
| | |  GitHub-এ উৎস দেখুন GitHub-এ উৎস দেখুন |
tf.data API আপনাকে সহজ, পুনরায় ব্যবহারযোগ্য টুকরা থেকে জটিল ইনপুট পাইপলাইন তৈরি করতে সক্ষম করে। উদাহরণস্বরূপ, একটি চিত্র মডেলের জন্য পাইপলাইন একটি বিতরণ করা ফাইল সিস্টেমের ফাইলগুলি থেকে ডেটা একত্রিত করতে পারে, প্রতিটি ছবিতে এলোমেলোভাবে বিভ্রান্তি প্রয়োগ করতে পারে এবং প্রশিক্ষণের জন্য এলোমেলোভাবে নির্বাচিত চিত্রগুলিকে একত্রিত করতে পারে। একটি টেক্সট মডেলের জন্য পাইপলাইনে কাঁচা পাঠ্য ডেটা থেকে চিহ্নগুলি বের করা, একটি লুকআপ টেবিলের সাহায্যে এম্বেডিং শনাক্তকারীতে রূপান্তর করা এবং বিভিন্ন দৈর্ঘ্যের ক্রমগুলি একসাথে ব্যাচ করা জড়িত থাকতে পারে। tf.data API এটিকে প্রচুর পরিমাণে ডেটা পরিচালনা করা, বিভিন্ন ডেটা ফরম্যাট থেকে পড়া এবং জটিল রূপান্তর সম্পাদন করা সম্ভব করে তোলে।
tf.data API একটি tf.data.Dataset বিমূর্ততা প্রবর্তন করে যা উপাদানগুলির একটি ক্রম প্রতিনিধিত্ব করে, যার প্রতিটি উপাদান এক বা একাধিক উপাদান নিয়ে গঠিত। উদাহরণস্বরূপ, একটি চিত্র পাইপলাইনে, একটি উপাদান একটি একক প্রশিক্ষণের উদাহরণ হতে পারে, যেখানে চিত্র এবং এর লেবেলের প্রতিনিধিত্ব করে এক জোড়া টেনসর উপাদান।
একটি ডেটাসেট তৈরি করার দুটি স্বতন্ত্র উপায় রয়েছে:
একটি ডেটা উত্স মেমরিতে বা এক বা একাধিক ফাইলে সংরক্ষিত ডেটা থেকে একটি
Datasetতৈরি করে।একটি ডেটা ট্রান্সফরমেশন এক বা একাধিক
tf.data.Datasetঅবজেক্ট থেকে একটি ডেটাসেট তৈরি করে।
import tensorflow as tf
import pathlib
import os
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
np.set_printoptions(precision=4)
বেসিক মেকানিক্স
একটি ইনপুট পাইপলাইন তৈরি করতে, আপনাকে অবশ্যই একটি ডেটা উত্স দিয়ে শুরু করতে হবে৷ উদাহরণস্বরূপ, মেমরির ডেটা থেকে একটি Dataset তৈরি করতে, আপনি tf.data.Dataset.from_tensors() বা tf.data.Dataset.from_tensor_slices() ) ব্যবহার করতে পারেন। বিকল্পভাবে, যদি আপনার ইনপুট ডেটা প্রস্তাবিত TFRecord বিন্যাসে একটি ফাইলে সংরক্ষণ করা হয়, আপনি tf.data.TFRecordDataset() ব্যবহার করতে পারেন।
একবার আপনার কাছে Dataset অবজেক্ট হয়ে গেলে, আপনি Dataset অবজেক্টে চেইনিং পদ্ধতির মাধ্যমে এটিকে একটি নতুন tf.data.Dataset রূপান্তর করতে পারেন। উদাহরণস্বরূপ, আপনি প্রতি-উপাদানের রূপান্তর যেমন Dataset.map() , এবং বহু-উপাদান রূপান্তর যেমন Dataset.batch() প্রয়োগ করতে পারেন। রূপান্তরের সম্পূর্ণ তালিকার জন্য tf.data.Dataset এর ডকুমেন্টেশন দেখুন।
Dataset অবজেক্টটি একটি পাইথন পুনরাবৃত্তিযোগ্য। এটি একটি লুপ ব্যবহার করে এর উপাদানগুলিকে গ্রাস করা সম্ভব করে তোলে:
dataset = tf.data.Dataset.from_tensor_slices([8, 3, 0, 8, 2, 1])
dataset
<TensorSliceDataset element_spec=TensorSpec(shape=(), dtype=tf.int32, name=None)>
for elem in dataset:
print(elem.numpy())
8 3 0 8 2 1
অথবা স্পষ্টভাবে iter ব্যবহার করে একটি Python iterator তৈরি করে এবং next ব্যবহার করে এর উপাদানগুলি ব্যবহার করে:
it = iter(dataset)
print(next(it).numpy())
8
বিকল্পভাবে, ডেটাসেট উপাদানগুলি reduce রূপান্তর ব্যবহার করে ব্যবহার করা যেতে পারে, যা একটি একক ফলাফল তৈরি করতে সমস্ত উপাদানকে হ্রাস করে। নিম্নোক্ত উদাহরণটি ব্যাখ্যা করে কিভাবে পূর্ণসংখ্যার একটি ডেটাসেটের যোগফল গণনা করতে reduce রূপান্তর ব্যবহার করতে হয়।
print(dataset.reduce(0, lambda state, value: state + value).numpy())
22
ডেটাসেট গঠন
একটি ডেটাসেট উপাদানগুলির একটি ক্রম তৈরি করে, যেখানে প্রতিটি উপাদান একই (নেস্টেড) উপাদানগুলির গঠন। কাঠামোর স্বতন্ত্র উপাদানগুলি tf.TypeSpec দ্বারা প্রতিনিধিত্বযোগ্য যে কোনো ধরনের হতে পারে, যার মধ্যে tf.Tensor , tf.sparse.SparseTensor , tf.RaggedTensor , tf.TensorArray , বা tf.data.Dataset ।
পাইথন গঠন যা উপাদানগুলির (নেস্টেড) গঠন প্রকাশ করতে ব্যবহার করা যেতে পারে তার মধ্যে রয়েছে tuple , dict , NamedTuple , এবং OrderedDict । বিশেষ করে, list ডেটাসেট উপাদানগুলির গঠন প্রকাশের জন্য একটি বৈধ গঠন নয়। এর কারণ হল প্রথম দিকের tf.data ব্যবহারকারীরা list ইনপুটগুলি (যেমন tf.data.Dataset.from_tensors পাস করা হয়েছে) স্বয়ংক্রিয়ভাবে টেনসর হিসাবে প্যাক করা এবং list আউটপুটগুলি (যেমন ব্যবহারকারী-সংজ্ঞায়িত ফাংশনের রিটার্ন মান) একটি tuple জোর করে নিয়ে যাওয়া সম্পর্কে দৃঢ়ভাবে অনুভব করেছিল। ফলস্বরূপ, আপনি যদি চান একটি list ইনপুটকে একটি কাঠামো হিসাবে বিবেচনা করা হোক, আপনাকে এটিকে tuple রূপান্তর করতে হবে এবং যদি আপনি একটি list আউটপুটকে একটি একক উপাদান হতে চান, তাহলে আপনাকে tf.stack ব্যবহার করে স্পষ্টভাবে প্যাক করতে হবে। .
Dataset.element_spec বৈশিষ্ট্য আপনাকে প্রতিটি উপাদান উপাদানের ধরন পরিদর্শন করতে দেয়। প্রপার্টিটি tf.TypeSpec অবজেক্টের একটি নেস্টেড স্ট্রাকচার প্রদান করে, যা এলিমেন্টের স্ট্রাকচারের সাথে মিলে যায়, যেটি হতে পারে একটি একক কম্পোনেন্ট, কম্পোনেন্টের টুপল বা কম্পোনেন্টের একটি নেস্টেড টুপল। উদাহরণ স্বরূপ:
dataset1 = tf.data.Dataset.from_tensor_slices(tf.random.uniform([4, 10]))
dataset1.element_spec
TensorSpec(shape=(10,), dtype=tf.float32, name=None)
dataset2 = tf.data.Dataset.from_tensor_slices(
(tf.random.uniform([4]),
tf.random.uniform([4, 100], maxval=100, dtype=tf.int32)))
dataset2.element_spec
(TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None))
dataset3 = tf.data.Dataset.zip((dataset1, dataset2))
dataset3.element_spec
(TensorSpec(shape=(10,), dtype=tf.float32, name=None), (TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None)))l10n
SparseTensorSpec(TensorShape([3, 4]), tf.int32)
