
ملخص
يتم توضيح خط أنابيب تحليل نموذج TensorFlow (TFMA) على النحو التالي:
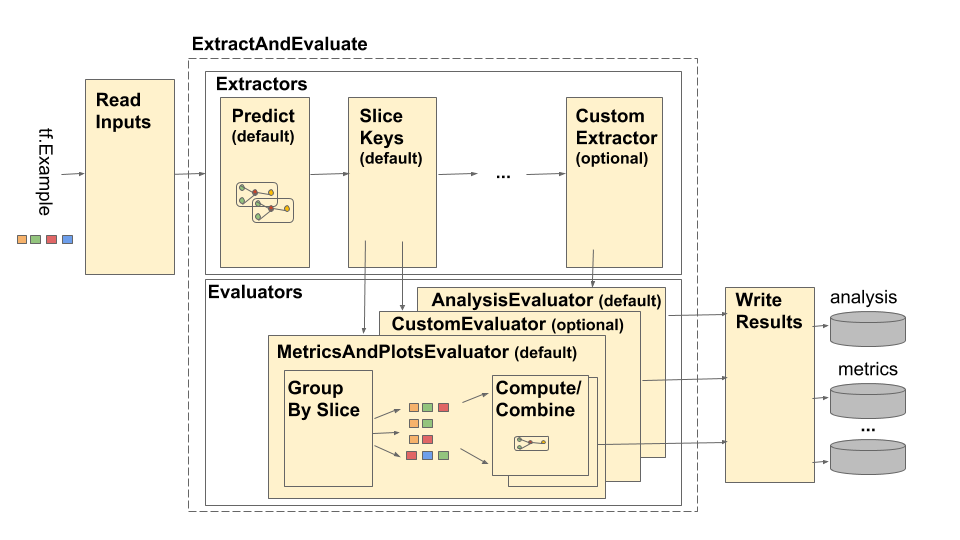
يتكون خط الأنابيب من أربعة مكونات رئيسية:
- قراءة المدخلات
- اِستِخلاص
- تقييم
- كتابة النتائج
تستخدم هذه المكونات نوعين أساسيين: tfma.Extracts و tfma.evaluators.Evaluation . يمثل النوع tfma.Extracts البيانات التي يتم استخراجها أثناء معالجة خطوط الأنابيب وقد تتوافق مع مثال واحد أو أكثر للنموذج. يمثل tfma.evaluators.Evaluation مخرجات تقييم المستخلصات في نقاط مختلفة أثناء عملية الاستخراج. من أجل توفير واجهة برمجة تطبيقات مرنة، هذه الأنواع هي مجرد إملاءات حيث يتم تعريف المفاتيح (محجوزة للاستخدام) من خلال تطبيقات مختلفة. يتم تعريف الأنواع على النحو التالي:
# Extracts represent data extracted during pipeline processing.
# For example, the PredictExtractor stores the data for the
# features, labels, and predictions under the keys "features",
# "labels", and "predictions".
Extracts = Dict[Text, Any]
# Evaluation represents the output from evaluating extracts at
# particular point in the pipeline. The evaluation outputs are
# keyed by their associated output type. For example, the metric / plot
# dictionaries from evaluating metrics and plots will be stored under
# "metrics" and "plots" respectively.
Evaluation = Dict[Text, beam.pvalue.PCollection]
لاحظ أن tfma.Extracts لا يتم كتابتها بشكل مباشر أبدًا، بل يجب دائمًا المرور عبر أحد المقيمين لإنتاج تقييم tfma.evaluators.Evaluation الذي يتم كتابته بعد ذلك. لاحظ أيضًا أن tfma.Extracts عبارة عن إملاءات يتم تخزينها beam.pvalue.PCollection (أي beam.PTransform يأخذ كمدخلاتشعاع beam.pvalue.PCollection[tfma.Extracts] ) في حين أن tfma.evaluators.Evaluation هو إملاء قيمه beam.pvalue.PCollection s (أي beam.PTransform PTransform يأخذ الإملاء نفسه كوسيطة لإدخال beam.value.PCollection ). بمعنى آخر، يتم استخدام tfma.evaluators.Evaluation في وقت إنشاء خط الأنابيب، ولكن يتم استخدام tfma.Extracts في وقت تشغيل خط الأنابيب.
