
بررسی اجمالی
ویژگی اصلی TensorBoard رابط کاربری گرافیکی تعاملی آن است. با این حال، کاربران گاهی اوقات می خواهید به برنامه نویسی به عنوان خوانده شده سیاهههای مربوط داده های ذخیره شده در TensorBoard، برای اهداف مانند انجام تعقیبی تحلیل و ایجاد تصویری سفارشی از اطلاعات ثبت شده.
TensorBoard 2.3 با پشتیبانی از این مورد استفاده با tensorboard.data.experimental.ExperimentFromDev() . این اجازه می دهد دسترسی برنامه ای به TensorBoard را سیاهههای مربوط اسکالر . این صفحه استفاده اساسی از این API جدید را نشان می دهد.
برپایی
به منظور استفاده از API برنامه ریزی، مطمئن شوید که شما نصب pandas در کنار tensorboard .
ما استفاده از matplotlib و seaborn برای قطعه سفارشی در این راهنما، اما شما می توانید ابزار مورد نظر خود را به تجزیه و تحلیل و تجسم را انتخاب نمایید DataFrame است.
pip install tensorboard pandaspip install matplotlib seaborn
from packaging import version
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
from scipy import stats
import tensorboard as tb
major_ver, minor_ver, _ = version.parse(tb.__version__).release
assert major_ver >= 2 and minor_ver >= 3, \
"This notebook requires TensorBoard 2.3 or later."
print("TensorBoard version: ", tb.__version__)
TensorBoard version: 2.3.0a20200626
در حال بارگذاری بندی TensorBoard به عنوان یک pandas.DataFrame
هنگامی که یک logdir TensorBoard به TensorBoard.dev آپلود شده است، آن را می شود آنچه که ما به عنوان یک آزمایش مراجعه کنید. هر آزمایش دارای یک شناسه منحصر به فرد است که می توانید آن را در آدرس اینترنتی TensorBoard.dev آزمایش مشاهده کنید. : برای تظاهرات ما در زیر، ما یک آزمایش TensorBoard.dev در استفاده https://tensorboard.dev/experiment/c1KCv3X3QvGwaXfgX1c4tg
experiment_id = "c1KCv3X3QvGwaXfgX1c4tg"
experiment = tb.data.experimental.ExperimentFromDev(experiment_id)
df = experiment.get_scalars()
df
df است pandas.DataFrame که شامل تمام سیاهههای مربوط اسکالر آزمایش.
ستون از DataFrame عبارتند از:
-
run: هر مربوط اجرا به یک دایرکتوری فرعی logdir اصلی است. در این آزمایش ، هر اجرا از آموزش کامل یک شبکه عصبی کانولوشنال (CNN) بر روی مجموعه داده MNIST با یک نوع بهینه ساز معین (یک پارامتر آموزشی) است. اینDataFrameشامل متعدد مانند اجرا می شود، که به اجرا می شود آموزش مجدد تحت انواع مختلف بهینه ساز مطابقت دارد. -
tag: این توصیف چهvalueدر وسایل همان سطر، این است که، چه ارزش متریک نشان دهنده در ردیف. در این آزمایش، ما فقط دو تگ منحصر به فرد:epoch_accuracyوepoch_lossبرای دقت و از دست دادن معیارهای بود. -
step: این تعداد که نشان دهنده سفارش سریال از ردیف مربوطه در اجرای آن است. در اینجاstepدر واقع به تعداد دوره اشاره دارد. اگر شما می خواهید برای به دست آوردن مهر زمانی در علاوه بر این بهstepارزش ها، شما می توانید استدلال کلمه کلیدی استفادهinclude_wall_time=Trueزمانی که خواستارget_scalars(). -
value: این مقدار عددی واقعی علاقه است. همانطور که در بالا توضیح داده شد، هرvalueدر این خاصDataFrameاست یا از دست دادن و یا دقت، بسته بهtagاز ردیف.
