
| | |  GitHub에서 소스 보기 GitHub에서 소스 보기 |
JAX의 TensorFlow Probability(TFP)에는 이제 분산 수치 컴퓨팅을 위한 도구가 있습니다. 많은 수의 가속기로 확장하기 위해 도구는 "단일 프로그램 다중 데이터" 패러다임(줄여서 SPMD)을 사용하여 코드 작성을 중심으로 구축되었습니다.
이 노트북에서는 "SPMD로 생각"하는 방법을 살펴보고 TPU 포드 또는 GPU 클러스터와 같은 구성으로 확장하기 위한 새로운 TFP 추상화를 소개합니다. 이 코드를 직접 실행하는 경우 TPU 런타임을 선택해야 합니다.
먼저 최신 버전의 TFP, JAX 및 TF를 설치합니다.
설치
pip install jaxlib --upgrade -q 2>&1 1> /dev/nullpip install tfp-nightly[jax] --upgrade -q 2>&1 1> /dev/nullpip install tf-nightly-cpu -q -I 2>&1 1> /dev/nullpip install jax -I -q --upgrade 2>&1 1>/dev/null
일부 JAX 유틸리티와 함께 일부 일반 라이브러리를 가져올 것입니다.
설정 및 가져오기
import functools
import collections
import contextlib
import jax
import jax.numpy as jnp
from jax import lax
from jax import random
import jax.numpy as jnp
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import tensorflow_datasets as tfds
from tensorflow_probability.substrates import jax as tfp
sns.set(style='white')
INFO:tensorflow:Enabling eager execution INFO:tensorflow:Enabling v2 tensorshape INFO:tensorflow:Enabling resource variables INFO:tensorflow:Enabling tensor equality INFO:tensorflow:Enabling control flow v2
또한 편리한 TFP 별칭을 설정합니다. 새로운 추상화는 현재 제공됩니다 tfp.experimental.distribute 및 tfp.experimental.mcmc .
tfd = tfp.distributions
tfb = tfp.bijectors
tfm = tfp.mcmc
tfed = tfp.experimental.distribute
tfde = tfp.experimental.distributions
tfem = tfp.experimental.mcmc
Root = tfed.JointDistributionCoroutine.Root
노트북을 TPU에 연결하기 위해 JAX의 다음 도우미를 사용합니다. 연결되었는지 확인하기 위해 장치 수(8개)를 출력합니다.
from jax.tools import colab_tpu
colab_tpu.setup_tpu()
print(f'Found {jax.device_count()} devices')
Found 8 devices
에 대한 간단한 소개 jax.pmap
TPU에 연결 한 후, 우리는 여덟 개 장치에 액세스 할 수 있습니다. 그러나 JAX 코드를 열심히 실행할 때 JAX는 기본적으로 하나만 계산을 실행합니다.
많은 장치에서 계산을 실행하는 가장 간단한 방법은 각 장치가 맵의 하나의 인덱스를 실행하도록 하여 함수를 매핑하는 것입니다. JAX가 제공 jax.pmap 여러 기기에 기능을 매핑 하나로 기능을 온 ( "평행 맵")을 변화.
다음 예에서는 크기가 8인 배열을 만들고(사용 가능한 장치 수와 일치하도록) 5를 더하는 함수를 매핑합니다.
xs = jnp.arange(8.)
out = jax.pmap(lambda x: x + 5.)(xs)
print(type(out), out)
<class 'jax.interpreters.pxla.ShardedDeviceArray'> [ 5. 6. 7. 8. 9. 10. 11. 12.]
참고 우리는 받도록 ShardedDeviceArray 출력 배열 물리적 장치로 분할되어있는 것을 나타내는 입력을 다시.
jax.pmap 의미지도와 같은 역할을하지만, 그 동작을 수정 몇 가지 중요한 옵션이 있습니다. 기본적으로 pmap 함수에 대한 모든 입력에 매핑되는 가정, 그러나 우리는이 동작을 수정할 수 있습니다 in_axes 인수를.
xs = jnp.arange(8.)
y = 5.
# Map over the 0-axis of `xs` and don't map over `y`
out = jax.pmap(lambda x, y: x + y, in_axes=(0, None))(xs, y)
print(out)
[ 5. 6. 7. 8. 9. 10. 11. 12.]
유사하게 상기 out_axes 에 인수 pmap 모든 기기의 값을 리턴 할 것인지를 결정한다. 설정 out_axes 에 None 자동으로 1 장치의 값을 반환하고 우리가 값이 모든 장치에서 동일 확신하는 경우에만 사용되어야한다.
xs = jnp.ones(8) # Value is the same on each device
out = jax.pmap(lambda x: x + 1, out_axes=None)(xs)
print(out)
2.0
우리가 하고 싶은 것이 매핑된 순수 함수로 쉽게 표현할 수 없을 때 어떻게 될까요? 예를 들어 매핑할 축을 가로질러 합계를 계산하려면 어떻게 해야 합니까? JAX는 더 흥미롭고 복잡한 분산 프로그램을 작성할 수 있도록 장치 간에 통신하는 기능인 "집합체"를 제공합니다. 정확히 어떻게 작동하는지 이해하기 위해 SPMD를 소개합니다.
SPMD란 무엇입니까?
단일 프로그램 다중 데이터(SPMD)는 단일 프로그램(즉, 동일한 코드)이 여러 장치에서 동시에 실행되지만 실행 중인 각 프로그램에 대한 입력은 다를 수 있는 동시 프로그래밍 모델입니다.
우리의 프로그램이 입력의 간단한 기능 (같은 즉, 어떤 경우 x + 5 ) 우리가했던 것처럼, SPMD에서 프로그램을 실행 단지 그것을 통해 다른 데이터를 매핑한다 jax.pmap 이전. 그러나 우리는 기능을 "매핑"하는 것 이상을 수행할 수 있습니다. JAX는 장치 간에 통신하는 기능인 "집합체"를 제공합니다.
예를 들어 모든 장치에서 수량의 합계를 구하고 싶을 수 있습니다. 우리가 그렇게하기 전에, 우리는이에 걸쳐 우리에게있는 거 매핑을 축에 이름을 할당해야 pmap . 우리는 다음 사용 lax.psum 우리가 이상 합산하고 축 우리가 이름을 식별 보장 장치를 통해 합을 수행하기 위해 ( "병렬 합") 함수를.
def f(x):
out = lax.psum(x, axis_name='i')
return out
xs = jnp.arange(8.) # Length of array matches number of devices
jax.pmap(f, axis_name='i')(xs)
ShardedDeviceArray([28., 28., 28., 28., 28., 28., 28., 28.], dtype=float32)
psum 공동 집계의 값 x 각 장치 및지도를 통해 그 값이 즉 동기화 out 인 28. 각 장치에. 우리는 더 이상 단순한 "지도"를 수행하지 않지만 각 장치의 계산이 이제 집합체를 사용하는 제한된 방식이지만 다른 장치의 동일한 계산과 상호 작용할 수 있는 SPMD 프로그램을 실행하고 있습니다. 이 시나리오에서는 사용할 수 out_axes = None 하기 때문에, psum 값을 동기화합니다.
def f(x):
out = lax.psum(x, axis_name='i')
return out
jax.pmap(f, axis_name='i', out_axes=None)(jnp.arange(8.))
