
| | |  Voir la source sur GitHub Voir la source sur GitHub | |
Ce didacticiel présente les encodeurs automatiques avec trois exemples : les bases, le débruitage d'image et la détection d'anomalies.
Un auto-encodeur est un type spécial de réseau neuronal qui est formé pour copier son entrée vers sa sortie. Par exemple, étant donné une image d'un chiffre manuscrit, un auto-encodeur encode d'abord l'image dans une représentation latente de dimension inférieure, puis décode la représentation latente en une image. Un auto-encodeur apprend à compresser les données tout en minimisant l'erreur de reconstruction.
Pour en savoir plus sur les encodeurs automatiques, veuillez lire le chapitre 14 de Deep Learning par Ian Goodfellow, Yoshua Bengio et Aaron Courville.
Importer TensorFlow et d'autres bibliothèques
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
from sklearn.metrics import accuracy_score, precision_score, recall_score
from sklearn.model_selection import train_test_split
from tensorflow.keras import layers, losses
from tensorflow.keras.datasets import fashion_mnist
from tensorflow.keras.models import Model
Charger le jeu de données
Pour commencer, vous allez entraîner l'encodeur automatique de base à l'aide du jeu de données Fashion MNIST. Chaque image de cet ensemble de données mesure 28 x 28 pixels.
(x_train, _), (x_test, _) = fashion_mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
print (x_train.shape)
print (x_test.shape)
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 32768/29515 [=================================] - 0s 0us/step 40960/29515 [=========================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26427392/26421880 [==============================] - 0s 0us/step 26435584/26421880 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 16384/5148 [===============================================================================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4423680/4422102 [==============================] - 0s 0us/step 4431872/4422102 [==============================] - 0s 0us/step (60000, 28, 28) (10000, 28, 28)
Premier exemple : encodeur automatique de base

Définissez un auto-encodeur avec deux couches denses : un encoder , qui comprime les images en un vecteur latent de 64 dimensions, et un decoder , qui reconstruit l'image originale à partir de l'espace latent.
Pour définir votre modèle, utilisez l' API Keras Model Subclassing .
latent_dim = 64
class Autoencoder(Model):
def __init__(self, latent_dim):
super(Autoencoder, self).__init__()
self.latent_dim = latent_dim
self.encoder = tf.keras.Sequential([
layers.Flatten(),
layers.Dense(latent_dim, activation='relu'),
])
self.decoder = tf.keras.Sequential([
layers.Dense(784, activation='sigmoid'),
layers.Reshape((28, 28))
])
def call(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return decoded
autoencoder = Autoencoder(latent_dim)
autoencoder.compile(optimizer='adam', loss=losses.MeanSquaredError())
Entraînez le modèle en utilisant x_train comme entrée et comme cible. L' encoder apprendra à compresser l'ensemble de données de 784 dimensions à l'espace latent, et le decoder apprendra à reconstruire les images originales. .
autoencoder.fit(x_train, x_train,
epochs=10,
shuffle=True,
validation_data=(x_test, x_test))
Epoch 1/10 1875/1875 [==============================] - 4s 2ms/step - loss: 0.0243 - val_loss: 0.0140 Epoch 2/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.0116 - val_loss: 0.0106 Epoch 3/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.0100 - val_loss: 0.0098 Epoch 4/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.0094 - val_loss: 0.0094 Epoch 5/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.0092 - val_loss: 0.0092 Epoch 6/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.0090 - val_loss: 0.0091 Epoch 7/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.0090 - val_loss: 0.0090 Epoch 8/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.0089 - val_loss: 0.0090 Epoch 9/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.0088 - val_loss: 0.0089 Epoch 10/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.0088 - val_loss: 0.0089 <keras.callbacks.History at 0x7ff1d35df550>
Maintenant que le modèle est entraîné, testons-le en encodant et en décodant les images de l'ensemble de test.
