
| | |  GitHub-এ উৎস দেখুন GitHub-এ উৎস দেখুন |
এই টিউটোরিয়ালটি TensorFlow এর সাথে কিভাবে CSV ডেটা ব্যবহার করতে হয় তার উদাহরণ প্রদান করে।
এর দুটি প্রধান অংশ রয়েছে:
- ডিস্ক বন্ধ ডাটা লোড হচ্ছে
- প্রশিক্ষণের জন্য উপযুক্ত একটি ফর্ম এটি প্রাক প্রক্রিয়াকরণ.
এই টিউটোরিয়ালটি লোডিং এর উপর ফোকাস করে এবং প্রিপ্রসেসিং এর কিছু দ্রুত উদাহরণ দেয়। একটি টিউটোরিয়ালের জন্য যা প্রিপ্রসেসিং দিকের উপর ফোকাস করে প্রিপ্রসেসিং লেয়ার গাইড এবং টিউটোরিয়াল দেখুন ।
সেটআপ
import pandas as pd
import numpy as np
# Make numpy values easier to read.
np.set_printoptions(precision=3, suppress=True)
import tensorflow as tf
from tensorflow.keras import layers
মেমরি ডেটাতে
যেকোনো ছোট CSV ডেটাসেটের জন্য এটিতে একটি TensorFlow মডেলকে প্রশিক্ষণ দেওয়ার সহজ উপায় হল এটিকে একটি পান্ডাস ডেটাফ্রেম বা একটি NumPy অ্যারে হিসাবে মেমরিতে লোড করা।
একটি অপেক্ষাকৃত সহজ উদাহরণ হল অ্যাবালোন ডেটাসেট ।
- ডেটাসেট ছোট।
- সমস্ত ইনপুট বৈশিষ্ট্যগুলি সমস্ত সীমিত-পরিসরের ফ্লোটিং পয়েন্ট মান।
একটি পান্ডাস DataFrame ডেটা কীভাবে ডাউনলোড করবেন তা এখানে রয়েছে:
abalone_train = pd.read_csv(
"https://storage.googleapis.com/download.tensorflow.org/data/abalone_train.csv",
names=["Length", "Diameter", "Height", "Whole weight", "Shucked weight",
"Viscera weight", "Shell weight", "Age"])
abalone_train.head()
ডেটাসেটে অ্যাবালোনের পরিমাপের একটি সেট রয়েছে, এক ধরনের সামুদ্রিক শামুক।

"অ্যাবালোন শেল" ( নিকি ডুগান পোগ দ্বারা, সিসি বাই-এসএ 2.0)
এই ডেটাসেটের জন্য নামমাত্র কাজ হল অন্যান্য পরিমাপ থেকে বয়সের ভবিষ্যদ্বাণী করা, তাই প্রশিক্ষণের জন্য বৈশিষ্ট্য এবং লেবেলগুলি আলাদা করুন:
abalone_features = abalone_train.copy()
abalone_labels = abalone_features.pop('Age')
এই ডেটাসেটের জন্য আপনি সমস্ত বৈশিষ্ট্যকে একইভাবে বিবেচনা করবেন। বৈশিষ্ট্যগুলিকে একটি একক NumPy অ্যারেতে প্যাক করুন৷:
abalone_features = np.array(abalone_features)
abalone_features
array([[0.435, 0.335, 0.11 , ..., 0.136, 0.077, 0.097],
[0.585, 0.45 , 0.125, ..., 0.354, 0.207, 0.225],
[0.655, 0.51 , 0.16 , ..., 0.396, 0.282, 0.37 ],
...,
[0.53 , 0.42 , 0.13 , ..., 0.374, 0.167, 0.249],
[0.395, 0.315, 0.105, ..., 0.118, 0.091, 0.119],
[0.45 , 0.355, 0.12 , ..., 0.115, 0.067, 0.16 ]])
পরবর্তী একটি রিগ্রেশন মডেল বয়স ভবিষ্যদ্বাণী করুন. যেহেতু এখানে শুধুমাত্র একটি একক ইনপুট টেনসর আছে, একটি keras.Sequential । অনুক্রমিক মডেল এখানে যথেষ্ট।
abalone_model = tf.keras.Sequential([
layers.Dense(64),
layers.Dense(1)
])
abalone_model.compile(loss = tf.losses.MeanSquaredError(),
optimizer = tf.optimizers.Adam())
সেই মডেলকে প্রশিক্ষণ দিতে, Model.fit এ বৈশিষ্ট্য এবং লেবেলগুলি পাস করুন:
abalone_model.fit(abalone_features, abalone_labels, epochs=10)
Epoch 1/10 104/104 [==============================] - 1s 2ms/step - loss: 63.0446 Epoch 2/10 104/104 [==============================] - 0s 2ms/step - loss: 11.9429 Epoch 3/10 104/104 [==============================] - 0s 2ms/step - loss: 8.4836 Epoch 4/10 104/104 [==============================] - 0s 2ms/step - loss: 8.0052 Epoch 5/10 104/104 [==============================] - 0s 2ms/step - loss: 7.6073 Epoch 6/10 104/104 [==============================] - 0s 2ms/step - loss: 7.2485 Epoch 7/10 104/104 [==============================] - 0s 2ms/step - loss: 6.9883 Epoch 8/10 104/104 [==============================] - 0s 2ms/step - loss: 6.7977 Epoch 9/10 104/104 [==============================] - 0s 2ms/step - loss: 6.6477 Epoch 10/10 104/104 [==============================] - 0s 2ms/step - loss: 6.5359 <keras.callbacks.History at 0x7f70543c7350>
আপনি CSV ডেটা ব্যবহার করে একটি মডেলকে প্রশিক্ষণ দেওয়ার সবচেয়ে প্রাথমিক উপায়টি দেখেছেন৷ এর পরে, আপনি শিখবেন কিভাবে সাংখ্যিক কলাম স্বাভাবিক করার জন্য প্রিপ্রসেসিং প্রয়োগ করতে হয়।
বেসিক প্রিপ্রসেসিং
আপনার মডেলের ইনপুটগুলিকে স্বাভাবিক করার জন্য এটি ভাল অনুশীলন। কেরাস প্রিপ্রসেসিং স্তরগুলি আপনার মডেলে এই স্বাভাবিককরণ তৈরি করার একটি সুবিধাজনক উপায় প্রদান করে।
স্তরটি প্রতিটি কলামের গড় এবং ভিন্নতা পূর্বনির্ধারণ করবে এবং ডেটা স্বাভাবিক করতে এগুলি ব্যবহার করবে।
প্রথমে আপনি স্তর তৈরি করুন:
normalize = layers.Normalization()
তারপরে আপনি আপনার ডেটাতে স্বাভাবিককরণ স্তরটিকে মানিয়ে নিতে Normalization.adapt() পদ্ধতি ব্যবহার করুন।
