
Bu kılavuz, TensorFlow modellerinizin performansını izlemek için TensorFlow Profiler'da bulunan araçların nasıl kullanılacağını gösterir. Modelinizin ana bilgisayarda (CPU), cihazda (GPU) veya hem ana bilgisayar hem de aygıtların birleşiminde nasıl performans gösterdiğini nasıl anlayacağınızı öğreneceksiniz.
Profil oluşturma, modelinizdeki çeşitli TensorFlow işlemlerinin (ops) donanım kaynağı tüketimini (zaman ve bellek) anlamanıza, performans darboğazlarını çözmenize ve sonuç olarak modelin daha hızlı yürütülmesine yardımcı olur.
Bu kılavuz, Profiler'ın nasıl kurulacağı, mevcut çeşitli araçlar, Profiler'ın performans verilerini nasıl topladığına ilişkin farklı modlar ve model performansını optimize etmek için önerilen bazı en iyi uygulamalar konusunda size yol gösterecektir.
Cloud TPU'larda model performansınızın profilini çıkarmak istiyorsanız Cloud TPU kılavuzuna bakın.
Profiler ve GPU önkoşullarını yükleyin
TensorBoard için Profiler eklentisini pip ile yükleyin. Profiler'ın TensorFlow ve TensorBoard'un en son sürümlerini (>=2.2) gerektirdiğini unutmayın.
pip install -U tensorboard_plugin_profile
GPU'da profil oluşturmak için şunları yapmanız gerekir:
- TensorFlow GPU destek yazılımı gereksinimlerinde listelenen NVIDIA® GPU sürücüleri ve CUDA® Araç Seti gereksinimlerini karşılayın.
Yolda NVIDIA® CUDA® Profil Oluşturma Araçları Arayüzünün (CUPTI) mevcut olduğundan emin olun:
/sbin/ldconfig -N -v $(sed 's/:/ /g' <<< $LD_LIBRARY_PATH) | \ grep libcupti
Yolda CUPTI yoksa, aşağıdakileri çalıştırarak kurulum dizinini $LD_LIBRARY_PATH ortam değişkeninin başına ekleyin:
export LD_LIBRARY_PATH=/usr/local/cuda/extras/CUPTI/lib64:$LD_LIBRARY_PATH
Daha sonra CUPTI kütüphanesinin bulunduğunu doğrulamak için yukarıdaki ldconfig komutunu tekrar çalıştırın.
Ayrıcalık sorunlarını çözme
Docker ortamında veya Linux'ta CUDA® Toolkit ile profil oluşturmayı çalıştırdığınızda, yetersiz CUPTI ayrıcalıklarıyla ( CUPTI_ERROR_INSUFFICIENT_PRIVILEGES ) ilgili sorunlarla karşılaşabilirsiniz. Linux'ta bu sorunları nasıl çözebileceğiniz hakkında daha fazla bilgi edinmek için NVIDIA Geliştirici Dokümanlarına gidin.
Docker ortamında CUPTI ayrıcalığı sorunlarını çözmek için şunu çalıştırın:
docker run option '--privileged=true'
Profil oluşturma araçları
Profiler'a, yalnızca bazı model verilerini yakaladıktan sonra görünen TensorBoard'daki Profil sekmesinden erişin.
Profiler'da performans analizine yardımcı olacak çeşitli araçlar bulunur:
- Genel Bakış Sayfası
- Giriş Boru Hattı Analizörü
- TensorFlow İstatistikleri
- İz Görüntüleyici
- GPU Çekirdek İstatistikleri
- Bellek Profili Aracı
- Kapsül Görüntüleyici
Genel bakış sayfası
Genel bakış sayfası, modelinizin bir profil çalıştırması sırasında nasıl performans gösterdiğine ilişkin üst düzey bir görünüm sağlar. Sayfada, ana makineniz ve tüm cihazlarınız için toplu bir genel bakış sayfası ve model eğitimi performansınızı iyileştirmeye yönelik bazı öneriler gösterilir. Ayrıca Ana Bilgisayar açılır menüsünden tek tek ana bilgisayarları da seçebilirsiniz.
Genel bakış sayfası verileri aşağıdaki gibi görüntüler:
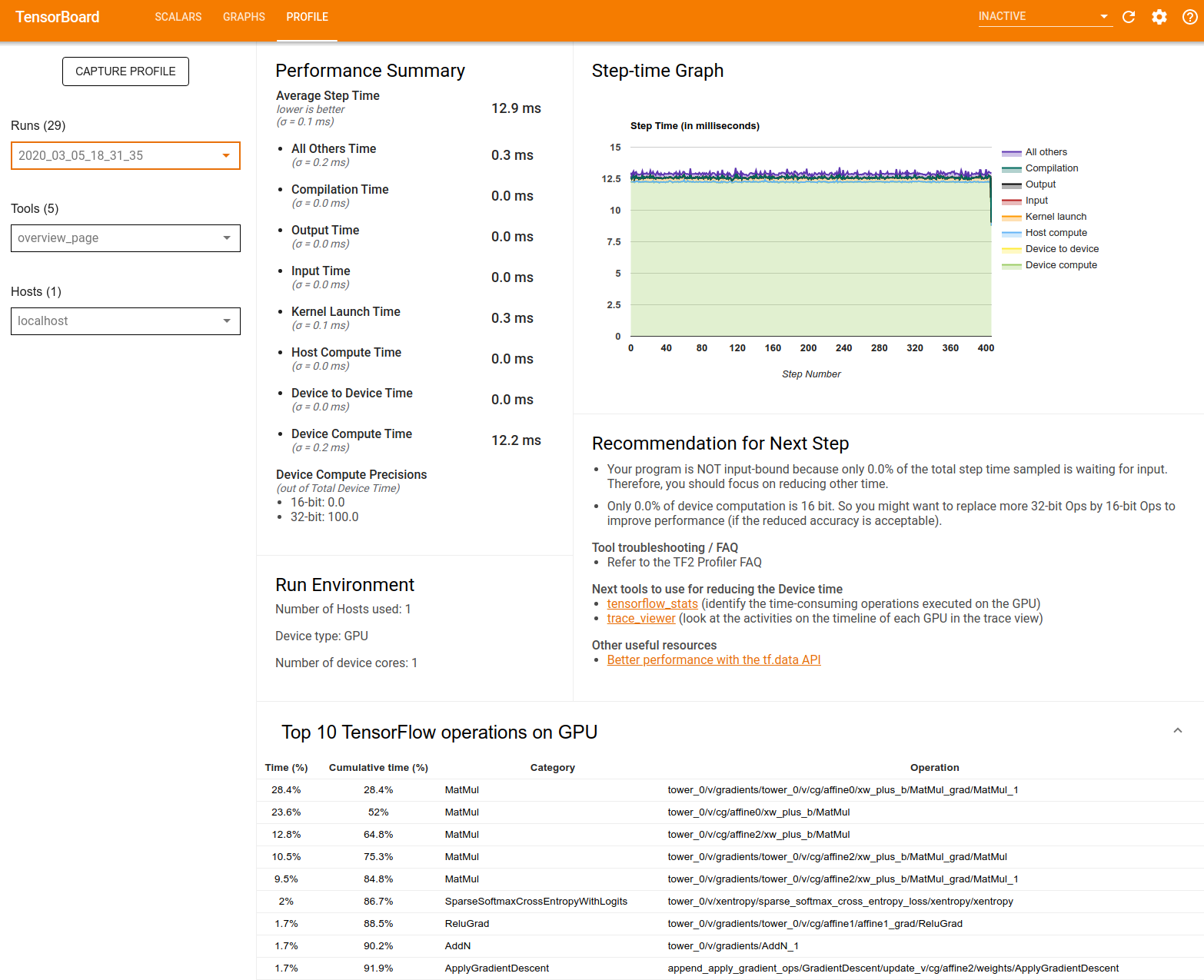
Performans Özeti : Model performansınızın üst düzey bir özetini görüntüler. Performans özeti iki bölümden oluşur:
Adım zamanı dökümü: Ortalama adım süresini, zamanın harcandığı yere göre birden fazla kategoriye ayırır:
- Derleme: Çekirdekleri derlemek için harcanan zaman.
- Giriş: Giriş verilerini okumak için harcanan süre.
- Çıktı: Çıktı verilerini okumak için harcanan süre.
- Çekirdek lansmanı: Ana bilgisayarın çekirdekleri başlatmak için harcadığı süre
- Ana bilgisayar hesaplama süresi..
- Cihazdan cihaza iletişim süresi.
- Cihaz üzerinde işlem süresi.
- Python yükü de dahil olmak üzere diğerleri.
Cihaz işlem hassasiyetleri - 16 ve 32 bit hesaplamaları kullanan cihaz işlem süresinin yüzdesini bildirir.
Adım Zamanı Grafiği : Örneklenen tüm adımlar üzerinden cihazın adım süresinin (milisaniye cinsinden) bir grafiğini görüntüler. Her adım, zamanın harcandığı yere göre birden fazla kategoriye (farklı renklerle) bölünmüştür. Kırmızı alan, cihazların ana bilgisayardan giriş verilerini beklerken boşta kaldığı adım süresinin bir kısmına karşılık gelir. Yeşil alan, cihazın gerçekte ne kadar süre çalıştığını gösterir.
Cihazdaki en iyi 10 TensorFlow işlemi (örn. GPU) : En uzun süre çalışan cihaz üzerindeki işlemleri görüntüler.
Her satırda bir operasyonun kendi zamanı (tüm operasyonların harcadığı zamanın yüzdesi olarak), kümülatif süre, kategori ve ad görüntülenir.
Çalıştırma Ortamı : Aşağıdakileri içeren model çalıştırma ortamının üst düzey bir özetini görüntüler:
- Kullanılan ana bilgisayar sayısı.
- Cihaz türü (GPU/TPU).
- Cihaz çekirdeği sayısı.
Sonraki Adım İçin Öneri : Bir modelin girdiye bağlı olduğunu bildirir ve model performans darboğazlarını bulmak ve çözmek için kullanabileceğiniz araçları önerir.
Giriş hattı analizörü
Bir TensorFlow programı bir dosyadan veri okuduğunda, işlem hattı şeklinde TensorFlow grafiğinin en üstünden başlar. Okuma işlemi, seri olarak bağlanan birden fazla veri işleme aşamasına bölünmüştür; burada bir aşamanın çıktısı, bir sonraki aşamanın girdisidir. Bu veri okuma sistemine giriş hattı adı verilir.
Dosyalardan kayıtları okumaya yönelik tipik bir işlem hattı aşağıdaki aşamalardan oluşur:
- Dosya okuma.
- Dosya ön işleme (isteğe bağlı).
- Ana bilgisayardan cihaza dosya aktarımı.
Verimsiz bir giriş hattı uygulamanızı ciddi şekilde yavaşlatabilir. Bir uygulama, zamanın önemli bir kısmını giriş hattında geçirdiğinde giriş bağlantılı olarak kabul edilir. Giriş hattının hangi noktalarda verimsiz olduğunu anlamak için giriş kanalı analiz aracından elde edilen bilgileri kullanın.
Giriş hattı analizörü, programınızın girişe bağlı olup olmadığını anında bildirir ve giriş hattının herhangi bir aşamasında performans darboğazlarında hata ayıklamak için cihaz ve ana bilgisayar tarafı analizinde size yol gösterir.
Veri giriş işlem hatlarınızı optimize etmeye yönelik önerilen en iyi uygulamalar için giriş işlem hattı performansına ilişkin kılavuza bakın.
Giriş hattı kontrol paneli
Giriş hattı çözümleyicisini açmak için Profil'i seçin, ardından Araçlar açılır menüsünden input_pipeline_analyzer'ı seçin.
