| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub | |
Обзор
TensorFlow реализует подмножество NumPy API , доступное как tf.experimental.numpy . Это позволяет запускать код NumPy, ускоренный TensorFlow, а также предоставляет доступ ко всем API-интерфейсам TensorFlow.
Настраивать
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow.experimental.numpy as tnp
import timeit
print("Using TensorFlow version %s" % tf.__version__)
Using TensorFlow version 2.6.0
Включение поведения NumPy
Чтобы использовать tnp в качестве NumPy, включите поведение NumPy для TensorFlow:
tnp.experimental_enable_numpy_behavior()
Этот вызов включает продвижение типа в TensorFlow, а также изменяет вывод типа при преобразовании литералов в тензоры, чтобы более строго следовать стандарту NumPy.
Массив TensorFlow NumPy ND
Экземпляр tf.experimental.numpy.ndarray , называемый ND Array , представляет собой многомерный плотный массив заданного dtype размещенный на определенном устройстве. Это псевдоним tf.Tensor . Ознакомьтесь с классом массива ND, чтобы узнать о полезных методах, таких как ndarray.T , ndarray.reshape , ndarray.ravel и других.
Сначала создайте объект массива ND, а затем вызовите различные методы.
# Create an ND array and check out different attributes.
ones = tnp.ones([5, 3], dtype=tnp.float32)
print("Created ND array with shape = %s, rank = %s, "
"dtype = %s on device = %s\n" % (
ones.shape, ones.ndim, ones.dtype, ones.device))
# `ndarray` is just an alias to `tf.Tensor`.
print("Is `ones` an instance of tf.Tensor: %s\n" % isinstance(ones, tf.Tensor))
# Try commonly used member functions.
print("ndarray.T has shape %s" % str(ones.T.shape))
print("narray.reshape(-1) has shape %s" % ones.reshape(-1).shape)
Created ND array with shape = (5, 3), rank = 2, dtype = <dtype: 'float32'> on device = /job:localhost/replica:0/task:0/device:GPU:0 Is `ones` an instance of tf.Tensor: True ndarray.T has shape (3, 5) narray.reshape(-1) has shape (15,)
Тип акции
API-интерфейсы TensorFlow NumPy имеют четко определенную семантику для преобразования литералов в массив ND, а также для выполнения повышения типа на входах массива ND. Пожалуйста, смотрите np.result_type для более подробной информации.
API-интерфейсы tf.Tensor оставляют входные данные tf.Tensor без изменений и не выполняют для них повышение типа, в то время как API-интерфейсы TensorFlow NumPy продвигают все входные данные в соответствии с правилами продвижения типов NumPy. В следующем примере вы выполните продвижение типа. Во-первых, запустите сложение на входах массива ND разных типов и обратите внимание на типы вывода. Ни одно из этих рекламных акций не будет разрешено API TensorFlow.
print("Type promotion for operations")
values = [tnp.asarray(1, dtype=d) for d in
(tnp.int32, tnp.int64, tnp.float32, tnp.float64)]
for i, v1 in enumerate(values):
for v2 in values[i + 1:]:
print("%s + %s => %s" %
(v1.dtype.name, v2.dtype.name, (v1 + v2).dtype.name))
Type promotion for operations int32 + int64 => int64 int32 + float32 => float64 int32 + float64 => float64 int64 + float32 => float64 int64 + float64 => float64 float32 + float64 => float64
Наконец, преобразуйте литералы в массив ND с помощью ndarray.asarray и обратите внимание на полученный тип.