قراءة المدخلات
تتكون مرحلة ReadInputs من تحويل يأخذ المدخلات الأولية (tf.train.Example، CSV، ...) ويحولها إلى مقتطفات. اليوم، يتم تمثيل المقتطفات على أنها بايتات إدخال خام مخزنة تحت tfma.INPUT_KEY ، ومع ذلك يمكن أن تكون المقتطفات في أي شكل متوافق مع خط أنابيب الاستخراج - مما يعني أنها تنشئ tfma.Extracts كمخرجات، وأن هذه المقتطفات متوافقة مع المصب النازعون. الأمر متروك للمستخرجين المختلفين لتوثيق ما يحتاجون إليه بوضوح.
اِستِخلاص
عملية الاستخراج عبارة عن قائمة من beam.PTransform PTransform التي يتم تشغيلها في سلسلة. يأخذ المستخرجون tfma.Extracts كمدخلات ويعيدون tfma.Extracts كمخرجات. المستخرج النموذجي الأولي هو tfma.extractors.PredictExtractor الذي يستخدم مستخلص الإدخال الناتج عن تحويل مدخلات القراءة وتشغيله من خلال نموذج لإنتاج مقتطفات تنبؤات. يمكن إدراج المستخرجات المخصصة في أي وقت بشرط أن تتوافق تحويلاتها مع tfma.Extracts in و tfma.Extracts out API. يتم تعريف النازع على النحو التالي:
# An Extractor is a PTransform that takes Extracts as input and returns
# Extracts as output. A typical example is a PredictExtractor that receives
# an 'input' placeholder for input and adds additional 'predictions' extracts.
Extractor = NamedTuple('Extractor', [
('stage_name', Text),
('ptransform', beam.PTransform)]) # Extracts -> Extracts
مستخرج الإدخال
يتم استخدام tfma.extractors.InputExtractor لاستخراج الميزات الأولية والتسميات الأولية وأوزان الأمثلة الأولية من سجلات tf.train.Example لاستخدامها في تقطيع المقاييس والحسابات. افتراضيًا، يتم تخزين القيم ضمن features استخراج المفاتيح labels و example_weights على التوالي. يتم تخزين تسميات نماذج الإخراج الفردي وأوزان الأمثلة مباشرةً كقيم np.ndarray . يتم تخزين تسميات النماذج متعددة المخرجات وأوزان الأمثلة كإملاءات لقيم np.ndarray (مرتبطة باسم المخرج). إذا تم إجراء تقييم متعدد النماذج، فسيتم تضمين التسميات وأوزان الأمثلة بشكل أكبر في إملاء آخر (مرتبط باسم النموذج).
توقع النازع
يقوم tfma.extractors.PredictExtractor بتشغيل تنبؤات النموذج ويخزنها ضمن predictions الرئيسية في إملاء tfma.Extracts . يتم تخزين تنبؤات نموذج الإخراج الفردي مباشرة كقيم الإخراج المتوقعة. يتم تخزين تنبؤات النماذج متعددة المخرجات كإملاء لقيم المخرجات (مرتبطة باسم المخرج). إذا تم إجراء تقييم متعدد النماذج، فسيتم تضمين التنبؤ بشكل أكبر في إملاء آخر (مرتبط باسم النموذج). تعتمد قيمة المخرجات الفعلية المستخدمة على النموذج (على سبيل المثال، مخرجات الإرجاع لمقدر TF في شكل إملاء بينما تقوم keras بإرجاع قيم np.ndarray ).
SliceKeyExtractor
يستخدم tfma.extractors.SliceKeyExtractor مواصفات التقطيع لتحديد الشرائح التي تنطبق على كل مثال مُدخل بناءً على الميزات المستخرجة ويضيف قيم التقطيع المتوافقة إلى المقتطفات ليستخدمها المقيِّمون لاحقًا.
