
यह मार्गदर्शिका दर्शाती है कि आपके TensorFlow मॉडल के प्रदर्शन को ट्रैक करने के लिए TensorFlow प्रोफाइलर के साथ उपलब्ध टूल का उपयोग कैसे करें। आप सीखेंगे कि कैसे समझें कि आपका मॉडल होस्ट (सीपीयू), डिवाइस (जीपीयू), या होस्ट और डिवाइस दोनों के संयोजन पर कैसा प्रदर्शन करता है।
प्रोफाइलिंग आपके मॉडल में विभिन्न TensorFlow संचालन (ऑप्स) के हार्डवेयर संसाधन खपत (समय और मेमोरी) को समझने और प्रदर्शन बाधाओं को हल करने में मदद करती है और अंततः, मॉडल को तेजी से निष्पादित करती है।
यह मार्गदर्शिका आपको प्रोफाइलर को स्थापित करने के तरीके, उपलब्ध विभिन्न उपकरणों, प्रोफाइलर द्वारा प्रदर्शन डेटा एकत्र करने के विभिन्न तरीकों और मॉडल प्रदर्शन को अनुकूलित करने के लिए कुछ अनुशंसित सर्वोत्तम प्रथाओं के बारे में बताएगी।
यदि आप क्लाउड टीपीयू पर अपने मॉडल के प्रदर्शन को प्रोफाइल करना चाहते हैं, तो क्लाउड टीपीयू गाइड देखें।
प्रोफाइलर और जीपीयू आवश्यकताएँ स्थापित करें
पाइप के साथ TensorBoard के लिए प्रोफाइलर प्लगइन स्थापित करें। ध्यान दें कि प्रोफाइलर को TensorFlow और TensorBoard (>=2.2) के नवीनतम संस्करण की आवश्यकता है।
pip install -U tensorboard_plugin_profile
GPU पर प्रोफ़ाइल करने के लिए, आपको यह करना होगा:
- TensorFlow GPU समर्थन सॉफ़्टवेयर आवश्यकताओं पर सूचीबद्ध NVIDIA® GPU ड्राइवर और CUDA® टूलकिट आवश्यकताओं को पूरा करें।
सुनिश्चित करें कि NVIDIA® CUDA® प्रोफाइलिंग टूल इंटरफ़ेस (CUPTI) पथ पर मौजूद है:
/sbin/ldconfig -N -v $(sed 's/:/ /g' <<< $LD_LIBRARY_PATH) | \ grep libcupti
यदि आपके पास पथ पर CUPTI नहीं है, तो इसकी स्थापना निर्देशिका को चलाकर $LD_LIBRARY_PATH पर्यावरण चर में जोड़ें:
export LD_LIBRARY_PATH=/usr/local/cuda/extras/CUPTI/lib64:$LD_LIBRARY_PATH
फिर, यह सत्यापित करने के लिए कि CUPTI लाइब्रेरी मिल गई है, ऊपर दिए गए ldconfig कमांड को फिर से चलाएँ।
विशेषाधिकार संबंधी मुद्दों का समाधान करें
जब आप डॉकर वातावरण में या लिनक्स पर CUDA® टूलकिट के साथ प्रोफाइलिंग चलाते हैं, तो आपको अपर्याप्त CUPTI विशेषाधिकार ( CUPTI_ERROR_INSUFFICIENT_PRIVILEGES ) से संबंधित समस्याओं का सामना करना पड़ सकता है। आप Linux पर इन समस्याओं को कैसे हल कर सकते हैं, इसके बारे में अधिक जानने के लिए NVIDIA डेवलपर दस्तावेज़ पर जाएँ।
डॉकर परिवेश में CUPTI विशेषाधिकार समस्याओं को हल करने के लिए, चलाएँ
docker run option '--privileged=true'
प्रोफाइलर उपकरण
TensorBoard में प्रोफ़ाइल टैब से प्रोफाइलर तक पहुंचें, जो आपके द्वारा कुछ मॉडल डेटा कैप्चर करने के बाद ही दिखाई देता है।
प्रदर्शन विश्लेषण में सहायता के लिए प्रोफाइलर के पास उपकरणों का चयन है:
- सिंहावलोकन पृष्ठ
- इनपुट पाइपलाइन विश्लेषक
- टेंसरफ़्लो आँकड़े
- ट्रेस व्यूअर
- जीपीयू कर्नेल आँकड़े
- मेमोरी प्रोफाइल टूल
- पॉड व्यूअर
सिंहावलोकन पृष्ठ
अवलोकन पृष्ठ एक शीर्ष स्तरीय दृश्य प्रदान करता है कि प्रोफ़ाइल चलाने के दौरान आपके मॉडल ने कैसा प्रदर्शन किया। यह पृष्ठ आपको आपके होस्ट और सभी उपकरणों के लिए एक समग्र अवलोकन पृष्ठ और आपके मॉडल प्रशिक्षण प्रदर्शन को बेहतर बनाने के लिए कुछ अनुशंसाएँ दिखाता है। आप होस्ट ड्रॉपडाउन में अलग-अलग होस्ट भी चुन सकते हैं।
अवलोकन पृष्ठ निम्नानुसार डेटा प्रदर्शित करता है:
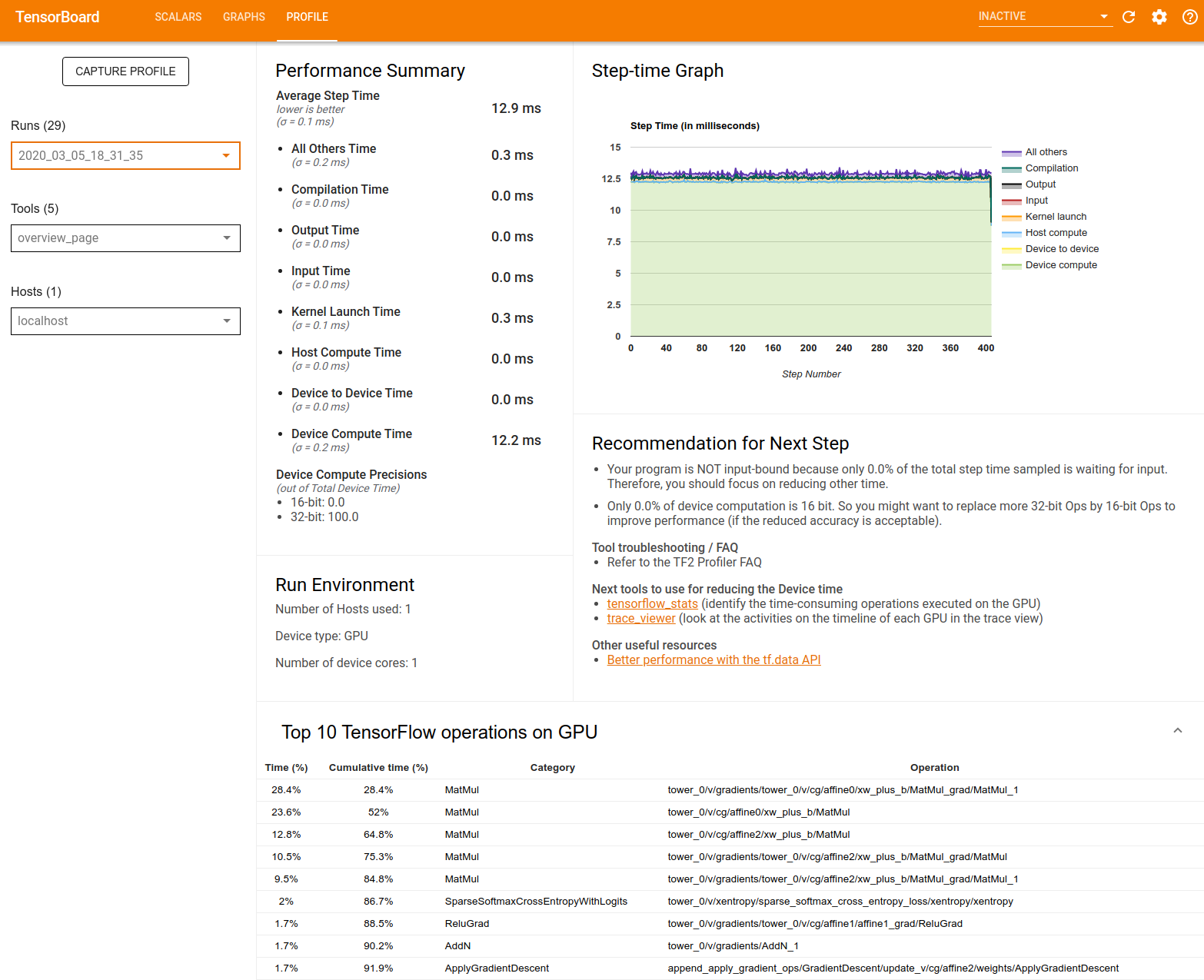
प्रदर्शन सारांश : आपके मॉडल के प्रदर्शन का उच्च-स्तरीय सारांश प्रदर्शित करता है। प्रदर्शन सारांश के दो भाग हैं:
चरण-समय विश्लेषण: औसत चरण समय को समय व्यतीत करने की कई श्रेणियों में विभाजित करता है:
- संकलन: गुठली संकलित करने में समय व्यतीत हुआ।
- इनपुट: इनपुट डेटा पढ़ने में लगा समय।
- आउटपुट: आउटपुट डेटा पढ़ने में लगा समय।
- कर्नेल लॉन्च: होस्ट द्वारा कर्नेल लॉन्च करने में बिताया गया समय
- होस्ट गणना समय..
- डिवाइस-टू-डिवाइस संचार समय.
- ऑन-डिवाइस गणना समय.
- पायथन ओवरहेड सहित अन्य सभी।
डिवाइस गणना सटीकता - 16 और 32-बिट गणनाओं का उपयोग करने वाले डिवाइस गणना समय के प्रतिशत की रिपोर्ट करता है।
चरण-समय ग्राफ़ : नमूना किए गए सभी चरणों पर डिवाइस चरण समय (मिलीसेकंड में) का एक ग्राफ़ प्रदर्शित करता है। प्रत्येक चरण को कई श्रेणियों (अलग-अलग रंगों के साथ) में विभाजित किया गया है, जहां समय बिताया जाता है। लाल क्षेत्र उस चरण के समय के भाग से मेल खाता है जब डिवाइस होस्ट से इनपुट डेटा की प्रतीक्षा में निष्क्रिय बैठे थे। हरा क्षेत्र दर्शाता है कि उपकरण वास्तव में कितने समय तक काम कर रहा था।
डिवाइस पर शीर्ष 10 TensorFlow ऑपरेशन (उदाहरण के लिए GPU) : सबसे लंबे समय तक चलने वाले ऑन-डिवाइस ऑप्स को प्रदर्शित करता है।
प्रत्येक पंक्ति एक ऑप का स्वयं का समय (सभी ऑप्स द्वारा लिए गए समय के प्रतिशत के रूप में), संचयी समय, श्रेणी और नाम प्रदर्शित करती है।
रन एनवायरनमेंट : मॉडल रन एनवायरनमेंट का उच्च-स्तरीय सारांश प्रदर्शित करता है, जिसमें शामिल हैं:
- प्रयुक्त होस्टों की संख्या.
- डिवाइस का प्रकार (जीपीयू/टीपीयू)।
- डिवाइस कोर की संख्या.
अगले चरण के लिए अनुशंसा : जब कोई मॉडल इनपुट बाउंड होता है तो रिपोर्ट करता है और उन टूल की अनुशंसा करता है जिनका उपयोग आप मॉडल प्रदर्शन बाधाओं का पता लगाने और उन्हें हल करने के लिए कर सकते हैं।
इनपुट पाइपलाइन विश्लेषक
जब कोई TensorFlow प्रोग्राम किसी फ़ाइल से डेटा पढ़ता है तो यह पाइपलाइन तरीके से TensorFlow ग्राफ़ के शीर्ष पर शुरू होता है। पढ़ने की प्रक्रिया को श्रृंखला में जुड़े कई डेटा प्रोसेसिंग चरणों में विभाजित किया गया है, जहां एक चरण का आउटपुट अगले चरण का इनपुट है। डेटा पढ़ने की इस प्रणाली को इनपुट पाइपलाइन कहा जाता है।
फ़ाइलों से रिकॉर्ड पढ़ने के लिए एक विशिष्ट पाइपलाइन में निम्नलिखित चरण होते हैं:
- फ़ाइल पढ़ना.