print("Type inference during array creation")
print("tnp.asarray(1).dtype == tnp.%s" % tnp.asarray(1).dtype.name)
print("tnp.asarray(1.).dtype == tnp.%s\n" % tnp.asarray(1.).dtype.name)
Type inference during array creation tnp.asarray(1).dtype == tnp.int64 tnp.asarray(1.).dtype == tnp.float64
При преобразовании литералов в массив ND NumPy предпочитает широкие типы, такие как tnp.int64 и tnp.float64 . Напротив, tf.convert_to_tensor предпочитает tf.int32 и tf.float32 для преобразования констант в tf.Tensor . API TensorFlow NumPy придерживаются поведения NumPy для целых чисел. Что касается чисел с плавающей запятой, аргумент prefer_float32 в tf.float64 позволяет вам контролировать, следует ли предпочесть tf.float32 experimental_enable_numpy_behavior (по умолчанию False ). Например:
tnp.experimental_enable_numpy_behavior(prefer_float32=True)
print("When prefer_float32 is True:")
print("tnp.asarray(1.).dtype == tnp.%s" % tnp.asarray(1.).dtype.name)
print("tnp.add(1., 2.).dtype == tnp.%s" % tnp.add(1., 2.).dtype.name)
tnp.experimental_enable_numpy_behavior(prefer_float32=False)
print("When prefer_float32 is False:")
print("tnp.asarray(1.).dtype == tnp.%s" % tnp.asarray(1.).dtype.name)
print("tnp.add(1., 2.).dtype == tnp.%s" % tnp.add(1., 2.).dtype.name)
When prefer_float32 is True: tnp.asarray(1.).dtype == tnp.float32 tnp.add(1., 2.).dtype == tnp.float32 When prefer_float32 is False: tnp.asarray(1.).dtype == tnp.float64 tnp.add(1., 2.).dtype == tnp.float64
Вещание
Подобно TensorFlow, NumPy определяет богатую семантику для «широковещательных» значений. Вы можете ознакомиться с руководством по вещанию NumPy для получения дополнительной информации и сравнить его с семантикой вещания TensorFlow .
x = tnp.ones([2, 3])
y = tnp.ones([3])
z = tnp.ones([1, 2, 1])
print("Broadcasting shapes %s, %s and %s gives shape %s" % (
x.shape, y.shape, z.shape, (x + y + z).shape))
Broadcasting shapes (2, 3), (3,) and (1, 2, 1) gives shape (1, 2, 3)
Индексация
NumPy определяет очень сложные правила индексации. См. руководство по индексированию NumPy . Обратите внимание на использование массивов ND в качестве индексов ниже.
x = tnp.arange(24).reshape(2, 3, 4)
print("Basic indexing")
print(x[1, tnp.newaxis, 1:3, ...], "\n")
print("Boolean indexing")
print(x[:, (True, False, True)], "\n")
print("Advanced indexing")
print(x[1, (0, 0, 1), tnp.asarray([0, 1, 1])])
Basic indexing tf.Tensor( [[[16 17 18 19] [20 21 22 23]]], shape=(1, 2, 4), dtype=int64) Boolean indexing tf.Tensor( [[[ 0 1 2 3] [ 8 9 10 11]] [[12 13 14 15] [20 21 22 23]]], shape=(2, 2, 4), dtype=int64) Advanced indexing tf.Tensor([12 13 17], shape=(3,), dtype=int64)
# Mutation is currently not supported
try:
tnp.arange(6)[1] = -1
except TypeError:
print("Currently, TensorFlow NumPy does not support mutation.")
Currently, TensorFlow NumPy does not support mutation.
Пример модели
Далее вы можете увидеть, как создать модель и выполнить на ней вывод. Эта простая модель применяет слой relu, за которым следует линейная проекция. В последующих разделах будет показано, как вычислять градиенты для этой модели с помощью GradientTape от TensorFlow.
class Model(object):
"""Model with a dense and a linear layer."""
def __init__(self):
self.weights = None
def predict(self, inputs):
if self.weights is None:
size = inputs.shape[1]
# Note that type `tnp.float32` is used for performance.
stddev = tnp.sqrt(size).astype(tnp.float32)
w1 = tnp.random.randn(size, 64).astype(tnp.float32) / stddev
bias = tnp.random.randn(64).astype(tnp.float32)
w2 = tnp.random.randn(64, 2).astype(tnp.float32) / 8
self.weights = (w1, bias, w2)
else:
w1, bias, w2 = self.weights
y = tnp.matmul(inputs, w1) + bias
y = tnp.maximum(y, 0) # Relu
return tnp.matmul(y, w2) # Linear projection
model = Model()
# Create input data and compute predictions.
print(model.predict(tnp.ones([2, 32], dtype=tnp.float32)))
tf.Tensor( [[-1.7706785 1.1137733] [-1.7706785 1.1137733]], shape=(2, 2), dtype=float32)
TensorFlow NumPy и NumPy
TensorFlow NumPy реализует подмножество полной спецификации NumPy. Хотя со временем будет добавлено больше символов, есть систематические функции, которые не будут поддерживаться в ближайшем будущем. К ним относятся поддержка NumPy C API, интеграция Swig, порядок хранения Fortran, представления и stride_tricks , а также некоторые dtype (например np.recarray и np.object ). Дополнительные сведения см. в документации TensorFlow NumPy API .
