
| | |  GitHub पर स्रोत देखें GitHub पर स्रोत देखें | |
अवलोकन
यह ट्यूटोरियल डेटा वृद्धि को प्रदर्शित करता है: छवि रोटेशन जैसे यादृच्छिक (लेकिन यथार्थवादी) परिवर्तनों को लागू करके आपके प्रशिक्षण सेट की विविधता को बढ़ाने के लिए एक तकनीक।
आप सीखेंगे कि डेटा वृद्धि को दो तरीकों से कैसे लागू किया जाए:
- केरस प्रीप्रोसेसिंग लेयर्स का उपयोग करें, जैसे कि
tf.keras.layers.Resizing,tf.keras.layers.Rescaling,tf.keras.layers.RandomFlip, औरtf.keras.layers.RandomRotation। -
tf.imageविधियों का उपयोग करें, जैसेtf.image.flip_left_right,tf.image.rgb_to_grayscale,tf.image.adjust_brightness,tf.image.central_crop, औरtf.image.stateless_random*।
सेट अप
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow.keras import layers
डेटासेट डाउनलोड करें
यह ट्यूटोरियल tf_flowers डेटासेट का उपयोग करता है। सुविधा के लिए, TensorFlow डेटासेट का उपयोग करके डेटासेट डाउनलोड करें। यदि आप डेटा आयात करने के अन्य तरीकों के बारे में जानना चाहते हैं, तो लोड इमेज ट्यूटोरियल देखें।
(train_ds, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
फूल डेटासेट में पांच वर्ग होते हैं।
num_classes = metadata.features['label'].num_classes
print(num_classes)
5
आइए डेटासेट से एक छवि पुनर्प्राप्त करें और डेटा वृद्धि को प्रदर्शित करने के लिए इसका उपयोग करें।
get_label_name = metadata.features['label'].int2str
image, label = next(iter(train_ds))
_ = plt.imshow(image)
_ = plt.title(get_label_name(label))
2022-01-26 05:09:18.712477: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.

केरस प्रीप्रोसेसिंग परतों का प्रयोग करें
आकार बदलना और आकार बदलना
आप अपनी छवियों को एक सुसंगत आकार ( tf.keras.layers.Resizing के साथ) और पिक्सेल मानों को फिर से स्केल करने के लिए ( tf.keras.layers.Rescaling के साथ) आकार बदलने के लिए केरस प्रीप्रोसेसिंग परतों का उपयोग कर सकते हैं।
IMG_SIZE = 180
resize_and_rescale = tf.keras.Sequential([
layers.Resizing(IMG_SIZE, IMG_SIZE),
layers.Rescaling(1./255)
])
आप इन परतों को एक छवि पर लागू करने के परिणाम की कल्पना कर सकते हैं।
result = resize_and_rescale(image)
_ = plt.imshow(result)
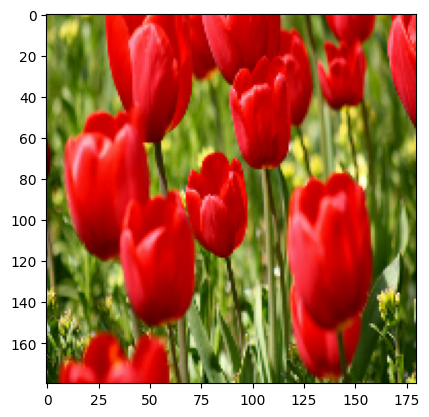
सत्यापित करें कि पिक्सेल [0, 1] श्रेणी में हैं:
print("Min and max pixel values:", result.numpy().min(), result.numpy().max())
Min and max pixel values: 0.0 1.0
डेटा वृद्धि
आप डेटा वृद्धि के लिए केरस प्रीप्रोसेसिंग परतों का भी उपयोग कर सकते हैं, जैसे कि tf.keras.layers.RandomFlip और tf.keras.layers.RandomRotation ।
आइए कुछ प्रीप्रोसेसिंग परतें बनाएं और उन्हें एक ही छवि पर बार-बार लागू करें।
data_augmentation = tf.keras.Sequential([
layers.RandomFlip("horizontal_and_vertical"),
layers.RandomRotation(0.2),
])
