
Метаданные ML (MLMD) — это библиотека для записи и извлечения метаданных, связанных с рабочими процессами разработчиков ML и специалистов по данным. MLMD является неотъемлемой частью TensorFlow Extended (TFX) , но спроектирован так, что его можно использовать независимо.
При каждом запуске производственного конвейера ML создаются метаданные, содержащие информацию о различных компонентах конвейера, их выполнении (например, обучающих запусках) и результирующих артефактах (например, обученных моделях). В случае неожиданного поведения или ошибок конвейера эти метаданные можно использовать для анализа происхождения компонентов конвейера и устранения проблем. Думайте об этих метаданных как об эквиваленте входа в систему разработки программного обеспечения.
MLMD помогает вам понять и проанализировать все взаимосвязанные части вашего конвейера ML, а не анализировать их по отдельности, и может помочь вам ответить на вопросы о вашем конвейере ML, такие как:
- На каком наборе данных тренировалась модель?
- Какие гиперпараметры использовались для обучения модели?
- Какой этап конвейера создал модель?
- Какой тренировочный прогон привел к созданию этой модели?
- Какая версия TensorFlow создала эту модель?
- Когда была выпущена неудачная модель?
Хранилище метаданных
MLMD регистрирует следующие типы метаданных в базе данных, называемой хранилищем метаданных .
- Метаданные об артефактах, созданных с помощью компонентов/шагов ваших конвейеров машинного обучения.
- Метаданные о выполнении этих компонентов/шагов
- Метаданные о конвейерах и связанная с ними информация о происхождении.
Хранилище метаданных предоставляет API для записи и извлечения метаданных в серверную часть хранилища и из нее. Серверная часть хранилища является подключаемой и может быть расширена. MLMD предоставляет эталонные реализации для SQLite (который поддерживает работу в памяти и на диске) и MySQL «из коробки».
На этом рисунке показан общий обзор различных компонентов, входящих в состав MLMD.
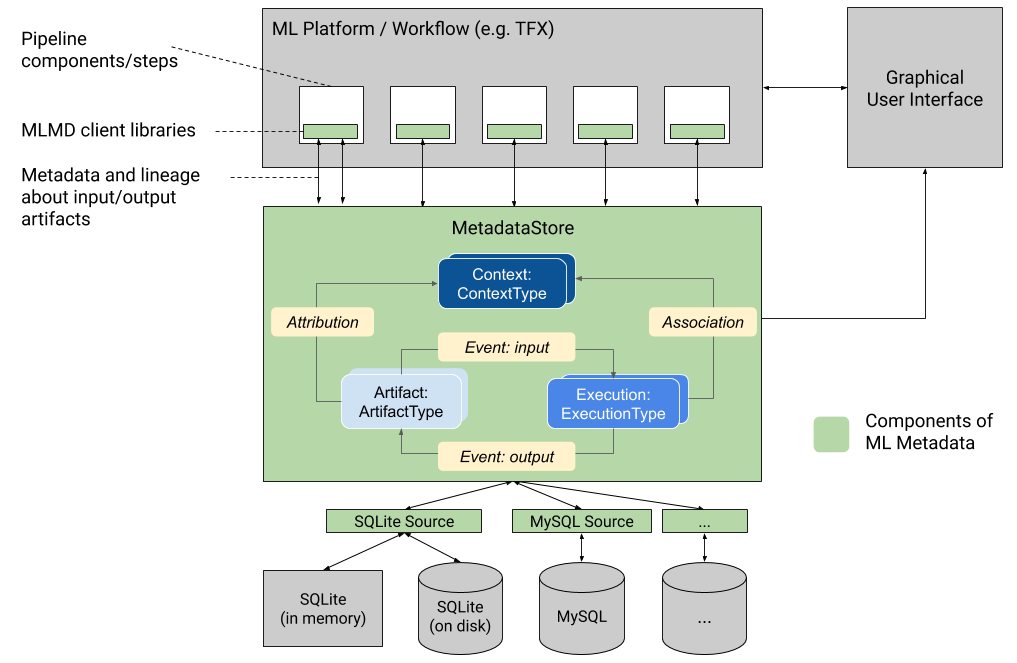
Серверные хранилища метаданных и конфигурация подключения к хранилищу
Объект MetadataStore получает конфигурацию подключения, соответствующую используемому серверу хранилища.