ShardedDeviceArray(28., dtype=float32)
SPMD를 사용하면 모든 TPU 구성의 모든 장치에서 동시에 실행되는 하나의 프로그램을 작성할 수 있습니다. 8개의 TPU 코어에서 기계 학습을 수행하는 데 사용되는 것과 동일한 코드를 수백에서 수천 개의 코어가 있는 TPU 포드에서 사용할 수 있습니다! 에 대한 자세한 튜토리얼 jax.pmap 및 SPMD, 당신하여 참조 할 수 JAX 101 튜토리얼 .
대규모 MCMC
이 노트북에서는 베이지안 추론에 MCMC(Markov Chain Monte Carlo) 방법을 사용하는 데 중점을 둡니다. MCMC를 위해 많은 장치를 활용하는 방법이 있을 수 있지만 이 노트북에서는 다음 두 가지에 중점을 둘 것입니다.
- 다른 장치에서 독립적인 Markov 체인을 실행합니다. 이 경우는 매우 간단하며 바닐라 TFP로 할 수 있습니다.
- 장치 간에 데이터 세트 분할. 이 경우는 조금 더 복잡하고 최근에 추가된 TFP 기계가 필요합니다.
독립 사슬
MCMC를 사용하여 문제에 대해 베이지안 추론을 수행하고 여러 장치(예: 각 장치에 2개)에서 여러 체인을 병렬로 실행하고 싶다고 가정해 보겠습니다. 이것은 우리가 장치 전반에 걸쳐 "매핑"할 수 있는 프로그램으로 밝혀졌습니다. 즉, 집합체가 필요하지 않은 프로그램입니다. 각 프로그램이 다른 Markov 체인을 실행하도록 하기 위해(같은 것을 실행하는 것과 반대), 우리는 랜덤 시드에 대해 다른 값을 각 장치에 전달합니다.
2차원 가우스 분포에서 샘플링하는 장난감 문제로 시도해 보겠습니다. TFP의 기존 MCMC 기능을 즉시 사용할 수 있습니다. 일반적으로 모든 장치에서 실행되는 것과 첫 번째 장치에서만 실행되는 것을 보다 명확하게 구별하기 위해 매핑된 함수 내부에 대부분의 논리를 넣으려고 합니다.
def run(seed):
target_log_prob = tfd.Sample(tfd.Normal(0., 1.), 2).log_prob
initial_state = jnp.zeros([2, 2]) # 2 chains
kernel = tfm.HamiltonianMonteCarlo(target_log_prob, 1e-1, 10)
def trace_fn(state, pkr):
return target_log_prob(state)
states, log_prob = tfm.sample_chain(
num_results=1000,
num_burnin_steps=1000,
kernel=kernel,
current_state=initial_state,
trace_fn=trace_fn,
seed=seed
)
return states, log_prob
그 자체로, run 기능은 무 임의 초기에 소요 (방법 무 임의성 작업을보고, 당신은 읽을 수 JAX의에 TFP 노트북 또는 참조 JAX (101) 튜토리얼 ). 매핑 run 다른 씨앗을 통해 여러 독립적 인 마르코프 체인을 실행에 발생합니다.
states, log_probs = jax.pmap(run)(random.split(random.PRNGKey(0), 8))
print(states.shape, log_probs.shape)
# states is (8 devices, 1000 samples, 2 chains, 2 dimensions)
# log_prob is (8 devices, 1000 samples, 2 chains)
(8, 1000, 2, 2) (8, 1000, 2)
이제 각 장치에 해당하는 추가 축이 어떻게 생겼는지 주목하십시오. 치수를 재정렬하고 평평하게 하여 16개 사슬의 축을 얻을 수 있습니다.
states = states.transpose([0, 2, 1, 3]).reshape([-1, 1000, 2])
log_probs = log_probs.transpose([0, 2, 1]).reshape([-1, 1000])
fig, ax = plt.subplots(1, 2, figsize=(10, 5))
ax[0].plot(log_probs.T, alpha=0.4)
ax[1].scatter(*states.reshape([-1, 2]).T, alpha=0.1)
plt.show()
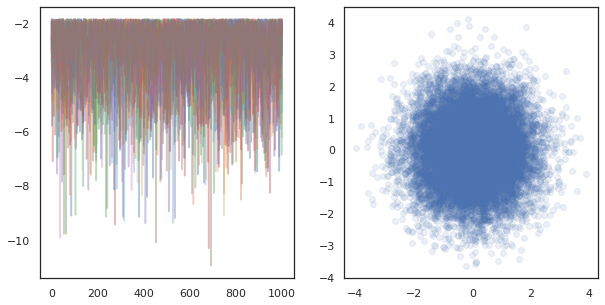
많은 장치에 독립적 인 체인을 실행하는 경우, 그것은 쉽게로의 pmap 사용하는 기능을 통해 -ing tfp.mcmc , 보장은 우리가 각 장치에 임의 화에 대해 서로 다른 값을 전달합니다.
데이터 샤딩
MCMC를 수행할 때 목표 분포는 종종 데이터 세트를 조건화하여 얻은 사후 분포이며, 비정규화된 로그 밀도를 계산하려면 각 관찰된 데이터에 대한 합산 가능성이 포함됩니다.
매우 큰 데이터 세트의 경우 단일 장치에서 하나의 체인을 실행하는 것조차 엄청난 비용이 들 수 있습니다. 그러나 여러 장치에 액세스할 수 있는 경우 사용 가능한 컴퓨팅을 더 잘 활용하기 위해 장치 간에 데이터 세트를 분할할 수 있습니다.
우리가 분산됩니다 데이터 세트와 MCMC을하려는 경우, 우리는 그렇지 않으면 각 장치가 자신의 잘못된 목표 MCMC을하고있을 것입니다, 우리는 각 장치에 계산 표준화 로그 밀도 즉, 모든 데이터에 대한 밀도 전체를 나타냅니다 확인해야합니다 분포. 이를 위해, TFP는 지금 (즉, 새로운 도구를 가지고 tfp.experimental.distribute 및 tfp.experimental.mcmc ) 그 계산 "분산됩니다"로그 확률을 활성화하고 그들과 함께 MCMC을하고.
샤딩된 배포판
코어 추상화 TFP 이제 분산됩니다 로그 probabiliities이다 산출 제공 Sharded 입력으로 분포 걸리고 SPMD 컨텍스트에서 실행될 때 특정 특성을 갖는 새로운 분포를 반환 메타 분포. Sharded 의 삶 tfp.experimental.distribute .
