
Operatory uczenia maszynowego (ML) używane w modelu mogą mieć wpływ na proces konwertowania modelu TensorFlow do formatu TensorFlow Lite. Konwerter TensorFlow Lite obsługuje ograniczoną liczbę operacji TensorFlow używanych w typowych modelach wnioskowania, co oznacza, że nie każdy model można bezpośrednio konwertować. Narzędzie konwertujące umożliwia dołączenie dodatkowych operatorów, ale konwersja modelu w ten sposób wymaga również modyfikacji środowiska wykonawczego TensorFlow Lite, którego używasz do wykonania modelu, co może ograniczyć możliwość korzystania ze standardowych opcji wdrażania środowiska wykonawczego, takich jak usługi Google Play .
Konwerter TensorFlow Lite przeznaczony jest do analizy struktury modelu i stosowania optymalizacji w celu zapewnienia jego kompatybilności z bezpośrednio obsługiwanymi operatorami. Na przykład, w zależności od operatorów ML w Twoim modelu, konwerter może pominąć lub połączyć te operatory w celu zmapowania ich na ich odpowiedniki w TensorFlow Lite.
Nawet w przypadku obsługiwanych operacji czasami oczekuje się określonych wzorców użycia ze względu na wydajność. Najlepszym sposobem, aby zrozumieć, jak zbudować model TensorFlow, którego można używać z TensorFlow Lite, jest dokładne rozważenie sposobu konwersji i optymalizacji operacji, wraz z ograniczeniami narzuconymi przez ten proces.
Obsługiwani operatorzy
Wbudowane operatory TensorFlow Lite stanowią podzbiór operatorów będących częścią podstawowej biblioteki TensorFlow. Twój model TensorFlow może również zawierać niestandardowe operatory w postaci operatorów złożonych lub nowych operatorów zdefiniowanych przez Ciebie. Poniższy diagram przedstawia zależności pomiędzy tymi operatorami.
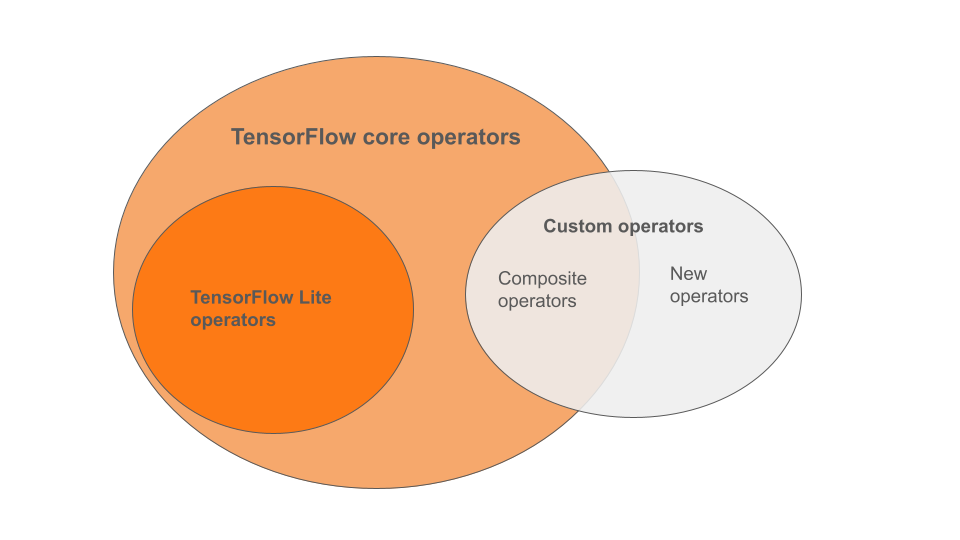
Z tej gamy operatorów modeli ML wyróżnia się 3 typy modeli obsługiwanych w procesie konwersji:
- Modele z wbudowanym operatorem TensorFlow Lite. ( Zalecana )
- Modele z wbudowanymi operatorami i wybranymi operatorami rdzeniowymi TensorFlow.
- Modele z wbudowanymi operatorami, operatorami podstawowymi TensorFlow i/lub operatorami niestandardowymi.