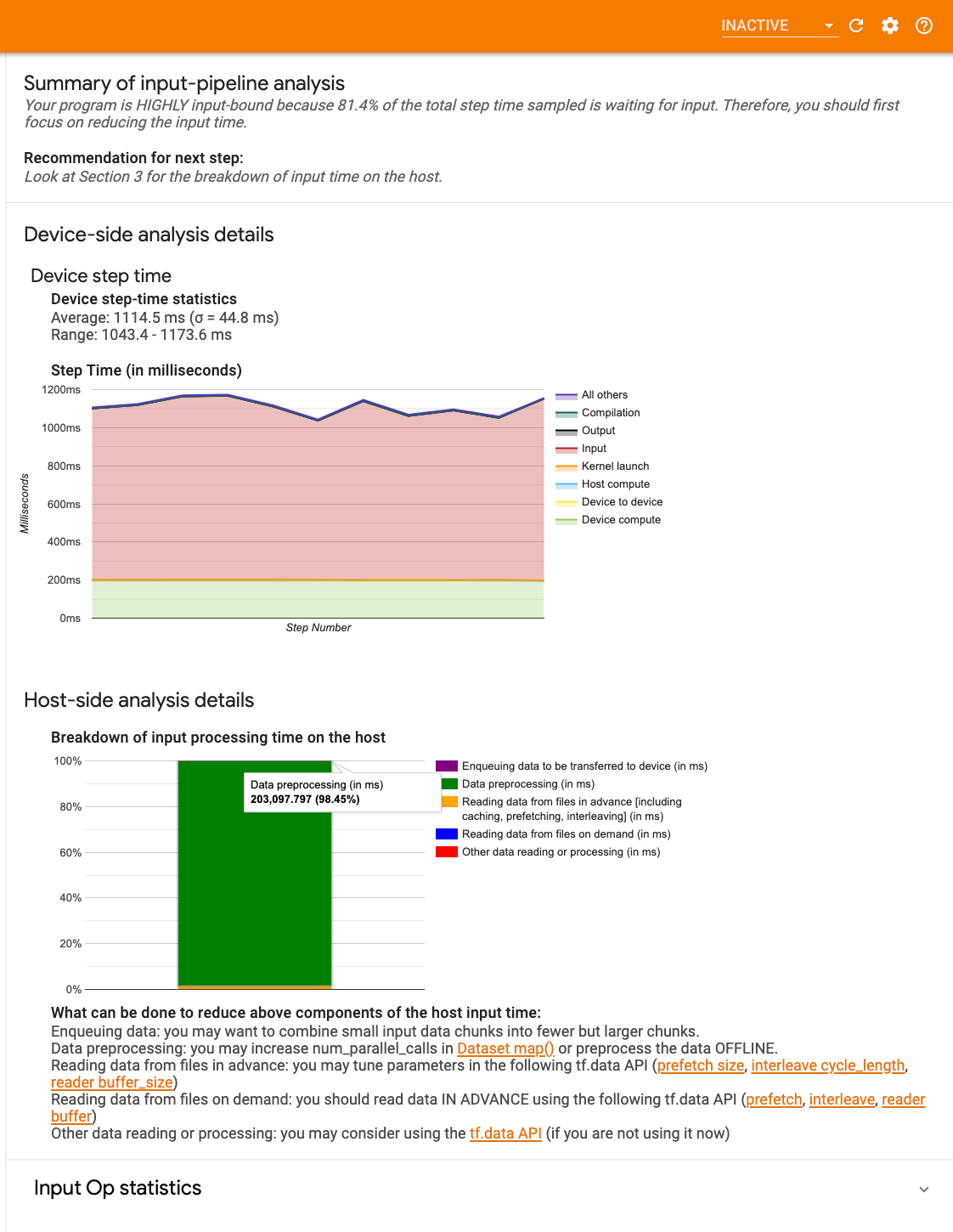
Kontrol panelinde üç bölüm bulunur:
- Özet : Uygulamanızın girdiye bağlı olup olmadığı ve eğer öyleyse ne kadar olduğuna ilişkin bilgilerle genel girdi hattını özetler.
- Cihaz tarafı analizi : Cihaz adım süresi ve her adımda çekirdekler arasında giriş verilerini beklerken harcanan cihaz süresi aralığı da dahil olmak üzere ayrıntılı cihaz tarafı analiz sonuçlarını görüntüler.
- Ana bilgisayar tarafı analizi : Ana bilgisayardaki giriş işleme süresinin dökümü de dahil olmak üzere, ana bilgisayar tarafında ayrıntılı bir analiz gösterir.
Giriş hattı özeti
Özet, ana bilgisayardan girişi beklerken harcanan cihaz süresinin yüzdesini sunarak programınızın girişe bağlı olup olmadığını bildirir. Araçlandırılmış standart bir girdi hattı kullanıyorsanız araç, girdi işleme süresinin çoğunun nerede harcandığını bildirir.
Cihaz tarafı analizi
Cihaz tarafı analizi, cihazda ve ana bilgisayarda harcanan zamana ve ana bilgisayardan giriş verileri beklenirken ne kadar cihaz süresinin harcandığına ilişkin bilgiler sağlar.
- Adım numarasına göre çizilen adım süresi : Örneklenen tüm adımlar üzerinden cihaz adım süresinin (milisaniye cinsinden) bir grafiğini görüntüler. Her adım, zamanın harcandığı yere göre birden fazla kategoriye (farklı renklerle) bölünmüştür. Kırmızı alan, cihazların ana bilgisayardan giriş verilerini beklerken boşta kaldığı adım süresinin bir kısmına karşılık gelir. Yeşil alan, cihazın gerçekte ne kadar süre çalıştığını gösterir.
- Adım süresi istatistikleri : Cihazın adım süresinin ortalamasını, standart sapmasını ve aralığını ([minimum, maksimum]) raporlar.
Ana makine tarafı analizi
Ana bilgisayar tarafı analizi, ana bilgisayardaki giriş işleme süresinin ( tf.data API işlemlerinde harcanan süre) birkaç kategoriye ayrıldığını rapor eder:
- Talep üzerine dosyalardan veri okuma : Önbelleğe alma, önceden getirme ve araya ekleme olmadan dosyalardan veri okumak için harcanan süre.
- Dosyalardaki verileri önceden okuma : Önbelleğe alma, önceden getirme ve araya ekleme dahil olmak üzere dosyaları okumak için harcanan süre.
- Veri ön işleme : Görüntü sıkıştırmasını açma gibi ön işleme operasyonlarında harcanan zaman.
- Cihaza aktarılacak verileri sıraya alma : Verileri cihaza aktarmadan önce verileri bir besleme kuyruğuna koymak için harcanan süre.
Bireysel giriş işlemlerine ilişkin istatistikleri ve yürütme süresine göre ayrılmış kategorilerini incelemek için Giriş Operasyonu İstatistikleri'ni genişletin.
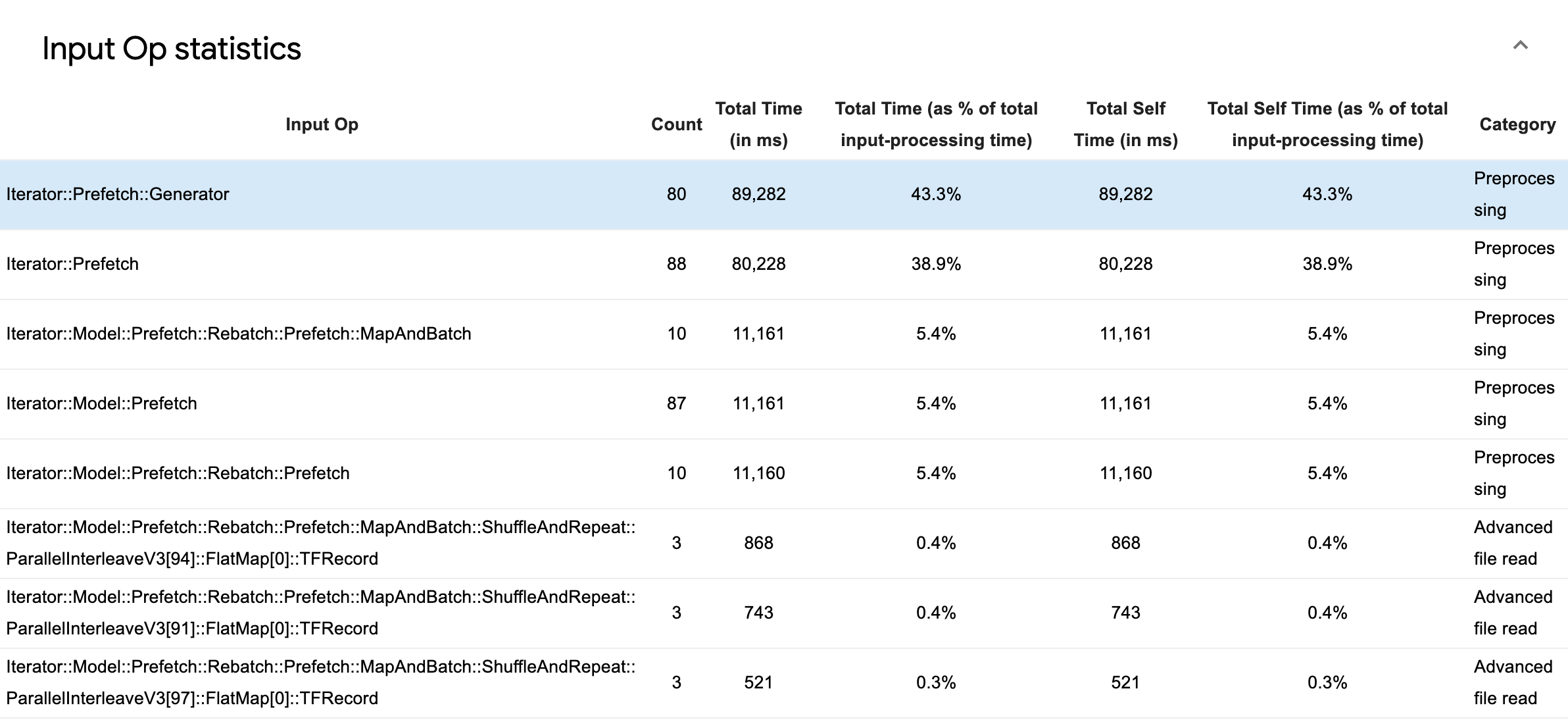
Her girişte aşağıdaki bilgileri içeren bir kaynak veri tablosu görünecektir:
- Giriş İşlemi : Giriş işleminin TensorFlow işlem adını gösterir.
- Sayım : Profil oluşturma dönemi boyunca op yürütme örneklerinin toplam sayısını gösterir.
- Toplam Süre (ms cinsinden) : Bu örneklerin her biri için harcanan toplam süreyi gösterir.
- Toplam Süre % : Bir operasyonda harcanan toplam süreyi, girdi işlemede harcanan toplam sürenin kesri olarak gösterir.
- Toplam Kişisel Zaman (ms cinsinden) : Bu örneklerin her birinde harcanan kişisel zamanın kümülatif toplamını gösterir. Buradaki kişisel zaman, çağırdığı işlevde harcanan süre hariç, işlev gövdesi içinde geçirilen süreyi ölçer.
- Toplam Zamanın Yüzdesi . Toplam kişisel zamanı, girdi işleme için harcanan toplam sürenin bir kısmı olarak gösterir.
- Kategori . Giriş işleminin işleme kategorisini gösterir.
TensorFlow istatistikleri
TensorFlow İstatistikleri aracı, bir profil oluşturma oturumu sırasında ana bilgisayar veya cihazda yürütülen her TensorFlow işleminin (op) performansını görüntüler.
