
| | |  Kaynağı GitHub'da görüntüleyin Kaynağı GitHub'da görüntüleyin | |
genel bakış
Bu öğretici, veri büyütmeyi gösterir: görüntü döndürme gibi rastgele (ancak gerçekçi) dönüşümler uygulayarak eğitim setinizin çeşitliliğini artırmaya yönelik bir teknik.
Veri büyütmeyi iki şekilde nasıl uygulayacağınızı öğreneceksiniz:
- tf.keras.layers.Resizing ,
tf.keras.layers.Rescaling,tf.keras.layers.RandomFlipvetf.keras.layers.RandomRotationgibitf.keras.layers.Resizingön işleme katmanlarını kullanın. -
tf.image.flip_left_right,tf.image.rgb_to_grayscale,tf.image.adjust_brightness,tf.image.central_cropvetf.image.stateless_random*gibitf.imageyöntemlerini kullanın.
Kurmak
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow.keras import layers
Bir veri kümesini indirin
Bu öğretici, tf_flowers veri kümesini kullanır. Kolaylık sağlamak için TensorFlow Datasets kullanarak veri kümesini indirin. Verileri içe aktarmanın diğer yolları hakkında bilgi edinmek isterseniz, resim yükleme eğitimine bakın.
(train_ds, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
Çiçekler veri kümesinin beş sınıfı vardır.
num_classes = metadata.features['label'].num_classes
print(num_classes)
5
Veri kümesinden bir görüntü alalım ve onu veri büyütmeyi göstermek için kullanalım.
get_label_name = metadata.features['label'].int2str
image, label = next(iter(train_ds))
_ = plt.imshow(image)
_ = plt.title(get_label_name(label))
2022-01-26 05:09:18.712477: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.

Keras ön işleme katmanlarını kullanın
Yeniden boyutlandırma ve yeniden ölçeklendirme
Resimlerinizi tutarlı bir şekle ( tf.keras.layers.Resizing ile) yeniden boyutlandırmak ve piksel değerlerini yeniden ölçeklendirmek ( tf.keras.layers.Rescaling ile) için Keras ön işleme katmanlarını kullanabilirsiniz.
IMG_SIZE = 180
resize_and_rescale = tf.keras.Sequential([
layers.Resizing(IMG_SIZE, IMG_SIZE),
layers.Rescaling(1./255)
])
Bu katmanları bir görüntüye uygulamanın sonucunu görselleştirebilirsiniz.
result = resize_and_rescale(image)
_ = plt.imshow(result)
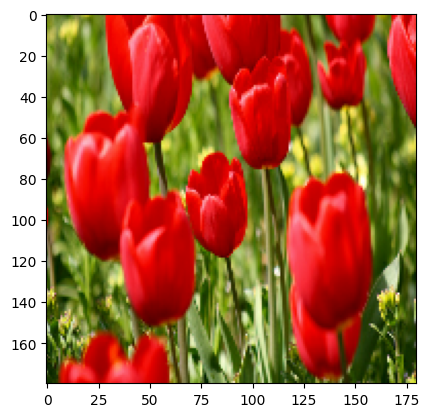
Piksellerin [0, 1] aralığında olduğunu doğrulayın:
print("Min and max pixel values:", result.numpy().min(), result.numpy().max())
Min and max pixel values: 0.0 1.0
Veri büyütme
Veri büyütme için Keras ön işleme katmanlarını da kullanabilirsiniz, örneğin tf.keras.layers.RandomFlip ve tf.keras.layers.RandomRotation .
Birkaç ön işleme katmanı oluşturalım ve bunları tekrar tekrar aynı görüntüye uygulayalım.
data_augmentation = tf.keras.Sequential([
layers.RandomFlip("horizontal_and_vertical"),
layers.RandomRotation(0.2),
])
# Add the image to a batch.
image = tf.expand_dims(image, 0)
plt.figure(figsize=(10, 10))
for i in range(9):
augmented_image = data_augmentation(image)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_image[0])
plt.axis("off")
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

tf.keras.layers.RandomContrast , tf.keras.layers.RandomCrop , tf.keras.layers.RandomZoom ve diğerleri dahil olmak üzere veri büyütme için kullanabileceğiniz çeşitli ön işleme katmanları vardır.