encoded_imgs = autoencoder.encoder(x_test).numpy()
decoded_imgs = autoencoder.decoder(encoded_imgs).numpy()
n = 10
plt.figure(figsize=(20, 4))
for i in range(n):
# display original
ax = plt.subplot(2, n, i + 1)
plt.imshow(x_test[i])
plt.title("original")
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# display reconstruction
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(decoded_imgs[i])
plt.title("reconstructed")
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()

Deuxième exemple : Débruitage d'image

Un auto-encodeur peut également être formé pour supprimer le bruit des images. Dans la section suivante, vous allez créer une version bruitée du jeu de données Fashion MNIST en appliquant un bruit aléatoire à chaque image. Vous entraînerez ensuite un encodeur automatique en utilisant l'image bruitée comme entrée et l'image d'origine comme cible.
Réimportons le jeu de données pour omettre les modifications apportées précédemment.
(x_train, _), (x_test, _) = fashion_mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = x_train[..., tf.newaxis]
x_test = x_test[..., tf.newaxis]
print(x_train.shape)
(60000, 28, 28, 1)
Ajout de bruit aléatoire aux images
noise_factor = 0.2
x_train_noisy = x_train + noise_factor * tf.random.normal(shape=x_train.shape)
x_test_noisy = x_test + noise_factor * tf.random.normal(shape=x_test.shape)
x_train_noisy = tf.clip_by_value(x_train_noisy, clip_value_min=0., clip_value_max=1.)
x_test_noisy = tf.clip_by_value(x_test_noisy, clip_value_min=0., clip_value_max=1.)
Tracez les images bruitées.
n = 10
plt.figure(figsize=(20, 2))
for i in range(n):
ax = plt.subplot(1, n, i + 1)
plt.title("original + noise")
plt.imshow(tf.squeeze(x_test_noisy[i]))
plt.gray()
plt.show()

Définir un auto-encodeur convolutif
Dans cet exemple, vous allez entraîner un auto-encodeur convolutif à l'aide de couches Conv2D dans l' encoder et de couches Conv2DTranspose dans le decoder .
class Denoise(Model):
def __init__(self):
super(Denoise, self).__init__()
self.encoder = tf.keras.Sequential([
layers.Input(shape=(28, 28, 1)),
layers.Conv2D(16, (3, 3), activation='relu', padding='same', strides=2),
layers.Conv2D(8, (3, 3), activation='relu', padding='same', strides=2)])
self.decoder = tf.keras.Sequential([
layers.Conv2DTranspose(8, kernel_size=3, strides=2, activation='relu', padding='same'),
layers.Conv2DTranspose(16, kernel_size=3, strides=2, activation='relu', padding='same'),
layers.Conv2D(1, kernel_size=(3, 3), activation='sigmoid', padding='same')])
def call(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return decoded
autoencoder = Denoise()
autoencoder.compile(optimizer='adam', loss=losses.MeanSquaredError())
autoencoder.fit(x_train_noisy, x_train,
epochs=10,
shuffle=True,
validation_data=(x_test_noisy, x_test))
Epoch 1/10 1875/1875 [==============================] - 8s 3ms/step - loss: 0.0169 - val_loss: 0.0107 Epoch 2/10 1875/1875 [==============================] - 6s 3ms/step - loss: 0.0095 - val_loss: 0.0086 Epoch 3/10 1875/1875 [==============================] - 6s 3ms/step - loss: 0.0082 - val_loss: 0.0080 Epoch 4/10 1875/1875 [==============================] - 6s 3ms/step - loss: 0.0078 - val_loss: 0.0077 Epoch 5/10 1875/1875 [==============================] - 6s 3ms/step - loss: 0.0076 - val_loss: 0.0075 Epoch 6/10 1875/1875 [==============================] - 6s 3ms/step - loss: 0.0074 - val_loss: 0.0074 Epoch 7/10 1875/1875 [==============================] - 6s 3ms/step - loss: 0.0073 - val_loss: 0.0073 Epoch 8/10 1875/1875 [==============================] - 6s 3ms/step - loss: 0.0072 - val_loss: 0.0072 Epoch 9/10 1875/1875 [==============================] - 6s 3ms/step - loss: 0.0071 - val_loss: 0.0071 Epoch 10/10 1875/1875 [==============================] - 6s 3ms/step - loss: 0.0070 - val_loss: 0.0071 <keras.callbacks.History at 0x7ff1c45a31d0>
Jetons un coup d'œil à un résumé de l'encodeur. Remarquez comment les images sont sous-échantillonnées de 28x28 à 7x7.