직관적으로하는 Sharded 기기에서 "분할"왔다 랜덤 변수들의 세트에 분배 대응한다. 각 장치에서 다른 샘플을 생성하고 개별적으로 다른 로그 밀도를 가질 수 있습니다. 대안 적으로, Sharded 플레이트 크기는 장치의 수는 그래픽 모델에서 용어 "플레이트"로 분배 대응한다.
샘플링 Sharded 분포를
우리가에서 샘플 경우 Normal 프로그램의 존재의 유통 pmap 각 장치에서 동일한 시드를 사용하여 -ed, 우리는 각각의 디바이스에서 동일한 샘플을 얻을 것이다. 다음 함수는 장치 간에 동기화되는 단일 랜덤 변수를 샘플링하는 것으로 생각할 수 있습니다.
# `pmap` expects at least one value to be mapped over, so we provide a dummy one
def f(seed, _):
return tfd.Normal(0., 1.).sample(seed=seed)
jax.pmap(f, in_axes=(None, 0))(random.PRNGKey(0), jnp.arange(8.))
ShardedDeviceArray([-0.20584236, -0.20584236, -0.20584236, -0.20584236,
-0.20584236, -0.20584236, -0.20584236, -0.20584236], dtype=float32)
우리는 포장하는 경우 tfd.Normal(0., 1.) 로모그래퍼 tfed.Sharded , 우리는 논리적으로 지금 (각 장치에 하나씩) 8 개 가지 확률 변수가 있고, 따라서 같은 종자를 전달에도 불구하고, 각각에 대해 다른 샘플을 생산합니다 .
def f(seed, _):
return tfed.Sharded(tfd.Normal(0., 1.), shard_axis_name='i').sample(seed=seed)
jax.pmap(f, in_axes=(None, 0), axis_name='i')(random.PRNGKey(0), jnp.arange(8.))
ShardedDeviceArray([ 1.2152631 , 0.7818249 , 0.32549605, 0.6828047 ,
1.3973192 , -0.57830244, 0.37862757, 2.7706041 ], dtype=float32)
단일 장치에서 이 분포의 등가 표현은 8개의 독립적인 정규 샘플에 불과합니다. 샘플의 값 (달라도 tfed.Sharded 약간 다르게 의사 난수 생성 않음), 이들은 동일한 분포를 나타내는 양.
dist = tfd.Sample(tfd.Normal(0., 1.), jax.device_count())
dist.sample(seed=random.PRNGKey(0))
DeviceArray([ 0.08086783, -0.38624594, -0.3756545 , 1.668957 ,
-1.2758069 , 2.1192007 , -0.85821325, 1.1305912 ], dtype=float32)
(A)의 기록 밀도를 가지고 Sharded 분포
SPMD 컨텍스트에서 정규 분포에서 샘플의 로그 밀도를 계산할 때 어떤 일이 발생하는지 봅시다.
def f(seed, _):
dist = tfd.Normal(0., 1.)
x = dist.sample(seed=seed)
return x, dist.log_prob(x)
jax.pmap(f, in_axes=(None, 0))(random.PRNGKey(0), jnp.arange(8.))
(ShardedDeviceArray([-0.20584236, -0.20584236, -0.20584236, -0.20584236,
-0.20584236, -0.20584236, -0.20584236, -0.20584236], dtype=float32),
ShardedDeviceArray([-0.94012403, -0.94012403, -0.94012403, -0.94012403,
-0.94012403, -0.94012403, -0.94012403, -0.94012403], dtype=float32))
각 샘플은 각 장치에서 동일하므로 각 장치에서도 동일한 밀도를 계산합니다. 직관적으로 여기에서는 단일 정규 분포 변수에 대한 분포만 있습니다.
A의 Sharded 분포, 우리는 우리가 계산할 때, 8 개 확률 변수에 걸쳐 분포를 가지고 log_prob 시료를, 우리는 각각의 기록 밀도들 각각 동안, 기기에서, 합계. (이 총 log_prob 값은 위에서 계산된 단일 log_prob보다 큽니다.)
def f(seed, _):
dist = tfed.Sharded(tfd.Normal(0., 1.), shard_axis_name='i')
x = dist.sample(seed=seed)
return x, dist.log_prob(x)
sample, log_prob = jax.pmap(f, in_axes=(None, 0), axis_name='i')(
random.PRNGKey(0), jnp.arange(8.))
print('Sample:', sample)
print('Log Prob:', log_prob)
Sample: [ 1.2152631 0.7818249 0.32549605 0.6828047 1.3973192 -0.57830244 0.37862757 2.7706041 ] Log Prob: [-13.7349205 -13.7349205 -13.7349205 -13.7349205 -13.7349205 -13.7349205 -13.7349205 -13.7349205]
동등한 "분할되지 않은" 분포는 동일한 로그 밀도를 생성합니다.
dist = tfd.Sample(tfd.Normal(0., 1.), jax.device_count())
dist.log_prob(sample)
DeviceArray(-13.7349205, dtype=float32)
Sharded 분포는 상이한 값을 생성하는 sample 의 각 장치에 있지만 동일한 값 얻을 log_prob 각 장치에있다. 무슨 일이야? Sharded 분포는 않는다 psum 있도록 내부적 log_prob 값은 장치에 걸쳐 동기화된다. 왜 이런 행동을 원할까요? 우리는 각각의 디바이스에서 동일한 MCMC 체인을 실행하는 경우, 우리는 원하는 target_log_prob 계산에 어떤 임의의 변수가 장치에 걸쳐 분산됩니다 경우에도, 각 장치에서 동일 할 수 있습니다.
또한, Sharded 기기에서 기울기가 올바른지 분포 보장하지만은 전이 함수의 일부로서 기록 밀도 함수의 기울기를 가지고 적절한 샘플을 생성 HMC 등이 알고리즘을 보장한다.
분산됩니다 JointDistribution 의
우리는 여러있는 모델 만들 수 있습니다 Sharded 사용하여 임의의 변수를 JointDistribution 의 (JDS). 불행하게도, Sharded 분포를 안전하게 바닐라와 함께 사용할 수 없습니다 tfd.JointDistribution 의,하지만 tfp.experimental.distribute 수출은 같은 동작합니다 JDS "패치" Sharded 분포를.
def f(seed, _):
dist = tfed.JointDistributionSequential([
tfd.Normal(0., 1.),
tfed.Sharded(tfd.Normal(0., 1.), shard_axis_name='i'),
])
x = dist.sample(seed=seed)
return x, dist.log_prob(x)
jax.pmap(f, in_axes=(None, 0), axis_name='i')(random.PRNGKey(0), jnp.arange(8.))
