
| |
|
 GitHub でソースを表示 GitHub でソースを表示 |
このチュートリアルでは、(深層)強化学習のポリシー勾配メソッドを理解していることを前提に、TensorFlow を使用して Actor-Critic 法を実装し、Open AI Gym の CartPole-v0 環境のエージェントをトレーニングする方法を示します。
Actor-Critic 法
Actor-Critic 法は、価値関数から独立してポリシー関数を表すTD(時間的差分)学習の手法です。
ポリシー関数(またはポリシー)は、ある特定の状態に基づいてエージェントが実行できるアクションの確率分布を返します。価値関数は、特定の状態で開始し、その後永久に特定のポリシーに従って動作するエージェントの期待される戻り値を決定します。
Actor-Critic 法では、ポリシーは状態に応じて一連の可能なアクションを提案する「アクター」と呼ばれます。推定される価値関数は「クリティック’と呼ばれ、特定のポリシーに基づいて「アクター」が実行するアクションを評価します。
このチュートリアルでは、アクターとクリティックは、2 つの出力を持つ 1 つのニューラルネットワークを使って表現されます。
CartPole-v0
CartPole-v0 環境では、ポールは摩擦のないレール上を移動するカートに取り付けられています。ポールは直立状態で始まり、エージェントの目標は、カートに -1 または +1 の力を加えてポールが倒れないようにすることです。ポールが直立状態を維持する時間ステップごとに +1 の報酬が与えられます。エピソードは、(1)ポールが直立から 15 度以上に傾斜したとき、または(2)カートが中央から 2.4 ユニット以上移動したときに、終了します。
<figure>
<image src="https://tensorflow.org/tutorials/reinforcement_learning/images/cartpole-v0.gif">
<figcaption>
Trained actor-critic model in Cartpole-v0 environment
</figcaption>
</figure>この問題は、100 回の連続トライアルにおいて、エピソードの平均合計報酬が 195 に達すると「解決」とみなされます。
セットアップ
必要なパッケージをインポートし、グローバル設定を構成します。
pip install gym[classic_control]pip install pyglet
# Install additional packages for visualizationsudo apt-get install -y python-opengl > /dev/null 2>&1pip install git+https://github.com/tensorflow/docs > /dev/null 2>&1
import collections
import gym
import numpy as np
import statistics
import tensorflow as tf
import tqdm
from matplotlib import pyplot as plt
from tensorflow.keras import layers
from typing import Any, List, Sequence, Tuple
# Create the environment
env = gym.make("CartPole-v1")
# Set seed for experiment reproducibility
seed = 42
tf.random.set_seed(seed)
np.random.seed(seed)
# Small epsilon value for stabilizing division operations
eps = np.finfo(np.float32).eps.item()
2024-01-11 20:25:03.412854: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered 2024-01-11 20:25:03.412898: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered 2024-01-11 20:25:03.414545: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
モデル
アクターとクリティックは、アクションの確率とクリティック値をそれぞれ生成する 1 つのニューラルネットワークを使ってモデル化されます。このチュートリアルでは、モデルの定義にモデルのサブクラス化を使用します。
フォワードパス中、モデルは、状態を入力として取り、アクション確率とクリティック値 \(V\) の両方を出力し、これによって状態に依存する価値関数を形成します。期待される戻り値を最大化するポリシー \(\pi\) に基づいてアクションを選択するモデルをトレーニングするのが目標です。
CartPole-v0 では、状態は 4 つの値で表現されます。カートの位置、カートの速度、ポールの角度、およびポールの速度です。エージェントは 2 つのアクションを取って、カートを左(0)と右(1)に押します。
詳細については、Gym's Cart Pole ドキュメントページと Barto, Sutton and Anderson (1983) の「Neuronlike adaptive elements that can solve difficult learning control problems」をご覧ください。
class ActorCritic(tf.keras.Model):
"""Combined actor-critic network."""
def __init__(
self,
num_actions: int,
num_hidden_units: int):
"""Initialize."""
