
TensorFlow Veri Doğrulaması (TFDV), eğitim ve hizmet verilerini aşağıdaki amaçlarla analiz edebilir:
tanımlayıcı istatistikleri hesaplamak,
bir şema çıkarımı,
veri anormalliklerini tespit edin.
Çekirdek API, her bir işlevsellik parçasını, üstüne eklenen ve not defterleri bağlamında çağrılabilen kolaylık yöntemleriyle destekler.
Tanımlayıcı veri istatistiklerinin hesaplanması
TFDV, mevcut özellikler ve değer dağılımlarının şekilleri açısından verilere hızlı bir genel bakış sağlayan tanımlayıcı istatistikler hesaplayabilir. Yönlere Genel Bakış gibi araçlar, kolay göz atma için bu istatistiklerin kısa ve öz bir görselleştirmesini sağlayabilir.
Örneğin, path TFRecord biçimindeki ( tensorflow.Example türündeki kayıtları tutan) bir dosyaya işaret ettiğini varsayalım. Aşağıdaki kod parçası, TFDV kullanılarak istatistiklerin hesaplanmasını göstermektedir:
stats = tfdv.generate_statistics_from_tfrecord(data_location=path)
Döndürülen değer bir DatasetFeatureStatisticsList protokol arabelleğidir. Örnek not defteri, Özellikler Genel Bakışı kullanılarak istatistiklerin görselleştirilmesini içerir:
tfdv.visualize_statistics(stats)
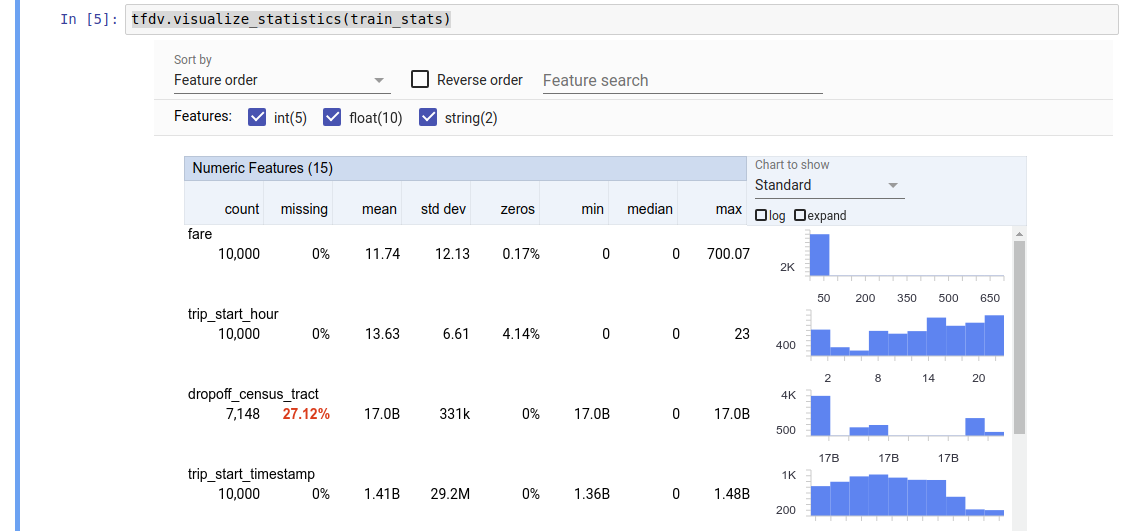
Önceki örnekte verilerin bir TFRecord dosyasında saklandığı varsayılmaktadır. TFDV ayrıca diğer yaygın formatlar için genişletilebilirlik özelliğiyle CSV giriş formatını da destekler. Mevcut veri kod çözücüleri burada bulabilirsiniz. Ayrıca TFDV, pandas DataFrame olarak temsil edilen bellek içi verilere sahip kullanıcılar için tfdv.generate_statistics_from_dataframe yardımcı program işlevini sağlar.
Varsayılan bir veri istatistikleri kümesinin hesaplanmasına ek olarak, TFDV aynı zamanda anlamsal alanlara (örneğin resimler, metin) ilişkin istatistikleri de hesaplayabilir. Anlamsal etki alanı istatistiklerinin hesaplanmasını etkinleştirmek için, tfdv.StatsOptions nesnesini, enable_semantic_domain_stats True olarak ayarlanmış şekilde tfdv.generate_statistics_from_tfrecord iletin.