Jeśli Twój model zawiera tylko operacje, które są natywnie obsługiwane przez TensorFlow Lite, nie potrzebujesz żadnych dodatkowych flag, aby go przekonwertować. Jest to zalecana ścieżka, ponieważ ten typ modelu będzie konwertowany płynnie i jest łatwiejszy w optymalizacji i uruchomieniu przy użyciu domyślnego środowiska wykonawczego TensorFlow Lite. Masz także więcej opcji wdrażania dla swojego modelu, takich jak usługi Google Play . Możesz zacząć od przewodnika po konwerterze TensorFlow Lite . Zobacz stronę TensorFlow Lite Ops, aby uzyskać listę wbudowanych operatorów.
Jeśli chcesz uwzględnić wybrane operacje TensorFlow z biblioteki podstawowej, musisz to określić podczas konwersji i upewnić się, że środowisko wykonawcze uwzględnia te operacje. Aby uzyskać szczegółowe instrukcje, zobacz temat Wybieranie operatorów TensorFlow .
Jeśli to możliwe, unikaj ostatniej opcji włączania niestandardowych operatorów do przekonwertowanego modelu. Operatory niestandardowe to operatory utworzone przez połączenie wielu prymitywnych operatorów podstawowych TensorFlow lub zdefiniowanie zupełnie nowego. Kiedy operatory niestandardowe są konwertowane, mogą zwiększyć rozmiar całego modelu, pociągając za sobą zależności poza wbudowaną biblioteką TensorFlow Lite. Niestandardowe operacje, jeśli nie zostały stworzone specjalnie do wdrażania na urządzeniach mobilnych lub urządzeniach, mogą skutkować gorszą wydajnością po wdrożeniu na urządzeniach o ograniczonych zasobach w porównaniu ze środowiskiem serwerowym. Wreszcie, podobnie jak w przypadku wybranych operatorów podstawowych TensorFlow, operatory niestandardowe wymagają modyfikacji środowiska wykonawczego modelu , co ogranicza możliwość korzystania ze standardowych usług wykonawczych, takich jak usługi Google Play .
Obsługiwane typy
Większość operacji TensorFlow Lite jest ukierunkowana zarówno na wnioskowanie zmiennoprzecinkowe ( float32 ), jak i kwantowane ( uint8 , int8 ), ale wiele operacji nie obsługuje jeszcze innych typów, takich jak tf.float16 i strings.
Oprócz stosowania różnych wersji operacji, inną różnicą między modelami zmiennoprzecinkowymi i skwantowanymi jest sposób ich konwersji. Kwantowana konwersja wymaga informacji o zakresie dynamicznym dla tensorów. Wymaga to „fałszywej kwantyzacji” podczas uczenia modelu, uzyskiwania informacji o zasięgu za pośrednictwem zestawu danych kalibracyjnych lub wykonywania szacowania zasięgu „w locie”. Więcej szczegółów można znaleźć w artykule kwantyzacja .
Proste konwersje, ciągłe składanie i łączenie
Wiele operacji TensorFlow może być przetwarzanych przez TensorFlow Lite, nawet jeśli nie mają one bezpośredniego odpowiednika. Dzieje się tak w przypadku operacji, które można po prostu usunąć z grafu ( tf.identity ), zastąpić tensorami ( tf.placeholder ) lub połączyć w bardziej złożone operacje ( tf.nn.bias_add ). Nawet niektóre obsługiwane operacje mogą czasami zostać usunięte w ramach jednego z tych procesów.
Oto niewyczerpująca lista operacji TensorFlow, które zwykle są usuwane z wykresu:
-
tf.add -
tf.debugging.check_numerics -
tf.constant -
tf.div -
tf.divide -
tf.fake_quant_with_min_max_args -
tf.fake_quant_with_min_max_vars -
tf.identity -
tf.maximum -
tf.minimum -
tf.multiply -
tf.no_op -
tf.placeholder -
tf.placeholder_with_default -
tf.realdiv -
tf.reduce_max -
tf.reduce_min -
tf.reduce_sum -
tf.rsqrt -
tf.shape -
tf.sqrt -
tf.square -
tf.subtract -
tf.tile -
tf.nn.batch_norm_with_global_normalization -
tf.nn.bias_add -
tf.nn.fused_batch_norm -
tf.nn.relu -
tf.nn.relu6
Operacje eksperymentalne
Następujące operacje TensorFlow Lite są obecne, ale nie są gotowe dla modeli niestandardowych:
-
CALL -
CONCAT_EMBEDDINGS -
CUSTOM -
EMBEDDING_LOOKUP_SPARSE -
HASHTABLE_LOOKUP -
LSH_PROJECTION -
SKIP_GRAM -
SVDF