# Dataset containing a sparse tensor.
dataset4 = tf.data.Dataset.from_tensors(tf.SparseTensor(indices=[[0, 0], [1, 2]], values=[1, 2], dense_shape=[3, 4]))
dataset4.element_spec
# Use value_type to see the type of value represented by the element spec
dataset4.element_spec.value_type
tensorflow.python.framework.sparse_tensor.SparseTensor
Dataset রূপান্তরগুলি যে কোনও কাঠামোর ডেটাসেটকে সমর্থন করে। Dataset.map() , এবং Dataset.filter() রূপান্তর ব্যবহার করার সময়, যা প্রতিটি উপাদানের জন্য একটি ফাংশন প্রয়োগ করে, উপাদান গঠন ফাংশনের আর্গুমেন্ট নির্ধারণ করে:
dataset1 = tf.data.Dataset.from_tensor_slices(
tf.random.uniform([4, 10], minval=1, maxval=10, dtype=tf.int32))
dataset1
<TensorSliceDataset element_spec=TensorSpec(shape=(10,), dtype=tf.int32, name=None)>
for z in dataset1:
print(z.numpy())
[3 3 7 5 9 8 4 2 3 7] [8 9 6 7 5 6 1 6 2 3] [9 8 4 4 8 7 1 5 6 7] [5 9 5 4 2 5 7 8 8 8]
dataset2 = tf.data.Dataset.from_tensor_slices(
(tf.random.uniform([4]),
tf.random.uniform([4, 100], maxval=100, dtype=tf.int32)))
dataset2
<TensorSliceDataset element_spec=(TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None))>
dataset3 = tf.data.Dataset.zip((dataset1, dataset2))
dataset3
<ZipDataset element_spec=(TensorSpec(shape=(10,), dtype=tf.int32, name=None), (TensorSpec(shape=(), dtype=tf.float32, name=None), TensorSpec(shape=(100,), dtype=tf.int32, name=None)))>
for a, (b,c) in dataset3:
print('shapes: {a.shape}, {b.shape}, {c.shape}'.format(a=a, b=b, c=c))
shapes: (10,), (), (100,) shapes: (10,), (), (100,) shapes: (10,), (), (100,) shapes: (10,), (), (100,)
ইনপুট ডেটা পড়া
NumPy অ্যারে ব্যবহার করছে
আরও উদাহরণের জন্য NumPy অ্যারে লোড হচ্ছে দেখুন।
যদি আপনার সমস্ত ইনপুট ডেটা মেমরিতে ফিট হয়ে যায়, তাহলে তাদের থেকে একটি Dataset তৈরি করার সহজ উপায় হল সেগুলিকে tf.Tensor অবজেক্টে রূপান্তর করা এবং Dataset.from_tensor_slices() ব্যবহার করা।
train, test = tf.keras.datasets.fashion_mnist.load_data()
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 32768/29515 [=================================] - 0s 0us/step 40960/29515 [=========================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26427392/26421880 [==============================] - 0s 0us/step 26435584/26421880 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 16384/5148 [===============================================================================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4423680/4422102 [==============================] - 0s 0us/step 4431872/4422102 [==============================] - 0s 0us/step
images, labels = train
images = images/255
dataset = tf.data.Dataset.from_tensor_slices((images, labels))
dataset
<TensorSliceDataset element_spec=(TensorSpec(shape=(28, 28), dtype=tf.float64, name=None), TensorSpec(shape=(), dtype=tf.uint8, name=None))>
পাইথন জেনারেটর ব্যবহার করছে
আরেকটি সাধারণ ডেটা উৎস যা সহজে একটি tf.data.Dataset হিসাবে গ্রহণ করা যেতে পারে তা হল পাইথন জেনারেটর।
def count(stop):
i = 0
while i<stop:
yield i
i += 1
for n in count(5):
print(n)
0 1 2 3 4
Dataset.from_generator কনস্ট্রাক্টর পাইথন জেনারেটরকে সম্পূর্ণ কার্যকরী tf.data.Dataset এ রূপান্তর করে।
কনস্ট্রাক্টর একটি কলযোগ্য ইনপুট হিসাবে নেয়, একটি পুনরাবৃত্তিকারী নয়। এটি জেনারেটর শেষ হয়ে গেলে এটি পুনরায় চালু করার অনুমতি দেয়। এটি একটি ঐচ্ছিক আর্গুমেন্ট নেয়, যা args আর্গুমেন্ট হিসাবে পাস করা হয়।
output_types আর্গুমেন্ট প্রয়োজন কারণ tf.data অভ্যন্তরীণভাবে একটি tf.Graph . গ্রাফ তৈরি করে, এবং গ্রাফ প্রান্তগুলির জন্য একটি tf.dtype প্রয়োজন।
ds_counter = tf.data.Dataset.from_generator(count, args=[25], output_types=tf.int32, output_shapes = (), )
for count_batch in ds_counter.repeat().batch(10).take(10):
print(count_batch.numpy())
[0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24 0 1 2 3 4] [ 5 6 7 8 9 10 11 12 13 14] [15 16 17 18 19 20 21 22 23 24] [0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24 0 1 2 3 4] [ 5 6 7 8 9 10 11 12 13 14] [15 16 17 18 19 20 21 22 23 24]
output_shapes আর্গুমেন্টের প্রয়োজন নেই কিন্তু অনেক TensorFlow অপারেশন একটি অজানা র্যাঙ্ক সহ টেনসর সমর্থন করে না বলে অত্যন্ত সুপারিশ করা হয়। একটি নির্দিষ্ট অক্ষের দৈর্ঘ্য অজানা বা পরিবর্তনশীল হলে, output_shapes এ None হিসেবে সেট করুন।
এটাও মনে রাখা গুরুত্বপূর্ণ যে output_shapes এবং output_types অন্যান্য ডেটাসেট পদ্ধতির মতো একই নেস্টিং নিয়ম অনুসরণ করে।
এখানে একটি উদাহরণ জেনারেটর যা উভয় দিক প্রদর্শন করে, এটি অ্যারের টিপল প্রদান করে, যেখানে দ্বিতীয় অ্যারেটি অজানা দৈর্ঘ্য সহ একটি ভেক্টর।
def gen_series():
i = 0
while True:
size = np.random.randint(0, 10)
yield i, np.random.normal(size=(size,))
i += 1
for i, series in gen_series():
print(i, ":", str(series))
if i > 5:
break
0 : [0.3939] 1 : [ 0.9282 -0.0158 1.0096 0.7155 0.0491 0.6697 -0.2565 0.487 ] 2 : [-0.4831 0.37 -1.3918 -0.4786 0.7425 -0.3299] 3 : [ 0.1427 -1.0438 0.821 -0.8766 -0.8369 0.4168] 4 : [-1.4984 -1.8424 0.0337 0.0941 1.3286 -1.4938] 5 : [-1.3158 -1.2102 2.6887 -1.2809] 6 : []
প্রথম আউটপুট একটি int32 দ্বিতীয়টি একটি float32 ।
প্রথম আইটেমটি একটি স্কেলার, আকৃতি () , এবং দ্বিতীয়টি অজানা দৈর্ঘ্যের একটি ভেক্টর, আকৃতি (None,)
ds_series = tf.data.Dataset.from_generator(
gen_series,
output_types=(tf.int32, tf.float32),
output_shapes=((), (None,)))
ds_series
<FlatMapDataset element_spec=(TensorSpec(shape=(), dtype=tf.int32, name=None), TensorSpec(shape=(None,), dtype=tf.float32, name=None))>
এখন এটি নিয়মিত tf.data.Dataset মতো ব্যবহার করা যেতে পারে। মনে রাখবেন যে একটি পরিবর্তনশীল আকৃতি সহ একটি ডেটাসেট ব্যাচ করার সময়, আপনাকে Dataset.padded_batch ব্যবহার করতে হবে।
ds_series_batch = ds_series.shuffle(20).padded_batch(10)
ids, sequence_batch = next(iter(ds_series_batch))
print(ids.numpy())
print()
print(sequence_batch.numpy())
[ 8 10 18 1 5 19 22 17 21 25] [[-0.6098 0.1366 -2.15 -0.9329 0. 0. ] [ 1.0295 -0.033 -0.0388 0. 0. 0. ] [-0.1137 0.3552 0.4363 -0.2487 -1.1329 0. ] [ 0. 0. 0. 0. 0. 0. ] [-1.0466 0.624 -1.7705 1.4214 0.9143 -0.62 ] [-0.9502 1.7256 0.5895 0.7237 1.5397 0. ] [ 0.3747 1.2967 0. 0. 0. 0. ] [-0.4839 0.292 -0.7909 -0.7535 0.4591 -1.3952] [-0.0468 0.0039 -1.1185 -1.294 0. 0. ] [-0.1679 -0.3375 0. 0. 0. 0. ]]
আরো বাস্তবসম্মত উদাহরণের জন্য, preprocessing.image.ImageDataGenerator কে tf.data.Dataset হিসেবে মোড়ানোর চেষ্টা করুন।
প্রথমে ডেটা ডাউনলোড করুন:
flowers = tf.keras.utils.get_file(
'flower_photos',
'https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',
untar=True)
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz 228818944/228813984 [==============================] - 10s 0us/step 228827136/228813984 [==============================] - 10s 0us/step
ইমেজ তৈরি করুন। image.ImageDataGenerator
img_gen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255, rotation_range=20)
images, labels = next(img_gen.flow_from_directory(flowers))
Found 3670 images belonging to 5 classes.
print(images.dtype, images.shape)
print(labels.dtype, labels.shape)
float32 (32, 256, 256, 3) float32 (32, 5)
ds = tf.data.Dataset.from_generator(
lambda: img_gen.flow_from_directory(flowers),
output_types=(tf.float32, tf.float32),
output_shapes=([32,256,256,3], [32,5])
)
ds.element_spec
(TensorSpec(shape=(32, 256, 256, 3), dtype=tf.float32, name=None), TensorSpec(shape=(32, 5), dtype=tf.float32, name=None))
for images, label in ds.take(1):
print('images.shape: ', images.shape)
print('labels.shape: ', labels.shape)
Found 3670 images belonging to 5 classes. images.shape: (32, 256, 256, 3) labels.shape: (32, 5)
TFRecord ডেটা ব্যবহার করছে
এন্ড-টু-এন্ড উদাহরণের জন্য TFRecords লোড হচ্ছে দেখুন।
tf.data API বিভিন্ন ধরণের ফাইল ফরম্যাট সমর্থন করে যাতে আপনি মেমরির সাথে খাপ খায় না এমন বড় ডেটাসেটগুলি প্রক্রিয়া করতে পারেন। উদাহরণ স্বরূপ, TFRecord ফাইল ফরম্যাট হল একটি সাধারণ রেকর্ড-ভিত্তিক বাইনারি বিন্যাস যা অনেক TensorFlow অ্যাপ্লিকেশন প্রশিক্ষণ ডেটার জন্য ব্যবহার করে। tf.data.TFRecordDataset ক্লাস আপনাকে ইনপুট পাইপলাইনের অংশ হিসাবে এক বা একাধিক TFRecord ফাইলের বিষয়বস্তু স্ট্রিম করতে সক্ষম করে।
ফ্রেঞ্চ স্ট্রিট নেম সাইনস (FSNS) থেকে পরীক্ষা ফাইল ব্যবহার করে এখানে একটি উদাহরণ দেওয়া হল।
