
| | |  GitHub-এ উৎস দেখুন GitHub-এ উৎস দেখুন |
এই টিউটোরিয়ালটি টেনসরফ্লো ব্যবহার করে সময় সিরিজের পূর্বাভাসের একটি ভূমিকা। এটি কনভোলিউশনাল এবং রিকারেন্ট নিউরাল নেটওয়ার্ক (সিএনএন এবং আরএনএন) সহ কয়েকটি ভিন্ন শৈলীর মডেল তৈরি করে।
এটি উপধারা সহ দুটি প্রধান অংশে আচ্ছাদিত:
- একক সময়ের জন্য পূর্বাভাস:
- একটি একক বৈশিষ্ট্য।
- সমস্ত বৈশিষ্ট্য.
- একাধিক ধাপ পূর্বাভাস:
- একক শট: একযোগে ভবিষ্যদ্বাণী করুন।
- অটোরিগ্রেসিভ: একবারে একটি ভবিষ্যদ্বাণী করুন এবং আউটপুটটিকে মডেলে ফিরিয়ে দিন।
সেটআপ
import os
import datetime
import IPython
import IPython.display
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
import tensorflow as tf
mpl.rcParams['figure.figsize'] = (8, 6)
mpl.rcParams['axes.grid'] = False
আবহাওয়া ডেটাসেট
এই টিউটোরিয়ালটি বায়োজিওকেমিস্ট্রির জন্য ম্যাক্স প্ল্যাঙ্ক ইনস্টিটিউট দ্বারা রেকর্ড করা একটি আবহাওয়ার সময় সিরিজ ডেটাসেট ব্যবহার করে।
এই ডেটাসেটে 14টি ভিন্ন বৈশিষ্ট্য রয়েছে যেমন বায়ুর তাপমাত্রা, বায়ুমণ্ডলীয় চাপ এবং আর্দ্রতা। এগুলি প্রতি 10 মিনিটে সংগ্রহ করা হয়েছিল, 2003 থেকে শুরু হয়েছিল৷ দক্ষতার জন্য, আপনি শুধুমাত্র 2009 থেকে 2016 সালের মধ্যে সংগৃহীত ডেটা ব্যবহার করবেন৷ ডেটাসেটের এই বিভাগটি ফ্রাঁসোয়া চোলেট তার বই ডিপ লার্নিং উইথ পাইথনের জন্য প্রস্তুত করেছিলেন৷
zip_path = tf.keras.utils.get_file(
origin='https://storage.googleapis.com/tensorflow/tf-keras-datasets/jena_climate_2009_2016.csv.zip',
fname='jena_climate_2009_2016.csv.zip',
extract=True)
csv_path, _ = os.path.splitext(zip_path)
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/jena_climate_2009_2016.csv.zip 13574144/13568290 [==============================] - 1s 0us/step 13582336/13568290 [==============================] - 1s 0us/step
এই টিউটোরিয়ালটি কেবল প্রতি ঘণ্টার ভবিষ্যদ্বাণী নিয়ে কাজ করবে, তাই 10-মিনিটের ব্যবধান থেকে এক-ঘণ্টার ব্যবধানে ডেটা সাব-স্যাম্পল করে শুরু করুন:
df = pd.read_csv(csv_path)
# Slice [start:stop:step], starting from index 5 take every 6th record.
df = df[5::6]
date_time = pd.to_datetime(df.pop('Date Time'), format='%d.%m.%Y %H:%M:%S')
এক নজরে দেখে নেওয়া যাক ডেটা। এখানে প্রথম কয়েকটি সারি রয়েছে:
df.head()
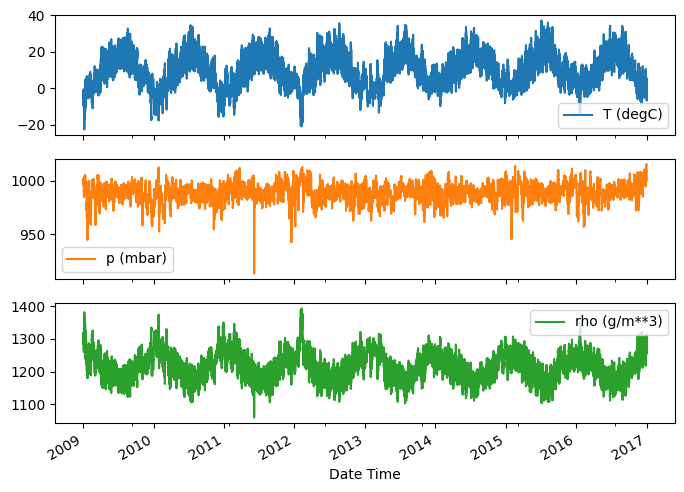
এখানে সময়ের সাথে সাথে কয়েকটি বৈশিষ্ট্যের বিবর্তন রয়েছে:
plot_cols = ['T (degC)', 'p (mbar)', 'rho (g/m**3)']
plot_features = df[plot_cols]
plot_features.index = date_time
_ = plot_features.plot(subplots=True)
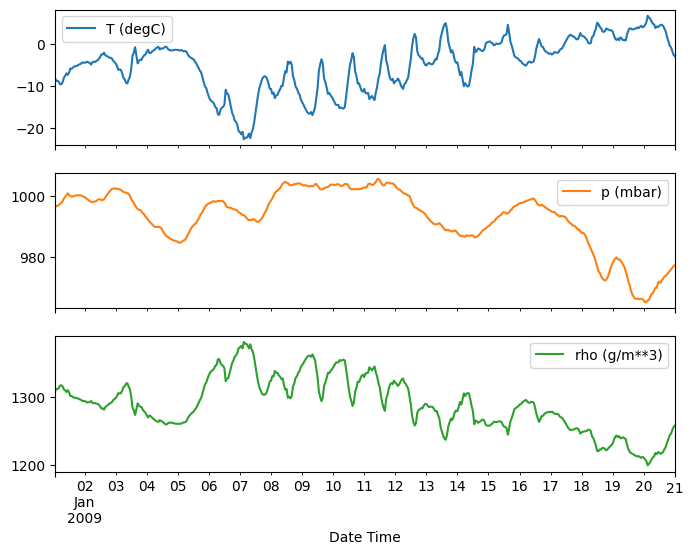
plot_features = df[plot_cols][:480]
plot_features.index = date_time[:480]
_ = plot_features.plot(subplots=True)
পরিদর্শন এবং পরিষ্কার করা
এরপরে, ডেটাসেটের পরিসংখ্যান দেখুন:
df.describe().transpose()
বাতাসের বেগ
একটি জিনিস যা আলাদা হওয়া উচিত তা হল বাতাসের বেগের min মান ( wv (m/s) ) এবং সর্বাধিক মান ( max. wv (m/s) ) কলাম৷ এই -9999 সম্ভবত ভুল.
একটি পৃথক বায়ু দিক কলাম আছে, তাই বেগ শূন্য ( >=0 ) এর চেয়ে বেশি হওয়া উচিত। এটিকে শূন্য দিয়ে প্রতিস্থাপন করুন:
wv = df['wv (m/s)']
bad_wv = wv == -9999.0
wv[bad_wv] = 0.0
max_wv = df['max. wv (m/s)']
bad_max_wv = max_wv == -9999.0
max_wv[bad_max_wv] = 0.0
# The above inplace edits are reflected in the DataFrame.
df['wv (m/s)'].min()
0.0
ফিচার ইঞ্জিনিয়ারিং
একটি মডেল তৈরি করতে ডাইভিং করার আগে, আপনার ডেটা বোঝা গুরুত্বপূর্ণ এবং নিশ্চিত হন যে আপনি মডেলটিকে যথাযথভাবে ফর্ম্যাট করা ডেটা পাস করছেন৷
বায়ু
ডেটার শেষ কলাম, wd (deg) — ডিগ্রীর এককে বাতাসের দিক নির্দেশ করে। কোণগুলি ভাল মডেল ইনপুট তৈরি করে না: 360° এবং 0° একে অপরের কাছাকাছি হওয়া উচিত এবং মসৃণভাবে মোড়ানো উচিত। বাতাস প্রবাহিত না হলে দিকনির্দেশ করা উচিত নয়।
এই মুহূর্তে বায়ু তথ্য বিতরণ এই মত দেখায়:
plt.hist2d(df['wd (deg)'], df['wv (m/s)'], bins=(50, 50), vmax=400)
plt.colorbar()
plt.xlabel('Wind Direction [deg]')
plt.ylabel('Wind Velocity [m/s]')
Text(0, 0.5, 'Wind Velocity [m/s]')
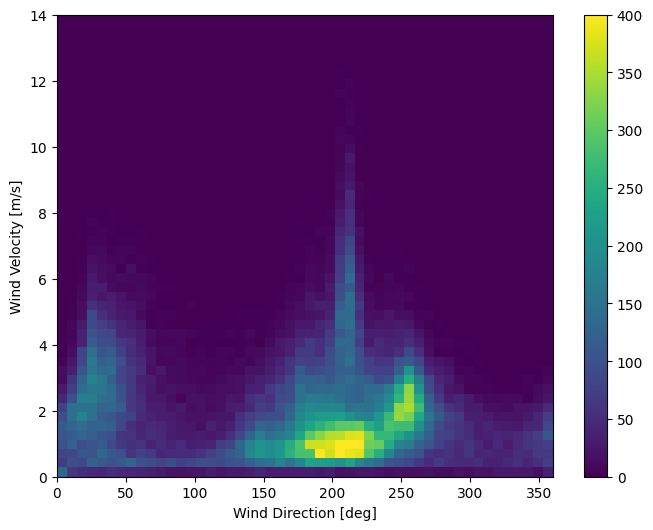
কিন্তু আপনি যদি বাতাসের দিক এবং বেগ কলামগুলিকে একটি বায়ু ভেক্টরে রূপান্তর করেন তবে মডেলটির পক্ষে ব্যাখ্যা করা সহজ হবে:
wv = df.pop('wv (m/s)')
max_wv = df.pop('max. wv (m/s)')
# Convert to radians.
wd_rad = df.pop('wd (deg)')*np.pi / 180
# Calculate the wind x and y components.
df['Wx'] = wv*np.cos(wd_rad)
df['Wy'] = wv*np.sin(wd_rad)
# Calculate the max wind x and y components.
df['max Wx'] = max_wv*np.cos(wd_rad)
df['max Wy'] = max_wv*np.sin(wd_rad)
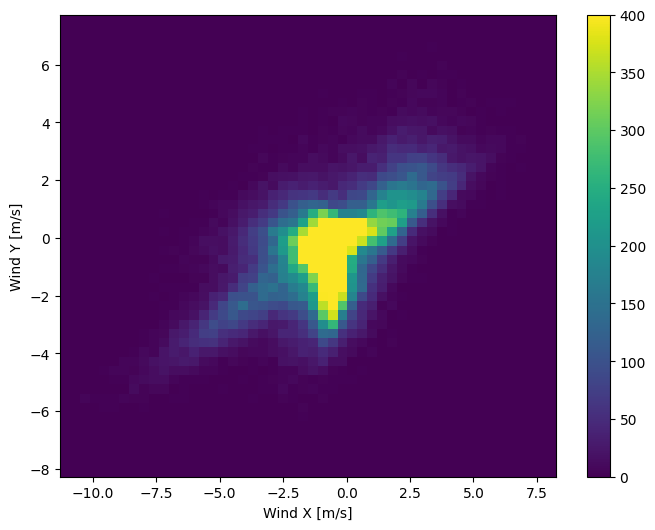
মডেলের সঠিকভাবে ব্যাখ্যা করার জন্য বায়ু ভেক্টরের বিতরণ অনেক সহজ:
plt.hist2d(df['Wx'], df['Wy'], bins=(50, 50), vmax=400)
plt.colorbar()
plt.xlabel('Wind X [m/s]')
plt.ylabel('Wind Y [m/s]')
ax = plt.gca()
ax.axis('tight')
(-11.305513973134667, 8.24469928549079, -8.27438540335515, 7.7338312955467785)
সময়
একইভাবে, Date Time কলাম খুব দরকারী, কিন্তু এই স্ট্রিং আকারে নয়। এটিকে সেকেন্ডে রূপান্তর করে শুরু করুন:
timestamp_s = date_time.map(pd.Timestamp.timestamp)
বাতাসের দিক অনুরূপ, সেকেন্ডের সময় একটি দরকারী মডেল ইনপুট নয়। আবহাওয়ার তথ্য হওয়ায়, এটিতে স্পষ্ট দৈনিক এবং বার্ষিক পর্যায়ক্রমিকতা রয়েছে। আপনি পর্যায়ক্রমিকতা মোকাবেলা করতে পারেন অনেক উপায় আছে.
আপনি "দিনের সময়" এবং "বছরের সময়" সংকেত পরিষ্কার করতে সাইন এবং কোসাইন রূপান্তর ব্যবহার করে ব্যবহারযোগ্য সংকেত পেতে পারেন:
day = 24*60*60
year = (365.2425)*day
df['Day sin'] = np.sin(timestamp_s * (2 * np.pi / day))
df['Day cos'] = np.cos(timestamp_s * (2 * np.pi / day))
df['Year sin'] = np.sin(timestamp_s * (2 * np.pi / year))
df['Year cos'] = np.cos(timestamp_s * (2 * np.pi / year))
plt.plot(np.array(df['Day sin'])[:25])
plt.plot(np.array(df['Day cos'])[:25])
plt.xlabel('Time [h]')
plt.title('Time of day signal')
Text(0.5, 1.0, 'Time of day signal')
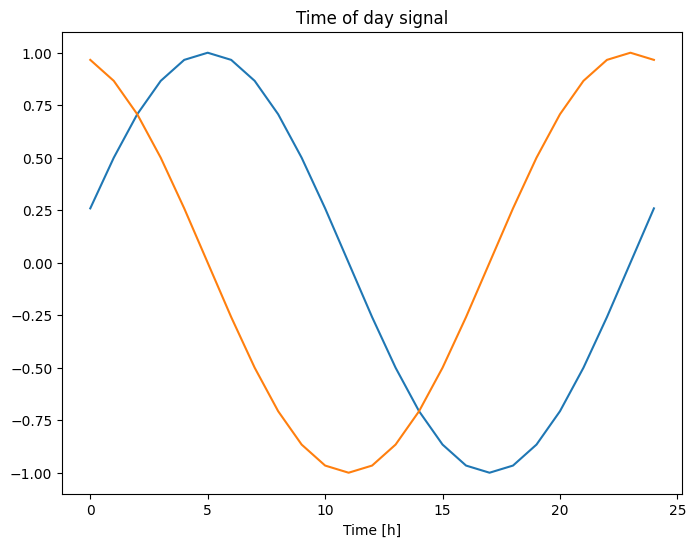
এটি মডেলটিকে সবচেয়ে গুরুত্বপূর্ণ ফ্রিকোয়েন্সি বৈশিষ্ট্যগুলিতে অ্যাক্সেস দেয়। এই ক্ষেত্রে আপনি সময়ের আগে জানতেন কোন ফ্রিকোয়েন্সিগুলি গুরুত্বপূর্ণ।
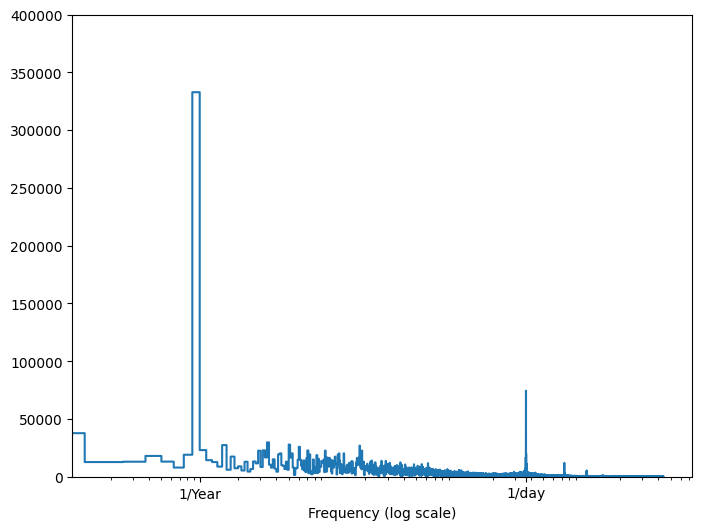
আপনার কাছে সেই তথ্য না থাকলে, আপনি ফাস্ট ফুরিয়ার ট্রান্সফর্মের সাথে বৈশিষ্ট্যগুলি বের করে কোন ফ্রিকোয়েন্সিগুলি গুরুত্বপূর্ণ তা নির্ধারণ করতে পারেন৷ অনুমানগুলি পরীক্ষা করার জন্য, এখানে সময়ের সাথে তাপমাত্রার tf.signal.rfft রয়েছে৷ 1/year এবং 1/day কাছাকাছি ফ্রিকোয়েন্সিতে সুস্পষ্ট শিখরগুলি লক্ষ্য করুন:
fft = tf.signal.rfft(df['T (degC)'])
f_per_dataset = np.arange(0, len(fft))
n_samples_h = len(df['T (degC)'])
hours_per_year = 24*365.2524
years_per_dataset = n_samples_h/(hours_per_year)
f_per_year = f_per_dataset/years_per_dataset
plt.step(f_per_year, np.abs(fft))
plt.xscale('log')
plt.ylim(0, 400000)
plt.xlim([0.1, max(plt.xlim())])
plt.xticks([1, 365.2524], labels=['1/Year', '1/day'])
_ = plt.xlabel('Frequency (log scale)')
ডেটা বিভক্ত করুন
আপনি প্রশিক্ষণ, বৈধতা এবং পরীক্ষার সেটের জন্য একটি (70%, 20%, 10%) বিভক্ত ব্যবহার করবেন। মনে রাখবেন ডেটা বিভক্ত করার আগে এলোমেলোভাবে এলোমেলোভাবে পরিবর্তন করা হচ্ছে না । এটি দুটি কারণে:
- এটি নিশ্চিত করে যে পরপর নমুনার উইন্ডোতে ডেটা কাটা এখনও সম্ভব।
- এটি নিশ্চিত করে যে বৈধতা/পরীক্ষার ফলাফলগুলি আরও বাস্তবসম্মত, মডেল প্রশিক্ষণের পরে সংগৃহীত ডেটার উপর মূল্যায়ন করা হচ্ছে।
column_indices = {name: i for i, name in enumerate(df.columns)}
n = len(df)
train_df = df[0:int(n*0.7)]
val_df = df[int(n*0.7):int(n*0.9)]
test_df = df[int(n*0.9):]
num_features = df.shape[1]
ডেটা স্বাভাবিক করুন
একটি নিউরাল নেটওয়ার্ক প্রশিক্ষণের আগে বৈশিষ্ট্যগুলি স্কেল করা গুরুত্বপূর্ণ। সাধারণীকরণ এই স্কেলিং করার একটি সাধারণ উপায়: গড় বিয়োগ করুন এবং প্রতিটি বৈশিষ্ট্যের আদর্শ বিচ্যুতি দ্বারা ভাগ করুন।
গড় এবং মানক বিচ্যুতি শুধুমাত্র প্রশিক্ষণ ডেটা ব্যবহার করে গণনা করা উচিত যাতে মডেলগুলির বৈধতা এবং পরীক্ষার সেটের মানগুলিতে কোনও অ্যাক্সেস না থাকে।
এটিও তর্কযোগ্য যে প্রশিক্ষণের সময় মডেলটির প্রশিক্ষণ সেটে ভবিষ্যত মানগুলিতে অ্যাক্সেস থাকা উচিত নয় এবং এই স্বাভাবিককরণটি চলমান গড় ব্যবহার করে করা উচিত। এটি এই টিউটোরিয়ালের ফোকাস নয়, এবং যাচাইকরণ এবং পরীক্ষার সেটগুলি নিশ্চিত করে যে আপনি (কিছুটা) সৎ মেট্রিক্স পেয়েছেন। সুতরাং, সরলতার স্বার্থে এই টিউটোরিয়ালটি একটি সাধারণ গড় ব্যবহার করে।
train_mean = train_df.mean()
train_std = train_df.std()
train_df = (train_df - train_mean) / train_std
val_df = (val_df - train_mean) / train_std
test_df = (test_df - train_mean) / train_std
এখন, বৈশিষ্ট্যগুলির বিতরণে উঁকি দিন। কিছু বৈশিষ্ট্যের লম্বা লেজ আছে, কিন্তু -9999 বায়ু বেগ মান মত কোন স্পষ্ট ত্রুটি নেই।
df_std = (df - train_mean) / train_std
df_std = df_std.melt(var_name='Column', value_name='Normalized')
plt.figure(figsize=(12, 6))
ax = sns.violinplot(x='Column', y='Normalized', data=df_std)
_ = ax.set_xticklabels(df.keys(), rotation=90)

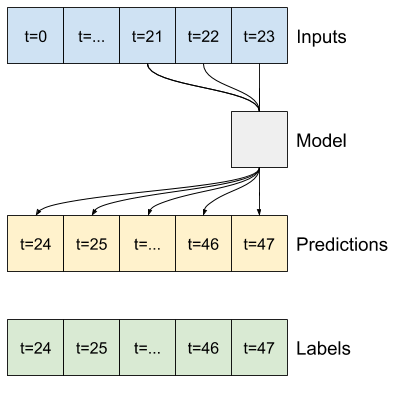
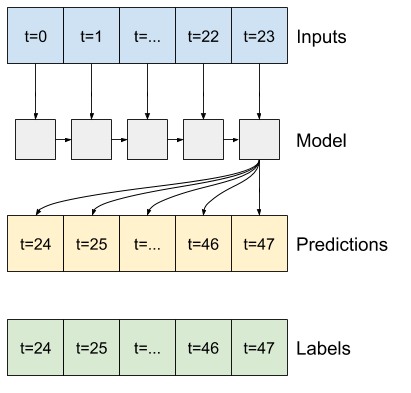
তথ্য জানালা
এই টিউটোরিয়ালের মডেলগুলি ডেটা থেকে ধারাবাহিক নমুনার একটি উইন্ডোর উপর ভিত্তি করে ভবিষ্যদ্বাণীগুলির একটি সেট তৈরি করবে।
ইনপুট উইন্ডোগুলির প্রধান বৈশিষ্ট্যগুলি হল:
- ইনপুট এবং লেবেল উইন্ডোর প্রস্থ (সময় ধাপের সংখ্যা)।
- তাদের মধ্যে সময় অফসেট.
