
מדריך זה מדגים כיצד להשתמש בכלים הזמינים עם TensorFlow Profiler כדי לעקוב אחר הביצועים של דגמי TensorFlow שלך. תלמד כיצד להבין כיצד המודל שלך מתפקד במארח (CPU), במכשיר (GPU), או בשילוב של המארח והמכשיר(ים).
פרופיל עוזר להבין את צריכת משאבי החומרה (זמן וזיכרון) של פעולות TensorFlow השונות (ops) במודל שלך ולפתור צווארי בקבוק בביצועים ובסופו של דבר לגרום למודל לפעול מהר יותר.
מדריך זה ידריך אותך כיצד להתקין את ה- Profiler, את הכלים השונים הזמינים, את המצבים השונים של האופן שבו ה- Profiler אוסף נתוני ביצועים, וכמה שיטות עבודה מומלצות מומלצות למיטוב ביצועי המודל.
אם ברצונך ליצור פרופיל של ביצועי הדגם שלך ב-Cloud TPUs, עיין במדריך Cloud TPU .
התקן את התנאים המוקדמים של Profiler ו-GPU
התקן את הפלאגין Profiler עבור TensorBoard עם pip. שימו לב שהפרופיל דורש את הגירסאות העדכניות ביותר של TensorFlow ו-TensorBoard (>=2.2).
pip install -U tensorboard_plugin_profile
כדי ליצור פרופיל ב-GPU, עליך:
- עמוד בדרישות מנהלי ההתקן של NVIDIA® GPU ודרישות CUDA® Toolkit המפורטות בדרישות התוכנה לתמיכה ב- TensorFlow GPU .
ודא שממשק כלי הפרופילים של NVIDIA® CUDA® (CUPTI) קיים בנתיב:
/sbin/ldconfig -N -v $(sed 's/:/ /g' <<< $LD_LIBRARY_PATH) | \ grep libcupti
אם אין לך CUPTI בנתיב, הוסף את ספריית ההתקנה שלו למשתנה הסביבה $LD_LIBRARY_PATH על ידי הפעלת:
export LD_LIBRARY_PATH=/usr/local/cuda/extras/CUPTI/lib64:$LD_LIBRARY_PATH
לאחר מכן, הפעל שוב את הפקודה ldconfig למעלה כדי לוודא שספריית CUPTI נמצאה.
פתרון בעיות הרשאות
כאשר אתה מפעיל פרופילים עם CUDA® Toolkit בסביבת Docker או ב-Linux, אתה עלול להיתקל בבעיות הקשורות להרשאות CUPTI לא מספיקות ( CUPTI_ERROR_INSUFFICIENT_PRIVILEGES ). עבור אל NVIDIA Developer Docs כדי ללמוד עוד על איך אתה יכול לפתור בעיות אלה ב-Linux.
כדי לפתור בעיות הרשאות CUPTI בסביבת Docker, הפעל
docker run option '--privileged=true'
כלים לפרופילים
גש ל-Profiler מהכרטיסייה Profile ב-TensorBoard, המופיעה רק לאחר שלכדת כמה נתוני דגם.
ל-Profiler יש מבחר של כלים שיעזרו בניתוח ביצועים:
- דף סקירה
- מנתח צינור קלט
- סטטיסטיקות TensorFlow
- Trace Viewer
- נתונים סטטיסטיים של ליבת GPU
- כלי פרופיל זיכרון
- Pod Viewer
דף סקירה כללית
דף הסקירה מספק תצוגה ברמה העליונה של ביצועי המודל שלך במהלך ריצת פרופיל. הדף מציג לך דף סקירה מצטבר עבור המארח שלך וכל המכשירים, וכמה המלצות לשיפור ביצועי האימון שלך במודל. אתה יכול גם לבחור מארחים בודדים בתפריט הנפתח מארח.
דף הסקירה מציג נתונים באופן הבא:
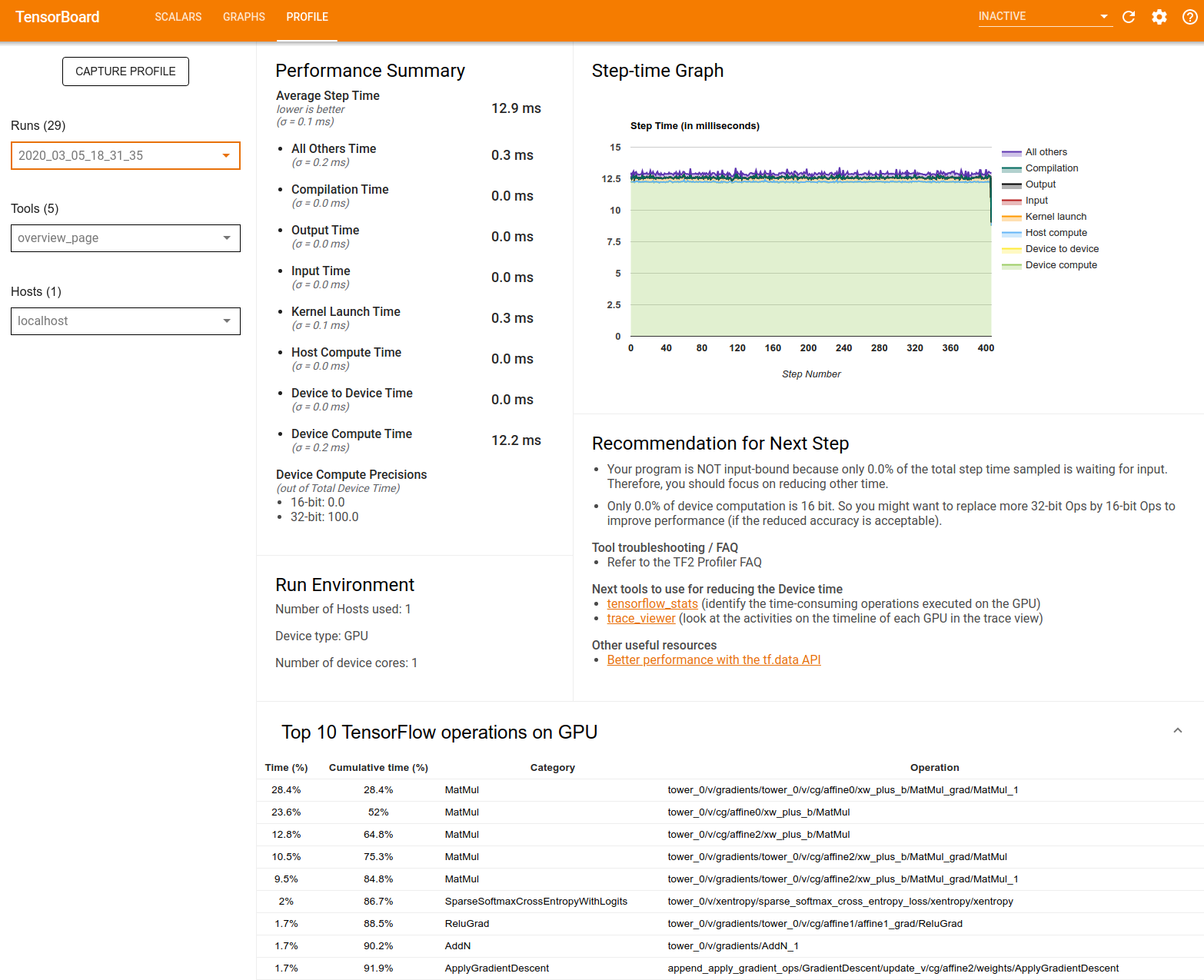
סיכום ביצועים : מציג סיכום ברמה גבוהה של ביצועי הדגם שלך. סיכום הביצועים כולל שני חלקים:
פירוט זמן שלבים: מפרק את זמן הצעד הממוצע למספר קטגוריות של מקומות בילוי:
- קומפילציה: הזמן המושקע בקומפילציה של גרעינים.
- קלט: הזמן המושקע בקריאת נתוני קלט.
- פלט: הזמן המושקע בקריאת נתוני הפלט.
- השקת ליבה: זמן השקת המארח להפעלת גרעינים
- זמן חישוב מארח..
- זמן תקשורת בין מכשיר למכשיר.
- זמן חישוב במכשיר.
- כל השאר, כולל Python תקורה.
דיוק מחשוב במכשיר - מדווח על אחוז זמן החישוב של המכשיר המשתמש בחישובים של 16 ו-32 סיביות.
גרף זמן צעד : מציג גרף של זמן הצעד של המכשיר (במילישניות) על פני כל השלבים שנדגמו. כל שלב מחולק לקטגוריות מרובות (עם צבעים שונים) של המקום שבו הזמן מבלה. האזור האדום מתאים לחלק מזמן הצעד שבו המכשירים ישבו בטל והמתינו לנתוני קלט מהמארח. האזור הירוק מראה כמה זמן המכשיר פעל בפועל.
10 פעולות TensorFlow המובילות במכשיר (למשל GPU) : מציג את הפעולות במכשיר שרצו הכי הרבה זמן.
כל שורה מציגה את הזמן העצמי של המבצע (כאחוז הזמן שלוקח כל המבצעים), זמן מצטבר, קטגוריה ושם.
סביבת ריצה : מציג סיכום ברמה גבוהה של סביבת הריצה של המודל כולל:
- מספר המארחים בשימוש.
- סוג מכשיר (GPU/TPU).
- מספר ליבות המכשיר.
המלצה לשלב הבא : מדווח כאשר מודל קשור לקלט וממליץ על כלים שבהם תוכל להשתמש כדי לאתר ולפתור צווארי בקבוק בביצועי המודל.
