
| | |  Afficher sur GitHub Afficher sur GitHub | | |
YAMNet est un réseau de neurones profonds pré-entraîné qui peut prédire des événements audio à partir de 521 classes , comme des rires, des aboiements ou une sirène.
Dans ce didacticiel, vous apprendrez à :
- Chargez et utilisez le modèle YAMNet pour l'inférence.
- Créez un nouveau modèle à l'aide des intégrations YAMNet pour classer les sons des chats et des chiens.
- Évaluez et exportez votre modèle.
Importer TensorFlow et d'autres bibliothèques
Commencez par installer TensorFlow I/O , ce qui vous facilitera le chargement des fichiers audio à partir du disque.
pip install tensorflow_io
import os
from IPython import display
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_io as tfio
À propos de YAMNet
YAMNet est un réseau neuronal préformé qui utilise l'architecture de convolution séparable en profondeur MobileNetV1 . Il peut utiliser une forme d'onde audio comme entrée et faire des prédictions indépendantes pour chacun des 521 événements audio du corpus AudioSet .
En interne, le modèle extrait des "trames" du signal audio et traite des lots de ces trames. Cette version du modèle utilise des images d'une durée de 0,96 seconde et extrait une image toutes les 0,48 seconde.
Le modèle accepte un tenseur 1-D float32 ou un tableau NumPy contenant une forme d'onde de longueur arbitraire, représentée sous forme d'échantillons à canal unique (mono) de 16 kHz dans la plage [-1.0, +1.0] . Ce didacticiel contient du code pour vous aider à convertir les fichiers WAV au format pris en charge.
Le modèle renvoie 3 sorties, y compris les scores de classe, les incorporations (que vous utiliserez pour l'apprentissage par transfert) et le spectrogramme log mel . Vous pouvez trouver plus de détails ici .
Une utilisation spécifique de YAMNet est en tant qu'extracteur de fonctionnalités de haut niveau - la sortie d'intégration à 1 024 dimensions. Vous utiliserez les fonctionnalités d'entrée du modèle de base (YAMNet) et les alimenterez dans votre modèle moins profond composé d'une couche tf.keras.layers.Dense cachée. Ensuite, vous formerez le réseau sur une petite quantité de données pour la classification audio sans nécessiter beaucoup de données étiquetées et de formation de bout en bout. (Ceci est similaire à l'apprentissage par transfert pour la classification d'images avec TensorFlow Hub pour plus d'informations.)
Tout d'abord, vous testerez le modèle et verrez les résultats de la classification audio. Vous construirez ensuite le pipeline de prétraitement des données.
Charger YAMNet depuis TensorFlow Hub
Vous allez utiliser un YAMNet pré-formé de Tensorflow Hub pour extraire les intégrations des fichiers audio.
Le chargement d'un modèle à partir de TensorFlow Hub est simple : choisissez le modèle, copiez son URL et utilisez la fonction de load .
yamnet_model_handle = 'https://tfhub.dev/google/yamnet/1'
yamnet_model = hub.load(yamnet_model_handle)
Une fois le modèle chargé, vous pouvez suivre le didacticiel d'utilisation de base de YAMNet et télécharger un exemple de fichier WAV pour exécuter l'inférence.
testing_wav_file_name = tf.keras.utils.get_file('miaow_16k.wav',
'https://storage.googleapis.com/audioset/miaow_16k.wav',
cache_dir='./',
cache_subdir='test_data')
print(testing_wav_file_name)
Downloading data from https://storage.googleapis.com/audioset/miaow_16k.wav 221184/215546 [==============================] - 0s 0us/step 229376/215546 [===============================] - 0s 0us/step ./test_data/miaow_16k.wav
Vous aurez besoin d'une fonction pour charger les fichiers audio, qui seront également utilisés plus tard lorsque vous travaillerez avec les données d'entraînement. (En savoir plus sur la lecture des fichiers audio et de leurs étiquettes dans Reconnaissance audio simple .