normalize.adapt(abalone_features)
তারপর আপনার মডেলে স্বাভাবিককরণ স্তর ব্যবহার করুন:
norm_abalone_model = tf.keras.Sequential([
normalize,
layers.Dense(64),
layers.Dense(1)
])
norm_abalone_model.compile(loss = tf.losses.MeanSquaredError(),
optimizer = tf.optimizers.Adam())
norm_abalone_model.fit(abalone_features, abalone_labels, epochs=10)
Epoch 1/10 104/104 [==============================] - 0s 2ms/step - loss: 92.5851 Epoch 2/10 104/104 [==============================] - 0s 2ms/step - loss: 55.1199 Epoch 3/10 104/104 [==============================] - 0s 2ms/step - loss: 18.2937 Epoch 4/10 104/104 [==============================] - 0s 2ms/step - loss: 6.2633 Epoch 5/10 104/104 [==============================] - 0s 2ms/step - loss: 5.1257 Epoch 6/10 104/104 [==============================] - 0s 2ms/step - loss: 5.0217 Epoch 7/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9775 Epoch 8/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9730 Epoch 9/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9348 Epoch 10/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9416 <keras.callbacks.History at 0x7f70541b2a50>
মিশ্র তথ্য প্রকার
"টাইটানিক" ডেটাসেটে টাইটানিকের যাত্রীদের তথ্য রয়েছে। এই ডেটাসেটের নামমাত্র কাজ হল ভবিষ্যদ্বাণী করা যে কে বেঁচে আছে।

উইকিমিডিয়া থেকে ছবি
{kind=link}
কাঁচা ডেটা সহজে একটি পান্ডাস DataFrame হিসাবে লোড করা যেতে পারে, কিন্তু টেনসরফ্লো মডেলের ইনপুট হিসাবে অবিলম্বে ব্যবহারযোগ্য নয়৷
titanic = pd.read_csv("https://storage.googleapis.com/tf-datasets/titanic/train.csv")
titanic.head()
titanic_features = titanic.copy()
titanic_labels = titanic_features.pop('survived')
বিভিন্ন ডেটা টাইপ এবং রেঞ্জের কারণে আপনি কেবল NumPy অ্যারেতে বৈশিষ্ট্যগুলি স্ট্যাক করতে পারবেন না এবং এটি একটি keras.Sequential মডেলে পাস করতে পারবেন না। প্রতিটি কলাম পৃথকভাবে পরিচালনা করা প্রয়োজন।
একটি বিকল্প হিসাবে, আপনি ক্যাটাগরিকাল কলামগুলিকে সংখ্যাসূচক কলামে রূপান্তর করতে আপনার ডেটা অফলাইনে প্রিপ্রসেস করতে পারেন (আপনার পছন্দের যে কোনও টুল ব্যবহার করে), তারপর প্রক্রিয়াকৃত আউটপুটটি আপনার টেনসরফ্লো মডেলে পাস করুন৷ সেই পদ্ধতির অসুবিধা হল যে আপনি যদি আপনার মডেলটি সংরক্ষণ এবং রপ্তানি করেন তবে এটির সাথে প্রিপ্রসেসিং সংরক্ষণ করা হয় না। কেরাস প্রিপ্রসেসিং স্তরগুলি এই সমস্যাটি এড়ায় কারণ তারা মডেলের অংশ।
এই উদাহরণে, আপনি একটি মডেল তৈরি করবেন যা কেরাস ফাংশনাল API ব্যবহার করে প্রিপ্রসেসিং লজিক প্রয়োগ করে। আপনি সাবক্লাসিং দ্বারা এটি করতে পারেন।
কার্যকরী API "সিম্বলিক" টেনসরগুলিতে কাজ করে। সাধারণ "আগ্রহী" tensors একটি মান আছে. বিপরীতে এই "প্রতীকী" টেনসরগুলি করে না। পরিবর্তে তারা কোন ক্রিয়াকলাপগুলি তাদের উপর চালানো হয় তা ট্র্যাক রাখে এবং গণনার উপস্থাপনা তৈরি করে, যা আপনি পরে চালাতে পারেন। এখানে একটি দ্রুত উদাহরণ:
# Create a symbolic input
input = tf.keras.Input(shape=(), dtype=tf.float32)
# Perform a calculation using the input
result = 2*input + 1
# the result doesn't have a value
result
<KerasTensor: shape=(None,) dtype=float32 (created by layer 'tf.__operators__.add')>
calc = tf.keras.Model(inputs=input, outputs=result)
print(calc(1).numpy())
print(calc(2).numpy())
3.0 5.0
প্রি-প্রসেসিং মডেল তৈরি করতে, সিম্বলিক keras.Input একটি সেট তৈরি করে শুরু করুন। CSV কলামের নাম এবং ডেটা-টাইপগুলির সাথে মিল করে ইনপুট অবজেক্ট।
inputs = {}
for name, column in titanic_features.items():
dtype = column.dtype
if dtype == object:
dtype = tf.string
else:
dtype = tf.float32
inputs[name] = tf.keras.Input(shape=(1,), name=name, dtype=dtype)
inputs
{'sex': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'sex')>,
'age': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'age')>,
'n_siblings_spouses': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'n_siblings_spouses')>,
'parch': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'parch')>,
'fare': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'fare')>,
'class': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'class')>,
'deck': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'deck')>,
'embark_town': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'embark_town')>,