מנתח צינור קלט
כאשר תוכנת TensorFlow קוראת נתונים מקובץ היא מתחילה בחלק העליון של גרף TensorFlow בצורה צנרת. תהליך הקריאה מחולק למספר שלבי עיבוד נתונים המחוברים בסדרה, כאשר הפלט של שלב אחד הוא הקלט לשלב הבא. מערכת זו של קריאת נתונים נקראת צינור הקלט .
לצינור טיפוסי לקריאת רשומות מקבצים יש את השלבים הבאים:
- קריאת קובץ.
- עיבוד מקדים של קבצים (אופציונלי).
- העברת קבצים מהמארח למכשיר.
צינור קלט לא יעיל יכול להאט מאוד את היישום שלך. אפליקציה נחשבת כבולה לקלט כאשר היא מבלה חלק ניכר מהזמן בצינור הקלט. השתמש בתובנות שהתקבלו מנתח צינור הקלט כדי להבין היכן צינור הקלט אינו יעיל.
מנתח צינור הקלט אומר לך מיד אם התוכנית שלך קשורה לקלט ומנחה אותך דרך ניתוח צד המכשיר והמארח כדי לאתר באגים בצווארי בקבוק בכל שלב בצינור הקלט.
בדוק את ההנחיות לגבי ביצועי צינור קלט עבור שיטות עבודה מומלצות מומלצות למיטוב צינורות קלט הנתונים שלך.
לוח מחוונים של צינור קלט
כדי לפתוח את מנתח צינור הקלט, בחר פרופיל , ולאחר מכן בחר input_pipeline_analyzer מהתפריט הנפתח כלים .
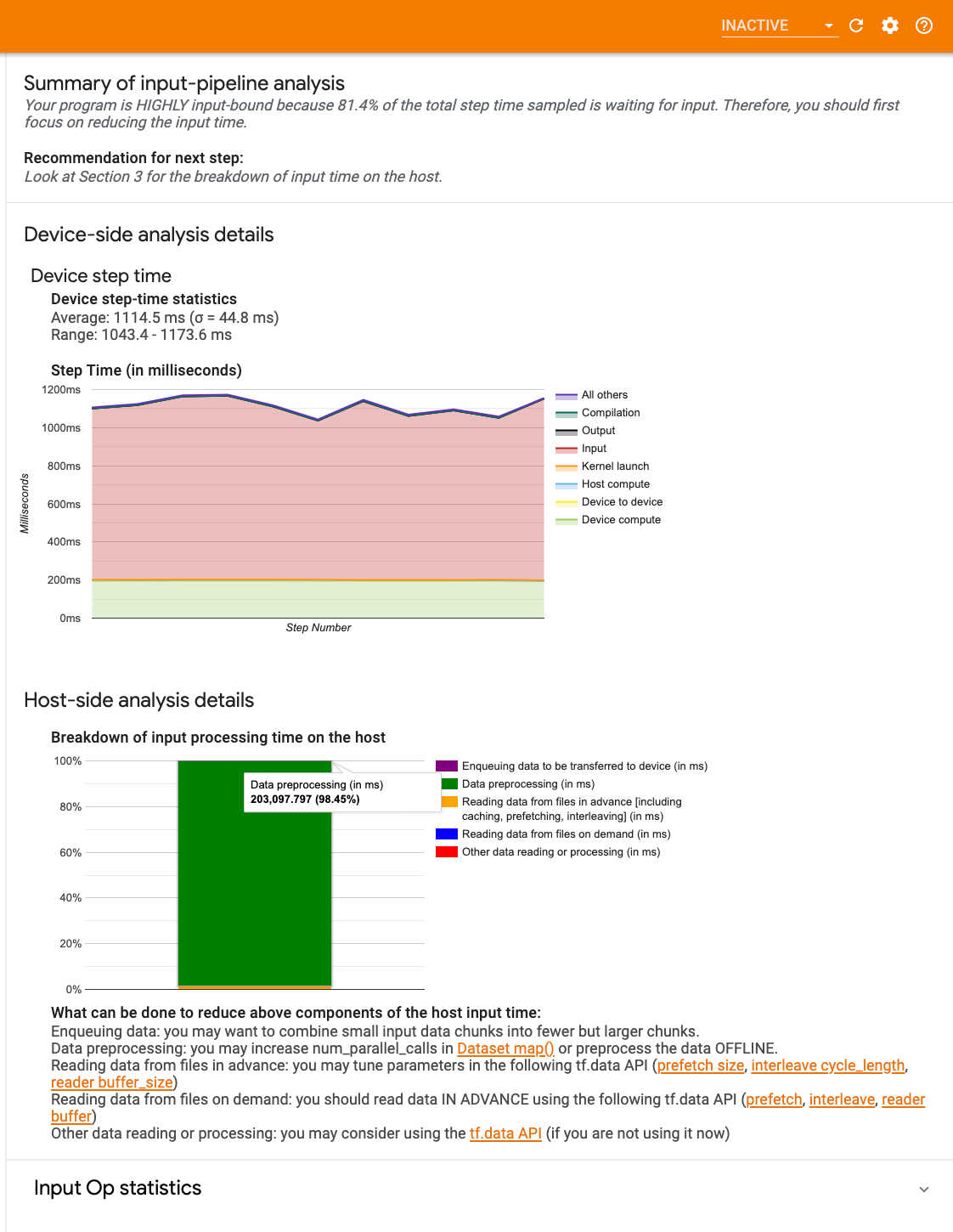
לוח המחוונים מכיל שלושה חלקים:
- סיכום : מסכם את צינור הקלט הכולל עם מידע על האם היישום שלך קשור לקלט ואם כן, בכמה.
- ניתוח צד המכשיר : מציג תוצאות ניתוח מפורטות בצד המכשיר, כולל זמן הצעד של המכשיר וטווח הזמן המושקע בהמתנה לנתוני קלט על פני הליבות בכל שלב.
- ניתוח צד המארח : מציג ניתוח מפורט בצד המארח, כולל פירוט של זמן עיבוד הקלט במארח.
סיכום צינור קלט
הסיכום מדווח אם התוכנית שלך קשורה לקלט על ידי הצגת אחוז זמן המכשיר המושקע בהמתנה לקלט מהמארח. אם אתה משתמש בצינור קלט סטנדרטי שהותקן, הכלי מדווח היכן מושקע רוב זמן עיבוד הקלט.
ניתוח צד המכשיר
ניתוח צד המכשיר מספק תובנות לגבי זמן שהייה במכשיר לעומת המארח וכמה זמן המכשיר הושקע בהמתנה לנתוני קלט מהמארח.
- זמן הצעד משורטט כנגד מספר הצעד : מציג גרף של זמן הצעד של המכשיר (במילישניות) על פני כל השלבים שנדגמו. כל שלב מחולק לקטגוריות מרובות (עם צבעים שונים) של המקום שבו הזמן מבלה. האזור האדום מתאים לחלק מזמן הצעד שבו המכשירים ישבו בטל והמתינו לנתוני קלט מהמארח. האזור הירוק מראה כמה מהזמן המכשיר פעל בפועל.
- סטטיסטיקת זמן צעד : מדווחת על הממוצע, סטיית התקן והטווח ([מינימום, מקסימום]) של זמן הצעד של המכשיר.
ניתוח צד המארח
הניתוח בצד המארח מדווח על פירוט של זמן עיבוד הקלט (הזמן המושקע ב- tf.data API ops) על המארח למספר קטגוריות:
- קריאת נתונים מקבצים לפי דרישה : הזמן המושקע בקריאת נתונים מקבצים ללא אחסון במטמון, אחזור מראש והשזירה.
- קריאת נתונים מקבצים מראש : הזמן המושקע בקריאת קבצים, כולל שמירה במטמון, אחזור מראש ושזירה.
- עיבוד מקדים של נתונים : הזמן המושקע בפעולות עיבוד מקדים, כגון פירוק תמונה.
- הצבת נתונים בתור שיועברו למכשיר : הזמן המושקע בהכנסת נתונים לתור הזנה לפני העברת הנתונים למכשיר.
הרחב את סטטיסטיקת הפעלה של קלט כדי לבדוק את הנתונים הסטטיסטיים של פעולות קלט בודדות והקטגוריות שלהן בחלוקה לפי זמן ביצוע.