تقييم
التقييم هو عملية أخذ المستخلص وتقييمه. على الرغم من أنه من الشائع إجراء التقييم في نهاية مسار الاستخراج، إلا أن هناك حالات استخدام تتطلب التقييم مبكرًا في عملية الاستخراج. وبما أن هؤلاء المقيمين يرتبطون بالمستخرجين الذين ينبغي تقييم مخرجاتهم على أساسهم. يتم تعريف المقيم على النحو التالي:
# An evaluator is a PTransform that takes Extracts as input and
# produces an Evaluation as output. A typical example of an evaluator
# is the MetricsAndPlotsEvaluator that takes the 'features', 'labels',
# and 'predictions' extracts from the PredictExtractor and evaluates
# them using post export metrics to produce metrics and plots dictionaries.
Evaluator = NamedTuple('Evaluator', [
('stage_name', Text),
('run_after', Text), # Extractor.stage_name
('ptransform', beam.PTransform)]) # Extracts -> Evaluation
لاحظ أن المقيم عبارة عن beam.PTransform تأخذ tfma.Extracts كمدخلات. لا يوجد ما يمنع التنفيذ من إجراء تحويلات إضافية على المقتطفات كجزء من عملية التقييم. على عكس المستخرجين الذين يجب عليهم إرجاع إملاء tfma.Extracts ، لا توجد قيود على أنواع المخرجات التي يمكن للمقيم إنتاجها على الرغم من أن معظم المقيمين أيضًا يقومون بإرجاع إملاء (على سبيل المثال، أسماء وقيم القياس).
MetricsAndPlotsEvaluator
يأخذ tfma.evaluators.MetricsAndPlotsEvaluator features labels predictions كمدخلات، ويقوم بتشغيلها من خلال tfma.slicer.FanoutSlices لتجميعها حسب الشرائح، ثم يقوم بتنفيذ المقاييس وحسابات المخططات. وينتج مخرجات في شكل قواميس للمقاييس ومفاتيح المخططات والقيم (يتم تحويلها لاحقًا إلى نماذج أولية متسلسلة للإخراج بواسطة tfma.writers.MetricsAndPlotsWriter ).
كتابة النتائج
مرحلة WriteResults هي حيث تتم كتابة مخرجات التقييم على القرص. يستخدم WriteResults الكتاب لكتابة البيانات بناءً على مفاتيح الإخراج. على سبيل المثال، قد يحتوي tfma.evaluators.Evaluation على مفاتيح metrics plots . سيتم بعد ذلك ربطها بقواميس المقاييس والمؤامرات التي تسمى "المقاييس" و"المؤامرات". يحدد الكتاب كيفية كتابة كل ملف:
# A writer is a PTransform that takes evaluation output as input and
# serializes the associated PCollections of data to a sink.
Writer = NamedTuple('Writer', [
('stage_name', Text),
('ptransform', beam.PTransform)]) # Evaluation -> PDone
المقاييس والمؤامرات
نحن نقدم tfma.writers.MetricsAndPlotsWriter الذي يحول المقاييس والقواميس إلى نماذج أولية متسلسلة ويكتبها على القرص.
إذا كنت ترغب في استخدام تنسيق تسلسل مختلف، فيمكنك إنشاء كاتب مخصص واستخدامه بدلاً من ذلك. نظرًا لأن tfma.evaluators.Evaluation الذي تم تمريره إلى الكتاب يحتوي على مخرجات جميع المقيمين مجتمعين، يتم توفير تحويل مساعد tfma.writers.Write يمكن للكتاب استخدامه في تطبيقات ptransform الخاصة بهم لتحديد beam.PCollection المناسبة. PCollection s استنادًا إلى مفتاح الإخراج (انظر أدناه للحصول على مثال).
التخصيص
يستخدم الأسلوب tfma.run_model_analysis وسيطات extractors evaluators writers لتخصيص المستخرجين والمقيمين والكتاب الذين يستخدمهم المسار. إذا لم يتم توفير أي وسائط، فسيتم استخدام tfma.default_extractors و tfma.default_evaluators و tfma.default_writers بشكل افتراضي.
النازعون المخصصون
لإنشاء مستخرج مخصص، قم بإنشاء نوع tfma.extractors.Extractor الذي يغلف beam.PTransform PTransform يأخذ tfma.Extracts كمدخل ويعيد tfma.Extracts كمخرجات. تتوفر أمثلة على المستخرجات ضمن tfma.extractors .
