
| | |  Visualizza l'origine su GitHub Visualizza l'origine su GitHub | |
Differenziazione automatica e gradienti
La differenziazione automatica è utile per implementare algoritmi di apprendimento automatico come la backpropagation per l'addestramento di reti neurali.
In questa guida esplorerai i modi per calcolare i gradienti con TensorFlow, specialmente nell'esecuzione ansiosa .
Impostare
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
Calcolo dei gradienti
Per differenziare automaticamente, TensorFlow deve ricordare quali operazioni avvengono in quale ordine durante il passaggio in avanti . Quindi, durante il passaggio all'indietro , TensorFlow attraversa questo elenco di operazioni in ordine inverso per calcolare i gradienti.
Nastri sfumati
TensorFlow fornisce l'API tf.GradientTape per la differenziazione automatica; ovvero calcolare il gradiente di un calcolo rispetto ad alcuni input, solitamente tf.Variable s. TensorFlow "registra" le operazioni rilevanti eseguite all'interno del contesto di un tf.GradientTape su un "nastro". TensorFlow utilizza quindi quel nastro per calcolare i gradienti di un calcolo "registrato" utilizzando la differenziazione in modalità inversa .
Qui c'è un semplice esempio:
x = tf.Variable(3.0)
with tf.GradientTape() as tape:
y = x**2
Dopo aver registrato alcune operazioni, utilizzare GradientTape.gradient(target, sources) per calcolare il gradiente di alcuni target (spesso una perdita) rispetto ad alcune sorgenti (spesso le variabili del modello):
# dy = 2x * dx
dy_dx = tape.gradient(y, x)
dy_dx.numpy()
6.0
L'esempio sopra usa scalari, ma tf.GradientTape funziona altrettanto facilmente su qualsiasi tensore:
w = tf.Variable(tf.random.normal((3, 2)), name='w')
b = tf.Variable(tf.zeros(2, dtype=tf.float32), name='b')
x = [[1., 2., 3.]]
with tf.GradientTape(persistent=True) as tape:
y = x @ w + b
loss = tf.reduce_mean(y**2)
Per ottenere il gradiente di loss rispetto ad entrambe le variabili, è possibile passare entrambe come sorgenti al metodo del gradient . Il nastro è flessibile su come vengono passate le fonti e accetterà qualsiasi combinazione nidificata di elenchi o dizionari e restituirà il gradiente strutturato allo stesso modo (vedi tf.nest ).
[dl_dw, dl_db] = tape.gradient(loss, [w, b])
Il gradiente rispetto a ciascuna sorgente ha la forma della sorgente:
print(w.shape)
print(dl_dw.shape)
(3, 2) (3, 2)
Ecco di nuovo il calcolo del gradiente, questa volta passando un dizionario di variabili:
my_vars = {
'w': w,
'b': b
}
grad = tape.gradient(loss, my_vars)
grad['b']
<tf.Tensor: shape=(2,), dtype=float32, numpy=array([-1.6920902, -3.2363236], dtype=float32)>
Gradienti rispetto a un modello
È comune raccogliere tf.Variables in un tf.Module o in una delle sue sottoclassi ( layers.Layer , keras.Model ) per il checkpoint e l'esportazione .
Nella maggior parte dei casi, vorrai calcolare i gradienti rispetto alle variabili addestrabili di un modello. Poiché tutte le sottoclassi di tf.Module aggregano le loro variabili nella proprietà Module.trainable_variables , puoi calcolare questi gradienti in poche righe di codice:
layer = tf.keras.layers.Dense(2, activation='relu')
x = tf.constant([[1., 2., 3.]])
with tf.GradientTape() as tape:
# Forward pass
y = layer(x)
loss = tf.reduce_mean(y**2)
# Calculate gradients with respect to every trainable variable
grad = tape.gradient(loss, layer.trainable_variables)
for var, g in zip(layer.trainable_variables, grad):
print(f'{var.name}, shape: {g.shape}')
dense/kernel:0, shape: (3, 2) dense/bias:0, shape: (2,)
Controllare ciò che il nastro guarda
Il comportamento predefinito è registrare tutte le operazioni dopo l'accesso a una tf.Variable . Le ragioni di ciò sono:
- Il nastro deve sapere quali operazioni registrare nel passaggio in avanti per calcolare i gradienti nel passaggio all'indietro.
- Il nastro contiene riferimenti alle uscite intermedie, quindi non si desidera registrare operazioni non necessarie.
- Il caso d'uso più comune riguarda il calcolo del gradiente di una perdita rispetto a tutte le variabili addestrabili di un modello.