- फ़ाइल प्रीप्रोसेसिंग (वैकल्पिक)।
- होस्ट से डिवाइस में फ़ाइल स्थानांतरण।
एक अकुशल इनपुट पाइपलाइन आपके एप्लिकेशन को गंभीर रूप से धीमा कर सकती है। किसी एप्लिकेशन को इनपुट बाउंड तब माना जाता है जब वह समय का एक महत्वपूर्ण हिस्सा इनपुट पाइपलाइन में बिताता है। यह समझने के लिए कि इनपुट पाइपलाइन कहां अक्षम है, इनपुट पाइपलाइन विश्लेषक से प्राप्त अंतर्दृष्टि का उपयोग करें।
इनपुट पाइपलाइन विश्लेषक आपको तुरंत बताता है कि आपका प्रोग्राम इनपुट बाउंड है या नहीं और इनपुट पाइपलाइन में किसी भी चरण में प्रदर्शन बाधाओं को दूर करने के लिए डिवाइस- और होस्ट-साइड विश्लेषण के माध्यम से आपका मार्गदर्शन करता है।
अपने डेटा इनपुट पाइपलाइनों को अनुकूलित करने के लिए अनुशंसित सर्वोत्तम प्रथाओं के लिए इनपुट पाइपलाइन प्रदर्शन पर मार्गदर्शन की जाँच करें।
इनपुट पाइपलाइन डैशबोर्ड
इनपुट पाइपलाइन विश्लेषक खोलने के लिए, प्रोफ़ाइल चुनें, फिर टूल्स ड्रॉपडाउन से इनपुट_पाइपलाइन_एनालाइज़र चुनें।
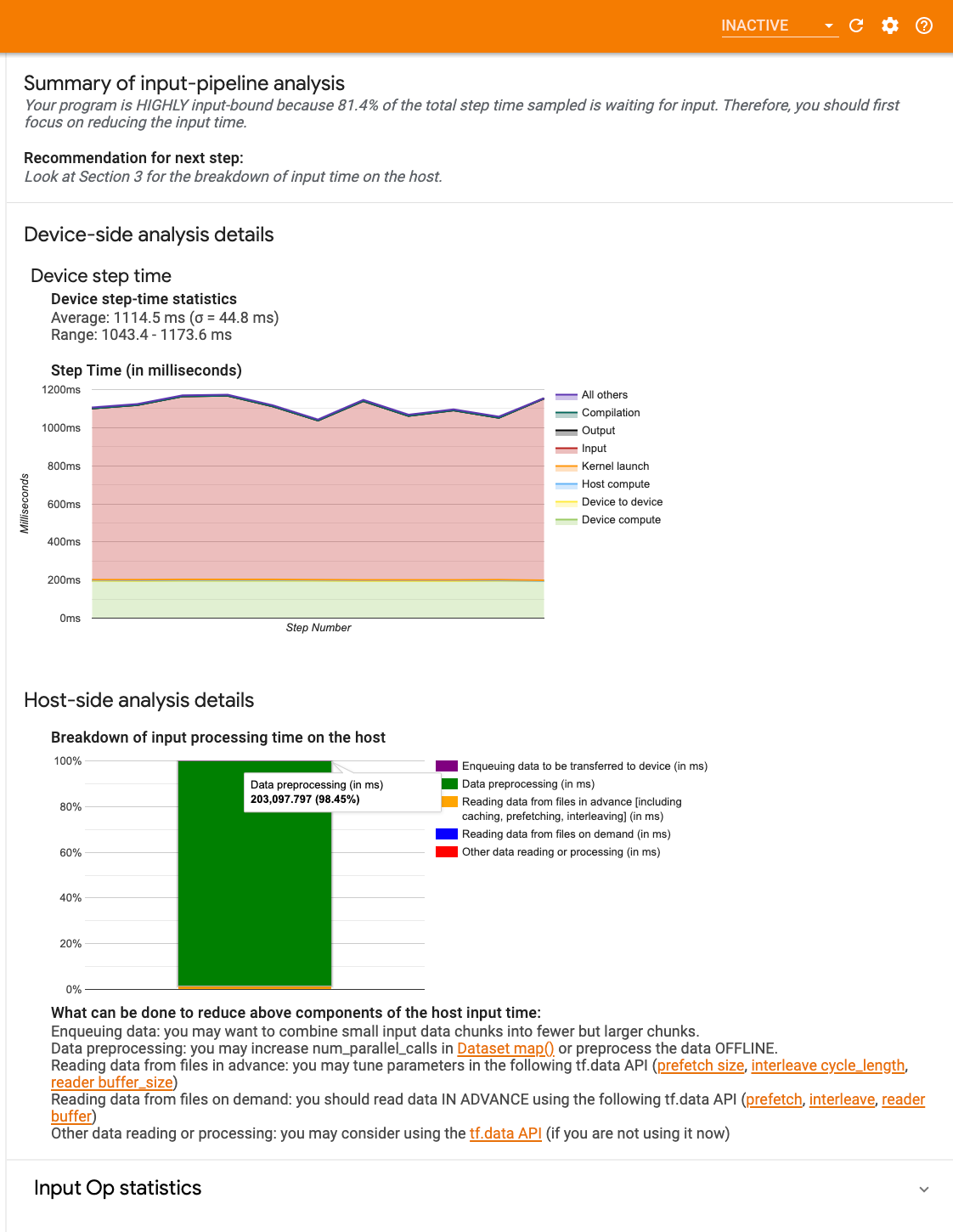
डैशबोर्ड में तीन अनुभाग हैं:
- सारांश : आपका एप्लिकेशन इनपुट बाउंड है या नहीं और यदि हां, तो कितना, इस जानकारी के साथ समग्र इनपुट पाइपलाइन का सारांश देता है।
- डिवाइस-साइड विश्लेषण : विस्तृत, डिवाइस-साइड विश्लेषण परिणाम प्रदर्शित करता है, जिसमें डिवाइस चरण-समय और प्रत्येक चरण पर कोर में इनपुट डेटा की प्रतीक्षा में बिताए गए डिवाइस समय की सीमा शामिल है।
- होस्ट-साइड विश्लेषण : होस्ट साइड पर एक विस्तृत विश्लेषण दिखाता है, जिसमें होस्ट पर इनपुट प्रोसेसिंग समय का विवरण भी शामिल है।
इनपुट पाइपलाइन सारांश
सारांश रिपोर्ट करता है कि क्या आपका प्रोग्राम होस्ट से इनपुट की प्रतीक्षा में खर्च किए गए डिवाइस समय का प्रतिशत प्रस्तुत करके इनपुट बाउंड है। यदि आप एक मानक इनपुट पाइपलाइन का उपयोग कर रहे हैं जिसे उपकरणबद्ध किया गया है, तो टूल रिपोर्ट करता है कि अधिकांश इनपुट प्रोसेसिंग समय कहाँ व्यतीत होता है।
डिवाइस-साइड विश्लेषण
डिवाइस-साइड विश्लेषण डिवाइस बनाम होस्ट पर बिताए गए समय और होस्ट से इनपुट डेटा की प्रतीक्षा में डिवाइस का कितना समय व्यतीत हुआ, इस पर अंतर्दृष्टि प्रदान करता है।
- चरण संख्या के विरुद्ध प्लॉट किया गया चरण समय : नमूना किए गए सभी चरणों पर डिवाइस चरण समय (मिलीसेकंड में) का एक ग्राफ प्रदर्शित करता है। प्रत्येक चरण को कई श्रेणियों (अलग-अलग रंगों के साथ) में विभाजित किया गया है, जहां समय बिताया जाता है। लाल क्षेत्र उस चरण के समय के भाग से मेल खाता है जब डिवाइस होस्ट से इनपुट डेटा की प्रतीक्षा में निष्क्रिय बैठे थे। हरा क्षेत्र दर्शाता है कि उपकरण वास्तव में कितने समय तक काम कर रहा था।
- चरण समय आँकड़े : डिवाइस चरण समय के औसत, मानक विचलन और सीमा ([न्यूनतम, अधिकतम]) की रिपोर्ट करता है।
होस्ट-साइड विश्लेषण
होस्ट-साइड विश्लेषण होस्ट पर इनपुट प्रोसेसिंग समय ( tf.data API ऑप्स पर बिताया गया समय) को कई श्रेणियों में विभाजित करने की रिपोर्ट करता है:
- मांग पर फ़ाइलों से डेटा पढ़ना : कैशिंग, प्रीफ़ेचिंग और इंटरलीविंग के बिना फ़ाइलों से डेटा पढ़ने में लगने वाला समय।
- फ़ाइलों से डेटा को पहले से पढ़ना : कैशिंग, प्रीफ़ेचिंग और इंटरलीविंग सहित फ़ाइलों को पढ़ने में लगने वाला समय।
- डेटा प्रीप्रोसेसिंग : प्रीप्रोसेसिंग ऑप्स पर खर्च किया गया समय, जैसे छवि डीकंप्रेसन।
- डिवाइस पर स्थानांतरित किए जाने वाले डेटा को कतारबद्ध करना : डिवाइस पर डेटा स्थानांतरित करने से पहले डेटा को इनफ़ीड कतार में डालने में लगने वाला समय।
निष्पादन समय के आधार पर अलग-अलग इनपुट ऑप्स और उनकी श्रेणियों के आँकड़ों का निरीक्षण करने के लिए इनपुट ऑप सांख्यिकी का विस्तार करें।
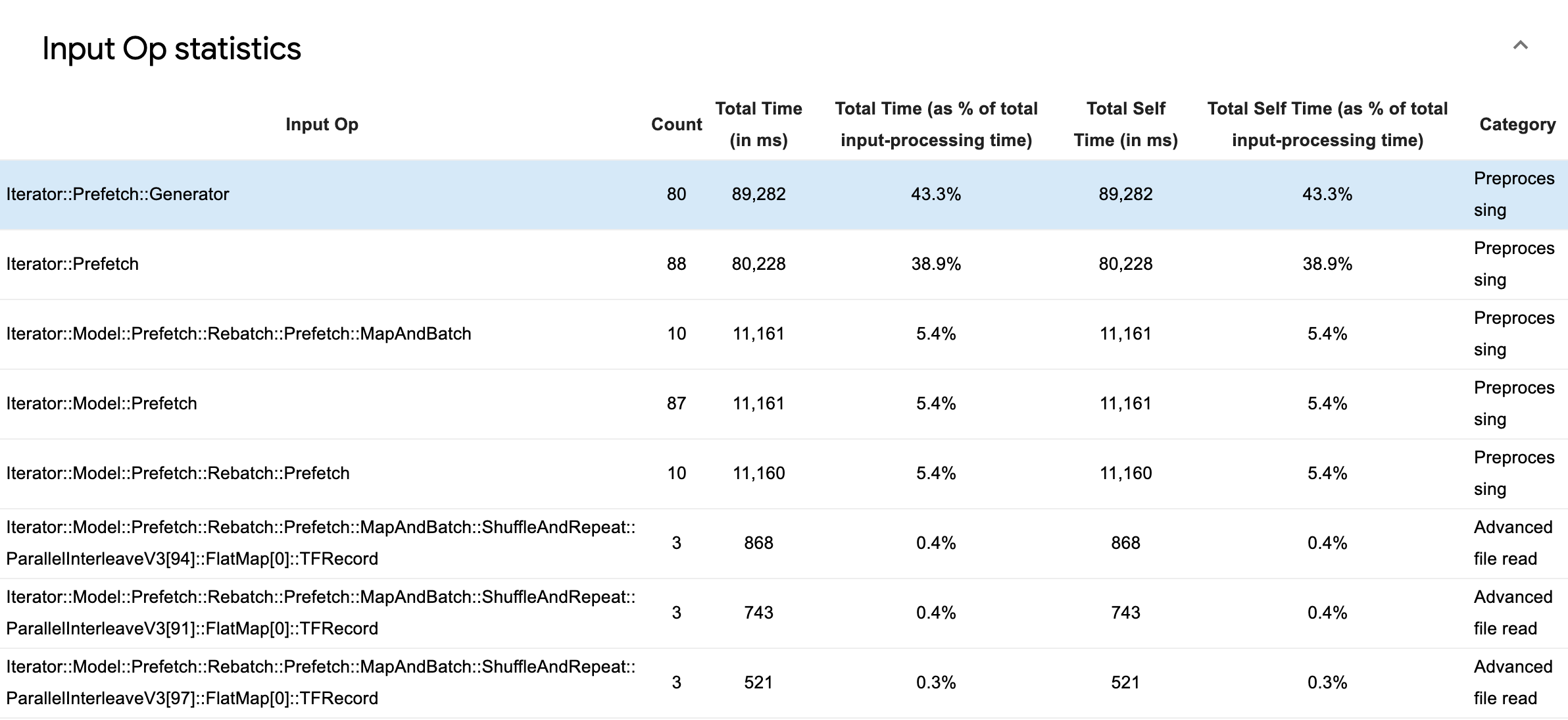
प्रत्येक प्रविष्टि के साथ एक स्रोत डेटा तालिका दिखाई देगी जिसमें निम्नलिखित जानकारी होगी:
- इनपुट ऑप : इनपुट ऑप का टेन्सरफ्लो ऑप नाम दिखाता है।
- गणना : प्रोफ़ाइलिंग अवधि के दौरान ऑप निष्पादन के उदाहरणों की कुल संख्या दिखाती है।
- कुल समय (एमएस में) : उनमें से प्रत्येक उदाहरण पर खर्च किए गए समय का संचयी योग दर्शाता है।
- कुल समय % : किसी ऑप पर बिताए गए कुल समय को इनपुट प्रोसेसिंग में बिताए गए कुल समय के एक अंश के रूप में दिखाता है।
- कुल स्व-समय (एमएस में) : उनमें से प्रत्येक उदाहरण पर खर्च किए गए स्व-समय का संचयी योग दर्शाता है। यहां सेल्फ टाइम फ़ंक्शन बॉडी के अंदर बिताए गए समय को मापता है, इसमें कॉल किए गए फ़ंक्शन में बिताए गए समय को छोड़कर।
- कुल स्व समय % . कुल स्व-समय को इनपुट प्रोसेसिंग पर खर्च किए गए कुल समय के एक अंश के रूप में दिखाता है।
- वर्ग । इनपुट ऑप की प्रोसेसिंग श्रेणी दिखाता है।
टेंसरफ़्लो आँकड़े
TensorFlow आँकड़े उपकरण प्रत्येक TensorFlow op (op) के प्रदर्शन को प्रदर्शित करता है जो प्रोफाइलिंग सत्र के दौरान होस्ट या डिवाइस पर निष्पादित होता है।
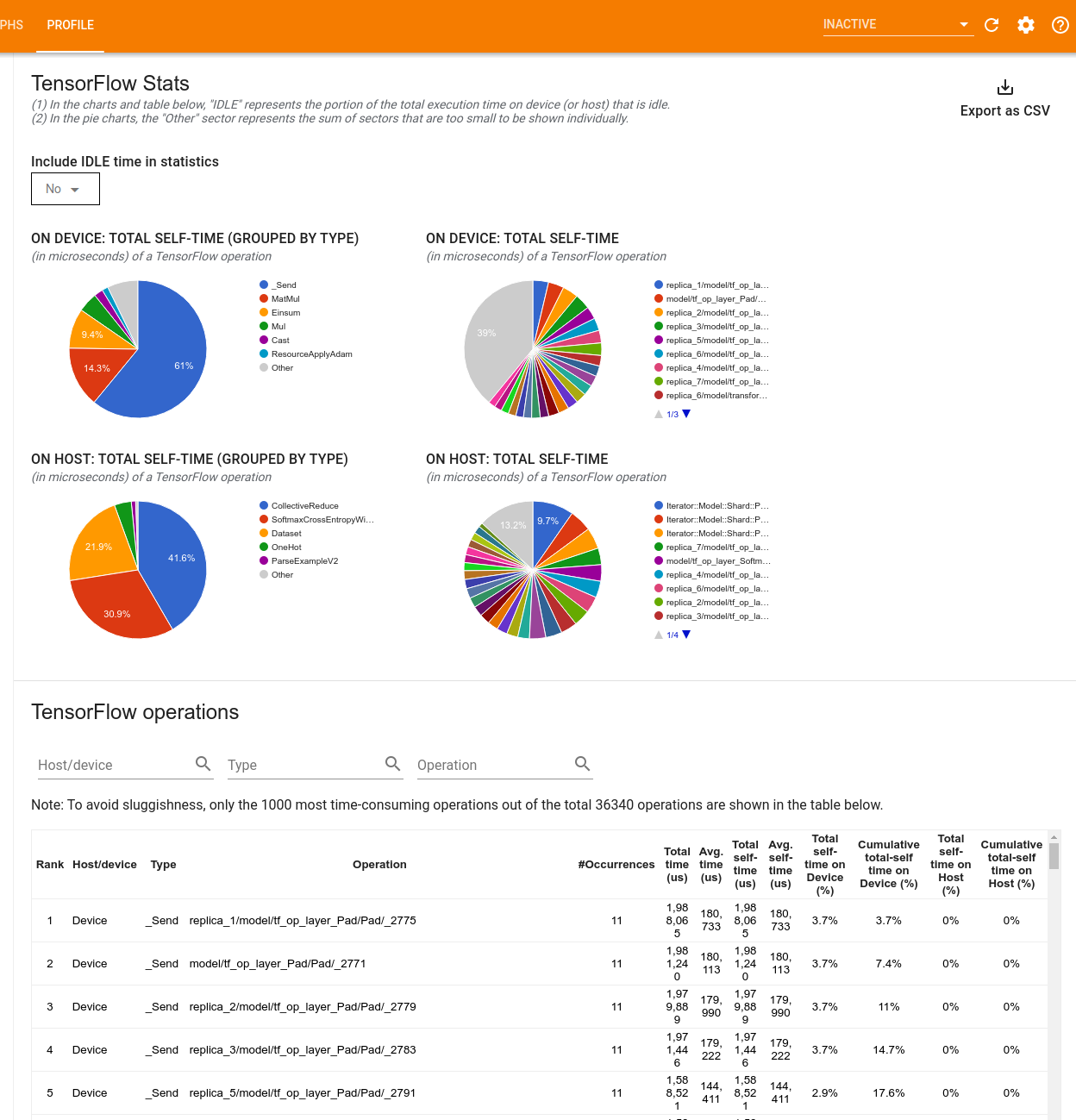
उपकरण दो फलक में प्रदर्शन जानकारी प्रदर्शित करता है:
ऊपरी फलक अधिकतम चार पाई चार्ट प्रदर्शित करता है:
- मेजबान पर प्रत्येक ऑप के स्व-निष्पादन समय का वितरण।
- होस्ट पर प्रत्येक ऑप प्रकार के स्व-निष्पादन समय का वितरण।
- डिवाइस पर प्रत्येक ऑप के स्व-निष्पादन समय का वितरण।
- डिवाइस पर प्रत्येक ऑप प्रकार के स्व-निष्पादन समय का वितरण।
निचला फलक एक तालिका दिखाता है जो प्रत्येक ऑप के लिए एक पंक्ति और प्रत्येक प्रकार के डेटा के लिए एक कॉलम के साथ टेन्सरफ्लो ऑप्स के बारे में डेटा रिपोर्ट करता है (कॉलम के शीर्षक पर क्लिक करके कॉलम को क्रमबद्ध करें)। इस तालिका से डेटा को CSV फ़ाइल के रूप में निर्यात करने के लिए ऊपरी फलक के दाईं ओर CSV के रूप में निर्यात करें बटन पर क्लिक करें।
ध्यान दें कि:
यदि किसी ऑप्स में चाइल्ड ऑप्स हैं:
- एक ऑप के कुल "संचित" समय में चाइल्ड ऑप्स के अंदर बिताया गया समय शामिल होता है।
- किसी ऑप के कुल "स्वयं" समय में चाइल्ड ऑप्स के अंदर बिताया गया समय शामिल नहीं होता है।
यदि कोई ऑप होस्ट पर निष्पादित होता है:
- ऑपरेशन द्वारा खर्च किए गए डिवाइस पर कुल स्व-समय का प्रतिशत 0 होगा।
- इस ऑप तक और इसमें शामिल डिवाइस पर कुल सेल्फ-टाइम का संचयी प्रतिशत 0 होगा।
यदि कोई ऑप डिवाइस पर निष्पादित होता है:
- इस ऑप द्वारा खर्च किए गए मेज़बान पर कुल स्व-समय का प्रतिशत 0 होगा।
- इस ऑप को शामिल करने तक होस्ट पर कुल सेल्फ-टाइम का संचयी प्रतिशत 0 होगा।
आप पाई चार्ट और तालिका में निष्क्रिय समय को शामिल या बाहर करना चुन सकते हैं।
दर्शक का पता लगाएं
ट्रेस व्यूअर एक टाइमलाइन प्रदर्शित करता है जो दिखाता है:
- आपके TensorFlow मॉडल द्वारा निष्पादित किए गए ऑप्स की अवधि
- सिस्टम के किस भाग (होस्ट या डिवाइस) ने एक ऑप निष्पादित किया। आमतौर पर, होस्ट इनपुट ऑपरेशंस निष्पादित करता है, प्रशिक्षण डेटा को प्रीप्रोसेस करता है और इसे डिवाइस में स्थानांतरित करता है, जबकि डिवाइस वास्तविक मॉडल प्रशिक्षण निष्पादित करता है
ट्रेस व्यूअर आपको अपने मॉडल में प्रदर्शन समस्याओं की पहचान करने, फिर उन्हें हल करने के लिए कदम उठाने की अनुमति देता है। उदाहरण के लिए, उच्च स्तर पर, आप पहचान सकते हैं कि इनपुट या मॉडल प्रशिक्षण में अधिकांश समय लग रहा है या नहीं। नीचे जाकर, आप पहचान सकते हैं कि कौन से ऑप्स को निष्पादित करने में सबसे अधिक समय लगता है। ध्यान दें कि ट्रेस व्यूअर प्रति डिवाइस 1 मिलियन इवेंट तक सीमित है।
व्यूअर इंटरफ़ेस का पता लगाएं
जब आप ट्रेस व्यूअर खोलते हैं, तो यह आपका सबसे हालिया रन प्रदर्शित करता हुआ दिखाई देता है:
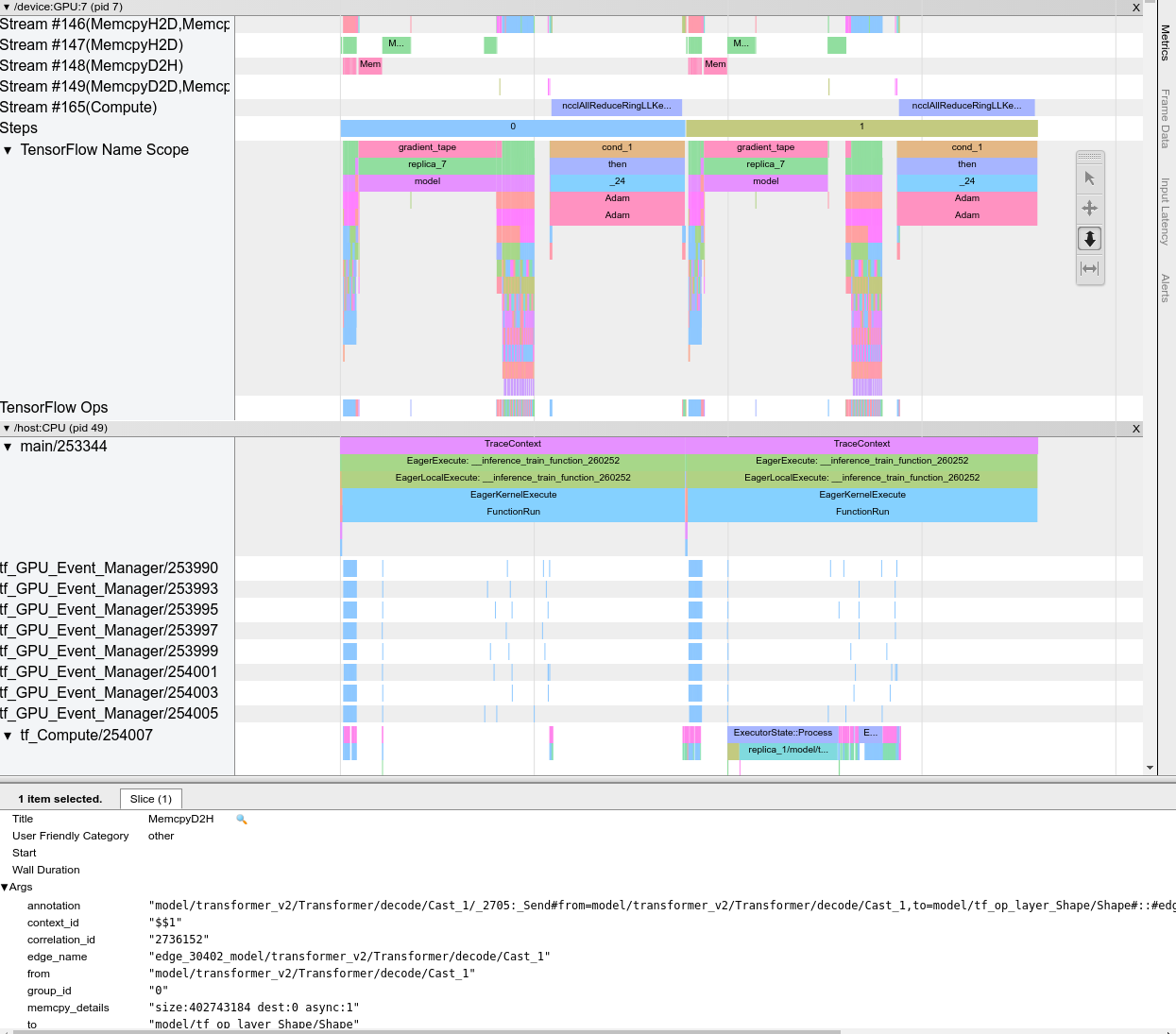
इस स्क्रीन में निम्नलिखित मुख्य तत्व हैं:
- टाइमलाइन फलक : ऑप्स दिखाता है कि डिवाइस और होस्ट समय के साथ निष्पादित हुए।