# Creates a dataset that reads all of the examples from two files.
fsns_test_file = tf.keras.utils.get_file("fsns.tfrec", "https://storage.googleapis.com/download.tensorflow.org/data/fsns-20160927/testdata/fsns-00000-of-00001")
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/fsns-20160927/testdata/fsns-00000-of-00001 7905280/7904079 [==============================] - 1s 0us/step 7913472/7904079 [==============================] - 1s 0us/step
TFRecordDataset ইনিশিয়ালাইজারের filenames আর্গুমেন্ট হয় একটি স্ট্রিং, স্ট্রিংগুলির একটি তালিকা বা স্ট্রিংগুলির একটি tf.Tensor .টেনসর হতে পারে৷ তাই আপনার কাছে প্রশিক্ষণ এবং বৈধতার উদ্দেশ্যে দুটি সেট ফাইল থাকলে, আপনি একটি ফ্যাক্টরি পদ্ধতি তৈরি করতে পারেন যা ডেটাসেট তৈরি করে, ফাইলের নামগুলিকে ইনপুট আর্গুমেন্ট হিসাবে গ্রহণ করে:
dataset = tf.data.TFRecordDataset(filenames = [fsns_test_file])
dataset
<TFRecordDatasetV2 element_spec=TensorSpec(shape=(), dtype=tf.string, name=None)>
অনেক TensorFlow প্রজেক্ট তাদের TFRecord ফাইলে ক্রমিককৃত tf.train.Example রেকর্ড ব্যবহার করে। এগুলি পরিদর্শন করার আগে ডিকোড করা দরকার:
raw_example = next(iter(dataset))
parsed = tf.train.Example.FromString(raw_example.numpy())
parsed.features.feature['image/text']
bytes_list {
value: "Rue Perreyon"
}
টেক্সট ডেটা গ্রাস করছে
শেষ থেকে শেষ উদাহরণের জন্য পাঠ্য লোড হচ্ছে দেখুন।
অনেক ডেটাসেট এক বা একাধিক টেক্সট ফাইল হিসাবে বিতরণ করা হয়। tf.data.TextLineDataset এক বা একাধিক টেক্সট ফাইল থেকে লাইন বের করার একটি সহজ উপায় প্রদান করে। এক বা একাধিক ফাইলের নাম দেওয়া হলে, একটি TextLineDataset সেই ফাইলগুলির প্রতি লাইনে একটি স্ট্রিং-মূল্যবান উপাদান তৈরি করবে।
directory_url = 'https://storage.googleapis.com/download.tensorflow.org/data/illiad/'
file_names = ['cowper.txt', 'derby.txt', 'butler.txt']
file_paths = [
tf.keras.utils.get_file(file_name, directory_url + file_name)
for file_name in file_names
]
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/illiad/cowper.txt 819200/815980 [==============================] - 0s 0us/step 827392/815980 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/illiad/derby.txt 811008/809730 [==============================] - 0s 0us/step 819200/809730 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/illiad/butler.txt 811008/807992 [==============================] - 0s 0us/step 819200/807992 [==============================] - 0s 0us/step
dataset = tf.data.TextLineDataset(file_paths)
এখানে প্রথম ফাইলের প্রথম কয়েকটি লাইন রয়েছে:
for line in dataset.take(5):
print(line.numpy())
b"\xef\xbb\xbfAchilles sing, O Goddess! Peleus' son;" b'His wrath pernicious, who ten thousand woes' b"Caused to Achaia's host, sent many a soul" b'Illustrious into Ades premature,' b'And Heroes gave (so stood the will of Jove)'
ফাইলের মধ্যে বিকল্প লাইন ব্যবহার করতে Dataset.interleave ব্যবহার করুন। এটি একসাথে ফাইলগুলিকে এলোমেলো করা সহজ করে তোলে। এখানে প্রতিটি অনুবাদের প্রথম, দ্বিতীয় এবং তৃতীয় লাইন রয়েছে:
files_ds = tf.data.Dataset.from_tensor_slices(file_paths)
lines_ds = files_ds.interleave(tf.data.TextLineDataset, cycle_length=3)
for i, line in enumerate(lines_ds.take(9)):
if i % 3 == 0:
print()
print(line.numpy())
b"\xef\xbb\xbfAchilles sing, O Goddess! Peleus' son;" b"\xef\xbb\xbfOf Peleus' son, Achilles, sing, O Muse," b'\xef\xbb\xbfSing, O goddess, the anger of Achilles son of Peleus, that brought' b'His wrath pernicious, who ten thousand woes' b'The vengeance, deep and deadly; whence to Greece' b'countless ills upon the Achaeans. Many a brave soul did it send' b"Caused to Achaia's host, sent many a soul" b'Unnumbered ills arose; which many a soul' b'hurrying down to Hades, and many a hero did it yield a prey to dogs and'
ডিফল্টরূপে, একটি TextLineDataset প্রতিটি ফাইলের প্রতিটি লাইন প্রদান করে, যা কাঙ্খিত নাও হতে পারে, উদাহরণস্বরূপ, যদি ফাইলটি একটি হেডার লাইন দিয়ে শুরু হয়, বা এতে মন্তব্য থাকে। Dataset.skip() বা Dataset.filter() রূপান্তর ব্যবহার করে এই লাইনগুলি সরানো যেতে পারে। এখানে, আপনি প্রথম লাইনটি এড়িয়ে যান, তারপর শুধুমাত্র জীবিতদের খুঁজে বের করতে ফিল্টার করুন।
titanic_file = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
titanic_lines = tf.data.TextLineDataset(titanic_file)
Downloading data from https://storage.googleapis.com/tf-datasets/titanic/train.csv 32768/30874 [===============================] - 0s 0us/step 40960/30874 [=======================================] - 0s 0us/step
for line in titanic_lines.take(10):
print(line.numpy())
b'survived,sex,age,n_siblings_spouses,parch,fare,class,deck,embark_town,alone' b'0,male,22.0,1,0,7.25,Third,unknown,Southampton,n' b'1,female,38.0,1,0,71.2833,First,C,Cherbourg,n' b'1,female,26.0,0,0,7.925,Third,unknown,Southampton,y' b'1,female,35.0,1,0,53.1,First,C,Southampton,n' b'0,male,28.0,0,0,8.4583,Third,unknown,Queenstown,y' b'0,male,2.0,3,1,21.075,Third,unknown,Southampton,n' b'1,female,27.0,0,2,11.1333,Third,unknown,Southampton,n' b'1,female,14.0,1,0,30.0708,Second,unknown,Cherbourg,n' b'1,female,4.0,1,1,16.7,Third,G,Southampton,n'
def survived(line):
return tf.not_equal(tf.strings.substr(line, 0, 1), "0")
survivors = titanic_lines.skip(1).filter(survived)
for line in survivors.take(10):
print(line.numpy())
b'1,female,38.0,1,0,71.2833,First,C,Cherbourg,n' b'1,female,26.0,0,0,7.925,Third,unknown,Southampton,y' b'1,female,35.0,1,0,53.1,First,C,Southampton,n' b'1,female,27.0,0,2,11.1333,Third,unknown,Southampton,n' b'1,female,14.0,1,0,30.0708,Second,unknown,Cherbourg,n' b'1,female,4.0,1,1,16.7,Third,G,Southampton,n' b'1,male,28.0,0,0,13.0,Second,unknown,Southampton,y' b'1,female,28.0,0,0,7.225,Third,unknown,Cherbourg,y' b'1,male,28.0,0,0,35.5,First,A,Southampton,y' b'1,female,38.0,1,5,31.3875,Third,unknown,Southampton,n'
CSV ডেটা ব্যবহার করা হচ্ছে
আরও উদাহরণের জন্য CSV ফাইল লোড হচ্ছে এবং পান্ডাস ডেটাফ্রেম লোড হচ্ছে দেখুন।
CSV ফাইল ফরম্যাট প্লেইন টেক্সটে ট্যাবুলার ডেটা সংরক্ষণের জন্য একটি জনপ্রিয় ফর্ম্যাট।
উদাহরণ স্বরূপ:
titanic_file = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
df = pd.read_csv(titanic_file)
df.head()
যদি আপনার ডেটা মেমরিতে ফিট হয় তবে একই Dataset.from_tensor_slices পদ্ধতি অভিধানে কাজ করে, এই ডেটা সহজেই আমদানি করার অনুমতি দেয়:
titanic_slices = tf.data.Dataset.from_tensor_slices(dict(df))