- কোন বৈশিষ্ট্যগুলি ইনপুট, লেবেল বা উভয় হিসাবে ব্যবহৃত হয়।
এই টিউটোরিয়ালটি বিভিন্ন মডেল তৈরি করে (লিনিয়ার, ডিএনএন, সিএনএন এবং আরএনএন মডেল সহ), এবং উভয়ের জন্য সেগুলি ব্যবহার করে:
- একক-আউটপুট , এবং বহু-আউটপুট পূর্বাভাস।
- একক-সময়-পদক্ষেপ এবং বহু-সময়-পদক্ষেপের পূর্বাভাস।
এই বিভাগটি ডেটা উইন্ডোজ বাস্তবায়নের উপর ফোকাস করে যাতে এটি সেই সমস্ত মডেলের জন্য পুনরায় ব্যবহার করা যায়।
টাস্ক এবং মডেলের ধরণের উপর নির্ভর করে আপনি বিভিন্ন ডেটা উইন্ডো তৈরি করতে চাইতে পারেন। এখানে কিছু উদাহরন:
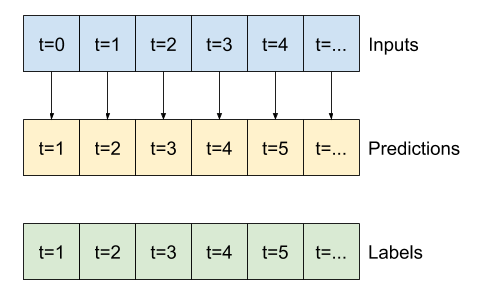
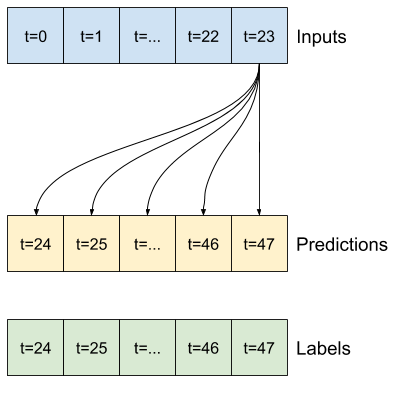
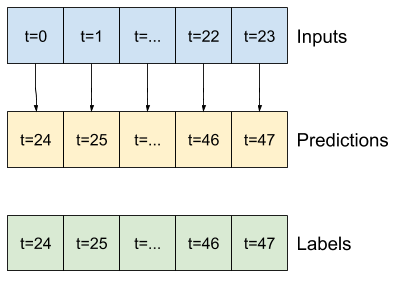
উদাহরণস্বরূপ, ইতিহাসের 24 ঘন্টা দেওয়া, ভবিষ্যতে 24 ঘন্টা একটি একক ভবিষ্যদ্বাণী করতে, আপনি এই মত একটি উইন্ডো সংজ্ঞায়িত করতে পারেন:
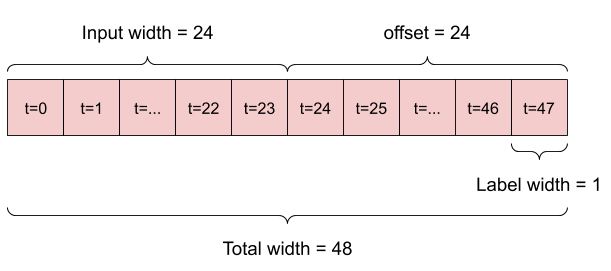
একটি মডেল যা ভবিষ্যৎবাণী করে এক ঘণ্টার ভবিষ্যতবাণী করে, ছয় ঘণ্টার ইতিহাস দেওয়া, তার জন্য এইরকম একটি উইন্ডোর প্রয়োজন হবে:

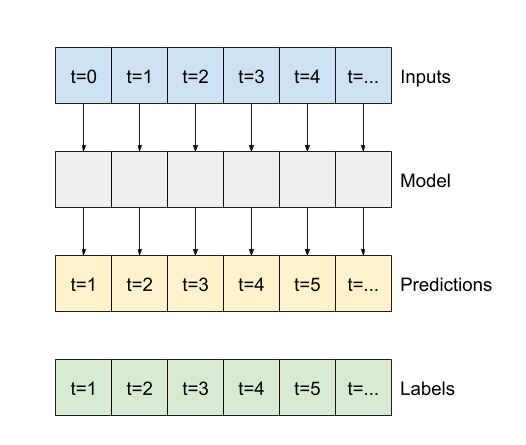
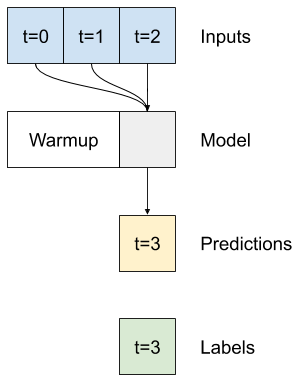
এই বিভাগের বাকি অংশ একটি WindowGenerator ক্লাস সংজ্ঞায়িত করে। এই ক্লাস করতে পারে:
- উপরের চিত্রে দেখানো হিসাবে সূচী এবং অফসেটগুলি পরিচালনা করুন।
- বৈশিষ্ট্যের উইন্ডোগুলিকে
(features, labels)জোড়ায় বিভক্ত করুন। - ফলস্বরূপ উইন্ডোগুলির বিষয়বস্তু প্লট করুন।
-
tf.data.Datasets ব্যবহার করে প্রশিক্ষণ, মূল্যায়ন এবং পরীক্ষার ডেটা থেকে দক্ষতার সাথে এই উইন্ডোগুলির ব্যাচগুলি তৈরি করুন।
1. সূচক এবং অফসেট
WindowGenerator ক্লাস তৈরি করে শুরু করুন। __init__ পদ্ধতিতে ইনপুট এবং লেবেল সূচকের জন্য প্রয়োজনীয় সমস্ত যুক্তি অন্তর্ভুক্ত রয়েছে।
এটি ইনপুট হিসাবে প্রশিক্ষণ, মূল্যায়ন এবং পরীক্ষা ডেটাফ্রেমগুলিও নেয়। এগুলো পরে উইন্ডোজের tf.data.Dataset s-এ রূপান্তরিত হবে।
class WindowGenerator():
def __init__(self, input_width, label_width, shift,
train_df=train_df, val_df=val_df, test_df=test_df,
label_columns=None):
# Store the raw data.
self.train_df = train_df
self.val_df = val_df
self.test_df = test_df
# Work out the label column indices.
self.label_columns = label_columns
if label_columns is not None:
self.label_columns_indices = {name: i for i, name in
enumerate(label_columns)}
self.column_indices = {name: i for i, name in
enumerate(train_df.columns)}
# Work out the window parameters.
self.input_width = input_width
self.label_width = label_width
self.shift = shift
self.total_window_size = input_width + shift
self.input_slice = slice(0, input_width)
self.input_indices = np.arange(self.total_window_size)[self.input_slice]
self.label_start = self.total_window_size - self.label_width
self.labels_slice = slice(self.label_start, None)
self.label_indices = np.arange(self.total_window_size)[self.labels_slice]
def __repr__(self):
return '\n'.join([
f'Total window size: {self.total_window_size}',
f'Input indices: {self.input_indices}',
f'Label indices: {self.label_indices}',
f'Label column name(s): {self.label_columns}'])
এই বিভাগের শুরুতে ডায়াগ্রামে দেখানো 2টি উইন্ডো তৈরি করার জন্য এখানে কোড রয়েছে:
w1 = WindowGenerator(input_width=24, label_width=1, shift=24,
label_columns=['T (degC)'])
w1
Total window size: 48 Input indices: [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23] Label indices: [47] Label column name(s): ['T (degC)']
w2 = WindowGenerator(input_width=6, label_width=1, shift=1,
label_columns=['T (degC)'])
w2
Total window size: 7 Input indices: [0 1 2 3 4 5] Label indices: [6] Label column name(s): ['T (degC)']
2. বিভক্ত
পরপর ইনপুটগুলির একটি তালিকা দেওয়া হলে, split_window পদ্ধতিটি সেগুলিকে ইনপুটগুলির একটি উইন্ডো এবং লেবেলের একটি উইন্ডোতে রূপান্তর করবে৷
উদাহরণ w2 আপনি আগে সংজ্ঞায়িত এই মত বিভক্ত করা হবে:
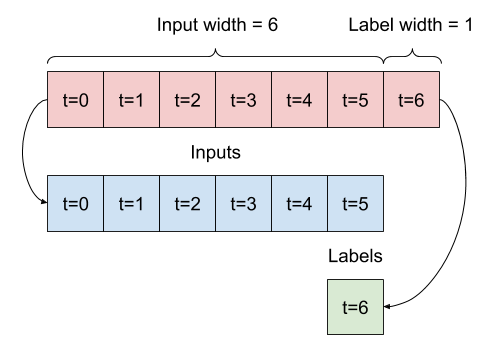
এই চিত্রটি ডেটার features অক্ষ দেখায় না, তবে এই split_window ফাংশনটি label_columns পরিচালনা করে যাতে এটি একক আউটপুট এবং মাল্টি-আউটপুট উদাহরণ উভয়ের জন্য ব্যবহার করা যেতে পারে।
def split_window(self, features):
inputs = features[:, self.input_slice, :]
labels = features[:, self.labels_slice, :]
if self.label_columns is not None:
labels = tf.stack(
[labels[:, :, self.column_indices[name]] for name in self.label_columns],
axis=-1)
# Slicing doesn't preserve static shape information, so set the shapes
# manually. This way the `tf.data.Datasets` are easier to inspect.
inputs.set_shape([None, self.input_width, None])
labels.set_shape([None, self.label_width, None])
return inputs, labels
WindowGenerator.split_window = split_window
চেষ্টা কর:
# Stack three slices, the length of the total window.
example_window = tf.stack([np.array(train_df[:w2.total_window_size]),
np.array(train_df[100:100+w2.total_window_size]),
np.array(train_df[200:200+w2.total_window_size])])
example_inputs, example_labels = w2.split_window(example_window)
print('All shapes are: (batch, time, features)')
print(f'Window shape: {example_window.shape}')
print(f'Inputs shape: {example_inputs.shape}')
print(f'Labels shape: {example_labels.shape}')
All shapes are: (batch, time, features) Window shape: (3, 7, 19) Inputs shape: (3, 6, 19) Labels shape: (3, 1, 1)
সাধারণত, TensorFlow-এর ডেটা অ্যারেগুলিতে প্যাক করা হয় যেখানে উদাহরণ জুড়ে সবচেয়ে বাইরের সূচকটি থাকে ("ব্যাচ" মাত্রা)। মাঝের সূচকগুলি হল "সময়" বা "স্থান" (প্রস্থ, উচ্চতা) মাত্রা(গুলি)। অন্তর্নিহিত সূচকগুলি হল বৈশিষ্ট্য।
উপরের কোডটি প্রতিটি সময় ধাপে 19টি বৈশিষ্ট্য সহ তিনটি 7-সময়ের ধাপের উইন্ডোর একটি ব্যাচ নিয়েছে। এটি এগুলিকে 6-বারের ধাপ 19-বৈশিষ্ট্য ইনপুটগুলির একটি ব্যাচে এবং একটি 1-বারের পদক্ষেপ 1-বৈশিষ্ট্য লেবেলে বিভক্ত করে৷ লেবেলের শুধুমাত্র একটি বৈশিষ্ট্য রয়েছে কারণ WindowGenerator label_columns=['T (degC)'] দিয়ে শুরু করা হয়েছিল। প্রাথমিকভাবে, এই টিউটোরিয়ালটি এমন মডেল তৈরি করবে যা একক আউটপুট লেবেলের পূর্বাভাস দেয়।
3. প্লট
এখানে একটি প্লট পদ্ধতি রয়েছে যা বিভক্ত উইন্ডোটির একটি সহজ ভিজ্যুয়ালাইজেশনের অনুমতি দেয়:
w2.example = example_inputs, example_labels
def plot(self, model=None, plot_col='T (degC)', max_subplots=3):
inputs, labels = self.example
plt.figure(figsize=(12, 8))
plot_col_index = self.column_indices[plot_col]
max_n = min(max_subplots, len(inputs))
for n in range(max_n):
plt.subplot(max_n, 1, n+1)
plt.ylabel(f'{plot_col} [normed]')
plt.plot(self.input_indices, inputs[n, :, plot_col_index],
label='Inputs', marker='.', zorder=-10)
if self.label_columns:
label_col_index = self.label_columns_indices.get(plot_col, None)
else:
label_col_index = plot_col_index
if label_col_index is None:
continue
plt.scatter(self.label_indices, labels[n, :, label_col_index],
edgecolors='k', label='Labels', c='#2ca02c', s=64)
if model is not None:
predictions = model(inputs)
plt.scatter(self.label_indices, predictions[n, :, label_col_index],
marker='X', edgecolors='k', label='Predictions',
c='#ff7f0e', s=64)
if n == 0:
plt.legend()
plt.xlabel('Time [h]')
WindowGenerator.plot = plot
এই প্লটটি ইনপুট, লেবেল এবং (পরে) ভবিষ্যদ্বাণীগুলিকে আইটেমটি নির্দেশ করে এমন সময়ের উপর ভিত্তি করে সারিবদ্ধ করে:
w2.plot()
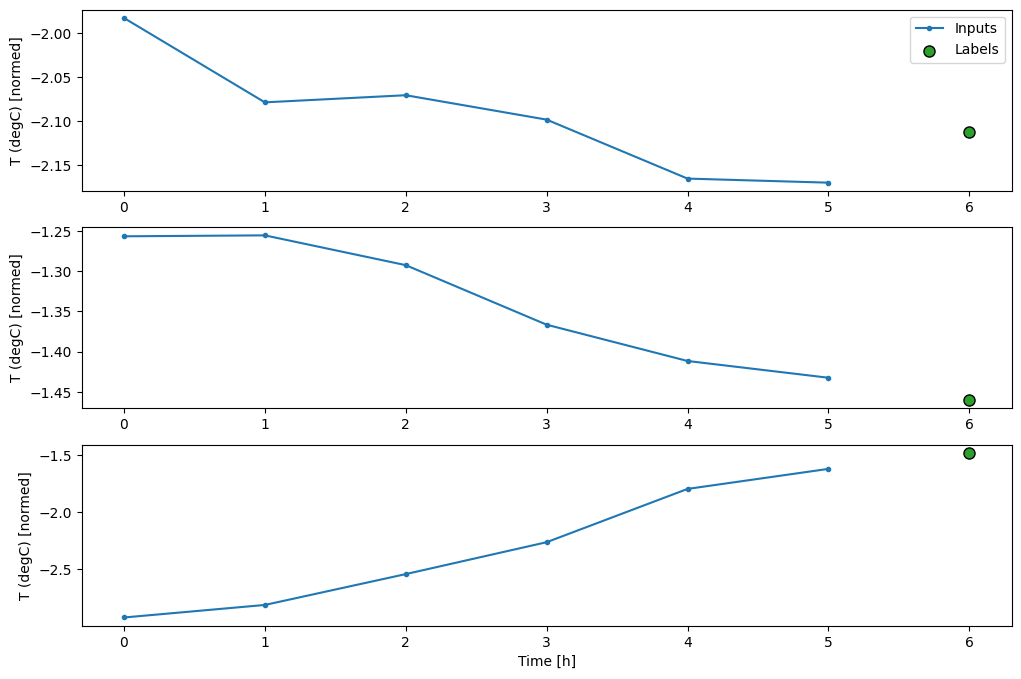
আপনি অন্যান্য কলাম প্লট করতে পারেন, কিন্তু উদাহরণ উইন্ডো w2 কনফিগারেশনে শুধুমাত্র T (degC) কলামের লেবেল রয়েছে।
w2.plot(plot_col='p (mbar)')
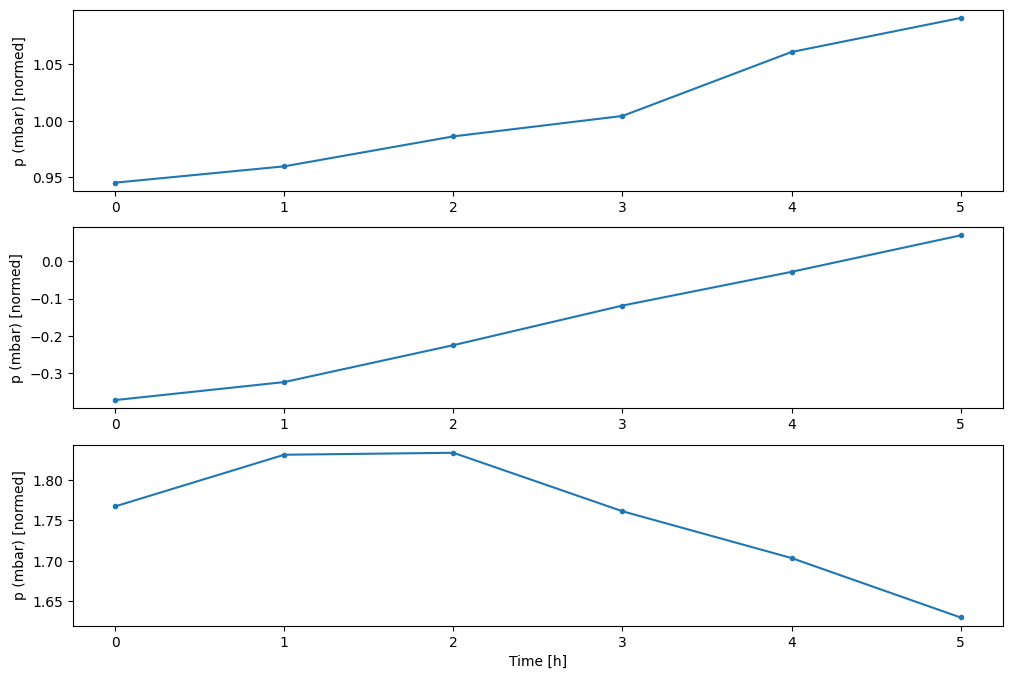
4. tf.data.Dataset s তৈরি করুন
অবশেষে, এই make_dataset পদ্ধতিটি একটি টাইম সিরিজ DataFrame লাগবে এবং tf.data.Dataset ফাংশন ব্যবহার করে (input_window, label_window) tf.keras.utils.timeseries_dataset_from_array রূপান্তর করবে:
def make_dataset(self, data):
data = np.array(data, dtype=np.float32)
ds = tf.keras.utils.timeseries_dataset_from_array(
data=data,
targets=None,
sequence_length=self.total_window_size,
sequence_stride=1,
shuffle=True,
batch_size=32,)
ds = ds.map(self.split_window)
return ds
WindowGenerator.make_dataset = make_dataset
WindowGenerator অবজেক্ট প্রশিক্ষণ, বৈধতা, এবং পরীক্ষার তথ্য ধারণ করে।
আপনি আগে সংজ্ঞায়িত make_dataset পদ্ধতি ব্যবহার করে tf.data.Dataset s হিসাবে তাদের অ্যাক্সেস করার জন্য বৈশিষ্ট্য যোগ করুন। এছাড়াও, সহজ অ্যাক্সেস এবং প্লট করার জন্য একটি আদর্শ উদাহরণ ব্যাচ যোগ করুন:
@property
def train(self):
return self.make_dataset(self.train_df)
@property
def val(self):
return self.make_dataset(self.val_df)
@property
def test(self):
return self.make_dataset(self.test_df)
@property
def example(self):
"""Get and cache an example batch of `inputs, labels` for plotting."""
result = getattr(self, '_example', None)
if result is None:
# No example batch was found, so get one from the `.train` dataset
result = next(iter(self.train))
# And cache it for next time
self._example = result
return result
WindowGenerator.train = train
WindowGenerator.val = val
WindowGenerator.test = test
WindowGenerator.example = example
এখন, WindowGenerator অবজেক্ট আপনাকে tf.data.Dataset অবজেক্টে অ্যাক্সেস দেয়, যাতে আপনি সহজেই ডেটার উপর পুনরাবৃত্তি করতে পারেন।
Dataset.element_spec প্রপার্টি আপনাকে ডেটাসেট এলিমেন্টের গঠন, ডেটার ধরন এবং আকৃতি বলে।
# Each element is an (inputs, label) pair.
w2.train.element_spec
(TensorSpec(shape=(None, 6, 19), dtype=tf.float32, name=None), TensorSpec(shape=(None, 1, 1), dtype=tf.float32, name=None))
একটি Dataset উপর পুনরাবৃত্তি করা কংক্রিট ব্যাচ দেয়:
for example_inputs, example_labels in w2.train.take(1):
print(f'Inputs shape (batch, time, features): {example_inputs.shape}')
print(f'Labels shape (batch, time, features): {example_labels.shape}')
Inputs shape (batch, time, features): (32, 6, 19) Labels shape (batch, time, features): (32, 1, 1)
একক ধাপ মডেল
এই ধরণের ডেটাতে আপনি যে সহজতম মডেলটি তৈরি করতে পারেন তা হল একটি একক বৈশিষ্ট্যের মান - শুধুমাত্র বর্তমান অবস্থার উপর ভিত্তি করে ভবিষ্যতের দিকে 1 টাইম স্টেপ (এক ঘন্টা) ভবিষ্যদ্বাণী করে৷
সুতরাং, ভবিষ্যতের এক ঘন্টা T (degC) মান ভবিষ্যদ্বাণী করতে মডেল তৈরি করে শুরু করুন।
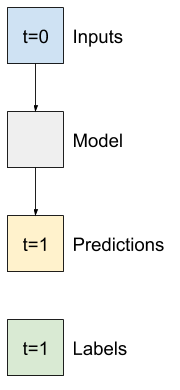
এই একক-পদক্ষেপ (input, label) জোড়া তৈরি করতে একটি WindowGenerator অবজেক্ট কনফিগার করুন:
single_step_window = WindowGenerator(
input_width=1, label_width=1, shift=1,
label_columns=['T (degC)'])
single_step_window
Total window size: 2 Input indices: [0] Label indices: [1] Label column name(s): ['T (degC)']
window অবজেক্ট প্রশিক্ষণ, বৈধতা এবং পরীক্ষা সেট থেকে tf.data.Dataset s তৈরি করে, যা আপনাকে ডেটার ব্যাচের উপর সহজেই পুনরাবৃত্তি করতে দেয়।
for example_inputs, example_labels in single_step_window.train.take(1):
print(f'Inputs shape (batch, time, features): {example_inputs.shape}')
print(f'Labels shape (batch, time, features): {example_labels.shape}')
Inputs shape (batch, time, features): (32, 1, 19) Labels shape (batch, time, features): (32, 1, 1)
বেসলাইন
একটি প্রশিক্ষণযোগ্য মডেল তৈরি করার আগে পরবর্তীতে আরও জটিল মডেলগুলির সাথে তুলনা করার জন্য একটি বিন্দু হিসাবে কর্মক্ষমতা বেসলাইন থাকা ভাল।
এই প্রথম কাজটি হ'ল সমস্ত বৈশিষ্ট্যের বর্তমান মান বিবেচনা করে ভবিষ্যতে এক ঘন্টা তাপমাত্রার পূর্বাভাস দেওয়া। বর্তমান মান বর্তমান তাপমাত্রা অন্তর্ভুক্ত.
সুতরাং, এমন একটি মডেল দিয়ে শুরু করুন যা ভবিষ্যদ্বাণী হিসাবে বর্তমান তাপমাত্রা প্রদান করে, "কোন পরিবর্তন নয়" ভবিষ্যদ্বাণী করে। এটি একটি যুক্তিসঙ্গত ভিত্তিরেখা যেহেতু তাপমাত্রা ধীরে ধীরে পরিবর্তিত হয়। অবশ্যই, আপনি যদি ভবিষ্যতে আরও ভবিষ্যদ্বাণী করেন তবে এই বেসলাইনটি কম ভাল কাজ করবে।
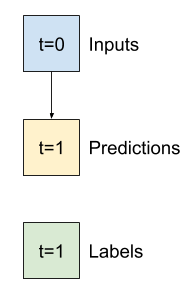
class Baseline(tf.keras.Model):
def __init__(self, label_index=None):
super().__init__()
self.label_index = label_index
def call(self, inputs):
if self.label_index is None:
return inputs
result = inputs[:, :, self.label_index]
return result[:, :, tf.newaxis]
এই মডেলটি তাত্ক্ষণিক এবং মূল্যায়ন করুন:
baseline = Baseline(label_index=column_indices['T (degC)'])
baseline.compile(loss=tf.losses.MeanSquaredError(),
metrics=[tf.metrics.MeanAbsoluteError()])
val_performance = {}
performance = {}
val_performance['Baseline'] = baseline.evaluate(single_step_window.val)
performance['Baseline'] = baseline.evaluate(single_step_window.test, verbose=0)
439/439 [==============================] - 1s 2ms/step - loss: 0.0128 - mean_absolute_error: 0.0785
এটি কিছু পারফরম্যান্স মেট্রিক্স প্রিন্ট করেছে, কিন্তু সেগুলি আপনাকে মডেলটি কতটা ভাল করছে তার জন্য অনুভূতি দেয় না।
WindowGenerator একটি প্লট পদ্ধতি রয়েছে, কিন্তু শুধুমাত্র একটি নমুনা দিয়ে প্লটগুলি খুব আকর্ষণীয় হবে না।
সুতরাং, একটি বৃহত্তর WindowGenerator তৈরি করুন যা উইন্ডোজ 24 ঘন্টা পরপর ইনপুট এবং লেবেল তৈরি করে। নতুন wide_window ভেরিয়েবল মডেলটির কাজ করার পদ্ধতি পরিবর্তন করে না। মডেলটি এখনও একটি একক ইনপুট সময় ধাপের উপর ভিত্তি করে ভবিষ্যতের এক ঘন্টা পূর্বাভাস দেয়। এখানে, time অক্ষ batch অক্ষের মতো কাজ করে: প্রতিটি ভবিষ্যদ্বাণী স্বাধীনভাবে করা হয় সময় ধাপের মধ্যে কোনো মিথস্ক্রিয়া ছাড়াই:
wide_window = WindowGenerator(
input_width=24, label_width=24, shift=1,
label_columns=['T (degC)'])
wide_window
Total window size: 25 Input indices: [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23] Label indices: [ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24] Label column name(s): ['T (degC)']
এই প্রসারিত উইন্ডোটি কোনো কোড পরিবর্তন ছাড়াই সরাসরি একই baseline মডেলে পাস করা যেতে পারে। এটি সম্ভব কারণ ইনপুট এবং লেবেলে একই সংখ্যক সময়ের ধাপ রয়েছে এবং বেসলাইনটি ইনপুটটিকে আউটপুটে ফরোয়ার্ড করে:
print('Input shape:', wide_window.example[0].shape)
print('Output shape:', baseline(wide_window.example[0]).shape)
Input shape: (32, 24, 19) Output shape: (32, 24, 1)
বেসলাইন মডেলের ভবিষ্যদ্বাণীগুলি প্লট করে, লক্ষ্য করুন যে এটি কেবলমাত্র লেবেলগুলি এক ঘন্টার মধ্যে স্থানান্তরিত হয়েছে:
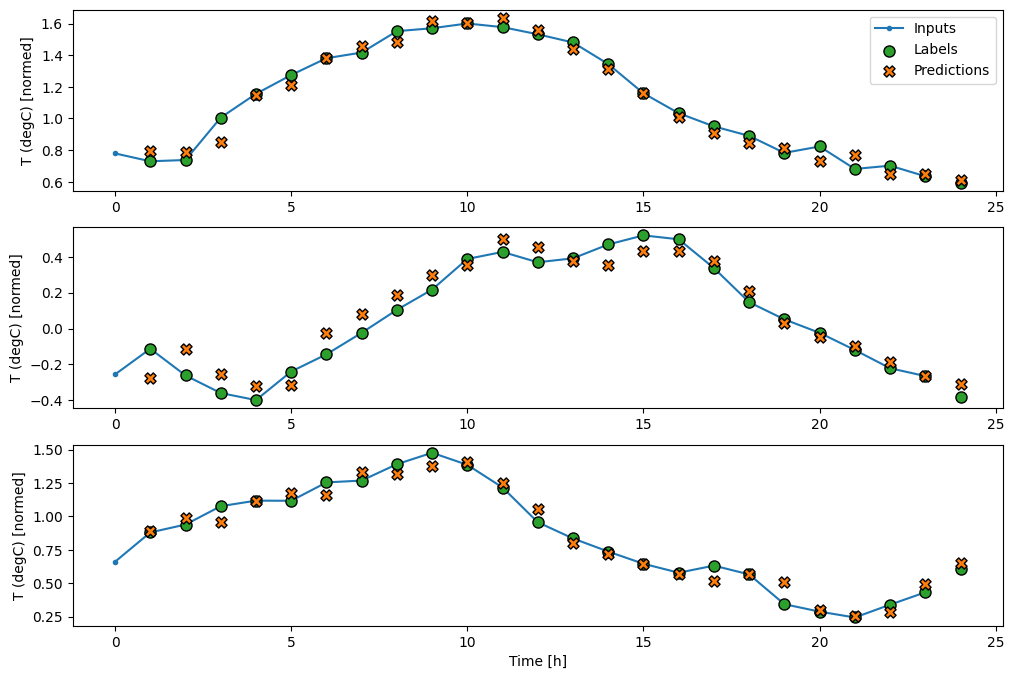
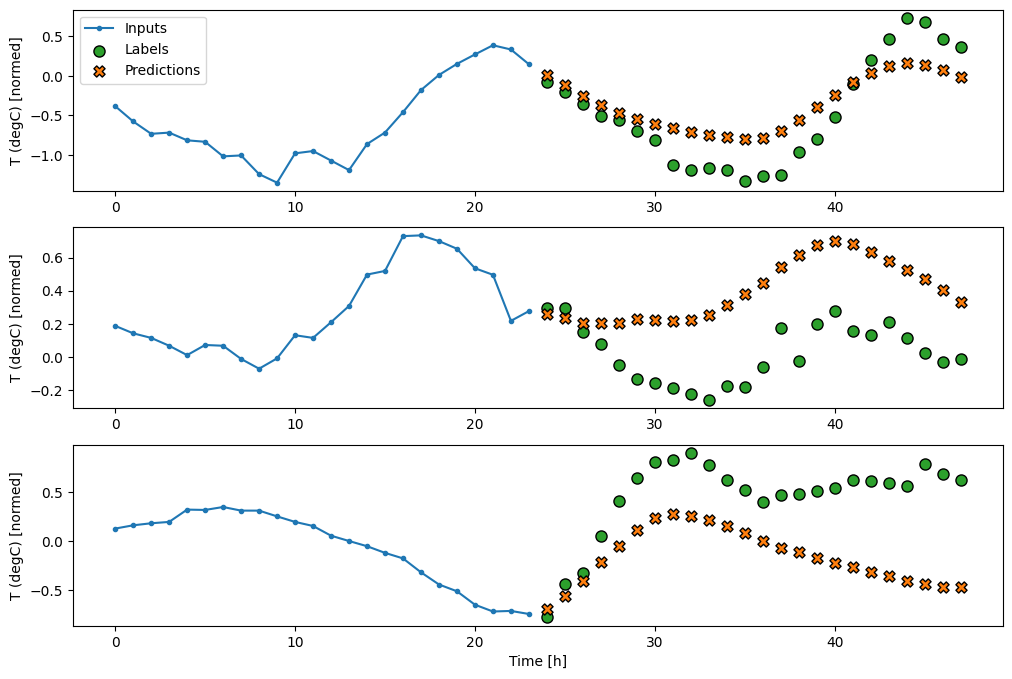
wide_window.plot(baseline)
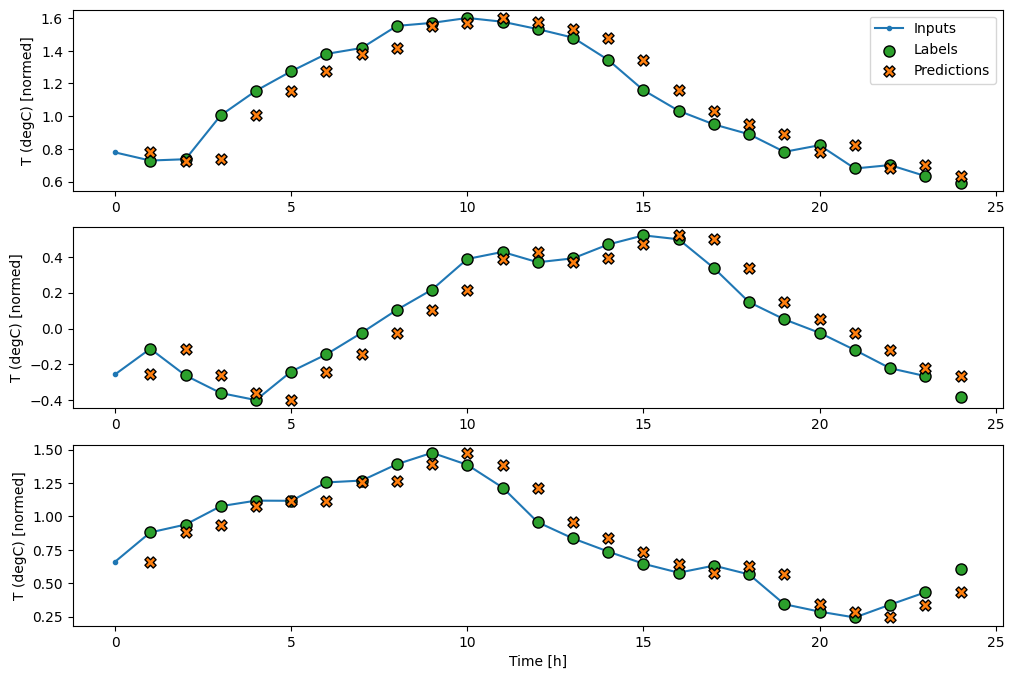
তিনটি উদাহরণের উপরের প্লটে একক ধাপের মডেলটি 24 ঘন্টার মধ্যে চালানো হয়। এটি কিছু ব্যাখ্যা প্রাপ্য:
- নীল
Inputsলাইন প্রতিটি ধাপে ইনপুট তাপমাত্রা দেখায়। মডেলটি সমস্ত বৈশিষ্ট্য গ্রহণ করে, এই প্লটটি শুধুমাত্র তাপমাত্রা দেখায়। - সবুজ
Labelsবিন্দু লক্ষ্য ভবিষ্যদ্বাণী মান দেখায়. এই বিন্দুগুলি ভবিষ্যদ্বাণীর সময় দেখানো হয়, ইনপুট সময় নয়। এই কারণেই লেবেলের পরিসর ইনপুটগুলির তুলনায় 1 ধাপে স্থানান্তরিত হয়। - কমলা
Predictionsক্রসগুলি প্রতিটি আউটপুট সময় ধাপের জন্য মডেলের ভবিষ্যদ্বাণী। যদি মডেলটি নিখুঁতভাবে ভবিষ্যদ্বাণী করে থাকে তবে ভবিষ্যদ্বাণীগুলি সরাসরিLabelsউপর ল্যান্ড করবে৷
লিনিয়ার মডেল
আপনি এই টাস্কে প্রয়োগ করতে পারেন সবচেয়ে সহজ প্রশিক্ষণযোগ্য মডেলটি হল ইনপুট এবং আউটপুটের মধ্যে রৈখিক রূপান্তর সন্নিবেশ করা। এই ক্ষেত্রে একটি সময় ধাপ থেকে আউটপুট শুধুমাত্র সেই ধাপের উপর নির্ভর করে:
activation সেট ছাড়া একটি tf.keras.layers.Dense . ঘন স্তর একটি রৈখিক মডেল। স্তরটি শুধুমাত্র ডেটার শেষ অক্ষকে (batch, time, inputs) থেকে (batch, time, units) তে রূপান্তরিত করে; এটি batch এবং time অক্ষ জুড়ে প্রতিটি আইটেম স্বাধীনভাবে প্রয়োগ করা হয়.