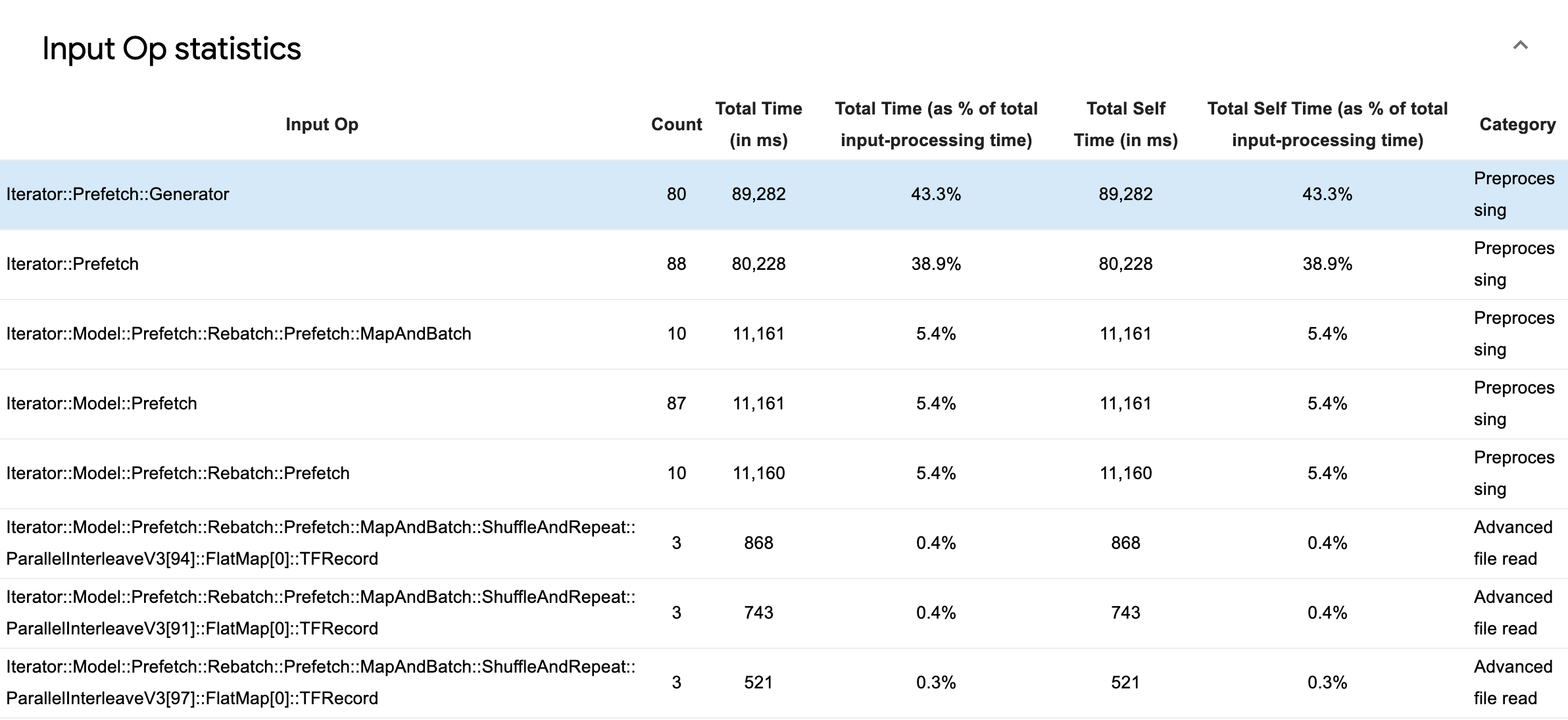
טבלת נתוני מקור תופיע עם כל ערך שמכיל את המידע הבא:
- Input Op : מציג את שם ה-Op TensorFlow של ה-Input Op.
- ספירה : מציג את המספר הכולל של מופעים של ביצוע פעולות במהלך תקופת הפרופיל.
- זמן כולל (בשניות השנייה) : מציג את הסכום המצטבר של הזמן שהושקע בכל אחד מהמקרים הללו.
- Total Time % : מציג את הזמן הכולל שהושקע ב-op כשבריר מהזמן הכולל שהושקע בעיבוד קלט.
- זמן עצמי כולל (ב-ms) : מציג את הסכום המצטבר של הזמן העצמי שהושקע בכל אחד מהמקרים האלה. הזמן העצמי כאן מודד את הזמן המושקע בתוך גוף הפונקציה, למעט הזמן המושקע בפונקציה שהוא קורא.
- סך זמן עצמי % . מציג את הזמן העצמי הכולל כשבריר מהזמן הכולל שהושקע בעיבוד קלט.
- קטגוריה . מציג את קטגוריית העיבוד של הקלט op.
נתונים סטטיסטיים של TensorFlow
הכלי TensorFlow Stats מציג את הביצועים של כל TensorFlow מבצע (op) שמתבצע במארח או במכשיר במהלך הפעלת פרופילים.
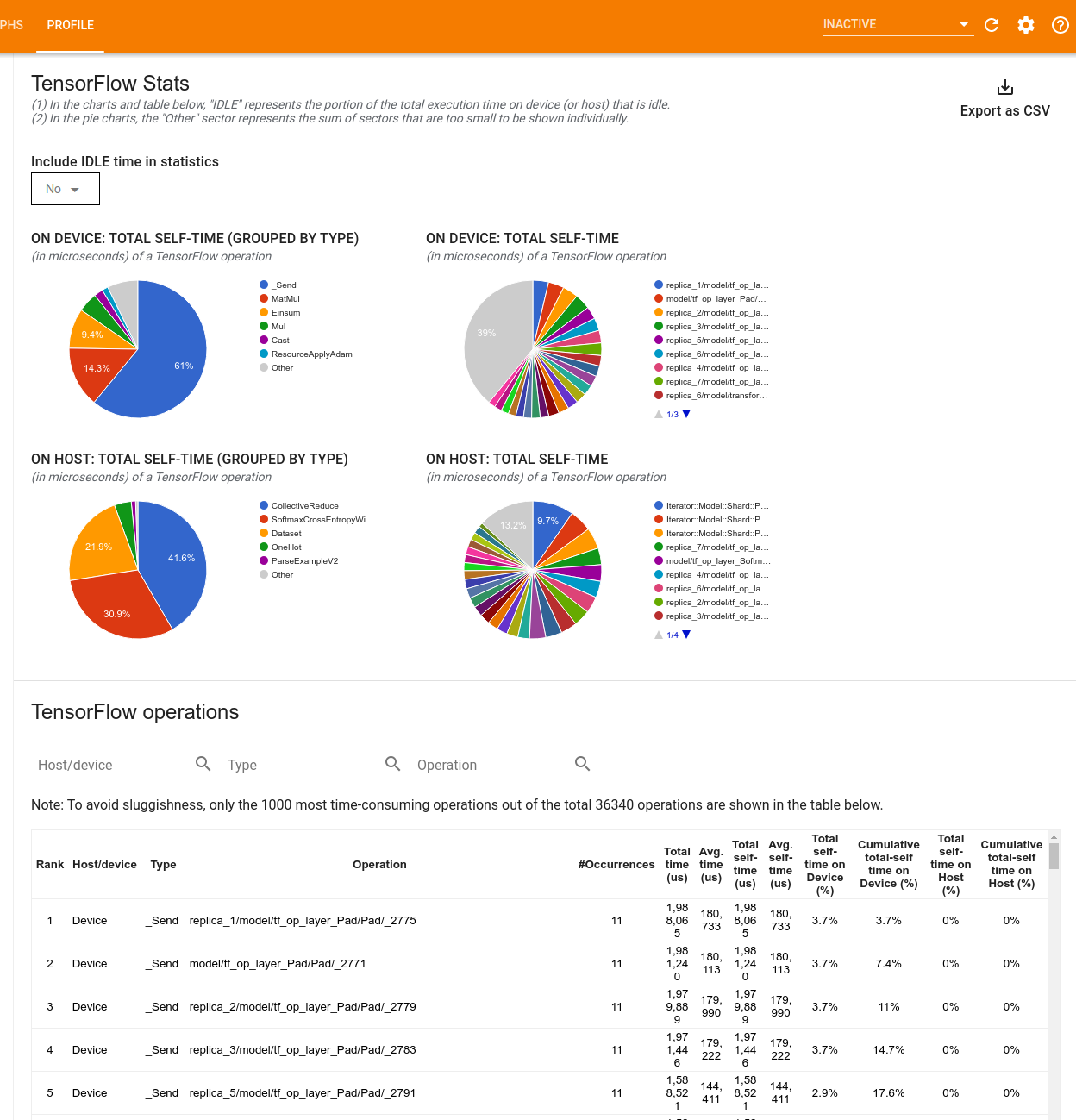
הכלי מציג מידע על ביצועים בשתי חלוניות:
החלונית העליונה מציגה עד ארבעה תרשימי עוגה:
- חלוקת זמן הביצוע העצמי של כל פעולה על המארח.
- התפלגות זמן הביצוע העצמי של כל סוג פעולה על המארח.
- חלוקת זמן הביצוע העצמי של כל פעולה במכשיר.
- התפלגות זמן הביצוע העצמי של כל סוג פעולה במכשיר.
החלונית התחתונה מציגה טבלה המדווחת על נתונים על פעולות TensorFlow עם שורה אחת עבור כל פעולה ועמודה אחת עבור כל סוג של נתונים (מיין עמודות על ידי לחיצה על כותרת העמודה). לחץ על הלחצן ייצא כ-CSV בצד ימין של החלונית העליונה כדי לייצא את הנתונים מטבלה זו כקובץ CSV.
שימו לב ש:
אם למבצעים מסוימים יש אופציות ילדים:
- הזמן ה"נצבר" הכולל של ניתוח כולל את הזמן המושקע בתוך מבצעי הילד.
- הזמן ה"עצמי" הכולל של ניתוח אינו כולל את זמן השהות בתוך ניתוח הילד.
אם מבצעים פעולה על המארח:
- האחוז מסך הזמן העצמי במכשיר שנגרם על ידי ההפעלה יהיה 0.
- האחוז המצטבר של הזמן העצמי הכולל במכשיר עד וכולל פעולה זו יהיה 0.
אם מבצעים פעולה במכשיר:
- האחוז מסך הזמן העצמי על המארח שייגרם על ידי מבצע זה יהיה 0.
- האחוז המצטבר של הזמן העצמי הכולל במארח עד וכולל פעולה זו יהיה 0.
אתה יכול לבחור לכלול או לא לכלול זמן סרק בתרשימים ובטבלה.
צופה עקבות
מציג המעקב מציג ציר זמן המציג:
- משך הזמן של הפעולות שבוצעו על ידי מודל TensorFlow שלך
- איזה חלק של המערכת (מארח או מכשיר) הוציא לפעולה. בדרך כלל, המארח מבצע פעולות קלט, מעבד מראש נתוני אימון ומעביר אותם למכשיר, בעוד שהמכשיר מבצע את אימון המודל בפועל
מציג המעקב מאפשר לך לזהות בעיות ביצועים במודל שלך, ולאחר מכן לנקוט בצעדים כדי לפתור אותן. לדוגמה, ברמה גבוהה, אתה יכול לזהות אם אימון קלט או מודל לוקח את רוב הזמן. בקידוח למטה, אתה יכול לזהות אילו פעולות לוקח הכי הרבה זמן לבצע. שימו לב שצופה המעקב מוגבל למיליון אירועים לכל מכשיר.
