|
|
|
 GitHubでソースを表示 GitHubでソースを表示
|
|
このチュートリアルは、tf.estimatorAPI で決定木を使用する勾配ブースティングモデルのエンドツーエンドのウォークスルーです。ブースティング木モデルは、回帰と分類の両方のための最も一般的かつ効果的な機械学習アプローチの 1 つです。これは、複数(10 以上、100 以上、あるいは 1000 以上の場合も考えられます)の木モデルからの予測値を結合するアンサンブル手法です。
最小限のハイパーパラメータ調整で優れたパフォーマンスを実現できるため、ブースティング木モデルは多くの機械学習実践者に人気があります。
Titanic データセットを読み込む
Titanic データセットを使用します。ここでの目標は、性別、年齢、船室クラスなどの特徴に基づき、(やや悪趣味ではありますが)乗船者の生存を予測することです。
import numpy as np
import pandas as pd
from IPython.display import clear_output
from matplotlib import pyplot as plt
# Load dataset.
dftrain = pd.read_csv('https://storage.googleapis.com/tf-datasets/titanic/train.csv')
dfeval = pd.read_csv('https://storage.googleapis.com/tf-datasets/titanic/eval.csv')
y_train = dftrain.pop('survived')
y_eval = dfeval.pop('survived')
import tensorflow as tf
tf.random.set_seed(123)
データセットはトレーニングセットと評価セットで構成されています。
dftrainとy_trainは トレーニングセットです — モデルが学習に使用するデータです。- モデルは評価セット、
dfeval、y_evalに対してテストされます。
トレーニングには以下の特徴を使用します。
| 特徴名 | 説明 |
|---|---|
| sex | 乗船者の性別 |
| age | 乗船者の年齢 |
| n_siblings_spouses | 同乗する兄弟姉妹および配偶者 |
| parch | 同乗する両親および子供 |
| fare | 運賃 |
| class | 船室のクラス |
| deck | 搭乗デッキ |
| embark_town | 乗船者の乗船地 |
| alone | 一人旅か否か |
データを検証する
まず最初に、データの一部をプレビューして、トレーニングセットの要約統計を作成します。
dftrain.head()
dftrain.describe()
トレーニングセットと評価セットには、それぞれ 627 個と 264 個の例があります。
dftrain.shape[0], dfeval.shape[0]
(627, 264)
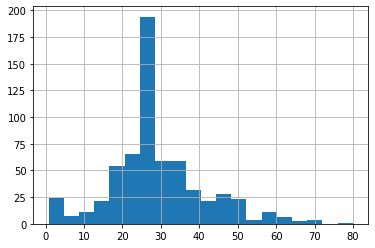
乗船者の大半は 20 代から 30 代です。
dftrain.age.hist(bins=20)
plt.show()
男性の乗船者数は女性の乗船者数の約 2 倍です。
dftrain.sex.value_counts().plot(kind='barh')
plt.show()
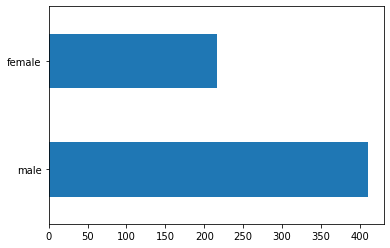
乗船者の大半は「3 等」の船室クラスを利用していました。
dftrain['class'].value_counts().plot(kind='barh')
plt.show()

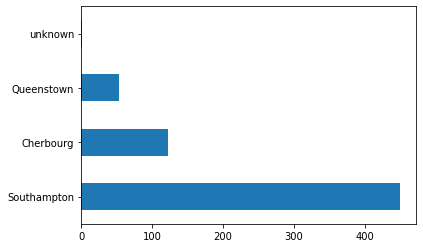
大半の乗船者はサウサンプトンから乗船しています。
dftrain['embark_town'].value_counts().plot(kind='barh')
plt.show()
女性は男性よりも生存する確率がはるかに高く、これは明らかにモデルの予測特徴です。
pd.concat([dftrain, y_train], axis=1).groupby('sex').survived.mean().plot(kind='barh').set_xlabel('% survive')
plt.show()

特徴量カラムを作成して関数を入力する
勾配ブースティング Estimator は数値特徴とカテゴリ特徴の両方を利用します。特徴量カラムは、全ての TensorFlow Estimator と機能し、その目的はモデリングに使用される特徴を定義することにあります。さらに、One-Hot エンコーディング、正規化、バケット化などいくつかの特徴量エンジニアリング機能を提供します。このチュートリアルでは、CATEGORICAL_COLUMNSのフィールドはカテゴリカラムから One-Hot エンコーディングされたカラム(インジケータカラム)に変換されます。