Совместимость NumPy
Массивы TensorFlow ND могут взаимодействовать с функциями NumPy. Эти объекты реализуют интерфейс __array__ . NumPy использует этот интерфейс для преобразования аргументов функции в значения np.ndarray перед их обработкой.
Точно так же функции TensorFlow NumPy могут принимать входные данные разных типов, включая np.ndarray . Эти входные данные преобразуются в массив ND путем вызова для них ndarray.asarray .
Преобразование массива ND в np.ndarray и из него может инициировать фактическое копирование данных. Пожалуйста, смотрите раздел о буферных копиях для более подробной информации.
# ND array passed into NumPy function.
np_sum = np.sum(tnp.ones([2, 3]))
print("sum = %s. Class: %s" % (float(np_sum), np_sum.__class__))
# `np.ndarray` passed into TensorFlow NumPy function.
tnp_sum = tnp.sum(np.ones([2, 3]))
print("sum = %s. Class: %s" % (float(tnp_sum), tnp_sum.__class__))
sum = 6.0. Class: <class 'numpy.float64'> sum = 6.0. Class: <class 'tensorflow.python.framework.ops.EagerTensor'>
# It is easy to plot ND arrays, given the __array__ interface.
labels = 15 + 2 * tnp.random.randn(1, 1000)
_ = plt.hist(labels)
Буферные копии
Смешивание TensorFlow NumPy с кодом NumPy может привести к копированию данных. Это связано с тем, что у TensorFlow NumPy более строгие требования к выравниванию памяти, чем у NumPy.
Когда np.ndarray передается в TensorFlow NumPy, он проверяет требования к выравниванию и при необходимости запускает копию. При передаче буфера ЦП массива ND в NumPy, как правило, буфер удовлетворяет требованиям выравнивания, и NumPy не нужно создавать копию.
Массивы ND могут ссылаться на буферы, размещенные на устройствах, отличных от локальной памяти ЦП. В таких случаях вызов функции NumPy запускает копии по сети или устройству по мере необходимости.
Учитывая это, смешивание с вызовами API NumPy, как правило, следует выполнять с осторожностью, и пользователь должен следить за накладными расходами на копирование данных. Чередование вызовов TensorFlow NumPy с вызовами TensorFlow, как правило, безопасно и позволяет избежать копирования данных. Дополнительные сведения см. в разделе о совместимости TensorFlow .
Приоритет оператора
TensorFlow NumPy определяет __array_priority__ выше, чем у NumPy. Это означает, что для операторов, включающих как массив ND, так и np.ndarray , первый будет иметь приоритет, т. е. ввод np.ndarray будет преобразован в массив ND, и будет вызвана реализация оператора TensorFlow NumPy.
x = tnp.ones([2]) + np.ones([2])
print("x = %s\nclass = %s" % (x, x.__class__))
x = tf.Tensor([2. 2.], shape=(2,), dtype=float64) class = <class 'tensorflow.python.framework.ops.EagerTensor'>
ТФ NumPy и TensorFlow
TensorFlow NumPy построен поверх TensorFlow и, следовательно, легко взаимодействует с TensorFlow.
tf.Tensor и массив ND
Массив ND является псевдонимом tf.Tensor , поэтому, очевидно, их можно смешивать без запуска реальных копий данных.
x = tf.constant([1, 2])
print(x)
# `asarray` and `convert_to_tensor` here are no-ops.
tnp_x = tnp.asarray(x)
print(tnp_x)
print(tf.convert_to_tensor(tnp_x))
# Note that tf.Tensor.numpy() will continue to return `np.ndarray`.
print(x.numpy(), x.numpy().__class__)
tf.Tensor([1 2], shape=(2,), dtype=int32) tf.Tensor([1 2], shape=(2,), dtype=int32) tf.Tensor([1 2], shape=(2,), dtype=int32) [1 2] <class 'numpy.ndarray'>
Совместимость с TensorFlow
Массив ND можно передать API-интерфейсам TensorFlow, поскольку массив ND — это просто псевдоним для tf.Tensor . Как упоминалось ранее, такое взаимодействие не создает копий данных, даже для данных, размещенных на ускорителях или удаленных устройствах.