linear = tf.keras.Sequential([
tf.keras.layers.Dense(units=1)
])
print('Input shape:', single_step_window.example[0].shape)
print('Output shape:', linear(single_step_window.example[0]).shape)
Input shape: (32, 1, 19) Output shape: (32, 1, 1)
এই টিউটোরিয়ালটি অনেক মডেলকে প্রশিক্ষণ দেয়, তাই প্রশিক্ষণ পদ্ধতিটিকে একটি ফাংশনে প্যাকেজ করুন:
MAX_EPOCHS = 20
def compile_and_fit(model, window, patience=2):
early_stopping = tf.keras.callbacks.EarlyStopping(monitor='val_loss',
patience=patience,
mode='min')
model.compile(loss=tf.losses.MeanSquaredError(),
optimizer=tf.optimizers.Adam(),
metrics=[tf.metrics.MeanAbsoluteError()])
history = model.fit(window.train, epochs=MAX_EPOCHS,
validation_data=window.val,
callbacks=[early_stopping])
return history
মডেলটিকে প্রশিক্ষণ দিন এবং এর কর্মক্ষমতা মূল্যায়ন করুন:
history = compile_and_fit(linear, single_step_window)
val_performance['Linear'] = linear.evaluate(single_step_window.val)
performance['Linear'] = linear.evaluate(single_step_window.test, verbose=0)
Epoch 1/20 1534/1534 [==============================] - 5s 3ms/step - loss: 0.0586 - mean_absolute_error: 0.1659 - val_loss: 0.0135 - val_mean_absolute_error: 0.0858 Epoch 2/20 1534/1534 [==============================] - 5s 3ms/step - loss: 0.0109 - mean_absolute_error: 0.0772 - val_loss: 0.0093 - val_mean_absolute_error: 0.0711 Epoch 3/20 1534/1534 [==============================] - 5s 3ms/step - loss: 0.0092 - mean_absolute_error: 0.0704 - val_loss: 0.0088 - val_mean_absolute_error: 0.0690 Epoch 4/20 1534/1534 [==============================] - 5s 3ms/step - loss: 0.0091 - mean_absolute_error: 0.0697 - val_loss: 0.0089 - val_mean_absolute_error: 0.0692 Epoch 5/20 1534/1534 [==============================] - 5s 3ms/step - loss: 0.0091 - mean_absolute_error: 0.0697 - val_loss: 0.0088 - val_mean_absolute_error: 0.0685 Epoch 6/20 1534/1534 [==============================] - 5s 3ms/step - loss: 0.0091 - mean_absolute_error: 0.0697 - val_loss: 0.0087 - val_mean_absolute_error: 0.0687 Epoch 7/20 1534/1534 [==============================] - 5s 3ms/step - loss: 0.0091 - mean_absolute_error: 0.0698 - val_loss: 0.0087 - val_mean_absolute_error: 0.0680 Epoch 8/20 1534/1534 [==============================] - 5s 3ms/step - loss: 0.0090 - mean_absolute_error: 0.0695 - val_loss: 0.0087 - val_mean_absolute_error: 0.0683 Epoch 9/20 1534/1534 [==============================] - 5s 3ms/step - loss: 0.0091 - mean_absolute_error: 0.0696 - val_loss: 0.0087 - val_mean_absolute_error: 0.0684 439/439 [==============================] - 1s 2ms/step - loss: 0.0087 - mean_absolute_error: 0.0684
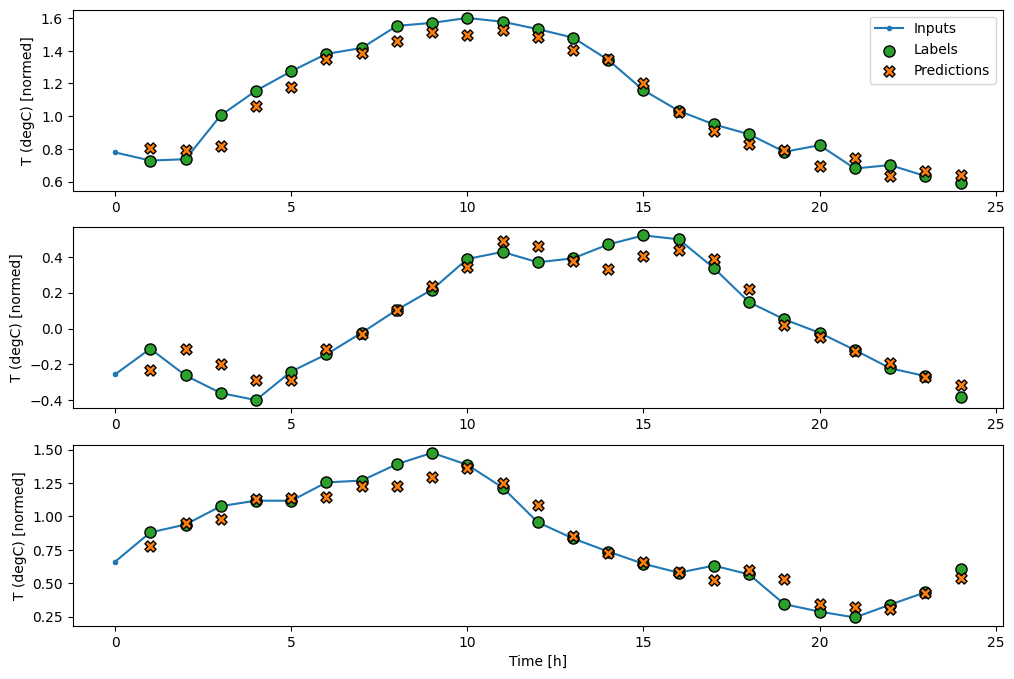
baseline মডেলের মতো, রৈখিক মডেলটিকে প্রশস্ত উইন্ডোগুলির ব্যাচে বলা যেতে পারে। এইভাবে ব্যবহৃত মডেলটি পরপর সময়ের ধাপে স্বাধীন ভবিষ্যদ্বাণীর একটি সেট তৈরি করে। time অক্ষ অন্য batch অক্ষের মত কাজ করে। প্রতিটি সময় ধাপে ভবিষ্যদ্বাণীগুলির মধ্যে কোনও মিথস্ক্রিয়া নেই।
print('Input shape:', wide_window.example[0].shape)
print('Output shape:', baseline(wide_window.example[0]).shape)
Input shape: (32, 24, 19) Output shape: (32, 24, 1)
এখানে wide_window এর উদাহরণ ভবিষ্যদ্বাণীর প্লট রয়েছে, লক্ষ্য করুন যে কত ক্ষেত্রে ভবিষ্যদ্বাণীটি কেবল ইনপুট তাপমাত্রা ফেরানোর চেয়ে স্পষ্টভাবে ভাল, তবে কয়েকটি ক্ষেত্রে এটি আরও খারাপ:
wide_window.plot(linear)
রৈখিক মডেলগুলির একটি সুবিধা হল যে তারা ব্যাখ্যা করা তুলনামূলকভাবে সহজ। আপনি স্তরের ওজন বের করতে পারেন এবং প্রতিটি ইনপুটে নির্ধারিত ওজন কল্পনা করতে পারেন:
plt.bar(x = range(len(train_df.columns)),
height=linear.layers[0].kernel[:,0].numpy())
axis = plt.gca()
axis.set_xticks(range(len(train_df.columns)))
_ = axis.set_xticklabels(train_df.columns, rotation=90)
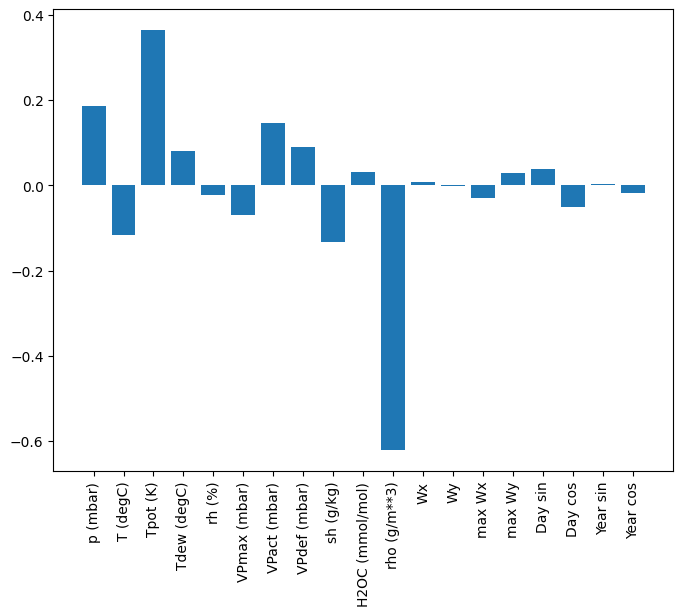
কখনও কখনও মডেলটি ইনপুট T (degC) তে সর্বাধিক ওজনও রাখে না। এটি এলোমেলো শুরুর ঝুঁকিগুলির মধ্যে একটি।
ঘন
একাধিক সময়-পদক্ষেপে কাজ করে এমন মডেলগুলি প্রয়োগ করার আগে, গভীর, আরও শক্তিশালী, একক ইনপুট ধাপের মডেলগুলির কার্যকারিতা পরীক্ষা করা মূল্যবান৷
এখানে linear মডেলের অনুরূপ একটি মডেল রয়েছে, এটি ইনপুট এবং আউটপুটের মধ্যে কয়েকটি Dense স্তর স্তূপাকার করে:
dense = tf.keras.Sequential([
tf.keras.layers.Dense(units=64, activation='relu'),
tf.keras.layers.Dense(units=64, activation='relu'),
tf.keras.layers.Dense(units=1)
])
history = compile_and_fit(dense, single_step_window)
val_performance['Dense'] = dense.evaluate(single_step_window.val)
performance['Dense'] = dense.evaluate(single_step_window.test, verbose=0)
Epoch 1/20 1534/1534 [==============================] - 7s 4ms/step - loss: 0.0132 - mean_absolute_error: 0.0779 - val_loss: 0.0081 - val_mean_absolute_error: 0.0666 Epoch 2/20 1534/1534 [==============================] - 6s 4ms/step - loss: 0.0081 - mean_absolute_error: 0.0652 - val_loss: 0.0073 - val_mean_absolute_error: 0.0610 Epoch 3/20 1534/1534 [==============================] - 6s 4ms/step - loss: 0.0076 - mean_absolute_error: 0.0627 - val_loss: 0.0072 - val_mean_absolute_error: 0.0618 Epoch 4/20 1534/1534 [==============================] - 6s 4ms/step - loss: 0.0072 - mean_absolute_error: 0.0609 - val_loss: 0.0068 - val_mean_absolute_error: 0.0582 Epoch 5/20 1534/1534 [==============================] - 6s 4ms/step - loss: 0.0072 - mean_absolute_error: 0.0606 - val_loss: 0.0066 - val_mean_absolute_error: 0.0581 Epoch 6/20 1534/1534 [==============================] - 6s 4ms/step - loss: 0.0070 - mean_absolute_error: 0.0594 - val_loss: 0.0067 - val_mean_absolute_error: 0.0579 Epoch 7/20 1534/1534 [==============================] - 6s 4ms/step - loss: 0.0069 - mean_absolute_error: 0.0590 - val_loss: 0.0068 - val_mean_absolute_error: 0.0580 439/439 [==============================] - 1s 3ms/step - loss: 0.0068 - mean_absolute_error: 0.0580
বহু-পদক্ষেপ ঘন
একটি একক-সময়-পদক্ষেপ মডেলের ইনপুটগুলির বর্তমান মানগুলির জন্য কোনও প্রসঙ্গ নেই৷ সময়ের সাথে সাথে ইনপুট বৈশিষ্ট্যগুলি কীভাবে পরিবর্তিত হচ্ছে তা দেখতে পাচ্ছে না। এই সমস্যাটির সমাধান করার জন্য ভবিষ্যদ্বাণী করার সময় মডেলটির একাধিক বার ধাপে অ্যাক্সেস প্রয়োজন:
baseline , linear এবং dense মডেলগুলি প্রতিটি সময় স্বাধীনভাবে পদক্ষেপ নেয়। এখানে মডেলটি একটি একক আউটপুট তৈরি করতে ইনপুট হিসাবে একাধিক সময় পদক্ষেপ নেবে।
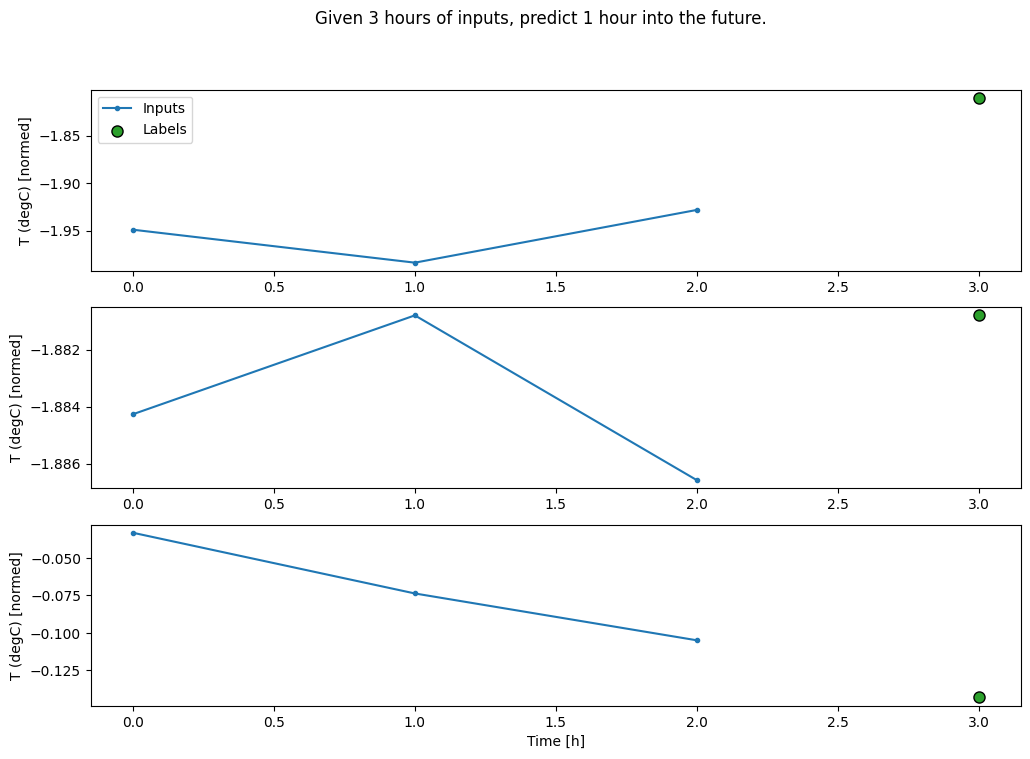
একটি WindowGenerator তৈরি করুন যা তিন ঘণ্টার ইনপুট এবং এক ঘণ্টার লেবেলের ব্যাচ তৈরি করবে:
মনে রাখবেন যে Window shift প্যারামিটার দুটি উইন্ডোর শেষের সাথে আপেক্ষিক।
CONV_WIDTH = 3
conv_window = WindowGenerator(
input_width=CONV_WIDTH,
label_width=1,
shift=1,
label_columns=['T (degC)'])
conv_window
Total window size: 4 Input indices: [0 1 2] Label indices: [3] Label column name(s): ['T (degC)']
conv_window.plot()
plt.title("Given 3 hours of inputs, predict 1 hour into the future.")
