
| | |  GitHub에서 소스 보기 GitHub에서 소스 보기 | |
이 예에서는 학습과 관련하여 어떤 양자 신경망 구조도 잘 작동하지 않는다는 McClean, 2019 의 결과를 살펴봅니다. 특히 임의의 양자 회로의 특정 대군은 거의 모든 곳에서 사라지는 기울기를 가지고 있기 때문에 좋은 양자 신경망 역할을 하지 않는다는 것을 알게 될 것입니다. 이 예제에서는 특정 학습 문제에 대한 모델을 훈련하지 않고 대신 그라디언트의 동작을 이해하는 더 간단한 문제에 초점을 맞춥니다.
설정
pip install tensorflow==2.7.0
TensorFlow Quantum 설치:
pip install tensorflow-quantum
# Update package resources to account for version changes.
import importlib, pkg_resources
importlib.reload(pkg_resources)
<module 'pkg_resources' from '/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py'>
이제 TensorFlow 및 모듈 종속성을 가져옵니다.
import tensorflow as tf
import tensorflow_quantum as tfq
import cirq
import sympy
import numpy as np
# visualization tools
%matplotlib inline
import matplotlib.pyplot as plt
from cirq.contrib.svg import SVGCircuit
np.random.seed(1234)
2022-02-04 12:15:43.355568: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
1. 요약
다음과 같은 블록이 많은 무작위 양자 회로(\(R_{P}(\theta)\) 은 임의의 Pauli 회전임):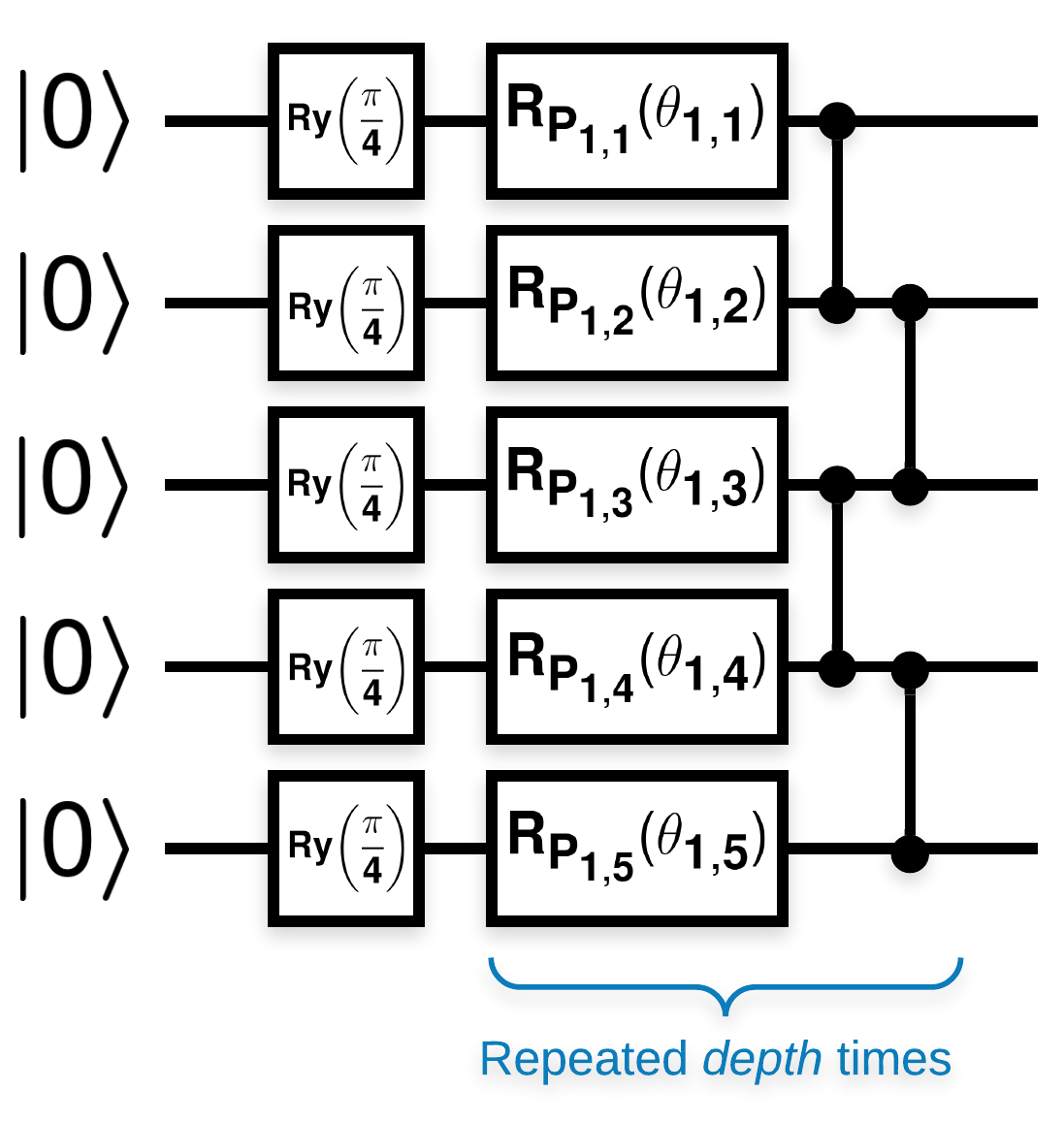
\(f(x)\) 가 임의의 큐비트 \(a\) 및 \(b\)placeholder5에 대한 기대값 wrt \(Z_{a}Z_{b}\) 로 정의되는 경우 l10n- \(f'(x)\) 의 평균이 0에 매우 가깝고 크게 변하지 않는다는 문제가 있습니다. 아래에서 볼 수 있습니다.
2. 랜덤 회로 생성
종이의 구성은 따라하기 쉽습니다. 다음은 큐비트 세트에서 주어진 깊이로 임의 양자 회로(때로는 양자 신경망 (QNN)라고도 함)를 생성하는 간단한 기능을 구현합니다.
def generate_random_qnn(qubits, symbol, depth):