- Fake Database предоставляет базу данных в памяти (с использованием SQLite) для быстрого экспериментирования и локального запуска. База данных удаляется при уничтожении объекта хранилища.
import ml_metadata as mlmd
from ml_metadata.metadata_store import metadata_store
from ml_metadata.proto import metadata_store_pb2
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.fake_database.SetInParent() # Sets an empty fake database proto.
store = metadata_store.MetadataStore(connection_config)
- SQLite читает и записывает файлы с диска.
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.sqlite.filename_uri = '...'
connection_config.sqlite.connection_mode = 3 # READWRITE_OPENCREATE
store = metadata_store.MetadataStore(connection_config)
- MySQL подключается к серверу MySQL.
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.mysql.host = '...'
connection_config.mysql.port = '...'
connection_config.mysql.database = '...'
connection_config.mysql.user = '...'
connection_config.mysql.password = '...'
store = metadata_store.MetadataStore(connection_config)
Аналогично, при использовании экземпляра MySQL с Google CloudSQL ( быстрое начало , подключение-обзор ) можно также использовать опцию SSL, если это применимо.
connection_config.mysql.ssl_options.key = '...'
connection_config.mysql.ssl_options.cert = '...'
connection_config.mysql.ssl_options.ca = '...'
connection_config.mysql.ssl_options.capath = '...'
connection_config.mysql.ssl_options.cipher = '...'
connection_config.mysql.ssl_options.verify_server_cert = '...'
store = metadata_store.MetadataStore(connection_config)
- PostgreSQL подключается к серверу PostgreSQL.
connection_config = metadata_store_pb2.ConnectionConfig()
connection_config.postgresql.host = '...'
connection_config.postgresql.port = '...'
connection_config.postgresql.user = '...'
connection_config.postgresql.password = '...'
connection_config.postgresql.dbname = '...'
store = metadata_store.MetadataStore(connection_config)
Аналогичным образом, при использовании экземпляра PostgreSQL с Google CloudSQL ( быстрое начало , подключение-обзор ) можно также использовать опцию SSL, если это применимо.
connection_config.postgresql.ssloption.sslmode = '...' # disable, allow, verify-ca, verify-full, etc.
connection_config.postgresql.ssloption.sslcert = '...'
connection_config.postgresql.ssloption.sslkey = '...'
connection_config.postgresql.ssloption.sslpassword = '...'
connection_config.postgresql.ssloption.sslrootcert = '...'
store = metadata_store.MetadataStore(connection_config)
Модель данных
Хранилище метаданных использует следующую модель данных для записи и получения метаданных из серверной части хранилища.
-
ArtifactTypeописывает тип артефакта и его свойства, которые хранятся в хранилище метаданных. Вы можете зарегистрировать эти типы «на лету» в хранилище метаданных в коде или загрузить их в хранилище из сериализованного формата. После регистрации типа его определение будет доступно на протяжении всего срока существования хранилища. -
Artifactописывает конкретный экземплярArtifactTypeи его свойства, которые записываются в хранилище метаданных. -
ExecutionTypeописывает тип компонента или шага рабочего процесса и его параметры времени выполнения. -
Execution— это запись запуска компонента или шага рабочего процесса ML и параметров времени выполнения. Выполнение можно рассматривать как экземплярExecutionType. Выполнения записываются при запуске конвейера или шага ML. -
Event— это запись взаимосвязи между артефактами и казнями. Когда происходит выполнение, события записывают каждый артефакт, использованный при выполнении, и каждый созданный артефакт. Эти записи позволяют отслеживать происхождение на протяжении всего рабочего процесса. Просматривая все события, MLMD знает, какие казни произошли и какие артефакты были созданы в результате. Затем MLMD может выполнить рекурсивный возврат от любого артефакта ко всем его восходящим входным данным. -
ContextTypeописывает тип концептуальной группы артефактов и выполнения в рабочем процессе, а также ее структурные свойства. Например: проекты, трубопроводы, эксперименты, владельцы и т. д. -
Context— это экземплярContextType. Он фиксирует общую информацию внутри группы. Например: имя проекта, идентификатор фиксации списка изменений, аннотации эксперимента и т. д. В егоContextTypeимеется определяемое пользователем уникальное имя. -
Attribution— это запись взаимосвязи между артефактами и контекстами. -
Association— это запись взаимосвязи между выполнениями и контекстами.