# Add the image to a batch.
image = tf.expand_dims(image, 0)
plt.figure(figsize=(10, 10))
for i in range(9):
augmented_image = data_augmentation(image)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_image[0])
plt.axis("off")
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

tf.keras.layers.RandomContrast , tf.keras.layers.RandomCrop , tf.keras.layers.RandomZoom , और अन्य सहित कई प्रकार की प्रीप्रोसेसिंग परतें हैं जिनका उपयोग आप डेटा वृद्धि के लिए कर सकते हैं।
केरस प्रीप्रोसेसिंग परतों का उपयोग करने के लिए दो विकल्प
महत्वपूर्ण ट्रेड-ऑफ के साथ, आप इन प्रीप्रोसेसिंग परतों का उपयोग करने के दो तरीके हैं।
विकल्प 1: प्रीप्रोसेसिंग परतों को अपने मॉडल का हिस्सा बनाएं
model = tf.keras.Sequential([
# Add the preprocessing layers you created earlier.
resize_and_rescale,
data_augmentation,
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
# Rest of your model.
])
इस मामले में ध्यान रखने योग्य दो महत्वपूर्ण बिंदु हैं:
डेटा संवर्द्धन डिवाइस पर चलेगा, आपकी बाकी परतों के साथ समकालिक रूप से चलेगा, और GPU त्वरण से लाभान्वित होगा।
जब आप
model.saveका उपयोग करके अपना मॉडल निर्यात करते हैं, तो प्रीप्रोसेसिंग परतें आपके बाकी मॉडल के साथ सहेजी जाएंगी। यदि आप बाद में इस मॉडल को परिनियोजित करते हैं, तो यह स्वचालित रूप से छवियों का मानकीकरण करेगा (आपकी परतों के कॉन्फ़िगरेशन के अनुसार)। यह आपको उस लॉजिक सर्वर-साइड को फिर से लागू करने के प्रयास से बचा सकता है।
विकल्प 2: अपने डेटासेट पर प्रीप्रोसेसिंग परतें लागू करें
aug_ds = train_ds.map(
lambda x, y: (resize_and_rescale(x, training=True), y))
इस दृष्टिकोण के साथ, आप डेटासेट बनाने के लिए Dataset.map का उपयोग करते हैं जो संवर्धित छवियों के बैच उत्पन्न करता है। इस मामले में:
- डेटा संवर्द्धन सीपीयू पर अतुल्यकालिक रूप से होगा, और गैर-अवरुद्ध है। आप नीचे दिखाए गए
Dataset.prefetchका उपयोग करके डेटा प्रीप्रोसेसिंग के साथ GPU पर अपने मॉडल के प्रशिक्षण को ओवरलैप कर सकते हैं। - इस मामले में जब आप
Model.saveको कॉल करते हैं तो प्रीप्रोसेसिंग परतें मॉडल के साथ निर्यात नहीं की जाएंगी। आपको इसे सहेजने या सर्वर-साइड को फिर से लागू करने से पहले उन्हें अपने मॉडल में संलग्न करना होगा। प्रशिक्षण के बाद, आप निर्यात से पहले प्रीप्रोसेसिंग परतों को संलग्न कर सकते हैं।
आप छवि वर्गीकरण ट्यूटोरियल में पहले विकल्प का एक उदाहरण पा सकते हैं। आइए यहां दूसरा विकल्प प्रदर्शित करें।
डेटासेट पर प्रीप्रोसेसिंग परतें लागू करें
आपके द्वारा पहले बनाई गई केरस प्रीप्रोसेसिंग परतों के साथ प्रशिक्षण, सत्यापन और परीक्षण डेटासेट को कॉन्फ़िगर करें। I/O ब्लॉक किए बिना डिस्क से बैचों को प्राप्त करने के लिए समानांतर रीड और बफर्ड प्रीफेचिंग का उपयोग करके आप प्रदर्शन के लिए डेटासेट को भी कॉन्फ़िगर करेंगे। ( tf.data API मार्गदर्शिका के साथ बेहतर प्रदर्शन में अधिक डेटासेट प्रदर्शन जानें।)
batch_size = 32
AUTOTUNE = tf.data.AUTOTUNE
def prepare(ds, shuffle=False, augment=False):