Google Cloud'da çalışıyor
Dahili olarak TFDV, büyük veri kümeleri üzerinde istatistik hesaplamasını ölçeklendirmek için Apache Beam'in veri paralel işleme çerçevesini kullanır. TFDV ile daha derin entegrasyon isteyen uygulamalar için (örneğin, veri oluşturma hattının sonuna istatistik oluşturma eklemek, özel formattaki veriler için istatistikler oluşturmak ), API aynı zamanda istatistik üretimi için bir Beam PTransform'u da kullanıma sunar.
TFDV'yi Google Cloud'da çalıştırmak için TFDV tekerlek dosyasının indirilmesi ve Dataflow çalışanlarına sağlanması gerekir. Wheel dosyasını geçerli dizine aşağıdaki şekilde indirin:
pip download tensorflow_data_validation \
--no-deps \
--platform manylinux2010_x86_64 \
--only-binary=:all:
Aşağıdaki kod parçası, Google Cloud'da TFDV'nin örnek kullanımını göstermektedir:
import tensorflow_data_validation as tfdv
from apache_beam.options.pipeline_options import PipelineOptions, GoogleCloudOptions, StandardOptions, SetupOptions
PROJECT_ID = ''
JOB_NAME = ''
GCS_STAGING_LOCATION = ''
GCS_TMP_LOCATION = ''
GCS_DATA_LOCATION = ''
# GCS_STATS_OUTPUT_PATH is the file path to which to output the data statistics
# result.
GCS_STATS_OUTPUT_PATH = ''
PATH_TO_WHL_FILE = ''
# Create and set your PipelineOptions.
options = PipelineOptions()
# For Cloud execution, set the Cloud Platform project, job_name,
# staging location, temp_location and specify DataflowRunner.
google_cloud_options = options.view_as(GoogleCloudOptions)
google_cloud_options.project = PROJECT_ID
google_cloud_options.job_name = JOB_NAME
google_cloud_options.staging_location = GCS_STAGING_LOCATION
google_cloud_options.temp_location = GCS_TMP_LOCATION
options.view_as(StandardOptions).runner = 'DataflowRunner'
setup_options = options.view_as(SetupOptions)
# PATH_TO_WHL_FILE should point to the downloaded tfdv wheel file.
setup_options.extra_packages = [PATH_TO_WHL_FILE]
tfdv.generate_statistics_from_tfrecord(GCS_DATA_LOCATION,
output_path=GCS_STATS_OUTPUT_PATH,
pipeline_options=options)
Bu durumda, oluşturulan istatistik protokolü GCS_STATS_OUTPUT_PATH yazılan bir TFRecord dosyasında saklanır.
NOT Google Cloud'da tfdv.generate_statistics_... işlevlerinden herhangi birini (ör. tfdv.generate_statistics_from_tfrecord ) çağırırken bir output_path sağlamanız gerekir. Yok seçeneğinin belirtilmesi hataya neden olabilir.
Veriler üzerinden bir şema çıkarımı
Şema, verilerin beklenen özelliklerini açıklar. Bu özelliklerden bazıları şunlardır:
- hangi özelliklerin mevcut olması bekleniyor
- onların türü
- her örnekteki bir özelliğe ilişkin değerlerin sayısı
- tüm örneklerde her özelliğin varlığı
- özelliklerin beklenen etki alanları.
Kısacası şema "doğru" veriye yönelik beklentileri açıklar ve dolayısıyla verilerdeki hataları tespit etmek için kullanılabilir (aşağıda açıklanmıştır). Ayrıca aynı şema, veri dönüşümleri için TensorFlow Transform'u ayarlamak için de kullanılabilir. Şemanın oldukça statik olmasının beklendiğini unutmayın; örneğin, birkaç veri kümesi aynı şemaya uyabilirken istatistikler (yukarıda açıklanmıştır) veri kümesine göre değişiklik gösterebilir.