- विवरण फलक : टाइमलाइन फलक में चयनित ऑप्स के लिए अतिरिक्त जानकारी दिखाता है।
टाइमलाइन फलक में निम्नलिखित तत्व शामिल हैं:
- शीर्ष पट्टी : इसमें विभिन्न सहायक नियंत्रण शामिल हैं।
- समय अक्ष : ट्रेस की शुरुआत के सापेक्ष समय दिखाता है।
- अनुभाग और ट्रैक लेबल : प्रत्येक अनुभाग में कई ट्रैक होते हैं और बाईं ओर एक त्रिकोण होता है जिस पर क्लिक करके आप अनुभाग को विस्तृत और संक्षिप्त कर सकते हैं। सिस्टम में प्रत्येक प्रसंस्करण तत्व के लिए एक अनुभाग है।
- टूल चयनकर्ता : इसमें ज़ूम, पैन, सेलेक्ट और टाइमिंग जैसे ट्रेस व्यूअर के साथ इंटरैक्ट करने के लिए विभिन्न टूल शामिल हैं। समय अंतराल को चिह्नित करने के लिए टाइमिंग टूल का उपयोग करें।
- घटनाएँ : ये उस समय को दर्शाते हैं जिसके दौरान एक ऑप निष्पादित किया गया था या मेटा-इवेंट की अवधि, जैसे कि प्रशिक्षण चरण।
अनुभाग और ट्रैक
ट्रेस व्यूअर में निम्नलिखित अनुभाग शामिल हैं:
- प्रत्येक डिवाइस नोड के लिए एक अनुभाग , डिवाइस चिप की संख्या और चिप के भीतर डिवाइस नोड के साथ लेबल किया गया (उदाहरण के लिए,
/device:GPU:0 (pid 0))। प्रत्येक डिवाइस नोड अनुभाग में निम्नलिखित ट्रैक होते हैं:- चरण : डिवाइस पर चल रहे प्रशिक्षण चरणों की अवधि दिखाता है
- TensorFlow Ops : डिवाइस पर निष्पादित ऑप्स दिखाता है
- XLA ऑप्स : यदि XLA उपयोग किया गया कंपाइलर है तो डिवाइस पर चलने वाले XLA ऑपरेशंस (ऑप्स) दिखाता है (प्रत्येक TensorFlow ऑप को एक या कई XLA ऑप्स में अनुवादित किया जाता है। XLA कंपाइलर XLA ऑप्स को डिवाइस पर चलने वाले कोड में अनुवादित करता है)।
- होस्ट मशीन के सीपीयू पर चलने वाले थ्रेड्स के लिए एक अनुभाग, जिसे "होस्ट थ्रेड्स" लेबल किया गया है। अनुभाग में प्रत्येक सीपीयू थ्रेड के लिए एक ट्रैक है। ध्यान दें कि आप अनुभाग लेबल के साथ प्रदर्शित जानकारी को अनदेखा कर सकते हैं।
घटनाएँ
समयरेखा के भीतर की घटनाओं को विभिन्न रंगों में प्रदर्शित किया जाता है; रंगों का स्वयं कोई विशेष अर्थ नहीं होता।
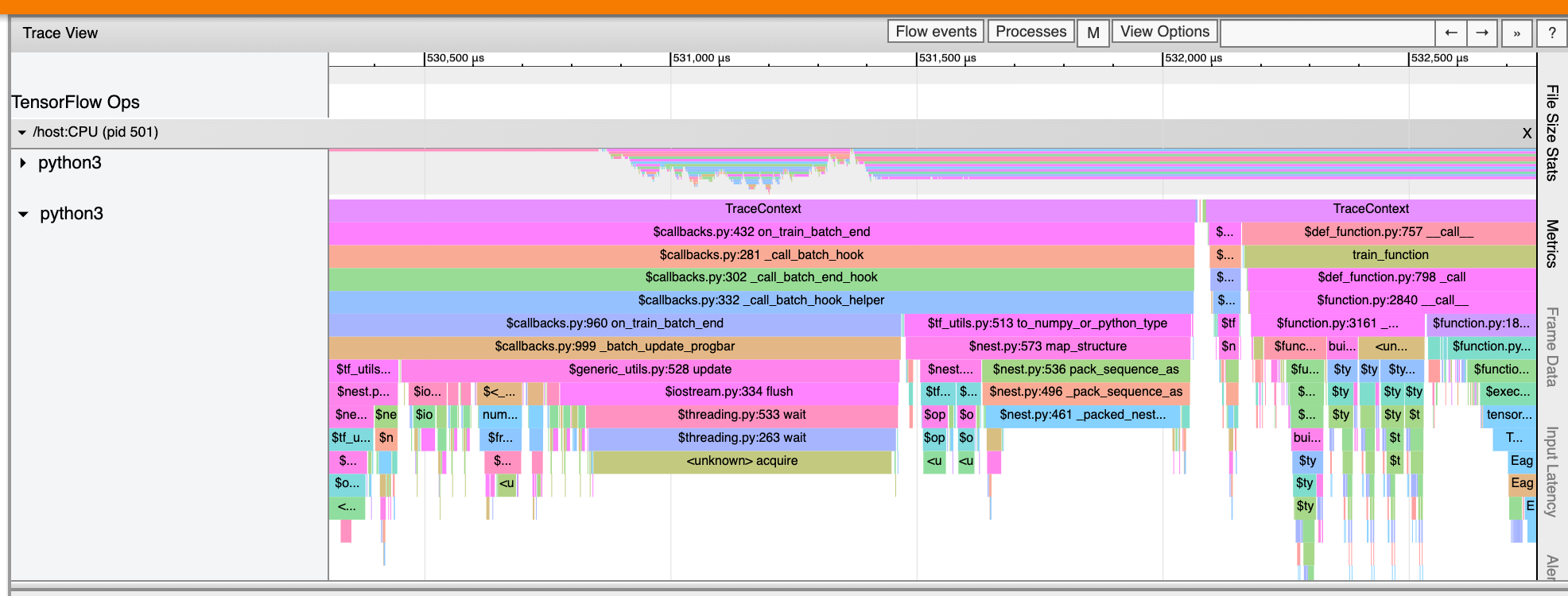
ट्रेस व्यूअर आपके TensorFlow प्रोग्राम में पायथन फ़ंक्शन कॉल के निशान भी प्रदर्शित कर सकता है। यदि आप tf.profiler.experimental.start API का उपयोग करते हैं, तो आप प्रोफाइलिंग शुरू करते समय ट्यूपल नामक ProfilerOptions का उपयोग करके पायथन ट्रेसिंग को सक्षम कर सकते हैं। वैकल्पिक रूप से, यदि आप प्रोफाइलिंग के लिए सैंपलिंग मोड का उपयोग करते हैं, तो आप कैप्चर प्रोफ़ाइल संवाद में ड्रॉपडाउन विकल्पों का उपयोग करके ट्रेसिंग के स्तर का चयन कर सकते हैं।
जीपीयू कर्नेल आँकड़े
यह उपकरण प्रत्येक GPU त्वरित कर्नेल के लिए प्रदर्शन आँकड़े और मूल ऑप दिखाता है।
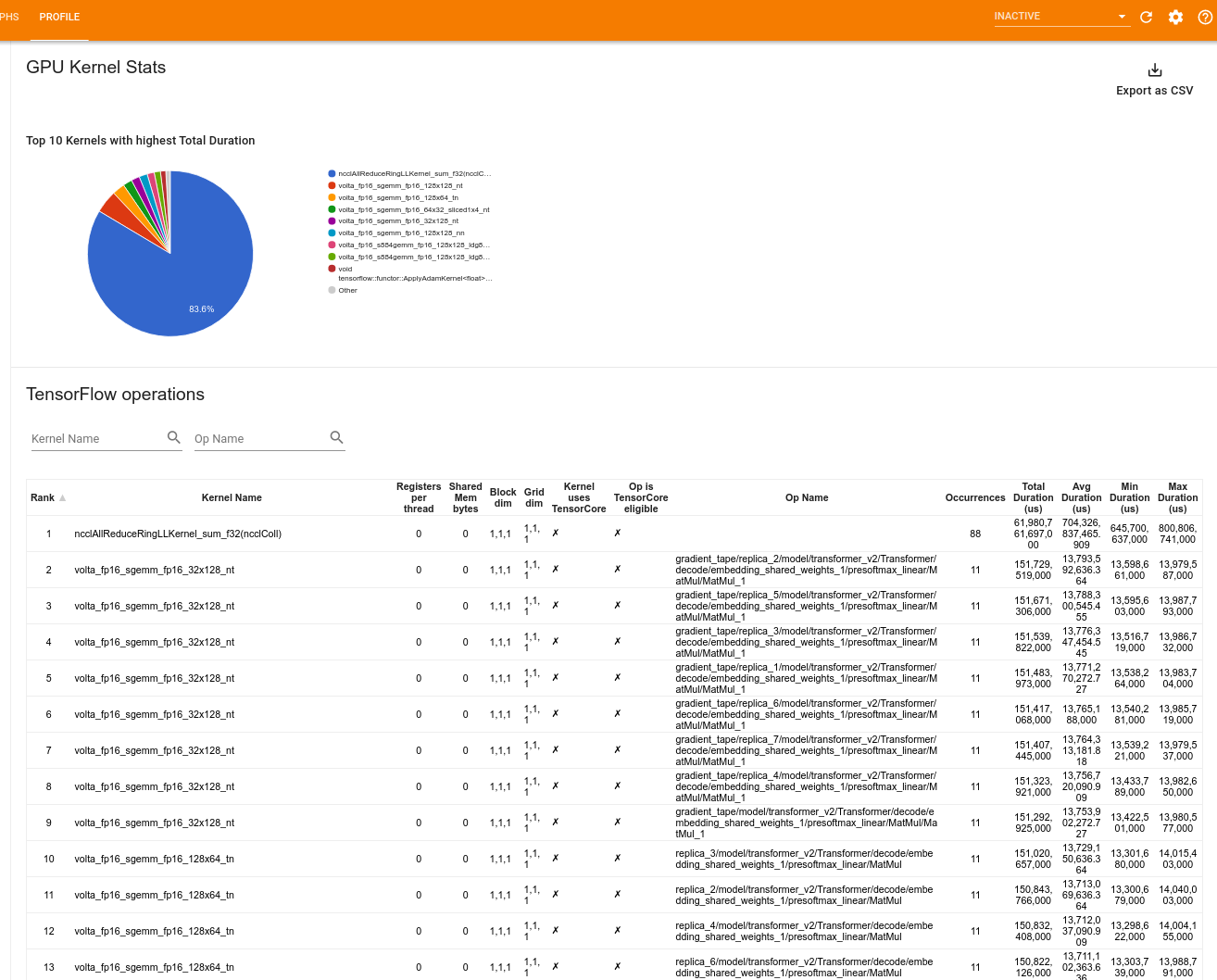
टूल दो पैन में जानकारी प्रदर्शित करता है:
ऊपरी फलक एक पाई चार्ट प्रदर्शित करता है जो CUDA कर्नेल दिखाता है जिसमें सबसे अधिक कुल समय व्यतीत हुआ है।
निचला फलक प्रत्येक अद्वितीय कर्नेल-ऑप जोड़ी के लिए निम्नलिखित डेटा वाली एक तालिका प्रदर्शित करता है:
- कर्नेल-ऑप जोड़ी द्वारा समूहीकृत कुल बीता हुआ GPU अवधि के अवरोही क्रम में एक रैंक।
- लॉन्च किए गए कर्नेल का नाम.
- कर्नेल द्वारा उपयोग किए गए GPU रजिस्टरों की संख्या।
- उपयोग की गई साझा (स्थैतिक + गतिशील साझा) मेमोरी का कुल आकार बाइट्स में।
- ब्लॉक आयाम को
blockDim.x, blockDim.y, blockDim.zके रूप में व्यक्त किया गया है। - ग्रिड आयाम को
gridDim.x, gridDim.y, gridDim.zके रूप में व्यक्त किया गया है। - क्या ऑप टेंसर कोर का उपयोग करने के लिए पात्र है।
- क्या कर्नेल में टेन्सर कोर निर्देश शामिल हैं।
- उस ऑप का नाम जिसने इस कर्नेल को लॉन्च किया।
- इस कर्नेल-ऑप जोड़ी की घटनाओं की संख्या।
- कुल बीता हुआ GPU समय माइक्रोसेकंड में।
- औसत बीता हुआ GPU समय माइक्रोसेकंड में.