# Resize and rescale all datasets.
ds = ds.map(lambda x, y: (resize_and_rescale(x), y),
num_parallel_calls=AUTOTUNE)
if shuffle:
ds = ds.shuffle(1000)
# Batch all datasets.
ds = ds.batch(batch_size)
# Use data augmentation only on the training set.
if augment:
ds = ds.map(lambda x, y: (data_augmentation(x, training=True), y),
num_parallel_calls=AUTOTUNE)
# Use buffered prefetching on all datasets.
return ds.prefetch(buffer_size=AUTOTUNE)
train_ds = prepare(train_ds, shuffle=True, augment=True)
val_ds = prepare(val_ds)
test_ds = prepare(test_ds)
एक मॉडल को प्रशिक्षित करें
पूर्णता के लिए, अब आप अपने द्वारा अभी तैयार किए गए डेटासेट का उपयोग करके एक मॉडल को प्रशिक्षित करेंगे।
अनुक्रमिक मॉडल में तीन कनवल्शन ब्लॉक होते हैं ( tf.keras.layers.Conv2D ) जिनमें से प्रत्येक में अधिकतम पूलिंग परत ( tf.keras.layers.MaxPooling2D ) होती है। एक पूरी तरह से जुड़ी हुई परत है ( tf.keras.layers.Dense ) जिसके ऊपर 128 इकाइयाँ हैं जो एक ReLU सक्रियण फ़ंक्शन ( 'relu' ) द्वारा सक्रिय है। इस मॉडल को सटीकता के लिए ट्यून नहीं किया गया है (लक्ष्य आपको यांत्रिकी दिखाना है)।
model = tf.keras.Sequential([
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes)
])
tf.keras.optimizers.Adam ऑप्टिमाइज़र और tf.keras.losses.SparseCategoricalCrossentropy loss function चुनें। प्रत्येक प्रशिक्षण युग के लिए प्रशिक्षण और सत्यापन सटीकता देखने के लिए, metrics तर्क को Model.compile पर पास करें।
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
कुछ युगों के लिए ट्रेन:
epochs=5
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
Epoch 1/5 92/92 [==============================] - 13s 110ms/step - loss: 1.2768 - accuracy: 0.4622 - val_loss: 1.0929 - val_accuracy: 0.5640 Epoch 2/5 92/92 [==============================] - 3s 25ms/step - loss: 1.0579 - accuracy: 0.5749 - val_loss: 0.9711 - val_accuracy: 0.6349 Epoch 3/5 92/92 [==============================] - 3s 26ms/step - loss: 0.9677 - accuracy: 0.6291 - val_loss: 0.9764 - val_accuracy: 0.6431 Epoch 4/5 92/92 [==============================] - 3s 25ms/step - loss: 0.9150 - accuracy: 0.6468 - val_loss: 0.8906 - val_accuracy: 0.6431 Epoch 5/5 92/92 [==============================] - 3s 25ms/step - loss: 0.8636 - accuracy: 0.6604 - val_loss: 0.8233 - val_accuracy: 0.6730
loss, acc = model.evaluate(test_ds)
print("Accuracy", acc)
12/12 [==============================] - 5s 14ms/step - loss: 0.7922 - accuracy: 0.6948 Accuracy 0.6948229074478149
कस्टम डेटा वृद्धि
आप कस्टम डेटा वृद्धि परतें भी बना सकते हैं।