И наоборот, объекты tf.Tensor можно передавать в API-интерфейсы tf.experimental.numpy без копирования данных.
# ND array passed into TensorFlow function.
tf_sum = tf.reduce_sum(tnp.ones([2, 3], tnp.float32))
print("Output = %s" % tf_sum)
# `tf.Tensor` passed into TensorFlow NumPy function.
tnp_sum = tnp.sum(tf.ones([2, 3]))
print("Output = %s" % tnp_sum)
Output = tf.Tensor(6.0, shape=(), dtype=float32) Output = tf.Tensor(6.0, shape=(), dtype=float32)
Градиенты и якобианы: tf.GradientTape
GradientTape от TensorFlow можно использовать для обратного распространения через код TensorFlow и TensorFlow NumPy.
Используйте модель, созданную в разделе Пример модели , и вычислите градиенты и якобианы.
def create_batch(batch_size=32):
"""Creates a batch of input and labels."""
return (tnp.random.randn(batch_size, 32).astype(tnp.float32),
tnp.random.randn(batch_size, 2).astype(tnp.float32))
def compute_gradients(model, inputs, labels):
"""Computes gradients of squared loss between model prediction and labels."""
with tf.GradientTape() as tape:
assert model.weights is not None
# Note that `model.weights` need to be explicitly watched since they
# are not tf.Variables.
tape.watch(model.weights)
# Compute prediction and loss
prediction = model.predict(inputs)
loss = tnp.sum(tnp.square(prediction - labels))
# This call computes the gradient through the computation above.
return tape.gradient(loss, model.weights)
inputs, labels = create_batch()
gradients = compute_gradients(model, inputs, labels)
# Inspect the shapes of returned gradients to verify they match the
# parameter shapes.
print("Parameter shapes:", [w.shape for w in model.weights])
print("Gradient shapes:", [g.shape for g in gradients])
# Verify that gradients are of type ND array.
assert isinstance(gradients[0], tnp.ndarray)
Parameter shapes: [TensorShape([32, 64]), TensorShape([64]), TensorShape([64, 2])] Gradient shapes: [TensorShape([32, 64]), TensorShape([64]), TensorShape([64, 2])]
# Computes a batch of jacobians. Each row is the jacobian of an element in the
# batch of outputs w.r.t. the corresponding input batch element.
def prediction_batch_jacobian(inputs):
with tf.GradientTape() as tape:
tape.watch(inputs)
prediction = model.predict(inputs)
return prediction, tape.batch_jacobian(prediction, inputs)
inp_batch = tnp.ones([16, 32], tnp.float32)
output, batch_jacobian = prediction_batch_jacobian(inp_batch)
# Note how the batch jacobian shape relates to the input and output shapes.
print("Output shape: %s, input shape: %s" % (output.shape, inp_batch.shape))
print("Batch jacobian shape:", batch_jacobian.shape)
Output shape: (16, 2), input shape: (16, 32) Batch jacobian shape: (16, 2, 32)
Компиляция трассировки: tf.function
tf.function работает путем «компилирования трассировки» кода, а затем оптимизации этих трассировок для повышения производительности. См. Введение в графы и функции .
tf.function также можно использовать для оптимизации кода TensorFlow NumPy. Вот простой пример, демонстрирующий ускорение. Обратите внимание, что тело кода tf.function включает вызовы API TensorFlow NumPy.
inputs, labels = create_batch(512)
print("Eager performance")
compute_gradients(model, inputs, labels)
print(timeit.timeit(lambda: compute_gradients(model, inputs, labels),
number=10) * 100, "ms")
print("\ntf.function compiled performance")
compiled_compute_gradients = tf.function(compute_gradients)
compiled_compute_gradients(model, inputs, labels) # warmup
print(timeit.timeit(lambda: compiled_compute_gradients(model, inputs, labels),
number=10) * 100, "ms")
Eager performance 1.291419400013183 ms tf.function compiled performance 0.5561202000080812 ms
Векторизация: tf.vectorized_map
TensorFlow имеет встроенную поддержку векторизации параллельных циклов, что позволяет ускорить работу на один-два порядка. Эти ускорения доступны через API tf.vectorized_map , а также применимы к коду TensorFlow NumPy.
