GitHub でソースを表示 GitHub でソースを表示 |
警告: 新しいコードには Estimators は推奨されません。Estimators は
v1.Sessionスタイルのコードを実行しますが、これは正しく記述するのはより難しく、特に TF 2 コードと組み合わせると予期しない動作をする可能性があります。Estimators は、互換性保証の対象となりますが、セキュリティの脆弱性以外の修正は行われません。詳細については、移行ガイドを参照してください。
概要
このエンドツーエンドのウォークスルーでは、tf.estimator API を使用してロジスティック回帰モデルをトレーニングします。このモデルはほかのより複雑なアルゴリズムの基準としてよく使用されます。
注意: Keras によるロジスティック回帰の例はこちらからご覧いただけます。これは、本チュートリアルよりも推奨されます。
セットアップ
pip install sklearnimport os
import sys
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from IPython.display import clear_output
from six.moves import urllib
Titanic データセットを読み込む
Titanic データセットを使用して、性別、年齢、船室クラスなどの特性に基づき、(やや悪趣味ではありますが)乗船者の生存を予測することを目標とします。
import tensorflow.compat.v2.feature_column as fc
import tensorflow as tf
2024-01-11 21:53:58.890761: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered 2024-01-11 21:53:58.890806: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered 2024-01-11 21:53:58.892379: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
# Load dataset.
dftrain = pd.read_csv('https://storage.googleapis.com/tf-datasets/titanic/train.csv')
dfeval = pd.read_csv('https://storage.googleapis.com/tf-datasets/titanic/eval.csv')
y_train = dftrain.pop('survived')
y_eval = dfeval.pop('survived')
データを確認する
データセットには、次の特徴量が含まれます。
dftrain.head()
dftrain.describe()
トレーニングセットと評価セットには、それぞれ 627 個と 264 個の例があります。
dftrain.shape[0], dfeval.shape[0]
(627, 264)
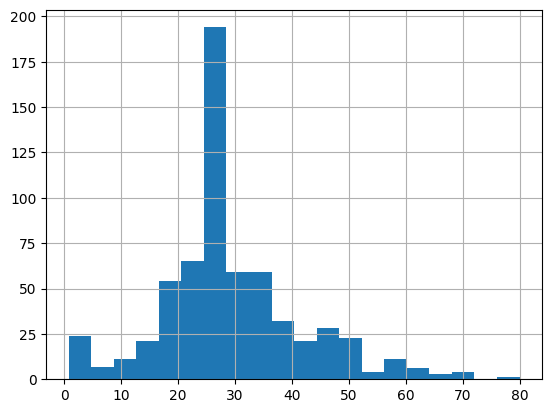
乗船者の大半は 20 代から 30 代です。
dftrain.age.hist(bins=20)
<Axes: >
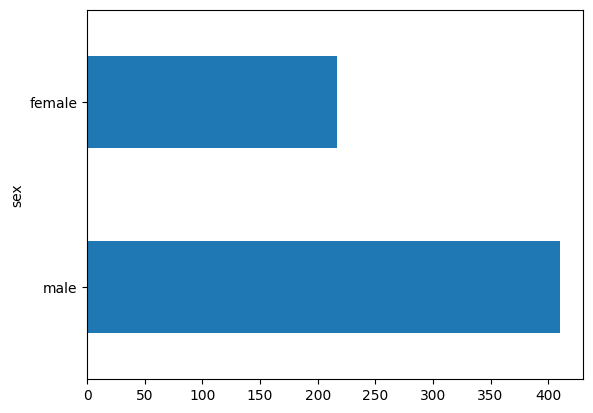
男性の乗船者数は女性の乗船者数の約 2 倍です。
dftrain.sex.value_counts().plot(kind='barh')
<Axes: ylabel='sex'>
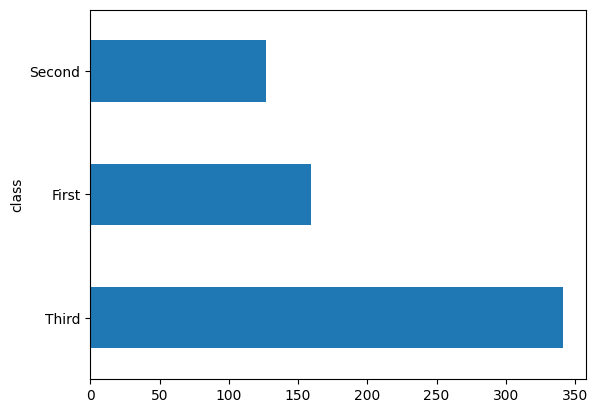
乗船者の大半は「3 等」の船室クラスを利用していました。
dftrain['class'].value_counts().plot(kind='barh')
<Axes: ylabel='class'>
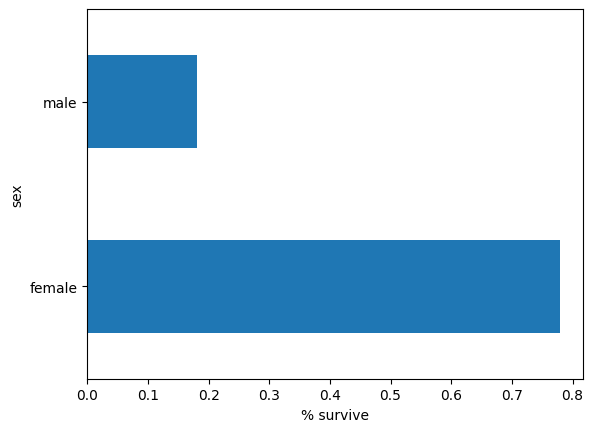
女性は男性よりも生存する確率がはるかに高く、これは明らかにモデルの予測特徴量です。
pd.concat([dftrain, y_train], axis=1).groupby('sex').survived.mean().plot(kind='barh').set_xlabel('% survive')
Text(0.5, 0, '% survive')
モデルの特徴量エンジニアリング