"""Generate random QNN's with the same structure from McClean et al."""
circuit = cirq.Circuit()
for qubit in qubits:
circuit += cirq.ry(np.pi / 4.0)(qubit)
for d in range(depth):
# Add a series of single qubit rotations.
for i, qubit in enumerate(qubits):
random_n = np.random.uniform()
random_rot = np.random.uniform(
) * 2.0 * np.pi if i != 0 or d != 0 else symbol
if random_n > 2. / 3.:
# Add a Z.
circuit += cirq.rz(random_rot)(qubit)
elif random_n > 1. / 3.:
# Add a Y.
circuit += cirq.ry(random_rot)(qubit)
else:
# Add a X.
circuit += cirq.rx(random_rot)(qubit)
# Add CZ ladder.
for src, dest in zip(qubits, qubits[1:]):
circuit += cirq.CZ(src, dest)
return circuit
generate_random_qnn(cirq.GridQubit.rect(1, 3), sympy.Symbol('theta'), 2)
저자는 단일 매개변수 \(\theta_{1,1}\)의 기울기를 조사합니다. \(\theta_{1,1}\) 이 있는 회로에 sympy.Symbol 을 배치하여 따라가 보겠습니다. 작성자는 회로의 다른 기호에 대한 통계를 분석하지 않으므로 나중에 대신 무작위 값으로 바꾸겠습니다.
3. 회로 실행
기울기가 많이 변하지 않는다는 주장을 테스트하기 위해 관찰 가능한 것과 함께 이러한 회로 중 몇 개를 생성합니다. 먼저 무작위 회로의 배치를 생성합니다. 임의의 ZZ 관찰 가능 항목을 선택하고 TensorFlow Quantum을 사용하여 기울기와 분산을 일괄 계산합니다.
3.1 배치 분산 계산
회로 배치에 대해 주어진 관찰 가능 항목의 그라디언트 분산을 계산하는 도우미 함수를 작성해 보겠습니다.
def process_batch(circuits, symbol, op):
"""Compute the variance of a batch of expectations w.r.t. op on each circuit that
contains `symbol`. Note that this method sets up a new compute graph every time it is
called so it isn't as performant as possible."""