Иногда полезно вычислить градиент каждого вывода в пакете относительно соответствующего входного элемента пакета. Такие вычисления можно эффективно выполнить с помощью tf.vectorized_map , как показано ниже.
@tf.function
def vectorized_per_example_gradients(inputs, labels):
def single_example_gradient(arg):
inp, label = arg
return compute_gradients(model,
tnp.expand_dims(inp, 0),
tnp.expand_dims(label, 0))
# Note that a call to `tf.vectorized_map` semantically maps
# `single_example_gradient` over each row of `inputs` and `labels`.
# The interface is similar to `tf.map_fn`.
# The underlying machinery vectorizes away this map loop which gives
# nice speedups.
return tf.vectorized_map(single_example_gradient, (inputs, labels))
batch_size = 128
inputs, labels = create_batch(batch_size)
per_example_gradients = vectorized_per_example_gradients(inputs, labels)
for w, p in zip(model.weights, per_example_gradients):
print("Weight shape: %s, batch size: %s, per example gradient shape: %s " % (
w.shape, batch_size, p.shape))
Weight shape: (32, 64), batch size: 128, per example gradient shape: (128, 32, 64) Weight shape: (64,), batch size: 128, per example gradient shape: (128, 64) Weight shape: (64, 2), batch size: 128, per example gradient shape: (128, 64, 2)
# Benchmark the vectorized computation above and compare with
# unvectorized sequential computation using `tf.map_fn`.
@tf.function
def unvectorized_per_example_gradients(inputs, labels):
def single_example_gradient(arg):
inp, label = arg
return compute_gradients(model,
tnp.expand_dims(inp, 0),
tnp.expand_dims(label, 0))
return tf.map_fn(single_example_gradient, (inputs, labels),
fn_output_signature=(tf.float32, tf.float32, tf.float32))
print("Running vectorized computation")
print(timeit.timeit(lambda: vectorized_per_example_gradients(inputs, labels),
number=10) * 100, "ms")
print("\nRunning unvectorized computation")
per_example_gradients = unvectorized_per_example_gradients(inputs, labels)
print(timeit.timeit(lambda: unvectorized_per_example_gradients(inputs, labels),
number=10) * 100, "ms")
Running vectorized computation 0.5265710999992734 ms Running unvectorized computation 40.35122630002661 ms
Размещение устройства
TensorFlow NumPy может размещать операции на процессорах, графических процессорах, TPU и удаленных устройствах. Он использует стандартные механизмы TensorFlow для размещения устройств. Ниже на простом примере показано, как составить список всех устройств, а затем выполнить некоторые вычисления для конкретного устройства.
TensorFlow также имеет API-интерфейсы для репликации вычислений между устройствами и выполнения коллективных сокращений, которые здесь не рассматриваются.
Список устройств
tf.config.list_logical_devices и tf.config.list_physical_devices можно использовать для определения того, какие устройства использовать.
print("All logical devices:", tf.config.list_logical_devices())
print("All physical devices:", tf.config.list_physical_devices())
# Try to get the GPU device. If unavailable, fallback to CPU.
try:
device = tf.config.list_logical_devices(device_type="GPU")[0]
except IndexError:
device = "/device:CPU:0"
All logical devices: [LogicalDevice(name='/device:CPU:0', device_type='CPU'), LogicalDevice(name='/device:GPU:0', device_type='GPU')] All physical devices: [PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU'), PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
Размещение операций: tf.device
Операции можно размещать на устройстве, вызывая его в области видимости tf.device .
print("Using device: %s" % str(device))
# Run operations in the `tf.device` scope.
# If a GPU is available, these operations execute on the GPU and outputs are
# placed on the GPU memory.
with tf.device(device):
prediction = model.predict(create_batch(5)[0])
print("prediction is placed on %s" % prediction.device)
Using device: LogicalDevice(name='/device:GPU:0', device_type='GPU') prediction is placed on /job:localhost/replica:0/task:0/device:GPU:0
Копирование массивов ND между устройствами: tnp.copy
Вызов tnp.copy , помещенный в область определенного устройства, скопирует данные на это устройство, если только данные уже не находятся на этом устройстве.