# Utility functions for loading audio files and making sure the sample rate is correct.
@tf.function
def load_wav_16k_mono(filename):
""" Load a WAV file, convert it to a float tensor, resample to 16 kHz single-channel audio. """
file_contents = tf.io.read_file(filename)
wav, sample_rate = tf.audio.decode_wav(
file_contents,
desired_channels=1)
wav = tf.squeeze(wav, axis=-1)
sample_rate = tf.cast(sample_rate, dtype=tf.int64)
wav = tfio.audio.resample(wav, rate_in=sample_rate, rate_out=16000)
return wav
testing_wav_data = load_wav_16k_mono(testing_wav_file_name)
_ = plt.plot(testing_wav_data)
# Play the audio file.
display.Audio(testing_wav_data,rate=16000)
2022-01-26 08:07:19.084427: W tensorflow_io/core/kernels/audio_video_mp3_kernels.cc:271] libmp3lame.so.0 or lame functions are not available WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample

Charger le mappage de classe
Il est important de charger les noms de classe que YAMNet est capable de reconnaître. Le fichier de mappage est présent dans yamnet_model.class_map_path() au format CSV.
class_map_path = yamnet_model.class_map_path().numpy().decode('utf-8')
class_names =list(pd.read_csv(class_map_path)['display_name'])
for name in class_names[:20]:
print(name)
print('...')
Speech Child speech, kid speaking Conversation Narration, monologue Babbling Speech synthesizer Shout Bellow Whoop Yell Children shouting Screaming Whispering Laughter Baby laughter Giggle Snicker Belly laugh Chuckle, chortle Crying, sobbing ...
Exécuter l'inférence
YAMNet fournit des scores de classe au niveau de la trame (c'est-à-dire 521 scores pour chaque trame). Afin de déterminer les prédictions au niveau du clip, les scores peuvent être agrégés par classe à travers les images (par exemple, en utilisant l'agrégation moyenne ou maximale). Ceci est fait ci-dessous par scores_np.mean(axis=0) . Enfin, pour trouver la classe la mieux notée au niveau du clip, vous prenez le maximum des 521 scores agrégés.
scores, embeddings, spectrogram = yamnet_model(testing_wav_data)
class_scores = tf.reduce_mean(scores, axis=0)
top_class = tf.argmax(class_scores)
inferred_class = class_names[top_class]
print(f'The main sound is: {inferred_class}')
print(f'The embeddings shape: {embeddings.shape}')
The main sound is: Animal The embeddings shape: (13, 1024)
Jeu de données ESC-50
L' ensemble de données ESC-50 ( Piczak, 2015 ) est une collection étiquetée de 2 000 enregistrements audio environnementaux de cinq secondes. L'ensemble de données se compose de 50 classes, avec 40 exemples par classe.
Téléchargez le jeu de données et extrayez-le.
_ = tf.keras.utils.get_file('esc-50.zip',
'https://github.com/karoldvl/ESC-50/archive/master.zip',
cache_dir='./',
cache_subdir='datasets',
extract=True)
Downloading data from https://github.com/karoldvl/ESC-50/archive/master.zip 645103616/Unknown - 47s 0us/step
Explorer les données
Les métadonnées de chaque fichier sont spécifiées dans le fichier csv à l' ./datasets/ESC-50-master/meta/esc50.csv
et tous les fichiers audio sont dans ./datasets/ESC-50-master/audio/
Vous allez créer un pandas DataFrame avec le mappage et l'utiliser pour avoir une vue plus claire des données.
esc50_csv = './datasets/ESC-50-master/meta/esc50.csv'
base_data_path = './datasets/ESC-50-master/audio/'
pd_data = pd.read_csv(esc50_csv)
pd_data.head()
Filtrer les données
Maintenant que les données sont stockées dans le DataFrame , appliquez quelques transformations :
- Filtrez les lignes et utilisez uniquement les classes sélectionnées -
dogetcat. Si vous souhaitez utiliser d'autres classes, c'est ici que vous pouvez les choisir. - Modifiez le nom du fichier pour avoir le chemin complet. Cela facilitera le chargement plus tard.