'alone': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'alone')>}
আপনার প্রিপ্রসেসিং লজিকের প্রথম ধাপ হল সাংখ্যিক ইনপুটগুলিকে একত্রিত করা এবং একটি স্বাভাবিককরণ স্তরের মাধ্যমে সেগুলি চালানো:
numeric_inputs = {name:input for name,input in inputs.items()
if input.dtype==tf.float32}
x = layers.Concatenate()(list(numeric_inputs.values()))
norm = layers.Normalization()
norm.adapt(np.array(titanic[numeric_inputs.keys()]))
all_numeric_inputs = norm(x)
all_numeric_inputs
<KerasTensor: shape=(None, 4) dtype=float32 (created by layer 'normalization_1')>
সমস্ত প্রতীকী প্রিপ্রসেসিং ফলাফল সংগ্রহ করুন, পরে সেগুলিকে একত্রিত করতে।
preprocessed_inputs = [all_numeric_inputs]
স্ট্রিং ইনপুটগুলির জন্য tf.keras.layers.StringLookup ফাংশনটি একটি শব্দভান্ডারে স্ট্রিং থেকে পূর্ণসংখ্যা সূচকে ম্যাপ করতে ব্যবহার করুন। এর পরে, মডেলের জন্য উপযুক্ত float32 ডেটাতে সূচীগুলিকে রূপান্তর করতে tf.keras.layers.CategoryEncoding ব্যবহার করুন।
tf.keras.layers.CategoryEncoding স্তরের ডিফল্ট সেটিংস প্রতিটি ইনপুটের জন্য একটি এক-হট ভেক্টর তৈরি করে। একটি স্তর. layers.Embedding কাজ করবে৷ এই বিষয়ে আরও জানতে প্রিপ্রসেসিং লেয়ার গাইড এবং টিউটোরিয়াল দেখুন।
for name, input in inputs.items():
if input.dtype == tf.float32:
continue
lookup = layers.StringLookup(vocabulary=np.unique(titanic_features[name]))
one_hot = layers.CategoryEncoding(max_tokens=lookup.vocab_size())
x = lookup(input)
x = one_hot(x)
preprocessed_inputs.append(x)
WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead.
inputs এবং processed_inputs সংগ্রহের সাথে, আপনি সমস্ত প্রাক-প্রসেসড ইনপুট একসাথে সংযুক্ত করতে পারেন এবং একটি মডেল তৈরি করতে পারেন যা প্রিপ্রসেসিং পরিচালনা করে:
preprocessed_inputs_cat = layers.Concatenate()(preprocessed_inputs)
titanic_preprocessing = tf.keras.Model(inputs, preprocessed_inputs_cat)
tf.keras.utils.plot_model(model = titanic_preprocessing , rankdir="LR", dpi=72, show_shapes=True)
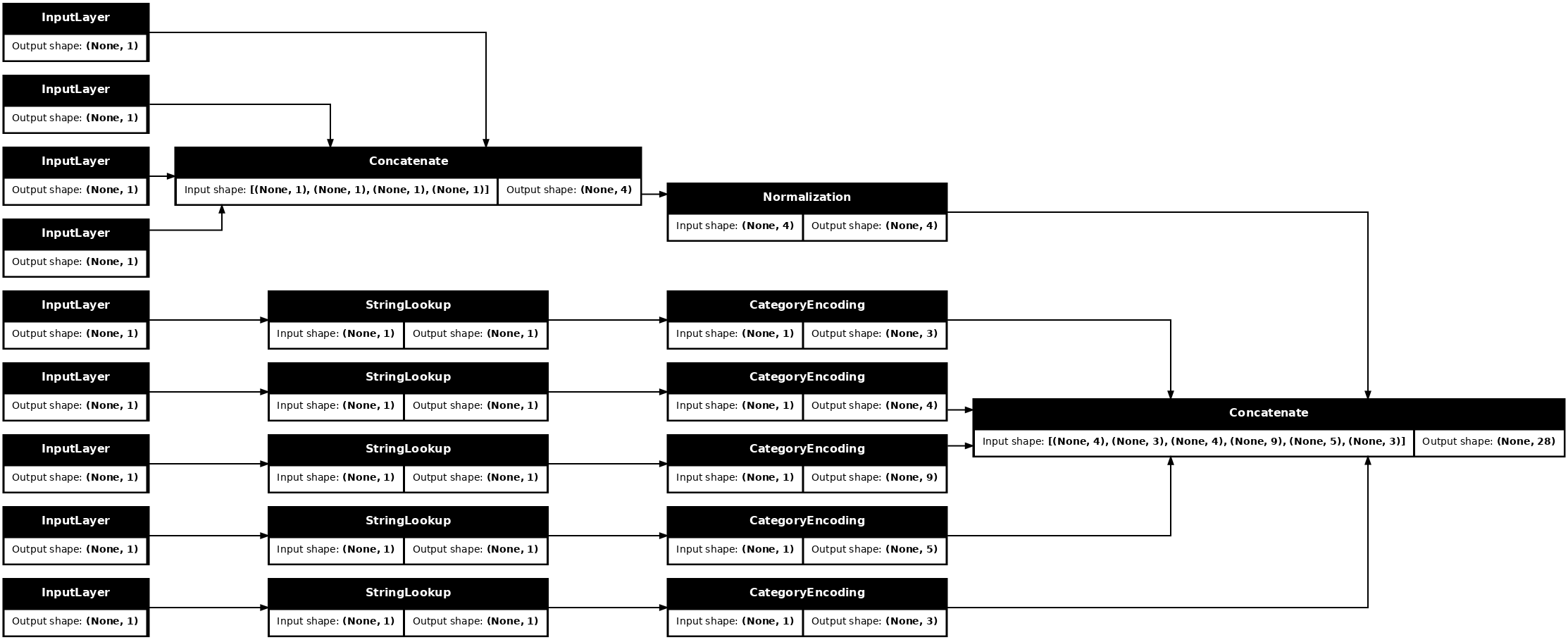
এই model শুধু ইনপুট প্রিপ্রসেসিং রয়েছে। এটি আপনার ডেটাতে কী করে তা দেখতে আপনি এটি চালাতে পারেন। কেরাস মডেলগুলি স্বয়ংক্রিয়ভাবে পান্ডাস DataFrames রূপান্তর করে না কারণ এটি একটি টেনসরে বা টেনসরের অভিধানে রূপান্তর করা উচিত কিনা তা পরিষ্কার নয়। তাই এটিকে টেনসরের অভিধানে রূপান্তর করুন:
titanic_features_dict = {name: np.array(value)
for name, value in titanic_features.items()}
প্রথম প্রশিক্ষণের উদাহরণটি স্লাইস করুন এবং এটি এই প্রিপ্রসেসিং মডেলে পাস করুন, আপনি সংখ্যাসূচক বৈশিষ্ট্যগুলি এবং স্ট্রিং ওয়ান-হটগুলিকে একত্রিত করে দেখতে পাবেন:
features_dict = {name:values[:1] for name, values in titanic_features_dict.items()}
titanic_preprocessing(features_dict)
<tf.Tensor: shape=(1, 28), dtype=float32, numpy=
array([[-0.61 , 0.395, -0.479, -0.497, 0. , 0. , 1. , 0. ,
0. , 0. , 1. , 0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 1. , 0. , 0. , 0. , 1. ,
0. , 0. , 1. , 0. ]], dtype=float32)>
এখন এর উপরে মডেল তৈরি করুন:
def titanic_model(preprocessing_head, inputs):
body = tf.keras.Sequential([
layers.Dense(64),
layers.Dense(1)
])
preprocessed_inputs = preprocessing_head(inputs)
result = body(preprocessed_inputs)
model = tf.keras.Model(inputs, result)
model.compile(loss=tf.losses.BinaryCrossentropy(from_logits=True),
optimizer=tf.optimizers.Adam())
return model
titanic_model = titanic_model(titanic_preprocessing, inputs)
আপনি যখন মডেলটি প্রশিক্ষণ দেন, তখন বৈশিষ্ট্যগুলির x হিসাবে এবং y হিসাবে পাস করুন।
titanic_model.fit(x=titanic_features_dict, y=titanic_labels, epochs=10)
Epoch 1/10 20/20 [==============================] - 1s 4ms/step - loss: 0.8017 Epoch 2/10 20/20 [==============================] - 0s 4ms/step - loss: 0.5913 Epoch 3/10 20/20 [==============================] - 0s 5ms/step - loss: 0.5212 Epoch 4/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4841 Epoch 5/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4615 Epoch 6/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4470 Epoch 7/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4367 Epoch 8/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4304 Epoch 9/10 20/20 [==============================] - 0s 4ms/step - loss: 0.4265 Epoch 10/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4239 <keras.callbacks.History at 0x7f70b1f82a50>