Keras ön işleme katmanlarını kullanmak için iki seçenek
Bu ön işleme katmanlarını önemli ödünleşimlerle birlikte kullanmanın iki yolu vardır.
Seçenek 1: Ön işleme katmanlarını modelinizin bir parçası yapın
model = tf.keras.Sequential([
# Add the preprocessing layers you created earlier.
resize_and_rescale,
data_augmentation,
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
# Rest of your model.
])
Bu durumda dikkat edilmesi gereken iki önemli nokta vardır:
Veri büyütme, cihaz üzerinde, diğer katmanlarınızla eşzamanlı olarak çalışacak ve GPU hızlandırmasından yararlanacaktır.
Modelinizi
model.savekullanarak dışa aktardığınızda, ön işleme katmanları modelinizin geri kalanıyla birlikte kaydedilir. Bu modeli daha sonra dağıtırsanız, görüntüleri otomatik olarak standartlaştıracaktır (katmanlarınızın yapılandırmasına göre). Bu, sizi bu mantığı sunucu tarafını yeniden uygulama zorunluluğundan kurtarabilir.
Seçenek 2: Ön işleme katmanlarını veri kümenize uygulayın
aug_ds = train_ds.map(
lambda x, y: (resize_and_rescale(x, training=True), y))
Bu yaklaşımla, yığın halinde artırılmış görüntü sağlayan bir veri kümesi oluşturmak için Dataset.map kullanırsınız. Bu durumda:
- Veri büyütme, CPU'da eşzamansız olarak gerçekleşir ve engellemez. Aşağıda gösterilen
Dataset.prefetchkullanarak veri ön işleme ile modelinizin GPU'daki eğitimini üst üste getirebilirsiniz. - Bu durumda,
Model.saveçağırdığınızda ön işleme katmanları modelle birlikte dışa aktarılmayacaktır. Kaydetmeden veya sunucu tarafında yeniden uygulamadan önce bunları modelinize eklemeniz gerekir. Eğitimden sonra, dışa aktarmadan önce ön işleme katmanlarını ekleyebilirsiniz.
İlk seçeneğin bir örneğini Görüntü sınıflandırma eğitiminde bulabilirsiniz. Burada ikinci seçeneği gösterelim.
Ön işleme katmanlarını veri kümelerine uygulayın
Daha önce oluşturduğunuz Keras ön işleme katmanlarıyla eğitim, doğrulama ve test veri kümelerini yapılandırın. Ayrıca, G/Ç bloke olmadan diskten toplu işler elde etmek için paralel okumalar ve arabelleğe alınmış önceden getirme kullanarak veri kümelerini performans için yapılandıracaksınız. ( tf.data API kılavuzuyla Daha iyi performans bölümünde daha fazla veri kümesi performansı öğrenin.)
batch_size = 32
AUTOTUNE = tf.data.AUTOTUNE
def prepare(ds, shuffle=False, augment=False):
# Resize and rescale all datasets.
ds = ds.map(lambda x, y: (resize_and_rescale(x), y),
num_parallel_calls=AUTOTUNE)
if shuffle:
ds = ds.shuffle(1000)
# Batch all datasets.
ds = ds.batch(batch_size)
# Use data augmentation only on the training set.
if augment:
ds = ds.map(lambda x, y: (data_augmentation(x, training=True), y),
num_parallel_calls=AUTOTUNE)
# Use buffered prefetching on all datasets.
return ds.prefetch(buffer_size=AUTOTUNE)
train_ds = prepare(train_ds, shuffle=True, augment=True)
val_ds = prepare(val_ds)
test_ds = prepare(test_ds)
Model eğit
Tamamlanması için, şimdi az önce hazırladığınız veri kümelerini kullanarak bir modeli eğiteceksiniz.
