
Компонент SampleGen TFX Pipeline принимает данные в конвейеры TFX. Он использует внешние файлы/сервисы для создания примеров, которые будут читаться другими компонентами TFX. Он также обеспечивает согласованное и настраиваемое разделение и перемешивает набор данных в соответствии с лучшими практиками машинного обучения.
- Потребляет: данные из внешних источников данных, таких как CSV,
TFRecord, Avro, Parquet и BigQuery. - Выдает: записи
tf.Example, записиtf.SequenceExampleили формат прототипа, в зависимости от формата полезных данных.
ПримерGen и другие компоненты
exampleGen предоставляет данные компонентам, которые используют библиотеку проверки данных TensorFlow , таким как SchemaGen , StatisticGen и example Validator . Он также предоставляет данные для Transform , который использует библиотеку TensorFlow Transform , и, в конечном итоге, для целей развертывания во время вывода.
Источники данных и форматы
В настоящее время стандартная установка TFX включает полные компоненты SampleGen для следующих источников данных и форматов:
Также доступны пользовательские исполнители, которые позволяют разрабатывать компоненты SampleGen для следующих источников данных и форматов:
См. примеры использования в исходном коде и это обсуждение для получения дополнительной информации о том, как использовать и разрабатывать собственные исполнители.
Кроме того, эти источники данных и форматы доступны в качестве примеров пользовательских компонентов :
Прием форматов данных, поддерживаемых Apache Beam.
Apache Beam поддерживает получение данных из широкого спектра источников данных и форматов ( см. ниже ). Эти возможности можно использовать для создания пользовательских компонентов SampleGen для TFX, что демонстрируют некоторые существующие компоненты SampleGen ( см. ниже ).
Как использовать компонент exampleGen
Для поддерживаемых источников данных (в настоящее время это файлы CSV, файлы TFRecord с tf.Example , tf.SequenceExample и форматом proto, а также результаты запросов BigQuery) компонент конвейера SampleGen можно использовать непосредственно при развертывании и требует небольшой настройки. Например:
example_gen = CsvExampleGen(input_base='data_root')
или, как показано ниже, для прямого импорта внешнего TFRecord с помощью tf.Example :
example_gen = ImportExampleGen(input_base=path_to_tfrecord_dir)
Диапазон, версия и разделение
Span — это группа обучающих примеров. Если ваши данные сохраняются в файловой системе, каждый диапазон может храниться в отдельном каталоге. Семантика Span не запрограммирована жестко в TFX; Промежуток может соответствовать дню данных, часу данных или любой другой группе, имеющей значение для вашей задачи.
Каждый диапазон может содержать несколько версий данных. В качестве примера: если вы удалите некоторые примеры из диапазона для очистки данных низкого качества, это может привести к созданию новой версии этого диапазона. По умолчанию компоненты TFX работают с последней версией в пределах диапазона.
Каждую версию внутри диапазона можно дополнительно разделить на несколько разделов. Самый распространенный вариант разделения диапазона — разделить его на обучающие и оценочные данные.
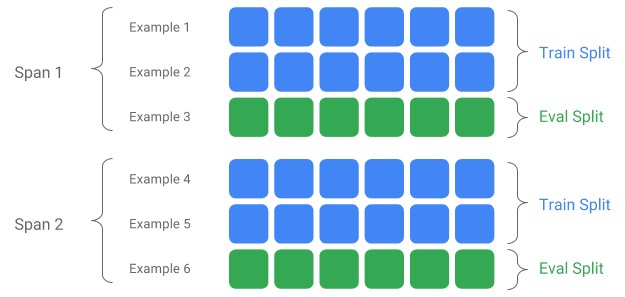
Пользовательское разделение ввода/вывода
Чтобы настроить соотношение разделения обучения/оценки, которое будет выводить SampleGen, установите output_config для компонента SampleGen. Например:
# Input has a single split 'input_dir/*'.
# Output 2 splits: train:eval=3:1.
output = proto.Output(
split_config=example_gen_pb2.SplitConfig(splits=[
proto.SplitConfig.Split(name='train', hash_buckets=3),
proto.SplitConfig.Split(name='eval', hash_buckets=1)
]))
example_gen = CsvExampleGen(input_base=input_dir, output_config=output)
Обратите внимание, как в этом примере были установлены hash_buckets .