- न्यूनतम बीता हुआ GPU समय माइक्रोसेकंड में।
- माइक्रोसेकंड में अधिकतम बीता हुआ GPU समय।
मेमोरी प्रोफाइल टूल
मेमोरी प्रोफाइल टूल प्रोफाइलिंग अंतराल के दौरान आपके डिवाइस के मेमोरी उपयोग की निगरानी करता है। आप इस टूल का उपयोग इसके लिए कर सकते हैं:
- चरम मेमोरी उपयोग और TensorFlow ऑप्स के लिए संबंधित मेमोरी आवंटन को इंगित करके मेमोरी से बाहर (OOM) समस्याओं को डीबग करें। आप बहु-किरायेदारी अनुमान चलाने पर उत्पन्न होने वाली ओओएम समस्याओं को भी डीबग कर सकते हैं।
- स्मृति विखंडन समस्याओं को डीबग करें।
मेमोरी प्रोफाइल टूल तीन खंडों में डेटा प्रदर्शित करता है:
- मेमोरी प्रोफ़ाइल सारांश
- मेमोरी टाइमलाइन ग्राफ़
- मेमोरी ब्रेकडाउन टेबल
मेमोरी प्रोफ़ाइल सारांश
यह अनुभाग आपके TensorFlow प्रोग्राम की मेमोरी प्रोफ़ाइल का उच्च-स्तरीय सारांश प्रदर्शित करता है जैसा कि नीचे दिखाया गया है:
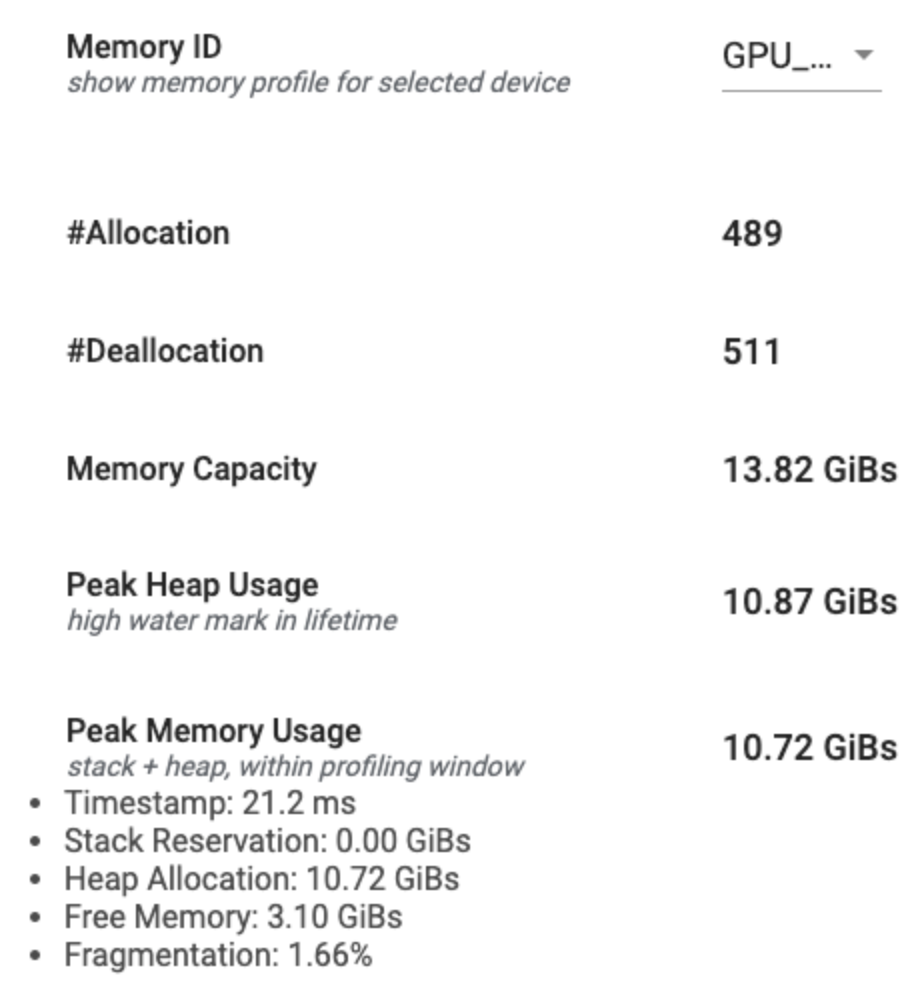
मेमोरी प्रोफ़ाइल सारांश में छह फ़ील्ड हैं:
- मेमोरी आईडी : ड्रॉपडाउन जो सभी उपलब्ध डिवाइस मेमोरी सिस्टम को सूचीबद्ध करता है। ड्रॉपडाउन से वह मेमोरी सिस्टम चुनें जिसे आप देखना चाहते हैं।
- #आवंटन : प्रोफाइलिंग अंतराल के दौरान किए गए मेमोरी आवंटन की संख्या।
- #डीललोकेशन : प्रोफाइलिंग अंतराल में मेमोरी डीलोकेशन की संख्या
- मेमोरी क्षमता : आपके द्वारा चयनित मेमोरी सिस्टम की कुल क्षमता (GiBs में)।
- पीक हीप उपयोग : मॉडल के चलने के बाद से अधिकतम मेमोरी उपयोग (जीआईबी में)।
- अधिकतम मेमोरी उपयोग : प्रोफ़ाइलिंग अंतराल में अधिकतम मेमोरी उपयोग (GiBs में)। इस फ़ील्ड में निम्नलिखित उप-फ़ील्ड हैं:
- टाइमस्टैम्प : टाइमलाइन ग्राफ़ पर अधिकतम मेमोरी उपयोग होने का टाइमस्टैम्प।
- स्टैक आरक्षण : स्टैक पर आरक्षित मेमोरी की मात्रा (GiBs में)।
- हीप आवंटन : हीप पर आवंटित मेमोरी की मात्रा (GiBs में)।
- निःशुल्क मेमोरी : निःशुल्क मेमोरी की मात्रा (GiBs में)। मेमोरी क्षमता स्टैक रिजर्वेशन, हीप आवंटन और फ्री मेमोरी का कुल योग है।
- विखंडन : विखंडन का प्रतिशत (कम बेहतर है)। इसकी गणना प्रतिशत के रूप में की जाती है
(1 - Size of the largest chunk of free memory / Total free memory)
मेमोरी टाइमलाइन ग्राफ़
यह खंड मेमोरी उपयोग का एक प्लॉट (जीआईबी में) और समय बनाम विखंडन का प्रतिशत (एमएस में) प्रदर्शित करता है।
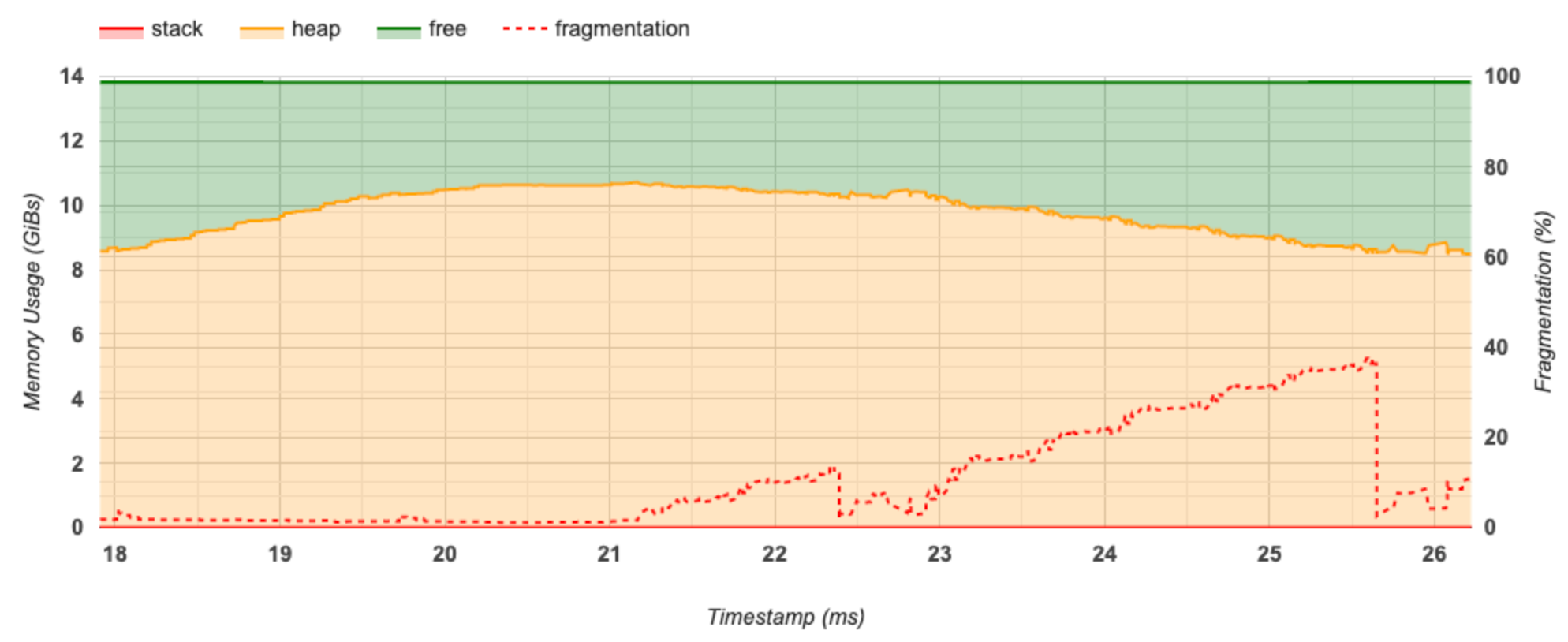
एक्स-अक्ष प्रोफाइलिंग अंतराल की समयरेखा (एमएस में) का प्रतिनिधित्व करता है। बाईं ओर Y-अक्ष मेमोरी उपयोग (GiBs में) को दर्शाता है और दाईं ओर Y-अक्ष विखंडन के प्रतिशत को दर्शाता है। एक्स-अक्ष पर प्रत्येक समय बिंदु पर, कुल मेमोरी को तीन श्रेणियों में विभाजित किया गया है: स्टैक (लाल रंग में), हीप (नारंगी में), और फ्री (हरे रंग में)। नीचे दिए गए अनुसार उस बिंदु पर मेमोरी आवंटन/डीललोकेशन घटनाओं के बारे में विवरण देखने के लिए एक विशिष्ट टाइमस्टैम्प पर होवर करें:
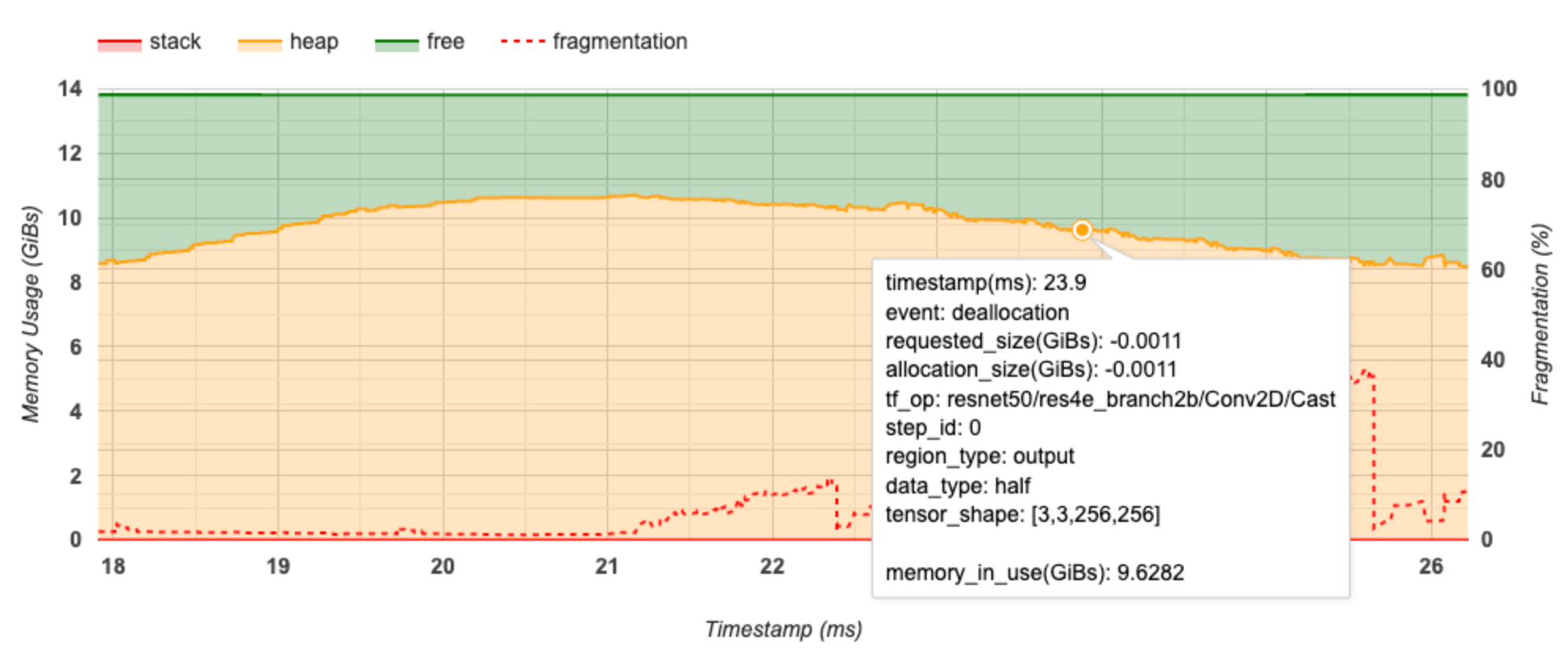
पॉप-अप विंडो निम्नलिखित जानकारी प्रदर्शित करती है:
- टाइमस्टैम्प (एमएस) : टाइमलाइन पर चयनित ईवेंट का स्थान।
- घटना : घटना का प्रकार (आवंटन या निरस्तीकरण)।
- request_size(GiBs) : अनुरोधित मेमोरी की मात्रा। यह आवंटन रद्द करने की घटनाओं के लिए एक नकारात्मक संख्या होगी।
- आवंटन_आकार (GiBs) : आवंटित मेमोरी की वास्तविक मात्रा। यह आवंटन रद्द करने की घटनाओं के लिए एक नकारात्मक संख्या होगी।
- tf_op : TensorFlow op जो आवंटन/डीलोकेशन का अनुरोध करता है।
- चरण_आईडी : वह प्रशिक्षण चरण जिसमें यह घटना घटी।
- क्षेत्र_प्रकार : डेटा इकाई प्रकार जिसके लिए यह आवंटित मेमोरी है। संभावित मान अस्थायी के लिए
temp, सक्रियण और ग्रेडिएंट के लिएoutput, और वजन और स्थिरांक के लिएpersist/dynamicहैं। - data_type : टेंसर तत्व प्रकार (उदाहरण के लिए, 8-बिट अहस्ताक्षरित पूर्णांक के लिए uint8)।
- टेंसर_शेप : टेंसर का आकार आवंटित/हटाया जा रहा है।
- मेमोरी_इन_यूज़(GiBs) : कुल मेमोरी जो इस समय उपयोग में है।
मेमोरी ब्रेकडाउन टेबल
यह तालिका प्रोफ़ाइलिंग अंतराल में चरम मेमोरी उपयोग के बिंदु पर सक्रिय मेमोरी आवंटन दिखाती है।
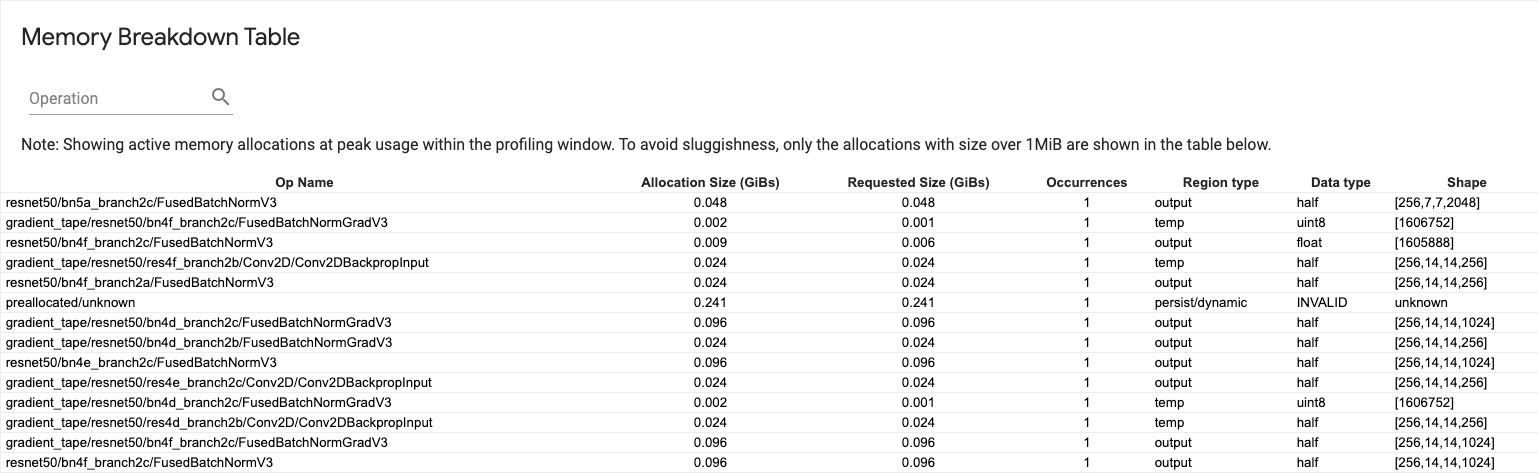
प्रत्येक TensorFlow Op के लिए एक पंक्ति है और प्रत्येक पंक्ति में निम्नलिखित कॉलम हैं:
- ऑप का नाम : टेन्सरफ्लो ऑप का नाम।
- आवंटन आकार (GiBs) : इस ऑप को आवंटित मेमोरी की कुल मात्रा।
- अनुरोधित आकार (GiBs) : इस ऑपशन के लिए अनुरोधित मेमोरी की कुल मात्रा।
- घटनाएँ : इस ऑप के लिए आवंटन की संख्या।
- क्षेत्र प्रकार : डेटा इकाई प्रकार जिसके लिए यह आवंटित मेमोरी है। संभावित मान अस्थायी के लिए
temp, सक्रियण और ग्रेडिएंट के लिएoutput, और वजन और स्थिरांक के लिएpersist/dynamicहैं। - डेटा प्रकार : टेंसर तत्व प्रकार।
- आकार : आवंटित टेंसर का आकार।
पॉड दर्शक
पॉड व्यूअर टूल सभी श्रमिकों के प्रशिक्षण चरण का विवरण दिखाता है।
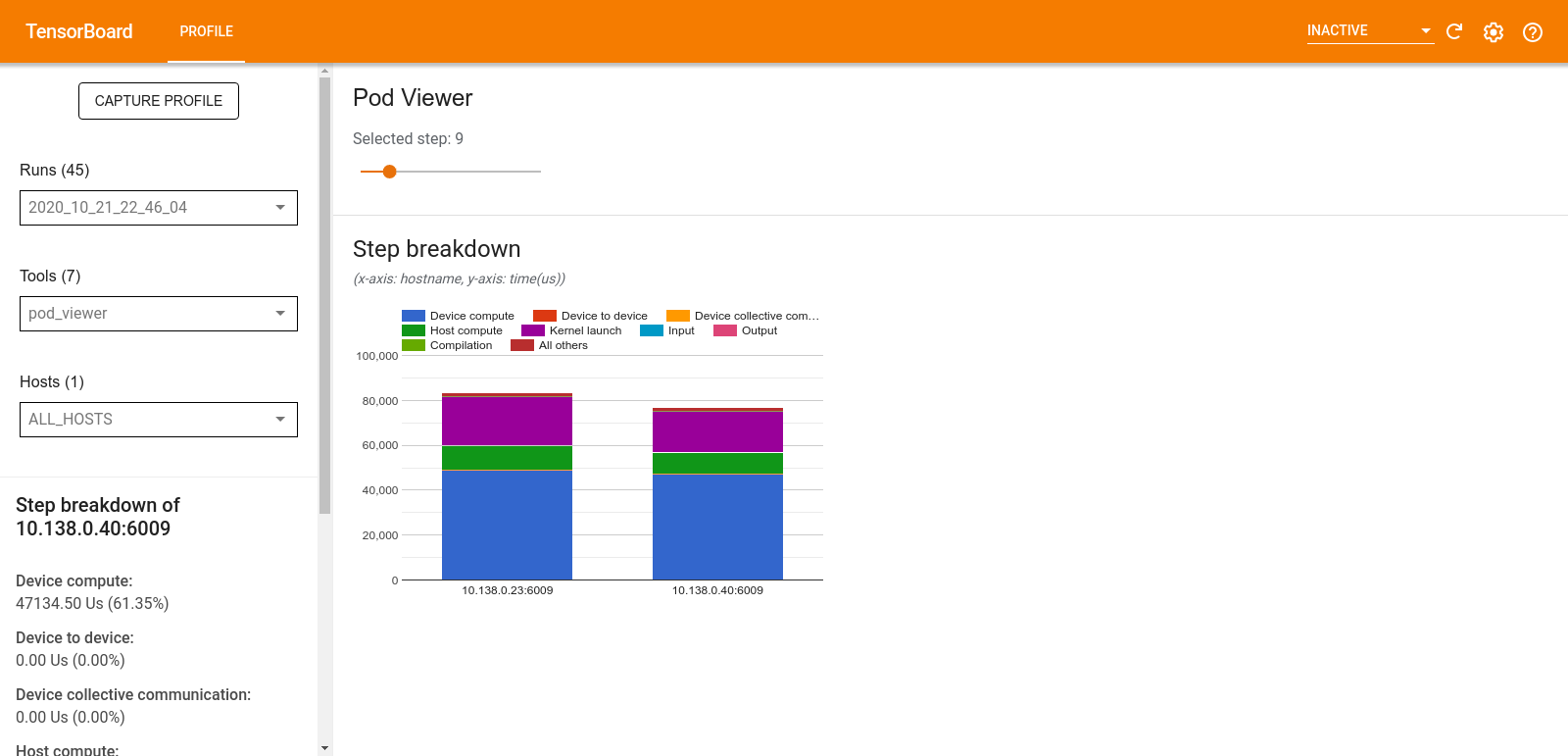
- ऊपरी फलक में चरण संख्या का चयन करने के लिए एक स्लाइडर है।
- निचला फलक एक स्टैक्ड कॉलम चार्ट प्रदर्शित करता है। यह एक-दूसरे के ऊपर रखी गई टूटी-फूटी चरण-समय श्रेणियों का उच्च स्तरीय दृश्य है। प्रत्येक स्टैक्ड कॉलम एक अद्वितीय कार्यकर्ता का प्रतिनिधित्व करता है।
- जब आप किसी स्टैक्ड कॉलम पर होवर करते हैं, तो बाईं ओर का कार्ड स्टेप ब्रेकडाउन के बारे में अधिक विवरण दिखाता है।
tf.डेटा बाधा विश्लेषण
tf.data टोंटी विश्लेषण उपकरण स्वचालित रूप से आपके प्रोग्राम में tf.data इनपुट पाइपलाइनों में बाधाओं का पता लगाता है और उन्हें ठीक करने के तरीके पर सिफारिशें प्रदान करता है। यह प्लेटफ़ॉर्म (सीपीयू/जीपीयू/टीपीयू) की परवाह किए बिना tf.data का उपयोग करने वाले किसी भी प्रोग्राम के साथ काम करता है। इसका विश्लेषण और सिफारिशें इस गाइड पर आधारित हैं।
यह इन चरणों का पालन करके बाधा का पता लगाता है:
- सबसे अधिक इनपुट बाउंड होस्ट ढूंढें।
-
tf.dataइनपुट पाइपलाइन का सबसे धीमा निष्पादन खोजें। - प्रोफाइलर ट्रेस से इनपुट पाइपलाइन ग्राफ़ का पुनर्निर्माण करें।
- इनपुट पाइपलाइन ग्राफ़ में महत्वपूर्ण पथ खोजें।
- महत्वपूर्ण पथ पर सबसे धीमे परिवर्तन को बाधा के रूप में पहचानें।
यूआई को तीन खंडों में विभाजित किया गया है: प्रदर्शन विश्लेषण सारांश , सभी इनपुट पाइपलाइनों का सारांश और इनपुट पाइपलाइन ग्राफ़ ।
प्रदर्शन विश्लेषण सारांश