ट्यूटोरियल का यह खंड ऐसा करने के दो तरीके दिखाता है:
- सबसे पहले, आप एक
tf.keras.layers.Lambdaलेयर बनाएंगे। संक्षिप्त कोड लिखने का यह एक अच्छा तरीका है। - इसके बाद, आप उपवर्ग के माध्यम से एक नई परत लिखेंगे, जो आपको अधिक नियंत्रण प्रदान करती है।
कुछ संभावना के अनुसार, दोनों परतें एक छवि में रंगों को बेतरतीब ढंग से उलट देंगी।
def random_invert_img(x, p=0.5):
if tf.random.uniform([]) < p:
x = (255-x)
else:
x
return x
def random_invert(factor=0.5):
return layers.Lambda(lambda x: random_invert_img(x, factor))
random_invert = random_invert()
plt.figure(figsize=(10, 10))
for i in range(9):
augmented_image = random_invert(image)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_image[0].numpy().astype("uint8"))
plt.axis("off")
2022-01-26 05:09:53.045204: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045264: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045312: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045369: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045418: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045467: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045511: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.047630: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module

इसके बाद, उपवर्ग द्वारा एक कस्टम परत लागू करें:
class RandomInvert(layers.Layer):
def __init__(self, factor=0.5, **kwargs):
super().__init__(**kwargs)
self.factor = factor
def call(self, x):
return random_invert_img(x)
_ = plt.imshow(RandomInvert()(image)[0])

इन दोनों परतों का उपयोग ऊपर विकल्प 1 और 2 में वर्णित अनुसार किया जा सकता है।
tf.छवि का उपयोग करना
उपरोक्त केरस प्रीप्रोसेसिंग उपयोगिताओं सुविधाजनक हैं। लेकिन, बेहतर नियंत्रण के लिए, आप tf.data और tf.image का उपयोग करके अपनी डेटा वृद्धि पाइपलाइन या परतें लिख सकते हैं। (आप TensorFlow Addons Image: Operations and TensorFlow I/O: Color Space Converts भी देखना चाह सकते हैं।)
चूंकि फूलों के डेटासेट को पहले डेटा वृद्धि के साथ कॉन्फ़िगर किया गया था, आइए इसे नए सिरे से शुरू करने के लिए पुन: आयात करें:
(train_ds, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
साथ काम करने के लिए एक छवि प्राप्त करें:
image, label = next(iter(train_ds))
_ = plt.imshow(image)
_ = plt.title(get_label_name(label))
2022-01-26 05:09:59.918847: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.प्लेसहोल्डर33

आइए मूल और संवर्धित छवियों को साथ-साथ देखने और तुलना करने के लिए निम्नलिखित फ़ंक्शन का उपयोग करें:
def visualize(original, augmented):
fig = plt.figure()
plt.subplot(1,2,1)