Sıralı model, her birinde bir maksimum havuzlama katmanına ( tf.keras.layers.MaxPooling2D ) sahip üç evrişim bloğundan ( tf.keras.layers.Conv2D ) oluşur. Üstünde bir ReLU etkinleştirme işlevi ( 'relu' ) tarafından etkinleştirilen 128 birimlik tam bağlı bir katman ( tf.keras.layers.Dense ) vardır. Bu model doğruluk için ayarlanmamıştır (amaç size mekaniği göstermektir).
model = tf.keras.Sequential([
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes)
])
tf.keras.optimizers.Adam optimizer ve tf.keras.losses.SparseCategoricalCrossentropy kaybı işlevini seçin. Her eğitim dönemi için eğitim ve doğrulama doğruluğunu görüntülemek için, metrics bağımsız değişkenini Model.compile .
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
Birkaç dönem için tren:
epochs=5
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
Epoch 1/5 92/92 [==============================] - 13s 110ms/step - loss: 1.2768 - accuracy: 0.4622 - val_loss: 1.0929 - val_accuracy: 0.5640 Epoch 2/5 92/92 [==============================] - 3s 25ms/step - loss: 1.0579 - accuracy: 0.5749 - val_loss: 0.9711 - val_accuracy: 0.6349 Epoch 3/5 92/92 [==============================] - 3s 26ms/step - loss: 0.9677 - accuracy: 0.6291 - val_loss: 0.9764 - val_accuracy: 0.6431 Epoch 4/5 92/92 [==============================] - 3s 25ms/step - loss: 0.9150 - accuracy: 0.6468 - val_loss: 0.8906 - val_accuracy: 0.6431 Epoch 5/5 92/92 [==============================] - 3s 25ms/step - loss: 0.8636 - accuracy: 0.6604 - val_loss: 0.8233 - val_accuracy: 0.6730yer tutucu22 l10n-yer
loss, acc = model.evaluate(test_ds)
print("Accuracy", acc)
12/12 [==============================] - 5s 14ms/step - loss: 0.7922 - accuracy: 0.6948 Accuracy 0.6948229074478149
Özel veri büyütme
Ayrıca özel veri büyütme katmanları da oluşturabilirsiniz.
Eğitimin bu bölümü, bunu yapmanın iki yolunu gösterir:
- İlk önce bir
tf.keras.layers.Lambdakatmanı oluşturacaksınız. Bu, kısa kod yazmanın iyi bir yoludur. - Ardından, size daha fazla kontrol sağlayan alt sınıflama yoluyla yeni bir katman yazacaksınız.
Her iki katman da, bir olasılığa göre, bir görüntüdeki renkleri rasgele tersine çevirecektir.
def random_invert_img(x, p=0.5):
if tf.random.uniform([]) < p:
x = (255-x)
else:
x
return x
def random_invert(factor=0.5):
return layers.Lambda(lambda x: random_invert_img(x, factor))
random_invert = random_invert()
plt.figure(figsize=(10, 10))
for i in range(9):
augmented_image = random_invert(image)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_image[0].numpy().astype("uint8"))
plt.axis("off")
2022-01-26 05:09:53.045204: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045264: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045312: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045369: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045418: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045467: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045511: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.047630: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module

Ardından, alt sınıflara ayırarak özel bir katman uygulayın:
class RandomInvert(layers.Layer):
def __init__(self, factor=0.5, **kwargs):
super().__init__(**kwargs)
self.factor = factor
def call(self, x):
return random_invert_img(x)
_ = plt.imshow(RandomInvert()(image)[0])

Bu katmanların her ikisi de yukarıdaki seçenekler 1 ve 2'de açıklandığı gibi kullanılabilir.
tf.image kullanma
Yukarıdaki Keras ön işleme yardımcı programları uygundur. Ancak daha hassas kontrol için tf.data ve tf.image kullanarak kendi veri büyütme işlem hatlarınızı veya katmanlarınızı yazabilirsiniz. (Ayrıca TensorFlow Addons Image: Operations ve TensorFlow I/O: Color Space Conversions'a da göz atmak isteyebilirsiniz.)
Çiçekler veri kümesi daha önce veri artırma ile yapılandırıldığından, yeni başlamak için yeniden içe aktaralım:
(train_ds, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
Çalışmak için bir görüntü alın:
image, label = next(iter(train_ds))
_ = plt.imshow(image)
_ = plt.title(get_label_name(label))
2022-01-26 05:09:59.918847: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.