print(df["run"].unique())
print(df["tag"].unique())
['adam,run_1/train' 'adam,run_1/validation' 'adam,run_2/train' 'adam,run_2/validation' 'adam,run_3/train' 'adam,run_3/validation' 'adam,run_4/train' 'adam,run_4/validation' 'adam,run_5/train' 'adam,run_5/validation' 'rmsprop,run_1/train' 'rmsprop,run_1/validation' 'rmsprop,run_2/train' 'rmsprop,run_2/validation' 'rmsprop,run_3/train' 'rmsprop,run_3/validation' 'rmsprop,run_4/train' 'rmsprop,run_4/validation' 'rmsprop,run_5/train' 'rmsprop,run_5/validation' 'sgd,run_1/train' 'sgd,run_1/validation' 'sgd,run_2/train' 'sgd,run_2/validation' 'sgd,run_3/train' 'sgd,run_3/validation' 'sgd,run_4/train' 'sgd,run_4/validation' 'sgd,run_5/train' 'sgd,run_5/validation'] ['epoch_accuracy' 'epoch_loss']
بدست آوردن یک DataFrame محوری (گسترده)
در آزمایش ما، دو تگ ( epoch_loss و epoch_accuracy ) در همان مجموعه ای از مراحل در هر اجرا حضور دارند. این امکان به دست آوردن یک "گسترده فرم" DataFrame به طور مستقیم از get_scalars() با استفاده از pivot=True استدلال کلمه کلیدی. گسترده فرم DataFrame است که تمام دستورات آن گنجانده شده به عنوان ستون از DataFrame است که راحت تر به کار با در برخی موارد از جمله این یکی.
با این حال، مراقب باشید که اگر، منوط به داشتن مجموعه یکپارچه از ارزشهای گام در تمام برچسب ها در تمام اجرا می شود است آشنا نیست، با استفاده از pivot=True در یک خطا منجر شود.
dfw = experiment.get_scalars(pivot=True)
dfw
توجه داشته باشید که به جای یک "ارزش" ستون، گسترده فرم DataFrame شامل دو تگ (متریک) به عنوان ستون های آن به صراحت: epoch_accuracy و epoch_loss .
ذخیره DataFrame به عنوان CSV
pandas.DataFrame است قابلیت همکاری خوب با CSV . می توانید آن را به عنوان یک فایل CSV محلی ذخیره کرده و بعداً بارگیری کنید. مثلا:
csv_path = '/tmp/tb_experiment_1.csv'
dfw.to_csv(csv_path, index=False)
dfw_roundtrip = pd.read_csv(csv_path)
pd.testing.assert_frame_equal(dfw_roundtrip, dfw)
انجام تجسم سفارشی و تجزیه و تحلیل آماری
# Filter the DataFrame to only validation data, which is what the subsequent
# analyses and visualization will be focused on.
dfw_validation = dfw[dfw.run.str.endswith("/validation")]
# Get the optimizer value for each row of the validation DataFrame.
optimizer_validation = dfw_validation.run.apply(lambda run: run.split(",")[0])
plt.figure(figsize=(16, 6))
plt.subplot(1, 2, 1)
sns.lineplot(data=dfw_validation, x="step", y="epoch_accuracy",
hue=optimizer_validation).set_title("accuracy")
plt.subplot(1, 2, 2)
sns.lineplot(data=dfw_validation, x="step", y="epoch_loss",
hue=optimizer_validation).set_title("loss")
Text(0.5, 1.0, 'loss')
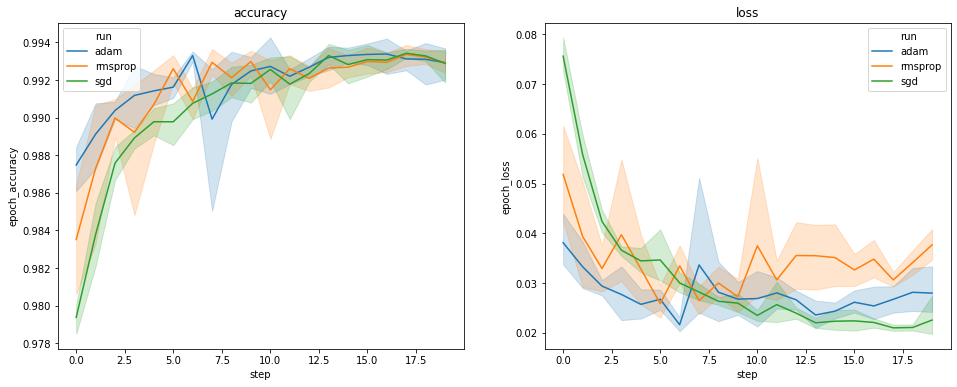
نمودارهای بالا دوره های زمانی اعتبار سنجی و از دست دادن اعتبار را نشان می دهد. هر منحنی میانگین 5 اجرا را تحت یک نوع بهینه ساز نشان می دهد. با تشکر از ویژگی ساخته شده است در seaborn.lineplot() ، هر یک از منحنی نیز انحراف استاندارد 1 نمایش ± اطراف میانگین، که به ما می دهد حس روشنی از تنوعی در این منحنی ها و اهمیت این تفاوت در میان سه نوع بهینه ساز. این تجسم تنوع هنوز در رابط کاربری گرافیکی TensorBoard پشتیبانی نمی شود.