यह अनुभाग विश्लेषण का सारांश प्रदान करता है. यह प्रोफ़ाइल में पाई गई धीमी tf.data इनपुट पाइपलाइनों पर रिपोर्ट करता है। यह अनुभाग अधिकतम इनपुट बाउंड होस्ट और अधिकतम विलंबता के साथ इसकी सबसे धीमी इनपुट पाइपलाइन को भी दिखाता है। सबसे महत्वपूर्ण बात यह है कि यह पहचानता है कि इनपुट पाइपलाइन के किस हिस्से में बाधा है और इसे कैसे ठीक किया जाए। अड़चन की जानकारी पुनरावर्तक प्रकार और उसके लंबे नाम के साथ प्रदान की जाती है।
tf.data iterator का लंबा नाम कैसे पढ़ें
एक लंबा नाम Iterator::<Dataset_1>::...::<Dataset_n> के रूप में स्वरूपित किया गया है। लंबे नाम में, <Dataset_n> इटरेटर प्रकार से मेल खाता है और लंबे नाम में अन्य डेटासेट डाउनस्ट्रीम परिवर्तनों का प्रतिनिधित्व करते हैं।
उदाहरण के लिए, निम्नलिखित इनपुट पाइपलाइन डेटासेट पर विचार करें:
dataset = tf.data.Dataset.range(10).map(lambda x: x).repeat(2).batch(5)
उपरोक्त डेटासेट से पुनरावर्तकों के लिए लंबे नाम होंगे:
| पुनरावर्तक प्रकार | लंबा नाम |
|---|---|
| श्रेणी | इटरेटर::बैच::रिपीट::मैप::रेंज |
| मानचित्र | इटरेटर::बैच::रिपीट::मैप |
| दोहराना | इटरेटर::बैच::दोहराएँ |
| बैच | इटरेटर::बैच |
सभी इनपुट पाइपलाइनों का सारांश
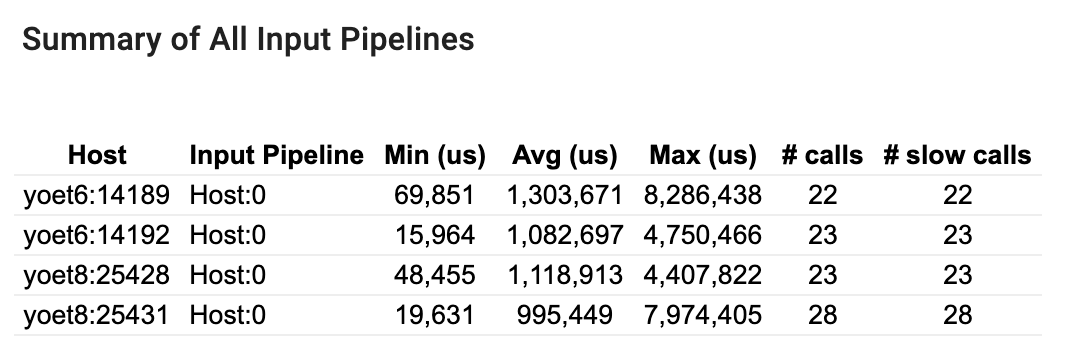
यह अनुभाग सभी होस्टों पर सभी इनपुट पाइपलाइनों का सारांश प्रदान करता है। आमतौर पर एक इनपुट पाइपलाइन होती है। वितरण रणनीति का उपयोग करते समय, एक होस्ट इनपुट पाइपलाइन होती है जो प्रोग्राम के tf.data कोड को चलाती है और कई डिवाइस इनपुट पाइपलाइन होती है जो होस्ट इनपुट पाइपलाइन से डेटा पुनर्प्राप्त करती है और इसे डिवाइसों में स्थानांतरित करती है।
प्रत्येक इनपुट पाइपलाइन के लिए, यह उसके निष्पादन समय के आँकड़े दिखाता है। यदि कोई कॉल 50 μs से अधिक समय लेती है तो उसे धीमी गति में गिना जाता है।
इनपुट पाइपलाइन ग्राफ़

यह अनुभाग निष्पादन समय की जानकारी के साथ इनपुट पाइपलाइन ग्राफ़ दिखाता है। कौन सा होस्ट और इनपुट पाइपलाइन देखना है यह चुनने के लिए आप "होस्ट" और "इनपुट पाइपलाइन" का उपयोग कर सकते हैं। इनपुट पाइपलाइन के निष्पादन को निष्पादन समय के अनुसार अवरोही क्रम में क्रमबद्ध किया जाता है जिसे आप रैंक ड्रॉपडाउन का उपयोग करके चुन सकते हैं।
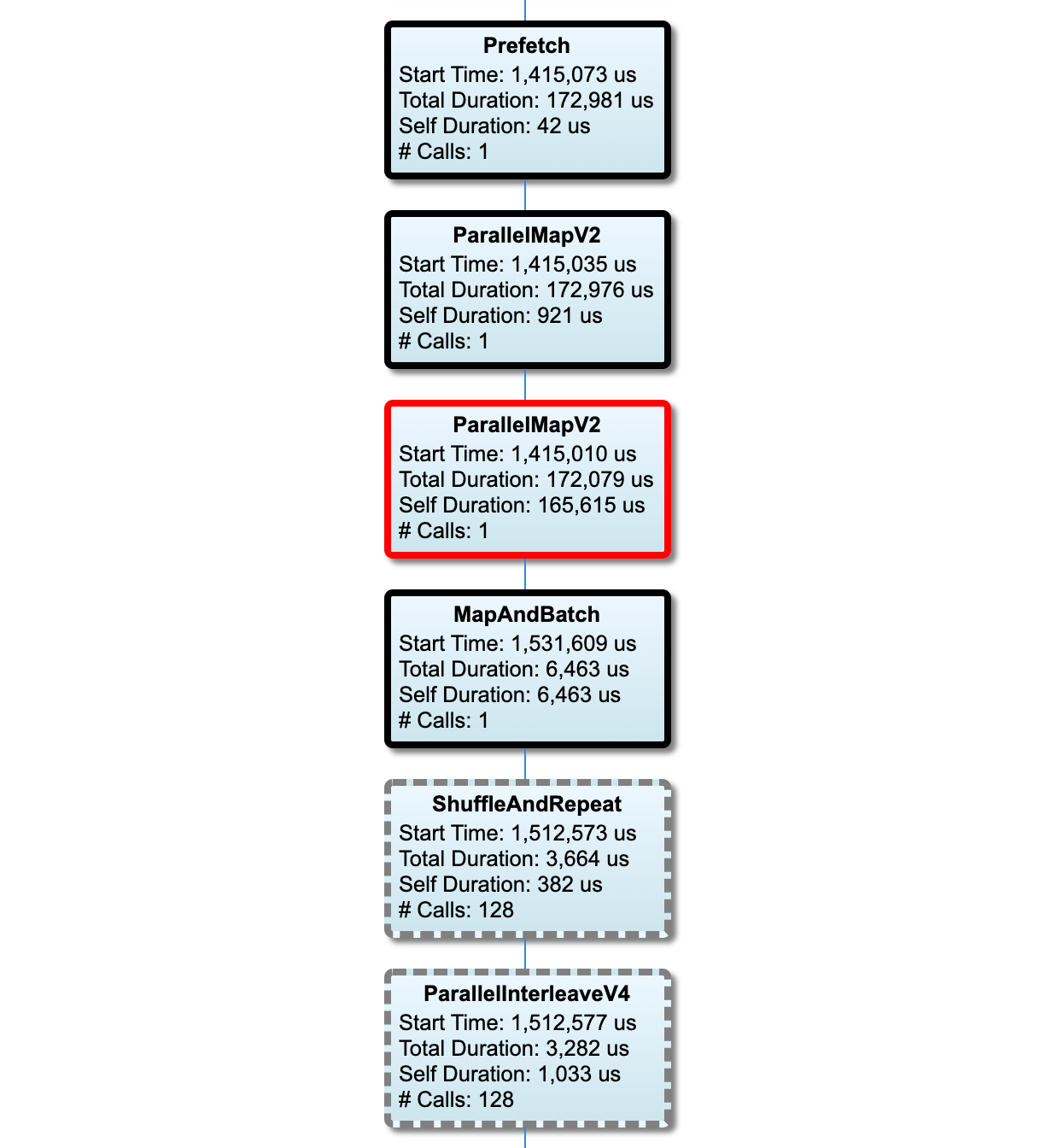
महत्वपूर्ण पथ पर नोड्स की रूपरेखा बोल्ड है। टोंटी नोड, जो महत्वपूर्ण पथ पर सबसे लंबे समय तक स्व-समय वाला नोड है, की एक लाल रूपरेखा है। अन्य गैर-महत्वपूर्ण नोड्स में ग्रे धराशायी रूपरेखाएँ हैं।
प्रत्येक नोड में, प्रारंभ समय निष्पादन के प्रारंभ समय को इंगित करता है। एक ही नोड को कई बार निष्पादित किया जा सकता है, उदाहरण के लिए, यदि इनपुट पाइपलाइन में Batch ऑप है। यदि इसे कई बार निष्पादित किया जाता है, तो यह पहले निष्पादन का प्रारंभ समय है।
कुल अवधि निष्पादन का दीवार समय है। यदि इसे कई बार निष्पादित किया जाता है, तो यह सभी निष्पादनों के दीवार समय का योग है।
सेल्फ टाइम अपने तत्काल चाइल्ड नोड्स के साथ ओवरलैप किए गए समय के बिना कुल समय है।
"# कॉल" इनपुट पाइपलाइन निष्पादित होने की संख्या है।
प्रदर्शन डेटा एकत्र करें
TensorFlow प्रोफाइलर आपके TensorFlow मॉडल की होस्ट गतिविधियों और GPU निशान एकत्र करता है। आप प्रोग्रामेटिक मोड या सैंपलिंग मोड के माध्यम से प्रदर्शन डेटा एकत्र करने के लिए प्रोफाइलर को कॉन्फ़िगर कर सकते हैं।
प्रोफाइलिंग एपीआई
प्रोफाइलिंग करने के लिए आप निम्नलिखित एपीआई का उपयोग कर सकते हैं।
TensorBoard Keras कॉलबैक (
tf.keras.callbacks.TensorBoard) का उपयोग करके प्रोग्रामेटिक मोड# Profile from batches 10 to 15 tb_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, profile_batch='10, 15') # Train the model and use the TensorBoard Keras callback to collect # performance profiling data model.fit(train_data, steps_per_epoch=20, epochs=5, callbacks=[tb_callback])tf.profilerफ़ंक्शन API का उपयोग करके प्रोग्रामेटिक मोडtf.profiler.experimental.start('logdir') # Train the model here tf.profiler.experimental.stop()संदर्भ प्रबंधक का उपयोग करके प्रोग्रामेटिक मोड
with tf.profiler.experimental.Profile('logdir'): # Train the model here pass
सैंपलिंग मोड: अपने TensorFlow मॉडल रन के साथ gRPC सर्वर शुरू करने के लिए
tf.profiler.experimental.server.startका उपयोग करके ऑन-डिमांड प्रोफाइलिंग करें। जीआरपीसी सर्वर शुरू करने और अपना मॉडल चलाने के बाद, आप टेन्सरबोर्ड प्रोफाइल प्लगइन में कैप्चर प्रोफाइल बटन के माध्यम से एक प्रोफ़ाइल कैप्चर कर सकते हैं। यदि TensorBoard इंस्टेंस पहले से नहीं चल रहा है तो उसे लॉन्च करने के लिए ऊपर इंस्टॉल प्रोफाइलर अनुभाग में स्क्रिप्ट का उपयोग करें।उदाहरण के तौर पर,
# Start a profiler server before your model runs. tf.profiler.experimental.server.start(6009) # (Model code goes here). # Send a request to the profiler server to collect a trace of your model. tf.profiler.experimental.client.trace('grpc://localhost:6009', 'gs://your_tb_logdir', 2000)एकाधिक श्रमिकों की प्रोफ़ाइलिंग का एक उदाहरण:
# E.g., your worker IP addresses are 10.0.0.2, 10.0.0.3, 10.0.0.4, and you # would like to profile for a duration of 2 seconds. tf.profiler.experimental.client.trace( 'grpc://10.0.0.2:8466,grpc://10.0.0.3:8466,grpc://10.0.0.4:8466', 'gs://your_tb_logdir', 2000)
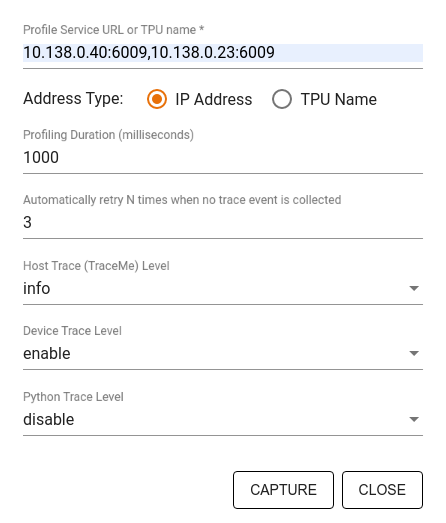
निर्दिष्ट करने के लिए कैप्चर प्रोफ़ाइल संवाद का उपयोग करें:
- प्रोफ़ाइल सेवा यूआरएल या टीपीयू नामों की अल्पविराम-सीमांकित सूची।
- एक प्रोफाइलिंग अवधि.
- डिवाइस, होस्ट और पायथन फ़ंक्शन कॉल ट्रेसिंग का स्तर।
- आप कितनी बार चाहते हैं कि प्रोफाइलर पहली बार में असफल होने पर प्रोफाइल कैप्चर करने का पुनः प्रयास करे।
प्रोफ़ाइलिंग कस्टम प्रशिक्षण लूप
अपने TensorFlow कोड में कस्टम ट्रेनिंग लूप्स को प्रोफाइल करने के लिए, प्रोफाइलर के लिए चरण सीमाओं को चिह्नित करने के लिए tf.profiler.experimental.Trace API के साथ ट्रेनिंग लूप को इंस्ट्रूमेंट करें।
name तर्क का उपयोग चरण नामों के लिए उपसर्ग के रूप में किया जाता है, step_num कीवर्ड तर्क को चरण नामों में जोड़ा जाता है, और _r कीवर्ड तर्क इस ट्रेस इवेंट को प्रोफाइलर द्वारा चरण इवेंट के रूप में संसाधित करता है।
उदाहरण के तौर पर,
for step in range(NUM_STEPS):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_data = next(dataset)
train_step(train_data)
यह प्रोफाइलर के चरण-आधारित प्रदर्शन विश्लेषण को सक्षम करेगा और चरण घटनाओं को ट्रेस व्यूअर में दिखाने का कारण बनेगा।
सुनिश्चित करें कि आपने इनपुट पाइपलाइन के सटीक विश्लेषण के लिए tf.profiler.experimental.Trace संदर्भ में डेटासेट इटरेटर को शामिल किया है।