যেহেতু প্রিপ্রসেসিং মডেলের অংশ, আপনি মডেলটিকে সংরক্ষণ করতে পারেন এবং এটি অন্য কোথাও পুনরায় লোড করতে পারেন এবং অভিন্ন ফলাফল পেতে পারেন:
titanic_model.save('test')
reloaded = tf.keras.models.load_model('test')
2022-01-26 06:36:18.822459: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: test/assets
features_dict = {name:values[:1] for name, values in titanic_features_dict.items()}
before = titanic_model(features_dict)
after = reloaded(features_dict)
assert (before-after)<1e-3
print(before)
print(after)
tf.Tensor([[-1.791]], shape=(1, 1), dtype=float32) tf.Tensor([[-1.791]], shape=(1, 1), dtype=float32)
tf.data ব্যবহার করে
পূর্ববর্তী বিভাগে আপনি মডেল প্রশিক্ষণের সময় মডেলের অন্তর্নির্মিত ডেটা শাফলিং এবং ব্যাচিংয়ের উপর নির্ভর করেছিলেন।
আপনার যদি ইনপুট ডেটা পাইপলাইনের উপর আরও নিয়ন্ত্রণের প্রয়োজন হয় বা এমন ডেটা ব্যবহার করার প্রয়োজন হয় যা সহজেই মেমরিতে ফিট হয় না: tf.data ব্যবহার করুন।
আরও উদাহরণের জন্য tf.data নির্দেশিকা দেখুন।
মেমরি ডেটাতে চালু
CSV ডেটাতে tf.data প্রয়োগের প্রথম উদাহরণ হিসাবে পূর্ববর্তী বিভাগ থেকে বৈশিষ্ট্যগুলির অভিধান ম্যানুয়ালি স্লাইস করতে নিম্নলিখিত কোডটি বিবেচনা করুন। প্রতিটি সূচকের জন্য, প্রতিটি বৈশিষ্ট্যের জন্য সেই সূচকটি লাগে:
import itertools
def slices(features):
for i in itertools.count():
# For each feature take index `i`
example = {name:values[i] for name, values in features.items()}
yield example
এটি চালান এবং প্রথম উদাহরণ মুদ্রণ করুন:
for example in slices(titanic_features_dict):
for name, value in example.items():
print(f"{name:19s}: {value}")
break
sex : male age : 22.0 n_siblings_spouses : 1 parch : 0 fare : 7.25 class : Third deck : unknown embark_town : Southampton alone : n
মেমরি ডেটা লোডারে সবচেয়ে মৌলিক tf.data.Dataset হল Dataset.from_tensor_slices কনস্ট্রাক্টর। এটি একটি tf.data.Dataset প্রদান করে যা TensorFlow-এ উপরের slices ফাংশনের একটি সাধারণ সংস্করণ প্রয়োগ করে।
features_ds = tf.data.Dataset.from_tensor_slices(titanic_features_dict)
আপনি একটি tf.data.Dataset উপর পুনরাবৃত্তি করতে পারেন অন্য যে কোন পাইথন পুনরাবৃত্তিযোগ্য:
for example in features_ds:
for name, value in example.items():
print(f"{name:19s}: {value}")
break
sex : b'male' age : 22.0 n_siblings_spouses : 1 parch : 0 fare : 7.25 class : b'Third' deck : b'unknown' embark_town : b'Southampton' alone : b'n'
from_tensor_slices ফাংশন নেস্টেড অভিধান বা টিপলগুলির যে কোনও কাঠামো পরিচালনা করতে পারে। নিম্নলিখিত কোডটি (features_dict, labels) জোড়াগুলির একটি ডেটাসেট তৈরি করে:
titanic_ds = tf.data.Dataset.from_tensor_slices((titanic_features_dict, titanic_labels))
এই Dataset ব্যবহার করে একটি মডেলকে প্রশিক্ষণ দিতে, আপনাকে অন্তত ডাটা shuffle এবং batch করতে হবে।
titanic_batches = titanic_ds.shuffle(len(titanic_labels)).batch(32)
Model.fit এ features এবং labels পাস করার পরিবর্তে, আপনি ডেটাসেট পাস করেন:
titanic_model.fit(titanic_batches, epochs=5)
Epoch 1/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4230 Epoch 2/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4216 Epoch 3/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4203 Epoch 4/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4198 Epoch 5/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4194 <keras.callbacks.History at 0x7f70b12485d0>
একটি একক ফাইল থেকে
এখন পর্যন্ত এই টিউটোরিয়াল ইন-মেমরি ডেটা নিয়ে কাজ করেছে। tf.data হল ডেটা পাইপলাইন তৈরির জন্য একটি অত্যন্ত স্কেলযোগ্য টুলকিট, এবং CSV ফাইল লোড করার জন্য কয়েকটি ফাংশন প্রদান করে।
titanic_file_path = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
Downloading data from https://storage.googleapis.com/tf-datasets/titanic/train.csv 32768/30874 [===============================] - 0s 0us/step 40960/30874 [=======================================] - 0s 0us/step
এখন ফাইল থেকে CSV ডেটা পড়ুন এবং একটি tf.data.Dataset তৈরি করুন।
(সম্পূর্ণ ডকুমেন্টেশনের জন্য, tf.data.experimental.make_csv_dataset দেখুন)
titanic_csv_ds = tf.data.experimental.make_csv_dataset(
titanic_file_path,
batch_size=5, # Artificially small to make examples easier to show.