- Modifiez les cibles pour qu'elles se situent dans une plage spécifique. Dans cet exemple,
dogrestera à0, maiscatdeviendra1au lieu de sa valeur d'origine de5.
my_classes = ['dog', 'cat']
map_class_to_id = {'dog':0, 'cat':1}
filtered_pd = pd_data[pd_data.category.isin(my_classes)]
class_id = filtered_pd['category'].apply(lambda name: map_class_to_id[name])
filtered_pd = filtered_pd.assign(target=class_id)
full_path = filtered_pd['filename'].apply(lambda row: os.path.join(base_data_path, row))
filtered_pd = filtered_pd.assign(filename=full_path)
filtered_pd.head(10)
Charger les fichiers audio et récupérer les embeddings
Ici, vous allez appliquer load_wav_16k_mono et préparer les données WAV pour le modèle.
Lors de l'extraction d'incorporations à partir des données WAV, vous obtenez un tableau de forme (N, 1024) où N est le nombre d'images trouvées par YAMNet (une pour chaque 0,48 seconde d'audio).
Votre modèle utilisera chaque image comme une entrée. Par conséquent, vous devez créer une nouvelle colonne contenant un cadre par ligne. Vous devez également développer les étiquettes et la colonne de fold pour refléter correctement ces nouvelles lignes.
La colonne de fold développée conserve les valeurs d'origine. Vous ne pouvez pas mélanger les images car, lors de l'exécution des divisions, vous pourriez vous retrouver avec des parties du même audio sur différentes divisions, ce qui rendrait vos étapes de validation et de test moins efficaces.
filenames = filtered_pd['filename']
targets = filtered_pd['target']
folds = filtered_pd['fold']
main_ds = tf.data.Dataset.from_tensor_slices((filenames, targets, folds))
main_ds.element_spec
(TensorSpec(shape=(), dtype=tf.string, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
def load_wav_for_map(filename, label, fold):
return load_wav_16k_mono(filename), label, fold
main_ds = main_ds.map(load_wav_for_map)
main_ds.element_spec
WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample (TensorSpec(shape=<unknown>, dtype=tf.float32, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
# applies the embedding extraction model to a wav data
def extract_embedding(wav_data, label, fold):
''' run YAMNet to extract embedding from the wav data '''
scores, embeddings, spectrogram = yamnet_model(wav_data)
num_embeddings = tf.shape(embeddings)[0]
return (embeddings,
tf.repeat(label, num_embeddings),
tf.repeat(fold, num_embeddings))
# extract embedding
main_ds = main_ds.map(extract_embedding).unbatch()
main_ds.element_spec
(TensorSpec(shape=(1024,), dtype=tf.float32, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
Diviser les données
Vous utiliserez la colonne de fold pour diviser l'ensemble de données en ensembles d'apprentissage, de validation et de test.
ESC-50 est organisé en cinq fold de validation croisée de taille uniforme, de sorte que les clips de la même source d'origine sont toujours dans le même fold - découvrez-en plus dans l'article ESC: Dataset for Environmental Sound Classification .
La dernière étape consiste à supprimer la colonne de fold de l'ensemble de données puisque vous n'allez pas l'utiliser pendant l'entraînement.
cached_ds = main_ds.cache()
train_ds = cached_ds.filter(lambda embedding, label, fold: fold < 4)
val_ds = cached_ds.filter(lambda embedding, label, fold: fold == 4)
test_ds = cached_ds.filter(lambda embedding, label, fold: fold == 5)
# remove the folds column now that it's not needed anymore
remove_fold_column = lambda embedding, label, fold: (embedding, label)
train_ds = train_ds.map(remove_fold_column)
val_ds = val_ds.map(remove_fold_column)
test_ds = test_ds.map(remove_fold_column)
train_ds = train_ds.cache().shuffle(1000).batch(32).prefetch(tf.data.AUTOTUNE)
val_ds = val_ds.cache().batch(32).prefetch(tf.data.AUTOTUNE)
test_ds = test_ds.cache().batch(32).prefetch(tf.data.AUTOTUNE)
Créez votre modèle
Vous avez fait le plus gros du travail ! Ensuite, définissez un modèle séquentiel très simple avec une couche cachée et deux sorties pour reconnaître les chats et les chiens à partir des sons.