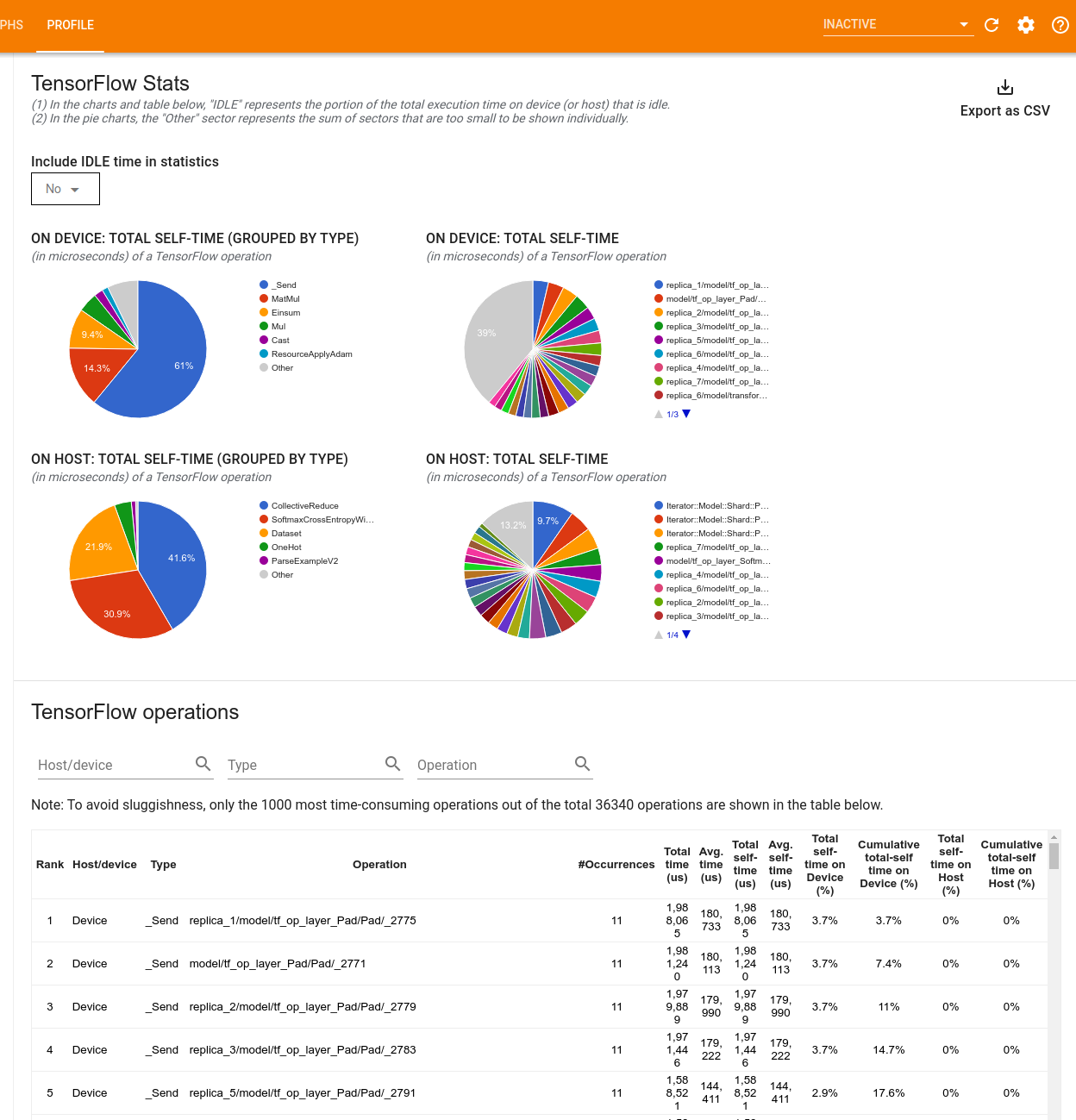
Araç, performans bilgilerini iki bölmede görüntüler:
Üst bölmede en fazla dört pasta grafik görüntülenir:
- Ana bilgisayardaki her işlemin kendi kendini yürütme süresinin dağılımı.
- Ana bilgisayardaki her işlem türünün kendi kendini yürütme süresinin dağılımı.
- Cihazdaki her bir işlemin kendi kendini yürütme süresinin dağılımı.
- Cihazdaki her işlem türünün kendi kendini yürütme süresinin dağılımı.
Alt bölmede, her işlem için bir satır ve her veri türü için bir sütun içeren TensorFlow işlemleri hakkındaki verileri raporlayan bir tablo gösterilir (sütunların başlığına tıklayarak sütunları sıralayın). Bu tablodaki verileri bir CSV dosyası olarak dışa aktarmak için üst bölmenin sağ tarafındaki CSV Olarak Dışa Aktar düğmesini tıklayın.
Dikkat:
Herhangi bir işlemin alt işlemleri varsa:
- Bir operasyonun toplam "birikmiş" süresi, alt operasyonlarda geçirilen süreyi de içerir.
- Bir operasyonun toplam "kendi" süresi, alt operasyonlarda harcanan zamanı içermez.
Ana bilgisayarda bir op yürütülürse:
- Opsiyonun cihazda harcadığı toplam zamanın yüzdesi 0 olacaktır.
- Bu operasyona kadar ve bu operasyon dahil olmak üzere cihazda geçirilen toplam zamanın kümülatif yüzdesi 0 olacaktır.
Cihazda bir operasyon yürütülürse:
- Bu operasyonun ana bilgisayar üzerinde harcadığı toplam zamanın yüzdesi 0 olacaktır.
- Bu operasyona kadar ve bu operasyon da dahil olmak üzere ana bilgisayardaki toplam kişisel zamanın kümülatif yüzdesi 0 olacaktır.
Pasta grafiklerine ve tabloya Boşta kalma süresini dahil etmeyi veya hariç tutmayı seçebilirsiniz.
İz görüntüleyici
İzleme görüntüleyici şunları gösteren bir zaman çizelgesi görüntüler:
- TensorFlow modeliniz tarafından gerçekleştirilen operasyonların süreleri
- Sistemin hangi kısmının (ana bilgisayar veya cihaz) bir işlem yürüttüğü. Tipik olarak, cihaz gerçek model eğitimini yürütürken, ana bilgisayar giriş işlemlerini yürütür, eğitim verilerini ön işler ve cihaza aktarır.
İzleme görüntüleyici, modelinizdeki performans sorunlarını tanımlamanıza ve ardından bunları çözmek için gerekli adımları atmanıza olanak tanır. Örneğin, yüksek düzeyde, zamanın çoğunu girdi eğitiminin mi yoksa model eğitiminin mi aldığını belirleyebilirsiniz. Detaylara inerek, hangi operasyonların yürütülmesinin en uzun sürdüğünü belirleyebilirsiniz. İzleme görüntüleyicinin cihaz başına 1 milyon olayla sınırlı olduğunu unutmayın.
İz görüntüleyici arayüzü
İzleme görüntüleyiciyi açtığınızda, en son çalıştırmanızı görüntüler:
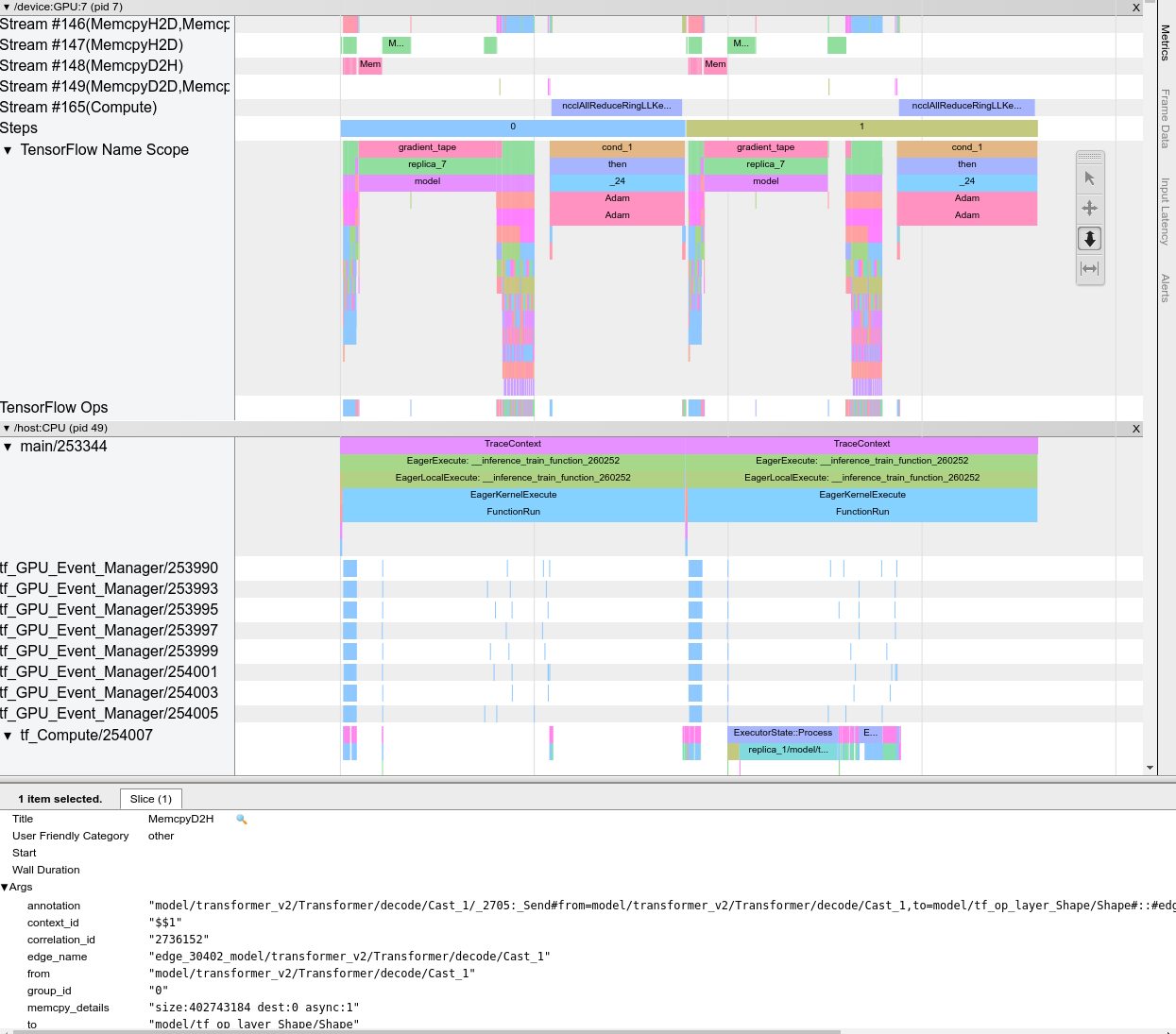
Bu ekran aşağıdaki ana unsurları içerir:
- Zaman çizelgesi bölmesi : Cihazın ve ana bilgisayarın zaman içinde yürüttüğü işlemleri gösterir.
- Ayrıntılar bölmesi : Zaman Çizelgesi bölmesinde seçilen işlemlere ilişkin ek bilgileri gösterir.
Zaman Çizelgesi bölmesi aşağıdaki öğeleri içerir:
- Üst çubuk : Çeşitli yardımcı kontrolleri içerir.
- Zaman ekseni : İzin başlangıcına göre zamanı gösterir.
- Bölüm ve parça etiketleri : Her bölüm birden fazla parça içerir ve solda bölümü genişletip daraltmak için tıklayabileceğiniz bir üçgen bulunur. Sistemde her işlem elemanı için bir bölüm bulunmaktadır.
- Araç seçici : Yakınlaştırma, Kaydırma, Seçme ve Zamanlama gibi iz görüntüleyiciyle etkileşime geçmek için çeşitli araçlar içerir. Bir zaman aralığını işaretlemek için Zamanlama aracını kullanın.
- Olaylar : Bunlar, bir operasyonun yürütüldüğü süreyi veya eğitim adımları gibi meta olayların süresini gösterir.
Bölümler ve parçalar
İzleme görüntüleyici aşağıdaki bölümleri içerir:
- Her cihaz düğümü için, cihaz çipinin ve çip içindeki cihaz düğümünün numarasıyla etiketlenmiş bir bölüm (örneğin,
/device:GPU:0 (pid 0)). Her cihaz düğümü bölümü aşağıdaki parçaları içerir:- Adım : Cihazda yürütülen eğitim adımlarının süresini gösterir
- TensorFlow Ops : Cihazda yürütülen işlemleri gösterir
- XLA Ops : Kullanılan derleyici XLA ise cihazda çalışan XLA işlemlerini (ops) gösterir (her TensorFlow işlemi bir veya daha fazla XLA işlemine çevrilir. XLA derleyicisi, XLA işlemlerini cihazda çalışan koda dönüştürür).