Для источника ввода, который уже разделен, установите input_config для компонента exampleGen:
# Input train split is 'input_dir/train/*', eval split is 'input_dir/eval/*'.
# Output splits are generated one-to-one mapping from input splits.
input = proto.Input(splits=[
example_gen_pb2.Input.Split(name='train', pattern='train/*'),
example_gen_pb2.Input.Split(name='eval', pattern='eval/*')
])
example_gen = CsvExampleGen(input_base=input_dir, input_config=input)
Для генерации примеров на основе файлов (например, CsvExampleGen и ImportExampleGen) pattern представляет собой общий шаблон относительного файла, который сопоставляется с входными файлами с корневым каталогом, заданным входным базовым путем. Для создания примеров на основе запросов (например, BigQueryExampleGen, PrestoExampleGen) pattern является SQL-запрос.
По умолчанию весь входной базовый каталог рассматривается как одно входное разделение, а выходное разделение поезда и оценки генерируется с соотношением 2:1.
Пожалуйста, обратитесь к proto/example_gen.proto для конфигурации разделения ввода и вывода exampleGen. И обратитесь к руководству по нижестоящим компонентам для использования пользовательских разделений ниже по потоку.
Метод разделения
При использовании метода разделения hash_buckets вместо всей записи можно использовать функцию разделения примеров. Если функция присутствует, SampleGen будет использовать отпечаток этой функции в качестве ключа раздела.
Эту функцию можно использовать для поддержания стабильного разделения относительно определенных свойств примеров: например, пользователь всегда будет помещен в одно и то же разделение, если в качестве имени функции раздела было выбрано «user_id».
Интерпретация того, что означает «функция» и как сопоставить «функцию» с указанным именем, зависит от реализации SampleGen и типа примеров.
Для готовых реализаций SampleGen:
- Если он генерирует tf.Example, то «функция» означает запись в tf.Example.features.feature.
- Если он генерирует tf.SequenceExample, то «функция» означает запись в tf.SequenceExample.context.feature.
- Поддерживаются только функции int64 и bytes.
В следующих случаях SampleGen выдает ошибки времени выполнения:
- Указанное имя объекта не существует в примере.
- Пустая функция:
tf.train.Feature(). - Неподдерживаемые типы объектов, например плавающие объекты.
Чтобы вывести разделение train/eval на основе функции в примерах, установите output_config для компонента SampleGen. Например:
# Input has a single split 'input_dir/*'.
# Output 2 splits based on 'user_id' features: train:eval=3:1.
output = proto.Output(
split_config=proto.SplitConfig(splits=[
proto.SplitConfig.Split(name='train', hash_buckets=3),
proto.SplitConfig.Split(name='eval', hash_buckets=1)
],
partition_feature_name='user_id'))
example_gen = CsvExampleGen(input_base=input_dir, output_config=output)
Обратите внимание, как в этом примере было установлено partition_feature_name .
Охватывать
Span можно получить, используя спецификацию «{SPAN}» во входном шаблоне glob :
- Эта спецификация сопоставляет цифры и сопоставляет данные с соответствующими номерами SPAN. Например, «data_{SPAN}-*.tfrecord» будет собирать такие файлы, как «data_12-a.tfrecord», «data_12-b.tfrecord».
- При желании эту спецификацию можно указать с шириной целых чисел при сопоставлении. Например, «data_{SPAN:2}.file» сопоставляется с такими файлами, как «data_02.file» и «data_27.file» (в качестве входных данных для Span-2 и Span-27 соответственно), но не сопоставляется с «data_1». файл» или «data_123.file».
- Если спецификация SPAN отсутствует, предполагается, что Span всегда равен 0.
- Если указан SPAN, конвейер будет обрабатывать последний диапазон и сохранять номер диапазона в метаданных.
Например, предположим, что есть входные данные:
- '/tmp/span-1/train/data'
- '/tmp/span-1/eval/data'
- '/tmp/span-2/train/data'
- '/tmp/span-2/eval/data'
и входная конфигурация показана ниже:
splits {
name: 'train'
pattern: 'span-{SPAN}/train/*'
}
splits {
name: 'eval'
pattern: 'span-{SPAN}/eval/*'
}
при запуске конвейера он будет обрабатывать:
- '/tmp/span-2/train/data' как разделение поезда
- '/tmp/span-2/eval/data' как разделение оценки
с номером диапазона «2». Если позже «/tmp/span-3/...» будет готов, просто снова запустите конвейер, и он выберет диапазон «3» для обработки. Ниже показан пример кода для использования спецификации диапазона:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
Получение определенного диапазона можно выполнить с помощью RangeConfig, который подробно описан ниже.
