
| | |  Kaynağı GitHub'da görüntüleyin Kaynağı GitHub'da görüntüleyin | |
Otomatik Farklılaşma ve Gradyanlar
Otomatik farklılaşma , sinir ağlarını eğitmek için geri yayılım gibi makine öğrenimi algoritmalarını uygulamak için kullanışlıdır.
Bu kılavuzda, özellikle istekli yürütmede TensorFlow ile gradyanları hesaplamanın yollarını keşfedeceksiniz.
Kurmak
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
gradyanları hesaplama
Otomatik olarak farklılaşmak için TensorFlow'un ileri geçiş sırasında hangi işlemlerin hangi sırayla gerçekleştiğini hatırlaması gerekir. Ardından, geriye doğru geçiş sırasında TensorFlow, gradyanları hesaplamak için bu işlem listesini ters sırayla geçer.
Gradyan bantları
TensorFlow, otomatik farklılaştırma için tf.GradientTape API'sini sağlar; yani, bazı girdilere göre bir hesaplamanın gradyanını hesaplamak, genellikle tf.Variable s. TensorFlow, bir tf.GradientTape bağlamında yürütülen ilgili işlemleri bir "teyp" üzerine "kaydeder". TensorFlow daha sonra bu bandı, ters mod farklılaşmasını kullanarak "kaydedilmiş" bir hesaplamanın gradyanlarını hesaplamak için kullanır.
İşte basit bir örnek:
x = tf.Variable(3.0)
with tf.GradientTape() as tape:
y = x**2
Bazı işlemleri kaydettikten sonra, bazı kaynaklara (genellikle modelin değişkenlerine) göre bazı hedeflerin (genellikle bir kayıp) gradyanını hesaplamak için GradientTape.gradient(target, sources) kullanın:
# dy = 2x * dx
dy_dx = tape.gradient(y, x)
dy_dx.numpy()
6.0
Yukarıdaki örnekte skaler kullanılır, ancak tf.GradientTape herhangi bir tensörde olduğu kadar kolay çalışır:
w = tf.Variable(tf.random.normal((3, 2)), name='w')
b = tf.Variable(tf.zeros(2, dtype=tf.float32), name='b')
x = [[1., 2., 3.]]
with tf.GradientTape(persistent=True) as tape:
y = x @ w + b
loss = tf.reduce_mean(y**2)
Her iki değişkene göre loss gradyanını elde etmek için, her ikisini de gradient yöntemine kaynak olarak iletebilirsiniz. Bant, kaynakların nasıl iletildiği konusunda esnektir ve iç içe geçmiş herhangi bir liste veya sözlük kombinasyonunu kabul eder ve aynı şekilde yapılandırılmış degradeyi döndürür (bkz. tf.nest ).
[dl_dw, dl_db] = tape.gradient(loss, [w, b])
Her kaynağa göre gradyan, kaynağın şekline sahiptir:
print(w.shape)
print(dl_dw.shape)
(3, 2) (3, 2)
İşte yine gradyan hesaplaması, bu sefer bir değişkenler sözlüğünü geçerek:
my_vars = {
'w': w,
'b': b
}
grad = tape.gradient(loss, my_vars)
grad['b']
<tf.Tensor: shape=(2,), dtype=float32, numpy=array([-1.6920902, -3.2363236], dtype=float32)>
Bir modele göre gradyanlar
Kontrol noktası ve dışa aktarma için tf.Variables bir tf.Module veya alt sınıflarından ( layers.Layer , keras.Model ) birinde toplamak yaygındır.