super().__init__()
self.common = layers.Dense(num_hidden_units, activation="relu")
self.actor = layers.Dense(num_actions)
self.critic = layers.Dense(1)
def call(self, inputs: tf.Tensor) -> Tuple[tf.Tensor, tf.Tensor]:
x = self.common(inputs)
return self.actor(x), self.critic(x)
num_actions = env.action_space.n # 2
num_hidden_units = 128
model = ActorCritic(num_actions, num_hidden_units)
エージェントをトレーニングする
エージェントをトレーニングするには、次の手順を実行します。
- 環境でエージェントを実行し、エピソードごとのトレーニングデータを収集します。
- 時間ステップごとに期待される戻り値を計算します。
- Actor-Critic の混合モデルの損失を計算します。
- 勾配を計算し、ネットワークパラメーターを更新します。
- 成功基準または最大エピソード数に達するまで、1~4 の手順を繰り返します。
1. トレーニングデータを収集する
アクタークリティックモデルのトレーニングでは、教師あり学習と同様にトレーニングデータが必要です。ただし、そのようなデータを収集するには、モデルを環境で「実行」する必要があります。
トレーニングデータは、エピソードごとに収集されます。次に、モデルの重みによってパラメーター化された現在のポリシーに基づいてアクションの確率とクリティック値を生成するために、時間ステップごとにモデルのフォワードパスが環境の状態で実行されます。
次のアクションはモデルが生成したアクション確率からサンプリングされます。これが環境に適用されると、次の状態と報酬が生成されます。
このプロセスは、run_episode 関数に実装されます。後で TensorFlow グラフにコンパイルしてトレーニングを加速化できるように、TensorFlow 演算が使用されています。可変長配列でテンソルをイテレーションできるように、tf.TensorArray が使用されていることに注意してください。
# Wrap Gym's `env.step` call as an operation in a TensorFlow function.
# This would allow it to be included in a callable TensorFlow graph.
def env_step(action: np.ndarray) -> Tuple[np.ndarray, np.ndarray, np.ndarray]:
"""Returns state, reward and done flag given an action."""
state, reward, done, truncated, info = env.step(action)
return (state.astype(np.float32),
np.array(reward, np.int32),
np.array(done, np.int32))
def tf_env_step(action: tf.Tensor) -> List[tf.Tensor]:
return tf.numpy_function(env_step, [action],
[tf.float32, tf.int32, tf.int32])
def run_episode(
initial_state: tf.Tensor,
model: tf.keras.Model,
max_steps: int) -> Tuple[tf.Tensor, tf.Tensor, tf.Tensor]:
"""Runs a single episode to collect training data."""
action_probs = tf.TensorArray(dtype=tf.float32, size=0, dynamic_size=True)
values = tf.TensorArray(dtype=tf.float32, size=0, dynamic_size=True)
rewards = tf.TensorArray(dtype=tf.int32, size=0, dynamic_size=True)
initial_state_shape = initial_state.shape
state = initial_state
for t in tf.range(max_steps):
# Convert state into a batched tensor (batch size = 1)
state = tf.expand_dims(state, 0)
# Run the model and to get action probabilities and critic value
action_logits_t, value = model(state)
# Sample next action from the action probability distribution
action = tf.random.categorical(action_logits_t, 1)[0, 0]
action_probs_t = tf.nn.softmax(action_logits_t)
# Store critic values
values = values.write(t, tf.squeeze(value))
# Store log probability of the action chosen
action_probs = action_probs.write(t, action_probs_t[0, action])
# Apply action to the environment to get next state and reward
state, reward, done = tf_env_step(action)
state.set_shape(initial_state_shape)
# Store reward
rewards = rewards.write(t, reward)
if tf.cast(done, tf.bool):
break
action_probs = action_probs.stack()
values = values.stack()
rewards = rewards.stack()
return action_probs, values, rewards
2. 期待される戻り値を計算する
1 つのエピソード中に収集される各時間ステップ \(t\) の報酬のシーケンス \({r_{t} }^{T}{t=1}\) は、期待される戻り値のシーケンス \({G{t} }^{T}_{t=1}\) に変換されます。ここで、報酬の合計は現在の時間ステップ \(t\) ~ \(T\) から取得され、各報酬は指数関数で気に減衰するディスカウント要因 \(\gamma\) で乗算されます。
\[G_{t} = \sum^{T}*{t'=t} \gamma^{t'-t}r*{t'}\]
\(\gamma\in(0,1)\) であるため、現在の時間ステップ以降の報酬には与えられる重みは、徐々に少なくなります。
直感的に、期待される戻り値は単に、現在の報酬が後の報酬より良いことを示しています。数学的に見れば、報酬の合計が収束することが保証されています。
トレーニングを安定化するには、生成される戻り値のシーケンスも標準化されます(つまり、平均と単位標準偏差がゼロ)。
def get_expected_return(
rewards: tf.Tensor,
gamma: float,
standardize: bool = True) -> tf.Tensor:
"""Compute expected returns per timestep."""
