
Обзор
Конвейер анализа модели TensorFlow (TFMA) изображен следующим образом:
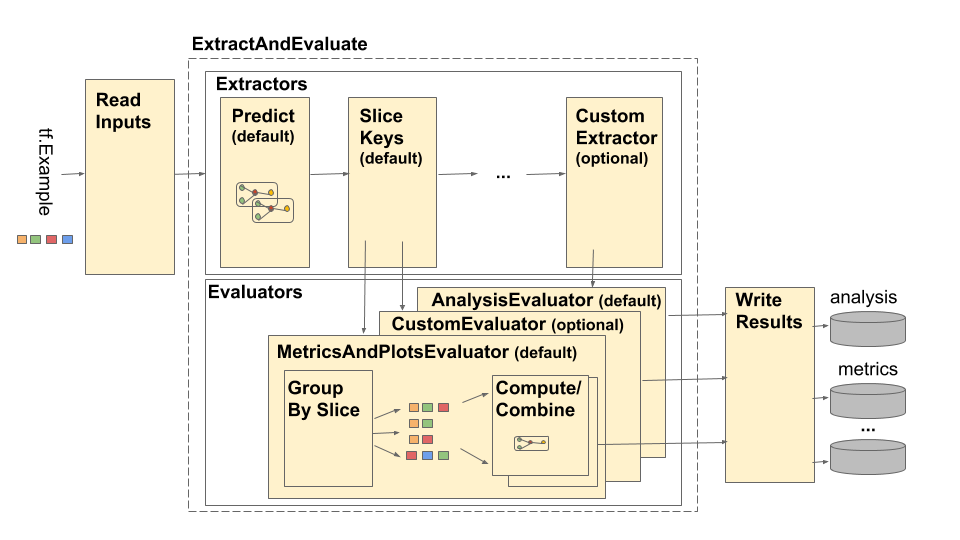
Трубопровод состоит из четырех основных компонентов:
- Чтение входных данных
- Добыча
- Оценка
- Написать результаты
Эти компоненты используют два основных типа: tfma.Extracts и tfma.evaluators.Evaluation . Тип tfma.Extracts представляет данные, извлекаемые во время конвейерной обработки, и может соответствовать одному или нескольким примерам модели. tfma.evaluators.Evaluation представляет собой результат оценки экстрактов на различных этапах процесса извлечения. Чтобы обеспечить гибкий API, эти типы представляют собой просто словари, в которых ключи определяются (зарезервированы для использования) различными реализациями. Типы определяются следующим образом:
# Extracts represent data extracted during pipeline processing.
# For example, the PredictExtractor stores the data for the
# features, labels, and predictions under the keys "features",
# "labels", and "predictions".
Extracts = Dict[Text, Any]
# Evaluation represents the output from evaluating extracts at
# particular point in the pipeline. The evaluation outputs are
# keyed by their associated output type. For example, the metric / plot
# dictionaries from evaluating metrics and plots will be stored under
# "metrics" and "plots" respectively.
Evaluation = Dict[Text, beam.pvalue.PCollection]
Обратите внимание, что tfma.Extracts никогда не записывается напрямую, они всегда должны пройти через оценщик, чтобы создать tfma.evaluators.Evaluation , который затем записывается. Также обратите внимание, что tfma.Extracts — это словари, которые хранятся в beam.pvalue.PCollection (т. е. beam.PTransform принимают в качестве входных данных beam.pvalue.PCollection[tfma.Extracts] ), тогда как tfma.evaluators.Evaluation — это словарь, значения которого являются beam.pvalue.PCollection (т. е. beam.PTransform принимают сам dict в качестве аргумента для входных данных beam.value.PCollection ). Другими словами, tfma.evaluators.Evaluation используется во время построения конвейера, а tfma.Extracts — во время выполнения конвейера.
Чтение входных данных
Этап ReadInputs состоит из преобразования, которое принимает необработанные входные данные (tf.train.Example, CSV,...) и преобразует их в извлечения. Сегодня экстракты представлены как необработанные входные байты, хранящиеся в tfma.INPUT_KEY , однако экстракты могут быть в любой форме, совместимой с конвейером извлечения - это означает, что он создает tfma.Extracts как выходные данные, и что эти экстракты совместимы с последующими экстракторы. Различные экстракторы должны четко документировать, что им требуется.