for feature_batch in titanic_slices.take(1):
for key, value in feature_batch.items():
print(" {!r:20s}: {}".format(key, value))
'survived' : 0 'sex' : b'male' 'age' : 22.0 'n_siblings_spouses': 1 'parch' : 0 'fare' : 7.25 'class' : b'Third' 'deck' : b'unknown' 'embark_town' : b'Southampton' 'alone' : b'n'
প্রয়োজনে ডিস্ক থেকে লোড করা আরও মাপযোগ্য পদ্ধতি।
tf.data মডিউল RFC 4180 মেনে চলা এক বা একাধিক CSV ফাইল থেকে রেকর্ড বের করার পদ্ধতি প্রদান করে।
experimental.make_csv_dataset ফাংশন হল csv ফাইলের সেট পড়ার জন্য উচ্চ স্তরের ইন্টারফেস। এটি কলাম টাইপ ইনফারেন্স এবং অন্যান্য অনেক বৈশিষ্ট্যকে সমর্থন করে, যেমন ব্যাচিং এবং শাফলিং, ব্যবহারকে সহজ করতে।
titanic_batches = tf.data.experimental.make_csv_dataset(
titanic_file, batch_size=4,
label_name="survived")
for feature_batch, label_batch in titanic_batches.take(1):
print("'survived': {}".format(label_batch))
print("features:")
for key, value in feature_batch.items():
print(" {!r:20s}: {}".format(key, value))
'survived': [1 0 0 0] features: 'sex' : [b'female' b'female' b'male' b'male'] 'age' : [32. 28. 37. 50.] 'n_siblings_spouses': [0 3 0 0] 'parch' : [0 1 1 0] 'fare' : [13. 25.4667 29.7 13. ] 'class' : [b'Second' b'Third' b'First' b'Second'] 'deck' : [b'unknown' b'unknown' b'C' b'unknown'] 'embark_town' : [b'Southampton' b'Southampton' b'Cherbourg' b'Southampton'] 'alone' : [b'y' b'n' b'n' b'y']
আপনি select_columns আর্গুমেন্ট ব্যবহার করতে পারেন যদি আপনার শুধুমাত্র কলামের একটি উপসেটের প্রয়োজন হয়।
titanic_batches = tf.data.experimental.make_csv_dataset(
titanic_file, batch_size=4,
label_name="survived", select_columns=['class', 'fare', 'survived'])
for feature_batch, label_batch in titanic_batches.take(1):
print("'survived': {}".format(label_batch))
for key, value in feature_batch.items():
print(" {!r:20s}: {}".format(key, value))
'survived': [0 1 1 0] 'fare' : [ 7.05 15.5 26.25 8.05] 'class' : [b'Third' b'Third' b'Second' b'Third']
এছাড়াও একটি নিম্ন-স্তরের experimental.CsvDataset । CsvDataset ক্লাস যা সূক্ষ্ম দানাদার নিয়ন্ত্রণ প্রদান করে। এটি কলাম টাইপ অনুমান সমর্থন করে না। পরিবর্তে আপনাকে অবশ্যই প্রতিটি কলামের ধরন নির্দিষ্ট করতে হবে।
titanic_types = [tf.int32, tf.string, tf.float32, tf.int32, tf.int32, tf.float32, tf.string, tf.string, tf.string, tf.string]
dataset = tf.data.experimental.CsvDataset(titanic_file, titanic_types , header=True)
for line in dataset.take(10):
print([item.numpy() for item in line])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n'] [1, b'female', 38.0, 1, 0, 71.2833, b'First', b'C', b'Cherbourg', b'n'] [1, b'female', 26.0, 0, 0, 7.925, b'Third', b'unknown', b'Southampton', b'y'] [1, b'female', 35.0, 1, 0, 53.1, b'First', b'C', b'Southampton', b'n'] [0, b'male', 28.0, 0, 0, 8.4583, b'Third', b'unknown', b'Queenstown', b'y'] [0, b'male', 2.0, 3, 1, 21.075, b'Third', b'unknown', b'Southampton', b'n'] [1, b'female', 27.0, 0, 2, 11.1333, b'Third', b'unknown', b'Southampton', b'n'] [1, b'female', 14.0, 1, 0, 30.0708, b'Second', b'unknown', b'Cherbourg', b'n'] [1, b'female', 4.0, 1, 1, 16.7, b'Third', b'G', b'Southampton', b'n'] [0, b'male', 20.0, 0, 0, 8.05, b'Third', b'unknown', b'Southampton', b'y']
কিছু কলাম খালি থাকলে, এই নিম্ন-স্তরের ইন্টারফেস আপনাকে কলামের প্রকারের পরিবর্তে ডিফল্ট মান প্রদান করতে দেয়।
%%writefile missing.csv
1,2,3,4
,2,3,4
1,,3,4
1,2,,4
1,2,3,
,,,
Writing missing.csv
# Creates a dataset that reads all of the records from two CSV files, each with
# four float columns which may have missing values.
record_defaults = [999,999,999,999]
dataset = tf.data.experimental.CsvDataset("missing.csv", record_defaults)
dataset = dataset.map(lambda *items: tf.stack(items))
dataset
<MapDataset element_spec=TensorSpec(shape=(4,), dtype=tf.int32, name=None)>
for line in dataset:
print(line.numpy())
[1 2 3 4] [999 2 3 4] [ 1 999 3 4] [ 1 2 999 4] [ 1 2 3 999] [999 999 999 999]
ডিফল্টরূপে, একটি CsvDataset ফাইলের প্রতিটি লাইনের প্রতিটি কলাম প্রদান করে, যা পছন্দসই নাও হতে পারে, উদাহরণস্বরূপ যদি ফাইলটি একটি হেডার লাইন দিয়ে শুরু হয় যা উপেক্ষা করা উচিত, অথবা যদি ইনপুটে কিছু কলামের প্রয়োজন না হয়। এই লাইন এবং ক্ষেত্র যথাক্রমে header এবং select_cols আর্গুমেন্ট দিয়ে মুছে ফেলা যেতে পারে।
# Creates a dataset that reads all of the records from two CSV files with
# headers, extracting float data from columns 2 and 4.
record_defaults = [999, 999] # Only provide defaults for the selected columns
dataset = tf.data.experimental.CsvDataset("missing.csv", record_defaults, select_cols=[1, 3])
dataset = dataset.map(lambda *items: tf.stack(items))
dataset
<MapDataset element_spec=TensorSpec(shape=(2,), dtype=tf.int32, name=None)>
for line in dataset:
print(line.numpy())
[2 4] [2 4] [999 4] [2 4] [ 2 999] [999 999]
ফাইলের সেট গ্রাস করছে
ফাইলগুলির একটি সেট হিসাবে বিতরণ করা অনেক ডেটাসেট রয়েছে, যেখানে প্রতিটি ফাইল একটি উদাহরণ।
flowers_root = tf.keras.utils.get_file(
'flower_photos',
'https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',
untar=True)
flowers_root = pathlib.Path(flowers_root)
রুট ডিরেক্টরিতে প্রতিটি শ্রেণীর জন্য একটি ডিরেক্টরি রয়েছে:
for item in flowers_root.glob("*"):
print(item.name)
sunflowers daisy LICENSE.txt roses tulips dandelion
প্রতিটি ক্লাস ডিরেক্টরির ফাইলগুলি উদাহরণ:
list_ds = tf.data.Dataset.list_files(str(flowers_root/'*/*'))
for f in list_ds.take(5):
print(f.numpy())
b'/home/kbuilder/.keras/datasets/flower_photos/sunflowers/5018120483_cc0421b176_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/dandelion/8642679391_0805b147cb_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/sunflowers/8266310743_02095e782d_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/tulips/13176521023_4d7cc74856_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/dandelion/19437578578_6ab1b3c984.jpg'
tf.io.read_file ফাংশন ব্যবহার করে ডেটা পড়ুন এবং পাথ থেকে লেবেলটি বের করুন, (image, label) জোড়া ফিরিয়ে দিন:
def process_path(file_path):
label = tf.strings.split(file_path, os.sep)[-2]
return tf.io.read_file(file_path), label
labeled_ds = list_ds.map(process_path)
for image_raw, label_text in labeled_ds.take(1):
print(repr(image_raw.numpy()[:100]))
print()
print(label_text.numpy())