autoencoder.encoder.summary()
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 14, 14, 16) 160
conv2d_1 (Conv2D) (None, 7, 7, 8) 1160
=================================================================
Total params: 1,320
Trainable params: 1,320
Non-trainable params: 0
_________________________________________________________________
Le décodeur suréchantillonne les images de 7x7 à 28x28.
autoencoder.decoder.summary()
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_transpose (Conv2DTra (None, 14, 14, 8) 584
nspose)
conv2d_transpose_1 (Conv2DT (None, 28, 28, 16) 1168
ranspose)
conv2d_2 (Conv2D) (None, 28, 28, 1) 145
=================================================================
Total params: 1,897
Trainable params: 1,897
Non-trainable params: 0
_________________________________________________________________
Tracer à la fois les images bruitées et les images débruitées produites par l'auto-encodeur.
encoded_imgs = autoencoder.encoder(x_test).numpy()
decoded_imgs = autoencoder.decoder(encoded_imgs).numpy()
n = 10
plt.figure(figsize=(20, 4))
for i in range(n):
# display original + noise
ax = plt.subplot(2, n, i + 1)
plt.title("original + noise")
plt.imshow(tf.squeeze(x_test_noisy[i]))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# display reconstruction
bx = plt.subplot(2, n, i + n + 1)
plt.title("reconstructed")
plt.imshow(tf.squeeze(decoded_imgs[i]))
plt.gray()
bx.get_xaxis().set_visible(False)
bx.get_yaxis().set_visible(False)
plt.show()

Troisième exemple : détection d'anomalies
Aperçu
Dans cet exemple, vous entraînerez un auto-encodeur pour détecter les anomalies sur le jeu de données ECG5000 . Cet ensemble de données contient 5 000 électrocardiogrammes , chacun avec 140 points de données. Vous utiliserez une version simplifiée du jeu de données, où chaque exemple a été étiqueté soit 0 (correspondant à un rythme anormal), soit 1 (correspondant à un rythme normal). Vous êtes intéressé à identifier les rythmes anormaux.
Comment détecterez-vous les anomalies à l'aide d'un encodeur automatique ? Rappelons qu'un auto-encodeur est formé pour minimiser l'erreur de reconstruction. Vous entraînerez un auto-encodeur sur les rythmes normaux uniquement, puis l'utiliserez pour reconstruire toutes les données. Notre hypothèse est que les rythmes anormaux auront une erreur de reconstruction plus élevée. Vous qualifierez alors un rythme d'anomalie si l'erreur de reconstruction dépasse un seuil fixé.
Charger les données ECG
L'ensemble de données que vous utiliserez est basé sur celui de timeseriesclassification.com .
# Download the dataset
dataframe = pd.read_csv('http://storage.googleapis.com/download.tensorflow.org/data/ecg.csv', header=None)
raw_data = dataframe.values
dataframe.head()
# The last element contains the labels
labels = raw_data[:, -1]
# The other data points are the electrocadriogram data
data = raw_data[:, 0:-1]
train_data, test_data, train_labels, test_labels = train_test_split(
data, labels, test_size=0.2, random_state=21
)
Normaliser les données à [0,1] .
min_val = tf.reduce_min(train_data)
max_val = tf.reduce_max(train_data)
train_data = (train_data - min_val) / (max_val - min_val)
test_data = (test_data - min_val) / (max_val - min_val)
train_data = tf.cast(train_data, tf.float32)
test_data = tf.cast(test_data, tf.float32)
Vous entraînerez l'auto-encodeur en utilisant uniquement les rythmes normaux, qui sont étiquetés dans cet ensemble de données comme 1 . Séparez les rythmes normaux des rythmes anormaux.