警告: このチュートリアルで説明されている tf.feature_columns モジュールは、新しいコードにはお勧めしません。Keras 前処理レイヤーがこの機能をカバーしています。移行手順については、特徴量カラムの移行ガイドをご覧ください。tf.feature_columns モジュールは、TF1 Estimators で使用するために設計されました。互換性保証の対象となりますが、セキュリティの脆弱性以外の修正は行われません。
Estimator は、モデルがどのように各行の入力特徴量を解釈すべきかを説明する特徴量カラムというシステムを使用しています。Estimator は数値入力のベクトルを期待しており、特徴量カラムにはモデルがどのように各特徴量を変換すべきかが記述されています。
効率的なモデルを学習するには、適切な特徴カラムの選択と作成が鍵となります。特徴量カラムは、元の特徴量 dict の生の入力の 1 つ(基本特徴量カラム)または 1 つ以上の基本カラムに定義された変換を使って作成された新規カラム(派生特徴量カラム)のいずれかです。
線形 Estimator は、数値特徴量とカテゴリカル特徴量の両方を利用します。特徴量カラムは TensorFlow Estimator と機能し、その目的はモデリングに使用される特徴量を定義することにあります。さらに、One-Hot エンコーディング、正規化、およびバケット化などのいくつかの特徴量エンジニアリング機能を提供します。
基本特徴量カラム
CATEGORICAL_COLUMNS = ['sex', 'n_siblings_spouses', 'parch', 'class', 'deck',
'embark_town', 'alone']
NUMERIC_COLUMNS = ['age', 'fare']
feature_columns = []
for feature_name in CATEGORICAL_COLUMNS:
vocabulary = dftrain[feature_name].unique()
feature_columns.append(tf.feature_column.categorical_column_with_vocabulary_list(feature_name, vocabulary))
for feature_name in NUMERIC_COLUMNS:
feature_columns.append(tf.feature_column.numeric_column(feature_name, dtype=tf.float32))
WARNING:tensorflow:From /tmpfs/tmp/ipykernel_978618/567449645.py:8: categorical_column_with_vocabulary_list (from tensorflow.python.feature_column.feature_column_v2) is deprecated and will be removed in a future version. Instructions for updating: Use Keras preprocessing layers instead, either directly or via the `tf.keras.utils.FeatureSpace` utility. Each of `tf.feature_column.*` has a functional equivalent in `tf.keras.layers` for feature preprocessing when training a Keras model. WARNING:tensorflow:From /tmpfs/tmp/ipykernel_978618/567449645.py:11: numeric_column (from tensorflow.python.feature_column.feature_column_v2) is deprecated and will be removed in a future version. Instructions for updating: Use Keras preprocessing layers instead, either directly or via the `tf.keras.utils.FeatureSpace` utility. Each of `tf.feature_column.*` has a functional equivalent in `tf.keras.layers` for feature preprocessing when training a Keras model.