Text(0.5, 1.0, 'Given 3 hours of inputs, predict 1 hour into the future.')
আপনি মডেলের প্রথম স্তর হিসাবে tf.keras.layers.Flatten যোগ করে একাধিক-ইনপুট-স্টেপ উইন্ডোতে একটি dense মডেলকে প্রশিক্ষণ দিতে পারেন:
multi_step_dense = tf.keras.Sequential([
# Shape: (time, features) => (time*features)
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(units=32, activation='relu'),
tf.keras.layers.Dense(units=32, activation='relu'),
tf.keras.layers.Dense(units=1),
# Add back the time dimension.
# Shape: (outputs) => (1, outputs)
tf.keras.layers.Reshape([1, -1]),
])
print('Input shape:', conv_window.example[0].shape)
print('Output shape:', multi_step_dense(conv_window.example[0]).shape)
Input shape: (32, 3, 19) Output shape: (32, 1, 1)
history = compile_and_fit(multi_step_dense, conv_window)
IPython.display.clear_output()
val_performance['Multi step dense'] = multi_step_dense.evaluate(conv_window.val)
performance['Multi step dense'] = multi_step_dense.evaluate(conv_window.test, verbose=0)
438/438 [==============================] - 1s 2ms/step - loss: 0.0070 - mean_absolute_error: 0.0609
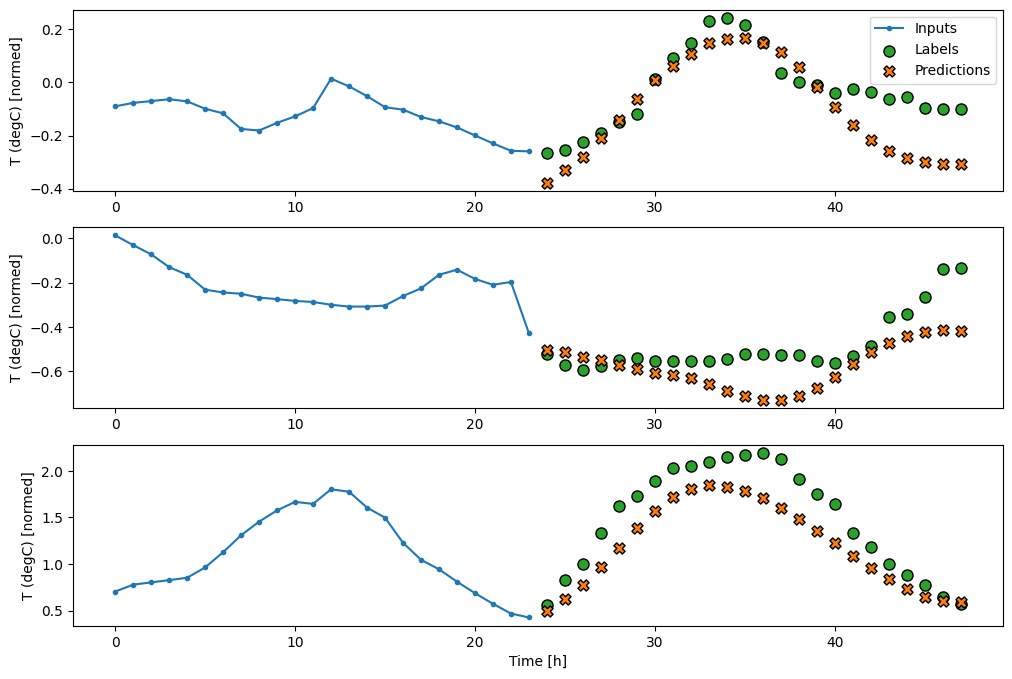
conv_window.plot(multi_step_dense)
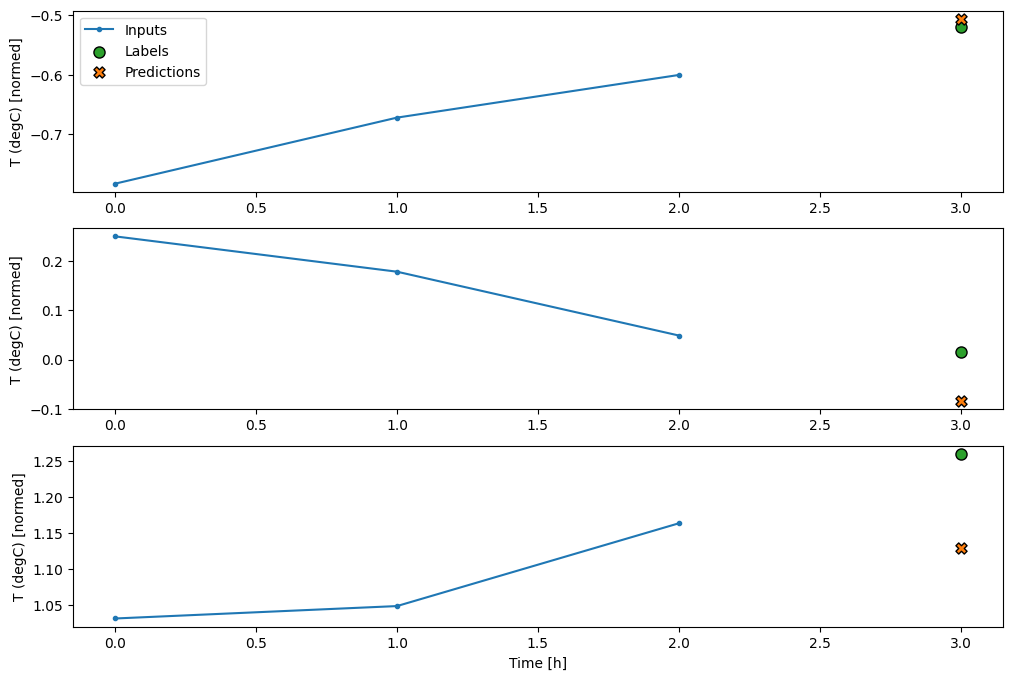
এই পদ্ধতির প্রধান নিম্ন-সদৃশ হল যে ফলাফল মডেলটি শুধুমাত্র এই আকৃতির ইনপুট উইন্ডোতে কার্যকর করা যেতে পারে।
print('Input shape:', wide_window.example[0].shape)
try:
print('Output shape:', multi_step_dense(wide_window.example[0]).shape)
except Exception as e:
print(f'\n{type(e).__name__}:{e}')
Input shape: (32, 24, 19) ValueError:Exception encountered when calling layer "sequential_2" (type Sequential). Input 0 of layer "dense_4" is incompatible with the layer: expected axis -1 of input shape to have value 57, but received input with shape (32, 456) Call arguments received: • inputs=tf.Tensor(shape=(32, 24, 19), dtype=float32) • training=None • mask=None
পরবর্তী বিভাগে কনভোলিউশনাল মডেলগুলি এই সমস্যার সমাধান করে।
কনভল্যুশন নিউরাল নেটওয়ার্ক
একটি কনভোলিউশন লেয়ার ( tf.keras.layers.Conv1D ) প্রতিটি ভবিষ্যদ্বাণীতে ইনপুট হিসাবে একাধিক সময় পদক্ষেপ নেয়।
নীচে মাল্টি_স্টেপ_ডেন্সের মতো একই মডেল, একটি multi_step_dense দিয়ে পুনরায় লেখা।
পরিবর্তনগুলি নোট করুন:
-
tf.keras.layers.Flattenএবং প্রথমtf.keras.layers.Denseএকটিtf.keras.layers.Conv1Dদ্বারা প্রতিস্থাপিত হয়। -
tf.keras.layers.Reshapeআর প্রয়োজন নেই যেহেতু কনভল্যুশন সময় অক্ষকে তার আউটপুটে রাখে।
conv_model = tf.keras.Sequential([
tf.keras.layers.Conv1D(filters=32,
kernel_size=(CONV_WIDTH,),
activation='relu'),
tf.keras.layers.Dense(units=32, activation='relu'),
tf.keras.layers.Dense(units=1),
])
মডেলটি প্রত্যাশিত আকারের সাথে আউটপুট তৈরি করে তা পরীক্ষা করার জন্য একটি উদাহরণ ব্যাচে এটি চালান:
print("Conv model on `conv_window`")
print('Input shape:', conv_window.example[0].shape)
print('Output shape:', conv_model(conv_window.example[0]).shape)
Conv model on `conv_window` Input shape: (32, 3, 19) Output shape: (32, 1, 1)
কনভ_উইন্ডোতে প্রশিক্ষণ দিন এবং মূল্যায়ন করুন এবং এটি conv_window মডেলের মতো পারফরম্যান্স প্রদান multi_step_dense ।
history = compile_and_fit(conv_model, conv_window)
IPython.display.clear_output()
val_performance['Conv'] = conv_model.evaluate(conv_window.val)
performance['Conv'] = conv_model.evaluate(conv_window.test, verbose=0)
438/438 [==============================] - 1s 3ms/step - loss: 0.0063 - mean_absolute_error: 0.0568
এই conv_model এবং multi_step_dense মডেলের মধ্যে পার্থক্য হল conv_model যেকোন দৈর্ঘ্যের ইনপুটে চালানো যেতে পারে। কনভোলিউশনাল লেয়ারটি ইনপুটগুলির একটি স্লাইডিং উইন্ডোতে প্রয়োগ করা হয়:
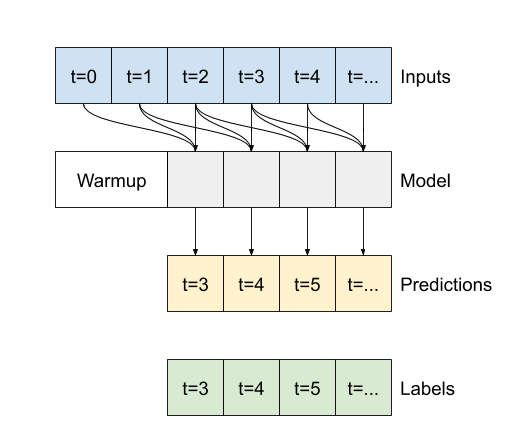
আপনি যদি এটি বৃহত্তর ইনপুটে চালান তবে এটি বিস্তৃত আউটপুট তৈরি করে:
print("Wide window")
print('Input shape:', wide_window.example[0].shape)
print('Labels shape:', wide_window.example[1].shape)
print('Output shape:', conv_model(wide_window.example[0]).shape)
Wide window Input shape: (32, 24, 19) Labels shape: (32, 24, 1) Output shape: (32, 22, 1)
নোট করুন যে আউটপুট ইনপুট থেকে ছোট। প্রশিক্ষণ বা প্লটিংয়ের কাজ করার জন্য, আপনার লেবেল এবং ভবিষ্যদ্বাণীর একই দৈর্ঘ্য থাকতে হবে। তাই লেবেল এবং ভবিষ্যদ্বাণীর দৈর্ঘ্য মিলে যাওয়ার জন্য কয়েকটি অতিরিক্ত ইনপুট সময় ধাপ সহ প্রশস্ত উইন্ডো তৈরি করতে একটি WindowGenerator তৈরি করুন:
LABEL_WIDTH = 24
INPUT_WIDTH = LABEL_WIDTH + (CONV_WIDTH - 1)
wide_conv_window = WindowGenerator(
input_width=INPUT_WIDTH,
label_width=LABEL_WIDTH,
shift=1,
label_columns=['T (degC)'])
wide_conv_window
Total window size: 27 Input indices: [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25] Label indices: [ 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26] Label column name(s): ['T (degC)']
print("Wide conv window")
print('Input shape:', wide_conv_window.example[0].shape)
print('Labels shape:', wide_conv_window.example[1].shape)
print('Output shape:', conv_model(wide_conv_window.example[0]).shape)
Wide conv window Input shape: (32, 26, 19) Labels shape: (32, 24, 1) Output shape: (32, 24, 1)
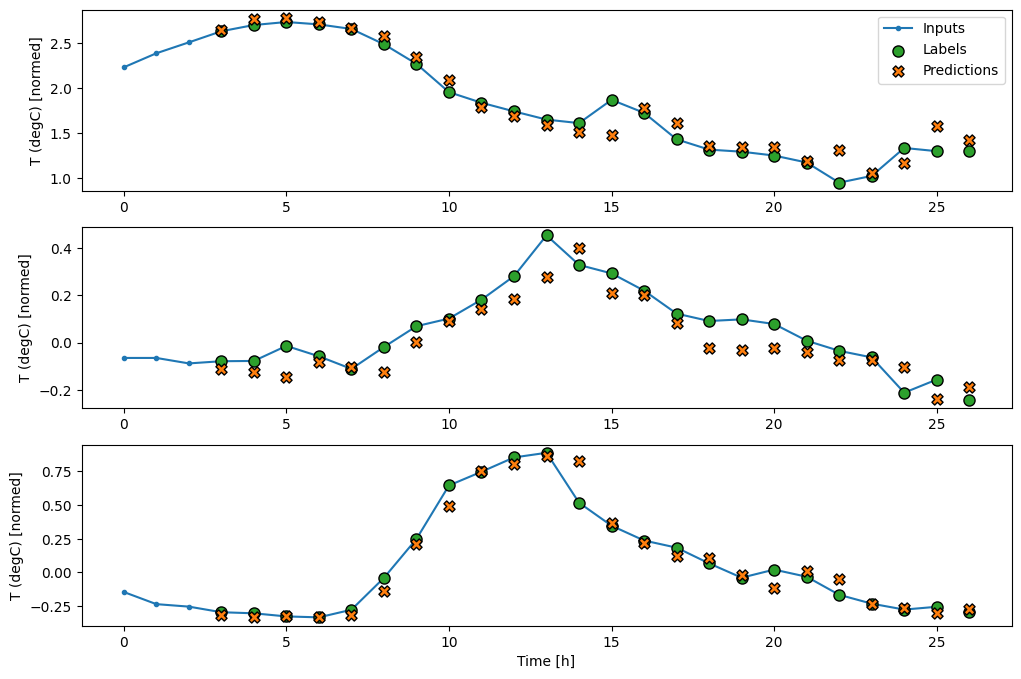
এখন, আপনি একটি বিস্তৃত উইন্ডোতে মডেলের ভবিষ্যদ্বাণীগুলি প্লট করতে পারেন৷ প্রথম ভবিষ্যদ্বাণীর আগে 3টি ইনপুট সময় ধাপ নোট করুন। এখানে প্রতিটি ভবিষ্যদ্বাণী 3টি পূর্ববর্তী সময়ের ধাপের উপর ভিত্তি করে করা হয়েছে:
wide_conv_window.plot(conv_model)
পৌনঃপুনিক নিউরাল নেটওয়ার্ক
একটি পুনরাবৃত্ত নিউরাল নেটওয়ার্ক (RNN) হল এক ধরনের নিউরাল নেটওয়ার্ক যা টাইম সিরিজ ডেটার জন্য উপযুক্ত। আরএনএনগুলি একটি টাইম সিরিজ ধাপে ধাপে প্রক্রিয়া করে, একটি অভ্যন্তরীণ অবস্থা বজায় রাখে সময়ে ধাপে ধাপে।
আপনি টেক্সট জেনারেশনে আরএনএন টিউটোরিয়াল এবং রিকারেন্ট নিউরাল নেটওয়ার্কস (আরএনএন) কেরাস গাইড সহ আরও শিখতে পারেন।
এই টিউটোরিয়ালে, আপনি লং শর্ট-টার্ম মেমরি ( tf.keras.layers.LSTM ) নামে একটি RNN স্তর ব্যবহার করবেন।
সমস্ত Keras RNN স্তরগুলির জন্য একটি গুরুত্বপূর্ণ কনস্ট্রাক্টর আর্গুমেন্ট, যেমন tf.keras.layers.LSTM , হল return_sequences আর্গুমেন্ট। এই সেটিংটি দুটি উপায়ের একটিতে স্তরটি কনফিগার করতে পারে:
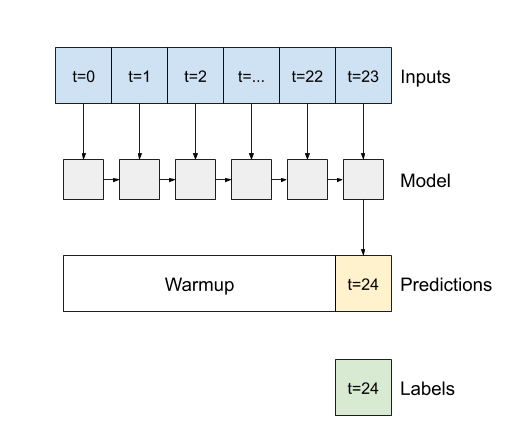
- যদি
False, ডিফল্ট, স্তরটি শুধুমাত্র চূড়ান্ত সময়ের ধাপের আউটপুট প্রদান করে, মডেলটিকে একটি একক ভবিষ্যদ্বাণী করার আগে তার অভ্যন্তরীণ অবস্থাকে উষ্ণ করার জন্য সময় দেয়:
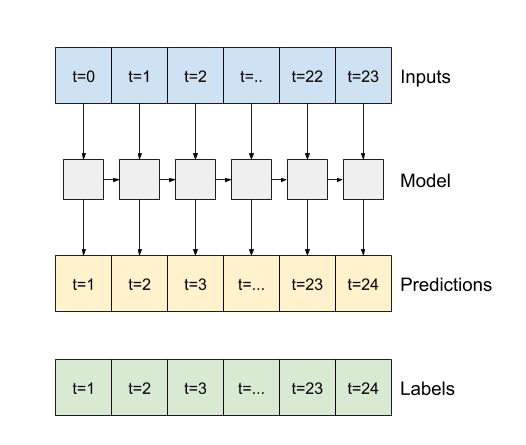
-