المقيمون المخصصون
لإنشاء مقيم مخصص، قم بإنشاء نوع tfma.evaluators.Evaluator الذي يغلف beam.PTransform PTransform يأخذ tfma.Extracts كمدخل ويعيد tfma.evaluators.Evaluation كمخرجات. يمكن للمقيم الأساسي أن يأخذ مقتطفات tfma.Extracts الواردة ويخرجها لتخزينها في جدول. وهذا هو بالضبط ما يفعله tfma.evaluators.AnalysisTableEvaluator . قد يقوم مقيم أكثر تعقيدًا بإجراء معالجة إضافية وتجميع البيانات. راجع tfma.evaluators.MetricsAndPlotsEvaluator كمثال.
لاحظ أنه يمكن تخصيص tfma.evaluators.MetricsAndPlotsEvaluator نفسه لدعم المقاييس المخصصة (راجع المقاييس لمزيد من التفاصيل).
كاتبين مخصصين
لإنشاء كاتب مخصص، قم بإنشاء نوع tfma.writers.Writer الذي يلتف على beam.PTransform PTransform يأخذ tfma.evaluators.Evaluation كمدخل ويعيدشعاع. beam.pvalue.PDone كمخرج. فيما يلي مثال أساسي للكاتب لكتابة سجلات TFRecords التي تحتوي على مقاييس:
tfma.writers.Writer(
stage_name='WriteTFRecord(%s)' % tfma.METRICS_KEY,
ptransform=tfma.writers.Write(
key=tfma.METRICS_KEY,
ptransform=beam.io.WriteToTFRecord(file_path_prefix=output_file))
تعتمد مدخلات الكاتب على مخرجات المقيم المرتبط. بالنسبة للمثال أعلاه، فإن الإخراج عبارة عن نموذج أولي متسلسل تم إنتاجه بواسطة tfma.evaluators.MetricsAndPlotsEvaluator . سيكون كاتب tfma.evaluators.AnalysisTableEvaluator مسؤولاً عن كتابة beam.pvalue.PCollection من tfma.Extracts .
لاحظ أن الكاتب مرتبط بمخرجات المقيم عبر مفتاح المخرجات المستخدم (على سبيل المثال tfma.METRICS_KEY ، tfma.ANALYSIS_KEY ، إلخ).
مثال خطوة بخطوة
فيما يلي مثال على الخطوات المتبعة في مسار الاستخراج والتقييم عند استخدام كل من tfma.evaluators.MetricsAndPlotsEvaluator و tfma.evaluators.AnalysisTableEvaluator :
run_model_analysis(
...
extractors=[
tfma.extractors.InputExtractor(...),
tfma.extractors.PredictExtractor(...),
tfma.extractors.SliceKeyExtrator(...)
],
evaluators=[
tfma.evaluators.MetricsAndPlotsEvaluator(...),
tfma.evaluators.AnalysisTableEvaluator(...)
])
ReadInputs
# Out
Extracts {
'input': bytes # CSV, Proto, ...
}
ExtractAndEvaluate
# In: ReadInputs Extracts
# Out:
Extracts {
'input': bytes # CSV, Proto, ...
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
}
# In: InputExtractor Extracts
# Out:
Extracts {
'input': bytes # CSV, Proto, ...
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
'predictions': tensor_like # Predictions
}
# In: PredictExtractor Extracts
# Out:
Extracts {
'features': tensor_like # Raw features
'labels': tensor_like # Labels
'example_weights': tensor_like # Example weights
'predictions': tensor_like # Predictions
'slice_key': Tuple[bytes...] # Slice
}
tfma.evaluators.MetricsAndPlotsEvaluator(run_after:SLICE_KEY_EXTRACTOR_STAGE_NAME)
# In: SliceKeyExtractor Extracts
# Out:
Evaluation {
'metrics': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from metric key to metric values)
'plots': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from plot key to plot values)
}
tfma.evaluators.AnalysisTableEvaluator(run_after:LAST_EXTRACTOR_STAGE_NAME)
# In: SliceKeyExtractor Extracts
# Out:
Evaluation {
'analysis': PCollection[Extracts] # Final Extracts
}
WriteResults
# In:
Evaluation {
'metrics': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from metric key to metric values)
'plots': PCollection[Tuple[slicer.SliceKeyType, Dict[Text, Any]]] # Tuples of (slice key, dictionary from plot key to plot values)
'analysis': PCollection[Extracts] # Final Extracts
}
# Out: metrics, plots, and analysis files