
| | |  צפה במקור ב-GitHub צפה במקור ב-GitHub | |
בדוגמה זו תחקור את התוצאה של McClean, 2019 שאומרת שלא סתם מבנה רשת עצבית קוונטית יצליח בכל הנוגע ללמידה. במיוחד תראה שמשפחה גדולה מסוימת של מעגלים קוונטיים אקראיים לא משמשת כרשתות עצביות קוונטיות טובות, כי יש להם שיפועים שנעלמים כמעט בכל מקום. בדוגמה זו לא תכשיר מודלים לבעיית למידה ספציפית, אלא תתמקד בבעיה הפשוטה יותר של הבנת התנהגויות של שיפועים.
להכין
pip install tensorflow==2.7.0
התקן את TensorFlow Quantum:
pip install tensorflow-quantum
# Update package resources to account for version changes.
import importlib, pkg_resources
importlib.reload(pkg_resources)
<module 'pkg_resources' from '/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py'>
כעת ייבא את TensorFlow ואת התלות של המודול:
import tensorflow as tf
import tensorflow_quantum as tfq
import cirq
import sympy
import numpy as np
# visualization tools
%matplotlib inline
import matplotlib.pyplot as plt
from cirq.contrib.svg import SVGCircuit
np.random.seed(1234)
2022-02-04 12:15:43.355568: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
1. סיכום
מעגלים קוונטיים אקראיים עם בלוקים רבים שנראים כך (\(R_{P}(\theta)\) הוא סיבוב פאולי אקראי):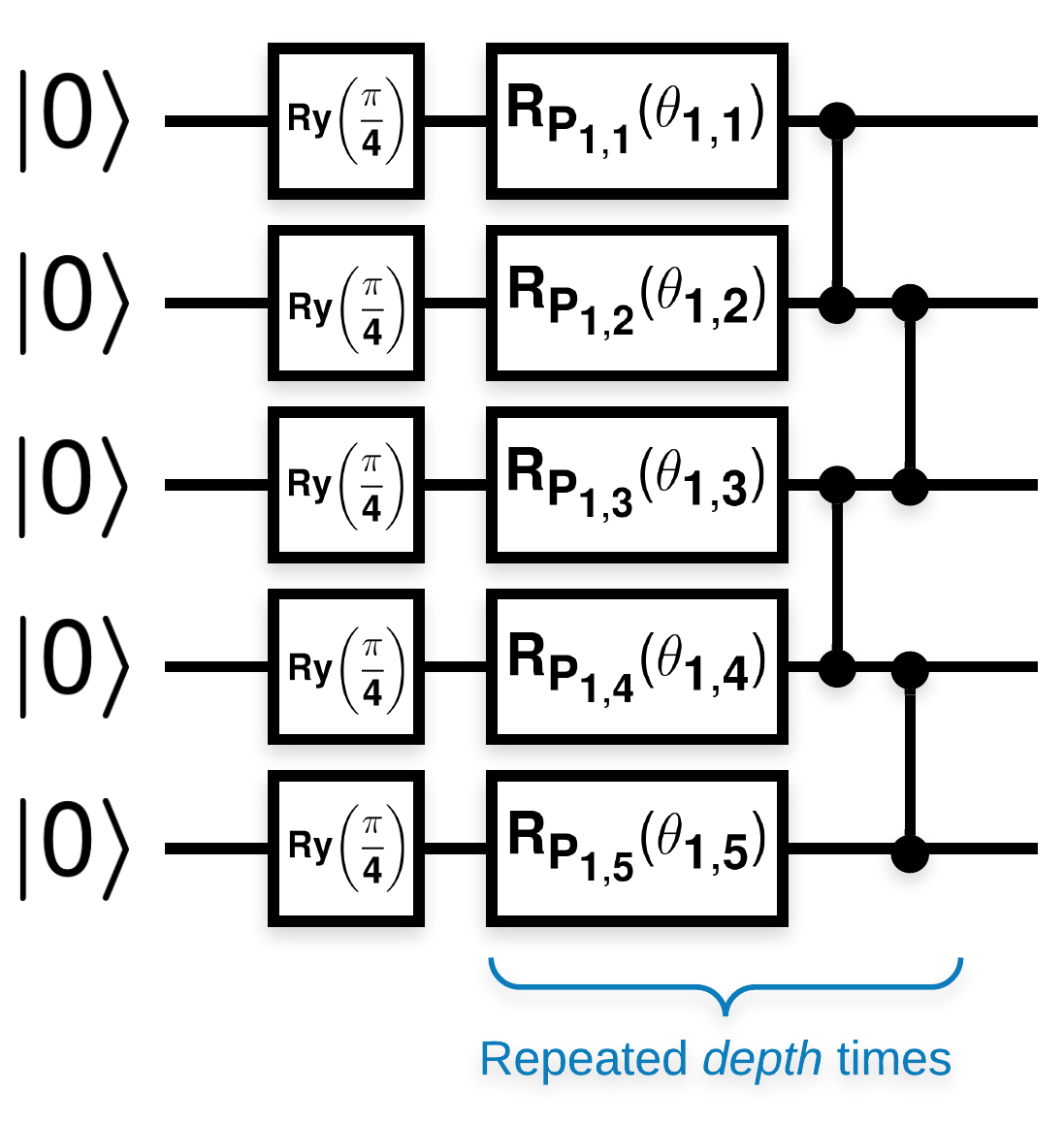
כאשר אם \(f(x)\) מוגדר כערך התוחלת wrt \(Z_{a}Z_{b}\) עבור כל qubits \(a\) ו- \(b\), אז יש בעיה \(f'(x)\) יש ממוצע קרוב מאוד ל-0 ואינו משתנה בהרבה. אתה תראה את זה למטה:
2. יצירת מעגלים אקראיים
הבנייה מהעיתון היא פשוטה לעקוב. הפעולות הבאות מיישמות פונקציה פשוטה המייצרת מעגל קוונטי אקראי - המכונה לפעמים רשת עצבית קוונטית (QNN) - עם העומק הנתון על קבוצה של קיוביטים:
def generate_random_qnn(qubits, symbol, depth):