Çoğu durumda, bir modelin eğitilebilir değişkenlerine göre gradyanları hesaplamak isteyeceksiniz. tf.Module tüm alt sınıfları, değişkenlerini Module.trainable_variables özelliğinde topladığı için, bu degradeleri birkaç kod satırında hesaplayabilirsiniz:
layer = tf.keras.layers.Dense(2, activation='relu')
x = tf.constant([[1., 2., 3.]])
with tf.GradientTape() as tape:
# Forward pass
y = layer(x)
loss = tf.reduce_mean(y**2)
# Calculate gradients with respect to every trainable variable
grad = tape.gradient(loss, layer.trainable_variables)
for var, g in zip(layer.trainable_variables, grad):
print(f'{var.name}, shape: {g.shape}')
dense/kernel:0, shape: (3, 2) dense/bias:0, shape: (2,)
Kasetin ne izlediğini kontrol etme
Varsayılan davranış, eğitilebilir bir tf.Variable sonra tüm işlemleri kaydetmektir. Bunun nedenleri:
- Teybin, geri geçişteki gradyanları hesaplamak için ileri geçişte hangi işlemlerin kaydedileceğini bilmesi gerekir.
- Bant ara çıkışlara referanslar içerir, böylece gereksiz işlemleri kaydetmek istemezsiniz.
- En yaygın kullanım durumu, bir modelin tüm eğitilebilir değişkenlerine göre bir kaybın gradyanını hesaplamayı içerir.
Örneğin, tf.Tensor varsayılan olarak "izlenmediği" ve tf.Variable eğitilebilir olmadığı için aşağıdakiler bir degradeyi hesaplayamaz:
# A trainable variable
x0 = tf.Variable(3.0, name='x0')
# Not trainable
x1 = tf.Variable(3.0, name='x1', trainable=False)
# Not a Variable: A variable + tensor returns a tensor.
x2 = tf.Variable(2.0, name='x2') + 1.0
# Not a variable
x3 = tf.constant(3.0, name='x3')
with tf.GradientTape() as tape:
y = (x0**2) + (x1**2) + (x2**2)
grad = tape.gradient(y, [x0, x1, x2, x3])
for g in grad:
print(g)
tf.Tensor(6.0, shape=(), dtype=float32) None None None
GradientTape.watched_variables yöntemini kullanarak bant tarafından izlenen değişkenleri listeleyebilirsiniz:
[var.name for var in tape.watched_variables()]
['x0:0']
tf.GradientTape , kullanıcıya neyin izlenip izlenmediği üzerinde kontrol sağlayan kancalar sağlar.
Bir tf.Tensor ile ilgili olarak degradeleri kaydetmek için GradientTape.watch(x) öğesini çağırmanız gerekir:
x = tf.constant(3.0)
with tf.GradientTape() as tape:
tape.watch(x)
y = x**2
# dy = 2x * dx
dy_dx = tape.gradient(y, x)
print(dy_dx.numpy())
6.0
Bunun tersine, tüm tf.Variables izleme varsayılan davranışını devre dışı bırakmak için degrade bandı oluştururken watch_accessed_variables=False olarak ayarlayın. Bu hesaplama iki değişken kullanır, ancak yalnızca değişkenlerden birinin gradyanı bağlar:
x0 = tf.Variable(0.0)
x1 = tf.Variable(10.0)
with tf.GradientTape(watch_accessed_variables=False) as tape:
tape.watch(x1)
y0 = tf.math.sin(x0)
y1 = tf.nn.softplus(x1)
y = y0 + y1
ys = tf.reduce_sum(y)
GradientTape.watch x0 üzerinde çağrılmadığı için, buna göre hiçbir gradyan hesaplanmaz:
# dys/dx1 = exp(x1) / (1 + exp(x1)) = sigmoid(x1)
grad = tape.gradient(ys, {'x0': x0, 'x1': x1})
print('dy/dx0:', grad['x0'])
print('dy/dx1:', grad['x1'].numpy())
dy/dx0: None dy/dx1: 0.9999546
ara sonuçlar
Ayrıca, tf.GradientTape bağlamında hesaplanan ara değerlere göre çıktının gradyanlarını da talep edebilirsiniz.
