
| | |  GitHub पर स्रोत देखें GitHub पर स्रोत देखें | |
इस उदाहरण में आप McClean, 2019 के परिणाम का पता लगाएंगे, जो कहता है कि जब सीखने की बात आती है तो कोई भी क्वांटम न्यूरल नेटवर्क संरचना अच्छा नहीं करेगी। विशेष रूप से आप देखेंगे कि यादृच्छिक क्वांटम सर्किट का एक निश्चित बड़ा परिवार अच्छे क्वांटम न्यूरल नेटवर्क के रूप में काम नहीं करता है, क्योंकि उनके पास ग्रेडिएंट हैं जो लगभग हर जगह गायब हो जाते हैं। इस उदाहरण में आप किसी विशिष्ट सीखने की समस्या के लिए किसी भी मॉडल को प्रशिक्षित नहीं करेंगे, बल्कि ग्रेडिएंट के व्यवहार को समझने की सरल समस्या पर ध्यान केंद्रित करेंगे।
सेट अप
pip install tensorflow==2.7.0
TensorFlow क्वांटम स्थापित करें:
pip install tensorflow-quantum
# Update package resources to account for version changes.
import importlib, pkg_resources
importlib.reload(pkg_resources)
<module 'pkg_resources' from '/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py'>
अब TensorFlow और मॉड्यूल निर्भरताएँ आयात करें:
import tensorflow as tf
import tensorflow_quantum as tfq
import cirq
import sympy
import numpy as np
# visualization tools
%matplotlib inline
import matplotlib.pyplot as plt
from cirq.contrib.svg import SVGCircuit
np.random.seed(1234)
2022-02-04 12:15:43.355568: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
1. सारांश
इस तरह दिखने वाले कई ब्लॉक वाले यादृच्छिक क्वांटम सर्किट (\(R_{P}(\theta)\) एक यादृच्छिक पाउली रोटेशन है):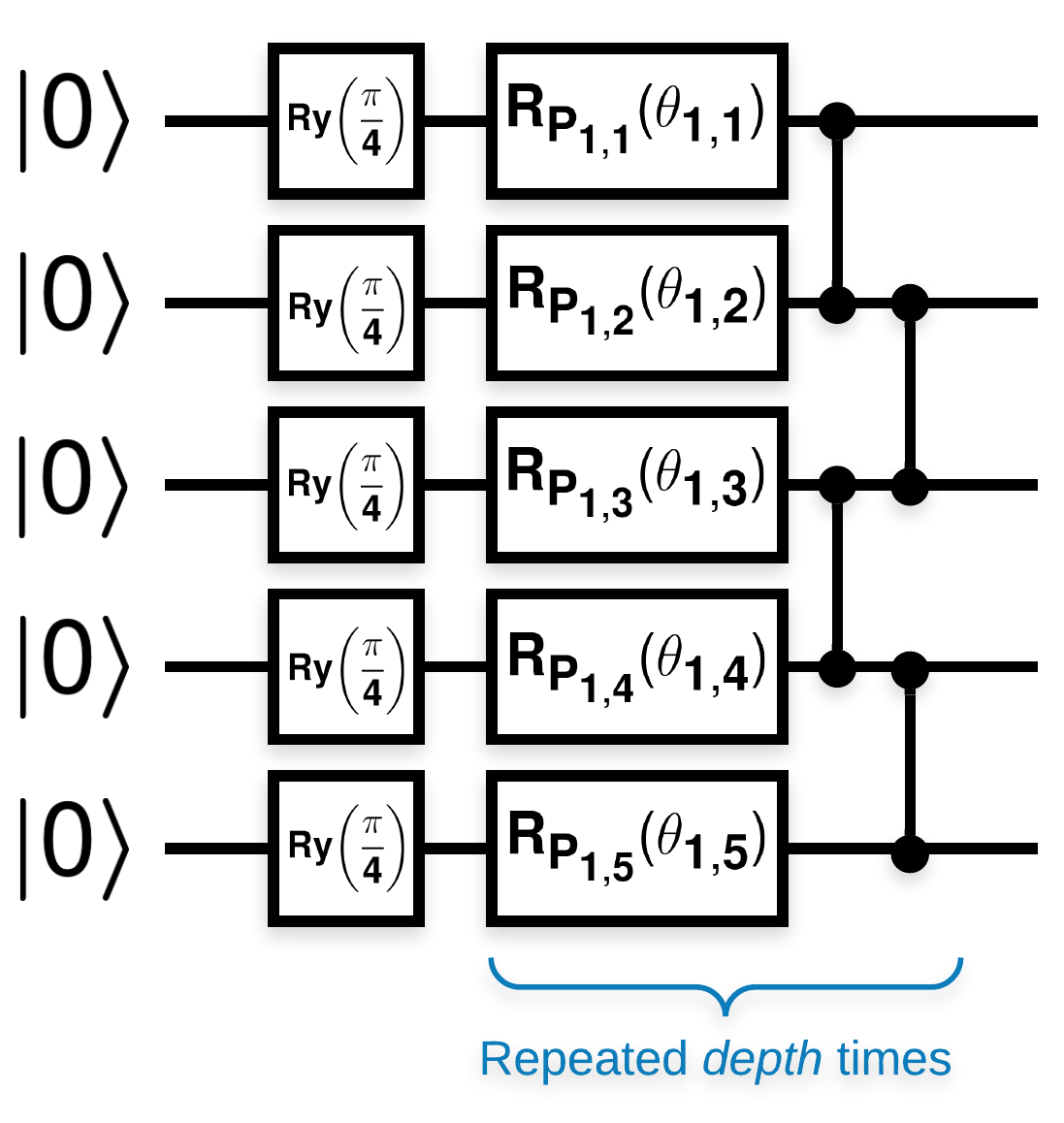
जहां \(f(x)\) -placeholder2 को किसी भी qubit \(a\) और \(b\)placeholder5 के लिए wrt \(Z_{a}Z_{b}\) के रूप में परिभाषित किया गया है, तो एक समस्या है कि \(f'(x)\) का माध्य 0 के बहुत करीब है और यह बहुत भिन्न नहीं है। आप इसे नीचे देखेंगे:
2. यादृच्छिक सर्किट उत्पन्न करना
कागज से निर्माण का पालन करना सीधा है। निम्नलिखित एक साधारण फ़ंक्शन को लागू करता है जो एक यादृच्छिक क्वांटम सर्किट उत्पन्न करता है - जिसे कभी-कभी क्वांटम न्यूरल नेटवर्क (क्यूएनएन) के रूप में संदर्भित किया जाता है - क्वैबिट के एक सेट पर दी गई गहराई के साथ:
def generate_random_qnn(qubits, symbol, depth):
"""Generate random QNN's with the same structure from McClean et al."""
circuit = cirq.Circuit()
for qubit in qubits:
circuit += cirq.ry(np.pi / 4.0)(qubit)
for d in range(depth):
# Add a series of single qubit rotations.
for i, qubit in enumerate(qubits):
random_n = np.random.uniform()
random_rot = np.random.uniform(
) * 2.0 * np.pi if i != 0 or d != 0 else symbol
if random_n > 2. / 3.:
# Add a Z.
circuit += cirq.rz(random_rot)(qubit)
elif random_n > 1. / 3.:
# Add a Y.
circuit += cirq.ry(random_rot)(qubit)
else:
# Add a X.
circuit += cirq.rx(random_rot)(qubit)
# Add CZ ladder.
for src, dest in zip(qubits, qubits[1:]):
circuit += cirq.CZ(src, dest)
return circuit
generate_random_qnn(cirq.GridQubit.rect(1, 3), sympy.Symbol('theta'), 2)
लेखक एकल पैरामीटर \(\theta_{1,1}\)के ग्रेडिएंट की जांच करते हैं। परिपथ में एक sympy.Symbol रखकर आगे बढ़ते हैं जहां \(\theta_{1,1}\) होगा। चूंकि लेखक सर्किट में किसी भी अन्य प्रतीकों के आंकड़ों का विश्लेषण नहीं करते हैं, इसलिए उन्हें बाद में के बजाय अब यादृच्छिक मानों से बदल दें।
3. सर्किट चलाना
इस दावे का परीक्षण करने के लिए एक अवलोकन के साथ इनमें से कुछ सर्किट उत्पन्न करें कि ग्रेडियेंट ज्यादा भिन्न नहीं होते हैं। सबसे पहले, यादृच्छिक सर्किट का एक बैच उत्पन्न करें। एक यादृच्छिक ZZ देखने योग्य चुनें और टेंसरफ्लो क्वांटम का उपयोग करके ग्रेडिएंट और विचरण की गणना करें।
3.1 बैच प्रसरण संगणना
आइए एक सहायक फ़ंक्शन लिखें जो सर्किट के एक बैच पर किसी दिए गए अवलोकन के ग्रेडिएंट के विचरण की गणना करता है:
def process_batch(circuits, symbol, op):
"""Compute the variance of a batch of expectations w.r.t. op on each circuit that
contains `symbol`. Note that this method sets up a new compute graph every time it is
called so it isn't as performant as possible."""