# Setup a simple layer to batch compute the expectation gradients.
expectation = tfq.layers.Expectation()
# Prep the inputs as tensors
circuit_tensor = tfq.convert_to_tensor(circuits)
values_tensor = tf.convert_to_tensor(
np.random.uniform(0, 2 * np.pi, (n_circuits, 1)).astype(np.float32))
# Use TensorFlow GradientTape to track gradients.
with tf.GradientTape() as g:
g.watch(values_tensor)
forward = expectation(circuit_tensor,
operators=op,
symbol_names=[symbol],
symbol_values=values_tensor)
# Return variance of gradients across all circuits.
grads = g.gradient(forward, values_tensor)
grad_var = tf.math.reduce_std(grads, axis=0)
return grad_var.numpy()[0]
3.1 설정 및 실행
생성할 무작위 회로의 수와 작동해야 하는 큐비트의 수를 선택합니다. 그런 다음 결과를 플로팅합니다.
n_qubits = [2 * i for i in range(2, 7)
] # Ranges studied in paper are between 2 and 24.
depth = 50 # Ranges studied in paper are between 50 and 500.
n_circuits = 200
theta_var = []
for n in n_qubits:
# Generate the random circuits and observable for the given n.
qubits = cirq.GridQubit.rect(1, n)
symbol = sympy.Symbol('theta')
circuits = [
generate_random_qnn(qubits, symbol, depth) for _ in range(n_circuits)
]
op = cirq.Z(qubits[0]) * cirq.Z(qubits[1])
theta_var.append(process_batch(circuits, symbol, op))
plt.semilogy(n_qubits, theta_var)
plt.title('Gradient Variance in QNNs')
plt.xlabel('n_qubits')
plt.xticks(n_qubits)
plt.ylabel('$\\partial \\theta$ variance')
plt.show()
WARNING:tensorflow:5 out of the last 5 calls to <function Adjoint.differentiate_analytic at 0x7f9e3b5c68c0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.
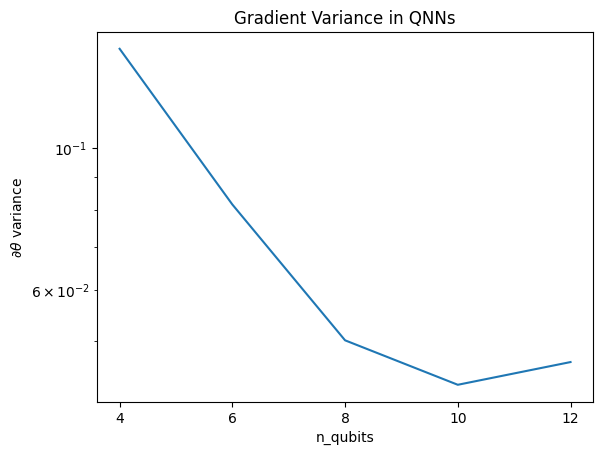
이 플롯은 양자 기계 학습 문제의 경우 무작위 QNN 새츠를 단순히 추측하고 최고를 기대할 수 없음을 보여줍니다. 학습이 발생할 수 있는 지점까지 기울기가 달라지려면 모델 회로에 일부 구조가 있어야 합니다.
4. 휴리스틱
2019년 그랜트 의 흥미로운 휴리스틱은 무작위에 매우 가깝게 시작할 수 있지만 완전하지는 않습니다. McClean et al.과 동일한 회로를 사용하여 저자는 불모의 고원을 피하기 위해 고전적인 제어 매개변수에 대해 다른 초기화 기술을 제안합니다. 초기화 기술은 완전히 무작위적인 제어 매개변수로 일부 계층을 시작하지만 바로 다음 계층에서는 처음 몇 개의 계층에서 수행한 초기 변환이 취소되도록 매개변수를 선택합니다. 저자는 이것을 식별 블록 이라고 부릅니다.
이 휴리스틱의 장점은 단일 매개변수만 변경하면 현재 블록 외부의 다른 모든 블록이 동일하게 유지되고 그래디언트 신호가 이전보다 훨씬 더 강력하게 전달된다는 것입니다. 이를 통해 사용자는 강력한 기울기 신호를 얻기 위해 수정할 변수와 블록을 선택할 수 있습니다. 이 휴리스틱은 사용자가 훈련 단계에서 불모의 고원에 빠지는 것을 방지하지 않으며(완전히 동시 업데이트를 제한함), 단지 당신이 고원 밖에서 시작할 수 있다는 것을 보장합니다.