מעקב אחר ממשק הצופה
כאשר אתה פותח את מציג המעקב, הוא מופיע עם הריצה האחרונה שלך:
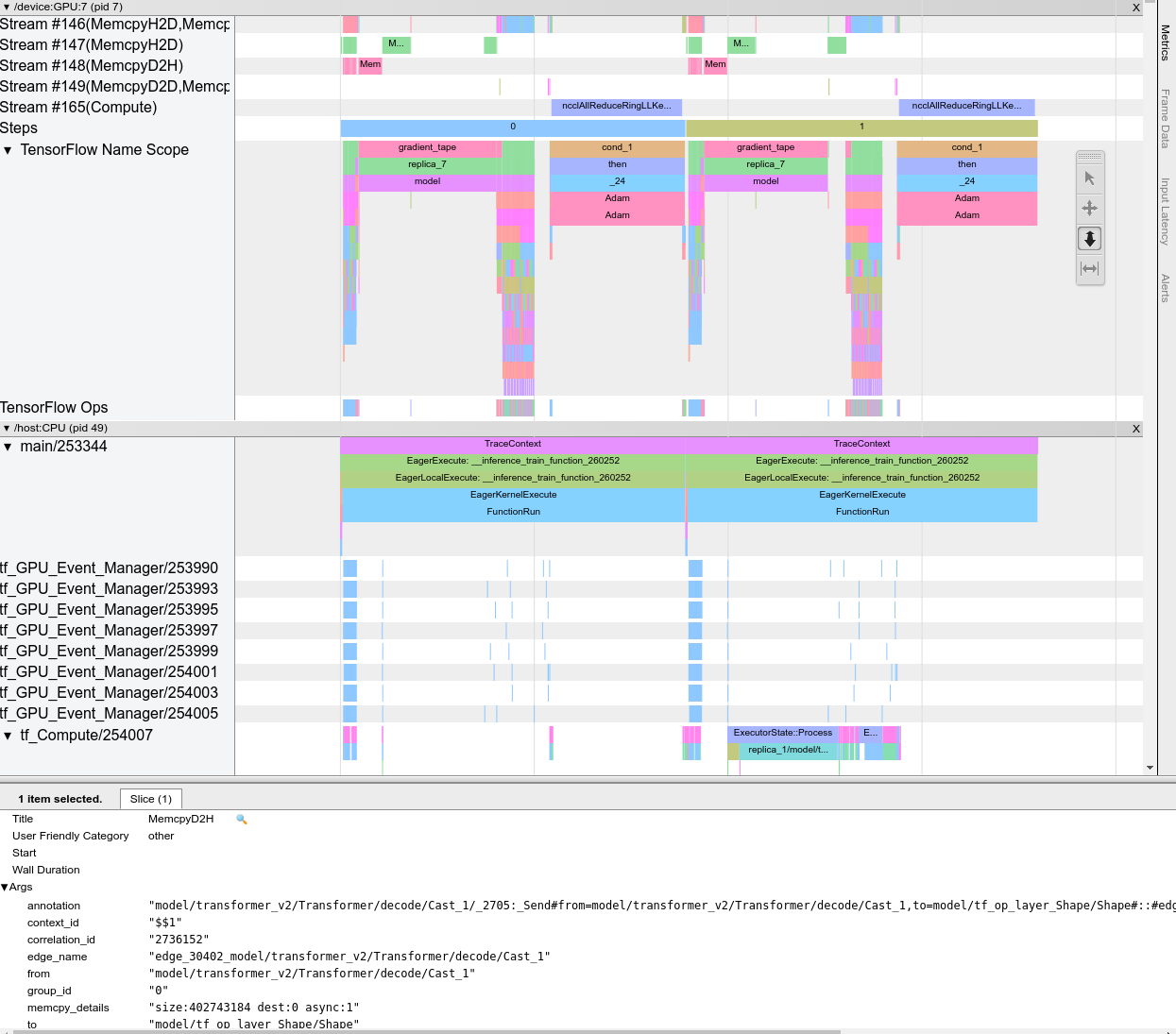
מסך זה מכיל את המרכיבים העיקריים הבאים:
- חלונית ציר זמן : מציגה פעולות שהמכשיר והמארח ביצעו לאורך זמן.
- חלונית פרטים : מציג מידע נוסף עבור פעולות שנבחרו בחלונית ציר הזמן.
חלונית ציר הזמן מכילה את הרכיבים הבאים:
- פס עליון : מכיל בקרי עזר שונים.
- ציר זמן : מציג את הזמן ביחס לתחילת העקיבה.
- תוויות מקטעים ורצועות : כל מקטע מכיל רצועות מרובות ויש לו משולש משמאל שעליו תוכל ללחוץ כדי להרחיב ולכווץ את המקטע. יש סעיף אחד לכל רכיב עיבוד במערכת.
- בורר כלים : מכיל כלים שונים לאינטראקציה עם מציג העקבות כגון זום, תנועה, בחירה ותזמון. השתמש בכלי התזמון כדי לסמן מרווח זמן.
- אירועים : אלה מציגים את הזמן שבמהלכו בוצעה ניתוח או את משך הזמן של מטא-אירועים, כגון שלבי אימון.
קטעים ומסלולים
מציג המעקב מכיל את הסעיפים הבאים:
- קטע אחד עבור כל צומת התקן , המסומן במספר שבב ההתקן וצומת ההתקן בתוך השבב (לדוגמה,
/device:GPU:0 (pid 0)). כל קטע של צומת מכשיר מכיל את הרצועות הבאות:- שלב : מציג את משך שלבי האימון שהופעלו במכשיר
- TensorFlow Ops : מציג את הפעולות שבוצעו במכשיר
- XLA Ops : מציג פעולות XLA (ops) שרצו במכשיר אם XLA הוא המהדר שבו נעשה שימוש (כל TensorFlow ops מתורגם ל-XLA אופציה אחת או כמה. המהדר XLA מתרגם את ה-XLA ops לקוד שרץ במכשיר).
- קטע אחד עבור שרשורים הפועלים על המעבד של המחשב המארח, שכותרתו "אשכולות מארח" . הקטע מכיל רצועה אחת עבור כל פתיל CPU. שים לב שאתה יכול להתעלם מהמידע המוצג לצד תוויות הסעיפים.
אירועים
אירועים בתוך ציר הזמן מוצגים בצבעים שונים; לצבעים עצמם אין משמעות ספציפית.
מציג המעקבים יכול גם להציג עקבות של קריאות לפונקציות Python בתוכנית TensorFlow שלך. אם אתה משתמש בממשק ה-API של tf.profiler.experimental.start , אתה יכול להפעיל מעקב אחר Python על ידי שימוש ב- ProfilerOptions namedtuple בעת התחלת יצירת פרופילים. לחלופין, אם אתה משתמש במצב הדגימה ליצירת פרופילים, תוכל לבחור את רמת המעקב באמצעות האפשרויות הנפתחות בתיבת הדו-שיח Capture Profile .
נתונים סטטיסטיים של ליבת GPU
כלי זה מציג נתונים סטטיסטיים של ביצועים והאופציה המקורית של כל ליבה מואצת של GPU.
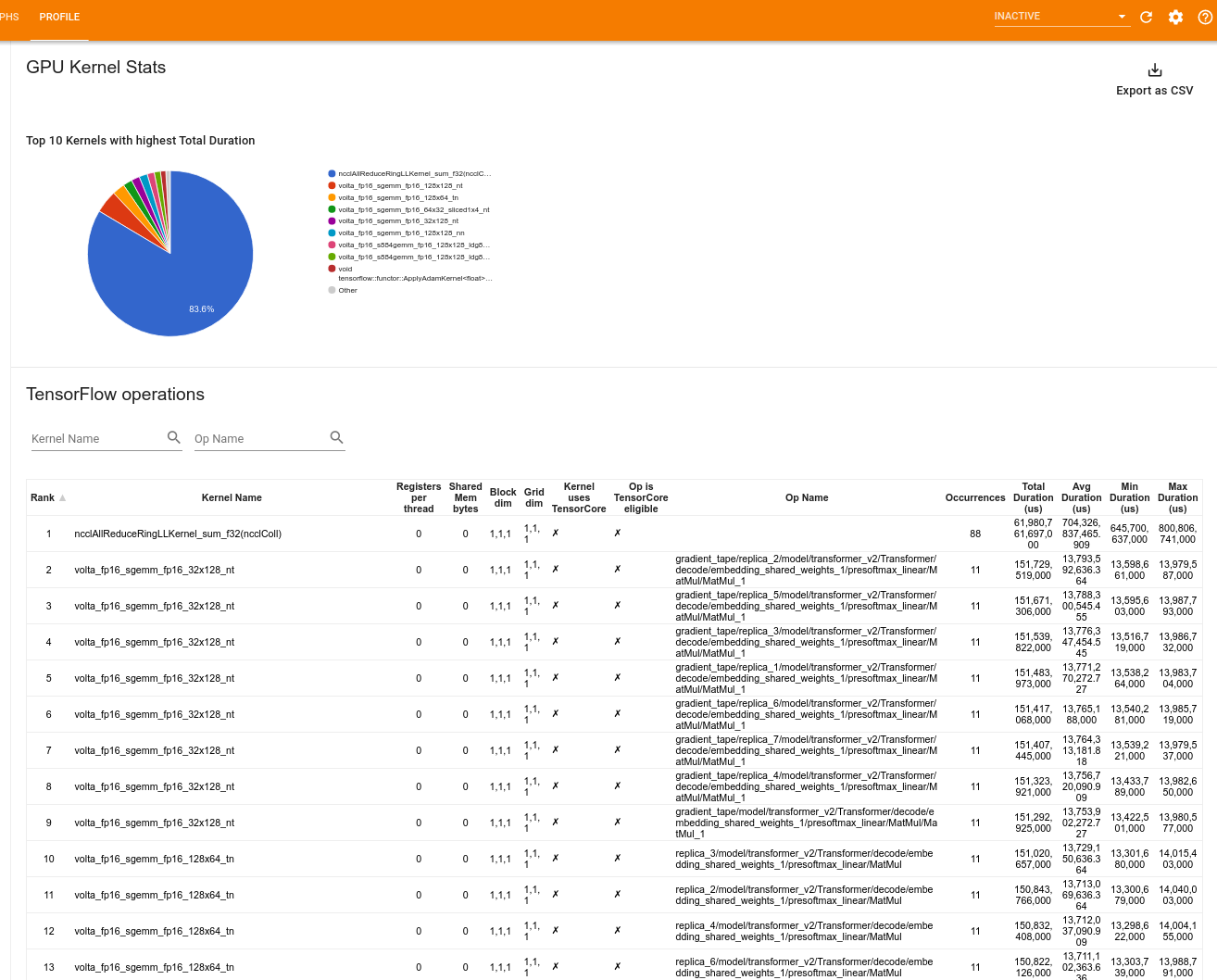
הכלי מציג מידע בשתי חלוניות:
החלונית העליונה מציגה תרשים עוגה המציג את גרעיני ה-CUDA בעלי הזמן הכולל הגבוה ביותר שחלף.