Добыча
Процесс извлечения представляет собой список beam.PTransform , которые выполняются последовательно. Экстракторы принимают tfma.Extracts в качестве входных данных и возвращают tfma.Extracts в качестве выходных данных. Прототипическим экстрактором является tfma.extractors.PredictExtractor , который использует входной экстракт, полученный в результате преобразования входных данных чтения, и пропускает его через модель для получения прогнозных экстрактов. Настраиваемые экстракторы можно вставлять в любой момент при условии, что их преобразования соответствуют API tfma.Extracts in и tfma.Extracts out. Экстрактор определяется следующим образом:
# An Extractor is a PTransform that takes Extracts as input and returns
# Extracts as output. A typical example is a PredictExtractor that receives
# an 'input' placeholder for input and adds additional 'predictions' extracts.
Extractor = NamedTuple('Extractor', [
('stage_name', Text),
('ptransform', beam.PTransform)]) # Extracts -> Extracts
Входной экстрактор
tfma.extractors.InputExtractor используется для извлечения необработанных функций, необработанных меток и необработанных примеров весов из записей tf.train.Example для использования в срезах метрик и вычислениях. По умолчанию значения сохраняются в ключах извлечения features , labels и example_weights соответственно. Метки модели с одним выходом и примеры весов сохраняются непосредственно как значения np.ndarray . Метки модели с несколькими выходами и примеры весов хранятся в виде значений np.ndarray (с ключом по имени выхода). Если выполняется оценка нескольких моделей, метки и примеры весов будут дополнительно встроены в другой словарь (с ключом по имени модели).
PredictExtractor
tfma.extractors.PredictExtractor выполняет прогнозы модели и сохраняет их под ключевыми predictions в словаре tfma.Extracts . Прогнозы модели с одним выходом сохраняются непосредственно как прогнозируемые выходные значения. Прогнозы модели с несколькими выходами хранятся в виде набора выходных значений (с ключом по имени выхода). Если выполняется оценка нескольких моделей, прогноз будет дополнительно встроен в другой словарь (с ключом по имени модели). Фактическое используемое выходное значение зависит от модели (например, выходные данные оценщика TF в форме dict, тогда как keras возвращает значения np.ndarray ).
SliceKeyExtractor
tfma.extractors.SliceKeyExtractor использует спецификацию срезов, чтобы определить, какие срезы применяются к каждому входному примеру на основе извлеченных функций, и добавляет соответствующие значения срезов к извлечениям для последующего использования оценщиками.
Оценка
Оценка – это процесс получения отрывка и его оценки. Хотя оценку обычно выполняют в конце конвейера извлечения, существуют случаи использования, которые требуют оценки на более ранних этапах процесса извлечения. Таким образом, вычислители связаны с экстракторами, выходные данные которых они должны оцениваться. Оценщик определяется следующим образом:
# An evaluator is a PTransform that takes Extracts as input and
# produces an Evaluation as output. A typical example of an evaluator
# is the MetricsAndPlotsEvaluator that takes the 'features', 'labels',
# and 'predictions' extracts from the PredictExtractor and evaluates
# them using post export metrics to produce metrics and plots dictionaries.
Evaluator = NamedTuple('Evaluator', [
('stage_name', Text),
('run_after', Text), # Extractor.stage_name
('ptransform', beam.PTransform)]) # Extracts -> Evaluation
Обратите внимание, что оценщиком является beam.PTransform , который принимает tfma.Extracts в качестве входных данных. Ничто не мешает реализации выполнять дополнительные преобразования извлечений в рамках процесса оценки. В отличие от экстракторов, которые должны возвращать словарь tfma.Extracts , нет ограничений на типы выходных данных, которые оценщик может выдать, хотя большинство оценщиков также возвращают словарь (например, имена и значения метрик).
MetricsAndPlotsEvaluator
tfma.evaluators.MetricsAndPlotsEvaluator принимает features , labels и predictions в качестве входных данных, пропускает их через tfma.slicer.FanoutSlices , чтобы сгруппировать их по срезам, а затем выполняет вычисления метрик и графиков. Он создает выходные данные в виде словарей метрик и отображает ключи и значения (позже они преобразуются в сериализованные прототипы для вывода с помощью tfma.writers.MetricsAndPlotsWriter ).
Написать результаты
На этапе WriteResults выходные данные оценки записываются на диск. WriteResults использует средства записи для записи данных на основе выходных ключей. Например, tfma.evaluators.Evaluation может содержать ключи для metrics и plots . Затем они будут связаны со словарями метрик и графиков, называемыми «метриками» и «графиками». Авторы указывают, как записывать каждый файл:
# A writer is a PTransform that takes evaluation output as input and
# serializes the associated PCollections of data to a sink.
Writer = NamedTuple('Writer', [
('stage_name', Text),
('ptransform', beam.PTransform)]) # Evaluation -> PDone
MetricsAndPlotsПисатель
Мы предоставляем tfma.writers.MetricsAndPlotsWriter , который преобразует словари метрик и графиков в сериализованные прототипы и записывает их на диск.