train_labels = train_labels.astype(bool)
test_labels = test_labels.astype(bool)
normal_train_data = train_data[train_labels]
normal_test_data = test_data[test_labels]
anomalous_train_data = train_data[~train_labels]
anomalous_test_data = test_data[~test_labels]
Tracez un ECG normal.
plt.grid()
plt.plot(np.arange(140), normal_train_data[0])
plt.title("A Normal ECG")
plt.show()
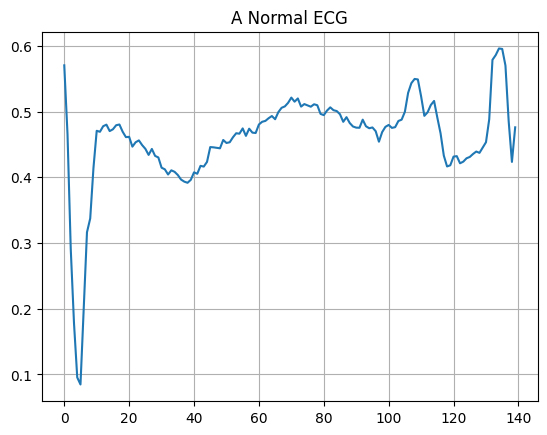
Tracez un ECG anormal.
plt.grid()
plt.plot(np.arange(140), anomalous_train_data[0])
plt.title("An Anomalous ECG")
plt.show()
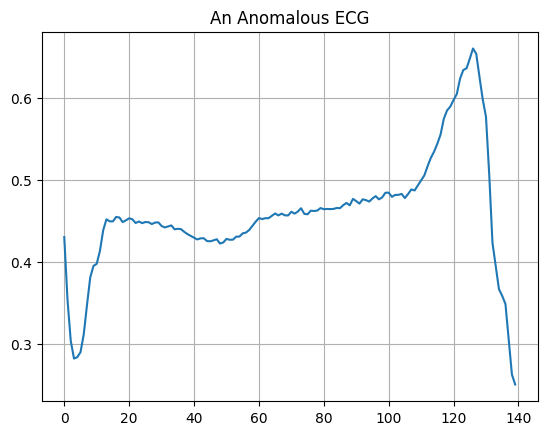
Construire le modèle
class AnomalyDetector(Model):
def __init__(self):
super(AnomalyDetector, self).__init__()
self.encoder = tf.keras.Sequential([
layers.Dense(32, activation="relu"),
layers.Dense(16, activation="relu"),
layers.Dense(8, activation="relu")])
self.decoder = tf.keras.Sequential([
layers.Dense(16, activation="relu"),
layers.Dense(32, activation="relu"),
layers.Dense(140, activation="sigmoid")])
def call(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return decoded
autoencoder = AnomalyDetector()
autoencoder.compile(optimizer='adam', loss='mae')
Notez que l'auto-encodeur est formé en utilisant uniquement les ECG normaux, mais est évalué en utilisant l'ensemble de test complet.