with tf.device("/device:CPU:0"):
prediction_cpu = tnp.copy(prediction)
print(prediction.device)
print(prediction_cpu.device)
/job:localhost/replica:0/task:0/device:GPU:0 /job:localhost/replica:0/task:0/device:CPU:0
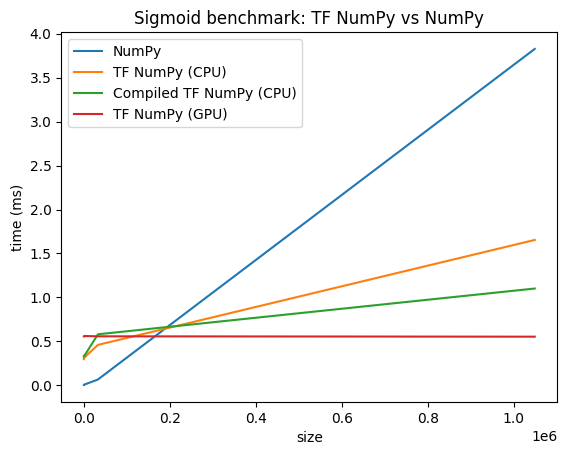
Сравнение производительности
TensorFlow NumPy использует высокооптимизированные ядра TensorFlow, которые могут быть отправлены на ЦП, ГП и ТПУ. TensorFlow также выполняет множество оптимизаций компилятора, таких как слияние операций, которые приводят к улучшению производительности и памяти. См. раздел Оптимизация графа TensorFlow с помощью Grappler , чтобы узнать больше.
Однако TensorFlow имеет более высокие накладные расходы на операции диспетчеризации по сравнению с NumPy. Для рабочих нагрузок, состоящих из небольших операций (менее 10 микросекунд), эти накладные расходы могут доминировать во время выполнения, и NumPy может обеспечить лучшую производительность. В других случаях TensorFlow обычно должен обеспечивать лучшую производительность.
Запустите тест ниже, чтобы сравнить производительность NumPy и TensorFlow NumPy для разных размеров ввода.
def benchmark(f, inputs, number=30, force_gpu_sync=False):
"""Utility to benchmark `f` on each value in `inputs`."""
times = []
for inp in inputs:
def _g():
if force_gpu_sync:
one = tnp.asarray(1)
f(inp)
if force_gpu_sync:
with tf.device("CPU:0"):
tnp.copy(one) # Force a sync for GPU case
_g() # warmup
t = timeit.timeit(_g, number=number)
times.append(t * 1000. / number)
return times
def plot(np_times, tnp_times, compiled_tnp_times, has_gpu, tnp_times_gpu):
"""Plot the different runtimes."""
plt.xlabel("size")
plt.ylabel("time (ms)")
plt.title("Sigmoid benchmark: TF NumPy vs NumPy")
plt.plot(sizes, np_times, label="NumPy")
plt.plot(sizes, tnp_times, label="TF NumPy (CPU)")
plt.plot(sizes, compiled_tnp_times, label="Compiled TF NumPy (CPU)")
if has_gpu:
plt.plot(sizes, tnp_times_gpu, label="TF NumPy (GPU)")
plt.legend()
# Define a simple implementation of `sigmoid`, and benchmark it using
# NumPy and TensorFlow NumPy for different input sizes.
def np_sigmoid(y):
return 1. / (1. + np.exp(-y))
def tnp_sigmoid(y):
return 1. / (1. + tnp.exp(-y))
@tf.function
def compiled_tnp_sigmoid(y):
return tnp_sigmoid(y)
sizes = (2 ** 0, 2 ** 5, 2 ** 10, 2 ** 15, 2 ** 20)
np_inputs = [np.random.randn(size).astype(np.float32) for size in sizes]
np_times = benchmark(np_sigmoid, np_inputs)
with tf.device("/device:CPU:0"):
tnp_inputs = [tnp.random.randn(size).astype(np.float32) for size in sizes]
tnp_times = benchmark(tnp_sigmoid, tnp_inputs)
compiled_tnp_times = benchmark(compiled_tnp_sigmoid, tnp_inputs)
has_gpu = len(tf.config.list_logical_devices("GPU"))
if has_gpu:
with tf.device("/device:GPU:0"):
tnp_inputs = [tnp.random.randn(size).astype(np.float32) for size in sizes]
tnp_times_gpu = benchmark(compiled_tnp_sigmoid, tnp_inputs, 100, True)
else:
tnp_times_gpu = None
plot(np_times, tnp_times, compiled_tnp_times, has_gpu, tnp_times_gpu)