([ShardedDeviceArray([1.6121525, 1.6121525, 1.6121525, 1.6121525, 1.6121525,
1.6121525, 1.6121525, 1.6121525], dtype=float32),
ShardedDeviceArray([ 0.8690128 , -0.83167845, 1.2209264 , 0.88412696,
0.76478404, -0.66208494, -0.0129658 , 0.7391483 ], dtype=float32)],
ShardedDeviceArray([-12.214451, -12.214451, -12.214451, -12.214451,
-12.214451, -12.214451, -12.214451, -12.214451], dtype=float32))
이 분산됩니다 JDS는 모두 가질 수 Sharded 구성 요소와 바닐라 TFP 분포를. 샤딩되지 않은 배포판의 경우 각 장치에서 동일한 샘플을 얻고 샤딩된 배포판의 경우 다른 샘플을 얻습니다. log_prob 각 기기가 아니라 동기화된다.
MCMC와 Sharded 분포
우리는 어떻게 생각합니까 Sharded MCMC의 맥락에서 배포판? 우리는 다음과 같이 표현 될 수있는 생식 모델이있는 경우 JointDistribution , 우리는에서 "파편"에 해당 모델의 일부 축을 선택할 수 있습니다. 일반적으로 모델의 하나의 랜덤 변수는 관찰된 데이터에 해당하며, 장치 간에 분할하려는 큰 데이터 세트가 있는 경우 데이터 포인트와 연결된 변수도 분할되기를 원합니다. 우리는 또한 우리가 샤딩하는 관찰과 일대일인 "로컬" 랜덤 변수를 가질 수 있으므로 이러한 랜덤 변수를 추가로 샤딩해야 합니다.
우리는의 사용의 예를 통해 갈거야 Sharded 이 섹션의 TFP MCMC와 분포를. 우리는 간단한 베이지안 로지스틱 회귀 예제로 시작하고,이에 대한 몇 가지 사용 사례를 시연 목적으로, 행렬 인수 분해 예제로 결론을 것이다 distribute 라이브러리입니다.
예: MNIST에 대한 베이지안 로지스틱 회귀
우리는 큰 데이터 세트에 대해 베이지안 로지스틱 회귀를 수행하고 싶습니다. 모델은 종래 갖는다 \(p(\theta)\) 회귀 가중치를 통해, 및 우도 \(p(y_i | \theta, x_i)\) 모든 데이터 합산된다 \(\{x_i, y_i\}_{i = 1}^N\) 총 조인트 기록 밀도를 얻었다. 우리는 우리의 데이터를 샤딩 경우에, 우리는 관찰 된 확률 변수 샤딩 것 \(x_i\) 및 \(y_i\) 우리의 모델.
MNIST 분류를 위해 다음 베이지안 로지스틱 회귀 모델을 사용합니다.
\[ \begin{align*} w &\sim \mathcal{N}(0, 1) \\ b &\sim \mathcal{N}(0, 1) \\ y_i | w, b, x_i &\sim \textrm{Categorical}(w^T x_i + b) \end{align*} \]
TensorFlow Datasets를 사용하여 MNIST를 로드해 보겠습니다.
mnist = tfds.as_numpy(tfds.load('mnist', batch_size=-1))
raw_train_images, train_labels = mnist['train']['image'], mnist['train']['label']
train_images = raw_train_images.reshape([raw_train_images.shape[0], -1]) / 255.
raw_test_images, test_labels = mnist['test']['image'], mnist['test']['label']
test_images = raw_test_images.reshape([raw_test_images.shape[0], -1]) / 255.
Downloading and preparing dataset mnist/3.0.1 (download: 11.06 MiB, generated: 21.00 MiB, total: 32.06 MiB) to /root/tensorflow_datasets/mnist/3.0.1... WARNING:absl:Dataset mnist is hosted on GCS. It will automatically be downloaded to your local data directory. If you'd instead prefer to read directly from our public GCS bucket (recommended if you're running on GCP), you can instead pass `try_gcs=True` to `tfds.load` or set `data_dir=gs://tfds-data/datasets`. HBox(children=(FloatProgress(value=0.0, description='Dl Completed...', max=4.0, style=ProgressStyle(descriptio… Dataset mnist downloaded and prepared to /root/tensorflow_datasets/mnist/3.0.1. Subsequent calls will reuse this data.
60000개의 훈련 이미지가 있지만 8개의 사용 가능한 코어를 활용하여 8가지 방식으로 분할해 보겠습니다. 우리는 편리한 사용합니다 shard 유틸리티 기능을.
def shard_value(x):
x = x.reshape((jax.device_count(), -1, *x.shape[1:]))
return jax.pmap(lambda x: x)(x) # pmap will physically place values on devices
shard = functools.partial(jax.tree_map, shard_value)
sharded_train_images, sharded_train_labels = shard((train_images, train_labels))
print(sharded_train_images.shape, sharded_train_labels.shape)
(8, 7500, 784) (8, 7500)
계속하기 전에 TPU의 정밀도와 HMC에 미치는 영향에 대해 빠르게 논의하겠습니다. TPU를 사용하여 낮은 행렬 곱셈 실행 bfloat16 속도 정확도. bfloat16 행렬 곱셈은 종종 많은 깊은 학습 애플리케이션에 충분하지만 현대차와 함께 사용할 때, 우리는 경험적으로 낮은 정밀도 거부의 원인이 궤도를 분기로 이어질 수 발견했다. 약간의 추가 계산 비용으로 더 높은 정밀도의 행렬 곱셈을 사용할 수 있습니다.
우리 matmul 정밀도를 높이기 위해, 우리는 사용할 수 jax.default_matmul_precision 와 장식 "tensorfloat32" (더 높은 정밀도 우리가 사용할 수있는 정밀도를 "float32" 정밀도).
의는 지금 우리의 정의하자 run (각 장치에서 동일 할) 임의의 씨앗에 걸릴 기능, MNIST의 파편을. 이 기능은 앞서 언급한 모델을 구현한 다음 TFP의 기본 MCMC 기능을 사용하여 단일 체인을 실행합니다. 우리는 확실히 장식을 만들거야 run 와 jax.default_matmul_precision 아래 특정 예에서, 우리는 단지뿐만 아니라 사용할 수 있지만, 확인 행렬 곱셈이 더 높은 정밀도로 실행하기 위해 장식 jnp.dot(images, w, precision=lax.Precision.HIGH) .