label_name='survived',
num_epochs=1,
ignore_errors=True,)
এই ফাংশনটিতে অনেক সুবিধাজনক বৈশিষ্ট্য রয়েছে তাই ডেটার সাথে কাজ করা সহজ। এটা অন্তর্ভুক্ত:
- অভিধান কী হিসেবে কলাম হেডার ব্যবহার করা।
- স্বয়ংক্রিয়ভাবে প্রতিটি কলামের ধরন নির্ধারণ করা হচ্ছে।
for batch, label in titanic_csv_ds.take(1):
for key, value in batch.items():
print(f"{key:20s}: {value}")
print()
print(f"{'label':20s}: {label}")
sex : [b'male' b'male' b'female' b'male' b'male'] age : [27. 18. 15. 46. 50.] n_siblings_spouses : [0 0 0 1 0] parch : [0 0 0 0 0] fare : [ 7.896 7.796 7.225 61.175 13. ] class : [b'Third' b'Third' b'Third' b'First' b'Second'] deck : [b'unknown' b'unknown' b'unknown' b'E' b'unknown'] embark_town : [b'Southampton' b'Southampton' b'Cherbourg' b'Southampton' b'Southampton'] alone : [b'y' b'y' b'y' b'n' b'y'] label : [0 0 1 0 0]
এটি উড়তে থাকা ডেটাকে ডিকম্প্রেস করতে পারে। এখানে একটি জিজিপড CSV ফাইল রয়েছে যাতে মেট্রো আন্তঃরাজ্য ট্রাফিক ডেটাসেট রয়েছে৷

উইকিমিডিয়া থেকে ছবি
{kind=link}
traffic_volume_csv_gz = tf.keras.utils.get_file(
'Metro_Interstate_Traffic_Volume.csv.gz',
"https://archive.ics.uci.edu/ml/machine-learning-databases/00492/Metro_Interstate_Traffic_Volume.csv.gz",
cache_dir='.', cache_subdir='traffic')
Downloading data from https://archive.ics.uci.edu/ml/machine-learning-databases/00492/Metro_Interstate_Traffic_Volume.csv.gz 409600/405373 [==============================] - 1s 1us/step 417792/405373 [==============================] - 1s 1us/step
সংকুচিত ফাইল থেকে সরাসরি পড়তে compression_type আর্গুমেন্ট সেট করুন:
traffic_volume_csv_gz_ds = tf.data.experimental.make_csv_dataset(
traffic_volume_csv_gz,
batch_size=256,
label_name='traffic_volume',
num_epochs=1,
compression_type="GZIP")
for batch, label in traffic_volume_csv_gz_ds.take(1):
for key, value in batch.items():
print(f"{key:20s}: {value[:5]}")
print()
print(f"{'label':20s}: {label[:5]}")
holiday : [b'None' b'None' b'None' b'None' b'None'] temp : [280.56 266.79 281.64 292.71 270.48] rain_1h : [0. 0. 0. 0. 0.] snow_1h : [0. 0. 0. 0. 0.] clouds_all : [46 90 90 0 64] weather_main : [b'Clear' b'Clouds' b'Mist' b'Clear' b'Clouds'] weather_description : [b'sky is clear' b'overcast clouds' b'mist' b'Sky is Clear' b'broken clouds'] date_time : [b'2012-11-05 20:00:00' b'2012-12-17 23:00:00' b'2013-10-06 19:00:00' b'2013-08-23 22:00:00' b'2013-11-11 05:00:00'] label : [2415 966 3459 2633 2576]
ক্যাশিং
সিএসভি ডেটা পার্স করার জন্য কিছু ওভারহেড আছে। ছোট মডেলের জন্য এটি প্রশিক্ষণে বাধা হতে পারে।
আপনার ব্যবহারের ক্ষেত্রে নির্ভর করে Dataset.cache বা data.experimental.snapshot ব্যবহার করা একটি ভাল ধারণা হতে পারে যাতে csv ডেটা শুধুমাত্র প্রথম যুগে পার্স করা হয়।
cache এবং snapshot পদ্ধতির মধ্যে প্রধান পার্থক্য হল cache ফাইলগুলি শুধুমাত্র টেনসরফ্লো প্রক্রিয়া দ্বারা ব্যবহার করা যেতে পারে যা তাদের তৈরি করেছে, তবে snapshot ফাইলগুলি অন্যান্য প্রক্রিয়া দ্বারা পড়তে পারে।
উদাহরণস্বরূপ, 20 বার traffic_volume_csv_gz_ds -এর উপর পুনরাবৃত্তি করতে, ক্যাশিং ছাড়াই ~15 সেকেন্ড বা ক্যাশিং সহ ~2 সেকেন্ড সময় লাগে।
%%time
for i, (batch, label) in enumerate(traffic_volume_csv_gz_ds.repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