n = tf.shape(rewards)[0]
returns = tf.TensorArray(dtype=tf.float32, size=n)
# Start from the end of `rewards` and accumulate reward sums
# into the `returns` array
rewards = tf.cast(rewards[::-1], dtype=tf.float32)
discounted_sum = tf.constant(0.0)
discounted_sum_shape = discounted_sum.shape
for i in tf.range(n):
reward = rewards[i]
discounted_sum = reward + gamma * discounted_sum
discounted_sum.set_shape(discounted_sum_shape)
returns = returns.write(i, discounted_sum)
returns = returns.stack()[::-1]
if standardize:
returns = ((returns - tf.math.reduce_mean(returns)) /
(tf.math.reduce_std(returns) + eps))
return returns
3. Actor-Critic 損失
ハイブリッドの Actor-Critic モデルを使用しているため、選択される損失関数は、以下に示すように、トレーニング用のアクター損失とクリティック損失の合計です。
\[L = L_{actor} + L_{critic}\]
アクター損失
アクター損失は、クリティックを状態依存の基準としたポリシー勾配に基づき、単一サンプル(エピソード単位)の推定で計算されます。
\[L_{actor} = -\sum^{T}*{t=1} log\pi*{\theta}(a_{t} | s_{t})[G(s_{t}, a_{t}) - V^{\pi}*{\theta}(s*{t})]\]
上記は以下を意味します。
- \(T\): エピソードごとの時間ステップの数。エピソードごとにことなります。
- \(s_{t}\): 時間ステップ \(t\) における状態。
- \(a_{t}\): 状態 \(s\) の場合の時間ステップ \(t\) で選択されたアクション。
- \(\pi_{\theta}\): \(\theta\) でパラメータ化されたポリシー(アクター)。
- \(V^{\pi}_{\theta}\): \(\theta\) でパラメータ化された価値関数(クリティック)。
- \(G = G_{t}\): 時間ステップ \(t\) において特定の状態とアクションに対して期待される戻り値。
組み合わせの損失を最小限に抑えることでアクションがより高い報酬を生み出す確率を最大化しようとしているため、合計に負の項が追加されます。
アドバンテージ
\(L_{actor}\) 式の \(G - V\) の項はアドバンテージと呼ばれ、特定の状態において、あるアクションが、その状態のポリシー \(\pi\) に従って選択されたランダムアクションと比べてどれくらい優れているかを示します。
ベースラインを除外することは可能ですが、除外した場合、トレーニング中のバリアンスが高くなってしまう可能性があります。また、ベースラインとしてクリティック \(V\) を選択すると、できる限り \(G\) に近くなるようにトレーニングされるため、バリアンスがより低くなります。
さらに、クリティックがなければ、アルゴリズムは特定の状態で実行されるアクションの確率を期待される戻り値に応じて高めようとするため、アクション間の相対的な確率が同じままである場合、結果はあまり変わりません。
たとえば、特定の状態における 2 つのアクションが同じ期待される戻り値を生成したとします。クリティックがなければ、アルゴリズムは客観的な \(J\) に基づき、これらのアクションの確率をあげようとします。クリティックがあれば、アドバンテージがなく(\(G - V = 0\))、そのためアクションの確率を上げることにアドバンテージがなく、アルゴリズムは勾配をゼロに設定します。
The Critic loss
Training \(V\) to be as close possible to \(G\) can be set up as a regression problem with the following loss function:
\[L_{critic} = L_{\delta}(G, V^{\pi}_{\theta})\]
上記の \(L_{\delta}\) は Huber 損失でこれは、二乗誤差損失よりもデータの外れ値に対する感度が低くなります。
huber_loss = tf.keras.losses.Huber(reduction=tf.keras.losses.Reduction.SUM)
def compute_loss(
action_probs: tf.Tensor,
values: tf.Tensor,
returns: tf.Tensor) -> tf.Tensor:
"""Computes the combined Actor-Critic loss."""