# Setup a simple layer to batch compute the expectation gradients.
expectation = tfq.layers.Expectation()
# Prep the inputs as tensors
circuit_tensor = tfq.convert_to_tensor(circuits)
values_tensor = tf.convert_to_tensor(
np.random.uniform(0, 2 * np.pi, (n_circuits, 1)).astype(np.float32))
# Use TensorFlow GradientTape to track gradients.
with tf.GradientTape() as g:
g.watch(values_tensor)
forward = expectation(circuit_tensor,
operators=op,
symbol_names=[symbol],
symbol_values=values_tensor)
# Return variance of gradients across all circuits.
grads = g.gradient(forward, values_tensor)
grad_var = tf.math.reduce_std(grads, axis=0)
return grad_var.numpy()[0]
3.1 सेट अप और रन
उनकी गहराई के साथ उत्पन्न करने के लिए यादृच्छिक सर्किटों की संख्या चुनें और उन्हें कितनी मात्रा में कार्य करना चाहिए। फिर परिणामों की साजिश करें।
n_qubits = [2 * i for i in range(2, 7)
] # Ranges studied in paper are between 2 and 24.
depth = 50 # Ranges studied in paper are between 50 and 500.
n_circuits = 200
theta_var = []
for n in n_qubits:
# Generate the random circuits and observable for the given n.
qubits = cirq.GridQubit.rect(1, n)
symbol = sympy.Symbol('theta')
circuits = [
generate_random_qnn(qubits, symbol, depth) for _ in range(n_circuits)
]
op = cirq.Z(qubits[0]) * cirq.Z(qubits[1])
theta_var.append(process_batch(circuits, symbol, op))
plt.semilogy(n_qubits, theta_var)
plt.title('Gradient Variance in QNNs')
plt.xlabel('n_qubits')
plt.xticks(n_qubits)
plt.ylabel('$\\partial \\theta$ variance')
plt.show()
WARNING:tensorflow:5 out of the last 5 calls to <function Adjoint.differentiate_analytic at 0x7f9e3b5c68c0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.प्लेसहोल्डर22
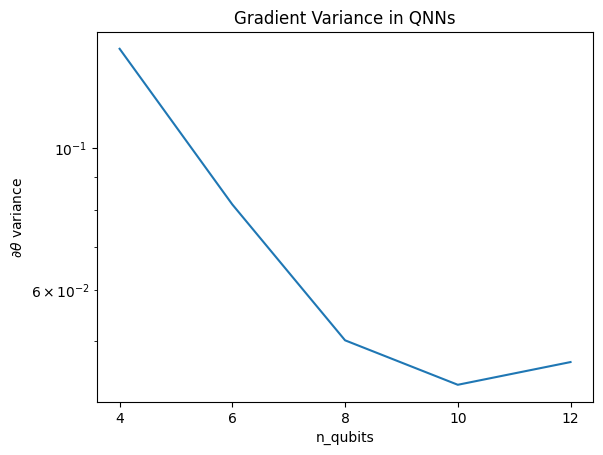
यह प्लॉट दिखाता है कि क्वांटम मशीन सीखने की समस्याओं के लिए, आप केवल एक यादृच्छिक QNN ansatz का अनुमान नहीं लगा सकते हैं और सर्वश्रेष्ठ की आशा कर सकते हैं। मॉडल सर्किट में कुछ संरचना मौजूद होनी चाहिए ताकि ग्रेडिएंट उस बिंदु तक भिन्न हो सकें जहां सीखना हो सकता है।
4. अनुमानी
ग्रांट, 2019 द्वारा एक दिलचस्प अनुमानी व्यक्ति को यादृच्छिक के बहुत करीब से शुरू करने की अनुमति देता है, लेकिन काफी नहीं। मैकक्लीन एट अल के समान सर्किट का उपयोग करते हुए, लेखक बंजर पठारों से बचने के लिए शास्त्रीय नियंत्रण मापदंडों के लिए एक अलग आरंभीकरण तकनीक का प्रस्ताव करते हैं। इनिशियलाइज़ेशन तकनीक कुछ परतों को पूरी तरह से यादृच्छिक नियंत्रण मापदंडों के साथ शुरू करती है - लेकिन, तुरंत बाद की परतों में, ऐसे पैरामीटर चुनें जैसे कि पहली कुछ परतों द्वारा किया गया प्रारंभिक परिवर्तन पूर्ववत हो। लेखक इसे एक पहचान ब्लॉक कहते हैं।
इस अनुमानी का लाभ यह है कि केवल एक पैरामीटर को बदलने से, वर्तमान ब्लॉक के बाहर के अन्य सभी ब्लॉक पहचान बने रहेंगे- और ग्रेडिएंट सिग्नल पहले की तुलना में बहुत मजबूत होता है। यह उपयोगकर्ता को एक मजबूत ढाल संकेत प्राप्त करने के लिए संशोधित करने के लिए कौन से चर और ब्लॉक चुनने और चुनने की अनुमति देता है। यह अनुमानी उपयोगकर्ता को प्रशिक्षण चरण के दौरान एक बंजर पठार में गिरने से नहीं रोकता है (और पूरी तरह से एक साथ अद्यतन को प्रतिबंधित करता है), यह केवल गारंटी देता है कि आप पठार के बाहर शुरू कर सकते हैं।