CATEGORICAL_COLUMNS = ['sex', 'n_siblings_spouses', 'parch', 'class', 'deck',
'embark_town', 'alone']
NUMERIC_COLUMNS = ['age', 'fare']
def one_hot_cat_column(feature_name, vocab):
return tf.feature_column.indicator_column(
tf.feature_column.categorical_column_with_vocabulary_list(feature_name,
vocab))
feature_columns = []
for feature_name in CATEGORICAL_COLUMNS:
# Need to one-hot encode categorical features.
vocabulary = dftrain[feature_name].unique()
feature_columns.append(one_hot_cat_column(feature_name, vocabulary))
for feature_name in NUMERIC_COLUMNS:
feature_columns.append(tf.feature_column.numeric_column(feature_name,
dtype=tf.float32))
特徴量カラムが生成する変換は表示することができます。例えば、indicator_columnを単一の例で使用した場合の出力は次のようになります。
example = dict(dftrain.head(1))
class_fc = tf.feature_column.indicator_column(tf.feature_column.categorical_column_with_vocabulary_list('class', ('First', 'Second', 'Third')))
print('Feature value: "{}"'.format(example['class'].iloc[0]))
print('One-hot encoded: ', tf.keras.layers.DenseFeatures([class_fc])(example).numpy())
Feature value: "Third" One-hot encoded: [[0. 0. 1.]]
さらに、特徴量カラムの変換を全てまとめて表示することができます。
tf.keras.layers.DenseFeatures(feature_columns)(example).numpy()
array([[22. , 1. , 0. , 1. , 0. , 0. , 1. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. , 1. , 0. , 0. , 0. ,
7.25, 1. , 0. , 0. , 0. , 0. , 0. , 0. , 1. ,
0. , 0. , 0. , 0. , 0. , 1. , 0. ]], dtype=float32)
次に、入力関数を作成する必要があります。これらはトレーニングと推論の両方のためにデータをモデルに読み込む方法を指定します。 tf.data API のfrom_tensor_slicesメソッドを使用して Pandas から直接データを読み取ります。これは小規模でインメモリのデータセットに適しています。大規模のデータセットの場合は、多様なファイル形式(csvを含む)をサポートする tf.data API を使用すると、メモリに収まりきれないデータセットも処理することができます。
# Use entire batch since this is such a small dataset.
NUM_EXAMPLES = len(y_train)
def make_input_fn(X, y, n_epochs=None, shuffle=True):
def input_fn():
dataset = tf.data.Dataset.from_tensor_slices((dict(X), y))
if shuffle:
dataset = dataset.shuffle(NUM_EXAMPLES)
# For training, cycle thru dataset as many times as need (n_epochs=None).
dataset = dataset.repeat(n_epochs)
# In memory training doesn't use batching.
dataset = dataset.batch(NUM_EXAMPLES)