החלונית התחתונה מציגה טבלה עם הנתונים הבאים עבור כל זוג קרנל-op ייחודי:
- דירוג בסדר יורד של משך ה-GPU הכולל שחלף, מקובץ לפי זוג קרנל-op.
- שם הקרנל שהושק.
- מספר אוגרי GPU בשימוש על ידי הליבה.
- הגודל הכולל של זיכרון משותף (סטטי + דינמי משותף) בשימוש בתים.
- ממד הבלוק מבוטא כ-
blockDim.x, blockDim.y, blockDim.z. - מידות הרשת המבוטאות כ-
gridDim.x, gridDim.y, gridDim.z. - האם ה-Op כשיר להשתמש ב- Tensor Cores .
- האם הקרנל מכיל הוראות Tensor Core.
- שם האופציה שהשיקה את הגרעין הזה.
- מספר המופעים של זוג קרנל-op זה.
- הזמן הכולל שחלף ב-GPU במיקרו-שניות.
- זמן ה-GPU הממוצע שחלף במיקרו-שניות.
- זמן ה-GPU המינימלי שחלף במיקרו-שניות.
- זמן ה-GPU המקסימלי שחלף במיקרו-שניות.
כלי פרופיל זיכרון
הכלי Memory Profile עוקב אחר השימוש בזיכרון של המכשיר שלך במהלך מרווח הפרופיל. אתה יכול להשתמש בכלי זה כדי:
- נפה באגים מחוץ לזיכרון (OOM) על ידי איתור שיא השימוש בזיכרון והקצאת הזיכרון המתאימה ל- TensorFlow. אתה יכול גם לנפות באגים בבעיות OOM שעלולות להתעורר בעת הפעלת מסקנות ריבוי דירות .
- ניפוי באגים של פיצול זיכרון.
כלי פרופיל הזיכרון מציג נתונים בשלושה חלקים:
- סיכום פרופיל זיכרון
- זיכרון ציר זמן גרף
- טבלת פירוק זיכרון
סיכום פרופיל הזיכרון
סעיף זה מציג סיכום ברמה גבוהה של פרופיל הזיכרון של תוכנית TensorFlow שלך כפי שמוצג להלן:
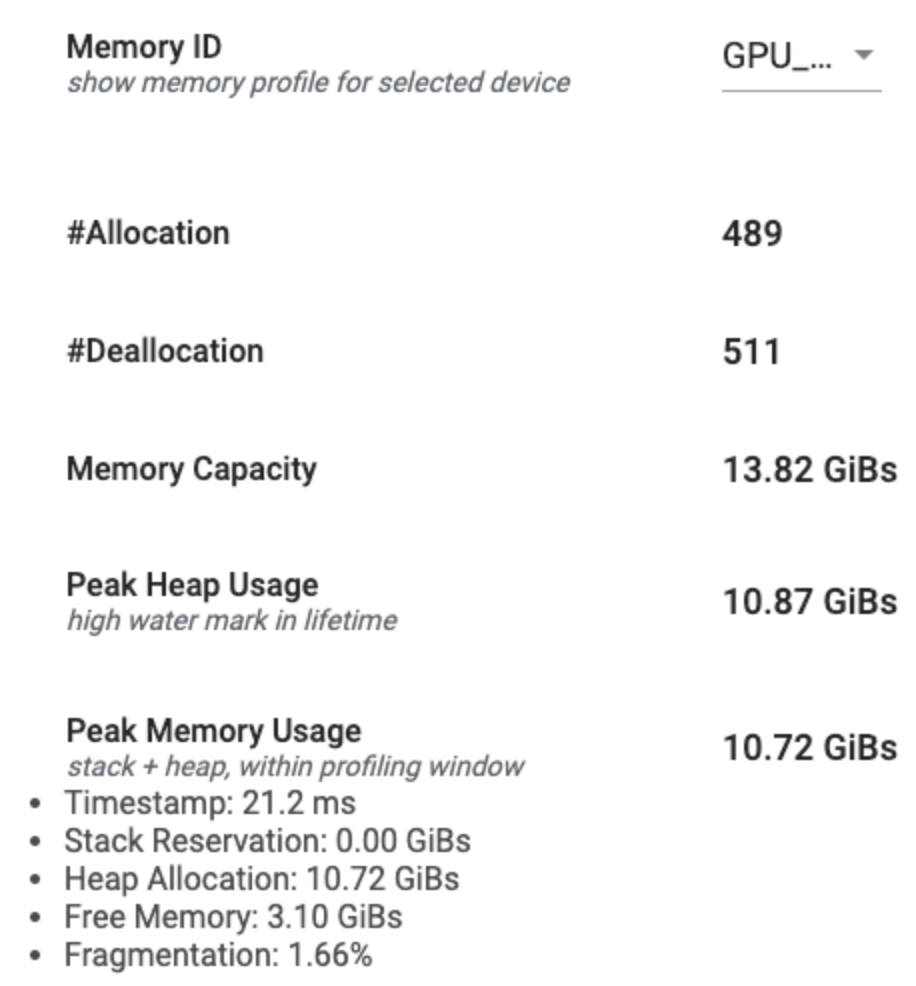
לסיכום פרופיל הזיכרון יש שישה שדות:
- מזהה זיכרון : תפריט נפתח המפרט את כל מערכות הזיכרון הזמינות של המכשיר. בחר את מערכת הזיכרון שברצונך להציג מהתפריט הנפתח.
- #הקצאה : מספר הקצאות הזיכרון שבוצעו במהלך מרווח הפרופיל.
- #Deallocation : מספר הקצאות הזיכרון במרווח הפרופיל
- קיבולת זיכרון : הקיבולת הכוללת (ב-GiBs) של מערכת הזיכרון שבחרת.
- Peak Heap Usage : שיא השימוש בזיכרון (ב-GiBs) מאז שהמודל התחיל לפעול.
- שיא השימוש בזיכרון : שיא השימוש בזיכרון (ב-GiBs) במרווח הפרופיל. שדה זה מכיל את שדות המשנה הבאים:
- חותמת זמן : חותמת הזמן שבה התרחש שיא השימוש בזיכרון בגרף ציר הזמן.
- שמירת מחסנית : כמות הזיכרון השמורה בערימה (ב-GiBs).
- הקצאת ערימה : כמות הזיכרון שהוקצה בערימה (ב-GiBs).
- זיכרון פנוי : כמות הזיכרון הפנוי (ב-GiBs). קיבולת הזיכרון היא הסכום הכולל של שמירת מחסנית, הקצאת ערימה וזיכרון פנוי.
- פיצול : אחוז הפיצול (נמוך יותר עדיף). זה מחושב כאחוז של
(1 - Size of the largest chunk of free memory / Total free memory).
גרף ציר זמן זיכרון
סעיף זה מציג עלילה של השימוש בזיכרון (ב-GiBs) ואחוז הפיצול לעומת זמן (ב-ms).