b'\xff\xd8\xff\xe0\x00\x10JFIF\x00\x01\x01\x00\x00\x01\x00\x01\x00\x00\xff\xe2\x0cXICC_PROFILE\x00\x01\x01\x00\x00\x0cHLino\x02\x10\x00\x00mntrRGB XYZ \x07\xce\x00\x02\x00\t\x00\x06\x001\x00\x00acspMSFT\x00\x00\x00\x00IEC sRGB\x00\x00\x00\x00\x00\x00' b'daisy'
ব্যাচিং ডেটাসেট উপাদান
সহজ ব্যাচিং
একটি ডেটাসেটের পরপর উপাদানগুলিকে একটি একক উপাদানে স্ট্যাক করে n সহজতম রূপ। Dataset.batch() ট্রান্সফরমেশন ঠিক এই কাজটি করে, tf.stack() অপারেটরের মতো একই সীমাবদ্ধতার সাথে, উপাদানগুলির প্রতিটি উপাদানে প্রয়োগ করা হয়: অর্থাৎ প্রতিটি উপাদান i এর জন্য, সমস্ত উপাদানের অবশ্যই একই আকৃতির একটি টেনসর থাকতে হবে।
inc_dataset = tf.data.Dataset.range(100)
dec_dataset = tf.data.Dataset.range(0, -100, -1)
dataset = tf.data.Dataset.zip((inc_dataset, dec_dataset))
batched_dataset = dataset.batch(4)
for batch in batched_dataset.take(4):
print([arr.numpy() for arr in batch])
[array([0, 1, 2, 3]), array([ 0, -1, -2, -3])] [array([4, 5, 6, 7]), array([-4, -5, -6, -7])] [array([ 8, 9, 10, 11]), array([ -8, -9, -10, -11])] [array([12, 13, 14, 15]), array([-12, -13, -14, -15])]
যদিও tf.data আকৃতির তথ্য প্রচার করার চেষ্টা করে, Dataset.batch এর ডিফল্ট সেটিংসের ফলে একটি অজানা ব্যাচের আকার দেখা দেয় কারণ শেষ ব্যাচটি পূর্ণ নাও হতে পারে। আকৃতিতে None s নোট করুন:
batched_dataset
<BatchDataset element_spec=(TensorSpec(shape=(None,), dtype=tf.int64, name=None), TensorSpec(shape=(None,), dtype=tf.int64, name=None))>
সেই শেষ ব্যাচটিকে উপেক্ষা করতে drop_remainder যুক্তিটি ব্যবহার করুন এবং সম্পূর্ণ আকৃতির প্রচার পান:
batched_dataset = dataset.batch(7, drop_remainder=True)
batched_dataset
<BatchDataset element_spec=(TensorSpec(shape=(7,), dtype=tf.int64, name=None), TensorSpec(shape=(7,), dtype=tf.int64, name=None))>
প্যাডিং সহ ব্যাচিং টেনসর
উপরের রেসিপিটি টেনসরগুলির জন্য কাজ করে যেগুলির সকলের একই আকার রয়েছে। যাইহোক, অনেক মডেল (যেমন সিকোয়েন্স মডেল) ইনপুট ডেটার সাথে কাজ করে যার বিভিন্ন আকার থাকতে পারে (যেমন বিভিন্ন দৈর্ঘ্যের সিকোয়েন্স)। এই ক্ষেত্রে পরিচালনা করার জন্য, Dataset.padded_batch রূপান্তর আপনাকে এক বা একাধিক মাত্রা নির্দিষ্ট করে বিভিন্ন আকারের ব্যাচ টেনসরগুলিকে প্যাড করা হতে পারে।
dataset = tf.data.Dataset.range(100)
dataset = dataset.map(lambda x: tf.fill([tf.cast(x, tf.int32)], x))
dataset = dataset.padded_batch(4, padded_shapes=(None,))
for batch in dataset.take(2):
print(batch.numpy())
print()
[[0 0 0] [1 0 0] [2 2 0] [3 3 3]] [[4 4 4 4 0 0 0] [5 5 5 5 5 0 0] [6 6 6 6 6 6 0] [7 7 7 7 7 7 7]]
Dataset.padded_batch রূপান্তর আপনাকে প্রতিটি উপাদানের প্রতিটি মাত্রার জন্য আলাদা প্যাডিং সেট করতে দেয় এবং এটি পরিবর্তনশীল-দৈর্ঘ্য (উপরের উদাহরণে None দ্বারা চিহ্নিত করা হয়নি) বা ধ্রুবক-দৈর্ঘ্য হতে পারে। প্যাডিং মানকে ওভাররাইড করাও সম্ভব, যা ডিফল্ট 0 তে।
প্রশিক্ষণ কর্মপ্রবাহ
একাধিক যুগ প্রক্রিয়াকরণ
tf.data API একই ডেটার একাধিক যুগ প্রক্রিয়া করার দুটি প্রধান উপায় অফার করে।
একাধিক যুগে একটি ডেটাসেটের উপর পুনরাবৃত্তি করার সবচেয়ে সহজ উপায় হল Dataset.repeat() রূপান্তর ব্যবহার করা। প্রথমে, টাইটানিক ডেটার একটি ডেটাসেট তৈরি করুন:
titanic_file = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
titanic_lines = tf.data.TextLineDataset(titanic_file)
def plot_batch_sizes(ds):
batch_sizes = [batch.shape[0] for batch in ds]
plt.bar(range(len(batch_sizes)), batch_sizes)
plt.xlabel('Batch number')
plt.ylabel('Batch size')
কোন আর্গুমেন্ট ছাড়া Dataset.repeat() রূপান্তর প্রয়োগ করলে ইনপুট অনির্দিষ্টকালের জন্য পুনরাবৃত্তি হবে।
Dataset.repeat রূপান্তর একটি যুগের সমাপ্তি এবং পরবর্তী যুগের শুরুর সংকেত ছাড়াই তার যুক্তিগুলিকে একত্রিত করে৷ এই কারণে Dataset.repeat-এর পরে প্রয়োগ করা একটি Dataset.batch যুগের সীমানা Dataset.repeat ব্যাচগুলি দেবে:
titanic_batches = titanic_lines.repeat(3).batch(128)
plot_batch_sizes(titanic_batches)
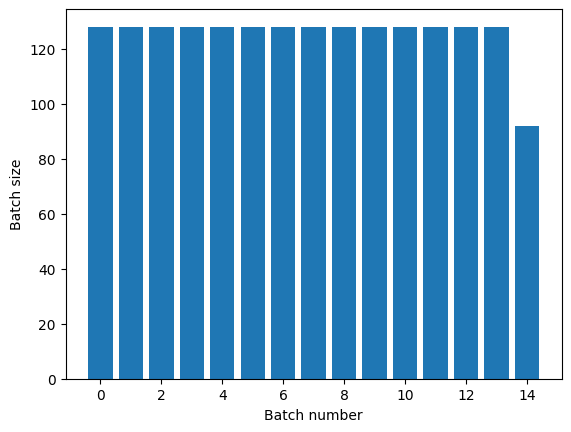
আপনার যদি স্পষ্ট যুগের বিচ্ছেদ প্রয়োজন হয়, পুনরাবৃত্তি করার আগে Dataset.batch :
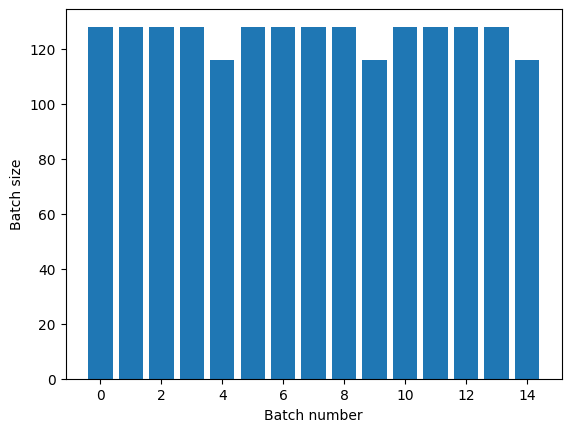
titanic_batches = titanic_lines.batch(128).repeat(3)
plot_batch_sizes(titanic_batches)
আপনি যদি প্রতিটি যুগের শেষে একটি কাস্টম গণনা করতে চান (যেমন পরিসংখ্যান সংগ্রহ করতে) তাহলে প্রতিটি যুগে ডেটাসেট পুনরাবৃত্তি পুনরায় চালু করা সহজ:
epochs = 3
dataset = titanic_lines.batch(128)
for epoch in range(epochs):
for batch in dataset:
print(batch.shape)
print("End of epoch: ", epoch)
(128,) (128,) (128,) (128,) (116,) End of epoch: 0 (128,) (128,) (128,) (128,) (116,) End of epoch: 1 (128,) (128,) (128,) (128,) (116,) End of epoch: 2
এলোমেলোভাবে ইনপুট ডেটা শাফেলিং
Dataset.shuffle() রূপান্তর একটি নির্দিষ্ট-আকারের বাফার বজায় রাখে এবং সেই বাফার থেকে এলোমেলোভাবে পরবর্তী উপাদানটি বেছে নেয়।
ডেটাসেটে একটি সূচক যুক্ত করুন যাতে আপনি প্রভাব দেখতে পারেন:
lines = tf.data.TextLineDataset(titanic_file)
counter = tf.data.experimental.Counter()
dataset = tf.data.Dataset.zip((counter, lines))
dataset = dataset.shuffle(buffer_size=100)
dataset = dataset.batch(20)
dataset
<BatchDataset element_spec=(TensorSpec(shape=(None,), dtype=tf.int64, name=None), TensorSpec(shape=(None,), dtype=tf.string, name=None))>
যেহেতু buffer_size হল 100, এবং ব্যাচের সাইজ হল 20, প্রথম ব্যাচে 120-এর বেশি সূচক সহ কোনও উপাদান নেই।
n,line_batch = next(iter(dataset))
print(n.numpy())
[ 52 94 22 70 63 96 56 102 38 16 27 104 89 43 41 68 42 61 112 8]
Dataset.repeat এর সাথে Dataset.batch বিষয়ের সাথে সম্পর্কিত অর্ডার।
শাফেল বাফার খালি না হওয়া পর্যন্ত Dataset.shuffle একটি যুগের সমাপ্তির সংকেত দেয় না। সুতরাং একটি পুনরাবৃত্তির আগে স্থাপন করা একটি শাফেল পরবর্তীতে যাওয়ার আগে একটি যুগের প্রতিটি উপাদান দেখাবে:
dataset = tf.data.Dataset.zip((counter, lines))
shuffled = dataset.shuffle(buffer_size=100).batch(10).repeat(2)
print("Here are the item ID's near the epoch boundary:\n")
for n, line_batch in shuffled.skip(60).take(5):
print(n.numpy())
Here are the item ID's near the epoch boundary: [509 595 537 550 555 591 480 627 482 519] [522 619 538 581 569 608 531 558 461 496] [548 489 379 607 611 622 234 525] [ 59 38 4 90 73 84 27 51 107 12] [77 72 91 60 7 62 92 47 70 67]
shuffle_repeat = [n.numpy().mean() for n, line_batch in shuffled]
plt.plot(shuffle_repeat, label="shuffle().repeat()")
plt.ylabel("Mean item ID")
plt.legend()
<matplotlib.legend.Legend at 0x7f7e7061c650>
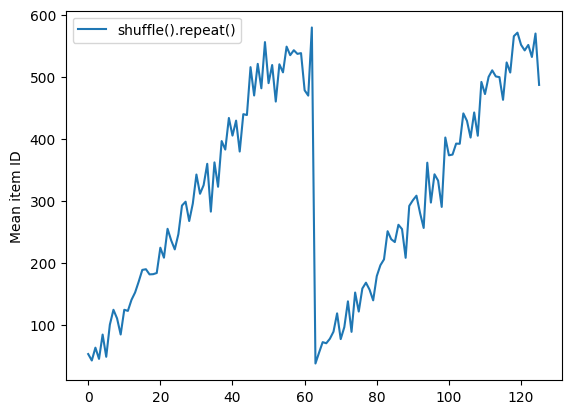
কিন্তু একটি এলোমেলো করার আগে একটি পুনরাবৃত্তি যুগের সীমানাকে একসাথে মিশ্রিত করে:
dataset = tf.data.Dataset.zip((counter, lines))
shuffled = dataset.repeat(2).shuffle(buffer_size=100).batch(10)
print("Here are the item ID's near the epoch boundary:\n")
for n, line_batch in shuffled.skip(55).take(15):
print(n.numpy())
Here are the item ID's near the epoch boundary: [ 6 8 528 604 13 492 308 441 569 475] [ 5 626 615 568 20 554 520 454 10 607] [510 542 0 363 32 446 395 588 35 4] [ 7 15 28 23 39 559 585 49 252 556] [581 617 25 43 26 548 29 460 48 41] [ 19 64 24 300 612 611 36 63 69 57] [287 605 21 512 442 33 50 68 608 47] [625 90 91 613 67 53 606 344 16 44] [453 448 89 45 465 2 31 618 368 105] [565 3 586 114 37 464 12 627 30 621] [ 82 117 72 75 84 17 571 610 18 600] [107 597 575 88 623 86 101 81 456 102] [122 79 51 58 80 61 367 38 537 113] [ 71 78 598 152 143 620 100 158 133 130] [155 151 144 135 146 121 83 27 103 134]
repeat_shuffle = [n.numpy().mean() for n, line_batch in shuffled]
plt.plot(shuffle_repeat, label="shuffle().repeat()")
plt.plot(repeat_shuffle, label="repeat().shuffle()")
plt.ylabel("Mean item ID")
plt.legend()
<matplotlib.legend.Legend at 0x7f7e706013d0>
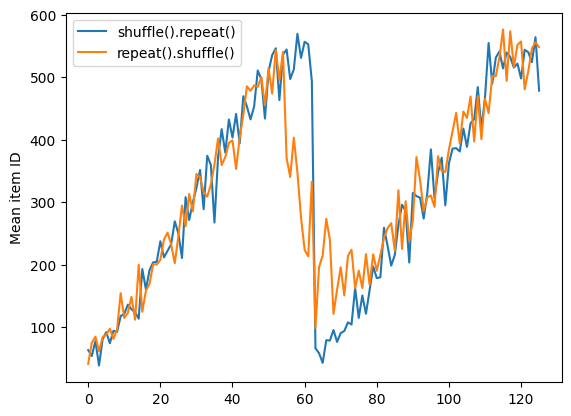
ডেটা প্রিপ্রসেস করা হচ্ছে
Dataset.map(f) রূপান্তর ইনপুট ডেটাসেটের প্রতিটি উপাদানে একটি প্রদত্ত ফাংশন f প্রয়োগ করে একটি নতুন ডেটাসেট তৈরি করে। এটি map() ফাংশনের উপর ভিত্তি করে যা সাধারণত কার্যকরী প্রোগ্রামিং ভাষার তালিকায় (এবং অন্যান্য কাঠামো) প্রয়োগ করা হয়। f ফাংশনটি tf. tf.Tensor অবজেক্টগুলিকে নেয় যা ইনপুটে একটি একক উপাদানকে প্রতিনিধিত্ব করে এবং tf. tf.Tensor অবজেক্টগুলিকে ফেরত দেয় যা নতুন ডেটাসেটে একটি একক উপাদানকে প্রতিনিধিত্ব করবে৷ এটির বাস্তবায়ন একটি উপাদানকে অন্য উপাদানে রূপান্তর করতে মানক টেনসরফ্লো অপারেশন ব্যবহার করে।
এই বিভাগে Dataset.map() কীভাবে ব্যবহার করতে হয় তার সাধারণ উদাহরণগুলি কভার করে।
ইমেজ ডেটা ডিকোডিং এবং এটির আকার পরিবর্তন করা
রিয়েল-ওয়ার্ল্ড ইমেজ ডেটার উপর একটি নিউরাল নেটওয়ার্ককে প্রশিক্ষণ দেওয়ার সময়, বিভিন্ন আকারের ছবিগুলিকে একটি সাধারণ আকারে রূপান্তর করতে প্রায়ই প্রয়োজন হয়, যাতে সেগুলি একটি নির্দিষ্ট আকারে ব্যাচ করা যায়।
ফুল ফাইলের নাম ডেটাসেট পুনর্নির্মাণ করুন:
list_ds = tf.data.Dataset.list_files(str(flowers_root/'*/*'))
একটি ফাংশন লিখুন যা ডেটাসেট উপাদানগুলিকে ম্যানিপুলেট করে।
# Reads an image from a file, decodes it into a dense tensor, and resizes it
# to a fixed shape.
def parse_image(filename):
parts = tf.strings.split(filename, os.sep)
label = parts[-2]
image = tf.io.read_file(filename)
image = tf.io.decode_jpeg(image)
image = tf.image.convert_image_dtype(image, tf.float32)
image = tf.image.resize(image, [128, 128])
return image, label
এটি কাজ করে তা পরীক্ষা করুন।
file_path = next(iter(list_ds))
image, label = parse_image(file_path)
def show(image, label):
plt.figure()
plt.imshow(image)
plt.title(label.numpy().decode('utf-8'))
plt.axis('off')
show(image, label)

ডেটাসেটের উপর এটি ম্যাপ করুন।
images_ds = list_ds.map(parse_image)
for image, label in images_ds.take(2):
show(image, label)


নির্বিচারে পাইথন যুক্তি প্রয়োগ করা হচ্ছে
পারফরম্যান্সের কারণে, যখনই সম্ভব আপনার ডেটা প্রিপ্রসেস করার জন্য TensorFlow অপারেশনগুলি ব্যবহার করুন। যাইহোক, কখনও কখনও আপনার ইনপুট ডেটা পার্স করার সময় বহিরাগত পাইথন লাইব্রেরি কল করা দরকারী। আপনি একটি Dataset.map() রূপান্তরে tf.py_function tf.py_function() অপারেশন ব্যবহার করতে পারেন।
উদাহরণস্বরূপ, যদি আপনি একটি এলোমেলো ঘূর্ণন প্রয়োগ করতে চান, tf.image মডিউলটিতে শুধুমাত্র tf.image.rot90 রয়েছে, যা চিত্র বৃদ্ধির জন্য খুব বেশি কার্যকর নয়।
tf.py_function প্রদর্শন করতে, পরিবর্তে scipy.ndimage.rotate ফাংশন ব্যবহার করার চেষ্টা করুন:
import scipy.ndimage as ndimage
def random_rotate_image(image):
image = ndimage.rotate(image, np.random.uniform(-30, 30), reshape=False)
return image
image, label = next(iter(images_ds))
image = random_rotate_image(image)
show(image, label)
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

Dataset.from_generator এর সাথে এই ফাংশনটি ব্যবহার করার জন্য Dataset.map এর মতো একই সতর্কতা প্রযোজ্য, আপনি যখন ফাংশন প্রয়োগ করবেন তখন আপনাকে রিটার্ন আকার এবং প্রকারগুলি বর্ণনা করতে হবে:
def tf_random_rotate_image(image, label):
im_shape = image.shape
[image,] = tf.py_function(random_rotate_image, [image], [tf.float32])
image.set_shape(im_shape)
return image, label
rot_ds = images_ds.map(tf_random_rotate_image)
for image, label in rot_ds.take(2):
show(image, label)
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).


পার্সিং tf.Example প্রোটোকল বাফার বার্তা
অনেক ইনপুট পাইপলাইন TFRecord ফরম্যাট থেকে tf.train.Example প্রোটোকল বাফার বার্তা বের করে। প্রতিটি tf.train.Example রেকর্ডে এক বা একাধিক "বৈশিষ্ট্য" থাকে এবং ইনপুট পাইপলাইন সাধারণত এই বৈশিষ্ট্যগুলিকে টেনসরে রূপান্তর করে।
fsns_test_file = tf.keras.utils.get_file("fsns.tfrec", "https://storage.googleapis.com/download.tensorflow.org/data/fsns-20160927/testdata/fsns-00000-of-00001")
dataset = tf.data.TFRecordDataset(filenames = [fsns_test_file])
dataset
<TFRecordDatasetV2 element_spec=TensorSpec(shape=(), dtype=tf.string, name=None)>
আপনি ডেটা বোঝার জন্য tf.data.Dataset এর বাইরে tf.train.Example প্রোটো নিয়ে কাজ করতে পারেন:
raw_example = next(iter(dataset))
parsed = tf.train.Example.FromString(raw_example.numpy())
feature = parsed.features.feature
raw_img = feature['image/encoded'].bytes_list.value[0]
img = tf.image.decode_png(raw_img)
plt.imshow(img)
plt.axis('off')
_ = plt.title(feature["image/text"].bytes_list.value[0])

raw_example = next(iter(dataset))
def tf_parse(eg):
example = tf.io.parse_example(
eg[tf.newaxis], {
'image/encoded': tf.io.FixedLenFeature(shape=(), dtype=tf.string),
'image/text': tf.io.FixedLenFeature(shape=(), dtype=tf.string)
})
return example['image/encoded'][0], example['image/text'][0]
img, txt = tf_parse(raw_example)
print(txt.numpy())
print(repr(img.numpy()[:20]), "...")
b'Rue Perreyon' b'\x89PNG\r\n\x1a\n\x00\x00\x00\rIHDR\x00\x00\x02X' ...
decoded = dataset.map(tf_parse)
decoded
<MapDataset element_spec=(TensorSpec(shape=(), dtype=tf.string, name=None), TensorSpec(shape=(), dtype=tf.string, name=None))>
image_batch, text_batch = next(iter(decoded.batch(10)))
image_batch.shape
TensorShape([10])
সময় সিরিজ জানালা
শেষ থেকে শেষ সময় সিরিজের উদাহরণের জন্য দেখুন: সময় সিরিজের পূর্বাভাস ।
টাইম সিরিজ ডেটা প্রায়ই সময় অক্ষ অক্ষত সঙ্গে সংগঠিত হয়.