"""Generate random QNN's with the same structure from McClean et al."""
circuit = cirq.Circuit()
for qubit in qubits:
circuit += cirq.ry(np.pi / 4.0)(qubit)
for d in range(depth):
# Add a series of single qubit rotations.
for i, qubit in enumerate(qubits):
random_n = np.random.uniform()
random_rot = np.random.uniform(
) * 2.0 * np.pi if i != 0 or d != 0 else symbol
if random_n > 2. / 3.:
# Add a Z.
circuit += cirq.rz(random_rot)(qubit)
elif random_n > 1. / 3.:
# Add a Y.
circuit += cirq.ry(random_rot)(qubit)
else:
# Add a X.
circuit += cirq.rx(random_rot)(qubit)
# Add CZ ladder.
for src, dest in zip(qubits, qubits[1:]):
circuit += cirq.CZ(src, dest)
return circuit
generate_random_qnn(cirq.GridQubit.rect(1, 3), sympy.Symbol('theta'), 2)
המחברים חוקרים את השיפוע של פרמטר יחיד \(\theta_{1,1}\). בואו נמשיך על ידי הצבת sympy.Symbol במעגל שבו יהיה \(\theta_{1,1}\) . מכיוון שהמחברים אינם מנתחים את הסטטיסטיקה עבור סמלים אחרים במעגל, הבה נחליף אותם בערכים אקראיים כעת במקום מאוחר יותר.
3. הפעלת המעגלים
צור כמה מהמעגלים הללו יחד עם בדיקה שניתן לראות כדי לבדוק את הטענה שהשיפועים אינם משתנים הרבה. ראשית, צור אצווה של מעגלים אקראיים. בחר ZZ אקראי הניתן לצפייה וחשב באצוות את ההדרגות והשונות באמצעות TensorFlow Quantum.
3.1 חישוב שונות אצווה
בוא נכתוב פונקציית מסייעת המחשבת את השונות של השיפוע של נתון שניתן לצפייה על פני אצווה של מעגלים:
def process_batch(circuits, symbol, op):
"""Compute the variance of a batch of expectations w.r.t. op on each circuit that
contains `symbol`. Note that this method sets up a new compute graph every time it is
called so it isn't as performant as possible."""