Ad esempio, quanto segue non riesce a calcolare un gradiente perché tf.Tensor non è "osservato" per impostazione predefinita e tf.Variable non è addestrabile:
# A trainable variable
x0 = tf.Variable(3.0, name='x0')
# Not trainable
x1 = tf.Variable(3.0, name='x1', trainable=False)
# Not a Variable: A variable + tensor returns a tensor.
x2 = tf.Variable(2.0, name='x2') + 1.0
# Not a variable
x3 = tf.constant(3.0, name='x3')
with tf.GradientTape() as tape:
y = (x0**2) + (x1**2) + (x2**2)
grad = tape.gradient(y, [x0, x1, x2, x3])
for g in grad:
print(g)
tf.Tensor(6.0, shape=(), dtype=float32) None None None
È possibile elencare le variabili osservate dal nastro utilizzando il metodo GradientTape.watched_variables :
[var.name for var in tape.watched_variables()]
['x0:0']
tf.GradientTape fornisce hook che danno all'utente il controllo su cosa è o non è guardato.
Per registrare i gradienti rispetto a un tf.Tensor , devi chiamare GradientTape.watch(x) :
x = tf.constant(3.0)
with tf.GradientTape() as tape:
tape.watch(x)
y = x**2
# dy = 2x * dx
dy_dx = tape.gradient(y, x)
print(dy_dx.numpy())
6.0
Al contrario, per disabilitare il comportamento predefinito di visualizzazione di tutti tf.Variables , impostare watch_accessed_variables=False durante la creazione del nastro gradiente. Questo calcolo utilizza due variabili, ma collega solo il gradiente per una delle variabili:
x0 = tf.Variable(0.0)
x1 = tf.Variable(10.0)
with tf.GradientTape(watch_accessed_variables=False) as tape:
tape.watch(x1)
y0 = tf.math.sin(x0)
y1 = tf.nn.softplus(x1)
y = y0 + y1
ys = tf.reduce_sum(y)
Poiché GradientTape.watch non è stato chiamato su x0 , non viene calcolato alcun gradiente rispetto ad esso:
# dys/dx1 = exp(x1) / (1 + exp(x1)) = sigmoid(x1)
grad = tape.gradient(ys, {'x0': x0, 'x1': x1})
print('dy/dx0:', grad['x0'])
print('dy/dx1:', grad['x1'].numpy())
dy/dx0: None dy/dx1: 0.9999546
Risultati intermedi
Puoi anche richiedere gradienti dell'output rispetto a valori intermedi calcolati all'interno del contesto tf.GradientTape .
x = tf.constant(3.0)
with tf.GradientTape() as tape:
tape.watch(x)
y = x * x
z = y * y
# Use the tape to compute the gradient of z with respect to the
# intermediate value y.
# dz_dy = 2 * y and y = x ** 2 = 9
print(tape.gradient(z, y).numpy())
18.0
Per impostazione predefinita, le risorse detenute da un GradientTape vengono rilasciate non appena viene chiamato il metodo GradientTape.gradient . Per calcolare più gradienti sullo stesso calcolo, crea un nastro gradiente con persistent=True . Ciò consente più chiamate al metodo gradient in quanto le risorse vengono rilasciate quando l'oggetto nastro viene raccolto in modo obsoleto. Per esempio:
x = tf.constant([1, 3.0])
with tf.GradientTape(persistent=True) as tape:
tape.watch(x)
y = x * x
z = y * y
print(tape.gradient(z, x).numpy()) # [4.0, 108.0] (4 * x**3 at x = [1.0, 3.0])
print(tape.gradient(y, x).numpy()) # [2.0, 6.0] (2 * x at x = [1.0, 3.0])
[ 4. 108.] [2. 6.]
del tape # Drop the reference to the tape
Note sulle prestazioni
C'è un piccolo sovraccarico associato all'esecuzione di operazioni all'interno di un contesto di nastro sfumato. Per l'esecuzione più ansiosa questo non sarà un costo notevole, ma dovresti comunque usare il contesto del nastro attorno alle aree solo dove è richiesto.
I nastri a gradiente utilizzano la memoria per memorizzare i risultati intermedi, inclusi input e output, da utilizzare durante il passaggio all'indietro.
Per efficienza, alcune operazioni (come
ReLU) non hanno bisogno di mantenere i loro risultati intermedi e vengono eliminate durante il passaggio in avanti. Tuttavia, se si utilizzapersistent=Truesul nastro, nulla viene scartato e il picco di utilizzo della memoria sarà maggiore.