Функциональность МЛМД
Отслеживание входных и выходных данных всех компонентов/шагов рабочего процесса ML и их происхождения позволяет платформам ML реализовать несколько важных функций. В следующем списке представлен неисчерпывающий обзор некоторых основных преимуществ.
- Перечислите все артефакты определенного типа. Пример: все модели, прошедшие обучение.
- Загрузите два артефакта одного типа для сравнения. Пример: сравнить результаты двух экспериментов.
- Покажите DAG всех связанных исполнений и их входных и выходных артефактов контекста. Пример: визуализируйте рабочий процесс эксперимента для отладки и обнаружения.
- Просмотрите все события, чтобы увидеть, как был создан артефакт. Примеры: посмотреть, какие данные вошли в модель; обеспечить соблюдение планов хранения данных.
- Определите все артефакты, созданные с использованием данного артефакта. Примеры: просмотрите все модели, обученные на основе определенного набора данных; отмечать модели, основанные на неверных данных.
- Определите, запускалось ли ранее выполнение на тех же входных данных. Пример: определить, выполнил ли компонент/шаг ту же работу и можно ли повторно использовать предыдущий результат.
- Записывайте и запрашивайте контекст выполнения рабочего процесса. Примеры: отслеживание владельца и списка изменений, использованных для запуска рабочего процесса; группировать линию путем экспериментов; управлять артефактами по проектам.
- Возможности декларативной фильтрации узлов по свойствам и узлам соседства с 1 переходом. Примеры: поиск артефактов определенного типа и в контексте некоторого конвейера; возвращать типизированные артефакты, где значение данного свойства находится в пределах диапазона; найти предыдущие исполнения в контексте с теми же входными данными.
См. руководство по MLMD , где приведен пример, показывающий, как использовать API MLMD и хранилище метаданных для получения информации о происхождении.
Интегрируйте метаданные ML в ваши рабочие процессы ML
Если вы разработчик платформы, заинтересованный в интеграции MLMD в свою систему, используйте приведенный ниже пример рабочего процесса, чтобы использовать API-интерфейсы MLMD низкого уровня для отслеживания выполнения задачи обучения. Вы также можете использовать API-интерфейсы Python более высокого уровня в средах записных книжек для записи метаданных эксперимента.
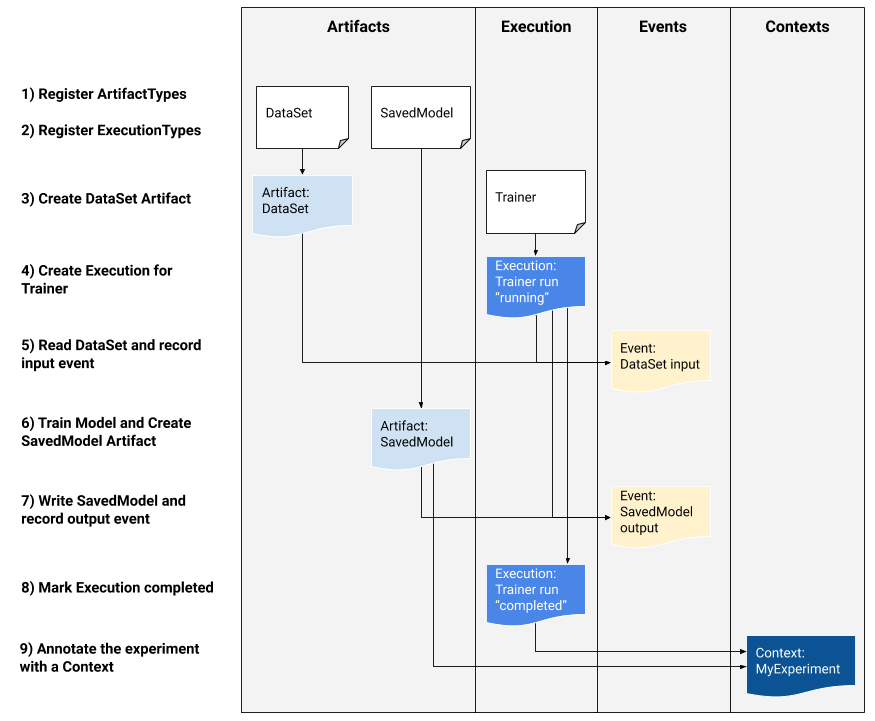
1) Регистрация типов артефактов
# Create ArtifactTypes, e.g., Data and Model
data_type = metadata_store_pb2.ArtifactType()
data_type.name = "DataSet"
data_type.properties["day"] = metadata_store_pb2.INT
data_type.properties["split"] = metadata_store_pb2.STRING
data_type_id = store.put_artifact_type(data_type)
model_type = metadata_store_pb2.ArtifactType()
model_type.name = "SavedModel"
model_type.properties["version"] = metadata_store_pb2.INT
model_type.properties["name"] = metadata_store_pb2.STRING
model_type_id = store.put_artifact_type(model_type)