नीचे दिया गया कोड स्निपेट एक विरोधी पैटर्न है:
for step, train_data in enumerate(dataset):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_step(train_data)
प्रोफ़ाइल उपयोग के मामले
प्रोफाइलर चार अलग-अलग अक्षों के साथ कई उपयोग मामलों को कवर करता है। कुछ संयोजन वर्तमान में समर्थित हैं और अन्य भविष्य में जोड़े जाएंगे। कुछ उपयोग के मामले हैं:
- स्थानीय बनाम रिमोट प्रोफाइलिंग : ये आपके प्रोफाइलिंग वातावरण को स्थापित करने के दो सामान्य तरीके हैं। स्थानीय प्रोफाइलिंग में, प्रोफाइलिंग एपीआई को उसी मशीन पर कॉल किया जाता है जिसे आपका मॉडल निष्पादित कर रहा है, उदाहरण के लिए, जीपीयू के साथ एक स्थानीय वर्कस्टेशन। रिमोट प्रोफाइलिंग में, प्रोफाइलिंग एपीआई को एक अलग मशीन पर कॉल किया जाता है जहां से आपका मॉडल निष्पादित हो रहा है, उदाहरण के लिए, क्लाउड टीपीयू पर।
- कई श्रमिकों की प्रोफाइलिंग : TensorFlow की वितरित प्रशिक्षण क्षमताओं का उपयोग करते समय आप कई मशीनों की प्रोफाइलिंग कर सकते हैं।
- हार्डवेयर प्लेटफ़ॉर्म : प्रोफ़ाइल सीपीयू, जीपीयू और टीपीयू।
नीचे दी गई तालिका ऊपर उल्लिखित TensorFlow-समर्थित उपयोग मामलों का त्वरित अवलोकन प्रदान करती है:
| प्रोफ़ाइलिंग एपीआई | स्थानीय | दूर | एकाधिक कार्यकर्ता | हार्डवेयर प्लेटफार्म |
|---|---|---|---|---|
| टेंसरबोर्ड केरस कॉलबैक | का समर्थन किया | समर्थित नहीं | समर्थित नहीं | सीपीयू, जीपीयू |
tf.profiler.experimental स्टार्ट/स्टॉप एपीआई | का समर्थन किया | समर्थित नहीं | समर्थित नहीं | सीपीयू, जीपीयू |
tf.profiler.experimental client.trace API | का समर्थन किया | का समर्थन किया | का समर्थन किया | सीपीयू, जीपीयू, टीपीयू |
| प्रसंग प्रबंधक एपीआई | का समर्थन किया | समर्थित नहीं | समर्थित नहीं | सीपीयू, जीपीयू |
इष्टतम मॉडल प्रदर्शन के लिए सर्वोत्तम अभ्यास
इष्टतम प्रदर्शन प्राप्त करने के लिए अपने TensorFlow मॉडल के लिए लागू निम्नलिखित अनुशंसाओं का उपयोग करें।
सामान्य तौर पर, डिवाइस पर सभी परिवर्तन करें और सुनिश्चित करें कि आप अपने प्लेटफ़ॉर्म के लिए cuDNN और Intel MKL जैसी लाइब्रेरी के नवीनतम संगत संस्करण का उपयोग करें।
इनपुट डेटा पाइपलाइन को अनुकूलित करें
अपने डेटा इनपुट पाइपलाइन को अनुकूलित करने के लिए [#input_pipeline_analyzer] से डेटा का उपयोग करें। एक कुशल डेटा इनपुट पाइपलाइन डिवाइस के निष्क्रिय समय को कम करके आपके मॉडल निष्पादन की गति में काफी सुधार कर सकती है। अपने डेटा इनपुट पाइपलाइन को अधिक कुशल बनाने के लिए tf.data API गाइड और नीचे बेहतर प्रदर्शन में विस्तृत सर्वोत्तम प्रथाओं को शामिल करने का प्रयास करें।
सामान्य तौर पर, किसी भी ऑप्स को समानांतर करना जिसे क्रमिक रूप से निष्पादित करने की आवश्यकता नहीं है, डेटा इनपुट पाइपलाइन को महत्वपूर्ण रूप से अनुकूलित कर सकता है।
कई मामलों में, यह कुछ कॉलों के क्रम को बदलने या तर्कों को इस तरह समायोजित करने में मदद करता है कि यह आपके मॉडल के लिए सबसे अच्छा काम करता है। इनपुट डेटा पाइपलाइन को अनुकूलित करते समय, अनुकूलन के प्रभाव को स्वतंत्र रूप से मापने के लिए प्रशिक्षण और बैकप्रॉपैगेशन चरणों के बिना केवल डेटा लोडर को बेंचमार्क करें।
यह जांचने के लिए कि क्या इनपुट पाइपलाइन एक प्रदर्शन बाधा है, अपने मॉडल को सिंथेटिक डेटा के साथ चलाने का प्रयास करें।
मल्टी-जीपीयू प्रशिक्षण के लिए
tf.data.Dataset.shardउपयोग करें। सुनिश्चित करें कि आप थ्रूपुट में कटौती को रोकने के लिए इनपुट लूप में बहुत पहले से ही शार्प हो जाएं। TFRecords के साथ काम करते समय, सुनिश्चित करें कि आप TFRecords की सूची को शार्प करें, न कि TFRecords की सामग्री को।tf.data.AUTOTUNEका उपयोग करकेnum_parallel_callsका मान गतिशील रूप से सेट करके कई ऑप्स को समानांतर करें।tf.data.Dataset.from_generatorके उपयोग को सीमित करने पर विचार करें क्योंकि यह शुद्ध TensorFlow ऑप्स की तुलना में धीमा है।tf.py_functionके उपयोग को सीमित करने पर विचार करें क्योंकि इसे क्रमबद्ध नहीं किया जा सकता है और वितरित TensorFlow में चलाने के लिए समर्थित नहीं है।इनपुट पाइपलाइन में स्थैतिक अनुकूलन को नियंत्रित करने के लिए
tf.data.Optionsउपयोग करें।
अपनी इनपुट पाइपलाइन को अनुकूलित करने पर अधिक मार्गदर्शन के लिए tf.data प्रदर्शन विश्लेषण मार्गदर्शिका भी पढ़ें।
डेटा वृद्धि का अनुकूलन करें
छवि डेटा के साथ काम करते समय, स्थानिक परिवर्तनों, जैसे फ़्लिपिंग, क्रॉपिंग, रोटेटिंग इत्यादि को लागू करने के बाद विभिन्न डेटा प्रकारों को कास्टिंग करके अपने डेटा संवर्द्धन को अधिक कुशल बनाएं।
NVIDIA® DALI का उपयोग करें
कुछ उदाहरणों में, जैसे कि जब आपके पास उच्च जीपीयू से सीपीयू अनुपात वाला सिस्टम होता है, तो उपरोक्त सभी अनुकूलन सीपीयू चक्रों की सीमाओं के कारण डेटा लोडर में आने वाली बाधाओं को खत्म करने के लिए पर्याप्त नहीं हो सकते हैं।
यदि आप कंप्यूटर विज़न और ऑडियो डीप लर्निंग अनुप्रयोगों के लिए NVIDIA® GPU का उपयोग कर रहे हैं, तो डेटा पाइपलाइन में तेजी लाने के लिए डेटा लोडिंग लाइब्रेरी ( DALI ) का उपयोग करने पर विचार करें।
समर्थित DALI ऑप्स की सूची के लिए NVIDIA® DALI: संचालन दस्तावेज़ की जाँच करें।
थ्रेडिंग और समानांतर निष्पादन का उपयोग करें
कई सीपीयू थ्रेड्स को तेजी से निष्पादित करने के लिए tf.config.threading API के साथ उन पर ऑप्स चलाएँ।
TensorFlow स्वचालित रूप से डिफ़ॉल्ट रूप से समांतरता थ्रेड्स की संख्या निर्धारित करता है। TensorFlow ऑप्स चलाने के लिए उपलब्ध थ्रेड पूल उपलब्ध CPU थ्रेड्स की संख्या पर निर्भर करता है।
tf.config.threading.set_intra_op_parallelism_threads का उपयोग करके एकल ऑप के लिए अधिकतम समानांतर स्पीडअप को नियंत्रित करें। ध्यान दें कि यदि आप समानांतर में एकाधिक ऑप्स चलाते हैं, तो वे सभी उपलब्ध थ्रेड पूल साझा करेंगे।
यदि आपके पास स्वतंत्र गैर-अवरुद्ध ऑप्स हैं (ग्राफ़ पर उनके बीच कोई निर्देशित पथ नहीं है), तो उपलब्ध थ्रेड पूल का उपयोग करके उन्हें समवर्ती रूप से चलाने के लिए tf.config.threading.set_inter_op_parallelism_threads का उपयोग करें।
मिश्रित
NVIDIA® GPU पर छोटे मॉडल के साथ काम करते समय, आप मॉडल प्रदर्शन को महत्वपूर्ण बढ़ावा देने के लिए CUDA पिन की गई मेमोरी के साथ सभी CPU टेंसर को आवंटित करने के लिए बाध्य करने के लिए tf.compat.v1.ConfigProto.force_gpu_compatible=True सेट कर सकते हैं। हालाँकि, अज्ञात/बहुत बड़े मॉडलों के लिए इस विकल्प का उपयोग करते समय सावधानी बरतें क्योंकि इससे होस्ट (सीपीयू) के प्रदर्शन पर नकारात्मक प्रभाव पड़ सकता है।