Gradienti di target non scalari
Un gradiente è fondamentalmente un'operazione su uno scalare.
x = tf.Variable(2.0)
with tf.GradientTape(persistent=True) as tape:
y0 = x**2
y1 = 1 / x
print(tape.gradient(y0, x).numpy())
print(tape.gradient(y1, x).numpy())
4.0 -0.25
Pertanto, se si richiede il gradiente di più target, il risultato per ciascuna sorgente è:
- Il gradiente della somma degli obiettivi, o in modo equivalente
- La somma dei gradienti di ciascun target.
x = tf.Variable(2.0)
with tf.GradientTape() as tape:
y0 = x**2
y1 = 1 / x
print(tape.gradient({'y0': y0, 'y1': y1}, x).numpy())
3.75
Allo stesso modo, se i target non sono scalari, viene calcolato il gradiente della somma:
x = tf.Variable(2.)
with tf.GradientTape() as tape:
y = x * [3., 4.]
print(tape.gradient(y, x).numpy())
7.0
Questo rende semplice prendere il gradiente della somma di una raccolta di perdite, o il gradiente della somma di un calcolo delle perdite a livello di elemento.
Se hai bisogno di una sfumatura separata per ogni elemento, fai riferimento a Jacobians .
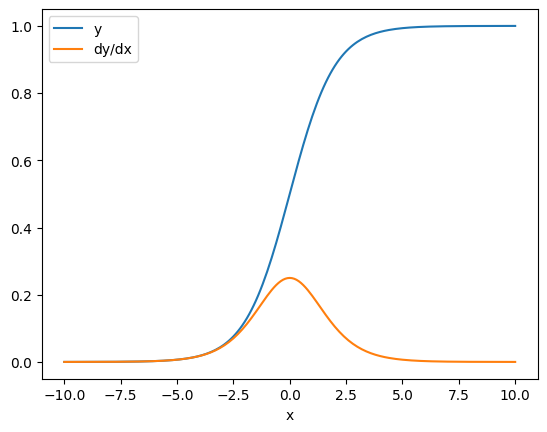
In alcuni casi puoi saltare il Jacobiano. Per un calcolo a livello di elemento, il gradiente della somma fornisce la derivata di ciascun elemento rispetto al suo elemento di input, poiché ogni elemento è indipendente:
x = tf.linspace(-10.0, 10.0, 200+1)
with tf.GradientTape() as tape:
tape.watch(x)
y = tf.nn.sigmoid(x)
dy_dx = tape.gradient(y, x)
plt.plot(x, y, label='y')
plt.plot(x, dy_dx, label='dy/dx')
plt.legend()
_ = plt.xlabel('x')
Flusso di controllo
Poiché un nastro gradiente registra le operazioni mentre vengono eseguite, il flusso di controllo Python viene gestito naturalmente (ad esempio, istruzioni if e while ).
Qui viene utilizzata una variabile diversa su ogni ramo di un if . Il gradiente si collega solo alla variabile che è stata utilizzata:
x = tf.constant(1.0)
v0 = tf.Variable(2.0)
v1 = tf.Variable(2.0)
with tf.GradientTape(persistent=True) as tape:
tape.watch(x)
if x > 0.0:
result = v0
else:
result = v1**2
dv0, dv1 = tape.gradient(result, [v0, v1])
print(dv0)
print(dv1)
tf.Tensor(1.0, shape=(), dtype=float32) None
Ricorda solo che le istruzioni di controllo stesse non sono differenziabili, quindi sono invisibili agli ottimizzatori basati su gradiente.
A seconda del valore di x nell'esempio sopra, il nastro registra result = v0 o result = v1**2 . Il gradiente rispetto a x è sempre None .
dx = tape.gradient(result, x)
print(dx)
None
Ottenere un gradiente di None
Quando un target non è connesso a una sorgente, otterrai un gradiente di None .
x = tf.Variable(2.)
y = tf.Variable(3.)
with tf.GradientTape() as tape:
z = y * y
print(tape.gradient(z, x))
None
Qui z ovviamente non è connesso a x , ma ci sono molti modi meno ovvi per disconnettere un gradiente.
1. Sostituita una variabile con un tensore
Nella sezione su "controllo di ciò che il nastro guarda" hai visto che il nastro guarderà automaticamente una tf.Variable ma non un tf.Tensor .