- Ana makinenin CPU'sunda çalışan iş parçacıkları için "Ana Bilgisayar Konuları" etiketli bir bölüm. Bu bölüm her CPU iş parçacığı için bir parça içerir. Bölüm etiketlerinin yanında görüntülenen bilgileri göz ardı edebileceğinizi unutmayın.
Olaylar
Zaman çizelgesindeki olaylar farklı renklerde görüntülenir; renklerin kendilerinin belirli bir anlamı yoktur.
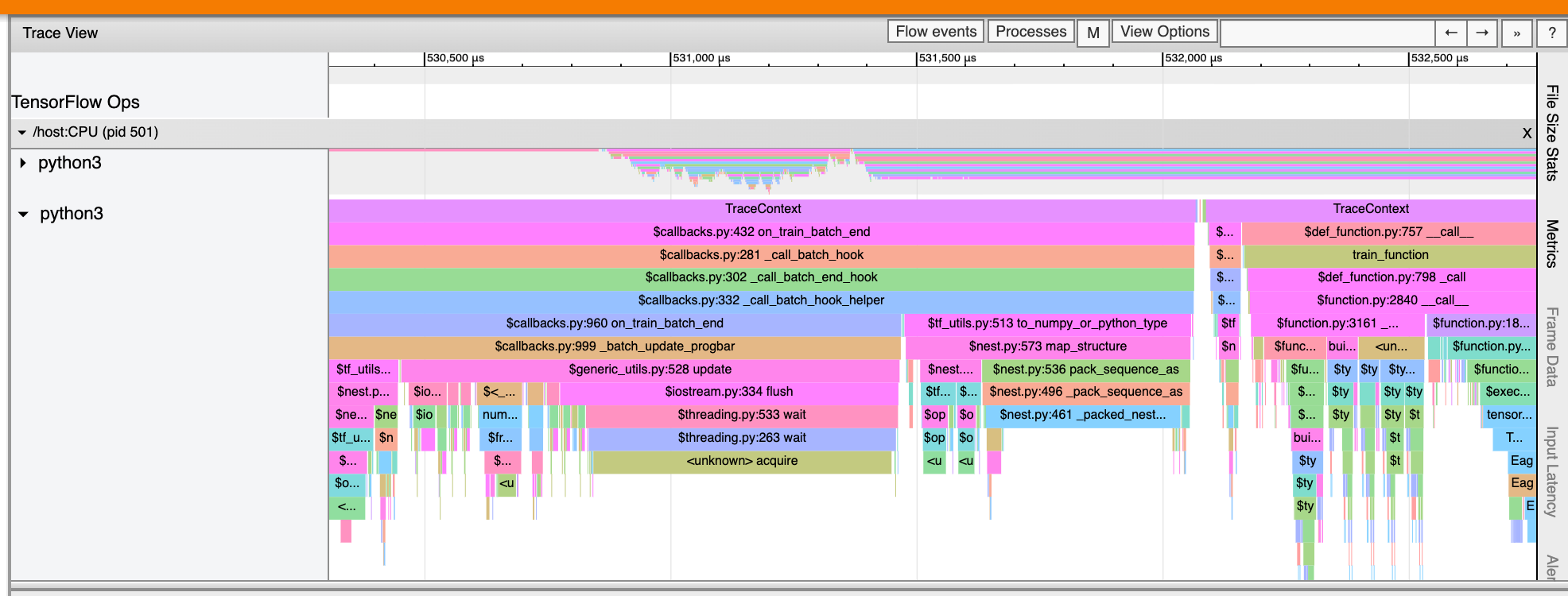
İzleme görüntüleyici ayrıca TensorFlow programınızdaki Python işlev çağrılarının izlerini de görüntüleyebilir. tf.profiler.experimental.start API'sini kullanıyorsanız profil oluşturmaya başlarken ProfilerOptions isimli tuple'ı kullanarak Python izlemeyi etkinleştirebilirsiniz. Alternatif olarak, profil oluşturma için örnekleme modunu kullanıyorsanız Profil Yakalama iletişim kutusundaki açılır seçenekleri kullanarak izleme düzeyini seçebilirsiniz.
GPU çekirdek istatistikleri
Bu araç, her GPU hızlandırmalı çekirdeğin performans istatistiklerini ve kaynak işlemini gösterir.
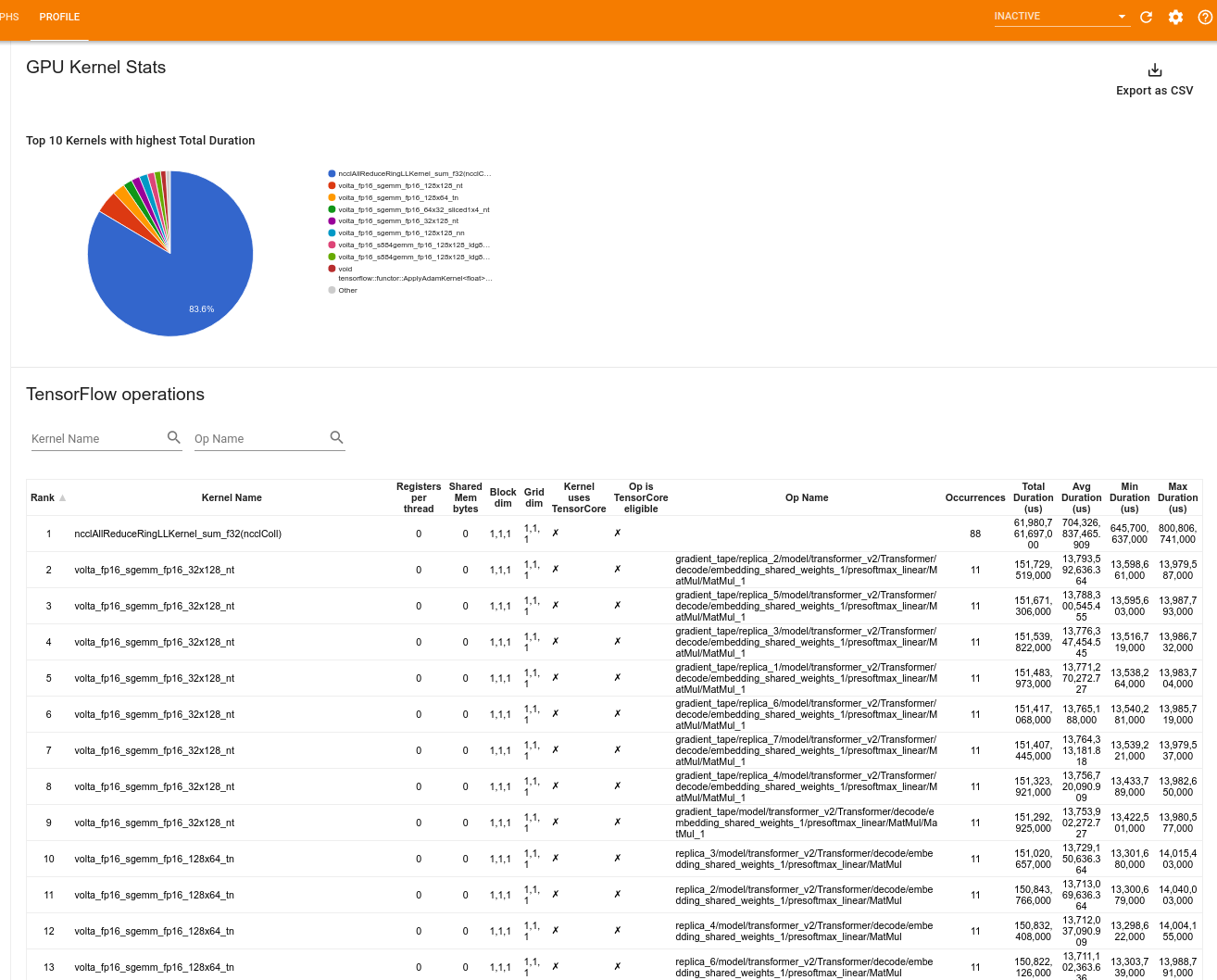
Araç, bilgileri iki bölmede görüntüler:
Üst bölmede, geçen en yüksek toplam süreye sahip CUDA çekirdeklerini gösteren bir pasta grafiği görüntülenir.
Alt bölmede, her benzersiz çekirdek işlem çifti için aşağıdaki verileri içeren bir tablo görüntülenir:
- Çekirdek-op çiftine göre gruplandırılmış, toplam geçen GPU süresinin azalan sırada sıralanması.
- Başlatılan çekirdeğin adı.
- Çekirdek tarafından kullanılan GPU kayıtlarının sayısı.
- Bayt cinsinden kullanılan paylaşılan (statik + dinamik paylaşılan) belleğin toplam boyutu.
-
blockDim.x, blockDim.y, blockDim.zolarak ifade edilen blok boyutu. -
gridDim.x, gridDim.y, gridDim.zolarak ifade edilen ızgara boyutları. - Operasyonun Tensör Çekirdeklerini kullanmaya uygun olup olmadığı.
- Çekirdeğin Tensör Çekirdeği talimatlarını içerip içermediği.
- Bu çekirdeği başlatan operasyonun adı.
- Bu çekirdek-op çiftinin oluşum sayısı.
- Mikrosaniye cinsinden toplam geçen GPU süresi.
- Mikrosaniye cinsinden ortalama geçen GPU süresi.
- Mikrosaniye cinsinden minimum geçen GPU süresi.
- Mikrosaniye cinsinden maksimum geçen GPU süresi.
Bellek profili aracı
Bellek Profili aracı, profil oluşturma aralığı sırasında cihazınızın bellek kullanımını izler. Bu aracı aşağıdakileri yapmak için kullanabilirsiniz:
- En yüksek bellek kullanımını ve TensorFlow işlemlerine karşılık gelen bellek tahsisini belirleyerek yetersiz bellek (OOM) sorunlarında hata ayıklayın. Çoklu kiracılı çıkarımı çalıştırdığınızda ortaya çıkabilecek OOM sorunlarında da hata ayıklayabilirsiniz.
- Bellek parçalanması sorunlarında hata ayıklayın.
Bellek profili aracı, verileri üç bölümde görüntüler:
- Bellek Profili Özeti
- Bellek Zaman Çizelgesi Grafiği
- Bellek Kırılım Tablosu
Bellek profili özeti
Bu bölüm, aşağıda gösterildiği gibi TensorFlow programınızın bellek profilinin üst düzey bir özetini görüntüler:
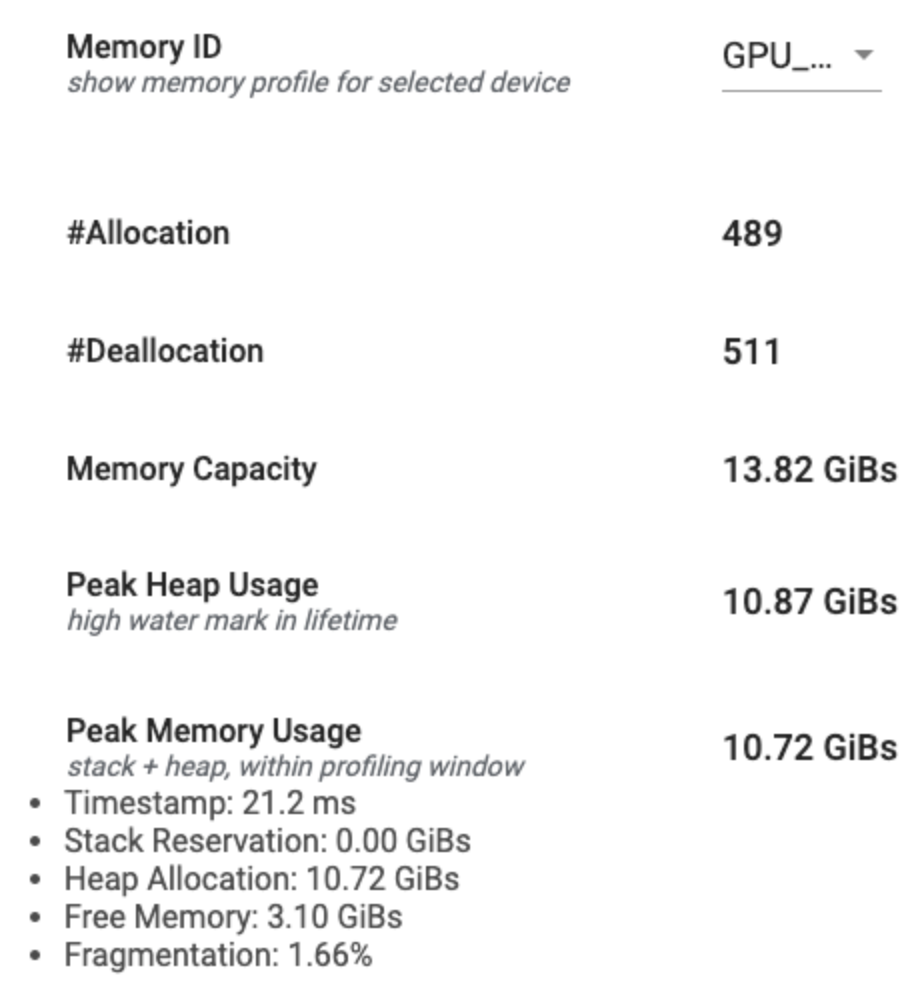
Bellek profili özetinin altı alanı vardır:
- Bellek Kimliği : Mevcut tüm cihaz bellek sistemlerini listeleyen açılır menü. Açılır menüden görüntülemek istediğiniz bellek sistemini seçin.