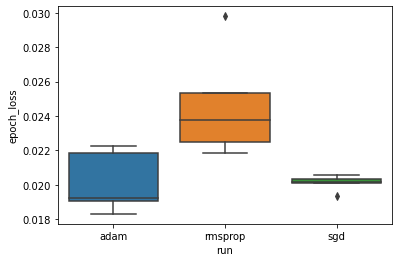
ما می خواهیم این فرضیه را مطالعه کنیم که حداقل زیان اعتبارسنجی در بین بهینه سازهای "adam" ، "rmsprop" و "sgd" تفاوت قابل توجهی دارد. بنابراین ما یک DataFrame برای حداقل زیان اعتبار سنجی تحت هر یک از بهینه سازها استخراج می کنیم.
سپس یک boxplot ایجاد می کنیم تا تفاوت حداقل تلفات اعتبار سنجی را تجسم کنیم.
adam_min_val_loss = dfw_validation.loc[optimizer_validation=="adam", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
rmsprop_min_val_loss = dfw_validation.loc[optimizer_validation=="rmsprop", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
sgd_min_val_loss = dfw_validation.loc[optimizer_validation=="sgd", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
min_val_loss = pd.concat([adam_min_val_loss, rmsprop_min_val_loss, sgd_min_val_loss])
sns.boxplot(data=min_val_loss, y="epoch_loss",
x=min_val_loss.run.apply(lambda run: run.split(",")[0]))
<matplotlib.axes._subplots.AxesSubplot at 0x7f5e017c8150>
# Perform pairwise comparisons between the minimum validation losses
# from the three optimizers.
_, p_adam_vs_rmsprop = stats.ttest_ind(
adam_min_val_loss["epoch_loss"],
rmsprop_min_val_loss["epoch_loss"])
_, p_adam_vs_sgd = stats.ttest_ind(
adam_min_val_loss["epoch_loss"],
sgd_min_val_loss["epoch_loss"])
_, p_rmsprop_vs_sgd = stats.ttest_ind(
rmsprop_min_val_loss["epoch_loss"],
sgd_min_val_loss["epoch_loss"])
print("adam vs. rmsprop: p = %.4f" % p_adam_vs_rmsprop)
print("adam vs. sgd: p = %.4f" % p_adam_vs_sgd)
print("rmsprop vs. sgd: p = %.4f" % p_rmsprop_vs_sgd)
adam vs. rmsprop: p = 0.0244 adam vs. sgd: p = 0.9749 rmsprop vs. sgd: p = 0.0135
بنابراین ، در سطح معنی داری 0.05 ، تجزیه و تحلیل ما فرضیه ما را تأیید می کند که حداقل ضرر اعتبارسنجی در بهینه ساز rmsprop به طور قابل توجهی بیشتر (یعنی بدتر) در مقایسه با دو بهینه ساز دیگر موجود در آزمایش ما است.
به طور خلاصه، این آموزش یک مثال از چگونگی دسترسی به داده عددی به عنوان فراهم می کند panda.DataFrame بازدید کنندگان از TensorBoard.dev. این نشان می دهد نوع از تجزیه و تحلیل انعطاف پذیر و قدرتمند و تجسم شما می توانید با انجام DataFrame است.