Trueহলে, স্তরটি প্রতিটি ইনপুটের জন্য একটি আউটপুট প্রদান করে। এই জন্য দরকারী:- RNN স্তরগুলি স্ট্যাক করা হচ্ছে।
- একযোগে একাধিক সময় ধাপে একটি মডেলকে প্রশিক্ষণ দেওয়া।
lstm_model = tf.keras.models.Sequential([
# Shape [batch, time, features] => [batch, time, lstm_units]
tf.keras.layers.LSTM(32, return_sequences=True),
# Shape => [batch, time, features]
tf.keras.layers.Dense(units=1)
])
return_sequences=True সহ, মডেলটিকে এক সময়ে 24 ঘন্টা ডেটার উপর প্রশিক্ষণ দেওয়া যেতে পারে।
print('Input shape:', wide_window.example[0].shape)
print('Output shape:', lstm_model(wide_window.example[0]).shape)
Input shape: (32, 24, 19) Output shape: (32, 24, 1)
history = compile_and_fit(lstm_model, wide_window)
IPython.display.clear_output()
val_performance['LSTM'] = lstm_model.evaluate(wide_window.val)
performance['LSTM'] = lstm_model.evaluate(wide_window.test, verbose=0)
438/438 [==============================] - 1s 3ms/step - loss: 0.0055 - mean_absolute_error: 0.0509
wide_window.plot(lstm_model)
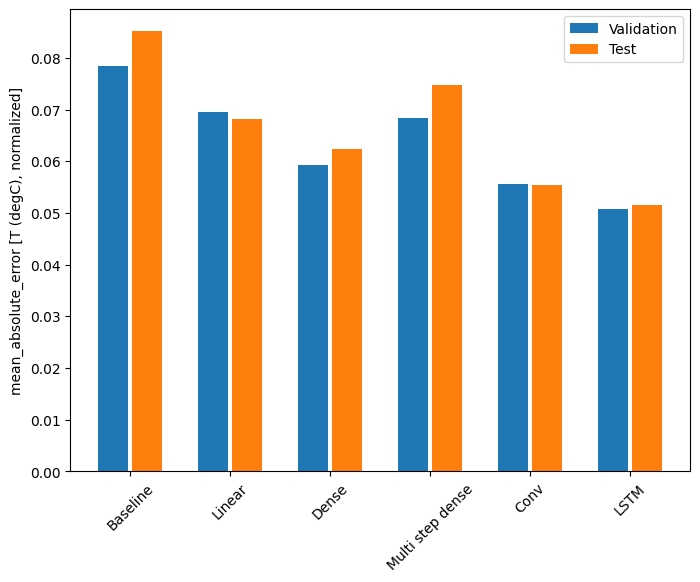
কর্মক্ষমতা
এই ডেটাসেটের সাথে সাধারণত প্রতিটি মডেল তার আগেরটির চেয়ে কিছুটা ভালো করে:
x = np.arange(len(performance))
width = 0.3
metric_name = 'mean_absolute_error'
metric_index = lstm_model.metrics_names.index('mean_absolute_error')
val_mae = [v[metric_index] for v in val_performance.values()]
test_mae = [v[metric_index] for v in performance.values()]
plt.ylabel('mean_absolute_error [T (degC), normalized]')
plt.bar(x - 0.17, val_mae, width, label='Validation')
plt.bar(x + 0.17, test_mae, width, label='Test')
plt.xticks(ticks=x, labels=performance.keys(),
rotation=45)
_ = plt.legend()
for name, value in performance.items():
print(f'{name:12s}: {value[1]:0.4f}')
Baseline : 0.0852 Linear : 0.0666 Dense : 0.0573 Multi step dense: 0.0586 Conv : 0.0577 LSTM : 0.0518
মাল্টি-আউটপুট মডেল
মডেলগুলি এখন পর্যন্ত একটি একক আউটপুট বৈশিষ্ট্য, T (degC) একটি একক সময়ের পদক্ষেপের জন্য ভবিষ্যদ্বাণী করেছে।
এই সমস্ত মডেলগুলিকে আউটপুট স্তরে ইউনিটের সংখ্যা পরিবর্তন করে এবং labels সমস্ত বৈশিষ্ট্য অন্তর্ভুক্ত করার জন্য প্রশিক্ষণ উইন্ডোগুলিকে সামঞ্জস্য করে একাধিক বৈশিষ্ট্যের পূর্বাভাস দিতে রূপান্তরিত করা যেতে পারে ( example_labels ):
single_step_window = WindowGenerator(
# `WindowGenerator` returns all features as labels if you
# don't set the `label_columns` argument.
input_width=1, label_width=1, shift=1)
wide_window = WindowGenerator(
input_width=24, label_width=24, shift=1)
for example_inputs, example_labels in wide_window.train.take(1):
print(f'Inputs shape (batch, time, features): {example_inputs.shape}')
print(f'Labels shape (batch, time, features): {example_labels.shape}')
Inputs shape (batch, time, features): (32, 24, 19) Labels shape (batch, time, features): (32, 24, 19)
উপরে উল্লেখ্য যে লেবেলের features অক্ষে এখন 1 এর পরিবর্তে ইনপুটগুলির মতো একই গভীরতা রয়েছে।
বেসলাইন
একই বেসলাইন মডেল ( Baseline ) এখানে ব্যবহার করা যেতে পারে, কিন্তু এইবার একটি নির্দিষ্ট label_index নির্বাচন করার পরিবর্তে সমস্ত বৈশিষ্ট্য পুনরাবৃত্তি করা হচ্ছে:
baseline = Baseline()
baseline.compile(loss=tf.losses.MeanSquaredError(),
metrics=[tf.metrics.MeanAbsoluteError()])
val_performance = {}
performance = {}
val_performance['Baseline'] = baseline.evaluate(wide_window.val)
performance['Baseline'] = baseline.evaluate(wide_window.test, verbose=0)
438/438 [==============================] - 1s 2ms/step - loss: 0.0886 - mean_absolute_error: 0.1589
ঘন
dense = tf.keras.Sequential([
tf.keras.layers.Dense(units=64, activation='relu'),
tf.keras.layers.Dense(units=64, activation='relu'),
tf.keras.layers.Dense(units=num_features)
])
history = compile_and_fit(dense, single_step_window)
IPython.display.clear_output()
val_performance['Dense'] = dense.evaluate(single_step_window.val)
performance['Dense'] = dense.evaluate(single_step_window.test, verbose=0)
439/439 [==============================] - 1s 3ms/step - loss: 0.0687 - mean_absolute_error: 0.1302
আরএনএন
%%time
wide_window = WindowGenerator(
input_width=24, label_width=24, shift=1)
lstm_model = tf.keras.models.Sequential([
# Shape [batch, time, features] => [batch, time, lstm_units]
tf.keras.layers.LSTM(32, return_sequences=True),
# Shape => [batch, time, features]
tf.keras.layers.Dense(units=num_features)
])
history = compile_and_fit(lstm_model, wide_window)
IPython.display.clear_output()
val_performance['LSTM'] = lstm_model.evaluate( wide_window.val)
performance['LSTM'] = lstm_model.evaluate( wide_window.test, verbose=0)
print()
438/438 [==============================] - 1s 3ms/step - loss: 0.0617 - mean_absolute_error: 0.1205 CPU times: user 5min 14s, sys: 1min 17s, total: 6min 31s Wall time: 2min 8s
উন্নত: অবশিষ্ট সংযোগ
আগের থেকে Baseline মডেলটি এই সত্যটির সুবিধা নিয়েছে যে ক্রমটি সময়ে সময়ে ধাপে ধাপে ব্যাপকভাবে পরিবর্তিত হয় না। এই টিউটোরিয়ালে এখন পর্যন্ত প্রশিক্ষিত প্রতিটি মডেল এলোমেলোভাবে শুরু করা হয়েছিল, এবং তারপরে শিখতে হয়েছিল যে আউটপুটটি আগের সময়ের ধাপ থেকে একটি ছোট পরিবর্তন।
যদিও আপনি সতর্কতার সাথে শুরু করার সাথে এই সমস্যাটি পেতে পারেন, এটি মডেল কাঠামোতে তৈরি করা সহজ।
মডেলগুলি তৈরি করার সময় সিরিজ বিশ্লেষণে এটি সাধারণ যে পরবর্তী মানের ভবিষ্যদ্বাণী করার পরিবর্তে, পরবর্তী সময়ের ধাপে মানটি কীভাবে পরিবর্তিত হবে তা ভবিষ্যদ্বাণী করে। একইভাবে, অবশিষ্ট নেটওয়ার্কগুলি —বা ResNets—গভীর শিক্ষায় স্থাপত্যকে বোঝায় যেখানে প্রতিটি স্তর মডেলের সঞ্চিত ফলাফলে যোগ করে।
এইভাবে আপনি জ্ঞানের সদ্ব্যবহার করেন যে পরিবর্তনটি ছোট হওয়া উচিত।
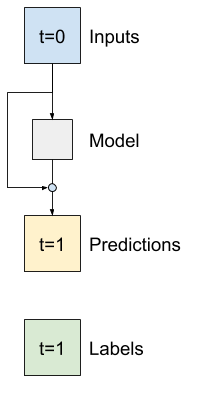
মূলত, এটি বেসলাইনের সাথে মেলে Baseline আরম্ভ করে। এই কাজের জন্য এটি মডেলগুলিকে আরও দ্রুত একত্রিত হতে সাহায্য করে, সামান্য ভাল কর্মক্ষমতা সহ।
এই পদ্ধতিটি এই টিউটোরিয়ালে আলোচিত যে কোনও মডেলের সাথে একত্রে ব্যবহার করা যেতে পারে।
এখানে, এটি LSTM মডেলে প্রয়োগ করা হচ্ছে, tf.initializers.zeros এর ব্যবহার লক্ষ্য করুন যাতে প্রাথমিক ভবিষ্যদ্বাণী করা পরিবর্তনগুলি ছোট হয় এবং অবশিষ্ট সংযোগের উপর প্রভাব ফেলবে না। এখানে গ্রেডিয়েন্টের জন্য কোন প্রতিসাম্য-ভাঙ্গা উদ্বেগ নেই, যেহেতু zeros শুধুমাত্র শেষ স্তরে ব্যবহার করা হয়।
class ResidualWrapper(tf.keras.Model):
def __init__(self, model):
super().__init__()
self.model = model
def call(self, inputs, *args, **kwargs):
delta = self.model(inputs, *args, **kwargs)