Bir şema yazmak, özellikle çok sayıda özelliğe sahip veri kümeleri için sıkıcı bir iş olabileceğinden, TFDV, tanımlayıcı istatistiklere dayalı olarak şemanın ilk sürümünü oluşturmak için bir yöntem sağlar:
schema = tfdv.infer_schema(stats)
Genel olarak TFDV, şemanın belirli veri kümesine gereğinden fazla uymasını önlemek amacıyla istatistiklerden kararlı veri özellikleri çıkarmak için koruyucu buluşsal yöntemler kullanır. TFDV'nin buluşsal yönteminin gözden kaçırmış olabileceği verilerle ilgili herhangi bir alan bilgisini yakalamak için , çıkarılan şemanın gözden geçirilmesi ve gerektiği gibi iyileştirilmesi önemle tavsiye edilir.
Varsayılan olarak, tfdv.infer_schema , özellik için value_count.min value_count.max değerine eşitse gerekli her özelliğin şeklini çıkarır. Şekil çıkarımını devre dışı bırakmak için infer_feature_shape bağımsız değişkenini Yanlış olarak ayarlayın.
Şemanın kendisi bir Şema protokol arabelleği olarak depolanır ve bu nedenle standart protokol arabellek API'si kullanılarak güncellenebilir/düzenlenebilir. TFDV ayrıca bu güncellemeleri kolaylaştırmak için birkaç yardımcı yöntem de sağlar. Örneğin şemanın, tek bir değer alan payment_type dize özelliğini açıklamak için aşağıdaki dörtlüğü içerdiğini varsayalım:
feature {
name: "payment_type"
value_count {
min: 1
max: 1
}
type: BYTES
domain: "payment_type"
presence {
min_fraction: 1.0
min_count: 1
}
}
Özelliğin örneklerin en az %50'sinde doldurulması gerektiğini belirtmek için:
tfdv.get_feature(schema, 'payment_type').presence.min_fraction = 0.5
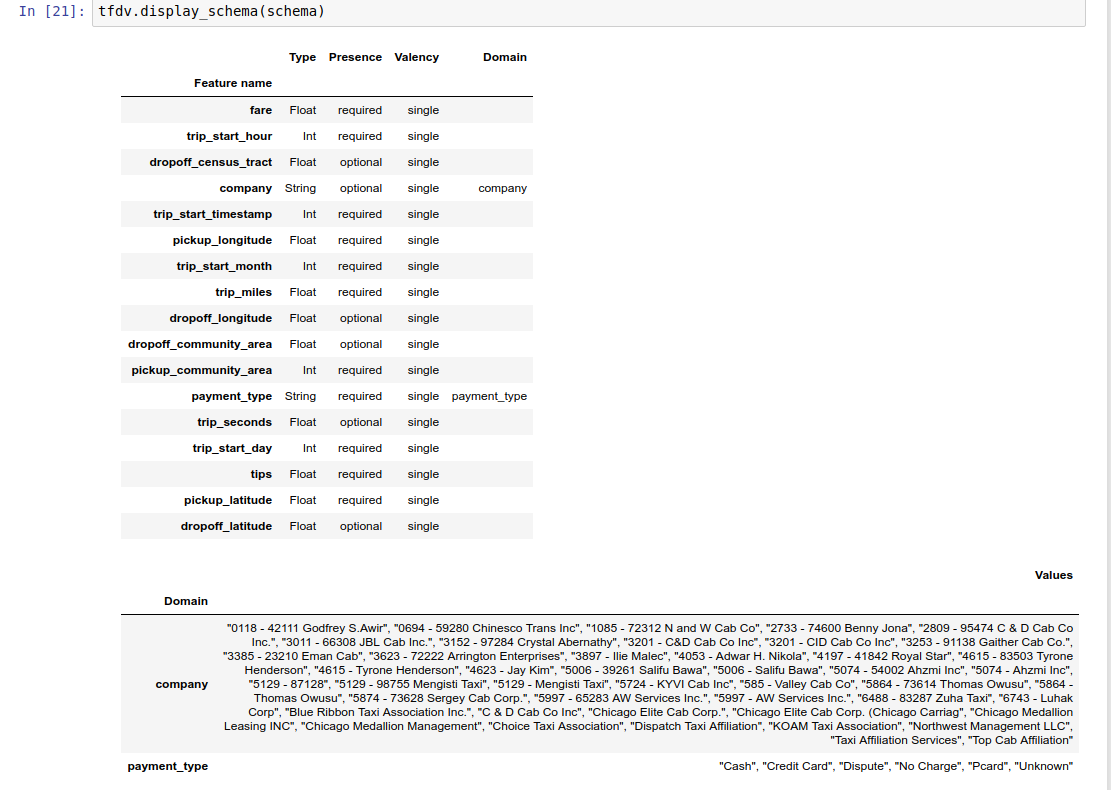
Örnek not defteri, şemanın basit bir görselleştirmesini, şemada kodlandığı şekliyle her bir özelliği ve ana özelliklerini listeleyen bir tablo olarak içerir.