Если вы хотите использовать другой формат сериализации, вы можете создать собственный модуль записи и использовать его. Поскольку tfma.evaluators.Evaluation , передаваемый средствам записи, содержит выходные данные для всех объединенных оценщиков, предоставляется вспомогательное преобразование tfma.writers.Write , которое авторы записи могут использовать в своих реализациях ptransform для выбора подходящих beam.PCollection на основе выходной ключ (см. пример ниже).
Кастомизация
Метод tfma.run_model_analysis принимает аргументы extractors , evaluators и writers для настройки экстракторов, оценщиков и писателей, используемых конвейером. Если аргументы не указаны, то tfma.default_extractors , tfma.default_evaluators и tfma.default_writers используются по умолчанию.
Пользовательские экстракторы
Чтобы создать собственный экстрактор, создайте тип tfma.extractors.Extractor , который обертывает beam.PTransform , принимая tfma.Extracts в качестве входных данных и возвращая tfma.Extracts в качестве выходных данных. Примеры экстракторов доступны в разделе tfma.extractors .
Пользовательские оценщики
Чтобы создать пользовательский оценщик, создайте тип tfma.evaluators.Evaluator , который обертывает beam.PTransform , принимая tfma.Extracts в качестве входных данных и возвращая tfma.evaluators.Evaluation в качестве выходных данных. Самый простой оценщик может просто взять входящие tfma.Extracts и вывести их для сохранения в таблице. Именно это и делает tfma.evaluators.AnalysisTableEvaluator . Более сложный оценщик может выполнить дополнительную обработку и агрегацию данных. См. пример tfma.evaluators.MetricsAndPlotsEvaluator .
Обратите внимание, что сам tfma.evaluators.MetricsAndPlotsEvaluator можно настроить для поддержки пользовательских метрик (подробнее см. в разделе Метрики ).
Пользовательские писатели
Чтобы создать собственный модуль записи, создайте тип tfma.writers.Writer , который обертывает beam.PTransform , принимая tfma.evaluators.Evaluation в качестве входных данных и возвращая beam.pvalue.PDone в качестве выходных данных. Ниже приведен базовый пример средства записи для записи TFRecords, содержащего метрики:
tfma.writers.Writer(
stage_name='WriteTFRecord(%s)' % tfma.METRICS_KEY,
ptransform=tfma.writers.Write(
key=tfma.METRICS_KEY,
ptransform=beam.io.WriteToTFRecord(file_path_prefix=output_file))
Входные данные автора зависят от результатов соответствующего оценщика. В приведенном выше примере выходные данные представляют собой сериализованный прототип, созданный tfma.evaluators.MetricsAndPlotsEvaluator . Автор tfma.evaluators.AnalysisTableEvaluator будет отвечать за запись beam.pvalue.PCollection tfma.Extracts .
Обратите внимание, что модуль записи связан с выводом оценщика через используемый выходной ключ (например, tfma.METRICS_KEY , tfma.ANALYSIS_KEY и т. д.).
Пошаговый пример
Ниже приведен пример шагов, участвующих в конвейере извлечения и оценки, когда используются как tfma.evaluators.MetricsAndPlotsEvaluator , так и tfma.evaluators.AnalysisTableEvaluator :
run_model_analysis(
...
extractors=[
tfma.extractors.InputExtractor(...),
tfma.extractors.PredictExtractor(...),
tfma.extractors.SliceKeyExtrator(...)
],
evaluators=[
tfma.evaluators.MetricsAndPlotsEvaluator(...),
tfma.evaluators.AnalysisTableEvaluator(...)
])
ReadInputs
# Out
Extracts {
'input': bytes # CSV, Proto, ...
}
ExtractAndEvaluate
# In: ReadInputs Extracts
# Out:
Extracts {
'input': bytes # CSV, Proto, ...
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
}
# In: InputExtractor Extracts
# Out:
Extracts {
'input': bytes # CSV, Proto, ...
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
'predictions': tensor_like # Predictions
}
# In: PredictExtractor Extracts
# Out:
Extracts {
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
'predictions': tensor_like # Predictions
'slice_key': Tuple[bytes...] # Slice
}
tfma.evaluators.MetricsAndPlotsEvaluator(run_after:SLICE_KEY_EXTRACTOR_STAGE_NAME)
# In: SliceKeyExtractor Extracts
# Out:
Evaluation {
'metrics': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from metric key to metric values)
'plots': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from plot key to plot values)
}
tfma.evaluators.AnalysisTableEvaluator(run_after:LAST_EXTRACTOR_STAGE_NAME)
# In: SliceKeyExtractor Extracts
# Out:
Evaluation {
'analysis': PCollection[Extracts] # Final Extracts
}
WriteResults
# In:
Evaluation {
'metrics': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from metric key to metric values)
'plots': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from plot key to plot values)
'analysis': PCollection[Extracts] # Final Extracts
}
# Out: metrics, plots, and analysis files