input_function は、入力パイプラインをストリーミングの手法でフィードする tf.data.Dataset にデータを変換する方法を指定します。tf.data.Dataset は、dataframe や csv 形式ファイルなど、複数のソースを取ることができます。
def make_input_fn(data_df, label_df, num_epochs=10, shuffle=True, batch_size=32):
def input_function():
ds = tf.data.Dataset.from_tensor_slices((dict(data_df), label_df))
if shuffle:
ds = ds.shuffle(1000)
ds = ds.batch(batch_size).repeat(num_epochs)
return ds
return input_function
train_input_fn = make_input_fn(dftrain, y_train)
eval_input_fn = make_input_fn(dfeval, y_eval, num_epochs=1, shuffle=False)
次のようにデータセットを検査できます。
ds = make_input_fn(dftrain, y_train, batch_size=10)()
for feature_batch, label_batch in ds.take(1):
print('Some feature keys:', list(feature_batch.keys()))
print()
print('A batch of class:', feature_batch['class'].numpy())
print()
print('A batch of Labels:', label_batch.numpy())
Some feature keys: ['sex', 'age', 'n_siblings_spouses', 'parch', 'fare', 'class', 'deck', 'embark_town', 'alone'] A batch of class: [b'Second' b'Third' b'Third' b'Third' b'First' b'Third' b'Second' b'Third' b'Third' b'First'] A batch of Labels: [1 0 0 0 1 1 0 0 0 1]
また、tf.keras.layers.DenseFeatures レイヤーを使用して、特定の特徴量カラムの結果を検査することもできます。
age_column = feature_columns[7]
tf.keras.layers.DenseFeatures([age_column])(feature_batch).numpy()
array([[ 3.],
[21.],
[32.],
[59.],
[44.],
[ 4.],
[24.],
[10.],
[28.],
[28.]], dtype=float32)
DenseFeatures は密なテンソルのみを受け入れ、それを最初にインジケータカラムに変換する必要のあるカテゴリカラムを検査します。
gender_column = feature_columns[0]
tf.keras.layers.DenseFeatures([tf.feature_column.indicator_column(gender_column)])(feature_batch).numpy()
WARNING:tensorflow:From /tmpfs/tmp/ipykernel_978618/1523458592.py:2: indicator_column (from tensorflow.python.feature_column.feature_column_v2) is deprecated and will be removed in a future version.
Instructions for updating:
Use Keras preprocessing layers instead, either directly or via the `tf.keras.utils.FeatureSpace` utility. Each of `tf.feature_column.*` has a functional equivalent in `tf.keras.layers` for feature preprocessing when training a Keras model.
array([[1., 0.],
[1., 0.],
[0., 1.],
[1., 0.],
[0., 1.],
[0., 1.],
[1., 0.],
[1., 0.],
[0., 1.],
[0., 1.]], dtype=float32)
すべての基本特徴量をモデルに追加したら、モデルをトレーニングすることにしましょう。モデルのトレーニングは、 tf.estimator API を使ってコマンド 1 つで行います。
linear_est = tf.estimator.LinearClassifier(feature_columns=feature_columns)
linear_est.train(train_input_fn)
result = linear_est.evaluate(eval_input_fn)
clear_output()
print(result)
{'accuracy': 0.7386364, 'accuracy_baseline': 0.625, 'auc': 0.8361494, 'auc_precision_recall': 0.78821784, 'average_loss': 0.47708422, 'label/mean': 0.375, 'loss': 0.47104964, 'precision': 0.64705884, 'prediction/mean': 0.3915048, 'recall': 0.6666667, 'global_step': 200}
派生特徴量カラム
精度が 75% に達しました。それぞれの基本特徴量カラムを個別に使用しても、データを説明するには不足している場合があります。たとえば、年齢とラベルの間の相関関係は、性別が変われば異なることがあります。そのため、gender="Male" と gender="Female" で単一モデルの重みのみを把握しただけでは、すべての年齢と性別の組み合わせをキャプチャすることはできません(gender="Male" と age="30" と gender="Male" と age="40" を区別するなど)。
さまざまな特徴量の組み合わせの間の違いを把握するには、相互特徴量カラムをモデルに追加できます(また、相互カラムの前に年齢カラムをバケット化できます)。
age_x_gender = tf.feature_column.crossed_column(['age', 'sex'], hash_bucket_size=100)
WARNING:tensorflow:From /tmpfs/tmp/ipykernel_978618/476100734.py:1: crossed_column (from tensorflow.python.feature_column.feature_column_v2) is deprecated and will be removed in a future version. Instructions for updating: Use `tf.keras.layers.experimental.preprocessing.HashedCrossing` instead for feature crossing when preprocessing data to train a Keras model.