Orijinal ve artırılmış görüntüleri yan yana görselleştirmek ve karşılaştırmak için aşağıdaki işlevi kullanalım:
def visualize(original, augmented):
fig = plt.figure()
plt.subplot(1,2,1)
plt.title('Original image')
plt.imshow(original)
plt.subplot(1,2,2)
plt.title('Augmented image')
plt.imshow(augmented)
Veri büyütme
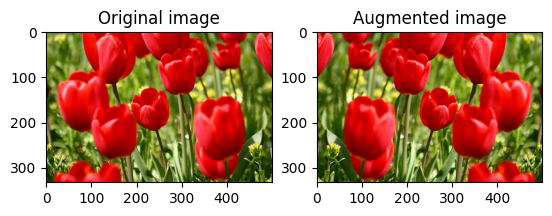
Bir resmi çevir
tf.image.flip_left_right ile bir görüntüyü dikey veya yatay olarak çevirin:
flipped = tf.image.flip_left_right(image)
visualize(image, flipped)
Gri tonlamalı bir görüntü
Bir görüntüyü tf.image.rgb_to_grayscale ile gri tonlama yapabilirsiniz:
grayscaled = tf.image.rgb_to_grayscale(image)
visualize(image, tf.squeeze(grayscaled))
_ = plt.colorbar()

Bir görüntüyü doyurun
Bir doygunluk faktörü sağlayarak bir görüntüyü tf.image.adjust_saturation ile doyurun:
saturated = tf.image.adjust_saturation(image, 3)
visualize(image, saturated)
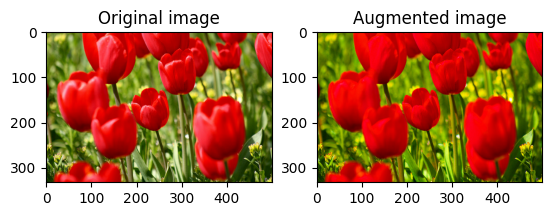
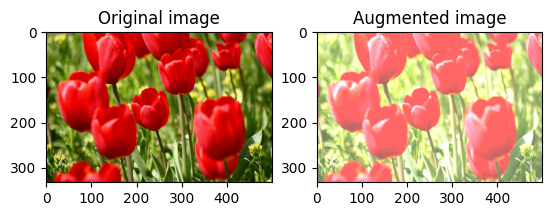
Görüntü parlaklığını değiştir
Bir parlaklık faktörü sağlayarak görüntünün parlaklığını tf.image.adjust_brightness ile değiştirin:
bright = tf.image.adjust_brightness(image, 0.4)
visualize(image, bright)
Resmi ortala kırp
tf.image.central_crop kullanarak görüntüyü ortadan istediğiniz bölüme kadar kırpın:
cropped = tf.image.central_crop(image, central_fraction=0.5)
visualize(image, cropped)
Bir görüntüyü döndürme
tf.image.rot90 ile bir görüntüyü 90 derece döndürün:
rotated = tf.image.rot90(image)
visualize(image, rotated)

rastgele dönüşümler
Görüntülere rastgele dönüşümler uygulamak, veri kümesini daha da genelleştirmeye ve genişletmeye yardımcı olabilir. Mevcut tf.image API, bu tür sekiz rastgele görüntü işlemi (ops) sağlar:
-
tf.image.stateless_random_brightness -
tf.image.stateless_random_contrast -
tf.image.stateless_random_crop -
tf.image.stateless_random_flip_left_right -
tf.image.stateless_random_flip_up_down -
tf.image.stateless_random_hue -
tf.image.stateless_random_jpeg_quality -
tf.image.stateless_random_saturation
Bu rastgele görüntü işlemleri tamamen işlevseldir: çıktı yalnızca girdiye bağlıdır. Bu, yüksek performanslı, deterministik girdi boru hatlarında kullanımlarını kolaylaştırır. Her adımda bir seed değeri girilmesini gerektirirler. Aynı seed verildiğinde, kaç kez çağrıldıklarından bağımsız olarak aynı sonuçları verirler.