Verilerde hatalar olup olmadığı kontrol ediliyor
Bir şema verildiğinde, bir veri kümesinin şemada belirlenen beklentilere uyup uymadığını veya herhangi bir veri anormalliğinin olup olmadığını kontrol etmek mümkündür. Verilerinizi hatalara karşı (a) veri kümesinin istatistiklerini şemayla eşleştirerek veri kümesinin tamamında toplu olarak veya (b) örnek bazında hataları kontrol ederek kontrol edebilirsiniz.
Veri kümesinin istatistiklerini bir şemayla eşleştirme
Toplamda hataları kontrol etmek için TFDV, veri kümesinin istatistiklerini şemayla eşleştirir ve varsa tutarsızlıkları işaretler. Örneğin:
# Assume that other_path points to another TFRecord file
other_stats = tfdv.generate_statistics_from_tfrecord(data_location=other_path)
anomalies = tfdv.validate_statistics(statistics=other_stats, schema=schema)
Sonuç, Anomaliler protokol arabelleğinin bir örneğidir ve istatistiklerin şema ile uyuşmadığı tüm hataları açıklar. Örneğin, other_path adresindeki verilerin, şemada belirtilen alanın dışındaki payment_type özelliğine ilişkin değerleri içeren örnekler içerdiğini varsayalım.
Bu bir anormallik yaratır
payment_type Unexpected string values Examples contain values missing from the schema: Prcard (<1%).
istatistiklerde özellik değerlerinin <%1'inde alan dışı değer bulunduğunu gösterir.
Eğer bu bekleniyorsa şema şu şekilde güncellenebilir:
tfdv.get_domain(schema, 'payment_type').value.append('Prcard')
Anormallik gerçekten bir veri hatasını gösteriyorsa, temeldeki veriler eğitim için kullanılmadan önce düzeltilmelidir.
Bu modül tarafından tespit edilebilecek çeşitli anormallik türleri burada listelenmiştir.
Örnek not defteri, anormalliklerin bir tablo halinde basit bir şekilde görselleştirilmesini, hataların tespit edildiği özelliklerin listelenmesini ve her hatanın kısa bir açıklamasını içerir.

Örnek bazında hataların kontrol edilmesi
TFDV ayrıca veri kümesi genelindeki istatistikleri şemayla karşılaştırmak yerine verileri örnek bazında doğrulama seçeneği de sunar. TFDV, verileri örnek bazında doğrulamak ve ardından bulunan anormal örnekler için özet istatistikler oluşturmak için işlevler sağlar. Örneğin:
options = tfdv.StatsOptions(schema=schema)
anomalous_example_stats = tfdv.validate_examples_in_tfrecord(
data_location=input, stats_options=options)
validate_examples_in_tfrecord döndürdüğü anomalous_example_stats , her veri kümesinin belirli bir anormallik sergileyen örnek kümesinden oluştuğu bir DatasetFeatureStatisticsList protokol arabelleğidir. Veri kümenizde belirli bir anormallik sergileyen örneklerin sayısını ve bu örneklerin özelliklerini belirlemek için bunu kullanabilirsiniz.
Şema Ortamları
Varsayılan olarak doğrulamalar, bir işlem hattındaki tüm veri kümelerinin tek bir şemaya bağlı olduğunu varsayar. Bazı durumlarda, küçük şema değişikliklerinin tanıtılması gereklidir; örneğin, etiket olarak kullanılan özellikler eğitim sırasında gereklidir (ve doğrulanmalıdır), ancak sunum sırasında eksiktir.
Bu tür gereksinimleri ifade etmek için ortamlar kullanılabilir. Özellikle şemadaki özellikler, default_environment, in_environment ve not_in_environment kullanılarak bir dizi ortamla ilişkilendirilebilir.