डिवाइस के प्रदर्शन में सुधार करें
ऑन-डिवाइस TensorFlow मॉडल प्रदर्शन को अनुकूलित करने के लिए यहां और GPU प्रदर्शन अनुकूलन मार्गदर्शिका में वर्णित सर्वोत्तम प्रथाओं का पालन करें।
यदि आप NVIDIA GPU का उपयोग कर रहे हैं, तो GPU और मेमोरी उपयोग को CSV फ़ाइल में लॉग इन करके लॉग करें:
nvidia-smi
--query-gpu=utilization.gpu,utilization.memory,memory.total,
memory.free,memory.used --format=csv
डेटा लेआउट कॉन्फ़िगर करें
चैनल जानकारी (जैसे छवियां) वाले डेटा के साथ काम करते समय, अंतिम चैनल (एनसीएचडब्ल्यू की तुलना में एनएचडब्ल्यूसी) को प्राथमिकता देने के लिए डेटा लेआउट प्रारूप को अनुकूलित करें।
चैनल-लास्ट डेटा प्रारूप टेन्सर कोर उपयोग में सुधार करते हैं और एएमपी के साथ युग्मित होने पर विशेष रूप से कन्वेन्शनल मॉडल में महत्वपूर्ण प्रदर्शन सुधार प्रदान करते हैं। एनसीएचडब्ल्यू डेटा लेआउट अभी भी टेन्सर कोर द्वारा संचालित किया जा सकता है, लेकिन स्वचालित ट्रांसपोज़ ऑप्स के कारण अतिरिक्त ओवरहेड पेश किया जा सकता है।
आप tf.keras.layers.Conv2D , tf.keras.layers.Conv3D , और tf.keras.layers.RandomRotation जैसी परतों के लिए data_format="channels_last" सेट करके NHWC लेआउट को प्राथमिकता देने के लिए डेटा लेआउट को अनुकूलित कर सकते हैं।
केरस बैकएंड एपीआई के लिए डिफ़ॉल्ट डेटा लेआउट प्रारूप सेट करने के लिए tf.keras.backend.set_image_data_format उपयोग करें।
L2 कैश को अधिकतम करें
NVIDIA® GPU के साथ काम करते समय, L2 फ़ेच ग्रैन्युलैरिटी को 128 बाइट्स तक अधिकतम करने के लिए प्रशिक्षण लूप से पहले नीचे दिए गए कोड स्निपेट को निष्पादित करें।
import ctypes
_libcudart = ctypes.CDLL('libcudart.so')
# Set device limit on the current device
# cudaLimitMaxL2FetchGranularity = 0x05
pValue = ctypes.cast((ctypes.c_int*1)(), ctypes.POINTER(ctypes.c_int))
_libcudart.cudaDeviceSetLimit(ctypes.c_int(0x05), ctypes.c_int(128))
_libcudart.cudaDeviceGetLimit(pValue, ctypes.c_int(0x05))
assert pValue.contents.value == 128
GPU थ्रेड उपयोग कॉन्फ़िगर करें
GPU थ्रेड मोड यह तय करता है कि GPU थ्रेड का उपयोग कैसे किया जाए।
यह सुनिश्चित करने के लिए थ्रेड मोड को gpu_private पर सेट करें कि प्रीप्रोसेसिंग सभी GPU थ्रेड्स को चुरा न ले। यह प्रशिक्षण के दौरान कर्नेल लॉन्च देरी को कम करेगा। आप प्रति GPU प्रति थ्रेड्स की संख्या भी सेट कर सकते हैं। पर्यावरण चर का उपयोग करके इन मूल्यों को सेट करें।
import os
os.environ['TF_GPU_THREAD_MODE']='gpu_private'
os.environ['TF_GPU_THREAD_COUNT']='1'
GPU मेमोरी विकल्प कॉन्फ़िगर करें
सामान्य तौर पर, बैच के आकार में वृद्धि करें और मॉडल को बेहतर तरीके से उपयोग करने के लिए मॉडल को स्केल करें और उच्च थ्रूपुट प्राप्त करें। ध्यान दें कि बैच के आकार को बढ़ाने से मॉडल की सटीकता बदल जाएगी, इसलिए लक्ष्य सटीकता को पूरा करने के लिए सीखने की दर की तरह हाइपरपैमेटर्स को ट्यूनिंग करके मॉडल को स्केल करने की आवश्यकता है।
इसके अलावा, tf.config.experimental.set_memory_growth का उपयोग करें GPU मेमोरी को सभी उपलब्ध मेमोरी को पूरी तरह से OPS को आवंटित होने से रोकने के लिए बढ़ने की अनुमति देने के लिए जो मेमोरी के केवल एक अंश की आवश्यकता होती है। यह अन्य प्रक्रियाओं की अनुमति देता है जो एक ही डिवाइस पर चलने के लिए GPU मेमोरी का उपभोग करते हैं।
अधिक जानने के लिए, अधिक जानने के लिए GPU गाइड में सीमित GPU मेमोरी ग्रोथ गाइडेंस को देखें।
मिश्रित
GPU पर मेमोरी (OOM) त्रुटि के बिना फिट होने वाली अधिकतम राशि के लिए प्रशिक्षण मिनी-बैच आकार (प्रशिक्षण लूप के एक पुनरावृत्ति में प्रति डिवाइस का उपयोग किए गए प्रशिक्षण नमूनों की संख्या) बढ़ाएं। बैच के आकार को बढ़ाने से मॉडल की सटीकता पर प्रभाव पड़ता है - इसलिए सुनिश्चित करें कि आप लक्ष्य सटीकता को पूरा करने के लिए हाइपरप्रेमीटर को ट्यून करके मॉडल को स्केल करें।
उत्पादन कोड में टेंसर आवंटन के दौरान OOM त्रुटियों को अक्षम करें। रिपोर्ट करें
report_tensor_allocations_upon_oom=Falsetf.compat.v1.RunOptionsमें गलत।कन्वेशन लेयर्स वाले मॉडल के लिए, बैच सामान्यीकरण का उपयोग करने पर पूर्वाग्रह जोड़ को हटा दें। बैच सामान्यीकरण अपने माध्य द्वारा मूल्यों को बदल देता है और यह एक निरंतर पूर्वाग्रह शब्द की आवश्यकता को दूर करता है।
टीएफ आँकड़ों का उपयोग करें कि यह पता लगाने के लिए कि ऑन-डिवाइस ऑप्स कितनी कुशलता से चलती है।
कम्प्यूटेशन करने के लिए
tf.functionउपयोग करें और वैकल्पिक रूप से,jit_compile=TrueFlag (tf.function(jit_compile=True) को सक्षम करें। अधिक जानने के लिए, XLA TF.Function का उपयोग करने के लिए जाएं।चरणों के बीच मेजबान पायथन संचालन को कम से कम करें और कॉलबैक को कम करें। हर कदम के बजाय हर कुछ चरणों की गणना करें।
डिवाइस कंप्यूट इकाइयों को व्यस्त रखें।
समानांतर में कई उपकरणों पर डेटा भेजें।
16-बिट संख्यात्मक अभ्यावेदन का उपयोग करने पर विचार करें, जैसे कि
fp16-IEEE द्वारा निर्दिष्ट आधे-सटीक फ्लोटिंग पॉइंट प्रारूप-या मस्तिष्क फ्लोटिंग-पॉइंट Bfloat16 प्रारूप।
अतिरिक्त संसाधन
- TensorFlow Profiler: केरा और टेंसरबोर्ड के साथ प्रोफ़ाइल मॉडल प्रदर्शन ट्यूटोरियल जहां आप इस गाइड में सलाह लागू कर सकते हैं।
- Tensorflow 2 में टेंसरफ्लो देव शिखर सम्मेलन 2020 से प्रदर्शन प्रोफाइलिंग ।
- Tensorflow प्रोफाइलर डेमो टेन्सरफ्लो देव शिखर सम्मेलन 2020 से।
ज्ञात सीमाएँ
Tensorflow 2.2 और TensorFlow 2.3 पर कई GPU को प्रोफाइलिंग करना
TensorFlow 2.2 और 2.3 केवल एकल होस्ट सिस्टम के लिए कई GPU प्रोफाइलिंग का समर्थन करते हैं; मल्टी-होस्ट सिस्टम के लिए एकाधिक जीपीयू प्रोफाइलिंग समर्थित नहीं है। मल्टी-वर्कर जीपीयू कॉन्फ़िगरेशन को प्रोफाइल करने के लिए, प्रत्येक कार्यकर्ता को स्वतंत्र रूप से प्रोफाइल करना होगा। Tensorflow 2.4 से कई श्रमिकों को tf.profiler.experimental.client.trace API का उपयोग करके प्रोफाइल किया जा सकता है।
CUDA® टूलकिट 10.2 या बाद में कई GPU को प्रोफाइल करने की आवश्यकता है। Tensorflow 2.2 और 2.3 के रूप में CUDA® टूलकिट संस्करणों का समर्थन केवल 10.1 तक, आपको libcudart.so.10.1 और libcupti.so.10.1 के लिए प्रतीकात्मक लिंक बनाने की आवश्यकता है।
sudo ln -s /usr/local/cuda/lib64/libcudart.so.10.2 /usr/local/cuda/lib64/libcudart.so.10.1
sudo ln -s /usr/local/cuda/extras/CUPTI/lib64/libcupti.so.10.2 /usr/local/cuda/extras/CUPTI/lib64/libcupti.so.10.1