............................................................................................... CPU times: user 14.9 s, sys: 3.7 s, total: 18.6 s Wall time: 11.2 s
%%time
caching = traffic_volume_csv_gz_ds.cache().shuffle(1000)
for i, (batch, label) in enumerate(caching.shuffle(1000).repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
............................................................................................... CPU times: user 1.43 s, sys: 173 ms, total: 1.6 s Wall time: 1.28 s
%%time
snapshot = tf.data.experimental.snapshot('titanic.tfsnap')
snapshotting = traffic_volume_csv_gz_ds.apply(snapshot).shuffle(1000)
for i, (batch, label) in enumerate(snapshotting.shuffle(1000).repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
WARNING:tensorflow:From <timed exec>:1: snapshot (from tensorflow.python.data.experimental.ops.snapshot) is deprecated and will be removed in a future version. Instructions for updating: Use `tf.data.Dataset.snapshot(...)`. ............................................................................................... CPU times: user 2.17 s, sys: 460 ms, total: 2.63 s Wall time: 1.6 s
csv ফাইল লোড করার মাধ্যমে আপনার ডেটা লোডিং ধীর হয়ে গেলে এবং cache এবং snapshot আপনার ব্যবহারের ক্ষেত্রে অপর্যাপ্ত হলে, আপনার ডেটাকে আরও সুগমিত বিন্যাসে পুনরায় এনকোড করার কথা বিবেচনা করুন।
একাধিক ফাইল
এই বিভাগে এখন পর্যন্ত সমস্ত উদাহরণ tf.data ছাড়াই সহজে করা যেতে পারে। একটি জায়গা যেখানে tf.data জিনিসগুলিকে সত্যিই সহজ করতে পারে তা হল ফাইল সংগ্রহের সাথে কাজ করার সময়।
উদাহরণস্বরূপ, অক্ষর ফন্ট ইমেজ ডেটাসেট csv ফাইলের সংগ্রহ হিসাবে বিতরণ করা হয়, প্রতি ফন্টে একটি।

পিক্সাবে থেকে উইলি হাইডেলবাচের ছবি
ডেটাসেট ডাউনলোড করুন এবং ভিতরে থাকা ফাইলগুলি দেখুন:
fonts_zip = tf.keras.utils.get_file(
'fonts.zip', "https://archive.ics.uci.edu/ml/machine-learning-databases/00417/fonts.zip",
cache_dir='.', cache_subdir='fonts',
extract=True)
Downloading data from https://archive.ics.uci.edu/ml/machine-learning-databases/00417/fonts.zip 160317440/160313983 [==============================] - 8s 0us/step 160325632/160313983 [==============================] - 8s 0us/step
import pathlib
font_csvs = sorted(str(p) for p in pathlib.Path('fonts').glob("*.csv"))
font_csvs[:10]
['fonts/AGENCY.csv', 'fonts/ARIAL.csv', 'fonts/BAITI.csv', 'fonts/BANKGOTHIC.csv', 'fonts/BASKERVILLE.csv', 'fonts/BAUHAUS.csv', 'fonts/BELL.csv', 'fonts/BERLIN.csv', 'fonts/BERNARD.csv', 'fonts/BITSTREAMVERA.csv']
len(font_csvs)
153
একগুচ্ছ ফাইল নিয়ে কাজ করার সময় আপনি experimental.make_csv_dataset .make_csv_dataset ফাংশনে একটি গ্লোব-স্টাইল file_pattern পাস করতে পারেন। ফাইলের ক্রম প্রতিটি পুনরাবৃত্তির পরিবর্তন করা হয়.
সমান্তরাল এবং ইন্টারলিভড একসাথে কতগুলি ফাইল পড়া হবে তা সেট করতে num_parallel_reads আর্গুমেন্ট ব্যবহার করুন।
fonts_ds = tf.data.experimental.make_csv_dataset(
file_pattern = "fonts/*.csv",
batch_size=10, num_epochs=1,
num_parallel_reads=20,
shuffle_buffer_size=10000)
এই csv ফাইলগুলিতে ছবিগুলিকে একটি একক সারিতে সমতল করা হয়েছে৷ কলামের নামগুলি r{row}c{column} ফর্ম্যাট করা হয়েছে। এখানে প্রথম ব্যাচ:
for features in fonts_ds.take(1):
for i, (name, value) in enumerate(features.items()):
if i>15:
break
print(f"{name:20s}: {value}")
print('...')