Örneğin, ipuçları özelliği eğitimde etiket olarak kullanılıyor ancak sunum verilerinde eksikse. Ortam belirtilmediği takdirde bir anormallik olarak ortaya çıkacaktır.
serving_stats = tfdv.generate_statistics_from_tfrecord(data_location=serving_data_path)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)

Bunu düzeltmek için, tüm özellikler için varsayılan ortamı hem 'EĞİTİM' hem de 'SERVING' olacak şekilde ayarlamamız ve 'ipuçları' özelliğini SERVING ortamından hariç tutmamız gerekir.
# All features are by default in both TRAINING and SERVING environments.
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
# Specify that 'tips' feature is not in SERVING environment.
tfdv.get_feature(schema, 'tips').not_in_environment.append('SERVING')
serving_anomalies_with_env = tfdv.validate_statistics(
serving_stats, schema, environment='SERVING')
Veri çarpıklığını ve kaymasını kontrol etme
TFDV, bir veri kümesinin şemada belirlenen beklentilere uyup uymadığını kontrol etmenin yanı sıra aşağıdakileri tespit edecek işlevler de sağlar:
- eğitim ve veri sunumu arasındaki çarpıklık
- farklı günlerdeki antrenman verileri arasındaki sapma
TFDV bu kontrolü, şemada belirtilen kayma/eğim karşılaştırıcılarına dayalı olarak farklı veri kümelerinin istatistiklerini karşılaştırarak gerçekleştirir. Örneğin, eğitim ve sunum veri kümesindeki 'payment_type' özelliği arasında herhangi bir sapma olup olmadığını kontrol etmek için:
# Assume we have already generated the statistics of training dataset, and
# inferred a schema from it.
serving_stats = tfdv.generate_statistics_from_tfrecord(data_location=serving_data_path)
# Add a skew comparator to schema for 'payment_type' and set the threshold
# of L-infinity norm for triggering skew anomaly to be 0.01.
tfdv.get_feature(schema, 'payment_type').skew_comparator.infinity_norm.threshold = 0.01
skew_anomalies = tfdv.validate_statistics(
statistics=train_stats, schema=schema, serving_statistics=serving_stats)
NOT L-sonsuz normu yalnızca kategorik özellikler için çarpıklığı algılayacaktır. Bir infinity_norm eşiği belirlemek yerine, skew_comparator bir jensen_shannon_divergence eşiği belirlemek hem sayısal hem de kategorik özellikler için çarpıklığı algılayacaktır.
Bir veri kümesinin şemada belirlenen beklentilere uyup uymadığının kontrol edilmesiyle aynı şekilde sonuç aynı zamanda Anomaliler protokol arabelleğinin bir örneğidir ve eğitim ile hizmet veri kümeleri arasındaki herhangi bir çarpıklığı açıklar. Örneğin, sunum verilerinin, Cash değerine sahip payement_type özelliğine sahip önemli ölçüde daha fazla örnek içerdiğini varsayalım; bu, bir çarpıklık anomalisine neden olur
payment_type High L-infinity distance between serving and training The L-infinity distance between serving and training is 0.0435984 (up to six significant digits), above the threshold 0.01. The feature value with maximum difference is: Cash
Anormallik gerçekten eğitim ve veri sunumu arasında bir sapmaya işaret ediyorsa model performansı üzerinde doğrudan bir etkiye sahip olabileceğinden daha fazla araştırma yapılması gerekir.
Örnek not defteri, eğriliğe dayalı anormallikleri kontrol etmenin basit bir örneğini içerir.
Farklı eğitim verileri günleri arasındaki sapmanın tespiti benzer şekilde yapılabilir.
# Assume we have already generated the statistics of training dataset for
# day 2, and inferred a schema from it.
train_day1_stats = tfdv.generate_statistics_from_tfrecord(data_location=train_day1_data_path)
# Add a drift comparator to schema for 'payment_type' and set the threshold
# of L-infinity norm for triggering drift anomaly to be 0.01.
tfdv.get_feature(schema, 'payment_type').drift_comparator.infinity_norm.threshold = 0.01
drift_anomalies = tfdv.validate_statistics(
statistics=train_day2_stats, schema=schema, previous_statistics=train_day1_stats)
NOT L-sonsuz normu yalnızca kategorik özellikler için çarpıklığı algılayacaktır. Bir infinity_norm eşiği belirlemek yerine, skew_comparator bir jensen_shannon_divergence eşiği belirlemek hem sayısal hem de kategorik özellikler için çarpıklığı algılayacaktır.