# We can use `out_axes=None` in the `pmap` because the results will be the same
# on every device.
@functools.partial(jax.pmap, axis_name='data', in_axes=(None, 0), out_axes=None)
@jax.default_matmul_precision('tensorfloat32')
def run(seed, data):
images, labels = data # a sharded dataset
num_examples, dim = images.shape
num_classes = 10
def model_fn():
w = yield Root(tfd.Sample(tfd.Normal(0., 1.), [dim, num_classes]))
b = yield Root(tfd.Sample(tfd.Normal(0., 1.), [num_classes]))
logits = jnp.dot(images, w) + b
yield tfed.Sharded(tfd.Independent(tfd.Categorical(logits=logits), 1),
shard_axis_name='data')
model = tfed.JointDistributionCoroutine(model_fn)
init_seed, sample_seed = random.split(seed)
initial_state = model.sample(seed=init_seed)[:-1] # throw away `y`
def target_log_prob(*state):
return model.log_prob((*state, labels))
def accuracy(w, b):
logits = images.dot(w) + b
preds = logits.argmax(axis=-1)
# We take the average accuracy across devices by using `lax.pmean`
return lax.pmean((preds == labels).mean(), 'data')
kernel = tfm.HamiltonianMonteCarlo(target_log_prob, 1e-2, 100)
kernel = tfm.DualAveragingStepSizeAdaptation(kernel, 500)
def trace_fn(state, pkr):
return (
target_log_prob(*state),
accuracy(*state),
pkr.new_step_size)
states, trace = tfm.sample_chain(
num_results=1000,
num_burnin_steps=1000,
current_state=initial_state,
kernel=kernel,
trace_fn=trace_fn,
seed=sample_seed
)
return states, trace
jax.pmap JIT 컴파일을 포함하지만 컴파일 된 함수는 첫 번째 호출 후 캐시됩니다. 우리는 전화 할게 run 하고 컴파일을 캐시 할 수있는 출력을 무시합니다.
%%time
output = run(random.PRNGKey(0), (sharded_train_images, sharded_train_labels))
jax.tree_map(lambda x: x.block_until_ready(), output)
CPU times: user 24.5 s, sys: 48.2 s, total: 1min 12s Wall time: 1min 54s
우리는 지금 전화 할게 run 다시 실제 실행에 걸리는 시간을 확인합니다.
%%time
states, trace = run(random.PRNGKey(0), (sharded_train_images, sharded_train_labels))
jax.tree_map(lambda x: x.block_until_ready(), trace)
CPU times: user 13.1 s, sys: 45.2 s, total: 58.3 s Wall time: 1min 43s
우리는 200,000 도약 단계를 실행하고 있으며, 각 단계는 전체 데이터 세트에 대한 기울기를 계산합니다. 8개의 코어로 계산을 분할하면 초당 약 2,100에포크인 약 95초 만에 200,000에포크의 훈련을 계산할 수 있습니다!
각 샘플의 로그 밀도와 각 샘플의 정확도를 플롯해 보겠습니다.
fig, ax = plt.subplots(1, 3, figsize=(15, 5))
ax[0].plot(trace[0])
ax[0].set_title('Log Prob')
ax[1].plot(trace[1])
ax[1].set_title('Accuracy')
ax[2].plot(trace[2])
ax[2].set_title('Step Size')
plt.show()
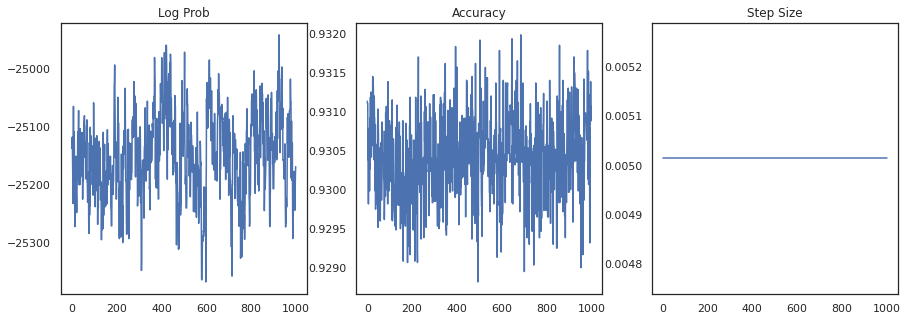
샘플을 앙상블하면 베이지안 모델 평균을 계산하여 성능을 향상시킬 수 있습니다.
@functools.partial(jax.pmap, axis_name='data', in_axes=(0, None), out_axes=None)
def bayesian_model_average(data, states):
images, labels = data
logits = jax.vmap(lambda w, b: images.dot(w) + b)(*states)
probs = jax.nn.softmax(logits, axis=-1)
bma_accuracy = (probs.mean(axis=0).argmax(axis=-1) == labels).mean()
avg_accuracy = (probs.argmax(axis=-1) == labels).mean()
return lax.pmean(bma_accuracy, axis_name='data'), lax.pmean(avg_accuracy, axis_name='data')
sharded_test_images, sharded_test_labels = shard((test_images, test_labels))
bma_acc, avg_acc = bayesian_model_average((sharded_test_images, sharded_test_labels), states)
print(f'Average Accuracy: {avg_acc}')
print(f'BMA Accuracy: {bma_acc}')
print(f'Accuracy Improvement: {bma_acc - avg_acc}')
Average Accuracy: 0.9188529253005981 BMA Accuracy: 0.9264000058174133 Accuracy Improvement: 0.0075470805168151855
베이지안 모델 평균은 정확도를 거의 1% 증가시킵니다!
예: MovieLens 추천 시스템
이제 다양한 영화에 대한 사용자 및 평점 모음인 MovieLens 권장 사항 데이터 세트를 사용하여 추론을 시도해 보겠습니다. 구체적으로, 우리는 MovieLens 같이 나타낼 수 \(N \times M\) 시계 매트릭스 \(W\) \(N\) 사용자와의 개수 \(M\) 영화의 개수이다; 우리는 기대 \(N > M\). 의 항목 \(W_{ij}\) 사용자 여부를 나타내는 부울입니다 \(i\) 영화 보았다 \(j\). MovieLens는 사용자 평가를 제공하지만 문제를 단순화하기 위해 무시합니다.
먼저 데이터 세트를 로드합니다. 우리는 100만 등급의 버전을 사용할 것입니다.
movielens = tfds.as_numpy(tfds.load('movielens/1m-ratings', batch_size=-1))
GENRES = ['Action', 'Adventure', 'Animation', 'Children', 'Comedy',
'Crime', 'Documentary', 'Drama', 'Fantasy', 'Film-Noir',
'Horror', 'IMAX', 'Musical', 'Mystery', 'Romance', 'Sci-Fi',
'Thriller', 'Unknown', 'War', 'Western', '(no genres listed)']
Downloading and preparing dataset movielens/1m-ratings/0.1.0 (download: Unknown size, generated: Unknown size, total: Unknown size) to /root/tensorflow_datasets/movielens/1m-ratings/0.1.0... HBox(children=(FloatProgress(value=1.0, bar_style='info', description='Dl Completed...', max=1.0, style=Progre… HBox(children=(FloatProgress(value=1.0, bar_style='info', description='Dl Size...', max=1.0, style=ProgressSty… HBox(children=(FloatProgress(value=1.0, bar_style='info', description='Extraction completed...', max=1.0, styl… HBox(children=(FloatProgress(value=1.0, bar_style='info', max=1.0), HTML(value=''))) Shuffling and writing examples to /root/tensorflow_datasets/movielens/1m-ratings/0.1.0.incompleteYKA3TG/movielens-train.tfrecord HBox(children=(FloatProgress(value=0.0, max=1000209.0), HTML(value=''))) Dataset movielens downloaded and prepared to /root/tensorflow_datasets/movielens/1m-ratings/0.1.0. Subsequent calls will reuse this data.