print(f"[total: {len(features)} features]")
font : [b'HANDPRINT' b'NIAGARA' b'EUROROMAN' b'NIAGARA' b'CENTAUR' b'NINA' b'GOUDY' b'SITKA' b'BELL' b'SITKA'] fontVariant : [b'scanned' b'NIAGARA SOLID' b'EUROROMAN' b'NIAGARA SOLID' b'CENTAUR' b'NINA' b'GOUDY STOUT' b'SITKA TEXT' b'BELL MT' b'SITKA TEXT'] m_label : [ 49 8482 245 88 174 9643 77 974 117 339] strength : [0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4] italic : [0 0 0 1 0 0 1 0 1 0] orientation : [0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] m_top : [ 0 32 24 32 28 57 38 48 51 64] m_left : [ 0 20 24 20 22 24 27 23 25 23] originalH : [20 27 55 47 50 15 51 50 27 34] originalW : [ 4 33 25 33 50 15 116 43 28 53] h : [20 20 20 20 20 20 20 20 20 20] w : [20 20 20 20 20 20 20 20 20 20] r0c0 : [ 1 255 255 1 1 255 1 1 1 1] r0c1 : [ 1 255 255 1 1 255 1 1 1 1] r0c2 : [ 1 217 255 1 1 255 54 1 1 1] r0c3 : [ 1 213 255 1 1 255 255 1 1 64] ... [total: 412 features]
ঐচ্ছিক: প্যাকিং ক্ষেত্র
আপনি সম্ভবত এই মত পৃথক কলামে প্রতিটি পিক্সেলের সাথে কাজ করতে চান না। এই ডেটাসেট ব্যবহার করার চেষ্টা করার আগে একটি ইমেজ-টেনসরে পিক্সেল প্যাক করতে ভুলবেন না।
এখানে এমন কোড রয়েছে যা প্রতিটি উদাহরণের জন্য ছবি তৈরি করতে কলামের নাম পার্স করে:
import re
def make_images(features):
image = [None]*400
new_feats = {}
for name, value in features.items():
match = re.match('r(\d+)c(\d+)', name)
if match:
image[int(match.group(1))*20+int(match.group(2))] = value
else:
new_feats[name] = value
image = tf.stack(image, axis=0)
image = tf.reshape(image, [20, 20, -1])
new_feats['image'] = image
return new_feats
ডেটাসেটের প্রতিটি ব্যাচে সেই ফাংশনটি প্রয়োগ করুন:
fonts_image_ds = fonts_ds.map(make_images)
for features in fonts_image_ds.take(1):
break
ফলস্বরূপ চিত্রগুলি প্লট করুন:
from matplotlib import pyplot as plt
plt.figure(figsize=(6,6), dpi=120)
for n in range(9):
plt.subplot(3,3,n+1)
plt.imshow(features['image'][..., n])
plt.title(chr(features['m_label'][n]))
plt.axis('off')

নিম্ন স্তরের ফাংশন
এখন পর্যন্ত এই টিউটোরিয়ালটি csv ডেটা পড়ার জন্য সর্বোচ্চ স্তরের ইউটিলিটিগুলির উপর দৃষ্টি নিবদ্ধ করেছে। আপনার ব্যবহারের ক্ষেত্রে মৌলিক প্যাটার্নের সাথে মানানসই না হলে উন্নত ব্যবহারকারীদের জন্য সহায়ক হতে পারে এমন আরও দুটি API আছে।
-
tf.io.decode_csv- CSV কলাম টেনসরের একটি তালিকায় পাঠ্যের লাইন পার্স করার জন্য একটি ফাংশন। -
tf.data.experimental.CsvDataset- একটি নিম্ন স্তরের csv ডেটাসেট কনস্ট্রাক্টর।
নিম্ন স্তরের কার্যকারিতা কীভাবে ব্যবহার করা যেতে পারে তা প্রদর্শন করতে এই বিভাগটি make_csv_dataset দ্বারা প্রদত্ত কার্যকারিতা পুনরায় তৈরি করে।
tf.io.decode_csv
এই ফাংশনটি একটি স্ট্রিং বা স্ট্রিংগুলির তালিকাকে কলামের তালিকায় ডিকোড করে।
make_csv_dataset বিপরীতে এই ফাংশনটি কলাম ডেটা-টাইপ অনুমান করার চেষ্টা করে না। আপনি প্রতিটি কলামের জন্য সঠিক প্রকারের একটি মান ধারণকারী record_defaults একটি তালিকা প্রদান করে কলামের প্রকারগুলি নির্দিষ্ট করুন৷
decode_csv ব্যবহার করে টাইটানিক ডেটা স্ট্রিং হিসাবে পড়তে আপনি বলবেন:
text = pathlib.Path(titanic_file_path).read_text()
lines = text.split('\n')[1:-1]
all_strings = [str()]*10
all_strings
['', '', '', '', '', '', '', '', '', '']
features = tf.io.decode_csv(lines, record_defaults=all_strings)
for f in features:
print(f"type: {f.dtype.name}, shape: {f.shape}")
type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,)
তাদের প্রকৃত প্রকারের সাথে পার্স করতে, সংশ্লিষ্ট প্রকারের record_defaults একটি তালিকা তৈরি করুন:
print(lines[0])
0,male,22.0,1,0,7.25,Third,unknown,Southampton,n
titanic_types = [int(), str(), float(), int(), int(), float(), str(), str(), str(), str()]
titanic_types
[0, '', 0.0, 0, 0, 0.0, '', '', '', '']
features = tf.io.decode_csv(lines, record_defaults=titanic_types)
for f in features:
print(f"type: {f.dtype.name}, shape: {f.shape}")
type: int32, shape: (627,) type: string, shape: (627,) type: float32, shape: (627,) type: int32, shape: (627,) type: int32, shape: (627,) type: float32, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,)
tf.data.experimental.CsvDataset
tf.data.experimental.CsvDataset ক্লাস make_csv_dataset ফাংশনের সুবিধার বৈশিষ্ট্য ছাড়াই একটি ন্যূনতম CSV Dataset ইন্টারফেস প্রদান করে: কলাম হেডার পার্সিং, কলাম টাইপ-ইনফারেন্স, স্বয়ংক্রিয় শাফলিং, ফাইল ইন্টারলিভিং।
এই কনস্ট্রাক্টর অনুসরণ করে record_defaults io.parse_csv করে:
simple_titanic = tf.data.experimental.CsvDataset(titanic_file_path, record_defaults=titanic_types, header=True)
for example in simple_titanic.take(1):
print([e.numpy() for e in example])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n']
উপরের কোডটি মূলত এর সমতুল্য:
def decode_titanic_line(line):
return tf.io.decode_csv(line, titanic_types)
manual_titanic = (
# Load the lines of text
tf.data.TextLineDataset(titanic_file_path)
# Skip the header row.
.skip(1)