history = autoencoder.fit(normal_train_data, normal_train_data,
epochs=20,
batch_size=512,
validation_data=(test_data, test_data),
shuffle=True)
Epoch 1/20 5/5 [==============================] - 1s 33ms/step - loss: 0.0576 - val_loss: 0.0531 Epoch 2/20 5/5 [==============================] - 0s 8ms/step - loss: 0.0552 - val_loss: 0.0514 Epoch 3/20 5/5 [==============================] - 0s 8ms/step - loss: 0.0519 - val_loss: 0.0499 Epoch 4/20 5/5 [==============================] - 0s 8ms/step - loss: 0.0483 - val_loss: 0.0475 Epoch 5/20 5/5 [==============================] - 0s 8ms/step - loss: 0.0445 - val_loss: 0.0451 Epoch 6/20 5/5 [==============================] - 0s 8ms/step - loss: 0.0409 - val_loss: 0.0432 Epoch 7/20 5/5 [==============================] - 0s 8ms/step - loss: 0.0377 - val_loss: 0.0415 Epoch 8/20 5/5 [==============================] - 0s 8ms/step - loss: 0.0348 - val_loss: 0.0401 Epoch 9/20 5/5 [==============================] - 0s 8ms/step - loss: 0.0319 - val_loss: 0.0388 Epoch 10/20 5/5 [==============================] - 0s 8ms/step - loss: 0.0293 - val_loss: 0.0378 Epoch 11/20 5/5 [==============================] - 0s 8ms/step - loss: 0.0273 - val_loss: 0.0369 Epoch 12/20 5/5 [==============================] - 0s 8ms/step - loss: 0.0259 - val_loss: 0.0361 Epoch 13/20 5/5 [==============================] - 0s 8ms/step - loss: 0.0249 - val_loss: 0.0354 Epoch 14/20 5/5 [==============================] - 0s 8ms/step - loss: 0.0239 - val_loss: 0.0346 Epoch 15/20 5/5 [==============================] - 0s 8ms/step - loss: 0.0230 - val_loss: 0.0340 Epoch 16/20 5/5 [==============================] - 0s 8ms/step - loss: 0.0222 - val_loss: 0.0335 Epoch 17/20 5/5 [==============================] - 0s 8ms/step - loss: 0.0215 - val_loss: 0.0331 Epoch 18/20 5/5 [==============================] - 0s 9ms/step - loss: 0.0211 - val_loss: 0.0331 Epoch 19/20 5/5 [==============================] - 0s 8ms/step - loss: 0.0208 - val_loss: 0.0329 Epoch 20/20 5/5 [==============================] - 0s 8ms/step - loss: 0.0206 - val_loss: 0.0327
plt.plot(history.history["loss"], label="Training Loss")
plt.plot(history.history["val_loss"], label="Validation Loss")
plt.legend()
<matplotlib.legend.Legend at 0x7ff1d339b790>
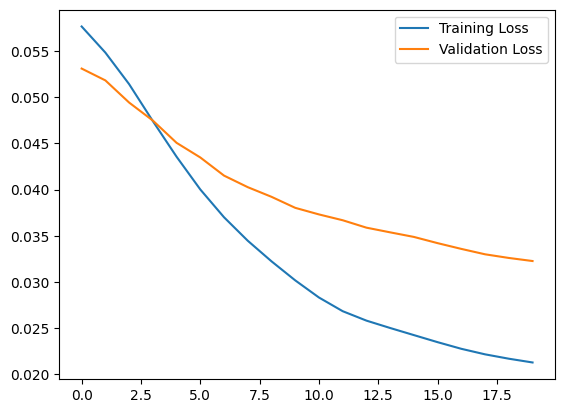
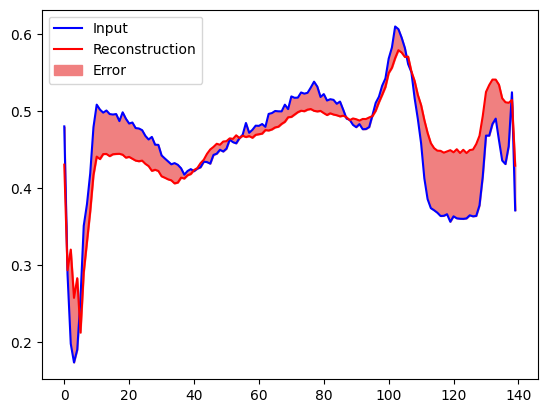
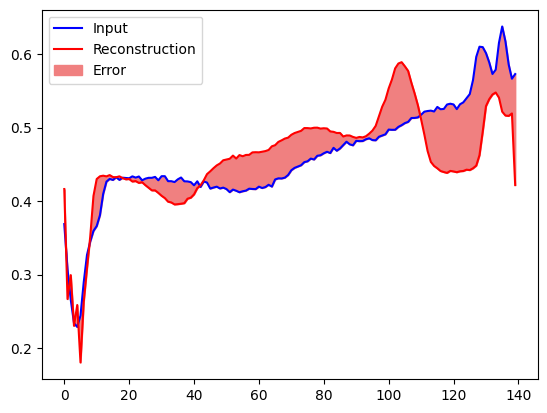
Vous classifierez bientôt un ECG comme anormal si l'erreur de reconstruction est supérieure à un écart type par rapport aux exemples d'entraînement normaux. Tout d'abord, traçons un ECG normal à partir de l'ensemble d'apprentissage, la reconstruction après son codage et son décodage par l'auto-encodeur et l'erreur de reconstruction.