우리는 시계 매트릭스 얻기 위해 데이터 세트의 일부 전처리을 다하겠습니다 \(W\).
raw_movie_ids = movielens['train']['movie_id']
raw_user_ids = movielens['train']['user_id']
genres = movielens['train']['movie_genres']
movie_ids, movie_labels = pd.factorize(movielens['train']['movie_id'])
user_ids, user_labels = pd.factorize(movielens['train']['user_id'])
num_movies = movie_ids.max() + 1
num_users = user_ids.max() + 1
movie_titles = dict(zip(movielens['train']['movie_id'],
movielens['train']['movie_title']))
movie_genres = dict(zip(movielens['train']['movie_id'],
genres))
movie_id_to_title = [movie_titles[movie_labels[id]].decode('utf-8')
for id in range(num_movies)]
movie_id_to_genre = [GENRES[movie_genres[movie_labels[id]][0]] for id in range(num_movies)]
watch_matrix = np.zeros((num_users, num_movies), bool)
watch_matrix[user_ids, movie_ids] = True
print(watch_matrix.shape)
(6040, 3706)
우리는을위한 생산적인 모델을 정의 할 수 있습니다 \(W\)단순 확률 행렬 인수 분해 모델을 사용. 우리는 잠재적 인 가정 \(N \times D\) 사용자 행렬 \(U\) 과 잠재 \(M \times D\) 영화 매트릭스 \(V\)시계 매트릭스에 대한 베르누이의 logits을 생산 곱한, \(W\). 우리는 또한 사용자와 영화에 대한 바이어스 벡터 포함됩니다 \(u\) 및 \(v\).
\[ \begin{align*} U &\sim \mathcal{N}(0, 1) \quad u \sim \mathcal{N}(0, 1)\\ V &\sim \mathcal{N}(0, 1) \quad v \sim \mathcal{N}(0, 1)\\ W_{ij} &\sim \textrm{Bernoulli}\left(\sigma\left(\left(UV^T\right)_{ij} + u_i + v_j\right)\right) \end{align*} \]
이것은 꽤 큰 행렬입니다. 6040 사용자 및 3706 영화는 2,200만 개 이상의 항목이 있는 매트릭스로 이어집니다. 이 모델을 샤딩하는 방법은 무엇입니까? 글쎄, 우리가 가정하면 \(N > M\) (영화보다 더 많은 사용자가 IE), 다음 각 장치가 사용자의 하위 집합에 해당하는 시계 행렬의 덩어리를 할 것이다, 그래서 사용자 축에서 시계 행렬을 샤딩하는 것이 만들 것 . 앞의 예와는 달리, 우리는 또한 최대 샤딩해야합니다 \(U\) 는 각 사용자에 대한 삽입이 있기 때문에 각 장치의 파편에 대한 책임을 질 것입니다, 그래서, 매트릭스를 \(U\) 과의 파편 \(W\). 반면에, \(V\) unsharded되며 장치에서 동기화 될 수있다.
sharded_watch_matrix = shard(watch_matrix)
우리가 작성하기 전에 run ,의 신속 로컬 확률 변수의 샤딩와 추가 문제 논의하자 \(U\). 현대차, 바닐라 실행할 때 tfp.mcmc.HamiltonianMonteCarlo 체인의 상태의 각 요소에 대해 커널 샘플 것 운동량을. 이전에는 샤딩되지 않은 랜덤 변수만 해당 상태의 일부였으며 모멘텀은 각 장치에서 동일했습니다. 우리는 지금 분산됩니다있을 때 \(U\), 우리는 각 장치에 다른 운동량 샘플링 할 필요가 \(U\)위한 동일한 운동량 샘플링하면서, \(V\). 이를 위해, 우리는 사용할 수 tfp.experimental.mcmc.PreconditionedHamiltonianMonteCarlo 으로 Sharded 운동량 분포. 우리가 계속해서 병렬 계산을 일류로 만들면서, 예를 들어 HMC 커널에 샤드니스 표시기를 가져옴으로써 이것을 단순화할 수 있습니다.
def make_run(*,
axis_name,
dim=20,
num_chains=2,
prior_variance=1.,
step_size=1e-2,
num_leapfrog_steps=100,
num_burnin_steps=1000,
num_results=500,
):
@functools.partial(jax.pmap, in_axes=(None, 0), axis_name=axis_name)
@jax.default_matmul_precision('tensorfloat32')
def run(key, watch_matrix):
num_users, num_movies = watch_matrix.shape
Sharded = functools.partial(tfed.Sharded, shard_axis_name=axis_name)
def prior_fn():
user_embeddings = yield Root(Sharded(tfd.Sample(tfd.Normal(0., 1.), [num_users, dim]), name='user_embeddings'))
user_bias = yield Root(Sharded(tfd.Sample(tfd.Normal(0., 1.), [num_users]), name='user_bias'))
movie_embeddings = yield Root(tfd.Sample(tfd.Normal(0., 1.), [num_movies, dim], name='movie_embeddings'))
movie_bias = yield Root(tfd.Sample(tfd.Normal(0., 1.), [num_movies], name='movie_bias'))
return (user_embeddings, user_bias, movie_embeddings, movie_bias)
prior = tfed.JointDistributionCoroutine(prior_fn)
def model_fn():
user_embeddings, user_bias, movie_embeddings, movie_bias = yield from prior_fn()
logits = (jnp.einsum('...nd,...md->...nm', user_embeddings, movie_embeddings)
+ user_bias[..., :, None] + movie_bias[..., None, :])
yield Sharded(tfd.Independent(tfd.Bernoulli(logits=logits), 2), name='watch')
model = tfed.JointDistributionCoroutine(model_fn)
init_key, sample_key = random.split(key)
initial_state = prior.sample(seed=init_key, sample_shape=num_chains)
def target_log_prob(*state):
return model.log_prob((*state, watch_matrix))
momentum_distribution = tfed.JointDistributionSequential([
Sharded(tfd.Independent(tfd.Normal(jnp.zeros([num_chains, num_users, dim]), 1.), 2)),
Sharded(tfd.Independent(tfd.Normal(jnp.zeros([num_chains, num_users]), 1.), 1)),
tfd.Independent(tfd.Normal(jnp.zeros([num_chains, num_movies, dim]), 1.), 2),
tfd.Independent(tfd.Normal(jnp.zeros([num_chains, num_movies]), 1.), 1),
])
# We pass in momentum_distribution here to ensure that the momenta for
# user_embeddings and user_bias are also sharded
kernel = tfem.PreconditionedHamiltonianMonteCarlo(target_log_prob, step_size,
num_leapfrog_steps,
momentum_distribution=momentum_distribution)
num_adaptation_steps = int(0.8 * num_burnin_steps)
kernel = tfm.DualAveragingStepSizeAdaptation(kernel, num_adaptation_steps)
def trace_fn(state, pkr):
return {
'log_prob': target_log_prob(*state),
'log_accept_ratio': pkr.inner_results.log_accept_ratio,
}
return tfm.sample_chain(
num_results, initial_state,
kernel=kernel,
num_burnin_steps=num_burnin_steps,
trace_fn=trace_fn,
seed=sample_key)
return run
컴파일 된 캐시되면 우리는 다시 실행됩니다 run .