x = tf.constant(3.0)
with tf.GradientTape() as tape:
tape.watch(x)
y = x * x
z = y * y
# Use the tape to compute the gradient of z with respect to the
# intermediate value y.
# dz_dy = 2 * y and y = x ** 2 = 9
print(tape.gradient(z, y).numpy())
18.0
Varsayılan olarak, bir GradientTape tarafından tutulan kaynaklar, GradientTape.gradient yöntemi çağrılır çağrılmaz serbest bırakılır. Aynı hesaplama üzerinden birden çok degradeyi hesaplamak için, persistent=True ile bir degrade bant oluşturun. Bu, teyp nesnesi çöp toplandığında kaynaklar serbest bırakıldığından, gradient yöntemine birden çok çağrı yapılmasına izin verir. Örneğin:
x = tf.constant([1, 3.0])
with tf.GradientTape(persistent=True) as tape:
tape.watch(x)
y = x * x
z = y * y
print(tape.gradient(z, x).numpy()) # [4.0, 108.0] (4 * x**3 at x = [1.0, 3.0])
print(tape.gradient(y, x).numpy()) # [2.0, 6.0] (2 * x at x = [1.0, 3.0])
[ 4. 108.] [2. 6.]-yer tutucu26 l10n-yer
del tape # Drop the reference to the tape
performansla ilgili notlar
Bir gradyan teyp bağlamında işlem yapmakla ilişkili küçük bir ek yük vardır. Çoğu hevesli uygulama için bu fark edilebilir bir maliyet olmayacaktır, ancak yine de yalnızca gerekli olduğu alanlarda bant bağlamını kullanmalısınız.
Degrade bantlar, geri geçiş sırasında kullanılmak üzere girişler ve çıkışlar dahil olmak üzere ara sonuçları depolamak için belleği kullanır.
Verimlilik için, bazı operasyonların (
ReLUgibi) ara sonuçlarını tutması gerekmez ve ileri geçiş sırasında budanırlar. Ancak,persistent=Truekullanırsanız, hiçbir şey atılmaz ve en yüksek bellek kullanımınız daha yüksek olur.
Skaler olmayan hedeflerin gradyanları
Gradyan temelde bir skaler üzerinde bir işlemdir.
x = tf.Variable(2.0)
with tf.GradientTape(persistent=True) as tape:
y0 = x**2
y1 = 1 / x
print(tape.gradient(y0, x).numpy())
print(tape.gradient(y1, x).numpy())
4.0 -0.25
Bu nedenle, birden fazla hedefin derecesini sorarsanız, her bir kaynak için sonuç şöyle olur:
- Hedeflerin toplamının gradyanı veya eşdeğeri
- Her hedefin gradyanlarının toplamı.
x = tf.Variable(2.0)
with tf.GradientTape() as tape:
y0 = x**2
y1 = 1 / x
print(tape.gradient({'y0': y0, 'y1': y1}, x).numpy())
3.75
Benzer şekilde, hedef(ler) skaler değilse toplamın gradyanı hesaplanır:
x = tf.Variable(2.)
with tf.GradientTape() as tape:
y = x * [3., 4.]
print(tape.gradient(y, x).numpy())
7.0
Bu, kayıpların toplamının gradyanını veya eleman bazında kayıp hesaplamasının toplamının gradyanını almayı kolaylaştırır.
Her öğe için ayrı bir degradeye ihtiyacınız varsa, Jacobian'a bakın.
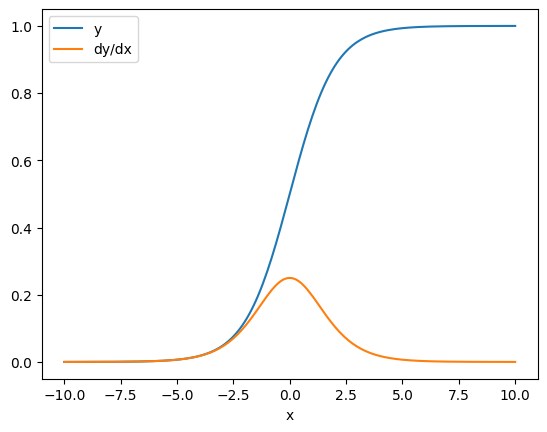
Bazı durumlarda Jacobian'ı atlayabilirsiniz. Eleman bazında bir hesaplama için, toplamın gradyanı, her eleman bağımsız olduğundan, her elemanın girdi elemanına göre türevini verir:
x = tf.linspace(-10.0, 10.0, 200+1)
with tf.GradientTape() as tape:
tape.watch(x)
y = tf.nn.sigmoid(x)
dy_dx = tape.gradient(y, x)
plt.plot(x, y, label='y')
plt.plot(x, dy_dx, label='dy/dx')
plt.legend()
_ = plt.xlabel('x')
Kontrol akışı
Degrade bant, işlemleri yürütüldükçe kaydettiği için, Python denetim akışı doğal olarak işlenir (örneğin, if ve while ifadeleri).