প্রদর্শন করতে একটি সাধারণ Dataset.range ব্যবহার করুন:
range_ds = tf.data.Dataset.range(100000)
সাধারণত, এই ধরণের ডেটার উপর ভিত্তি করে মডেলগুলি একটি সংলগ্ন সময়ের স্লাইস চাইবে।
সবচেয়ে সহজ পদ্ধতি হবে ডেটা ব্যাচ করা:
batch ব্যবহার করে
batches = range_ds.batch(10, drop_remainder=True)
for batch in batches.take(5):
print(batch.numpy())
[0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24 25 26 27 28 29] [30 31 32 33 34 35 36 37 38 39] [40 41 42 43 44 45 46 47 48 49]
অথবা ভবিষ্যতের এক ধাপ ঘন ভবিষ্যদ্বাণী করতে, আপনি একে অপরের সাপেক্ষে বৈশিষ্ট্য এবং লেবেলগুলিকে এক ধাপে স্থানান্তর করতে পারেন:
def dense_1_step(batch):
# Shift features and labels one step relative to each other.
return batch[:-1], batch[1:]
predict_dense_1_step = batches.map(dense_1_step)
for features, label in predict_dense_1_step.take(3):
print(features.numpy(), " => ", label.numpy())
[0 1 2 3 4 5 6 7 8] => [1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18] => [11 12 13 14 15 16 17 18 19] [20 21 22 23 24 25 26 27 28] => [21 22 23 24 25 26 27 28 29]
একটি নির্দিষ্ট অফসেটের পরিবর্তে একটি সম্পূর্ণ উইন্ডো ভবিষ্যদ্বাণী করতে আপনি ব্যাচ দুটি ভাগে বিভক্ত করতে পারেন:
batches = range_ds.batch(15, drop_remainder=True)
def label_next_5_steps(batch):
return (batch[:-5], # Inputs: All except the last 5 steps
batch[-5:]) # Labels: The last 5 steps
predict_5_steps = batches.map(label_next_5_steps)
for features, label in predict_5_steps.take(3):
print(features.numpy(), " => ", label.numpy())
[0 1 2 3 4 5 6 7 8 9] => [10 11 12 13 14] [15 16 17 18 19 20 21 22 23 24] => [25 26 27 28 29] [30 31 32 33 34 35 36 37 38 39] => [40 41 42 43 44]
একটি ব্যাচের বৈশিষ্ট্য এবং অন্য ব্যাচের লেবেলের মধ্যে কিছু ওভারল্যাপ করার অনুমতি দিতে, Dataset.zip ব্যবহার করুন:
feature_length = 10
label_length = 3
features = range_ds.batch(feature_length, drop_remainder=True)
labels = range_ds.batch(feature_length).skip(1).map(lambda labels: labels[:label_length])
predicted_steps = tf.data.Dataset.zip((features, labels))
for features, label in predicted_steps.take(5):
print(features.numpy(), " => ", label.numpy())
[0 1 2 3 4 5 6 7 8 9] => [10 11 12] [10 11 12 13 14 15 16 17 18 19] => [20 21 22] [20 21 22 23 24 25 26 27 28 29] => [30 31 32] [30 31 32 33 34 35 36 37 38 39] => [40 41 42] [40 41 42 43 44 45 46 47 48 49] => [50 51 52]
window ব্যবহার করে
Dataset.batch ব্যবহার করার সময়, এমন পরিস্থিতি রয়েছে যেখানে আপনার আরও সূক্ষ্ম নিয়ন্ত্রণের প্রয়োজন হতে পারে। Dataset.window পদ্ধতি আপনাকে সম্পূর্ণ নিয়ন্ত্রণ দেয়, কিন্তু কিছু যত্নের প্রয়োজন: এটি Datasets একটি Dataset প্রদান করে। বিস্তারিত জানার জন্য ডেটাসেট কাঠামো দেখুন।
window_size = 5
windows = range_ds.window(window_size, shift=1)
for sub_ds in windows.take(5):
print(sub_ds)
<_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)> <_VariantDataset element_spec=TensorSpec(shape=(), dtype=tf.int64, name=None)>
Dataset.flat_map পদ্ধতিটি ডেটাসেটের একটি ডেটাসেট নিতে পারে এবং এটিকে একটি একক ডেটাসেটে সমতল করতে পারে:
for x in windows.flat_map(lambda x: x).take(30):
print(x.numpy(), end=' ')
0 1 2 3 4 1 2 3 4 5 2 3 4 5 6 3 4 5 6 7 4 5 6 7 8 5 6 7 8 9
প্রায় সব ক্ষেত্রে, আপনি প্রথমে ডেটাসেট .batch করতে চাইবেন:
def sub_to_batch(sub):
return sub.batch(window_size, drop_remainder=True)
for example in windows.flat_map(sub_to_batch).take(5):
print(example.numpy())
[0 1 2 3 4] [1 2 3 4 5] [2 3 4 5 6] [3 4 5 6 7] [4 5 6 7 8]
এখন, আপনি দেখতে পাচ্ছেন যে shift আর্গুমেন্ট প্রতিটি উইন্ডোর উপর কতটা চলে যায় তা নিয়ন্ত্রণ করে।
এটি একসাথে রেখে আপনি এই ফাংশনটি লিখতে পারেন:
def make_window_dataset(ds, window_size=5, shift=1, stride=1):
windows = ds.window(window_size, shift=shift, stride=stride)
def sub_to_batch(sub):
return sub.batch(window_size, drop_remainder=True)
windows = windows.flat_map(sub_to_batch)
return windows
ds = make_window_dataset(range_ds, window_size=10, shift = 5, stride=3)
for example in ds.take(10):
print(example.numpy())
[ 0 3 6 9 12 15 18 21 24 27] [ 5 8 11 14 17 20 23 26 29 32] [10 13 16 19 22 25 28 31 34 37] [15 18 21 24 27 30 33 36 39 42] [20 23 26 29 32 35 38 41 44 47] [25 28 31 34 37 40 43 46 49 52] [30 33 36 39 42 45 48 51 54 57] [35 38 41 44 47 50 53 56 59 62] [40 43 46 49 52 55 58 61 64 67] [45 48 51 54 57 60 63 66 69 72]
তারপর লেবেলগুলি বের করা সহজ, আগের মতো:
dense_labels_ds = ds.map(dense_1_step)
for inputs,labels in dense_labels_ds.take(3):
print(inputs.numpy(), "=>", labels.numpy())
[ 0 3 6 9 12 15 18 21 24] => [ 3 6 9 12 15 18 21 24 27] [ 5 8 11 14 17 20 23 26 29] => [ 8 11 14 17 20 23 26 29 32] [10 13 16 19 22 25 28 31 34] => [13 16 19 22 25 28 31 34 37]
রিস্যাম্পলিং
খুব শ্রেণী-ভারসাম্যহীন একটি ডেটাসেটের সাথে কাজ করার সময়, আপনি ডেটাসেটটি পুনরায় নমুনা করতে চাইতে পারেন। tf.data করার জন্য দুটি পদ্ধতি প্রদান করে। ক্রেডিট কার্ড জালিয়াতি ডেটাসেট এই ধরণের সমস্যার একটি ভাল উদাহরণ।
zip_path = tf.keras.utils.get_file(
origin='https://storage.googleapis.com/download.tensorflow.org/data/creditcard.zip',
fname='creditcard.zip',
extract=True)
csv_path = zip_path.replace('.zip', '.csv')
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/creditcard.zip 69156864/69155632 [==============================] - 2s 0us/step 69165056/69155632 [==============================] - 2s 0us/step