plt.title('Original image')
plt.imshow(original)
plt.subplot(1,2,2)
plt.title('Augmented image')
plt.imshow(augmented)
डेटा वृद्धि
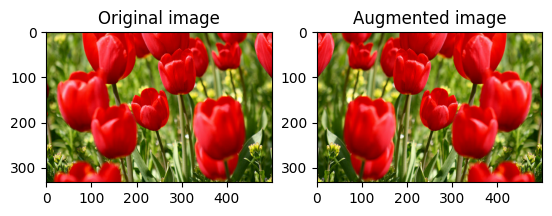
एक छवि पलटें
tf.image.flip_left_right के साथ किसी छवि को लंबवत या क्षैतिज रूप से फ़्लिप करें:
flipped = tf.image.flip_left_right(image)
visualize(image, flipped)
छवि को ग्रेस्केल करें
आप tf.image.rgb_to_grayscale के साथ एक छवि को ग्रेस्केल कर सकते हैं:
grayscaled = tf.image.rgb_to_grayscale(image)
visualize(image, tf.squeeze(grayscaled))
_ = plt.colorbar()

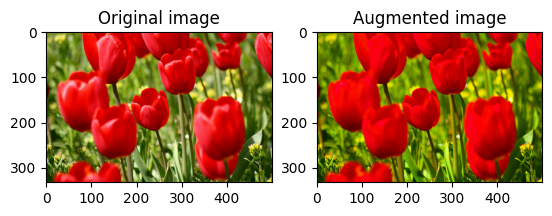
एक छवि को संतृप्त करें
संतृप्ति कारक प्रदान करके tf.image.adjust_saturation के साथ एक छवि को संतृप्त करें:
saturated = tf.image.adjust_saturation(image, 3)
visualize(image, saturated)
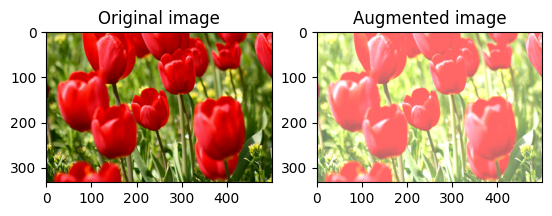
छवि चमक बदलें
एक चमक कारक प्रदान करके छवि की चमक को tf.image.adjust_brightness के साथ बदलें:
bright = tf.image.adjust_brightness(image, 0.4)
visualize(image, bright)
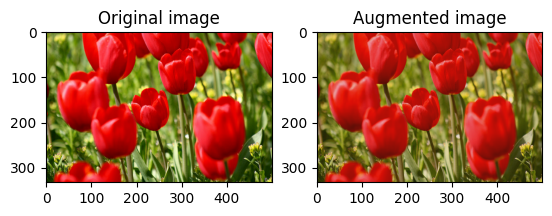
केंद्र में एक छवि क्रॉप करें
tf.image.central_crop का उपयोग करके छवि को केंद्र से छवि भाग तक क्रॉप करें जिसे आप चाहते हैं:
cropped = tf.image.central_crop(image, central_fraction=0.5)
visualize(image, cropped)
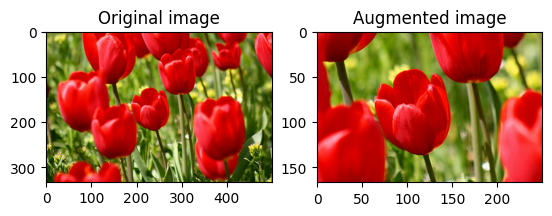
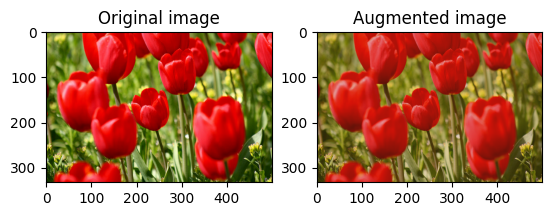
एक छवि घुमाएँ
tf.image.rot90 के साथ किसी छवि को 90 डिग्री घुमाएँ:
rotated = tf.image.rot90(image)
visualize(image, rotated)

यादृच्छिक परिवर्तन
छवियों में यादृच्छिक परिवर्तन लागू करने से डेटासेट को सामान्य बनाने और विस्तारित करने में मदद मिल सकती है। वर्तमान tf.image API आठ ऐसे यादृच्छिक छवि संचालन (ऑप्स) प्रदान करता है:
-
tf.image.stateless_random_brightness -
tf.image.stateless_random_contrast -
tf.image.stateless_random_crop -
tf.image.stateless_random_flip_left_right -
tf.image.stateless_random_flip_up_down -
tf.image.stateless_random_hue -
tf.image.stateless_random_jpeg_quality -
tf.image.stateless_random_saturation
ये रैंडम इमेज ऑप्स विशुद्ध रूप से कार्यात्मक हैं: आउटपुट केवल इनपुट पर निर्भर करता है। यह उन्हें उच्च प्रदर्शन, नियतात्मक इनपुट पाइपलाइनों में उपयोग करने में आसान बनाता है। उन्हें प्रत्येक चरण में एक seed मूल्य इनपुट की आवश्यकता होती है। एक ही seed को देखते हुए, वे कितनी बार बुलाए जाने से स्वतंत्र होकर वही परिणाम लौटाते हैं।
निम्नलिखित अनुभागों में, आप करेंगे:
- एक छवि को बदलने के लिए यादृच्छिक छवि संचालन का उपयोग करने के उदाहरणों पर जाएं।
- एक प्रशिक्षण डेटासेट में यादृच्छिक परिवर्तनों को लागू करने का तरीका प्रदर्शित करें।