Un errore comune consiste nel sostituire inavvertitamente una tf.Variable con una tf.Tensor , invece di usare Variable.assign per aggiornare la tf.Variable . Ecco un esempio:
x = tf.Variable(2.0)
for epoch in range(2):
with tf.GradientTape() as tape:
y = x+1
print(type(x).__name__, ":", tape.gradient(y, x))
x = x + 1 # This should be `x.assign_add(1)`
ResourceVariable : tf.Tensor(1.0, shape=(), dtype=float32) EagerTensor : None
2. Ha eseguito calcoli al di fuori di TensorFlow
Il nastro non può registrare il percorso del gradiente se il calcolo esce da TensorFlow. Per esempio:
x = tf.Variable([[1.0, 2.0],
[3.0, 4.0]], dtype=tf.float32)
with tf.GradientTape() as tape:
x2 = x**2
# This step is calculated with NumPy
y = np.mean(x2, axis=0)
# Like most ops, reduce_mean will cast the NumPy array to a constant tensor
# using `tf.convert_to_tensor`.
y = tf.reduce_mean(y, axis=0)
print(tape.gradient(y, x))
None
3. Ha preso i gradienti attraverso un numero intero o una stringa
Interi e stringhe non sono differenziabili. Se un percorso di calcolo utilizza questi tipi di dati non ci sarà alcun gradiente.
Nessuno si aspetta che le stringhe siano differenziabili, ma è facile creare accidentalmente una costante o una variabile int se non specifichi dtype .
x = tf.constant(10)
with tf.GradientTape() as g:
g.watch(x)
y = x * x
print(g.gradient(y, x))
WARNING:tensorflow:The dtype of the watched tensor must be floating (e.g. tf.float32), got tf.int32 WARNING:tensorflow:The dtype of the target tensor must be floating (e.g. tf.float32) when calling GradientTape.gradient, got tf.int32 WARNING:tensorflow:The dtype of the source tensor must be floating (e.g. tf.float32) when calling GradientTape.gradient, got tf.int32 None
TensorFlow non esegue automaticamente il cast tra i tipi, quindi, in pratica, riceverai spesso un errore di tipo invece di un gradiente mancante.
4. Ha preso i gradienti attraverso un oggetto con stato
Lo stato interrompe i gradienti. Quando leggi da un oggetto con stato, il nastro può osservare solo lo stato corrente, non la cronologia che lo porta.
Un tf.Tensor è immutabile. Non puoi cambiare un tensore una volta creato. Ha un valore , ma non uno stato . Anche tutte le operazioni discusse finora sono stateless: l'output di un tf.matmul dipende solo dai suoi input.
Una tf.Variable ha uno stato interno, il suo valore. Quando si utilizza la variabile, viene letto lo stato. È normale calcolare un gradiente rispetto a una variabile, ma lo stato della variabile impedisce ai calcoli del gradiente di tornare più indietro. Per esempio:
x0 = tf.Variable(3.0)
x1 = tf.Variable(0.0)
with tf.GradientTape() as tape:
# Update x1 = x1 + x0.
x1.assign_add(x0)
# The tape starts recording from x1.
y = x1**2 # y = (x1 + x0)**2
# This doesn't work.
print(tape.gradient(y, x0)) #dy/dx0 = 2*(x1 + x0)
None
Allo stesso modo, gli iteratori tf.data.Dataset e tf.queue s sono stateful e interromperanno tutti i gradienti sui tensori che li attraversano.
Nessun gradiente registrato
Alcune tf.Operation sono registrate come non differenziabili e restituiranno None . Altri non hanno gradiente registrato .
La pagina tf.raw_ops mostra quali operazioni di basso livello hanno gradienti registrati.
Se si tenta di acquisire una sfumatura tramite un'operazione float che non ha alcuna sfumatura registrata, il nastro genererà un errore invece di restituire silenziosamente None . In questo modo sai che qualcosa è andato storto.
Ad esempio, la funzione tf.image.adjust_contrast il wrapping raw_ops.AdjustContrastv2 , che potrebbe avere un gradiente ma il gradiente non è implementato:
image = tf.Variable([[[0.5, 0.0, 0.0]]])
delta = tf.Variable(0.1)
with tf.GradientTape() as tape:
new_image = tf.image.adjust_contrast(image, delta)
try:
print(tape.gradient(new_image, [image, delta]))
assert False # This should not happen.
except LookupError as e:
print(f'{type(e).__name__}: {e}')
LookupError: gradient registry has no entry for: AdjustContrastv2
Se devi differenziare attraverso questa operazione, dovrai implementare il gradiente e registrarlo (usando tf.RegisterGradient ) o implementare nuovamente la funzione usando altre operazioni.
Zero invece di Nessuno
In alcuni casi sarebbe conveniente ottenere 0 invece di None per gradienti non collegati. Puoi decidere cosa restituire quando hai gradienti non collegati usando l'argomento unconnected_gradients :
x = tf.Variable([2., 2.])
y = tf.Variable(3.)
with tf.GradientTape() as tape:
z = y**2
print(tape.gradient(z, x, unconnected_gradients=tf.UnconnectedGradients.ZERO))
tf.Tensor([0. 0.], shape=(2,), dtype=float32)