# The prediction for each time step is the input
# from the previous time step plus the delta
# calculated by the model.
return inputs + delta
%%time
residual_lstm = ResidualWrapper(
tf.keras.Sequential([
tf.keras.layers.LSTM(32, return_sequences=True),
tf.keras.layers.Dense(
num_features,
# The predicted deltas should start small.
# Therefore, initialize the output layer with zeros.
kernel_initializer=tf.initializers.zeros())
]))
history = compile_and_fit(residual_lstm, wide_window)
IPython.display.clear_output()
val_performance['Residual LSTM'] = residual_lstm.evaluate(wide_window.val)
performance['Residual LSTM'] = residual_lstm.evaluate(wide_window.test, verbose=0)
print()
438/438 [==============================] - 1s 3ms/step - loss: 0.0620 - mean_absolute_error: 0.1179 CPU times: user 1min 43s, sys: 26.1 s, total: 2min 9s Wall time: 43.1 s
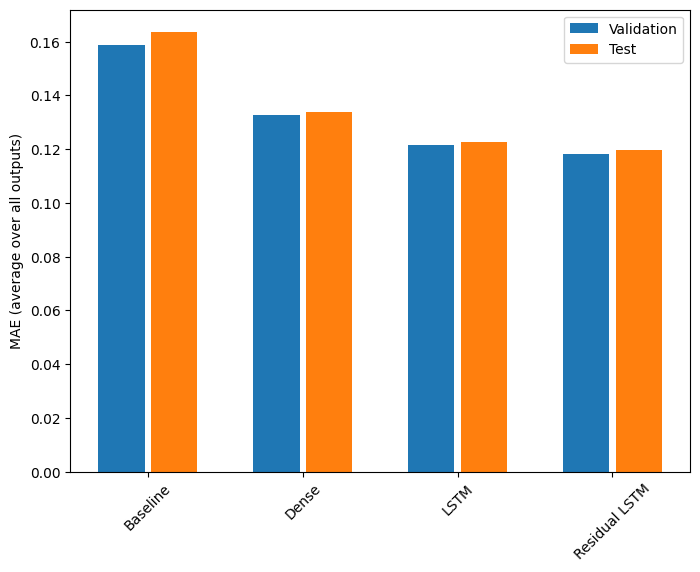
কর্মক্ষমতা
এই মাল্টি-আউটপুট মডেলগুলির সামগ্রিক কর্মক্ষমতা এখানে।
x = np.arange(len(performance))
width = 0.3
metric_name = 'mean_absolute_error'
metric_index = lstm_model.metrics_names.index('mean_absolute_error')
val_mae = [v[metric_index] for v in val_performance.values()]
test_mae = [v[metric_index] for v in performance.values()]
plt.bar(x - 0.17, val_mae, width, label='Validation')
plt.bar(x + 0.17, test_mae, width, label='Test')
plt.xticks(ticks=x, labels=performance.keys(),
rotation=45)
plt.ylabel('MAE (average over all outputs)')
_ = plt.legend()
for name, value in performance.items():
print(f'{name:15s}: {value[1]:0.4f}')
Baseline : 0.1638 Dense : 0.1311 LSTM : 0.1214 Residual LSTM : 0.1194
উপরের পারফরম্যান্সগুলি সমস্ত মডেল আউটপুট জুড়ে গড় করা হয়।
মাল্টি-স্টেপ মডেল
পূর্ববর্তী বিভাগে একক-আউটপুট এবং একাধিক-আউটপুট মডেল উভয়ই একক সময়ের পদক্ষেপের ভবিষ্যদ্বাণী করেছে, ভবিষ্যতে এক ঘন্টা।
এই বিভাগটি একাধিক সময়ের পদক্ষেপের ভবিষ্যদ্বাণী করতে এই মডেলগুলিকে কীভাবে প্রসারিত করতে হয় তা দেখায়।
একটি মাল্টি-স্টেপ ভবিষ্যদ্বাণীতে, মডেলটিকে ভবিষ্যতের মানগুলির একটি পরিসীমা ভবিষ্যদ্বাণী করতে শিখতে হবে। এইভাবে, একটি একক পদক্ষেপ মডেলের বিপরীতে, যেখানে শুধুমাত্র একটি একক ভবিষ্যত বিন্দুর পূর্বাভাস দেওয়া হয়, একটি বহু-পদক্ষেপ মডেল ভবিষ্যতের মানগুলির একটি অনুক্রমের পূর্বাভাস দেয়।
এর জন্য দুটি রুক্ষ পন্থা রয়েছে:
- একক শট ভবিষ্যদ্বাণী যেখানে সমগ্র সময়ের সিরিজ একবারে ভবিষ্যদ্বাণী করা হয়।
- অটোরিগ্রেসিভ ভবিষ্যদ্বাণী যেখানে মডেলটি শুধুমাত্র একক ধাপের ভবিষ্যদ্বাণী করে এবং এর আউটপুটটি তার ইনপুট হিসাবে ফেরত দেওয়া হয়।
এই বিভাগে সমস্ত মডেল সমস্ত আউটপুট সময় ধাপে সমস্ত বৈশিষ্ট্যের পূর্বাভাস দেবে।
মাল্টি-স্টেপ মডেলের জন্য, প্রশিক্ষণের ডেটা আবার ঘন্টায় নমুনা নিয়ে গঠিত। যাইহোক, এখানে, মডেলগুলি অতীতের 24 ঘন্টা দেওয়া ভবিষ্যতের 24 ঘন্টা ভবিষ্যদ্বাণী করতে শিখবে।
এখানে একটি Window অবজেক্ট রয়েছে যা ডেটাসেট থেকে এই স্লাইসগুলি তৈরি করে:
OUT_STEPS = 24
multi_window = WindowGenerator(input_width=24,
label_width=OUT_STEPS,
shift=OUT_STEPS)
multi_window.plot()
multi_window
Total window size: 48 Input indices: [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23] Label indices: [24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47] Label column name(s): None
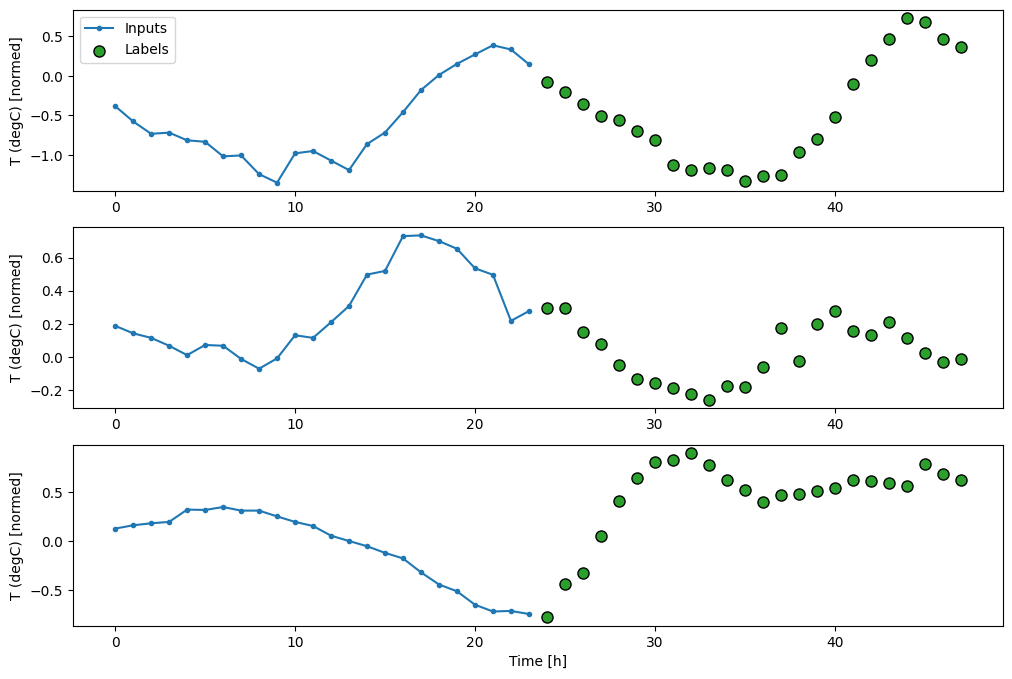
বেসলাইন
এই কাজের জন্য একটি সাধারণ বেসলাইন হল প্রয়োজনীয় সংখ্যক আউটপুট সময় ধাপের জন্য শেষ ইনপুট সময় ধাপটি পুনরাবৃত্তি করা:
class MultiStepLastBaseline(tf.keras.Model):
def call(self, inputs):
return tf.tile(inputs[:, -1:, :], [1, OUT_STEPS, 1])
last_baseline = MultiStepLastBaseline()
last_baseline.compile(loss=tf.losses.MeanSquaredError(),
metrics=[tf.metrics.MeanAbsoluteError()])
multi_val_performance = {}
multi_performance = {}
multi_val_performance['Last'] = last_baseline.evaluate(multi_window.val)
multi_performance['Last'] = last_baseline.evaluate(multi_window.test, verbose=0)
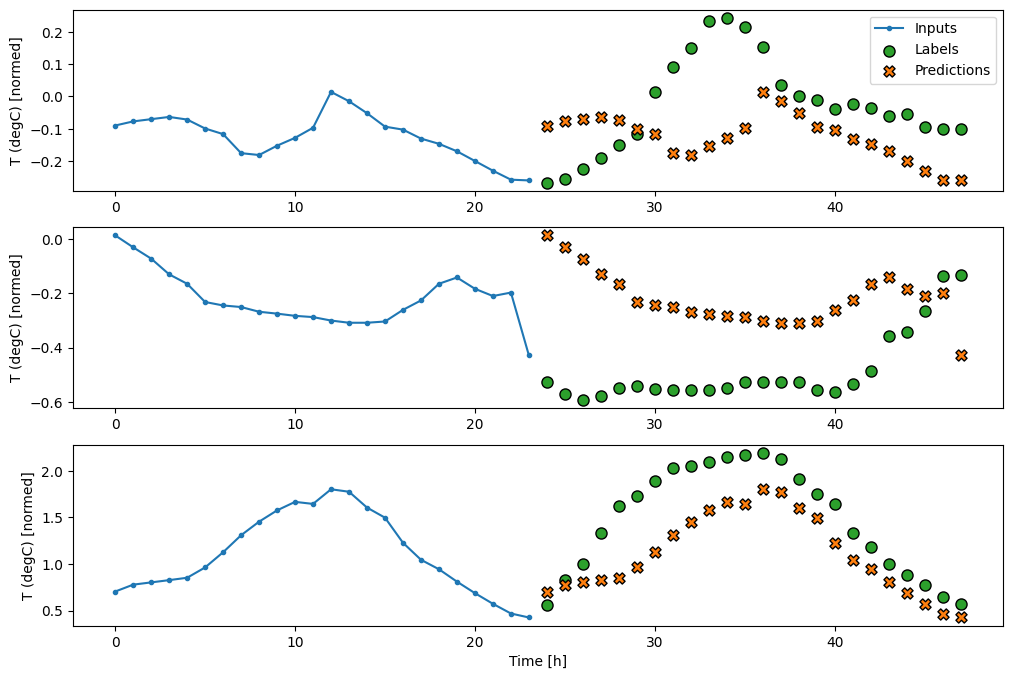
multi_window.plot(last_baseline)
437/437 [==============================] - 1s 2ms/step - loss: 0.6285 - mean_absolute_error: 0.5007
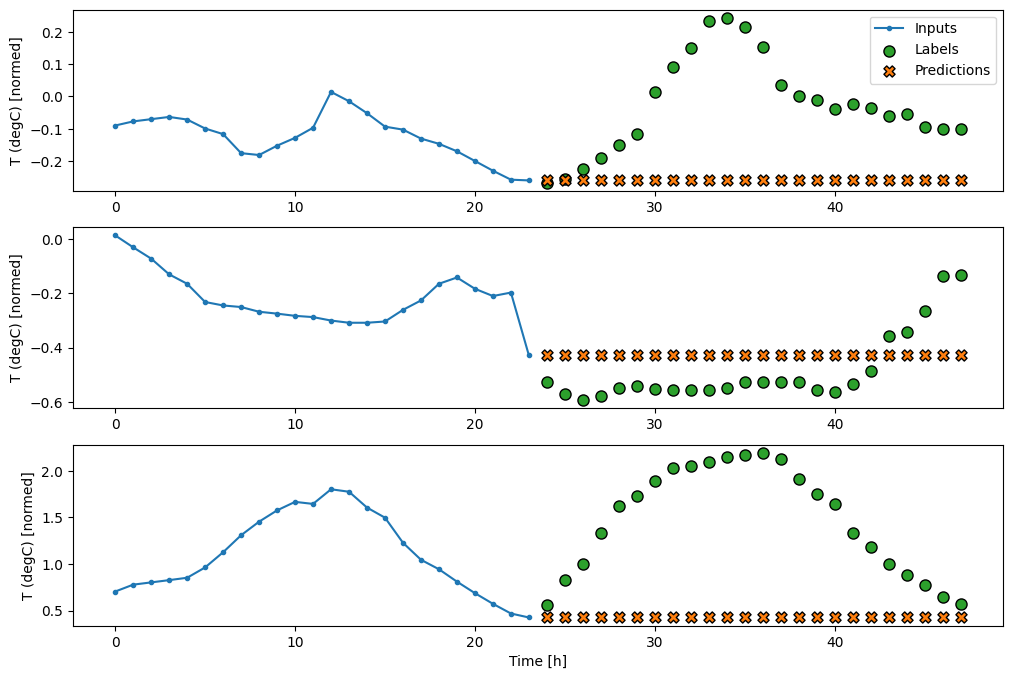
যেহেতু এই কাজটি হল ভবিষ্যতের 24 ঘন্টা ভবিষ্যদ্বাণী করা, অতীতের 24 ঘন্টা দেওয়া, আরেকটি সহজ পদ্ধতি হল আগের দিনের পুনরাবৃত্তি করা, ধরে নেওয়া আগামীকাল একই রকম হবে:
class RepeatBaseline(tf.keras.Model):
def call(self, inputs):
return inputs
repeat_baseline = RepeatBaseline()
repeat_baseline.compile(loss=tf.losses.MeanSquaredError(),
metrics=[tf.metrics.MeanAbsoluteError()])
multi_val_performance['Repeat'] = repeat_baseline.evaluate(multi_window.val)
multi_performance['Repeat'] = repeat_baseline.evaluate(multi_window.test, verbose=0)
multi_window.plot(repeat_baseline)
437/437 [==============================] - 1s 2ms/step - loss: 0.4270 - mean_absolute_error: 0.3959
একক শট মডেল
এই সমস্যাটির জন্য একটি উচ্চ-স্তরের পদ্ধতি হল একটি "একক-শট" মডেল ব্যবহার করা, যেখানে মডেলটি একটি একক ধাপে সম্পূর্ণ অনুক্রমের পূর্বাভাস দেয়।
এটি একটি tf.keras.layers.Dense হিসাবে দক্ষতার সাথে প্রয়োগ করা যেতে পারে। OUT_STEPS*features আউটপুট ইউনিটগুলির সাথে ঘন। মডেলটিকে কেবলমাত্র সেই আউটপুটটিকে প্রয়োজনীয় (OUTPUT_STEPS, features) দিতে হবে।
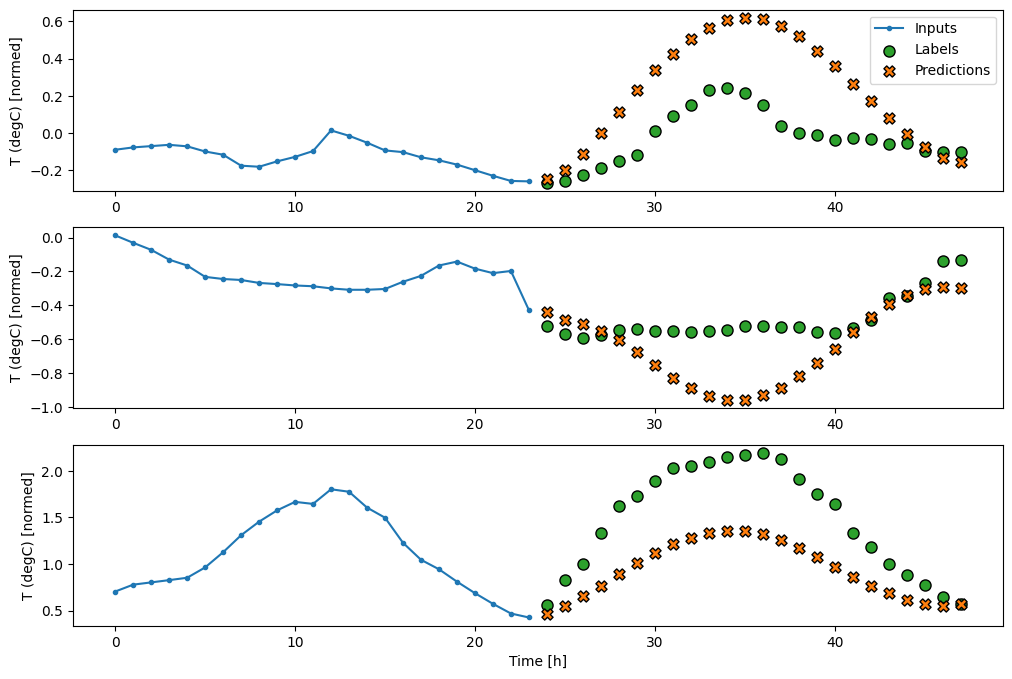
রৈখিক
শেষ ইনপুট টাইম ধাপের উপর ভিত্তি করে একটি সাধারণ রৈখিক মডেল বেসলাইনের চেয়ে ভাল করে, কিন্তু কম শক্তিযুক্ত। মডেলটিকে OUTPUT_STEPS সময় পদক্ষেপের পূর্বাভাস দিতে হবে, একটি লিনিয়ার প্রজেকশন সহ একটি একক ইনপুট সময় ধাপ থেকে। এটি শুধুমাত্র আচরণের একটি নিম্ন-মাত্রিক স্লাইস ক্যাপচার করতে পারে, সম্ভবত প্রধানত দিনের সময় এবং বছরের সময়ের উপর ভিত্তি করে।
multi_linear_model = tf.keras.Sequential([
# Take the last time-step.
# Shape [batch, time, features] => [batch, 1, features]
tf.keras.layers.Lambda(lambda x: x[:, -1:, :]),
# Shape => [batch, 1, out_steps*features]
tf.keras.layers.Dense(OUT_STEPS*num_features,
kernel_initializer=tf.initializers.zeros()),
# Shape => [batch, out_steps, features]
tf.keras.layers.Reshape([OUT_STEPS, num_features])
])
history = compile_and_fit(multi_linear_model, multi_window)
IPython.display.clear_output()
multi_val_performance['Linear'] = multi_linear_model.evaluate(multi_window.val)
multi_performance['Linear'] = multi_linear_model.evaluate(multi_window.test, verbose=0)
multi_window.plot(multi_linear_model)
437/437 [==============================] - 1s 2ms/step - loss: 0.2559 - mean_absolute_error: 0.3053
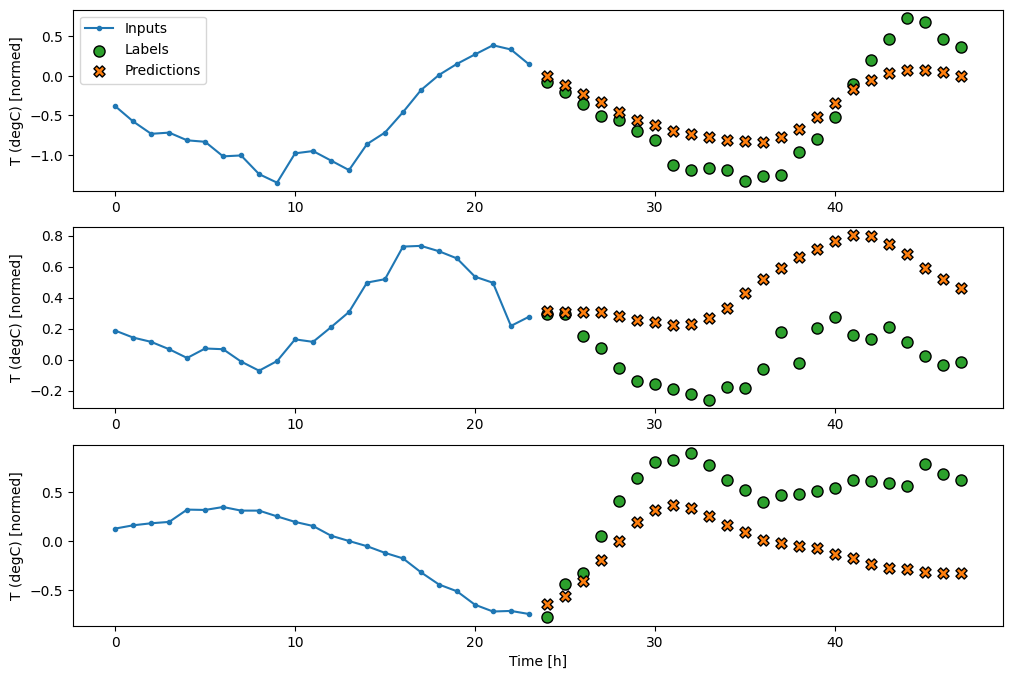
ঘন
ইনপুট এবং আউটপুটের মধ্যে একটি tf.keras.layers.Dense যোগ করা রৈখিক মডেলটিকে আরও শক্তি দেয়, কিন্তু এখনও শুধুমাত্র একটি ইনপুট সময় ধাপের উপর ভিত্তি করে।