छवि चमक को बेतरतीब ढंग से बदलें
एक चमक कारक और seed प्रदान करके tf.image.stateless_random_brightness का उपयोग करके image की चमक को यादृच्छिक रूप से बदलें। ब्राइटनेस फैक्टर [-max_delta, max_delta) रेंज में बेतरतीब ढंग से चुना जाता है और दिए गए seed से जुड़ा होता है।
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_brightness = tf.image.stateless_random_brightness(
image, max_delta=0.95, seed=seed)
visualize(image, stateless_random_brightness)
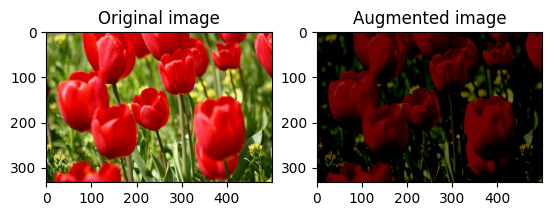
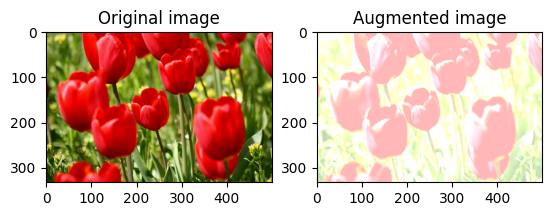
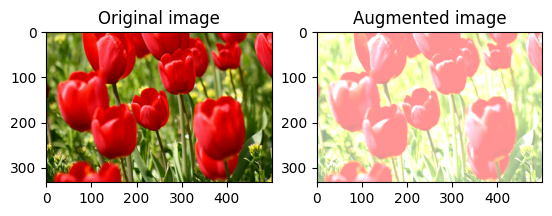
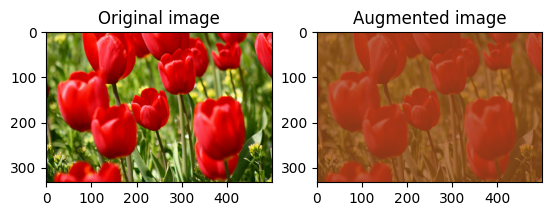
छवि कंट्रास्ट को बेतरतीब ढंग से बदलें
कंट्रास्ट रेंज और seed प्रदान करके tf.image.stateless_random_contrast का उपयोग करके image के कंट्रास्ट को यादृच्छिक रूप से बदलें। कंट्रास्ट रेंज को अंतराल [lower, upper] में यादृच्छिक रूप से चुना जाता है और दिए गए seed से जुड़ा होता है।
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_contrast = tf.image.stateless_random_contrast(
image, lower=0.1, upper=0.9, seed=seed)
visualize(image, stateless_random_contrast)
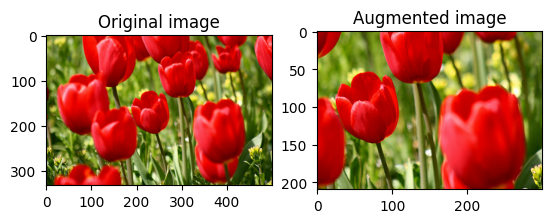
छवि को बेतरतीब ढंग से क्रॉप करें
लक्ष्य size और seed प्रदान करके tf.image.stateless_random_crop का उपयोग करके image को बेतरतीब ढंग से क्रॉप करें। image से जो हिस्सा काट दिया जाता है वह बेतरतीब ढंग से चुने गए ऑफसेट पर होता है और दिए गए seed से जुड़ा होता है।
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_crop = tf.image.stateless_random_crop(
image, size=[210, 300, 3], seed=seed)
visualize(image, stateless_random_crop)
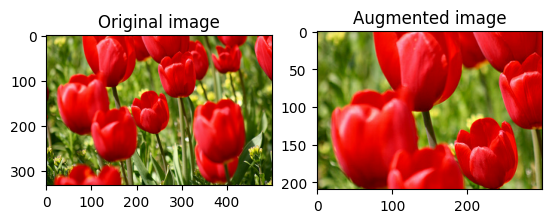
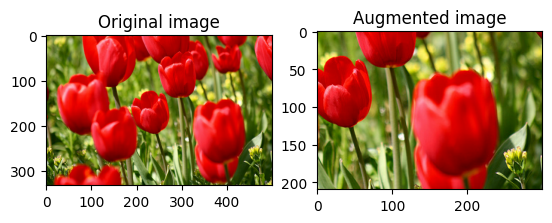
डेटासेट में वृद्धि लागू करें
आइए पहले छवि डेटासेट को फिर से डाउनलोड करें यदि वे पिछले अनुभागों में संशोधित हैं।
(train_datasets, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
इसके बाद, छवियों का आकार बदलने और उन्हें छोटा करने के लिए उपयोगिता फ़ंक्शन को परिभाषित करें। इस फ़ंक्शन का उपयोग डेटासेट में छवियों के आकार और पैमाने को एकीकृत करने में किया जाएगा:
def resize_and_rescale(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, [IMG_SIZE, IMG_SIZE])
image = (image / 255.0)
return image, label
आइए augment फ़ंक्शन को भी परिभाषित करें जो छवियों में यादृच्छिक परिवर्तन लागू कर सकता है। इस फ़ंक्शन का उपयोग अगले चरण में डेटासेट पर किया जाएगा।
def augment(image_label, seed):
image, label = image_label
image, label = resize_and_rescale(image, label)
image = tf.image.resize_with_crop_or_pad(image, IMG_SIZE + 6, IMG_SIZE + 6)