# Decode the line.
.map(decode_titanic_line)
)
for example in manual_titanic.take(1):
print([e.numpy() for e in example])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n']
একাধিক ফাইল
experimental.CsvDataset .CsvDataset ব্যবহার করে ফন্ট ডেটাসেট পার্স করতে, আপনাকে প্রথমে record_defaults এর জন্য কলামের ধরন নির্ধারণ করতে হবে। একটি ফাইলের প্রথম সারি পরিদর্শন করে শুরু করুন:
font_line = pathlib.Path(font_csvs[0]).read_text().splitlines()[1]
print(font_line)
AGENCY,AGENCY FB,64258,0.400000,0,0.000000,35,21,51,22,20,20,1,1,1,21,101,210,255,255,255,255,255,255,255,255,255,255,255,255,255,255,1,1,1,93,255,255,255,176,146,146,146,146,146,146,146,146,216,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,141,141,141,182,255,255,255,172,141,141,141,115,1,1,1,1,163,255,255,255,255,255,255,255,255,255,255,255,255,255,255,209,1,1,1,1,163,255,255,255,6,6,6,96,255,255,255,74,6,6,6,5,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255
শুধুমাত্র প্রথম দুটি ক্ষেত্র হল স্ট্রিং, বাকিগুলি হল ints বা floats, এবং আপনি কমাগুলি গণনা করে মোট বৈশিষ্ট্যগুলি পেতে পারেন:
num_font_features = font_line.count(',')+1
font_column_types = [str(), str()] + [float()]*(num_font_features-2)
CsvDatasaet কনস্ট্রাক্টর ইনপুট ফাইলগুলির একটি তালিকা নিতে পারে, কিন্তু সেগুলিকে ক্রমানুসারে পড়তে পারে। CSV-এর তালিকার প্রথম ফাইলটি হল AGENCY.csv :
font_csvs[0]
'fonts/AGENCY.csv'
তাই যখন আপনি CsvDataaset-এ ফাইলগুলির তালিকা পাস করেন তখন CsvDataaset থেকে AGENCY.csv প্রথমে পড়া হয়:
simple_font_ds = tf.data.experimental.CsvDataset(
font_csvs,
record_defaults=font_column_types,
header=True)
for row in simple_font_ds.take(10):
print(row[0].numpy())
b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY'
একাধিক ফাইল ইন্টারলিভ করতে, Dataset.interleave ব্যবহার করুন।
এখানে একটি প্রাথমিক ডেটাসেট রয়েছে যাতে csv ফাইলের নাম রয়েছে:
font_files = tf.data.Dataset.list_files("fonts/*.csv")
এটি প্রতিটি যুগের ফাইলের নাম পরিবর্তন করে:
print('Epoch 1:')
for f in list(font_files)[:5]:
print(" ", f.numpy())
print(' ...')
print()
print('Epoch 2:')
for f in list(font_files)[:5]:
print(" ", f.numpy())
print(' ...')
Epoch 1:
b'fonts/CORBEL.csv'
b'fonts/GLOUCESTER.csv'
b'fonts/GABRIOLA.csv'
b'fonts/FORTE.csv'
b'fonts/GILL.csv'
...
Epoch 2:
b'fonts/MONEY.csv'
b'fonts/ISOC.csv'
b'fonts/DUTCH801.csv'
b'fonts/CALIBRI.csv'
b'fonts/ROMANTIC.csv'
...
interleave পদ্ধতিটি একটি map_func নেয় যা পিতামাতার প্রতিটি উপাদানের জন্য একটি শিশু- Dataset তৈরি করে- Dataset ।
এখানে, আপনি ফাইলের ডেটাসেটের প্রতিটি উপাদান থেকে একটি CsvDataset তৈরি করতে চান:
def make_font_csv_ds(path):
return tf.data.experimental.CsvDataset(
path,
record_defaults=font_column_types,
header=True)
ইন্টারলিভ দ্বারা প্রত্যাবর্তিত Dataset অনেকগুলি শিশুর উপর সাইকেল চালিয়ে উপাদানগুলি ফিরিয়ে দেয়- Dataset ৷ নিচে উল্লেখ্য, কিভাবে ডেটাসেট cycle_length=3 তিনটি ফন্ট ফাইলের উপর সাইকেল করে:
font_rows = font_files.interleave(make_font_csv_ds,
cycle_length=3)
fonts_dict = {'font_name':[], 'character':[]}
for row in font_rows.take(10):
fonts_dict['font_name'].append(row[0].numpy().decode())
fonts_dict['character'].append(chr(row[2].numpy()))
pd.DataFrame(fonts_dict)
কর্মক্ষমতা
এর আগে, এটি উল্লেখ করা হয়েছিল যে io.decode_csv স্ট্রিংগুলির একটি ব্যাচে চালানোর সময় আরও কার্যকর।
CSV লোডিং পারফরম্যান্স উন্নত করার জন্য, বড় ব্যাচের মাপ ব্যবহার করার সময় এই সত্যটির সুবিধা নেওয়া সম্ভব (তবে প্রথমে ক্যাশে করার চেষ্টা করুন)।
অন্তর্নির্মিত লোডার 20 সহ, 2048- উদাহরণ ব্যাচগুলি প্রায় 17 সেকেন্ড সময় নেয়।
BATCH_SIZE=2048
fonts_ds = tf.data.experimental.make_csv_dataset(
file_pattern = "fonts/*.csv",
batch_size=BATCH_SIZE, num_epochs=1,
num_parallel_reads=100)
%%time
for i,batch in enumerate(fonts_ds.take(20)):
print('.',end='')
print()
.................... CPU times: user 24.3 s, sys: 1.46 s, total: 25.7 s Wall time: 10.9 s
decode_csv পাঠ্য লাইনের ব্যাচগুলি পাস করা দ্রুত চলে, প্রায় 5 সেকেন্ডে:
fonts_files = tf.data.Dataset.list_files("fonts/*.csv")
fonts_lines = fonts_files.interleave(
lambda fname:tf.data.TextLineDataset(fname).skip(1),
cycle_length=100).batch(BATCH_SIZE)
fonts_fast = fonts_lines.map(lambda x: tf.io.decode_csv(x, record_defaults=font_column_types))
%%time
for i,batch in enumerate(fonts_fast.take(20)):
print('.',end='')
print()
.................... CPU times: user 8.77 s, sys: 0 ns, total: 8.77 s Wall time: 1.57 s
বড় ব্যাচ ব্যবহার করে CSV কর্মক্ষমতা বাড়ানোর আরেকটি উদাহরণের জন্য ওভারফিট এবং আন্ডারফিট টিউটোরিয়ালটি দেখুন।
এই ধরণের পদ্ধতি কাজ করতে পারে, তবে cache এবং snapshot বা আপনার ডেটাকে আরও সুগমিত বিন্যাসে পুনরায় এনকোড করার মত অন্যান্য বিকল্পগুলি বিবেচনা করুন৷