creditcard_ds = tf.data.experimental.make_csv_dataset(
csv_path, batch_size=1024, label_name="Class",
# Set the column types: 30 floats and an int.
column_defaults=[float()]*30+[int()])
এখন, ক্লাসের বিতরণ পরীক্ষা করুন, এটি অত্যন্ত তির্যক:
def count(counts, batch):
features, labels = batch
class_1 = labels == 1
class_1 = tf.cast(class_1, tf.int32)
class_0 = labels == 0
class_0 = tf.cast(class_0, tf.int32)
counts['class_0'] += tf.reduce_sum(class_0)
counts['class_1'] += tf.reduce_sum(class_1)
return counts
counts = creditcard_ds.take(10).reduce(
initial_state={'class_0': 0, 'class_1': 0},
reduce_func = count)
counts = np.array([counts['class_0'].numpy(),
counts['class_1'].numpy()]).astype(np.float32)
fractions = counts/counts.sum()
print(fractions)
[0.9956 0.0044]
ভারসাম্যহীন ডেটাসেটের সাথে প্রশিক্ষণের একটি সাধারণ পদ্ধতি হল এটির ভারসাম্য বজায় রাখা। tf.data কয়েকটি পদ্ধতি রয়েছে যা এই কর্মপ্রবাহকে সক্ষম করে:
ডেটাসেট স্যাম্পলিং
একটি ডেটাসেট পুনরায় নমুনা করার একটি পদ্ধতি হল sample_from_datasets ব্যবহার করা। এটি আরও প্রযোজ্য যখন আপনার কাছে একটি পৃথক ডেটা থাকে। প্রতিটি ক্লাসের জন্য data.Dataset ।
এখানে, ক্রেডিট কার্ড জালিয়াতি ডেটা থেকে সেগুলি তৈরি করতে ফিল্টার ব্যবহার করুন:
negative_ds = (
creditcard_ds
.unbatch()
.filter(lambda features, label: label==0)
.repeat())
positive_ds = (
creditcard_ds
.unbatch()
.filter(lambda features, label: label==1)
.repeat())
for features, label in positive_ds.batch(10).take(1):
print(label.numpy())
[1 1 1 1 1 1 1 1 1 1]
tf.data.Dataset.sample_from_datasets ব্যবহার করতে ডেটাসেট পাস করুন এবং প্রতিটির ওজন:
balanced_ds = tf.data.Dataset.sample_from_datasets(
[negative_ds, positive_ds], [0.5, 0.5]).batch(10)
এখন ডেটাসেট 50/50 সম্ভাব্যতার সাথে প্রতিটি শ্রেণীর উদাহরণ তৈরি করে:
for features, labels in balanced_ds.take(10):
print(labels.numpy())
[1 0 1 0 1 0 1 1 1 1] [0 0 1 1 0 1 1 1 1 1] [1 1 1 1 0 0 1 0 1 0] [1 1 1 0 1 0 0 1 1 1] [0 1 0 1 1 1 0 1 1 0] [0 1 0 0 0 1 0 0 0 0] [1 1 1 1 1 0 0 1 1 0] [0 0 0 1 0 1 1 1 0 0] [0 0 1 1 1 1 0 1 1 1] [1 0 0 1 1 1 1 0 1 1]
প্রত্যাখ্যান পুনরায় নমুনা
উপরের Dataset.sample_from_datasets পদ্ধতির সাথে একটি সমস্যা হল যে এটির জন্য ক্লাস প্রতি একটি পৃথক tf.data.Dataset প্রয়োজন। আপনি এই দুটি ডেটাসেট তৈরি করতে Dataset.filter ব্যবহার করতে পারেন, কিন্তু এর ফলে সমস্ত ডেটা দুইবার লোড হয়।
data.Dataset.rejection_resample পদ্ধতিটি একটি ডেটাসেটে পুনরায় ভারসাম্য বজায় রাখতে প্রয়োগ করা যেতে পারে, শুধুমাত্র একবার লোড করার সময়। ভারসাম্য অর্জন করতে ডেটাসেট থেকে উপাদানগুলি বাদ দেওয়া হবে।
data.Dataset.rejection_resample একটি class_func আর্গুমেন্ট নেয়। এই class_func প্রতিটি ডেটাসেট উপাদানে প্রয়োগ করা হয়, এবং ভারসাম্য রক্ষার উদ্দেশ্যে একটি উদাহরণ কোন শ্রেণীর অন্তর্গত তা নির্ধারণ করতে ব্যবহৃত হয়।
এখানে লক্ষ্য হল লেবেল ডিস্ট্রিবিউশনের ভারসাম্য বজায় রাখা, এবং creditcard_ds উপাদানগুলি ইতিমধ্যেই (features, label) জোড়া। তাই class_func শুধুমাত্র সেই লেবেলগুলি ফেরত দিতে হবে:
def class_func(features, label):
return label
রিস্যাম্পলিং পদ্ধতিটি পৃথক উদাহরণের সাথে কাজ করে, তাই এই ক্ষেত্রে আপনাকে অবশ্যই সেই পদ্ধতিটি প্রয়োগ করার আগে ডেটাসেটটি unbatch করতে হবে।
পদ্ধতির একটি লক্ষ্য বন্টন প্রয়োজন, এবং ঐচ্ছিকভাবে ইনপুট হিসাবে একটি প্রাথমিক বিতরণ অনুমান।
resample_ds = (
creditcard_ds
.unbatch()
.rejection_resample(class_func, target_dist=[0.5,0.5],
initial_dist=fractions)
.batch(10))
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/data/ops/dataset_ops.py:5797: Print (from tensorflow.python.ops.logging_ops) is deprecated and will be removed after 2018-08-20. Instructions for updating: Use tf.print instead of tf.Print. Note that tf.print returns a no-output operator that directly prints the output. Outside of defuns or eager mode, this operator will not be executed unless it is directly specified in session.run or used as a control dependency for other operators. This is only a concern in graph mode. Below is an example of how to ensure tf.print executes in graph mode:
rejection_resample পদ্ধতিটি (class, example) জোড়া প্রদান করে যেখানে class class_func এর আউটপুট। এই ক্ষেত্রে, example ইতিমধ্যেই একটি (feature, label) জোড়া ছিল, তাই লেবেলের অতিরিক্ত অনুলিপি ফেলে দিতে map ব্যবহার করুন:
balanced_ds = resample_ds.map(lambda extra_label, features_and_label: features_and_label)
এখন ডেটাসেট 50/50 সম্ভাব্যতার সাথে প্রতিটি শ্রেণীর উদাহরণ তৈরি করে:
for features, labels in balanced_ds.take(10):
print(labels.numpy())
Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] Proportion of examples rejected by sampler is high: [0.995605469][0.995605469 0.00439453125][0 1] [0 1 1 1 0 1 1 0 1 1] [1 1 0 1 0 0 0 0 1 1] [1 1 1 1 0 0 0 0 1 1] [1 0 0 1 0 0 1 0 1 1] [1 0 0 0 0 1 0 0 0 0] [1 0 0 1 1 0 1 1 1 0] [1 1 0 0 0 0 0 0 0 1] [0 0 1 0 0 0 1 0 1 1] [0 1 0 1 0 1 0 0 0 1] [0 0 0 0 0 0 0 0 1 1]
ইটারেটার চেকপয়েন্টিং
টেনসরফ্লো চেকপয়েন্ট নেওয়া সমর্থন করে যাতে আপনার প্রশিক্ষণ প্রক্রিয়া পুনরায় চালু হলে এটি তার বেশিরভাগ অগ্রগতি পুনরুদ্ধার করতে সর্বশেষ চেকপয়েন্ট পুনরুদ্ধার করতে পারে। মডেল ভেরিয়েবল চেকপয়েন্ট করার পাশাপাশি, আপনি ডেটাসেট ইটারেটরের অগ্রগতিও চেকপয়েন্ট করতে পারেন। আপনার যদি একটি বড় ডেটাসেট থাকে এবং প্রতিটি রিস্টার্টের শুরু থেকে ডেটাসেট শুরু করতে না চান তাহলে এটি কার্যকর হতে পারে। তবে নোট করুন যে ইটারেটর চেকপয়েন্টগুলি বড় হতে পারে, যেহেতু পরিবর্তন যেমন prefetch shuffle ইটারেটরের মধ্যে বাফারিং উপাদান প্রয়োজন।
আপনার পুনরাবৃত্তিকারীকে একটি চেকপয়েন্টে অন্তর্ভুক্ত করতে, tf.train.Checkpoint কনস্ট্রাক্টরের কাছে পুনরাবৃত্তিকারীকে পাস করুন।
range_ds = tf.data.Dataset.range(20)
iterator = iter(range_ds)
ckpt = tf.train.Checkpoint(step=tf.Variable(0), iterator=iterator)
manager = tf.train.CheckpointManager(ckpt, '/tmp/my_ckpt', max_to_keep=3)
print([next(iterator).numpy() for _ in range(5)])
save_path = manager.save()
print([next(iterator).numpy() for _ in range(5)])
ckpt.restore(manager.latest_checkpoint)
print([next(iterator).numpy() for _ in range(5)])
[0, 1, 2, 3, 4] [5, 6, 7, 8, 9] [5, 6, 7, 8, 9]
tf.keras সহ tf.data ব্যবহার করা
tf.keras API মেশিন লার্নিং মডেল তৈরি এবং কার্যকর করার অনেক দিককে সরল করে। এর .fit() এবং .evaluate() এবং .predict() APIগুলি ইনপুট হিসাবে ডেটাসেটগুলিকে সমর্থন করে৷ এখানে একটি দ্রুত ডেটাসেট এবং মডেল সেটআপ রয়েছে:
train, test = tf.keras.datasets.fashion_mnist.load_data()
images, labels = train
images = images/255.0
labels = labels.astype(np.int32)
fmnist_train_ds = tf.data.Dataset.from_tensor_slices((images, labels))
fmnist_train_ds = fmnist_train_ds.shuffle(5000).batch(32)
model = tf.keras.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10)
])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
(feature, label) জোড়ার ডেটাসেট পাস Model.fit এবং Model.evaluate এর জন্য প্রয়োজন:
model.fit(fmnist_train_ds, epochs=2)
Epoch 1/2 1875/1875 [==============================] - 4s 2ms/step - loss: 0.5984 - accuracy: 0.7973 Epoch 2/2 1875/1875 [==============================] - 4s 2ms/step - loss: 0.4607 - accuracy: 0.8430 <keras.callbacks.History at 0x7f7e70283110>
আপনি যদি একটি অসীম ডেটাসেট পাস করেন, উদাহরণস্বরূপ Dataset.repeat() কল করে, আপনাকে শুধু steps_per_epoch আর্গুমেন্ট পাস করতে হবে:
model.fit(fmnist_train_ds.repeat(), epochs=2, steps_per_epoch=20)
Epoch 1/2 20/20 [==============================] - 0s 2ms/step - loss: 0.4574 - accuracy: 0.8672 Epoch 2/2 20/20 [==============================] - 0s 2ms/step - loss: 0.4216 - accuracy: 0.8562 <keras.callbacks.History at 0x7f7e144948d0>
মূল্যায়নের জন্য আপনি মূল্যায়ন ধাপের সংখ্যা পাস করতে পারেন:
loss, accuracy = model.evaluate(fmnist_train_ds)
print("Loss :", loss)
print("Accuracy :", accuracy)
1875/1875 [==============================] - 4s 2ms/step - loss: 0.4350 - accuracy: 0.8524 Loss : 0.4350026249885559 Accuracy : 0.8524333238601685
দীর্ঘ ডেটাসেটের জন্য, মূল্যায়নের জন্য ধাপের সংখ্যা সেট করুন:
loss, accuracy = model.evaluate(fmnist_train_ds.repeat(), steps=10)
print("Loss :", loss)
print("Accuracy :", accuracy)
10/10 [==============================] - 0s 2ms/step - loss: 0.4345 - accuracy: 0.8687 Loss : 0.43447819352149963 Accuracy : 0.8687499761581421
Model.predict কল করার সময় লেবেলগুলির প্রয়োজন নেই।
predict_ds = tf.data.Dataset.from_tensor_slices(images).batch(32)
result = model.predict(predict_ds, steps = 10)
print(result.shape)
(320, 10)
কিন্তু লেবেলগুলি উপেক্ষা করা হয় যদি আপনি সেগুলি ধারণকারী একটি ডেটাসেট পাস করেন:
result = model.predict(fmnist_train_ds, steps = 10)
print(result.shape)
(320, 10)