advantage = returns - values
action_log_probs = tf.math.log(action_probs)
actor_loss = -tf.math.reduce_sum(action_log_probs * advantage)
critic_loss = huber_loss(values, returns)
return actor_loss + critic_loss
4. パラメータを更新するようにトレーニングステップを定義する
上記のすべてのステップは、エピソードごとに実行されるトレーニングステップに結合されます。損失関数に導くすべてのステップは、自動微分を可能にする tf.GradientTape コンテキストで実行されます。
このチュートリアルでは、Adam オプティマイザを使って勾配をモデルパラメーターに適用します。
ディスカウントされていない報酬の合計 episode_reward も、このステップで計算されます。この値は、成功基準が満たされるかどうかを評価するために、後で使用されます。
tf.function コンテキストは train_step 関数に適用することで、コーラブル TenSorFlow グラフにコンパイルできるようなります。そうすることで、トレーニングを 10 倍加速させることができます。
optimizer = tf.keras.optimizers.Adam(learning_rate=0.01)
@tf.function
def train_step(
initial_state: tf.Tensor,
model: tf.keras.Model,
optimizer: tf.keras.optimizers.Optimizer,
gamma: float,
max_steps_per_episode: int) -> tf.Tensor:
"""Runs a model training step."""
with tf.GradientTape() as tape:
# Run the model for one episode to collect training data
action_probs, values, rewards = run_episode(
initial_state, model, max_steps_per_episode)
# Calculate the expected returns
returns = get_expected_return(rewards, gamma)
# Convert training data to appropriate TF tensor shapes
action_probs, values, returns = [
tf.expand_dims(x, 1) for x in [action_probs, values, returns]]
# Calculate the loss values to update our network
loss = compute_loss(action_probs, values, returns)
# Compute the gradients from the loss
grads = tape.gradient(loss, model.trainable_variables)
# Apply the gradients to the model's parameters
optimizer.apply_gradients(zip(grads, model.trainable_variables))
episode_reward = tf.math.reduce_sum(rewards)
return episode_reward
5. トレーニングツールを実行する
トレーニングは、成功基準またはエピソードの最大数に達するまでトレーニングステップを実行することで、実行されます。
エピソード報酬の実行中の記録はキューに保持されます。100 トライアルに達したら、キューの左終端(テール)から最も古い報酬が削除され、キューの右(ヘッド)に最も新しい報酬が追加されます。実行中の報酬の合計も、計算の効率を得るために管理されます。
ランタイムによっては、トレーニングを 1 分未満で完了することもできます。
%%time
min_episodes_criterion = 100
max_episodes = 10000
max_steps_per_episode = 500
# `CartPole-v1` is considered solved if average reward is >= 475 over 500
# consecutive trials
reward_threshold = 475
running_reward = 0
# The discount factor for future rewards
gamma = 0.99
# Keep the last episodes reward
episodes_reward: collections.deque = collections.deque(maxlen=min_episodes_criterion)
t = tqdm.trange(max_episodes)
for i in t:
initial_state, info = env.reset()
initial_state = tf.constant(initial_state, dtype=tf.float32)
episode_reward = int(train_step(
initial_state, model, optimizer, gamma, max_steps_per_episode))
episodes_reward.append(episode_reward)
running_reward = statistics.mean(episodes_reward)
t.set_postfix(