Özel veri bağlayıcı yazma
Veri istatistiklerini hesaplamak için TFDV, çeşitli formatlardaki giriş verilerini işlemek için çeşitli uygun yöntemler sağlar (örneğin, tf.train.Example'ın TFRecord , CSV, vb.). Veri formatınız bu listede yoksa, giriş verilerini okumak için özel bir veri bağlayıcı yazmanız ve bunu veri istatistiklerini hesaplamak için TFDV çekirdek API'sine bağlamanız gerekir.
Veri istatistiklerini hesaplamaya yönelik TFDV çekirdek API'si, giriş örnekleri gruplarından oluşan bir PCollection'ı alan (bir grup giriş örneği, Arrow RecordBatch olarak temsil edilir) ve tek bir DatasetFeatureStatisticsList protokol arabelleği içeren bir PCollection çıktısı veren bir Beam PTransform'dur .
Giriş örneklerinizi bir Arrow RecordBatch'te gruplayan özel veri bağlayıcıyı uyguladıktan sonra, veri istatistiklerini hesaplamak için bunu tfdv.GenerateStatistics API'sine bağlamanız gerekir. Örneğin tf.train.Example TFRecord ele alalım. tfx_bsl TFExampleRecord veri bağlayıcısını sağlar ve aşağıda bunun tfdv.GenerateStatistics API'sine nasıl bağlanacağına ilişkin bir örnek verilmiştir.
import tensorflow_data_validation as tfdv
from tfx_bsl.public import tfxio
import apache_beam as beam
from tensorflow_metadata.proto.v0 import statistics_pb2
DATA_LOCATION = ''
OUTPUT_LOCATION = ''
with beam.Pipeline() as p:
_ = (
p
# 1. Read and decode the data with tfx_bsl.
| 'TFXIORead' >> (
tfxio.TFExampleRecord(
file_pattern=[DATA_LOCATION],
telemetry_descriptors=['my', 'tfdv']).BeamSource())
# 2. Invoke TFDV `GenerateStatistics` API to compute the data statistics.
| 'GenerateStatistics' >> tfdv.GenerateStatistics()
# 3. Materialize the generated data statistics.
| 'WriteStatsOutput' >> WriteStatisticsToTFRecord(OUTPUT_LOCATION))
Veri dilimleri üzerinden istatistik hesaplama
TFDV, veri dilimleri üzerinden istatistik hesaplamak üzere yapılandırılabilir. Dilimleme, Arrow RecordBatch alan ve bir dizi form dizisi (slice key, record batch) çıkaran dilimleme işlevleri sağlanarak etkinleştirilebilir. TFDV, istatistikler hesaplanırken tfdv.StatsOptions bir parçası olarak sağlanabilecek özellik değerine dayalı dilimleme işlevlerini oluşturmanın kolay bir yolunu sağlar.
Dilimleme etkinleştirildiğinde, çıktı DatasetFeatureStatisticsList protokolü, her dilim için bir tane olmak üzere birden fazla DatasetFeatureStatistics protokolü içerir. Her dilim , DatasetFeatureStatistics protokolünde veri kümesi adı olarak belirlenen benzersiz bir adla tanımlanır. Varsayılan olarak TFDV, yapılandırılmış dilimlere ek olarak genel veri kümesine ilişkin istatistikleri hesaplar.
import tensorflow_data_validation as tfdv
from tensorflow_data_validation.utils import slicing_util
# Slice on country feature (i.e., every unique value of the feature).
slice_fn1 = slicing_util.get_feature_value_slicer(features={'country': None})
# Slice on the cross of country and state feature (i.e., every unique pair of
# values of the cross).
slice_fn2 = slicing_util.get_feature_value_slicer(
features={'country': None, 'state': None})
# Slice on specific values of a feature.
slice_fn3 = slicing_util.get_feature_value_slicer(
features={'age': [10, 50, 70]})
stats_options = tfdv.StatsOptions(
slice_functions=[slice_fn1, slice_fn2, slice_fn3])