# Setup a simple layer to batch compute the expectation gradients.
expectation = tfq.layers.Expectation()
# Prep the inputs as tensors
circuit_tensor = tfq.convert_to_tensor(circuits)
values_tensor = tf.convert_to_tensor(
np.random.uniform(0, 2 * np.pi, (n_circuits, 1)).astype(np.float32))
# Use TensorFlow GradientTape to track gradients.
with tf.GradientTape() as g:
g.watch(values_tensor)
forward = expectation(circuit_tensor,
operators=op,
symbol_names=[symbol],
symbol_values=values_tensor)
# Return variance of gradients across all circuits.
grads = g.gradient(forward, values_tensor)
grad_var = tf.math.reduce_std(grads, axis=0)
return grad_var.numpy()[0]
3.1 הגדר והפעל
בחר את מספר המעגלים האקראיים ליצירת יחד עם העומק שלהם וכמות הקיוביטים שהם צריכים לפעול לפיהם. לאחר מכן תכננו את התוצאות.
n_qubits = [2 * i for i in range(2, 7)
] # Ranges studied in paper are between 2 and 24.
depth = 50 # Ranges studied in paper are between 50 and 500.
n_circuits = 200
theta_var = []
for n in n_qubits:
# Generate the random circuits and observable for the given n.
qubits = cirq.GridQubit.rect(1, n)
symbol = sympy.Symbol('theta')
circuits = [
generate_random_qnn(qubits, symbol, depth) for _ in range(n_circuits)
]
op = cirq.Z(qubits[0]) * cirq.Z(qubits[1])
theta_var.append(process_batch(circuits, symbol, op))
plt.semilogy(n_qubits, theta_var)
plt.title('Gradient Variance in QNNs')
plt.xlabel('n_qubits')
plt.xticks(n_qubits)
plt.ylabel('$\\partial \\theta$ variance')
plt.show()
WARNING:tensorflow:5 out of the last 5 calls to <function Adjoint.differentiate_analytic at 0x7f9e3b5c68c0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.
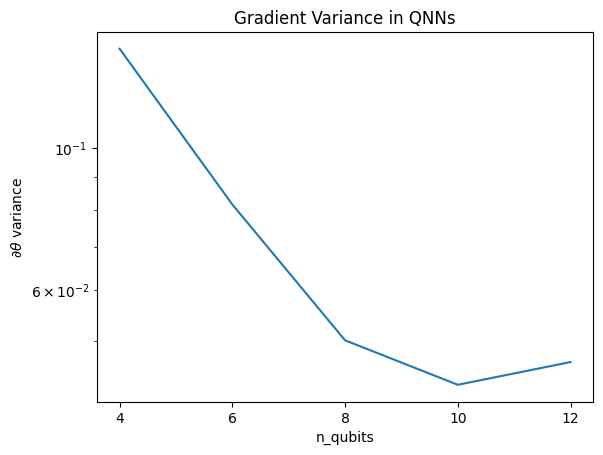
העלילה הזו מראה שלבעיות למידה של מכונות קוונטיות, אתה לא יכול פשוט לנחש תוספת QNN אקראית ולקוות לטוב. מבנה כלשהו חייב להיות קיים במעגל המודל על מנת שהשיפועים ישתנו עד לנקודה שבה למידה יכולה להתרחש.
4. היוריסטיקה
היוריסטיקה מעניינת של גרנט, 2019 מאפשרת להתחיל קרוב מאוד לאקראי, אבל לא לגמרי. באמצעות אותם מעגלים כמו McClean וחב', המחברים מציעים טכניקת אתחול שונה עבור פרמטרי הבקרה הקלאסיים כדי למנוע רמות עקרה. טכניקת האתחול מתחילה כמה שכבות עם פרמטרי בקרה אקראיים לחלוטין - אך בשכבות מיד לאחר מכן, בחר פרמטרים כך שהשינוי הראשוני שנעשה על ידי השכבות הראשונות יבוטל. המחברים קוראים לזה חסם זהות .
היתרון של היוריסטיקה הזו הוא שעל ידי שינוי של פרמטר בודד בלבד, כל שאר הבלוקים מחוץ לבלוק הנוכחי יישארו זהות - והאות הגרדיאנט מגיע חזק הרבה יותר מבעבר. זה מאפשר למשתמש לבחור ולבחור אילו משתנים ובלוקים לשנות כדי לקבל אות שיפוע חזק. היוריסטיקה זו אינה מונעת מהמשתמש ליפול לרמה עקרה במהלך שלב האימון (ומגביל עדכון בו-זמני לחלוטין), היא רק מבטיחה שתוכל להתחיל מחוץ לרמה.