# Make a new seed.
new_seed = tf.random.experimental.stateless_split(seed, num=1)[0, :]
# Random crop back to the original size.
image = tf.image.stateless_random_crop(
image, size=[IMG_SIZE, IMG_SIZE, 3], seed=seed)
# Random brightness.
image = tf.image.stateless_random_brightness(
image, max_delta=0.5, seed=new_seed)
image = tf.clip_by_value(image, 0, 1)
return image, label
विकल्प 1: tf.data.experimental.Counter का उपयोग करना
एक tf.data.experimental.Counter ऑब्जेक्ट बनाएं (इसे counter कहते हैं) और डेटासेट को (counter, counter) के साथ डेटासेट Dataset.zip करें। यह सुनिश्चित करेगा कि डेटासेट में प्रत्येक छवि counter के आधार पर एक अद्वितीय मूल्य (आकार (2,) ) के साथ जुड़ी हो, जो बाद में यादृच्छिक परिवर्तनों के लिए seed मूल्य के रूप में augment समारोह में पारित हो सकती है।
# Create a `Counter` object and `Dataset.zip` it together with the training set.
counter = tf.data.experimental.Counter()
train_ds = tf.data.Dataset.zip((train_datasets, (counter, counter)))
प्रशिक्षण डेटासेट में augment फ़ंक्शन को मैप करें:
train_ds = (
train_ds
.shuffle(1000)
.map(augment, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
val_ds = (
val_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
test_ds = (
test_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
विकल्प 2: tf.random.Generator का उपयोग करना
- प्रारंभिक
seedमान के साथ एकtf.random.Generatorऑब्जेक्ट बनाएं। एक ही जनरेटर ऑब्जेक्ट परmake_seedsफ़ंक्शन को कॉल करना हमेशा एक नया, अद्वितीयseedमान देता है। - एक रैपर फ़ंक्शन को परिभाषित करें जो: 1)
make_seedsफ़ंक्शन को कॉल करता है; और 2) यादृच्छिक परिवर्तनों के लिए नए उत्पन्नseedमूल्य कोaugmentसमारोह में पास करता है।
# Create a generator.
rng = tf.random.Generator.from_seed(123, alg='philox')
# Create a wrapper function for updating seeds.
def f(x, y):
seed = rng.make_seeds(2)[0]
image, label = augment((x, y), seed)
return image, label
रैपर फ़ंक्शन f को प्रशिक्षण डेटासेट में मैप करें, और resize_and_rescale फ़ंक्शन—सत्यापन और परीक्षण सेट के लिए:
train_ds = (
train_datasets
.shuffle(1000)
.map(f, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
val_ds = (
val_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
test_ds = (
test_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
जैसा कि पहले दिखाया गया है, इन डेटासेट का उपयोग अब एक मॉडल को प्रशिक्षित करने के लिए किया जा सकता है।
अगले कदम
इस ट्यूटोरियल ने केरस प्रीप्रोसेसिंग लेयर्स और tf.image का उपयोग करके डेटा वृद्धि का प्रदर्शन किया।
- अपने मॉडल के अंदर प्रीप्रोसेसिंग परतों को शामिल करने का तरीका जानने के लिए, छवि वर्गीकरण ट्यूटोरियल देखें।
- आपको यह सीखने में भी रुचि हो सकती है कि प्रीप्रोसेसिंग परतें टेक्स्ट को वर्गीकृत करने में आपकी मदद कैसे कर सकती हैं, जैसा कि मूल टेक्स्ट वर्गीकरण ट्यूटोरियल में दिखाया गया है।
- आप इस गाइड में
tf.dataके बारे में अधिक जान सकते हैं, और आप यहां प्रदर्शन के लिए अपनी इनपुट पाइपलाइनों को कॉन्फ़िगर करना सीख सकते हैं।