# Query all registered Artifact types.
artifact_types = store.get_artifact_types()
2) Зарегистрируйте типы выполнения для всех шагов рабочего процесса ML.
# Create an ExecutionType, e.g., Trainer
trainer_type = metadata_store_pb2.ExecutionType()
trainer_type.name = "Trainer"
trainer_type.properties["state"] = metadata_store_pb2.STRING
trainer_type_id = store.put_execution_type(trainer_type)
# Query a registered Execution type with the returned id
[registered_type] = store.get_execution_types_by_id([trainer_type_id])
3) Создайте артефакт DataSet ArtifactType.
# Create an input artifact of type DataSet
data_artifact = metadata_store_pb2.Artifact()
data_artifact.uri = 'path/to/data'
data_artifact.properties["day"].int_value = 1
data_artifact.properties["split"].string_value = 'train'
data_artifact.type_id = data_type_id
[data_artifact_id] = store.put_artifacts([data_artifact])
# Query all registered Artifacts
artifacts = store.get_artifacts()
# Plus, there are many ways to query the same Artifact
[stored_data_artifact] = store.get_artifacts_by_id([data_artifact_id])
artifacts_with_uri = store.get_artifacts_by_uri(data_artifact.uri)
artifacts_with_conditions = store.get_artifacts(
list_options=mlmd.ListOptions(
filter_query='uri LIKE "%/data" AND properties.day.int_value > 0'))
4) Создайте выполнение трейнера.
# Register the Execution of a Trainer run
trainer_run = metadata_store_pb2.Execution()
trainer_run.type_id = trainer_type_id
trainer_run.properties["state"].string_value = "RUNNING"
[run_id] = store.put_executions([trainer_run])
# Query all registered Execution
executions = store.get_executions_by_id([run_id])
# Similarly, the same execution can be queried with conditions.
executions_with_conditions = store.get_executions(
list_options = mlmd.ListOptions(
filter_query='type = "Trainer" AND properties.state.string_value IS NOT NULL'))
5) Определите входное событие и прочитайте данные.
# Define the input event
input_event = metadata_store_pb2.Event()
input_event.artifact_id = data_artifact_id
input_event.execution_id = run_id
input_event.type = metadata_store_pb2.Event.DECLARED_INPUT
# Record the input event in the metadata store
store.put_events([input_event])
6) Объявить выходной артефакт
# Declare the output artifact of type SavedModel
model_artifact = metadata_store_pb2.Artifact()
model_artifact.uri = 'path/to/model/file'
model_artifact.properties["version"].int_value = 1
model_artifact.properties["name"].string_value = 'MNIST-v1'
model_artifact.type_id = model_type_id
[model_artifact_id] = store.put_artifacts([model_artifact])
7) Запишите выходное событие
# Declare the output event
output_event = metadata_store_pb2.Event()
output_event.artifact_id = model_artifact_id
output_event.execution_id = run_id
output_event.type = metadata_store_pb2.Event.DECLARED_OUTPUT
# Submit output event to the Metadata Store
store.put_events([output_event])
8) Отметить выполнение как завершенное
trainer_run.id = run_id
trainer_run.properties["state"].string_value = "COMPLETED"
store.put_executions([trainer_run])
9) Группируйте артефакты и исполнения в контексте с использованием артефактов атрибуции и утверждений.