4.1 בניית QNN חדשה
כעת בנה פונקציה ליצירת QNN של חסימת זהות. יישום זה שונה במקצת מזה מהעיתון. לעת עתה, הסתכלו על התנהגות הגרדיאנט של פרמטר בודד כך שתהיה עקבית עם McClean וחב', כך שניתן לעשות כמה הפשטות.
כדי ליצור בלוק זהות ולהכשיר את המודל, בדרך כלל אתה צריך \(U1(\theta_{1a}) U1(\theta_{1b})^{\dagger}\) ולא \(U1(\theta_1) U1(\theta_1)^{\dagger}\). בתחילה \(\theta_{1a}\) ו- \(\theta_{1b}\) הן אותן זוויות אבל הן נלמדות באופן עצמאי. אחרת, תמיד תקבל את הזהות גם לאחר האימון. הבחירה במספר בלוקי הזהות היא אמפירית. ככל שהגוש עמוק יותר, השונות באמצע הבלוק קטנה יותר. אבל בהתחלה ובסוף הבלוק, השונות של שיפוע הפרמטרים צריכה להיות גדולה.
def generate_identity_qnn(qubits, symbol, block_depth, total_depth):
"""Generate random QNN's with the same structure from Grant et al."""
circuit = cirq.Circuit()
# Generate initial block with symbol.
prep_and_U = generate_random_qnn(qubits, symbol, block_depth)
circuit += prep_and_U
# Generate dagger of initial block without symbol.
U_dagger = (prep_and_U[1:])**-1
circuit += cirq.resolve_parameters(
U_dagger, param_resolver={symbol: np.random.uniform() * 2 * np.pi})
for d in range(total_depth - 1):
# Get a random QNN.
prep_and_U_circuit = generate_random_qnn(
qubits,
np.random.uniform() * 2 * np.pi, block_depth)
# Remove the state-prep component
U_circuit = prep_and_U_circuit[1:]
# Add U
circuit += U_circuit
# Add U^dagger
circuit += U_circuit**-1
return circuit
generate_identity_qnn(cirq.GridQubit.rect(1, 3), sympy.Symbol('theta'), 2, 2)
4.2 השוואה
כאן אתה יכול לראות שהיוריסטיקה אכן עוזרת למנוע מהשונות של הגרדיאנט להיעלם באותה מהירות:
block_depth = 10
total_depth = 5
heuristic_theta_var = []
for n in n_qubits:
# Generate the identity block circuits and observable for the given n.
qubits = cirq.GridQubit.rect(1, n)
symbol = sympy.Symbol('theta')
circuits = [
generate_identity_qnn(qubits, symbol, block_depth, total_depth)
for _ in range(n_circuits)
]
op = cirq.Z(qubits[0]) * cirq.Z(qubits[1])
heuristic_theta_var.append(process_batch(circuits, symbol, op))
plt.semilogy(n_qubits, theta_var)
plt.semilogy(n_qubits, heuristic_theta_var)
plt.title('Heuristic vs. Random')
plt.xlabel('n_qubits')
plt.xticks(n_qubits)
plt.ylabel('$\\partial \\theta$ variance')
plt.show()
WARNING:tensorflow:6 out of the last 6 calls to <function Adjoint.differentiate_analytic at 0x7f9e3b5c68c0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.
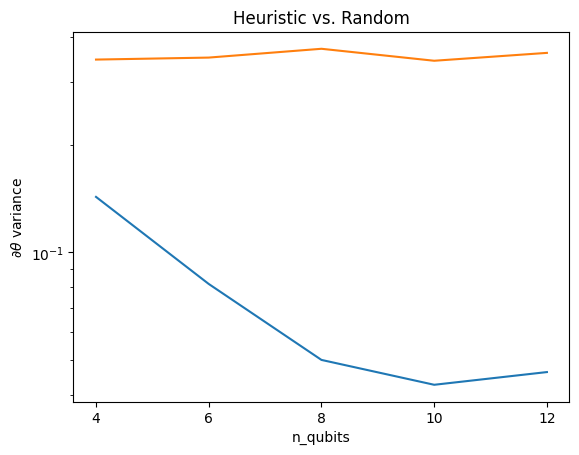
זהו שיפור גדול בהשגת אותות שיפוע חזקים יותר מ-QNN אקראיים (קרוב).