Burada if öğesinin her dalında farklı bir değişken kullanılır. Degrade yalnızca kullanılan değişkene bağlanır:
x = tf.constant(1.0)
v0 = tf.Variable(2.0)
v1 = tf.Variable(2.0)
with tf.GradientTape(persistent=True) as tape:
tape.watch(x)
if x > 0.0:
result = v0
else:
result = v1**2
dv0, dv1 = tape.gradient(result, [v0, v1])
print(dv0)
print(dv1)
tf.Tensor(1.0, shape=(), dtype=float32) None
Sadece kontrol ifadelerinin kendilerinin türevlenebilir olmadığını unutmayın, bu nedenle degrade tabanlı optimize ediciler tarafından görünmezler.
Yukarıdaki örnekteki x değerine bağlı olarak, bant ya result = v0 ya da result = v1**2 kaydeder. x göre gradyan her zaman None .
dx = tape.gradient(result, x)
print(dx)
None
None gradyanı alma
Bir hedef bir kaynağa bağlı olmadığında, None şeklinde bir gradyan alırsınız.
x = tf.Variable(2.)
y = tf.Variable(3.)
with tf.GradientTape() as tape:
z = y * y
print(tape.gradient(z, x))
None
Burada z açıkça x ile bağlantılı değildir, ancak bir degradenin bağlantısını kesmenin daha az belirgin olan birkaç yolu vardır.
1. Bir değişkeni bir tensörle değiştirdi
"Teybin ne izlediğini kontrol etme" bölümünde, kasetin otomatik olarak bir tf.Variable izleyeceğini, ancak bir tf.Tensor .
Yaygın bir hata, tf.Variable öğesini güncellemek için Variable.assign kullanmak yerine yanlışlıkla bir tf.Tensor öğesini bir tf.Variable ile değiştirmektir. İşte bir örnek:
x = tf.Variable(2.0)
for epoch in range(2):
with tf.GradientTape() as tape:
y = x+1
print(type(x).__name__, ":", tape.gradient(y, x))
x = x + 1 # This should be `x.assign_add(1)`
ResourceVariable : tf.Tensor(1.0, shape=(), dtype=float32) EagerTensor : None
2. TensorFlow dışında hesaplamalar yaptı
Hesaplama TensorFlow'dan çıkarsa bant gradyan yolunu kaydedemez. Örneğin:
x = tf.Variable([[1.0, 2.0],
[3.0, 4.0]], dtype=tf.float32)
with tf.GradientTape() as tape:
x2 = x**2
# This step is calculated with NumPy
y = np.mean(x2, axis=0)
# Like most ops, reduce_mean will cast the NumPy array to a constant tensor
# using `tf.convert_to_tensor`.
y = tf.reduce_mean(y, axis=0)
print(tape.gradient(y, x))
None
3. Degradeleri bir tamsayı veya dize yoluyla aldı
Tamsayılar ve dizeler türevlenebilir değildir. Bir hesaplama yolu bu veri türlerini kullanırsa gradyan olmaz.