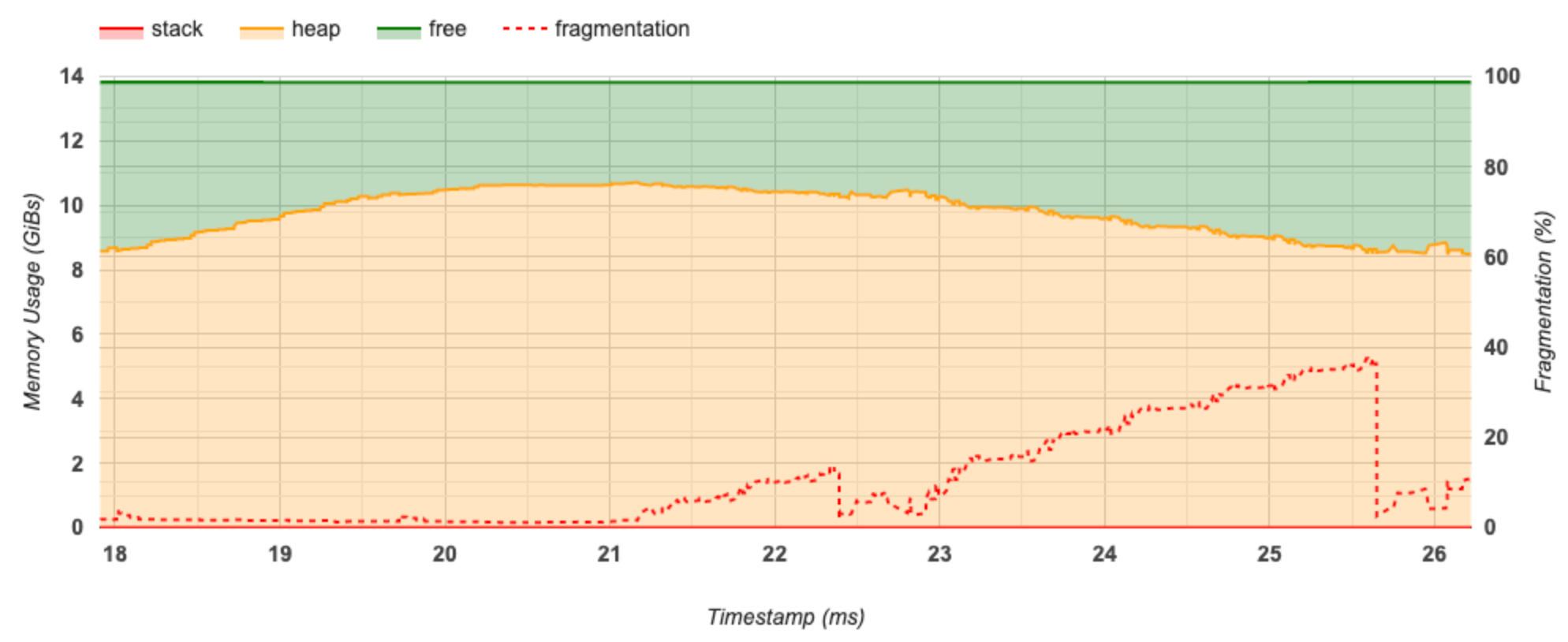
ציר ה-X מייצג את ציר הזמן (ב-ms) של מרווח הפרופיל. ציר ה-Y משמאל מייצג את השימוש בזיכרון (ב-GiBs) וציר ה-Y מימין מייצג את אחוז הפיצול. בכל נקודת זמן על ציר ה-X, הזיכרון הכולל מתחלק לשלוש קטגוריות: מחסנית (באדום), ערימה (בכתום) וחופשית (בירוק). רחף מעל חותמת זמן ספציפית כדי להציג את הפרטים על אירועי הקצאת/ביטול ההקצאה של זיכרון באותה נקודה כמו להלן:
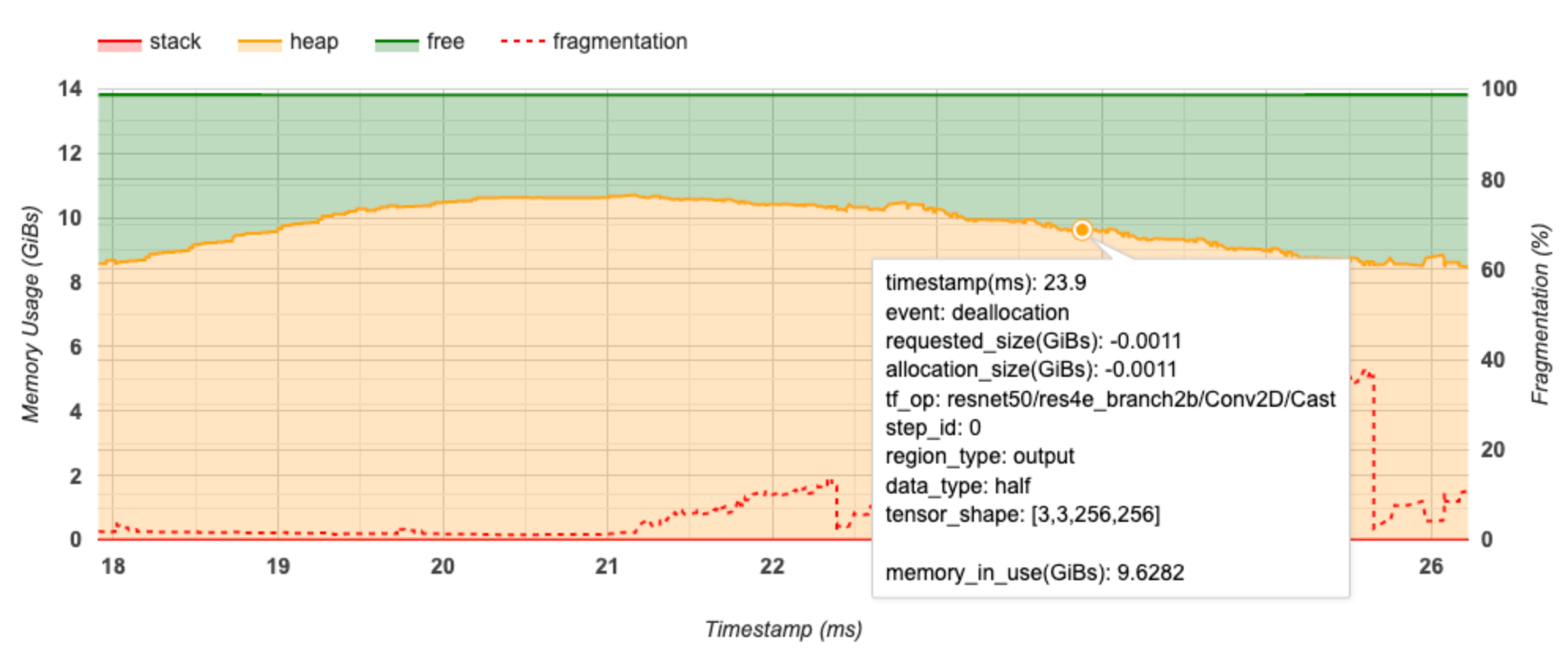
החלון המוקפץ מציג את המידע הבא:
- timestamp(ms) : המיקום של האירוע שנבחר על ציר הזמן.
- אירוע : סוג האירוע (הקצאה או ביטול).
- requested_size(GiBs) : כמות הזיכרון המבוקשת. זה יהיה מספר שלילי עבור אירועי ביטול ההקצאה.
- allocation_size(GiBs) : כמות הזיכרון שהוקצתה בפועל. זה יהיה מספר שלילי עבור אירועי ביטול ההקצאה.
- tf_op : האופ של TensorFlow שמבקש את ההקצאה/ההקצאה.
- step_id : שלב האימון שבו התרחש אירוע זה.
- region_type : סוג ישות הנתונים שעבורו מיועד הזיכרון המוקצה. ערכים אפשריים הם
tempעבור זמניים,outputעבור הפעלות והדרגות,persist/dynamicעבור משקלים וקבועים. - data_type : סוג רכיב הטנזור (למשל, uint8 עבור מספר שלם ללא סימן של 8 סיביות).
- tensor_shape : צורת הטנזור המוקצה/מבוטל.
- memory_in_use(GiBs) : סך הזיכרון שנמצא בשימוש בנקודת זמן זו.
טבלת פירוט זיכרון
טבלה זו מציגה את הקצאות הזיכרון הפעילות בנקודת שיא השימוש בזיכרון במרווח הפרופיל.
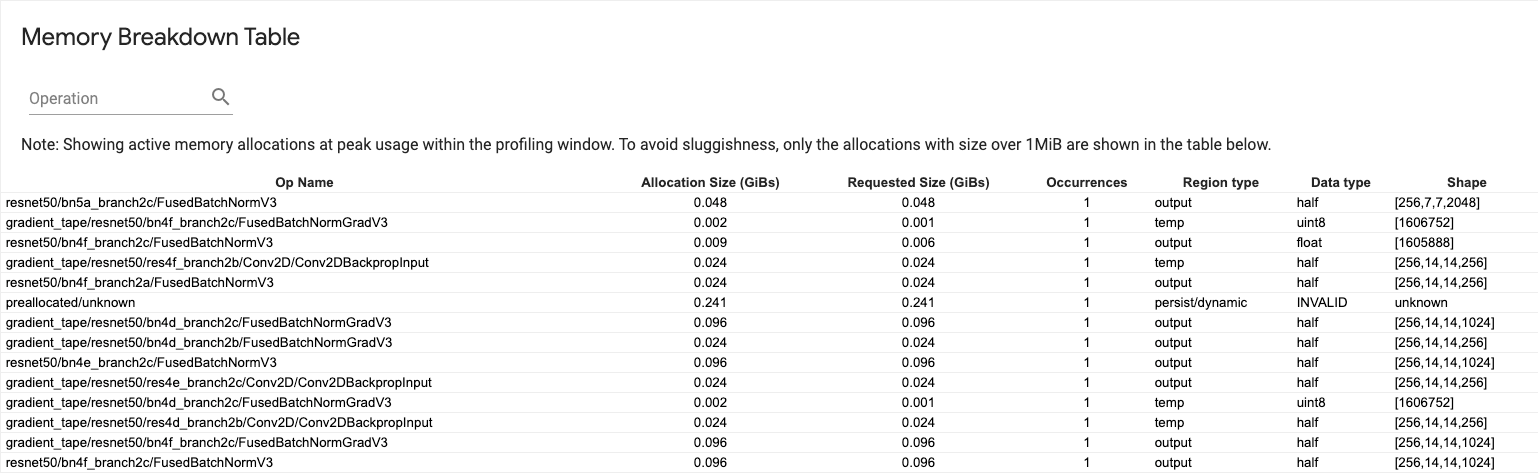
יש שורה אחת לכל TensorFlow Op ולכל שורה יש את העמודות הבאות:
- שם המבצע : השם של ה-TensorFlow אופ.