episode_reward=episode_reward, running_reward=running_reward)
# Show the average episode reward every 10 episodes
if i % 10 == 0:
pass # print(f'Episode {i}: average reward: {avg_reward}')
if running_reward > reward_threshold and i >= min_episodes_criterion:
break
print(f'\nSolved at episode {i}: average reward: {running_reward:.2f}!')
0%| | 0/10000 [00:00<?, ?it/s]/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/gym/utils/passive_env_checker.py:233: DeprecationWarning: `np.bool8` is a deprecated alias for `np.bool_`. (Deprecated NumPy 1.24) if not isinstance(terminated, (bool, np.bool8)): WARNING: All log messages before absl::InitializeLog() is called are written to STDERR I0000 00:00:1705004711.393610 544566 device_compiler.h:186] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process. 4%|▎ | 367/10000 [01:30<39:29, 4.07it/s, episode_reward=500, running_reward=476] Solved at episode 367: average reward: 476.04! CPU times: user 3min 8s, sys: 32 s, total: 3min 40s Wall time: 1min 30s
可視化
トレーニングが終わったら、モデルが環境でどのように実行するかを可視化すると良いでしょう。以下のセルを実行すると、モデルの 1 エピソードの実行を視覚化する GIF アニメーションを生成することができます。Colab で環境の画像を正しくレンダリングするには、Gym の追加パッケージをインストールする必要があることに注意してください。
# Render an episode and save as a GIF file
from IPython import display as ipythondisplay
from PIL import Image
render_env = gym.make("CartPole-v1", render_mode='rgb_array')
def render_episode(env: gym.Env, model: tf.keras.Model, max_steps: int):
state, info = env.reset()
state = tf.constant(state, dtype=tf.float32)
screen = env.render()
images = [Image.fromarray(screen)]
for i in range(1, max_steps + 1):
state = tf.expand_dims(state, 0)
action_probs, _ = model(state)
action = np.argmax(np.squeeze(action_probs))
state, reward, done, truncated, info = env.step(action)
state = tf.constant(state, dtype=tf.float32)
# Render screen every 10 steps
if i % 10 == 0:
screen = env.render()
images.append(Image.fromarray(screen))
if done:
break
return images
# Save GIF image
images = render_episode(render_env, model, max_steps_per_episode)
image_file = 'cartpole-v1.gif'
# loop=0: loop forever, duration=1: play each frame for 1ms
images[0].save(
image_file, save_all=True, append_images=images[1:], loop=0, duration=1)
import tensorflow_docs.vis.embed as embed
embed.embed_file(image_file)
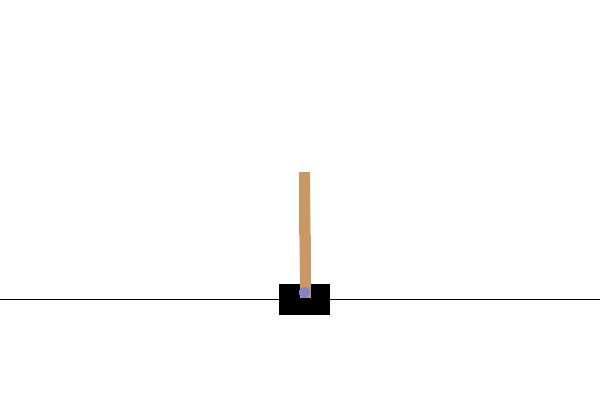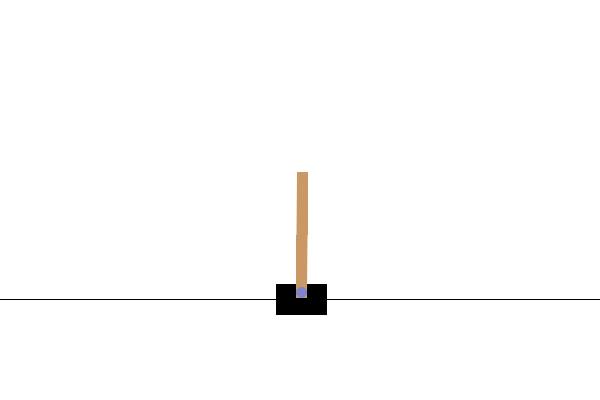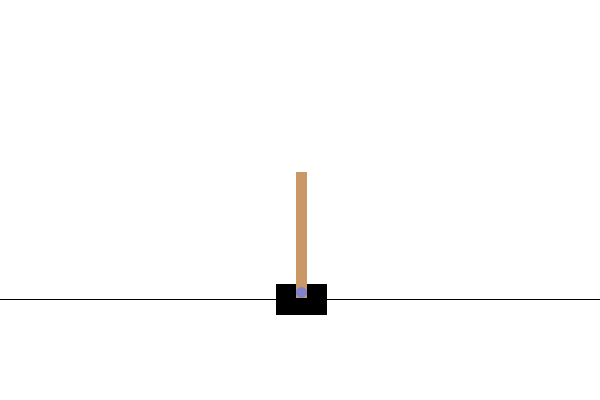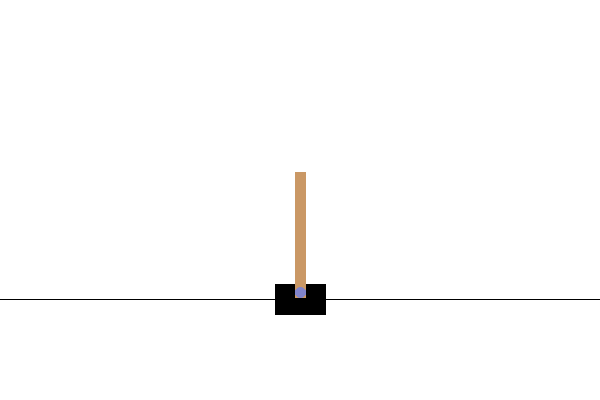
次のステップ
このチュートリアルでは、TensorFlow を使って Actor-Critic 法を実装する方法を説明しました。
次のステップでは、Gym の別の環境でモデルをトレーニングしてみるとよいでしょう。
Actor-Critic 法と Cartpole-v0 問題に関するその他の詳細については、以下のリソースをご覧ください。
TenSorFlow における強化学習のその他の例については、次のリソースをご覧ください。