Дата
Если ваш источник данных организован в файловой системе по дате, TFX поддерживает сопоставление дат непосредственно с числами интервалов. Существует три спецификации для представления сопоставления дат с интервалами: {ГГГГ}, {ММ} и {ДД}:
- Три спецификации должны полностью присутствовать во входном шаблоне glob, если таковые указаны:
- Можно указать либо спецификацию {SPAN}, либо этот набор спецификаций даты.
- Рассчитывается календарная дата с годом от ГГГГ, месяцем от ММ и днем месяца от ДД, затем номер интервала рассчитывается как количество дней с эпохи unix (т. е. 1970-01-01). Например, «log-{YYYY}{MM}{DD}.data» соответствует файлу «log-19700101.data» и использует его в качестве входных данных для Span-0, а «log-20170101.data» в качестве входных данных для Пролет-17167.
- Если указан этот набор спецификаций даты, конвейер будет обрабатывать самую последнюю дату и сохранять соответствующий номер диапазона в метаданных.
Например, предположим, что есть входные данные, упорядоченные по календарной дате:
- '/tmp/1970-01-02/train/data'
- '/tmp/1970-01-02/оценка/данные'
- '/tmp/1970-01-03/train/data'
- '/tmp/1970-01-03/eval/данные'
и входная конфигурация показана ниже:
splits {
name: 'train'
pattern: '{YYYY}-{MM}-{DD}/train/*'
}
splits {
name: 'eval'
pattern: '{YYYY}-{MM}-{DD}/eval/*'
}
при запуске конвейера он будет обрабатывать:
- '/tmp/1970-01-03/train/data' как разделение поезда
- '/tmp/1970-01-03/eval/data' как разделение оценок
с номером диапазона «2». Если позже «/tmp/1970-01-04/...» будет готов, просто снова запустите конвейер, и он выберет диапазон «3» для обработки. Ниже показан пример кода для использования спецификации даты:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='{YYYY}-{MM}-{DD}/train/*'),
proto.Input.Split(name='eval',
pattern='{YYYY}-{MM}-{DD}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
Версия
Версию можно получить, используя спецификацию «{VERSION}» во входном шаблоне glob :
- Эта спецификация сопоставляет цифры и сопоставляет данные с соответствующими номерами ВЕРСИЙ в SPAN. Обратите внимание, что спецификацию версии можно использовать в сочетании со спецификацией Span или Date.
- В этой спецификации также можно дополнительно указать ширину так же, как в спецификации SPAN. например, 'span-{SPAN}/version-{VERSION:4}/data-*'.
- Если спецификация VERSION отсутствует, для версии установлено значение None.
- Если указаны оба SPAN и VERSION, конвейер будет обрабатывать последнюю версию для последнего диапазона и сохранять номер версии в метаданных.
- Если указана ВЕРСИЯ, но не SPAN (или спецификация даты), будет выдана ошибка.
Например, предположим, что есть входные данные:
- '/tmp/span-1/ver-1/train/data'
- '/tmp/span-1/ver-1/eval/data'
- '/tmp/span-2/ver-1/train/data'
- '/tmp/span-2/ver-1/eval/data'
- '/tmp/span-2/ver-2/train/data'
- '/tmp/span-2/ver-2/eval/data'
и входная конфигурация показана ниже:
splits {
name: 'train'
pattern: 'span-{SPAN}/ver-{VERSION}/train/*'
}
splits {
name: 'eval'
pattern: 'span-{SPAN}/ver-{VERSION}/eval/*'
}
при запуске конвейера он будет обрабатывать:
- '/tmp/span-2/ver-2/train/data' как разделение поезда
- '/tmp/span-2/ver-2/eval/data' как разделение оценки
с номером диапазона «2» и номером версии «2». Если позже «/tmp/span-2/ver-3/...» будет готов, просто снова запустите конвейер, и он выберет для обработки диапазон «2» и версию «3». Ниже показан пример кода для использования спецификации версии:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN}/ver-{VERSION}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN}/ver-{VERSION}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
Конфигурация диапазона
TFX поддерживает извлечение и обработку определенного диапазона в файловом SampleGen с использованием конфигурации диапазона — абстрактной конфигурации, используемой для описания диапазонов для различных объектов TFX. Чтобы получить определенный диапазон, установите range_config для файлового компонента SampleGen. Например, предположим, что есть входные данные:
- '/tmp/span-01/train/data'
- '/tmp/span-01/eval/data'
- '/tmp/span-02/train/data'
- '/tmp/span-02/eval/data'
Чтобы специально получить и обработать данные с диапазоном «1», мы указываем конфигурацию диапазона в дополнение к входной конфигурации. Обратите внимание, что SampleGen поддерживает только статические диапазоны с одним диапазоном (чтобы указать обработку определенных отдельных диапазонов). Таким образом, для StaticRange start_span_number должен равняться end_span_number. Используя предоставленный диапазон и информацию о ширине диапазона (если предоставлена) для заполнения нулями, exampleGen заменит спецификацию SPAN в предоставленных шаблонах разделения на желаемый номер диапазона. Пример использования показан ниже:
# In cases where files have zero-padding, the width modifier in SPAN spec is
# required so TFX can correctly substitute spec with zero-padded span number.
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN:2}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN:2}/eval/*')
])
# Specify the span number to be processed here using StaticRange.
range = proto.RangeConfig(
static_range=proto.StaticRange(
start_span_number=1, end_span_number=1)
)
# After substitution, the train and eval split patterns will be
# 'input_dir/span-01/train/*' and 'input_dir/span-01/eval/*', respectively.
example_gen = CsvExampleGen(input_base=input_dir, input_config=input,
range_config=range)
Конфигурацию диапазона также можно использовать для обработки определенных дат, если вместо спецификации SPAN используется спецификация даты. Например, предположим, что есть входные данные, упорядоченные по календарной дате:
- '/tmp/1970-01-02/train/data'
- '/tmp/1970-01-02/оценка/данные'
- '/tmp/1970-01-03/train/data'
- '/tmp/1970-01-03/eval/данные'
Чтобы конкретно получить и обработать данные по состоянию на 2 января 1970 года, мы делаем следующее:
from tfx.components.example_gen import utils
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='{YYYY}-{MM}-{DD}/train/*'),
proto.Input.Split(name='eval',
pattern='{YYYY}-{MM}-{DD}/eval/*')
])
# Specify date to be converted to span number to be processed using StaticRange.
span = utils.date_to_span_number(1970, 1, 2)
range = proto.RangeConfig(
static_range=range_config_pb2.StaticRange(
start_span_number=span, end_span_number=span)
)
# After substitution, the train and eval split patterns will be
# 'input_dir/1970-01-02/train/*' and 'input_dir/1970-01-02/eval/*',
# respectively.
example_gen = CsvExampleGen(input_base=input_dir, input_config=input,
range_config=range)
Пользовательский генератор примеров
Если доступные в настоящее время компоненты SampleGen не соответствуют вашим потребностям, вы можете создать собственный SampleGen, который позволит вам читать данные из разных источников или в разных форматах данных.
Настройка exampleGen на основе файлов (экспериментальная)
Во-первых, расширите BaseExampleGenExecutor с помощью специального Beam PTransform, который обеспечивает преобразование входных данных, разделенных на поезд/оценку, в примеры TF. Например, исполнитель CsvExampleGen обеспечивает преобразование входного разделения CSV в примеры TF.
Затем создайте компонент с указанным выше исполнителем, как это сделано в компоненте CsvExampleGen . Альтернативно можно передать собственный исполнитель в стандартный компонент SampleGen, как показано ниже.
from tfx.components.base import executor_spec
from tfx.components.example_gen.csv_example_gen import executor
example_gen = FileBasedExampleGen(
input_base=os.path.join(base_dir, 'data/simple'),
custom_executor_spec=executor_spec.ExecutorClassSpec(executor.Executor))
Теперь мы также поддерживаем чтение файлов Avro и Parquet с помощью этого метода .
Дополнительные форматы данных
Apache Beam поддерживает чтение ряда дополнительных форматов данных . через преобразования Beam I/O. Вы можете создавать собственные компоненты exampleGen, используя преобразования ввода-вывода Beam, используя шаблон, аналогичный примеру Avro.
return (pipeline
| 'ReadFromAvro' >> beam.io.ReadFromAvro(avro_pattern)
| 'ToTFExample' >> beam.Map(utils.dict_to_example))
На момент написания этой статьи в число поддерживаемых в настоящее время форматов и источников данных для Beam Python SDK входят:
- Амазонка S3
- Апач Авро
- Апач Хадуп
- Апач Кафка
- Паркет Апач
- Google Cloud BigQuery
- Google Cloud BigTable
- Облачное хранилище данных Google
- Google Cloud Pub/Sub
- Облачное хранилище Google (GCS)
- МонгоБД
Свежий список можно найти в документации Beam .