encoded_data = autoencoder.encoder(normal_test_data).numpy()
decoded_data = autoencoder.decoder(encoded_data).numpy()
plt.plot(normal_test_data[0], 'b')
plt.plot(decoded_data[0], 'r')
plt.fill_between(np.arange(140), decoded_data[0], normal_test_data[0], color='lightcoral')
plt.legend(labels=["Input", "Reconstruction", "Error"])
plt.show()
Créez un tracé similaire, cette fois pour un exemple de test anormal.
encoded_data = autoencoder.encoder(anomalous_test_data).numpy()
decoded_data = autoencoder.decoder(encoded_data).numpy()
plt.plot(anomalous_test_data[0], 'b')
plt.plot(decoded_data[0], 'r')
plt.fill_between(np.arange(140), decoded_data[0], anomalous_test_data[0], color='lightcoral')
plt.legend(labels=["Input", "Reconstruction", "Error"])
plt.show()
Détecter les anomalies
Détectez les anomalies en calculant si la perte de reconstruction est supérieure à un seuil fixé. Dans ce didacticiel, vous allez calculer l'erreur moyenne moyenne pour les exemples normaux de l'ensemble d'apprentissage, puis classer les futurs exemples comme anormaux si l'erreur de reconstruction est supérieure à un écart type par rapport à l'ensemble d'apprentissage.
Tracer l'erreur de reconstruction sur des ECG normaux à partir de l'ensemble d'apprentissage
reconstructions = autoencoder.predict(normal_train_data)
train_loss = tf.keras.losses.mae(reconstructions, normal_train_data)
plt.hist(train_loss[None,:], bins=50)
plt.xlabel("Train loss")
plt.ylabel("No of examples")
plt.show()

Choisissez une valeur de seuil située à un écart type au-dessus de la moyenne.
threshold = np.mean(train_loss) + np.std(train_loss)
print("Threshold: ", threshold)
Threshold: 0.03241627
Si vous examinez l'erreur de reconstruction pour les exemples anormaux dans le jeu de test, vous remarquerez que la plupart ont une erreur de reconstruction supérieure au seuil. En faisant varier le seuil, vous pouvez ajuster la précision et le rappel de votre classifieur.
reconstructions = autoencoder.predict(anomalous_test_data)
test_loss = tf.keras.losses.mae(reconstructions, anomalous_test_data)
plt.hist(test_loss[None, :], bins=50)
plt.xlabel("Test loss")
plt.ylabel("No of examples")
plt.show()

Classer un ECG comme une anomalie si l'erreur de reconstruction est supérieure au seuil.
def predict(model, data, threshold):
reconstructions = model(data)
loss = tf.keras.losses.mae(reconstructions, data)
return tf.math.less(loss, threshold)
def print_stats(predictions, labels):
print("Accuracy = {}".format(accuracy_score(labels, predictions)))
print("Precision = {}".format(precision_score(labels, predictions)))
print("Recall = {}".format(recall_score(labels, predictions)))
preds = predict(autoencoder, test_data, threshold)
print_stats(preds, test_labels)
Accuracy = 0.944 Precision = 0.9921875 Recall = 0.9071428571428571
Prochaines étapes
Pour en savoir plus sur la détection d'anomalies avec les encodeurs automatiques, consultez cet excellent exemple interactif construit avec TensorFlow.js par Victor Dibia. Pour un cas d'utilisation réel, vous pouvez découvrir comment Airbus détecte les anomalies dans les données de télémétrie ISS à l' aide de TensorFlow. Pour en savoir plus sur les bases, pensez à lire cet article de blog de François Chollet. Pour plus de détails, consultez le chapitre 14 de Deep Learning par Ian Goodfellow, Yoshua Bengio et Aaron Courville.