monotonicity thiết lập trong tính năng config.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7699775695800781 Testing AUC: 0.8594040274620056


Bộ hiệu chuẩn phân loại này hiển thị ưu tiên của đầu ra mô hình: DD> D> DDD> DDDD, phù hợp với thiết lập của chúng tôi. Lưu ý rằng cũng có một cột cho các giá trị bị thiếu. Mặc dù không có tính năng nào bị thiếu trong dữ liệu đào tạo và thử nghiệm của chúng tôi, nhưng mô hình cung cấp cho chúng tôi giá trị bị thiếu nếu nó xảy ra trong quá trình phân phối mô hình hạ lưu.
Ở đây chúng ta cũng vẽ CTR dự đoán của mô hình này lạnh trên dollar_rating . Lưu ý rằng tất cả các ràng buộc mà chúng tôi yêu cầu đều được đáp ứng trong mỗi lát cắt.
Hiệu chuẩn đầu ra
Đối với tất cả các mô hình TFL mà chúng tôi đã đào tạo cho đến nay, lớp mạng tinh thể (được chỉ định là "Lưới" trong biểu đồ mô hình) trực tiếp đưa ra dự đoán mô hình. Đôi khi chúng tôi không chắc liệu đầu ra mạng có nên được thay đổi tỷ lệ để phát ra đầu ra mô hình hay không:
- các tính năng là \(log\) tội trong khi các nhãn được đếm.
- mạng tinh thể được cấu hình để có rất ít đỉnh nhưng sự phân bố nhãn tương đối phức tạp.
Trong những trường hợp đó, chúng ta có thể thêm một bộ hiệu chuẩn khác giữa đầu ra mạng tinh thể và đầu ra mô hình để tăng tính linh hoạt của mô hình. Ở đây, hãy thêm một lớp hiệu chuẩn với 5 điểm chính vào mô hình mà chúng ta vừa tạo. Chúng tôi cũng thêm một bộ điều chỉnh cho bộ hiệu chuẩn đầu ra để giữ cho chức năng hoạt động trơn tru.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
output_calibration=True,
output_calibration_num_keypoints=5,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="output_calib_wrinkle", l2=0.1),
],
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7697908878326416 Testing AUC: 0.861327052116394


Số liệu và biểu đồ thử nghiệm cuối cùng cho thấy cách sử dụng các ràng buộc thông thường có thể giúp mô hình tránh được hành vi không mong muốn và ngoại suy tốt hơn cho toàn bộ không gian đầu vào.