Настройка генератора примеров на основе запросов (экспериментальная)
Сначала расширите BaseExampleGenExecutor с помощью специального Beam PTransform, который считывает данные из внешнего источника данных. Затем создайте простой компонент, расширив QueryBasedExampleGen.
Это может потребовать или не потребовать дополнительных конфигураций подключения. Например, исполнитель BigQuery считывает данные с помощью коннектора beam.io по умолчанию, который абстрагирует детали конфигурации соединения. Исполнителю Presto требуется настраиваемый Beam PTransform и настраиваемый protobuf конфигурации соединения в качестве входных данных.
Если для пользовательского компонента SampleGen требуется конфигурация соединения, создайте новый protobuf и передайте его через custom_config, который теперь является необязательным параметром выполнения. Ниже приведен пример использования настроенного компонента.
from tfx.examples.custom_components.presto_example_gen.proto import presto_config_pb2
from tfx.examples.custom_components.presto_example_gen.presto_component.component import PrestoExampleGen
presto_config = presto_config_pb2.PrestoConnConfig(host='localhost', port=8080)
example_gen = PrestoExampleGen(presto_config, query='SELECT * FROM chicago_taxi_trips')
Примеры последующих компонентов Gen
Пользовательская конфигурация разделения поддерживается для последующих компонентов.
Генерация статистики
Поведение по умолчанию — генерация статистики для всех сплитов.
Чтобы исключить какие-либо разделения, установите exclude_splits для компонентаStatisticsGen. Например:
# Exclude the 'eval' split.
statistics_gen = StatisticsGen(
examples=example_gen.outputs['examples'],
exclude_splits=['eval'])
Генер схемы
Поведение по умолчанию — создание схемы на основе всех разбиений.
Чтобы исключить любые разделения, установите exclude_splits для компонента SchemaGen. Например:
# Exclude the 'eval' split.
schema_gen = SchemaGen(
statistics=statistics_gen.outputs['statistics'],
exclude_splits=['eval'])
ПримерВалидатора
Поведение по умолчанию — проверка статистики всех разбиений во входных примерах на соответствие схеме.
Чтобы исключить любые разделения, установите exclude_splits для компонента exampleValidator. Например:
# Exclude the 'eval' split.
example_validator = ExampleValidator(
statistics=statistics_gen.outputs['statistics'],
schema=schema_gen.outputs['schema'],
exclude_splits=['eval'])
Трансформировать
Поведение по умолчанию — анализ и создание метаданных из разделения «поезд» и преобразование всех разделений.
Чтобы указать разделения анализа и разделения преобразования, установите splits_config для компонента Transform. Например:
# Analyze the 'train' split and transform all splits.
transform = Transform(
examples=example_gen.outputs['examples'],
schema=schema_gen.outputs['schema'],
module_file=_taxi_module_file,
splits_config=proto.SplitsConfig(analyze=['train'],
transform=['train', 'eval']))
Тренер и настройщик
Поведение по умолчанию — обучение на разбиении «обучение» и оценка на разбиении «оценка».
Чтобы указать разделения поездов и оценить разделения, установите train_args и eval_args для компонента Trainer. Например:
# Train on the 'train' split and evaluate on the 'eval' split.
Trainer = Trainer(
module_file=_taxi_module_file,
examples=transform.outputs['transformed_examples'],
schema=schema_gen.outputs['schema'],
transform_graph=transform.outputs['transform_graph'],
train_args=proto.TrainArgs(splits=['train'], num_steps=10000),
eval_args=proto.EvalArgs(splits=['eval'], num_steps=5000))
оценщик
Поведение по умолчанию — предоставление метрик, рассчитанных на основе разделения «eval».
Чтобы вычислить статистику оценки для пользовательских разделений, установите example_splits для компонента Evaluator. Например:
# Compute metrics on the 'eval1' split and the 'eval2' split.
evaluator = Evaluator(
examples=example_gen.outputs['examples'],
model=trainer.outputs['model'],
example_splits=['eval1', 'eval2'])
Более подробную информацию можно найти в справочнике по API CsvExampleGen , реализации API FileBasedExampleGen и справочнике по API ImportExampleGen .