- #Allocation : Profil oluşturma aralığı sırasında yapılan bellek ayırma sayısı.
- #Deallocation : Profil oluşturma aralığındaki bellek serbest bırakma sayısı
- Bellek Kapasitesi : Seçtiğiniz bellek sisteminin toplam kapasitesi (GiB cinsinden).
- Tepe Yığın Kullanımı : Model çalışmaya başladığından bu yana en yüksek bellek kullanımı (GiB'lerde).
- Tepe Bellek Kullanımı : Profil oluşturma aralığındaki en yüksek bellek kullanımı (GiB cinsinden). Bu alan aşağıdaki alt alanları içerir:
- Zaman Damgası : Zaman Çizelgesi Grafiğinde en yüksek bellek kullanımının ne zaman gerçekleştiğini gösteren zaman damgası.
- Yığın Rezervasyonu : Yığında ayrılan bellek miktarı (GiB cinsinden).
- Yığın Ayırma : Yığında ayrılan bellek miktarı (GiB'lerde).
- Boş Bellek : Boş bellek miktarı (GiB cinsinden). Bellek Kapasitesi, Yığın Rezervasyonu, Yığın Tahsisi ve Boş Belleğin toplamıdır.
- Parçalanma : Parçalanma yüzdesi (daha düşük olan daha iyidir).
(1 - Size of the largest chunk of free memory / Total free memory)yüzdesi olarak hesaplanır.
Bellek zaman çizelgesi grafiği
Bu bölüm, bellek kullanımının (GiB cinsinden) ve zamana karşı parçalanma yüzdesinin (ms cinsinden) bir grafiğini görüntüler.
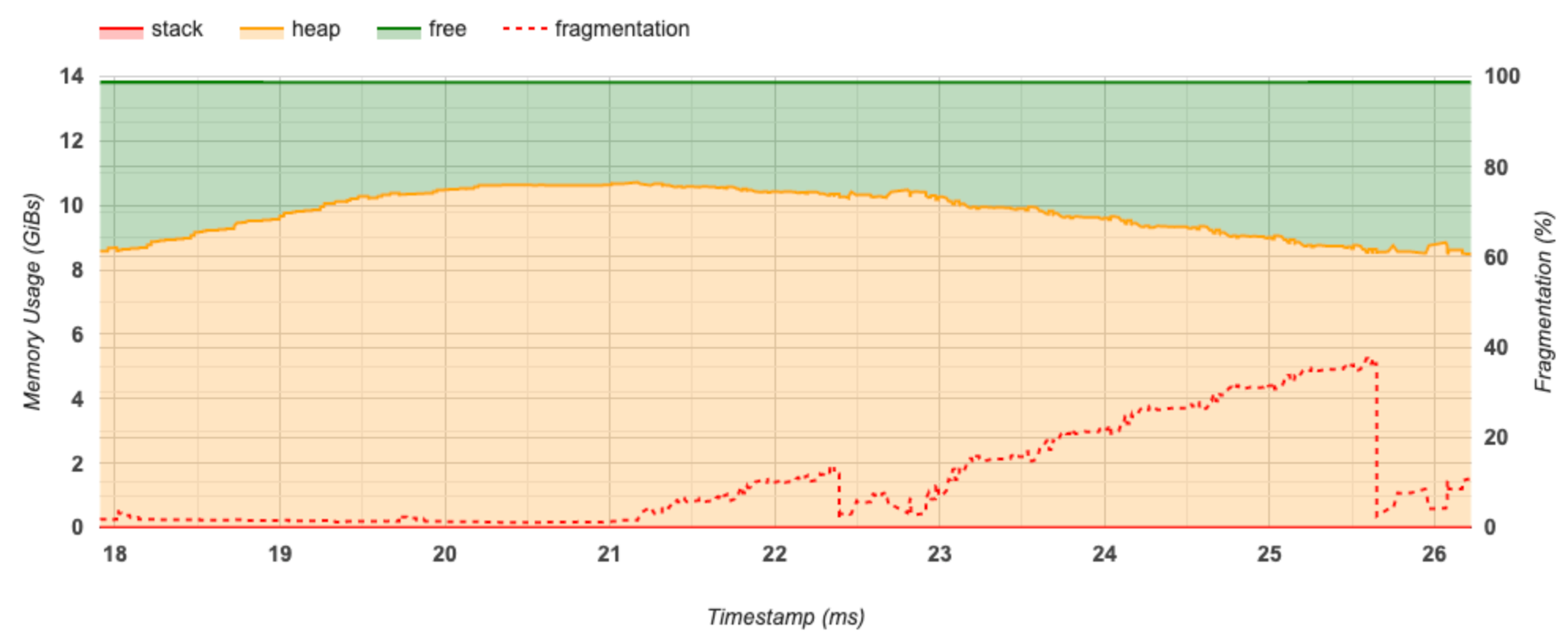
X ekseni, profil oluşturma aralığının zaman çizelgesini (ms cinsinden) temsil eder. Soldaki Y ekseni bellek kullanımını (GiB'lerde) temsil eder ve sağdaki Y ekseni parçalanma yüzdesini temsil eder. X ekseninde zamanın her noktasında, toplam bellek üç kategoriye ayrılır: yığın (kırmızı), yığın (turuncu) ve serbest (yeşil). Belirli bir zaman damgasının üzerine gelin ve o noktadaki bellek ayırma/yer ayırma olaylarıyla ilgili ayrıntıları aşağıdaki gibi görüntüleyin:
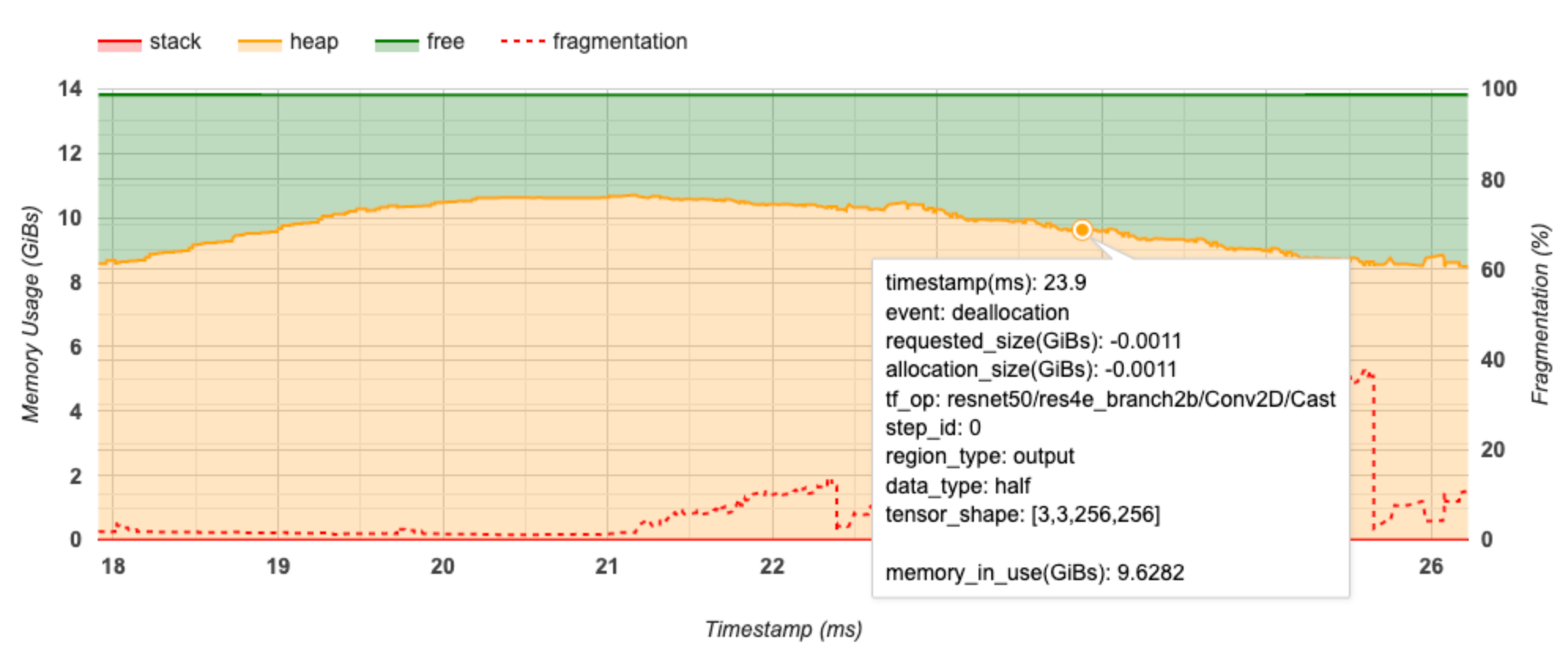
Açılan pencerede aşağıdaki bilgiler görüntülenir:
- timestamp(ms) : Seçilen etkinliğin zaman çizelgesindeki konumu.
- olay : Olayın türü (tahsis veya serbest bırakma).
- request_size(GiBs) : İstenen bellek miktarı. Bu, serbest bırakma etkinlikleri için negatif bir sayı olacaktır.
- tahsis_size(GiBs) : Ayrılan gerçek bellek miktarı. Bu, serbest bırakma etkinlikleri için negatif bir sayı olacaktır.
- tf_op : Tahsis/tahsis talebinde bulunan TensorFlow işlemi.
- step_id : Bu olayın gerçekleştiği eğitim adımı.
- bölge_tipi : Bu ayrılmış belleğin ait olduğu veri varlığı türü. Olası değerler geçiciler için
temp, aktivasyonlar ve degradeler içinoutputve ağırlıklar ve sabitler içinpersist/dynamic. - data_type : Tensör öğesi türü (örneğin, 8 bitlik işaretsiz tamsayı için uint8).
- tensor_shape : Tahsis edilen/tahsisi kaldırılan tensörün şekli.
- Memory_in_use(GiBs) : Bu noktada kullanımda olan toplam bellek.
Bellek dökümü tablosu
Bu tablo, profil oluşturma aralığında bellek kullanımının en yüksek olduğu noktada etkin bellek ayırmalarını gösterir.