4.1 새로운 QNN 구축
이제 ID 블록 QNN을 생성하는 함수를 구성하십시오. 이 구현은 논문의 구현과 약간 다릅니다. 지금은 McClean et al과 일치하도록 단일 매개변수의 기울기 동작을 살펴보고 일부 단순화를 수행할 수 있습니다.
ID 블록을 생성하고 모델을 훈련시키려면 일반적으로 \(U1(\theta_{1a}) U1(\theta_{1b})^{\dagger}\) 이 아니라 \(U1(\theta_1) U1(\theta_1)^{\dagger}\)가 필요합니다. 처음 \(\theta_{1a}\) 과 \(\theta_{1b}\) 는 같은 각도이지만 독립적으로 학습됩니다. 그렇지 않으면 훈련 후에도 항상 ID를 얻게 됩니다. 식별 블록 수에 대한 선택은 경험적입니다. 블록이 깊을수록 블록 중간의 분산이 작아집니다. 그러나 블록의 시작과 끝에서 매개변수 기울기의 분산이 커야 합니다.
def generate_identity_qnn(qubits, symbol, block_depth, total_depth):
"""Generate random QNN's with the same structure from Grant et al."""
circuit = cirq.Circuit()
# Generate initial block with symbol.
prep_and_U = generate_random_qnn(qubits, symbol, block_depth)
circuit += prep_and_U
# Generate dagger of initial block without symbol.
U_dagger = (prep_and_U[1:])**-1
circuit += cirq.resolve_parameters(
U_dagger, param_resolver={symbol: np.random.uniform() * 2 * np.pi})
for d in range(total_depth - 1):
# Get a random QNN.
prep_and_U_circuit = generate_random_qnn(
qubits,
np.random.uniform() * 2 * np.pi, block_depth)
# Remove the state-prep component
U_circuit = prep_and_U_circuit[1:]
# Add U
circuit += U_circuit
# Add U^dagger
circuit += U_circuit**-1
return circuit
generate_identity_qnn(cirq.GridQubit.rect(1, 3), sympy.Symbol('theta'), 2, 2)
4.2 비교
여기에서 휴리스틱이 그라디언트의 분산이 빠르게 사라지는 것을 방지하는 데 도움이 된다는 것을 알 수 있습니다.
block_depth = 10
total_depth = 5
heuristic_theta_var = []
for n in n_qubits:
# Generate the identity block circuits and observable for the given n.
qubits = cirq.GridQubit.rect(1, n)
symbol = sympy.Symbol('theta')
circuits = [
generate_identity_qnn(qubits, symbol, block_depth, total_depth)
for _ in range(n_circuits)
]
op = cirq.Z(qubits[0]) * cirq.Z(qubits[1])
heuristic_theta_var.append(process_batch(circuits, symbol, op))
plt.semilogy(n_qubits, theta_var)
plt.semilogy(n_qubits, heuristic_theta_var)
plt.title('Heuristic vs. Random')
plt.xlabel('n_qubits')
plt.xticks(n_qubits)
plt.ylabel('$\\partial \\theta$ variance')
plt.show()
WARNING:tensorflow:6 out of the last 6 calls to <function Adjoint.differentiate_analytic at 0x7f9e3b5c68c0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/guide/function#controlling_retracing and https://www.tensorflow.org/api_docs/python/tf/function for more details.
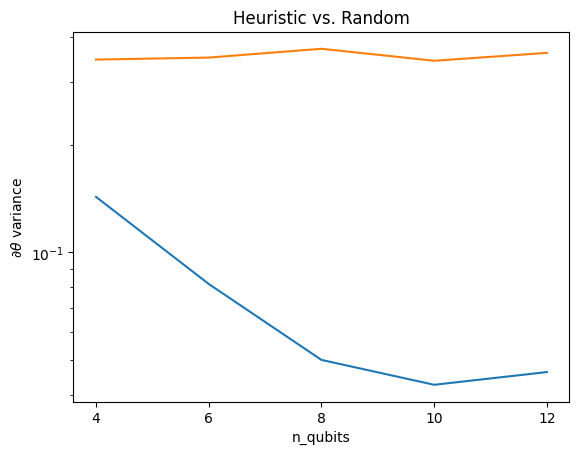
이것은 (근처) 임의의 QNN에서 더 강한 기울기 신호를 얻는 데 있어 크게 개선되었습니다.