multi_dense_model = tf.keras.Sequential([
# Take the last time step.
# Shape [batch, time, features] => [batch, 1, features]
tf.keras.layers.Lambda(lambda x: x[:, -1:, :]),
# Shape => [batch, 1, dense_units]
tf.keras.layers.Dense(512, activation='relu'),
# Shape => [batch, out_steps*features]
tf.keras.layers.Dense(OUT_STEPS*num_features,
kernel_initializer=tf.initializers.zeros()),
# Shape => [batch, out_steps, features]
tf.keras.layers.Reshape([OUT_STEPS, num_features])
])
history = compile_and_fit(multi_dense_model, multi_window)
IPython.display.clear_output()
multi_val_performance['Dense'] = multi_dense_model.evaluate(multi_window.val)
multi_performance['Dense'] = multi_dense_model.evaluate(multi_window.test, verbose=0)
multi_window.plot(multi_dense_model)
437/437 [==============================] - 1s 3ms/step - loss: 0.2205 - mean_absolute_error: 0.2837
সিএনএন
একটি কনভোল্যুশনাল মডেল একটি নির্দিষ্ট-প্রস্থ ইতিহাসের উপর ভিত্তি করে ভবিষ্যদ্বাণী করে, যা ঘন মডেলের চেয়ে ভাল কার্যক্ষমতার দিকে নিয়ে যেতে পারে কারণ এটি দেখতে পারে যে সময়ের সাথে কীভাবে জিনিসগুলি পরিবর্তিত হচ্ছে:
CONV_WIDTH = 3
multi_conv_model = tf.keras.Sequential([
# Shape [batch, time, features] => [batch, CONV_WIDTH, features]
tf.keras.layers.Lambda(lambda x: x[:, -CONV_WIDTH:, :]),
# Shape => [batch, 1, conv_units]
tf.keras.layers.Conv1D(256, activation='relu', kernel_size=(CONV_WIDTH)),
# Shape => [batch, 1, out_steps*features]
tf.keras.layers.Dense(OUT_STEPS*num_features,
kernel_initializer=tf.initializers.zeros()),
# Shape => [batch, out_steps, features]
tf.keras.layers.Reshape([OUT_STEPS, num_features])
])
history = compile_and_fit(multi_conv_model, multi_window)
IPython.display.clear_output()
multi_val_performance['Conv'] = multi_conv_model.evaluate(multi_window.val)
multi_performance['Conv'] = multi_conv_model.evaluate(multi_window.test, verbose=0)
multi_window.plot(multi_conv_model)
437/437 [==============================] - 1s 2ms/step - loss: 0.2158 - mean_absolute_error: 0.2833
আরএনএন
একটি পুনরাবৃত্ত মডেল ইনপুটগুলির একটি দীর্ঘ ইতিহাস ব্যবহার করতে শিখতে পারে, যদি এটি মডেলটি তৈরি করা ভবিষ্যদ্বাণীগুলির সাথে প্রাসঙ্গিক হয়। এখানে মডেলটি 24 ঘন্টার জন্য অভ্যন্তরীণ অবস্থা জমা করবে, পরবর্তী 24 ঘন্টার জন্য একটি একক ভবিষ্যদ্বাণী করার আগে।
এই একক-শট বিন্যাসে, LSTM-কে শুধুমাত্র শেষ সময়ে একটি আউটপুট তৈরি করতে হবে, তাই tf.keras.layers.LSTM-এ tf.keras.layers.LSTM return_sequences=False সেট করুন।
multi_lstm_model = tf.keras.Sequential([
# Shape [batch, time, features] => [batch, lstm_units].
# Adding more `lstm_units` just overfits more quickly.
tf.keras.layers.LSTM(32, return_sequences=False),
# Shape => [batch, out_steps*features].
tf.keras.layers.Dense(OUT_STEPS*num_features,
kernel_initializer=tf.initializers.zeros()),
# Shape => [batch, out_steps, features].
tf.keras.layers.Reshape([OUT_STEPS, num_features])
])
history = compile_and_fit(multi_lstm_model, multi_window)
IPython.display.clear_output()
multi_val_performance['LSTM'] = multi_lstm_model.evaluate(multi_window.val)
multi_performance['LSTM'] = multi_lstm_model.evaluate(multi_window.test, verbose=0)
multi_window.plot(multi_lstm_model)
437/437 [==============================] - 1s 3ms/step - loss: 0.2159 - mean_absolute_error: 0.2863
উন্নত: অটোরিগ্রেসিভ মডেল
উপরের মডেলগুলি সমস্ত একক ধাপে সম্পূর্ণ আউটপুট ক্রম অনুমান করে।
কিছু ক্ষেত্রে মডেলের জন্য এই ভবিষ্যদ্বাণীটিকে পৃথক সময়ের ধাপে পচানো সহায়ক হতে পারে। তারপরে, প্রতিটি মডেলের আউটপুট প্রতিটি ধাপে নিজের মধ্যে ফেরত দেওয়া যেতে পারে এবং পূর্বাভাসগুলি আগেরটির উপর শর্তযুক্ত করা যেতে পারে, যেমন ক্লাসিক জেনারেটিং সিকোয়েন্স উইথ রিকারেন্ট নিউরাল নেটওয়ার্ক ।
মডেলের এই শৈলীর একটি সুস্পষ্ট সুবিধা হল যে এটি একটি পরিবর্তিত দৈর্ঘ্যের সাথে আউটপুট উত্পাদন করতে সেট আপ করা যেতে পারে।
আপনি এই টিউটোরিয়ালের প্রথমার্ধে প্রশিক্ষিত যেকোন একক-পদক্ষেপ মাল্টি-আউটপুট মডেল নিতে পারেন এবং একটি অটোরিগ্রেসিভ ফিডব্যাক লুপে চালাতে পারেন, কিন্তু এখানে আপনি একটি মডেল তৈরিতে ফোকাস করবেন যা স্পষ্টভাবে এটি করার জন্য প্রশিক্ষিত।
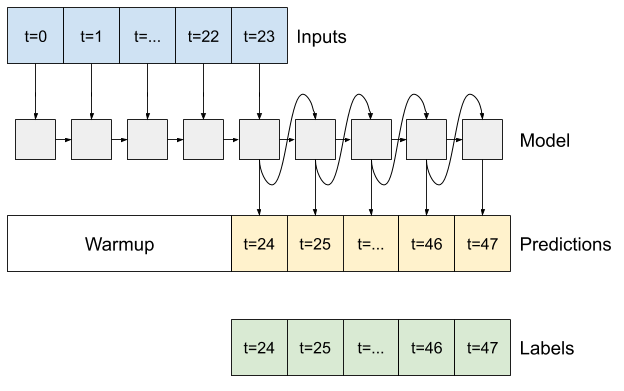
আরএনএন
এই টিউটোরিয়ালটি শুধুমাত্র একটি অটোরিগ্রেসিভ RNN মডেল তৈরি করে, কিন্তু এই প্যাটার্নটি যেকোন মডেলে প্রয়োগ করা যেতে পারে যা একটি একক ধাপ আউটপুট করার জন্য ডিজাইন করা হয়েছিল।
মডেলটির পূর্বের একক-পদক্ষেপ LSTM মডেলগুলির মতো একই মৌলিক রূপ থাকবে: একটি tf.keras.layers.LSTM স্তর এবং একটি tf.keras.layers.Dense স্তর যা LSTM স্তরের আউটপুটগুলিকে মডেল পূর্বাভাসে রূপান্তর করে৷
একটি tf.keras.layers.LSTM হল একটি tf.keras.layers.LSTMCell উচ্চ স্তরের tf.keras.layers.RNN এ মোড়ানো যা আপনার জন্য অবস্থা এবং ক্রম ফলাফলগুলি পরিচালনা করে (কেরাসের সাথে পুনরাবৃত্তি নিউরাল নেটওয়ার্ক (RNN) দেখুন বিস্তারিত জানার জন্য গাইড)।
এই ক্ষেত্রে, মডেলটিকে প্রতিটি ধাপের জন্য ম্যানুয়ালি ইনপুটগুলি পরিচালনা করতে হবে, তাই এটি নিম্ন স্তরের জন্য সরাসরি tf.keras.layers.LSTMCell ব্যবহার করে, একক সময় পদক্ষেপ ইন্টারফেস।
class FeedBack(tf.keras.Model):
def __init__(self, units, out_steps):
super().__init__()
self.out_steps = out_steps
self.units = units
self.lstm_cell = tf.keras.layers.LSTMCell(units)
# Also wrap the LSTMCell in an RNN to simplify the `warmup` method.
self.lstm_rnn = tf.keras.layers.RNN(self.lstm_cell, return_state=True)
self.dense = tf.keras.layers.Dense(num_features)
feedback_model = FeedBack(units=32, out_steps=OUT_STEPS)
এই মডেলটির প্রথম যে পদ্ধতিটি প্রয়োজন তা হল ইনপুটগুলির উপর ভিত্তি করে এর অভ্যন্তরীণ অবস্থা শুরু করার জন্য একটি warmup পদ্ধতি। একবার প্রশিক্ষিত হলে, এই রাজ্য ইনপুট ইতিহাসের প্রাসঙ্গিক অংশগুলি ক্যাপচার করবে। এটি আগের থেকে একক-পদক্ষেপ LSTM মডেলের সমতুল্য:
def warmup(self, inputs):
# inputs.shape => (batch, time, features)
# x.shape => (batch, lstm_units)
x, *state = self.lstm_rnn(inputs)
# predictions.shape => (batch, features)
prediction = self.dense(x)
return prediction, state
FeedBack.warmup = warmup
এই পদ্ধতিটি একটি একক সময়-পদক্ষেপ পূর্বাভাস এবং LSTM এর অভ্যন্তরীণ অবস্থা প্রদান করে:
prediction, state = feedback_model.warmup(multi_window.example[0])
prediction.shape
TensorShape([32, 19])
RNN এর অবস্থা, এবং একটি প্রাথমিক ভবিষ্যদ্বাণী দিয়ে আপনি এখন ইনপুট হিসাবে প্রতিটি ধাপে পূর্বাভাসগুলিকে ফিডিং মডেলটি পুনরাবৃত্তি করা চালিয়ে যেতে পারেন।
আউটপুট পূর্বাভাস সংগ্রহ করার জন্য সবচেয়ে সহজ পদ্ধতি হল একটি পাইথন তালিকা এবং লুপের পরে একটি tf.stack ব্যবহার করা।
def call(self, inputs, training=None):
# Use a TensorArray to capture dynamically unrolled outputs.
predictions = []
# Initialize the LSTM state.
prediction, state = self.warmup(inputs)
# Insert the first prediction.
predictions.append(prediction)
# Run the rest of the prediction steps.
for n in range(1, self.out_steps):
# Use the last prediction as input.
x = prediction
# Execute one lstm step.
x, state = self.lstm_cell(x, states=state,
training=training)
# Convert the lstm output to a prediction.
prediction = self.dense(x)
# Add the prediction to the output.
predictions.append(prediction)
# predictions.shape => (time, batch, features)
predictions = tf.stack(predictions)
# predictions.shape => (batch, time, features)
predictions = tf.transpose(predictions, [1, 0, 2])
return predictions
FeedBack.call = call
উদাহরণ ইনপুটগুলিতে এই মডেলটি পরীক্ষা করুন:
print('Output shape (batch, time, features): ', feedback_model(multi_window.example[0]).shape)
Output shape (batch, time, features): (32, 24, 19)
এখন, মডেলকে প্রশিক্ষণ দিন:
history = compile_and_fit(feedback_model, multi_window)
IPython.display.clear_output()
multi_val_performance['AR LSTM'] = feedback_model.evaluate(multi_window.val)
multi_performance['AR LSTM'] = feedback_model.evaluate(multi_window.test, verbose=0)
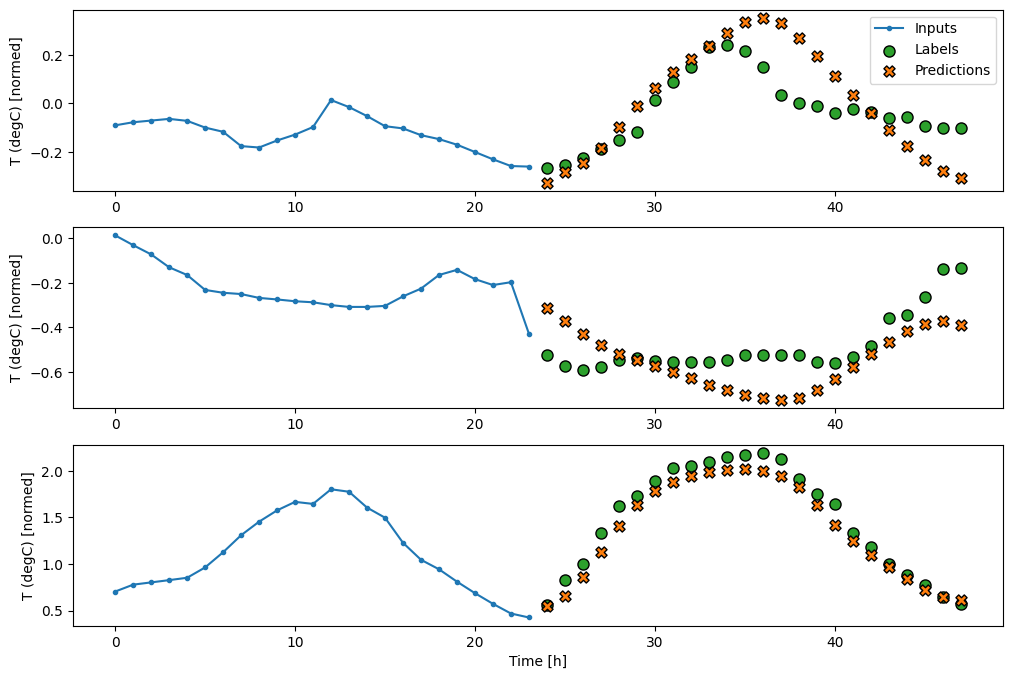
multi_window.plot(feedback_model)
437/437 [==============================] - 3s 8ms/step - loss: 0.2269 - mean_absolute_error: 0.3011
কর্মক্ষমতা
এই সমস্যাটিতে মডেল জটিলতার একটি ফাংশন হিসাবে স্পষ্টভাবে হ্রাসকারী রিটার্ন রয়েছে:
x = np.arange(len(multi_performance))
width = 0.3
metric_name = 'mean_absolute_error'
metric_index = lstm_model.metrics_names.index('mean_absolute_error')
val_mae = [v[metric_index] for v in multi_val_performance.values()]
test_mae = [v[metric_index] for v in multi_performance.values()]
plt.bar(x - 0.17, val_mae, width, label='Validation')
plt.bar(x + 0.17, test_mae, width, label='Test')
plt.xticks(ticks=x, labels=multi_performance.keys(),
rotation=45)
plt.ylabel(f'MAE (average over all times and outputs)')
_ = plt.legend()
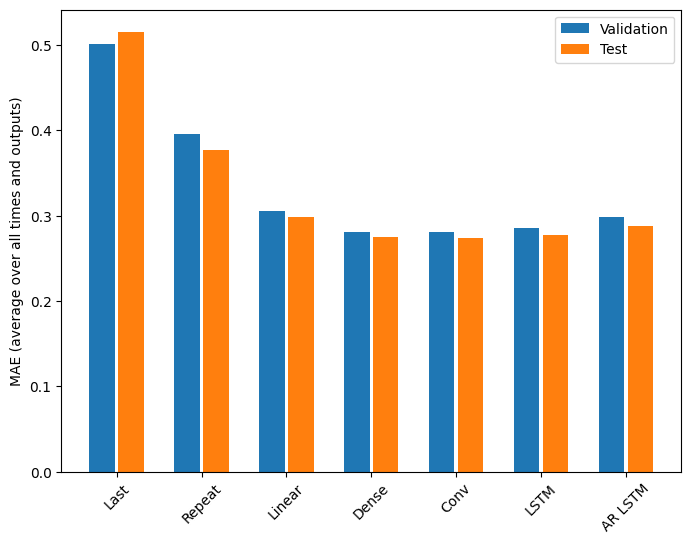
এই টিউটোরিয়ালের প্রথমার্ধে মাল্টি-আউটপুট মডেলের মেট্রিক্স সমস্ত আউটপুট বৈশিষ্ট্য জুড়ে কর্মক্ষমতা গড় দেখায়। এই পারফরম্যান্সগুলি একই রকম তবে আউটপুট সময় ধাপে গড়।
for name, value in multi_performance.items():
print(f'{name:8s}: {value[1]:0.4f}')
Last : 0.5157 Repeat : 0.3774 Linear : 0.2977 Dense : 0.2781 Conv : 0.2796 LSTM : 0.2767 AR LSTM : 0.2901
একটি ঘন মডেল থেকে কনভোল্যুশনাল এবং পৌনঃপুনিক মডেলে গিয়ে অর্জিত লাভগুলি মাত্র কয়েক শতাংশ (যদি থাকে), এবং অটোরিগ্রেসিভ মডেলটি স্পষ্টতই খারাপ কাজ করেছে। তাই এই সমস্যাটির সময় এই আরও জটিল পদ্ধতির মূল্য নাও হতে পারে, তবে চেষ্টা না করে জানার কোন উপায় ছিল না এবং এই মডেলগুলি আপনার সমস্যার জন্য সহায়ক হতে পারে।
পরবর্তী পদক্ষেপ
এই টিউটোরিয়ালটি টেনসরফ্লো ব্যবহার করে সময় সিরিজের পূর্বাভাসের একটি দ্রুত ভূমিকা ছিল।
আরও জানতে, পড়ুন:
- স্কিট-লার্ন, কেরাস এবং টেনসরফ্লো সহ হ্যান্ডস-অন মেশিন লার্নিং- এর 15 অধ্যায়, 2য় সংস্করণ।
- পাইথনের সাথে গভীর শিক্ষার অধ্যায় 6।
- ব্যায়াম নোটবুক সহ গভীর শিক্ষার জন্য TensorFlow-এ Udacity-এর ভূমিকার পাঠ 8।
এছাড়াও, মনে রাখবেন যে আপনি TensorFlow-এ যেকোন ক্লাসিক্যাল টাইম সিরিজ মডেল প্রয়োগ করতে পারেন—এই টিউটোরিয়ালটি শুধুমাত্র TensorFlow-এর অন্তর্নির্মিত কার্যকারিতার উপর ফোকাস করে।