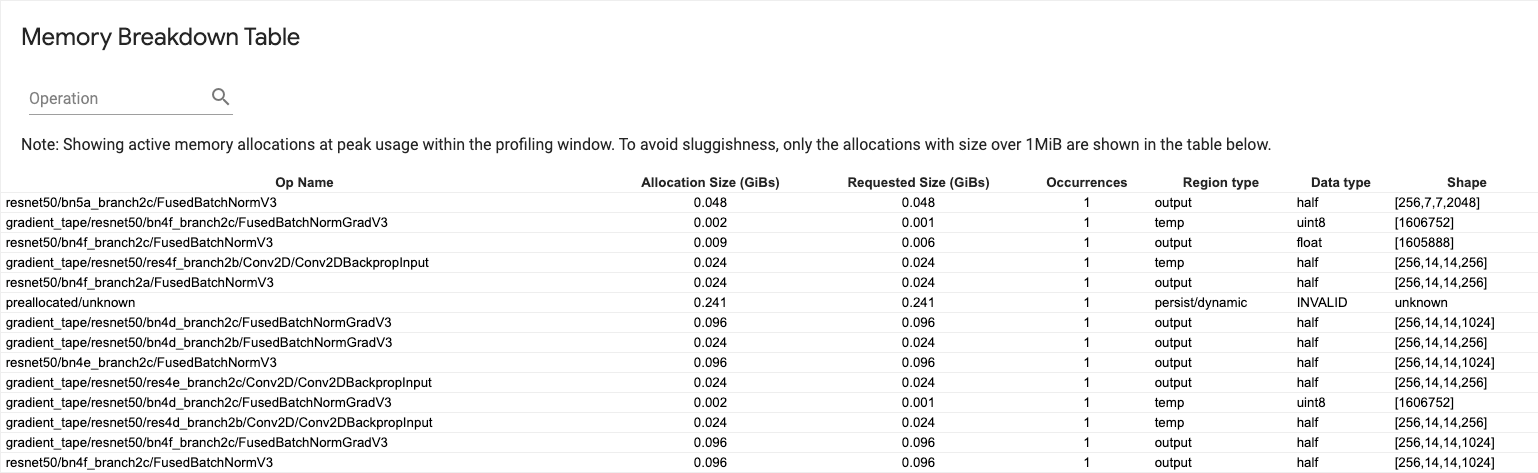
Her TensorFlow Op için bir satır vardır ve her satırda aşağıdaki sütunlar bulunur:
- Op Name : TensorFlow operasyonunun adı.
- Ayırma Boyutu (GiB'ler) : Bu operasyona ayrılan toplam bellek miktarı.
- İstenen Boyut (GiB'ler) : Bu işlem için istenen toplam bellek miktarı.
- Oluşumlar : Bu operasyon için tahsislerin sayısı.
- Bölge türü : Bu ayrılmış belleğin ait olduğu veri varlığı türü. Olası değerler geçiciler için
temp, aktivasyonlar ve degradeler içinoutputve ağırlıklar ve sabitler içinpersist/dynamic. - Veri türü : Tensör elemanı türü.
- Şekil : Tahsis edilen tensörlerin şekli.
Kapsül görüntüleyici
Pod Görüntüleyici aracı, bir eğitim adımının tüm çalışanlara ilişkin dökümünü gösterir.
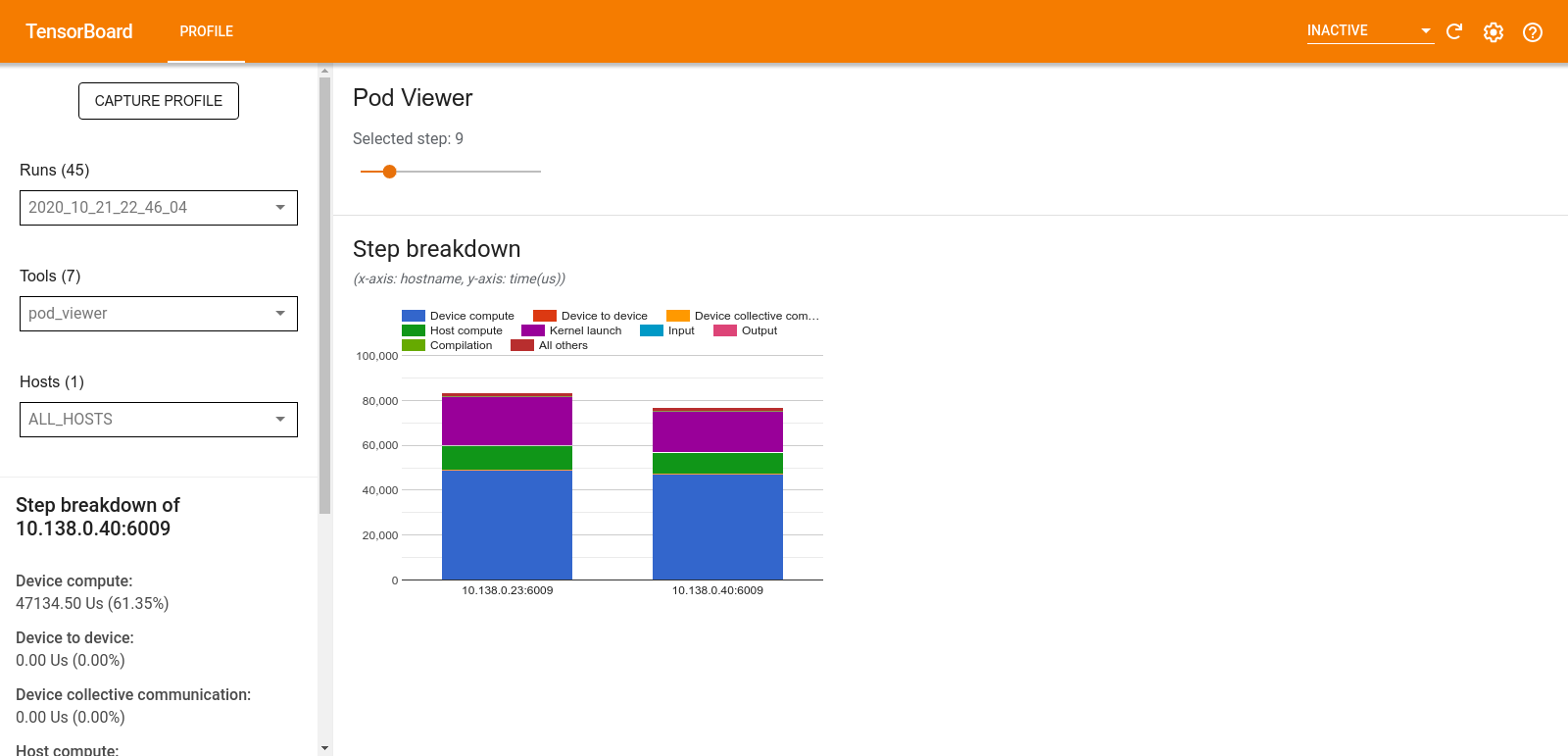
- Üst bölmede adım numarasını seçmek için bir kaydırıcı bulunur.
- Alt bölmede yığılmış bir sütun grafiği görüntülenir. Bu, üst üste yerleştirilmiş parçalanmış adım zamanı kategorilerinin üst düzey bir görünümüdür. Her yığılmış sütun benzersiz bir çalışanı temsil eder.
- Yığılmış bir sütunun üzerine geldiğinizde sol taraftaki kart, adım dökümüyle ilgili daha fazla ayrıntı gösterir.
tf.data darboğaz analizi
tf.data darboğaz analiz aracı, programınızdaki tf.data giriş hatlarındaki darboğazları otomatik olarak algılar ve bunların nasıl düzeltileceği konusunda öneriler sağlar. Platformdan (CPU/GPU/TPU) bağımsız olarak tf.data kullanan herhangi bir programla çalışır. Analizi ve tavsiyeleri bu kılavuza dayanmaktadır.
Aşağıdaki adımları izleyerek bir darboğaz tespit eder:
- En fazla girdiye bağlı ana bilgisayarı bulun.
- Bir
tf.datagiriş hattının en yavaş yürütülmesini bulun. - Giriş hattı grafiğini profil oluşturucu izlemesinden yeniden oluşturun.
- Giriş hattı grafiğindeki kritik yolu bulun.
- Kritik yoldaki en yavaş dönüşümü darboğaz olarak tanımlayın.
Kullanıcı arayüzü üç bölüme ayrılmıştır: Performans Analizi Özeti , Tüm Giriş İşlem Hatlarının Özeti ve Giriş İşlem Hattı Grafiği .
Performans analizi özeti

Bu bölümde analizin özeti yer almaktadır. Profilde tespit edilen yavaş tf.data giriş işlem hatlarını rapor eder. Bu bölüm aynı zamanda en fazla girişe bağlı ana bilgisayarı ve maksimum gecikmeyle en yavaş giriş hattını gösterir. En önemlisi, giriş hattının hangi kısmının darboğaz olduğunu ve bunun nasıl düzeltileceğini tanımlar. Darboğaz bilgisi yineleyici türü ve uzun adı ile sağlanır.
tf.data yineleyicinin uzun adı nasıl okunur
Uzun bir ad Iterator::<Dataset_1>::...::<Dataset_n> olarak biçimlendirilir. Uzun adda <Dataset_n> yineleyici türüyle eşleşir ve uzun addaki diğer veri kümeleri aşağı akış dönüşümlerini temsil eder.
Örneğin, aşağıdaki girdi hattı veri kümesini göz önünde bulundurun:
dataset = tf.data.Dataset.range(10).map(lambda x: x).repeat(2).batch(5)
Yukarıdaki veri kümesindeki yineleyicilerin uzun adları şöyle olacaktır:
| Yineleyici Türü | Uzun Ad |
|---|---|
| Menzil | Yineleyici::Toplu::Tekrar::Harita::Aralık |
| Harita | Yineleyici::Toplu::Tekrar::Harita |
| Tekrarlamak | Yineleyici::Toplu::Tekrar |
| Grup | Yineleyici::Toplu |
Tüm giriş boru hatlarının özeti
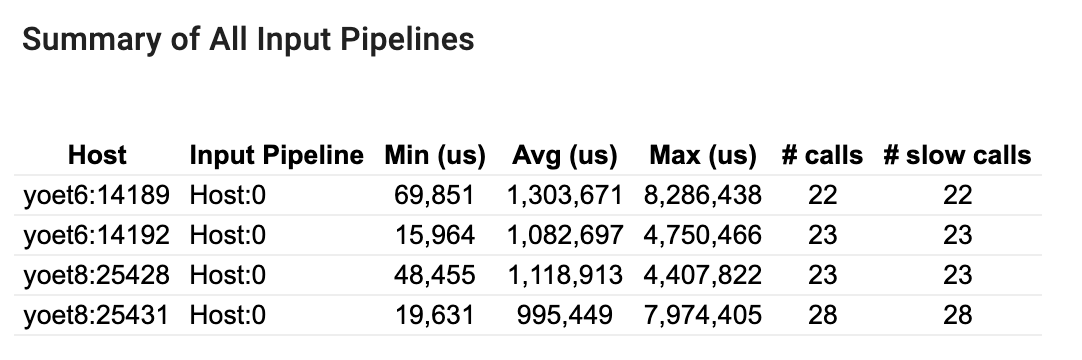
Bu bölüm, tüm ana bilgisayarlardaki tüm giriş işlem hatlarının özetini sağlar. Tipik olarak bir giriş hattı vardır. Dağıtım stratejisini kullanırken, programın tf.data kodunu çalıştıran bir ana bilgisayar giriş hattı ve ana bilgisayar giriş hattından veri alan ve bunu cihazlara aktaran birden fazla cihaz giriş hattı vardır.
Her giriş hattı için yürütme süresinin istatistiklerini gösterir. Bir çağrı 50 μs'den uzun sürerse yavaş sayılır.
Giriş hattı grafiği

Bu bölüm, yürütme süresi bilgileriyle birlikte giriş hattı grafiğini gösterir. Hangi ana makineyi ve giriş hattını göreceğinizi seçmek için "Ana Bilgisayar" ve "Giriş Boru Hattı"nı kullanabilirsiniz. Giriş hattının yürütmeleri, Sıralama açılır menüsünü kullanarak seçebileceğiniz yürütme süresine göre azalan sırada sıralanır.