Hiç kimse dizelerin türevlenebilir olmasını beklemez, ancak dtype belirtmezseniz yanlışlıkla bir int sabiti veya değişkeni oluşturmak kolaydır.
x = tf.constant(10)
with tf.GradientTape() as g:
g.watch(x)
y = x * x
print(g.gradient(y, x))
WARNING:tensorflow:The dtype of the watched tensor must be floating (e.g. tf.float32), got tf.int32 WARNING:tensorflow:The dtype of the target tensor must be floating (e.g. tf.float32) when calling GradientTape.gradient, got tf.int32 WARNING:tensorflow:The dtype of the source tensor must be floating (e.g. tf.float32) when calling GradientTape.gradient, got tf.int32 None
TensorFlow, türler arasında otomatik olarak yayın yapmaz, bu nedenle pratikte, eksik bir degrade yerine genellikle bir tür hatası alırsınız.
4. Durum bilgisi olan bir nesne aracılığıyla gradyanlar aldı
Devlet gradyanları durdurur. Durum bilgisi olan bir nesneden okuduğunuzda, bant, kendisine yol açan geçmişi değil, yalnızca mevcut durumu gözlemleyebilir.
Bir tf.Tensor değişmezdir. Bir tensörü oluşturulduktan sonra değiştiremezsiniz. Bir değeri var ama durumu yok. Şimdiye kadar tartışılan tüm işlemler de durumsuzdur: bir tf.matmul yalnızca girdilerine bağlıdır.
Bir tf.Variable dahili durumu, yani değeri vardır. Değişkeni kullandığınızda durum okunur. Bir değişkene göre bir gradyan hesaplamak normaldir, ancak değişkenin durumu gradyan hesaplamalarının daha geriye gitmesini engeller. Örneğin:
x0 = tf.Variable(3.0)
x1 = tf.Variable(0.0)
with tf.GradientTape() as tape:
# Update x1 = x1 + x0.
x1.assign_add(x0)
# The tape starts recording from x1.
y = x1**2 # y = (x1 + x0)**2
# This doesn't work.
print(tape.gradient(y, x0)) #dy/dx0 = 2*(x1 + x0)
None
Benzer şekilde, tf.data.Dataset yineleyicileri ve tf.queue s durum bilgisidir ve içlerinden geçen tensörlerdeki tüm gradyanları durdurur.
Gradyan kayıtlı değil
Bazı tf.Operation olarak kaydedilir ve None döndürür. Diğerlerinde kayıtlı bir eğim yoktur .
tf.raw_ops sayfası, hangi düşük seviyeli operasyonların gradyanların kayıtlı olduğunu gösterir.
Kaydedilmiş degradesi olmayan bir kayan noktalı işlem aracılığıyla bir degrade almaya çalışırsanız, bant sessizce None döndürmek yerine bir hata verir. Bu şekilde bir şeylerin yanlış gittiğini bilirsiniz.
Örneğin, tf.image.adjust_contrast işlevi, bir degradeye sahip olabilen ancak degrade uygulanmayan raw_ops.AdjustContrastv2 öğesini sarar:
image = tf.Variable([[[0.5, 0.0, 0.0]]])
delta = tf.Variable(0.1)
with tf.GradientTape() as tape:
new_image = tf.image.adjust_contrast(image, delta)
try:
print(tape.gradient(new_image, [image, delta]))
assert False # This should not happen.
except LookupError as e:
print(f'{type(e).__name__}: {e}')
LookupError: gradient registry has no entry for: AdjustContrastv2
Bu işlem aracılığıyla farklılaştırmanız gerekiyorsa, ya degradeyi uygulamanız ve kaydetmeniz ( tf.RegisterGradient kullanarak) veya diğer işlemleri kullanarak işlevi yeniden uygulamanız gerekir.
Yok yerine sıfırlar
Bazı durumlarda, bağlantısız gradyanlar için None yerine 0 almak uygun olacaktır. unconnected_gradients değişkenini kullanarak, bağlantısız gradyanlarınız olduğunda neyin döndürüleceğine karar verebilirsiniz:
x = tf.Variable([2., 2.])
y = tf.Variable(3.)
with tf.GradientTape() as tape:
z = y**2
print(tape.gradient(z, x, unconnected_gradients=tf.UnconnectedGradients.ZERO))
tf.Tensor([0. 0.], shape=(2,), dtype=float32)