Aşağıdaki bölümlerde şunları yapacaksınız:
- Bir görüntüyü dönüştürmek için rastgele görüntü işlemlerini kullanma örneklerini gözden geçirin.
- Bir eğitim veri kümesine rastgele dönüşümlerin nasıl uygulanacağını gösterin.
Görüntü parlaklığını rastgele değiştir
Bir parlaklık faktörü ve seed sağlayarak tf.image.stateless_random_brightness kullanarak image parlaklığını rastgele değiştirin. Parlaklık faktörü [-max_delta, max_delta) aralığında rastgele seçilir ve verilen seed ilişkilendirilir.
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_brightness = tf.image.stateless_random_brightness(
image, max_delta=0.95, seed=seed)
visualize(image, stateless_random_brightness)
Rastgele görüntü kontrastını değiştir
Bir kontrast aralığı ve seed sağlayarak tf.image.stateless_random_contrast kullanarak image kontrastını rastgele değiştirin. Kontrast aralığı [lower, upper] aralığında rastgele seçilir ve verilen seed ilişkilendirilir.
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_contrast = tf.image.stateless_random_contrast(
image, lower=0.1, upper=0.9, seed=seed)
visualize(image, stateless_random_contrast)
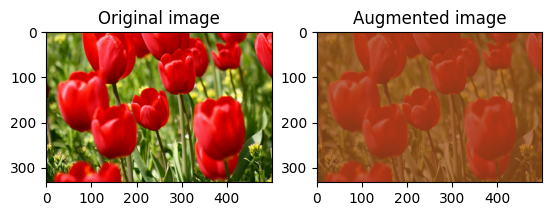
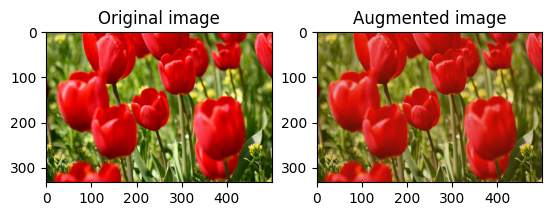
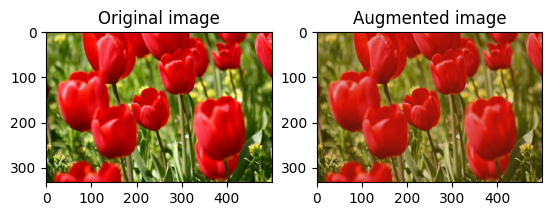
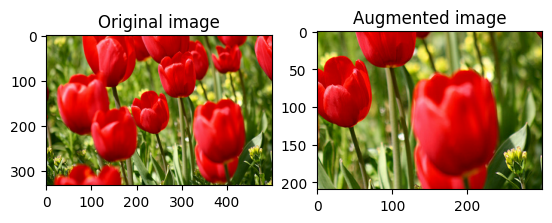
Bir resmi rastgele kırp
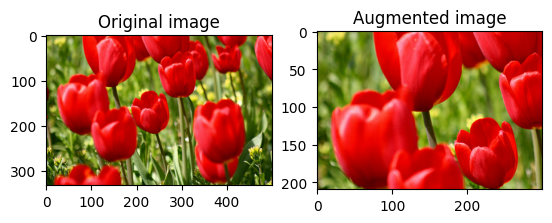
Hedef size ve seed sağlayarak tf.image.stateless_random_crop kullanarak image rastgele kırpın. image kırpılan kısım rastgele seçilen bir ofsettedir ve verilen seed ilişkilendirilir.
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_crop = tf.image.stateless_random_crop(
image, size=[210, 300, 3], seed=seed)
visualize(image, stateless_random_crop)
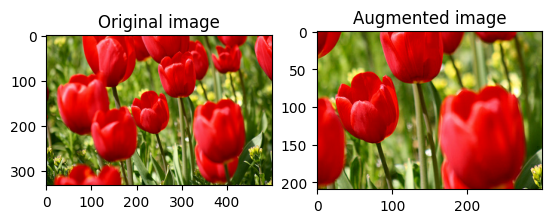
Bir veri kümesine büyütme uygulama
Önceki bölümlerde değiştirilmiş olmaları ihtimaline karşı önce görüntü veri setini tekrar indirelim.