4.1 नया क्यूएनएन निर्माण
अब पहचान ब्लॉक QNN उत्पन्न करने के लिए एक फ़ंक्शन का निर्माण करें। यह कार्यान्वयन कागज से थोड़ा अलग है। अभी के लिए, किसी एकल पैरामीटर के ग्रेडिएंट के व्यवहार को देखें ताकि यह McClean et al के अनुरूप हो, इसलिए कुछ सरलीकरण किए जा सकते हैं।
पहचान ब्लॉक उत्पन्न करने और मॉडल को प्रशिक्षित करने के लिए, आमतौर पर आपको \(U1(\theta_{1a}) U1(\theta_{1b})^{\dagger}\) की आवश्यकता होती है न कि \(U1(\theta_1) U1(\theta_1)^{\dagger}\)। प्रारंभ में \(\theta_{1a}\) और \(\theta_{1b}\) एक ही कोण हैं लेकिन उन्हें स्वतंत्र रूप से सीखा जाता है। नहीं तो ट्रेनिंग के बाद भी आपको हमेशा पहचान मिलेगी। पहचान ब्लॉकों की संख्या का चुनाव अनुभवजन्य है। ब्लॉक जितना गहरा होगा, ब्लॉक के बीच में विचरण उतना ही छोटा होगा। लेकिन ब्लॉक की शुरुआत और अंत में, पैरामीटर ग्रेडिएंट्स का विचरण बड़ा होना चाहिए।
def generate_identity_qnn(qubits, symbol, block_depth, total_depth):
"""Generate random QNN's with the same structure from Grant et al."""
circuit = cirq.Circuit()
# Generate initial block with symbol.
prep_and_U = generate_random_qnn(qubits, symbol, block_depth)
circuit += prep_and_U
# Generate dagger of initial block without symbol.
U_dagger = (prep_and_U[1:])**-1
circuit += cirq.resolve_parameters(
U_dagger, param_resolver={symbol: np.random.uniform() * 2 * np.pi})
for d in range(total_depth - 1):
# Get a random QNN.
prep_and_U_circuit = generate_random_qnn(
qubits,
np.random.uniform() * 2 * np.pi, block_depth)
# Remove the state-prep component
U_circuit = prep_and_U_circuit[1:]
# Add U
circuit += U_circuit
# Add U^dagger
circuit += U_circuit**-1
return circuit
generate_identity_qnn(cirq.GridQubit.rect(1, 3), sympy.Symbol('theta'), 2, 2)
4.2 तुलना
यहां आप देख सकते हैं कि अनुमानी ढाल के विचरण को जल्दी से जल्दी गायब होने से बचाने में मदद करता है:
block_depth = 10
total_depth = 5
heuristic_theta_var = []
for n in n_qubits:
# Generate the identity block circuits and observable for the given n.
qubits = cirq.GridQubit.rect(1, n)
symbol = sympy.Symbol('theta')
circuits = [
generate_identity_qnn(qubits, symbol, block_depth, total_depth)
for _ in range(n_circuits)
]
op = cirq.Z(qubits[0]) * cirq.Z(qubits[1])
heuristic_theta_var.append(process_batch(circuits, symbol, op))
plt.semilogy(n_qubits, theta_var)
plt.semilogy(n_qubits, heuristic_theta_var)
plt.title('Heuristic vs. Random')
plt.xlabel('n_qubits')
plt.xticks(n_qubits)
plt.ylabel('$\\partial \\theta$ variance')
plt.show()
WARNING:tensorflow:6 out of the last 6 calls to <function Adjoint.differentiate_analytic at 0x7f9e3b5c68c0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.
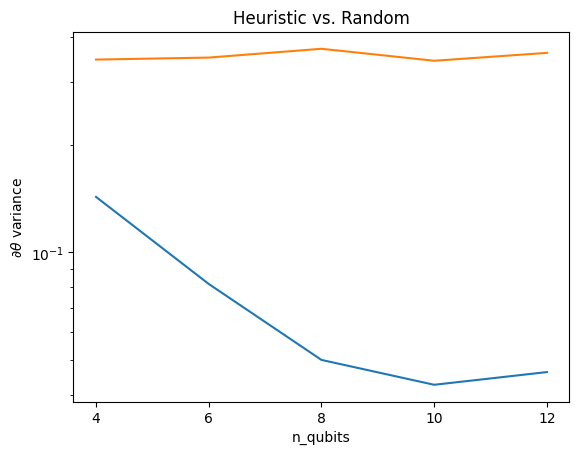
यादृच्छिक क्यूएनएन से (निकट) से मजबूत ढाल संकेत प्राप्त करने में यह एक बड़ा सुधार है।