%%time
run = make_run(axis_name='data')
output = run(random.PRNGKey(0), sharded_watch_matrix)
jax.tree_map(lambda x: x.block_until_ready(), output)
CPU times: user 56 s, sys: 1min 24s, total: 2min 20s Wall time: 3min 35s
이제 컴파일 오버헤드 없이 다시 실행합니다.
%%time
states, trace = run(random.PRNGKey(0), sharded_watch_matrix)
jax.tree_map(lambda x: x.block_until_ready(), trace)
CPU times: user 28.8 s, sys: 1min 16s, total: 1min 44s Wall time: 3min 1s
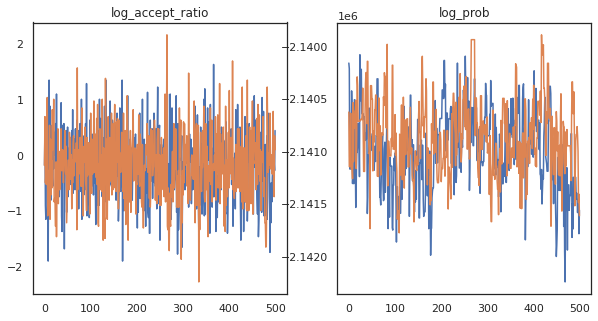
약 3분 만에 약 150,000번의 도약을 완료한 것 같으니 초당 약 83번의 도약을! 샘플의 허용 비율과 로그 밀도를 플롯해 보겠습니다.
fig, axs = plt.subplots(1, len(trace), figsize=(5 * len(trace), 5))
for ax, (key, val) in zip(axs, trace.items()):
ax.plot(val[0]) # Indexing into a sharded array, each element is the same
ax.set_title(key);
이제 Markov 체인에서 몇 가지 샘플을 얻었으므로 이를 사용하여 몇 가지 예측을 만들어 보겠습니다. 먼저 각 구성 요소를 추출해 보겠습니다. 기억 user_embeddings 및 user_bias 우리가 우리의 연결할 필요가 있으므로, 디바이스에 걸쳐 분할 ShardedArray 모두 얻을 수 있습니다. 반면에, movie_embeddings 및 movie_bias 모든 장치에서 동일, 그래서 우리는 첫 번째 파편에서 값을 선택할 수 있습니다. 우리는 정기적으로 사용합니다 numpy CPU에 TPU에의 뒷면에서 값을 복사 할 수 있습니다.
user_embeddings = np.concatenate(np.array(states.user_embeddings, np.float32), axis=2)
user_bias = np.concatenate(np.array(states.user_bias, np.float32), axis=2)
movie_embeddings = np.array(states.movie_embeddings[0], dtype=np.float32)
movie_bias = np.array(states.movie_bias[0], dtype=np.float32)
samples = (user_embeddings, user_bias, movie_embeddings, movie_bias)
print(f'User embeddings: {user_embeddings.shape}')
print(f'User bias: {user_bias.shape}')
print(f'Movie embeddings: {movie_embeddings.shape}')
print(f'Movie bias: {movie_bias.shape}')
User embeddings: (500, 2, 6040, 20) User bias: (500, 2, 6040) Movie embeddings: (500, 2, 3706, 20) Movie bias: (500, 2, 3706)
이 샘플에서 캡처된 불확실성을 활용하는 간단한 추천 시스템을 구축해 보겠습니다. 먼저 시청 확률에 따라 영화의 순위를 매기는 함수를 작성해 보겠습니다.
@jax.jit
def recommend(sample, user_id):
user_embeddings, user_bias, movie_embeddings, movie_bias = sample
movie_logits = (
jnp.einsum('d,md->m', user_embeddings[user_id], movie_embeddings)
+ user_bias[user_id] + movie_bias)
return movie_logits.argsort()[::-1]
이제 모든 샘플을 반복하고 각 샘플에 대해 사용자가 아직 시청하지 않은 최고 순위의 영화를 선택하는 함수를 작성할 수 있습니다. 그런 다음 샘플에서 모든 추천 영화의 수를 볼 수 있습니다.
def get_recommendations(user_id):
movie_ids = []
already_watched = set(jnp.arange(num_movies)[watch_matrix[user_id] == 1])
for i in range(500):
for j in range(2):
sample = jax.tree_map(lambda x: x[i, j], samples)
ranking = recommend(sample, user_id)
for movie_id in ranking:
if int(movie_id) not in already_watched:
movie_ids.append(movie_id)
break
return movie_ids
def plot_recommendations(movie_ids, ax=None):
titles = collections.Counter([movie_id_to_title[i] for i in movie_ids])
ax = ax or plt.gca()
names, counts = zip(*sorted(titles.items(), key=lambda x: -x[1]))
ax.bar(names, counts)
ax.set_xticklabels(names, rotation=90)
영화를 가장 많이 본 사용자와 가장 적게 본 사용자를 예로 들어 보겠습니다.
user_watch_counts = watch_matrix.sum(axis=1)
user_most = user_watch_counts.argmax()
user_least = user_watch_counts.argmin()
print(user_watch_counts[user_most], user_watch_counts[user_least])
2314 20
우리는 우리의 시스템에 대한 자세한 확신을 가지고 희망 user_most 보다 user_least 우리가 영화의 정렬에 대한 자세한 정보가 주어진, user_most 볼 가능성이 있습니다.