(train_datasets, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
Ardından, görüntüleri yeniden boyutlandırmak ve yeniden ölçeklendirmek için bir yardımcı program işlevi tanımlayın. Bu işlev, veri kümesindeki görüntülerin boyutunu ve ölçeğini birleştirmede kullanılacaktır:
def resize_and_rescale(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, [IMG_SIZE, IMG_SIZE])
image = (image / 255.0)
return image, label
Rastgele dönüşümleri görüntülere uygulayabilen augment işlevini de tanımlayalım. Bu fonksiyon bir sonraki adımda veri setinde kullanılacaktır.
def augment(image_label, seed):
image, label = image_label
image, label = resize_and_rescale(image, label)
image = tf.image.resize_with_crop_or_pad(image, IMG_SIZE + 6, IMG_SIZE + 6)
# Make a new seed.
new_seed = tf.random.experimental.stateless_split(seed, num=1)[0, :]
# Random crop back to the original size.
image = tf.image.stateless_random_crop(
image, size=[IMG_SIZE, IMG_SIZE, 3], seed=seed)
# Random brightness.
image = tf.image.stateless_random_brightness(
image, max_delta=0.5, seed=new_seed)
image = tf.clip_by_value(image, 0, 1)
return image, label
Seçenek 1: tf.data.experimental.Counter'ı kullanma
Bir tf.data.experimental.Counter nesnesi oluşturun (buna counter diyelim) ve veri kümesini (counter, counter) ile Dataset.zip . Bu, veri kümesindeki her görüntünün, daha sonra rastgele dönüşümler için seed değeri olarak augment işlevine geçirilebilecek counter dayalı benzersiz bir değerle (şekil (2,) ) ilişkilendirilmesini sağlayacaktır.
# Create a `Counter` object and `Dataset.zip` it together with the training set.
counter = tf.data.experimental.Counter()
train_ds = tf.data.Dataset.zip((train_datasets, (counter, counter)))
augment işlevini eğitim veri kümesiyle eşleştirin:
train_ds = (
train_ds
.shuffle(1000)
.map(augment, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
val_ds = (
val_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
test_ds = (
test_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
Seçenek 2: tf.random.Generator'ı kullanma
- Başlangıç
seeddeğerine sahip birtf.random.Generatornesnesi oluşturun. Aynı oluşturucu nesnesindemake_seedsişlevinin çağrılması her zaman yeni, benzersiz birseeddeğeri döndürür. - Aşağıdakileri sağlayan bir sarmalayıcı işlevi tanımlayın: 1)
make_seedsişlevini çağırır; ve 2) rastgele dönüşümler için yeni oluşturulanseeddeğeriniaugmentişlevine iletir.
# Create a generator.
rng = tf.random.Generator.from_seed(123, alg='philox')
# Create a wrapper function for updating seeds.
def f(x, y):
seed = rng.make_seeds(2)[0]
image, label = augment((x, y), seed)
return image, label
f sarmalayıcı işlevini eğitim veri kümesiyle ve resize_and_rescale işlevini doğrulama ve test kümeleriyle eşleyin:
train_ds = (
train_datasets
.shuffle(1000)
.map(f, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
val_ds = (
val_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
test_ds = (
test_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
Bu veri kümeleri şimdi daha önce gösterildiği gibi bir modeli eğitmek için kullanılabilir.
Sonraki adımlar
Bu öğretici, Keras ön işleme katmanları ve tf.image kullanılarak veri büyütmeyi gösterdi.
- Modelinizin içine ön işleme katmanlarını nasıl ekleyeceğinizi öğrenmek için Görüntü sınıflandırma öğreticisine bakın.
- Ayrıca, Temel metin sınıflandırma eğitiminde gösterildiği gibi, ön işleme katmanlarının metni sınıflandırmanıza nasıl yardımcı olabileceğini öğrenmek de ilginizi çekebilir.
- Bu kılavuzda
tf.datahakkında daha fazla bilgi edinebilir ve giriş işlem hatlarınızı performans için nasıl yapılandıracağınızı buradan öğrenebilirsiniz.