- גודל הקצאה (GiBs) : כמות הזיכרון הכוללת שהוקצתה לאופציה זו.
- גודל מבוקש (GiBs) : כמות הזיכרון הכוללת המבוקשת עבור פעולה זו.
- התרחשויות : מספר ההקצאות לאופציה זו.
- סוג אזור : סוג ישות הנתונים שעבורו מיועד הזיכרון המוקצה. ערכים אפשריים הם
tempעבור זמניים,outputעבור הפעלות והדרגות,persist/dynamicעבור משקלים וקבועים. - סוג נתונים : סוג אלמנט הטנזור.
- צורה : צורת הטנזורים שהוקצו.
מציג פוד
הכלי Pod Viewer מציג את הפירוט של שלב הכשרה על פני כל העובדים.
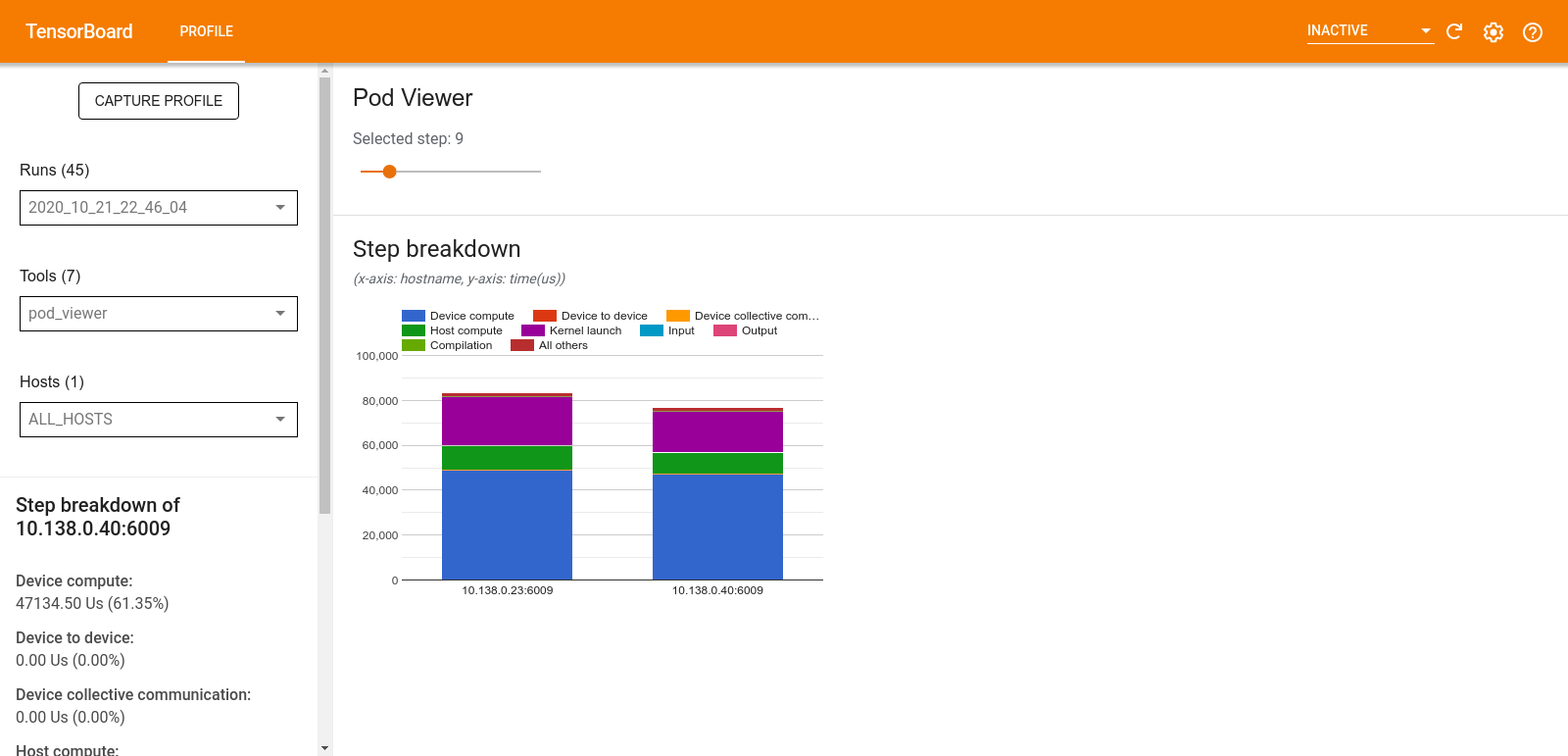
- בחלונית העליונה יש מחוון לבחירת מספר הצעד.
- החלונית התחתונה מציגה תרשים עמודות מוערם. זוהי תצוגה ברמה גבוהה של קטגוריות מפורקות של זמן-שלב הממוקמות זו על גבי זו. כל עמודה מוערמת מייצגת עובד ייחודי.
- כאשר אתה מרחף מעל עמודה מוערמת, הכרטיס בצד שמאל מציג פרטים נוספים על פירוט השלבים.
tf.data ניתוח צוואר בקבוק
כלי ניתוח צוואר הבקבוק tf.data מזהה אוטומטית צווארי בקבוק בצינורות הקלט tf.data בתוכנית שלך ומספק המלצות כיצד לתקן אותם. זה עובד עם כל תוכנית המשתמשת ב- tf.data ללא קשר לפלטפורמה (CPU/GPU/TPU). הניתוח וההמלצות שלו מבוססים על מדריך זה.
הוא מזהה צוואר בקבוק על ידי ביצוע השלבים הבאים:
- מצא את המארח הכי קשור לקלט.
- מצא את הביצוע האיטי ביותר של צינור קלט
tf.data. - שחזר את גרף צינור הקלט מתוך עקבות הפרופיל.
- מצא את הנתיב הקריטי בגרף צינור הקלט.
- זהה את הטרנספורמציה האיטית ביותר בנתיב הקריטי כצוואר בקבוק.
ממשק המשתמש מחולק לשלושה חלקים: סיכום ניתוח ביצועים , סיכום של כל צינורות הקלט ותרשים צינורות קלט .
סיכום ניתוח ביצועים

חלק זה מספק את סיכום הניתוח. הוא מדווח על צינורות קלט איטיים tf.data שזוהו בפרופיל. סעיף זה מציג גם את המארח המקושר ביותר לקלט ואת צינור הקלט האיטי ביותר שלו עם השהיה המקסימלית. והכי חשוב, הוא מזהה איזה חלק בצינור הקלט הוא צוואר הבקבוק וכיצד לתקן אותו. מידע צוואר הבקבוק מסופק עם סוג האיטרטור ושמו הארוך.
כיצד לקרוא את השם הארוך של tf.data iterator
שם ארוך מעוצב בתור Iterator::<Dataset_1>::...::<Dataset_n> . בשם הארוך, <Dataset_n> מתאים לסוג האיטרטור ושאר מערכי הנתונים בשם הארוך מייצגים טרנספורמציות במורד הזרם.
לדוגמה, שקול את מערך הנתונים הבא של צינור הקלט:
dataset = tf.data.Dataset.range(10).map(lambda x: x).repeat(2).batch(5)
השמות הארוכים של האיטרטורים ממערך הנתונים שלמעלה יהיו:
| סוג איטרטור | שם ארוך |
|---|---|
| לָנוּעַ | איטרטור::אצווה::חזרה::מפה::טווח |
| מַפָּה | Iterator::אצווה::Repeat::Map |
| לַחֲזוֹר עַל | איטרטור::אצווה::חזור |
| קְבוּצָה | Iterator::אצווה |
סיכום כל צינורות הקלט
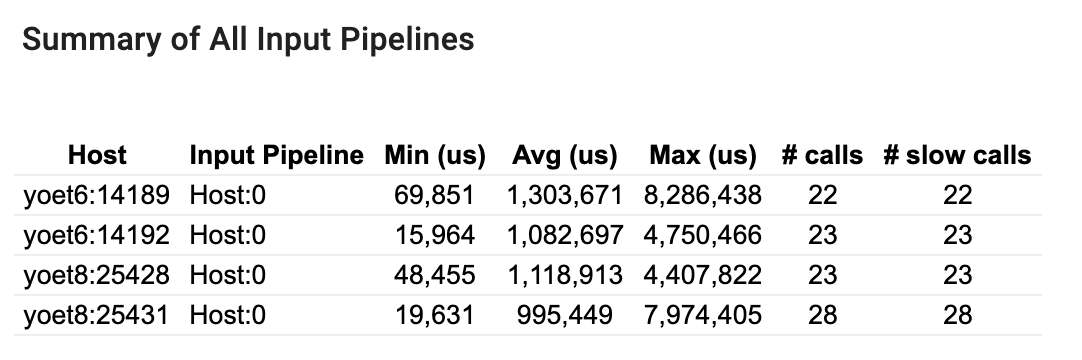
סעיף זה מספק את הסיכום של כל צינורות הקלט בכל המארחים. בדרך כלל יש צינור קלט אחד. בעת שימוש באסטרטגיית ההפצה, קיים צינור קלט מארח אחד המריץ את קוד tf.data של התוכנית וצינורות קלט מרובים של התקנים המאחזרים נתונים מצינור הקלט המארח ומעבירים אותם למכשירים.