fig, ax = plt.subplots(1, 2, figsize=(20, 10))
most_recommendations = get_recommendations(user_most)
plot_recommendations(most_recommendations, ax=ax[0])
ax[0].set_title('Recommendation for user_most')
least_recommendations = get_recommendations(user_least)
plot_recommendations(least_recommendations, ax=ax[1])
ax[1].set_title('Recommendation for user_least');
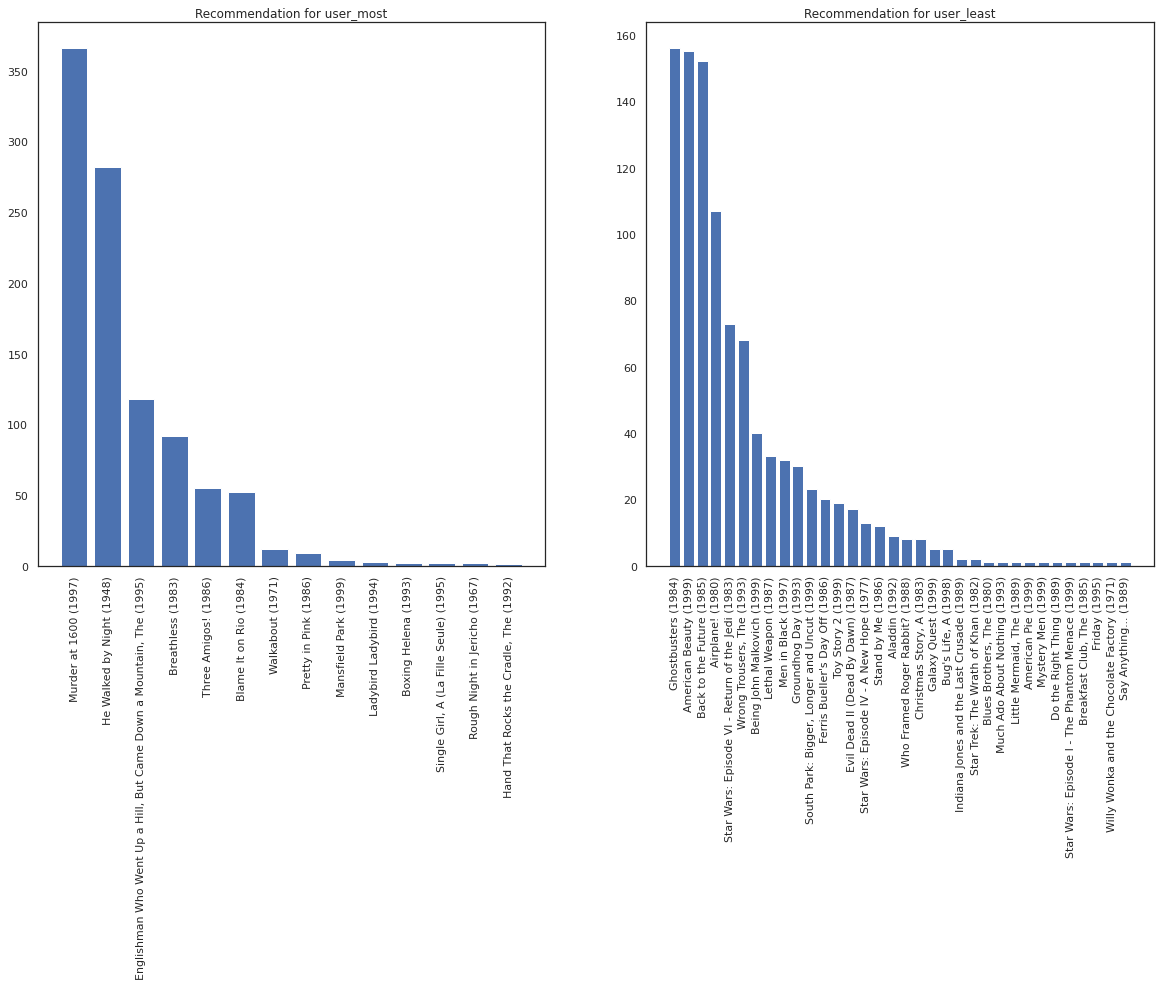
우리는 우리의 권고에 더 많은 차이가 있음을 볼 수 user_least 자신의 시계 환경 설정에서 우리의 추가 불확실성을 반영하는가.
추천 영화의 장르도 볼 수 있습니다.
most_genres = collections.Counter([movie_id_to_genre[i] for i in most_recommendations])
least_genres = collections.Counter([movie_id_to_genre[i] for i in least_recommendations])
fig, ax = plt.subplots(1, 2, figsize=(20, 10))
ax[0].bar(most_genres.keys(), most_genres.values())
ax[0].set_title('Genres recommended for user_most')
ax[1].bar(least_genres.keys(), least_genres.values())
ax[1].set_title('Genres recommended for user_least');
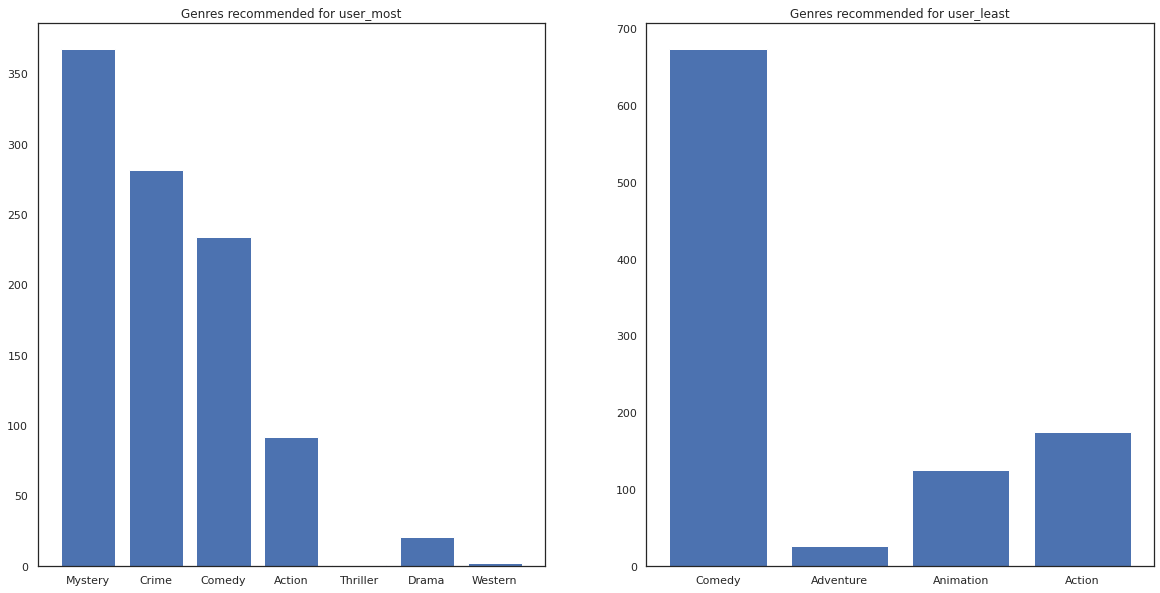
user_most 영화를 많이 볼 수 있으며, 반면 신비와 범죄와 같은보다 틈새 장르를 권장하고있다 user_least 많은 영화를 시청하지 않았으며 어떤 스큐 코미디와 액션 주류 영화를 추천했다.