my_model = tf.keras.Sequential([
tf.keras.layers.Input(shape=(1024), dtype=tf.float32,
name='input_embedding'),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(len(my_classes))
], name='my_model')
my_model.summary()
Model: "my_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 512) 524800
dense_1 (Dense) (None, 2) 1026
=================================================================
Total params: 525,826
Trainable params: 525,826
Non-trainable params: 0
_________________________________________________________________
my_model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer="adam",
metrics=['accuracy'])
callback = tf.keras.callbacks.EarlyStopping(monitor='loss',
patience=3,
restore_best_weights=True)
history = my_model.fit(train_ds,
epochs=20,
validation_data=val_ds,
callbacks=callback)
Epoch 1/20 15/15 [==============================] - 6s 49ms/step - loss: 0.7811 - accuracy: 0.8229 - val_loss: 0.4866 - val_accuracy: 0.9125 Epoch 2/20 15/15 [==============================] - 0s 18ms/step - loss: 0.3385 - accuracy: 0.8938 - val_loss: 0.2185 - val_accuracy: 0.8813 Epoch 3/20 15/15 [==============================] - 0s 18ms/step - loss: 0.3091 - accuracy: 0.9021 - val_loss: 0.4290 - val_accuracy: 0.8813 Epoch 4/20 15/15 [==============================] - 0s 18ms/step - loss: 0.5354 - accuracy: 0.9062 - val_loss: 0.2074 - val_accuracy: 0.9125 Epoch 5/20 15/15 [==============================] - 0s 18ms/step - loss: 0.4651 - accuracy: 0.9333 - val_loss: 0.6857 - val_accuracy: 0.8813 Epoch 6/20 15/15 [==============================] - 0s 18ms/step - loss: 0.2489 - accuracy: 0.9167 - val_loss: 0.3640 - val_accuracy: 0.8750 Epoch 7/20 15/15 [==============================] - 0s 17ms/step - loss: 0.2020 - accuracy: 0.9292 - val_loss: 0.2158 - val_accuracy: 0.9125 Epoch 8/20 15/15 [==============================] - 0s 16ms/step - loss: 0.4550 - accuracy: 0.9208 - val_loss: 0.9893 - val_accuracy: 0.8750 Epoch 9/20 15/15 [==============================] - 0s 17ms/step - loss: 0.3434 - accuracy: 0.9354 - val_loss: 0.2670 - val_accuracy: 0.8813 Epoch 10/20 15/15 [==============================] - 0s 17ms/step - loss: 0.2864 - accuracy: 0.9208 - val_loss: 0.5122 - val_accuracy: 0.8813
Exécutons la méthode d' evaluate sur les données de test juste pour être sûr qu'il n'y a pas de surajustement.
loss, accuracy = my_model.evaluate(test_ds)
print("Loss: ", loss)
print("Accuracy: ", accuracy)
5/5 [==============================] - 0s 9ms/step - loss: 0.2526 - accuracy: 0.9000 Loss: 0.25257644057273865 Accuracy: 0.8999999761581421
Tu l'as fait!
Testez votre modèle
Ensuite, essayez votre modèle sur l'intégration du test précédent en utilisant uniquement YAMNet.
scores, embeddings, spectrogram = yamnet_model(testing_wav_data)
result = my_model(embeddings).numpy()
inferred_class = my_classes[result.mean(axis=0).argmax()]
print(f'The main sound is: {inferred_class}')
The main sound is: cat
Enregistrer un modèle qui peut directement prendre un fichier WAV en entrée
Votre modèle fonctionne lorsque vous lui donnez les plongements en entrée.
Dans un scénario réel, vous souhaiterez utiliser des données audio comme entrée directe.
Pour ce faire, vous combinerez YAMNet avec votre modèle en un seul modèle que vous pourrez exporter pour d'autres applications.
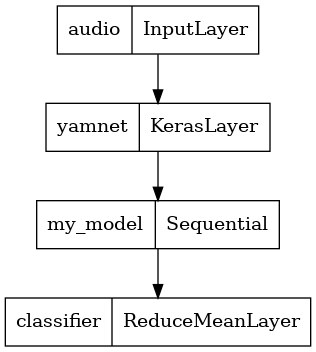
Pour faciliter l'utilisation du résultat du modèle, la couche finale sera une opération reduce_mean . Lorsque vous utilisez ce modèle pour servir (que vous découvrirez plus tard dans le didacticiel), vous aurez besoin du nom de la couche finale. Si vous n'en définissez pas, TensorFlow en définira automatiquement un incrémentiel qui le rendra difficile à tester, car il changera à chaque fois que vous entraînerez le modèle. Lorsque vous utilisez une opération TensorFlow brute, vous ne pouvez pas lui attribuer de nom. Pour résoudre ce problème, vous allez créer une couche personnalisée qui applique reduce_mean et l'appeler 'classifier' .