# Create a ContextType, e.g., Experiment with a note property
experiment_type = metadata_store_pb2.ContextType()
experiment_type.name = "Experiment"
experiment_type.properties["note"] = metadata_store_pb2.STRING
experiment_type_id = store.put_context_type(experiment_type)
# Group the model and the trainer run to an experiment.
my_experiment = metadata_store_pb2.Context()
my_experiment.type_id = experiment_type_id
# Give the experiment a name
my_experiment.name = "exp1"
my_experiment.properties["note"].string_value = "My first experiment."
[experiment_id] = store.put_contexts([my_experiment])
attribution = metadata_store_pb2.Attribution()
attribution.artifact_id = model_artifact_id
attribution.context_id = experiment_id
association = metadata_store_pb2.Association()
association.execution_id = run_id
association.context_id = experiment_id
store.put_attributions_and_associations([attribution], [association])
# Query the Artifacts and Executions that are linked to the Context.
experiment_artifacts = store.get_artifacts_by_context(experiment_id)
experiment_executions = store.get_executions_by_context(experiment_id)
# You can also use neighborhood queries to fetch these artifacts and executions
# with conditions.
experiment_artifacts_with_conditions = store.get_artifacts(
list_options = mlmd.ListOptions(
filter_query=('contexts_a.type = "Experiment" AND contexts_a.name = "exp1"')))
experiment_executions_with_conditions = store.get_executions(
list_options = mlmd.ListOptions(
filter_query=('contexts_a.id = {}'.format(experiment_id))))
Используйте MLMD с удаленным сервером gRPC.
Вы можете использовать MLMD с удаленными серверами gRPC, как показано ниже:
- Запустить сервер
bazel run -c opt --define grpc_no_ares=true //ml_metadata/metadata_store:metadata_store_server
По умолчанию сервер использует поддельную базу данных в памяти для каждого запроса и не сохраняет метаданные между вызовами. Его также можно настроить с помощью MLMD MetadataStoreServerConfig для использования файлов SQLite или экземпляров MySQL. Конфигурацию можно сохранить в текстовом файле protobuf и передать в двоичный файл с помощью --metadata_store_server_config_file=path_to_the_config_file .
Пример файла MetadataStoreServerConfig в текстовом формате protobuf:
connection_config {
sqlite {
filename_uri: '/tmp/test_db'
connection_mode: READWRITE_OPENCREATE
}
}
- Создайте заглушку клиента и используйте ее в Python.
from grpc import insecure_channel
from ml_metadata.proto import metadata_store_pb2
from ml_metadata.proto import metadata_store_service_pb2
from ml_metadata.proto import metadata_store_service_pb2_grpc
channel = insecure_channel('localhost:8080')
stub = metadata_store_service_pb2_grpc.MetadataStoreServiceStub(channel)
- Используйте MLMD с вызовами RPC
# Create ArtifactTypes, e.g., Data and Model
data_type = metadata_store_pb2.ArtifactType()
data_type.name = "DataSet"
data_type.properties["day"] = metadata_store_pb2.INT
data_type.properties["split"] = metadata_store_pb2.STRING
request = metadata_store_service_pb2.PutArtifactTypeRequest()
request.all_fields_match = True
request.artifact_type.CopyFrom(data_type)
stub.PutArtifactType(request)
model_type = metadata_store_pb2.ArtifactType()
model_type.name = "SavedModel"
model_type.properties["version"] = metadata_store_pb2.INT
model_type.properties["name"] = metadata_store_pb2.STRING
request.artifact_type.CopyFrom(model_type)
stub.PutArtifactType(request)
Ресурсы
Библиотека MLMD имеет API высокого уровня, который вы можете легко использовать со своими конвейерами ML. Дополнительные сведения см. в документации по API MLMD .
Ознакомьтесь с фильтрацией декларативных узлов MLMD , чтобы узнать, как использовать возможности фильтрации декларативных узлов MLMD на свойствах и узлах соседства с 1 переходом.
Также ознакомьтесь с руководством по MLMD , чтобы узнать, как использовать MLMD для отслеживания происхождения компонентов вашего конвейера.
MLMD предоставляет утилиты для управления миграцией схем и данных между выпусками. Дополнительную информацию см. в Руководстве MLMD.