組み合わせた特徴量をモデルに追加したら、モデルをもう一度トレーニングしましょう。
derived_feature_columns = [age_x_gender]
linear_est = tf.estimator.LinearClassifier(feature_columns=feature_columns+derived_feature_columns)
linear_est.train(train_input_fn)
result = linear_est.evaluate(eval_input_fn)
clear_output()
print(result)
{'accuracy': 0.7462121, 'accuracy_baseline': 0.625, 'auc': 0.8426691, 'auc_precision_recall': 0.79368746, 'average_loss': 0.47478184, 'label/mean': 0.375, 'loss': 0.46697915, 'precision': 0.6666667, 'prediction/mean': 0.40963757, 'recall': 0.64646465, 'global_step': 200}
これで、77.6% の精度に達しました。基本特徴量のみでトレーニングした場合よりわずかに改善されています。ほかの特徴量と変換を使用して、さらに改善されるか確認してみましょう!
このトレーニングモデルを使用して、評価セットからある乗船者に予測を立てることができます。TensorFlow モデルは、バッチ、コレクション、または例に対してまとめて予測を立てられるように最適化されています。以前は、eval_input_fn は評価セット全体を使って定義されていました。
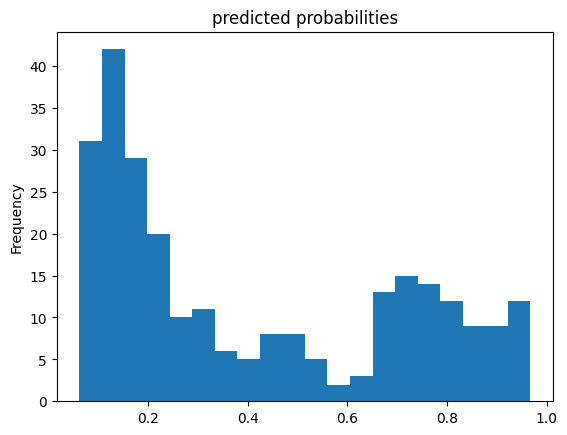
pred_dicts = list(linear_est.predict(eval_input_fn))
probs = pd.Series([pred['probabilities'][1] for pred in pred_dicts])
probs.plot(kind='hist', bins=20, title='predicted probabilities')
INFO:tensorflow:Calling model_fn.
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow_estimator/python/estimator/head/base_head.py:786: ClassificationOutput.__init__ (from tensorflow.python.saved_model.model_utils.export_output) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.keras instead.
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow_estimator/python/estimator/head/binary_class_head.py:561: RegressionOutput.__init__ (from tensorflow.python.saved_model.model_utils.export_output) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.keras instead.
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow_estimator/python/estimator/head/binary_class_head.py:563: PredictOutput.__init__ (from tensorflow.python.saved_model.model_utils.export_output) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.keras instead.
INFO:tensorflow:Done calling model_fn.
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Restoring parameters from /tmpfs/tmp/tmpsa7vq6kw/model.ckpt-200
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
<Axes: title={'center': 'predicted probabilities'}, ylabel='Frequency'>
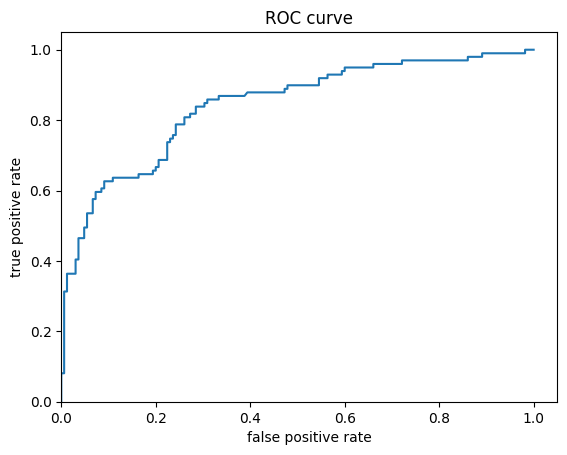
最後に、結果の受信者操作特性(ROC)を見てみましょう。真陽性率と偽陽性率間のトレードオフに関し、より明確な予想を得ることができます。
from sklearn.metrics import roc_curve
from matplotlib import pyplot as plt
fpr, tpr, _ = roc_curve(y_eval, probs)
plt.plot(fpr, tpr)
plt.title('ROC curve')
plt.xlabel('false positive rate')
plt.ylabel('true positive rate')
plt.xlim(0,)
plt.ylim(0,)
(0.0, 1.05)