class ReduceMeanLayer(tf.keras.layers.Layer):
def __init__(self, axis=0, **kwargs):
super(ReduceMeanLayer, self).__init__(**kwargs)
self.axis = axis
def call(self, input):
return tf.math.reduce_mean(input, axis=self.axis)
saved_model_path = './dogs_and_cats_yamnet'
input_segment = tf.keras.layers.Input(shape=(), dtype=tf.float32, name='audio')
embedding_extraction_layer = hub.KerasLayer(yamnet_model_handle,
trainable=False, name='yamnet')
_, embeddings_output, _ = embedding_extraction_layer(input_segment)
serving_outputs = my_model(embeddings_output)
serving_outputs = ReduceMeanLayer(axis=0, name='classifier')(serving_outputs)
serving_model = tf.keras.Model(input_segment, serving_outputs)
serving_model.save(saved_model_path, include_optimizer=False)
WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. 2022-01-26 08:08:33.807036: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: ./dogs_and_cats_yamnet/assets INFO:tensorflow:Assets written to: ./dogs_and_cats_yamnet/assets
tf.keras.utils.plot_model(serving_model)
Chargez votre modèle enregistré pour vérifier qu'il fonctionne comme prévu.
reloaded_model = tf.saved_model.load(saved_model_path)
Et pour le test final : étant donné quelques données sonores, votre modèle renvoie-t-il le bon résultat ?
reloaded_results = reloaded_model(testing_wav_data)
cat_or_dog = my_classes[tf.argmax(reloaded_results)]
print(f'The main sound is: {cat_or_dog}')
The main sound is: cat
Si vous souhaitez essayer votre nouveau modèle sur une configuration de diffusion, vous pouvez utiliser la signature "serving_default".
serving_results = reloaded_model.signatures['serving_default'](testing_wav_data)
cat_or_dog = my_classes[tf.argmax(serving_results['classifier'])]
print(f'The main sound is: {cat_or_dog}')
The main sound is: cat
(Facultatif) Quelques tests supplémentaires
Le modèle est prêt.
Comparons-le à YAMNet sur l'ensemble de données de test.
test_pd = filtered_pd.loc[filtered_pd['fold'] == 5]
row = test_pd.sample(1)
filename = row['filename'].item()
print(filename)
waveform = load_wav_16k_mono(filename)
print(f'Waveform values: {waveform}')
_ = plt.plot(waveform)
display.Audio(waveform, rate=16000)
./datasets/ESC-50-master/audio/5-214759-A-5.wav WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample Waveform values: [ 3.2084468e-09 -7.7704687e-09 -1.2222010e-08 ... 2.2788899e-02 1.0315948e-02 -3.4766860e-02]
# Run the model, check the output.
scores, embeddings, spectrogram = yamnet_model(waveform)
class_scores = tf.reduce_mean(scores, axis=0)
top_class = tf.argmax(class_scores)
inferred_class = class_names[top_class]
top_score = class_scores[top_class]
print(f'[YAMNet] The main sound is: {inferred_class} ({top_score})')
reloaded_results = reloaded_model(waveform)
your_top_class = tf.argmax(reloaded_results)
your_inferred_class = my_classes[your_top_class]
class_probabilities = tf.nn.softmax(reloaded_results, axis=-1)
your_top_score = class_probabilities[your_top_class]
print(f'[Your model] The main sound is: {your_inferred_class} ({your_top_score})')
[YAMNet] The main sound is: Silence (0.500638484954834) [Your model] The main sound is: cat (0.9981643557548523)
Prochaines étapes
Vous avez créé un modèle capable de classer les sons de chiens ou de chats. Avec la même idée et un ensemble de données différent, vous pouvez essayer, par exemple, de construire un identifiant acoustique des oiseaux basé sur leur chant.
Partagez votre projet avec l'équipe TensorFlow sur les réseaux sociaux !