return dataset
return input_fn
# Training and evaluation input functions.
train_input_fn = make_input_fn(dftrain, y_train)
eval_input_fn = make_input_fn(dfeval, y_eval, shuffle=False, n_epochs=1)
モデルをトレーニングして評価する
以下のステップで行います。
- 特徴とハイパーパラメータを指定してモデルを初期化する。
train_input_fnを使用してモデルにトレーニングデータを与え、train関数を使用してモデルをトレーニングする。- 評価セット(この例では
dfevalDataFrame)を使用してモデルのパフォーマンスを評価する。予測値がy_eval配列のラベルと一致することを確認する。
ブースティング木モデルをトレーニングする前に、まず線形分類器(ロジスティック回帰モデル)をトレーニングしてみましょう。ベンチマークを確立するには、より単純なモデルから始めるのがベストプラクティスです。
linear_est = tf.estimator.LinearClassifier(feature_columns)
# Train model.
linear_est.train(train_input_fn, max_steps=100)
# Evaluation.
result = linear_est.evaluate(eval_input_fn)
clear_output()
print(pd.Series(result))
accuracy 0.765152 accuracy_baseline 0.625000 auc 0.832844 auc_precision_recall 0.789631 average_loss 0.478908 label/mean 0.375000 loss 0.478908 precision 0.703297 prediction/mean 0.350790 recall 0.646465 global_step 100.000000 dtype: float64
次に、ブースティング木モデルをトレーニングしてみましょう。ブースティング木では、回帰(BoostedTreesRegressor)と分類(BoostedTreesClassifier)をサポートします。目標は、生存か非生存かのクラスを予測することなので、BoostedTreesClassifierを使用します。
# Since data fits into memory, use entire dataset per layer. It will be faster.
# Above one batch is defined as the entire dataset.
n_batches = 1
est = tf.estimator.BoostedTreesClassifier(feature_columns,
n_batches_per_layer=n_batches)
# The model will stop training once the specified number of trees is built, not
# based on the number of steps.
est.train(train_input_fn, max_steps=100)
# Eval.
result = est.evaluate(eval_input_fn)
clear_output()
print(pd.Series(result))
accuracy 0.837121 accuracy_baseline 0.625000 auc 0.871993 auc_precision_recall 0.858760 average_loss 0.406563 label/mean 0.375000 loss 0.406563 precision 0.797872 prediction/mean 0.384452 recall 0.757576 global_step 100.000000 dtype: float64
このトレーニングモデルを使用して、評価セットからある乗船者に予測を立てることができます。TensorFlow モデルは、バッチ、コレクション、または例に対してまとめて予測を立てられるように最適化されています。以前は、eval_input_fn は評価セット全体を使って定義されていました。
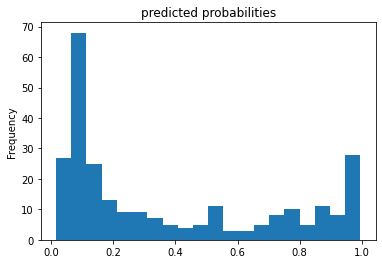
pred_dicts = list(est.predict(eval_input_fn))
probs = pd.Series([pred['probabilities'][1] for pred in pred_dicts])
probs.plot(kind='hist', bins=20, title='predicted probabilities')
plt.show()
INFO:tensorflow:Calling model_fn. INFO:tensorflow:Done calling model_fn. INFO:tensorflow:Graph was finalized. INFO:tensorflow:Restoring parameters from /tmp/tmpl84on_za/model.ckpt-100 INFO:tensorflow:Running local_init_op. INFO:tensorflow:Done running local_init_op.
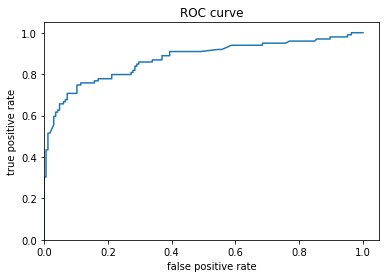
最後に、結果の受信者操作特性(ROC)を見てみましょう。真陽性率と偽陽性率間のトレードオフに関し、より明確な予想を得ることができます。
from sklearn.metrics import roc_curve
fpr, tpr, _ = roc_curve(y_eval, probs)
plt.plot(fpr, tpr)
plt.title('ROC curve')
plt.xlabel('false positive rate')
plt.ylabel('true positive rate')
plt.xlim(0,)
plt.ylim(0,)
plt.show()