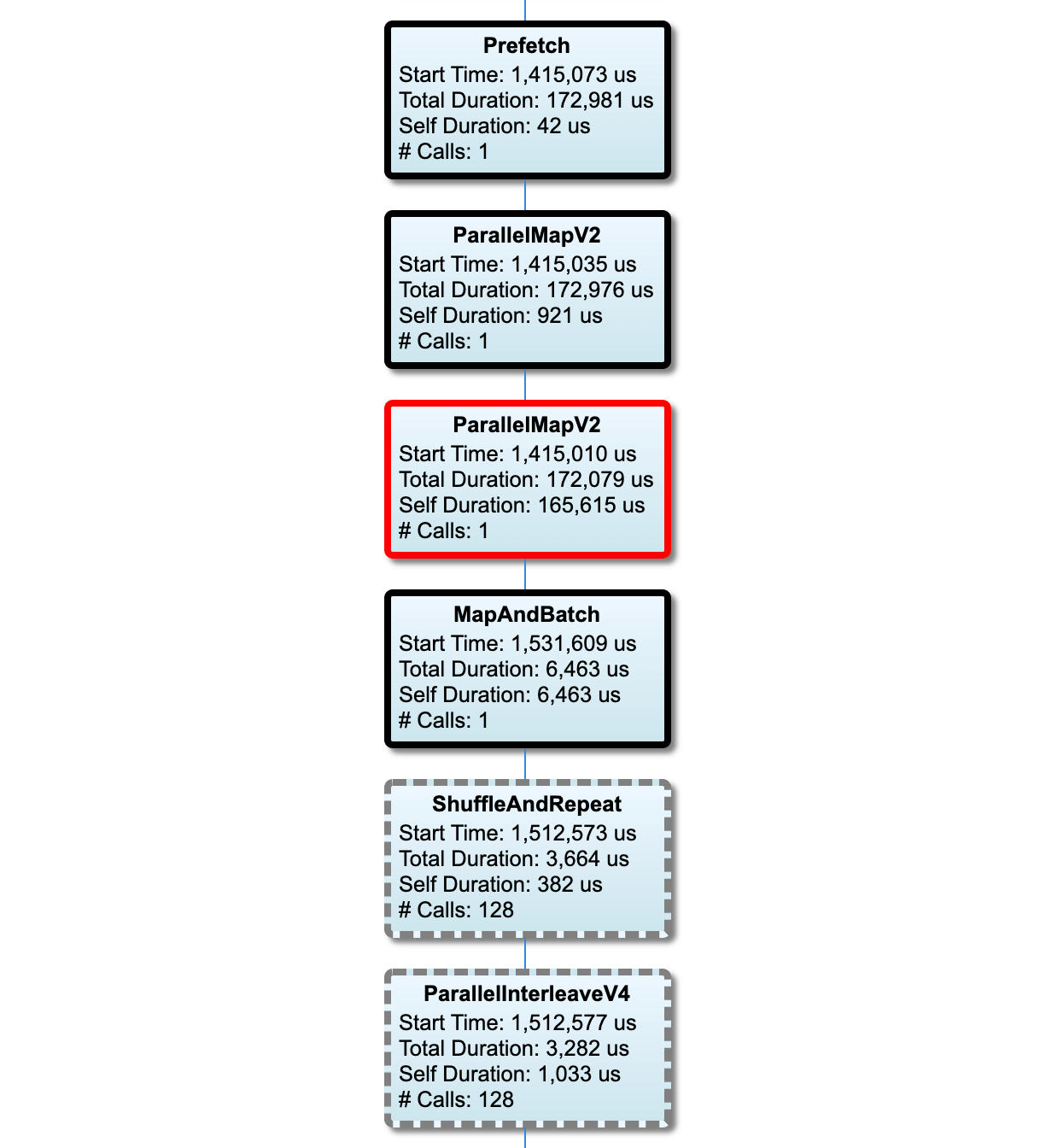
Kritik yoldaki düğümlerin kalın hatları vardır. Kritik yolda en uzun süreye sahip olan düğüm olan darboğaz düğümü kırmızı bir çerçeveye sahiptir. Diğer kritik olmayan düğümlerin gri kesikli hatları vardır.
Her düğümde Başlangıç Zamanı , yürütmenin başlangıç zamanını gösterir. Aynı düğüm, örneğin giriş hattında bir Batch işlem varsa, birden çok kez yürütülebilir. Birden çok kez yürütülürse, ilk yürütmenin başlangıç zamanıdır.
Toplam Süre, yürütmenin duvar süresidir. Birden çok kez yürütülürse, tüm yürütmelerin duvar sürelerinin toplamıdır.
Kişisel Zaman, yakın alt düğümleriyle çakışan zaman olmadan Toplam Zamandır .
"# Çağrılar", giriş hattının yürütülme sayısıdır.
Performans verilerini toplayın
TensorFlow Profiler, TensorFlow modelinizin ana bilgisayar etkinliklerini ve GPU izlerini toplar. Profiler'ı performans verilerini programlı mod veya örnekleme modu aracılığıyla toplayacak şekilde yapılandırabilirsiniz.
Profil oluşturma API'leri
Profil oluşturma işlemini gerçekleştirmek için aşağıdaki API'leri kullanabilirsiniz.
TensorBoard Keras Geri Çağırma (
tf.keras.callbacks.TensorBoard) kullanılarak programlı mod# Profile from batches 10 to 15 tb_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, profile_batch='10, 15') # Train the model and use the TensorBoard Keras callback to collect # performance profiling data model.fit(train_data, steps_per_epoch=20, epochs=5, callbacks=[tb_callback])tf.profilerİşlev API'sini kullanan programlı modtf.profiler.experimental.start('logdir') # Train the model here tf.profiler.experimental.stop()İçerik yöneticisini kullanan programlı mod
with tf.profiler.experimental.Profile('logdir'): # Train the model here pass
Örnekleme modu: TensorFlow model çalıştırmanızla birlikte bir gRPC sunucusu başlatmak için
tf.profiler.experimental.server.startkomutunu kullanarak isteğe bağlı profil oluşturma gerçekleştirin. GRPC sunucusunu başlattıktan ve modelinizi çalıştırdıktan sonra TensorBoard profil eklentisindeki Profil Yakala düğmesi aracılığıyla bir profil yakalayabilirsiniz. Zaten çalışmıyorsa bir TensorBoard örneğini başlatmak için yukarıdaki Profil oluşturucuyu yükle bölümündeki komut dosyasını kullanın.Örnek olarak,
# Start a profiler server before your model runs. tf.profiler.experimental.server.start(6009) # (Model code goes here). # Send a request to the profiler server to collect a trace of your model. tf.profiler.experimental.client.trace('grpc://localhost:6009', 'gs://your_tb_logdir', 2000)Birden fazla çalışanın profilini çıkarmaya yönelik bir örnek:
# E.g., your worker IP addresses are 10.0.0.2, 10.0.0.3, 10.0.0.4, and you # would like to profile for a duration of 2 seconds. tf.profiler.experimental.client.trace( 'grpc://10.0.0.2:8466,grpc://10.0.0.3:8466,grpc://10.0.0.4:8466', 'gs://your_tb_logdir', 2000)
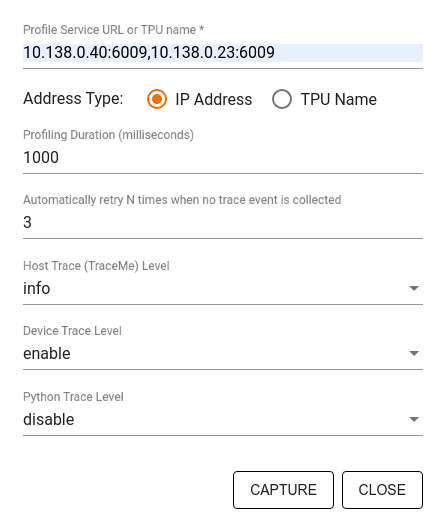
Aşağıdakileri belirtmek için Yakalama Profili iletişim kutusunu kullanın:
- Profil hizmeti URL'lerinin veya TPU adlarının virgülle ayrılmış listesi.
- Bir profil oluşturma süresi.
- Cihaz, ana bilgisayar ve Python işlev çağrısı izleme düzeyi.
- İlk başta başarısız olursa Profiler'ın profilleri yakalamayı kaç kez yeniden denemesini istiyorsunuz?
Özel eğitim döngülerinin profilini oluşturma
TensorFlow kodunuzdaki özel eğitim döngülerinin profilini çıkarmak için, Profiler'ın adım sınırlarını işaretlemek amacıyla eğitim döngüsünü tf.profiler.experimental.Trace API ile ayarlayın.
name argümanı adım adları için bir önek olarak kullanılır, step_num anahtar kelime argümanı adım adlarına eklenir ve _r anahtar kelime argümanı bu izleme olayının Profiler tarafından bir adım olayı olarak işlenmesini sağlar.
Örnek olarak,
for step in range(NUM_STEPS):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_data = next(dataset)
train_step(train_data)
Bu, Profiler'ın adım bazlı performans analizini etkinleştirecek ve adım olaylarının izleme görüntüleyicide görünmesine neden olacaktır.
Giriş hattının doğru analizi için veri kümesi yineleyicisini tf.profiler.experimental.Trace bağlamına eklediğinizden emin olun.
Aşağıdaki kod parçacığı bir anti-kalıptır:
for step, train_data in enumerate(dataset):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_step(train_data)
Profil oluşturma kullanım örnekleri
Profil oluşturucu dört farklı eksende çok sayıda kullanım durumunu kapsar. Kombinasyonlardan bazıları şu anda desteklenmektedir ve diğerleri gelecekte eklenecektir. Kullanım durumlarından bazıları şunlardır:
- Yerel ve uzak profil oluşturma : Bunlar, profil oluşturma ortamınızı ayarlamanın iki yaygın yoludur. Yerel profil oluşturmada profil oluşturma API'si, modelinizin çalıştırdığı makinede (örneğin, GPU'lu yerel bir iş istasyonu) çağrılır. Uzaktan profil oluşturmada profil oluşturma API'si, modelinizin yürütüldüğü yerden farklı bir makinede (örneğin, Cloud TPU'da) çağrılır.
- Birden fazla çalışanın profilini oluşturma : TensorFlow'un dağıtılmış eğitim özelliklerini kullanırken birden fazla makinenin profilini oluşturabilirsiniz.
- Donanım platformu : CPU'ların, GPU'ların ve TPU'ların profilini çıkarın.
Aşağıdaki tablo, yukarıda bahsedilen TensorFlow destekli kullanım senaryolarına hızlı bir genel bakış sunmaktadır:
| Profil Oluşturma API'si | Yerel | Uzak | Birden fazla işçi | Donanım Platformları |
|---|---|---|---|---|
| TensorBoard Keras Geri Çağırma | Destekleniyor | Desteklenmiyor | Desteklenmiyor | CPU, GPU |
tf.profiler.experimental başlatma/durdurma API'si | Destekleniyor | Desteklenmiyor | Desteklenmiyor | CPU, GPU |
tf.profiler.experimental client.trace API'si | Destekleniyor | Destekleniyor | Destekleniyor | CPU, GPU, TPU |
| Bağlam yöneticisi API'si | Destekleniyor | Desteklenmiyor | Desteklenmiyor | CPU, GPU |
Optimum model performansı için en iyi uygulamalar
Optimum performansa ulaşmak için TensorFlow modelleriniz için geçerli olan aşağıdaki önerileri kullanın.
Genel olarak tüm dönüşümleri cihaz üzerinde gerçekleştirin ve platformunuz için cuDNN ve Intel MKL gibi kitaplıkların en son uyumlu sürümlerini kullandığınızdan emin olun.
Giriş veri hattını optimize edin
Veri giriş hattınızı optimize etmek için [#input_pipeline_analyzer] verilerini kullanın. Verimli bir veri girişi hattı, cihazın boşta kalma süresini azaltarak model yürütme hızınızı büyük ölçüde artırabilir. Veri giriş hattınızı daha verimli hale getirmek için tf.data API kılavuzunda ve aşağıdaki Daha iyi performans bölümünde ayrıntılı olarak açıklanan en iyi uygulamaları birleştirmeye çalışın.
Genel olarak, sırayla yürütülmesi gerekmeyen herhangi bir işlemin paralelleştirilmesi, veri giriş hattını önemli ölçüde optimize edebilir.
Çoğu durumda, bazı çağrıların sırasını değiştirmek veya argümanları modeliniz için en iyi şekilde çalışacak şekilde ayarlamak yardımcı olur. Giriş veri hattını optimize ederken, optimizasyonların etkisini bağımsız olarak ölçmek için eğitim ve geri yayılım adımları olmadan yalnızca veri yükleyiciyi karşılaştırın.
Giriş hattının bir performans darboğazı olup olmadığını kontrol etmek için modelinizi sentetik verilerle çalıştırmayı deneyin.
Çoklu GPU eğitimi için
tf.data.Dataset.shardkullanın. Verimin azalmasını önlemek için giriş döngüsünde çok erken parçalama yaptığınızdan emin olun. TFRecords ile çalışırken, TFRecords'un içeriğini değil, TFRecords listesini parçaladığınızdan emin olun.tf.data.AUTOTUNEkullanaraknum_parallel_callsdeğerini dinamik olarak ayarlayarak birkaç işlemi paralelleştirin.Saf TensorFlow işlemlerine kıyasla daha yavaş olduğundan
tf.data.Dataset.from_generatorkullanımını sınırlamayı düşünün.Serileştirilemediği ve dağıtılmış TensorFlow'da çalışması desteklenmediği için
tf.py_functionişlevinin kullanımını sınırlamayı düşünün.Giriş hattındaki statik optimizasyonları kontrol etmek için
tf.data.Optionskullanın.
Ayrıca giriş hattınızı optimize etme konusunda daha fazla rehberlik için tf.data performans analizi kılavuzunu da okuyun.
Veri artırmayı optimize edin
Görüntü verileriyle çalışırken, çevirme, kırpma, döndürme gibi uzamsal dönüşümler uyguladıktan sonra farklı veri türlerine döküm yaparak veri büyütme işleminizi daha verimli hale getirin.
NVIDIA® DALI'yi kullanın
Bazı durumlarda, örneğin yüksek GPU/CPU oranına sahip bir sisteminiz olduğunda, yukarıdaki optimizasyonların tümü, CPU döngülerinin sınırlamaları nedeniyle veri yükleyicide meydana gelen darboğazları ortadan kaldırmak için yeterli olmayabilir.
Bilgisayar görüşü ve ses derin öğrenme uygulamaları için NVIDIA® GPU'ları kullanıyorsanız veri hattını hızlandırmak için Veri Yükleme Kitaplığını ( DALI ) kullanmayı düşünün.
Desteklenen DALI işlemlerinin listesi için NVIDIA® DALI: İşlemler belgelerine bakın.
İş parçacığı ve paralel yürütmeyi kullanma
İşlemleri daha hızlı yürütmek için tf.config.threading API'si ile birden fazla CPU iş parçacığında çalıştırın.
TensorFlow, varsayılan olarak paralellik iş parçacıklarının sayısını otomatik olarak ayarlar. TensorFlow operasyonlarını çalıştırmak için mevcut olan iş parçacığı havuzu, mevcut CPU iş parçacıklarının sayısına bağlıdır.
tf.config.threading.set_intra_op_parallelism_threads kullanarak tek bir işlem için maksimum paralel hızlanmayı kontrol edin. Birden fazla işlemi paralel olarak çalıştırırsanız hepsinin mevcut iş parçacığı havuzunu paylaşacağını unutmayın.
Bağımsız engellemeyen operasyonlarınız varsa (grafik üzerinde aralarında yönlendirilmiş yol bulunmayan operasyonlar), bunları mevcut iş parçacığı havuzunu kullanarak eşzamanlı olarak çalıştırmak için tf.config.threading.set_inter_op_parallelism_threads kullanın.
Çeşitli
NVIDIA® GPU'larda daha küçük modellerle çalışırken, model performansında önemli bir artış sağlamak üzere tüm CPU tensörlerinin CUDA sabitlenmiş belleğe tahsis edilmesini sağlamak için tf.compat.v1.ConfigProto.force_gpu_compatible=True ayarını yapabilirsiniz. Ancak, bu seçeneği bilinmeyen/çok büyük modeller için kullanırken dikkatli olun; çünkü bu, ana bilgisayarın (CPU) performansını olumsuz etkileyebilir.
Cihaz performansını iyileştirin
Cihaz içi TensorFlow modeli performansını optimize etmek için burada ve GPU performans optimizasyonu kılavuzunda ayrıntılı olarak açıklanan en iyi uygulamaları izleyin.
NVIDIA GPU'ları kullanıyorsanız aşağıdakileri çalıştırarak GPU ve bellek kullanımını bir CSV dosyasına kaydedin:
nvidia-smi
--query-gpu=utilization.gpu,utilization.memory,memory.total,
memory.free,memory.used --format=csv
Veri düzenini yapılandırma
Kanal bilgilerini içeren verilerle (görüntüler gibi) çalışırken, kanalları en son tercih edecek şekilde (NCHW yerine NHWC) veri düzeni formatını optimize edin.
Kanal-son veri formatları, Tensör Çekirdeği kullanımını iyileştirir ve AMP ile birleştirildiğinde özellikle evrişimli modellerde önemli performans iyileştirmeleri sağlar. NCHW veri düzenleri hala Tensör Çekirdekleri tarafından çalıştırılabilir, ancak otomatik transpoze işlemleri nedeniyle ek yük getirir.
tf.keras.layers.Conv2D , tf.keras.layers.Conv3D ve tf.keras.layers.RandomRotation gibi katmanlar için data_format="channels_last" ayarını yaparak veri düzenini NHWC düzenlerini tercih edecek şekilde optimize edebilirsiniz.
Keras arka uç API'sine yönelik varsayılan veri düzeni biçimini ayarlamak için tf.keras.backend.set_image_data_format kullanın.
L2 önbelleğini maksimuma çıkarın
NVIDIA® GPU'larla çalışırken, L2 getirme ayrıntı düzeyini 128 bayta çıkarmak için eğitim döngüsünden önce aşağıdaki kod parçacığını yürütün.
import ctypes
_libcudart = ctypes.CDLL('libcudart.so')
# Set device limit on the current device
# cudaLimitMaxL2FetchGranularity = 0x05
pValue = ctypes.cast((ctypes.c_int*1)(), ctypes.POINTER(ctypes.c_int))
_libcudart.cudaDeviceSetLimit(ctypes.c_int(0x05), ctypes.c_int(128))
_libcudart.cudaDeviceGetLimit(pValue, ctypes.c_int(0x05))
assert pValue.contents.value == 128
GPU iş parçacığı kullanımını yapılandırma
GPU iş parçacığı modu, GPU iş parçacıklarının nasıl kullanılacağına karar verir.
Ön işlemin tüm GPU iş parçacıklarını çalmadığından emin olmak için iş parçacığı modunu gpu_private olarak ayarlayın. Bu, eğitim sırasında çekirdek fırlatma gecikmesini azaltacaktır. Ayrıca GPU başına iş parçacığı sayısını da ayarlayabilirsiniz. Bu değerleri ortam değişkenlerini kullanarak ayarlayın.
import os
os.environ['TF_GPU_THREAD_MODE']='gpu_private'
os.environ['TF_GPU_THREAD_COUNT']='1'
GPU bellek seçeneklerini yapılandırın
Genel olarak, parti boyutunu artırın ve GPU'ları daha iyi kullanmak ve daha yüksek verim elde etmek için modeli ölçeklendirin. Toplu boyutun artırılmasının, modelin doğruluğunu değiştireceğini unutmayın, böylece hedef doğruluğunu karşılamak için öğrenme oranı gibi hiperparametreleri ayarlayarak modelin ölçeklendirilmesi gerekir.
Ayrıca, mevcut tüm belleğin belleğin sadece bir kısmını gerektiren OP'lere tamamen tahsis edilmesini önlemek için GPU belleğinin büyümesine izin vermek için tf.config.experimental.set_memory_growth kullanın. Bu, GPU belleğini tüketen diğer işlemlerin aynı cihazda çalışmasını sağlar.
Daha fazla bilgi edinmek için, daha fazla bilgi edinmek için GPU kılavuzundaki sınırlayıcı GPU bellek büyüme kılavuzuna göz atın.
Çeşitli
GPU'da bellek dışı (OOM) hatası olmadan uyan maksimum miktara kadar eğitim mini-toplu boyutunu (eğitim döngüsünün bir yinelemesinde cihaz başına kullanılan eğitim örneklerinin sayısı) artırın. Parti boyutunu artırmak, modelin doğruluğunu etkiler - bu nedenle, hedef doğruluğunu karşılamak için hiperparametreleri ayarlayarak modeli ölçeklendirdiğinizden emin olun.
Üretim kodunda tensör tahsisi sırasında raporlama OOM hatalarını devre dışı bırakın.
report_tensor_allocations_upon_oom=Falsetf.compat.v1.RunOptionsolarak ayarlayın.Evrişim katmanları olan modeller için, toplu normalizasyon kullanıyorsanız önyargı ilavesini kaldırın. Toplu normalizasyon değerleri ortalamalarına göre kaydırır ve bu da sabit bir önyargı terimine sahip olma ihtiyacını ortadan kaldırır.
Bitişik OPS'nin ne kadar verimli bir şekilde çalıştığını öğrenmek için TF istatistiklerini kullanın.
Hesaplamaları gerçekleştirmek için
tf.functionkullanın ve isteğe bağlı olarak,jit_compile=Truebayrağını (tf.function(jit_compile=True) etkinleştirin. Daha fazla bilgi edinmek için xla tf.function kullanın .Adımlar arasındaki ana bilgisayar python işlemlerini en aza indirin ve geri çağrıları azaltın. Metrikleri her adımda bir birkaç adımda bir hesaplayın.
Cihaz hesaplama birimlerini meşgul edin.
Paralel olarak birden çok cihaza veri gönderin.
IEEE tarafından belirtilen yarı öne çıkan yüzen nokta formatı-veya beyin yüzen BFLOAT16 formatı olan
fp16gibi 16 bit sayısal gösterimleri kullanmayı düşünün.
Ek kaynaklar
- Tensorflow Profiler: Bu kılavuzdaki tavsiyeyi uygulayabileceğiniz Keras ve Tensorboard ile Profil Modeli Performans Eğitimi.
- Tensorflow 2'deki performans profili oluşturma Tensorflow Dev Summit 2020'den konuşuyor.
- Tensorflow Dev Zirvesi 2020'den Tensorflow Profiler Demosu .
Bilinen sınırlamalar
TensorFlow 2.2 ve Tensorflow 2.3'te birden çok GPU'nun profilini
TensorFlow 2.2 ve 2.3, yalnızca tek ana bilgisayar sistemleri için birden fazla GPU profilini destekler; Çok evli sistemler için çoklu GPU profili desteklenmez. Çok işçi GPU yapılandırmalarını profillemek için, her işçinin bağımsız olarak profillenmesi gerekir. TensorFlow 2.4 birden fazla işçi tf.profiler.experimental.client.trace API kullanılarak profillenebilir.
Birden fazla GPU profilini yapmak için CUDA® Toolk 10 10.2 veya üstü gereklidir. Tensorflow 2.2 ve 2.3, yalnızca 10.1'e kadar olan CUDA® Toolkit sürümlerini desteklediğinden, libcudart.so.10.1 ve libcupti.so.10.1 sembolik bağlantılar oluşturmanız gerekir:
sudo ln -s /usr/local/cuda/lib64/libcudart.so.10.2 /usr/local/cuda/lib64/libcudart.so.10.1
sudo ln -s /usr/local/cuda/extras/CUPTI/lib64/libcupti.so.10.2 /usr/local/cuda/extras/CUPTI/lib64/libcupti.so.10.1