עבור כל צינור קלט, הוא מציג את הסטטיסטיקה של זמן הביצוע שלו. שיחה נספרת כאיטית אם היא נמשכת יותר מ-50 מיקרומטר שניות.
גרף צינור קלט

סעיף זה מציג את גרף צינור הקלט עם מידע זמן הביצוע. אתה יכול להשתמש ב-"Host" ו-"Input Pipeline" כדי לבחור איזה מארח וצינור קלט לראות. ביצועים של צינור הקלט ממוינים לפי זמן הביצוע בסדר יורד, שבו אתה יכול לבחור באמצעות התפריט הנפתח דירוג .
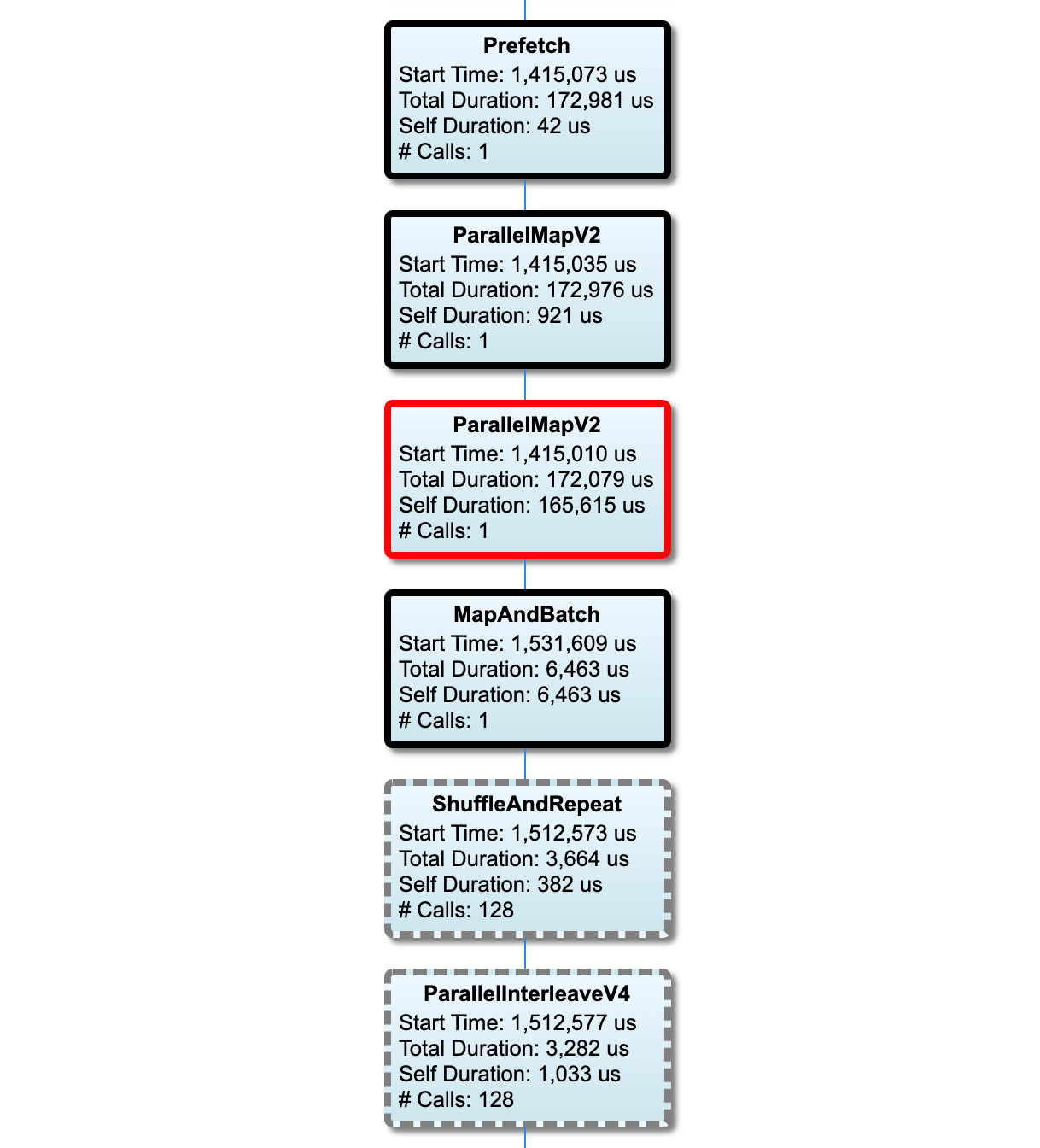
לצמתים בנתיב הקריטי יש קווי מתאר מודגשים. לצוואר הבקבוק, שהוא הצומת עם הזמן העצמי הארוך ביותר בנתיב הקריטי, יש קו מתאר אדום. שאר הצמתים הלא קריטיים כוללים קווי מתאר מקווקו אפורים.
בכל צומת, זמן התחלה מציין את שעת ההתחלה של הביצוע. אותו צומת עשוי להתבצע מספר פעמים, למשל, אם יש Batch op בצינור הקלט. אם הוא מבוצע מספר פעמים, זוהי שעת ההתחלה של הביצוע הראשון.
משך הכולל הוא זמן הקיר של הביצוע. אם הוא מבוצע מספר פעמים, זהו סכום זמני הקיר של כל הביצועים.
זמן עצמי הוא זמן כולל ללא הזמן החופף עם צמתי הצאצא המיידיים שלו.
"# שיחות" הוא מספר הפעמים שצינור הקלט מבוצע.
איסוף נתוני ביצועים
TensorFlow Profiler אוסף פעילויות מארח ועקבות GPU של דגם TensorFlow שלך. אתה יכול להגדיר את ה-Profiler לאסוף נתוני ביצועים דרך המצב התכנותי או מצב הדגימה.
ממשקי API ליצירת פרופילים
אתה יכול להשתמש בממשקי ה-API הבאים כדי לבצע פרופילים.
מצב פרוגרמטי באמצעות TensorBoard Keras Callback (
tf.keras.callbacks.TensorBoard)# Profile from batches 10 to 15 tb_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, profile_batch='10, 15') # Train the model and use the TensorBoard Keras callback to collect # performance profiling data model.fit(train_data, steps_per_epoch=20, epochs=5, callbacks=[tb_callback])מצב פרוגרמטי באמצעות
tf.profilerFunction APItf.profiler.experimental.start('logdir') # Train the model here tf.profiler.experimental.stop()מצב פרוגרמטי באמצעות מנהל ההקשרים
with tf.profiler.experimental.Profile('logdir'): # Train the model here pass
מצב דגימה: בצע פרופיל לפי דרישה באמצעות
tf.profiler.experimental.server.startכדי להפעיל שרת gRPC עם הפעלת מודל TensorFlow שלך. לאחר הפעלת שרת gRPC והפעלת הדגם שלך, תוכל ללכוד פרופיל דרך לחצן Capture Profile בתוסף הפרופיל TensorBoard. השתמש בסקריפט בסעיף התקנת פרופיל למעלה כדי להפעיל מופע TensorBoard אם הוא עדיין לא פועל.כדוגמה,
# Start a profiler server before your model runs. tf.profiler.experimental.server.start(6009) # (Model code goes here). # Send a request to the profiler server to collect a trace of your model. tf.profiler.experimental.client.trace('grpc://localhost:6009', 'gs://your_tb_logdir', 2000)דוגמה ליצירת פרופיל של מספר עובדים:
# E.g., your worker IP addresses are 10.0.0.2, 10.0.0.3, 10.0.0.4, and you # would like to profile for a duration of 2 seconds. tf.profiler.experimental.client.trace( 'grpc://10.0.0.2:8466,grpc://10.0.0.3:8466,grpc://10.0.0.4:8466', 'gs://your_tb_logdir', 2000)
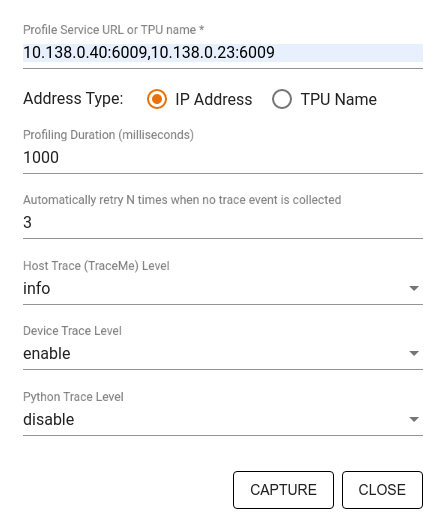
השתמש בתיבת הדו-שיח Capture Profile כדי לציין:
- רשימה מופרדת בפסיקים של כתובות אתרים של שירותי פרופיל או שמות TPU.
- משך פרופיל.
- רמת מעקב אחר שיחות מכשיר, מארח ופונקציית Python.
- כמה פעמים אתה רוצה ש-Profiler ינסה שוב ללכוד פרופילים אם לא יצליח בהתחלה.
יצירת פרופילים של לולאות אימון מותאמות אישית
כדי ליצור פרופיל של לולאות אימון מותאמות אישית בקוד TensorFlow שלך, מכשיר את לולאת האימון באמצעות ממשק ה-API של tf.profiler.experimental.Trace כדי לסמן את גבולות השלבים עבור Profiler.
ארגומנט name משמש כתחילית לשמות השלבים, ארגומנט מילת המפתח step_num מצורף בשמות השלבים, וארגומנט מילת המפתח _r גורם לאירוע המעקב הזה לעיבוד כאירוע שלב על ידי הפרופיל.
כדוגמה,
for step in range(NUM_STEPS):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_data = next(dataset)
train_step(train_data)
זה יאפשר את ניתוח הביצועים המבוסס על שלבים של Profiler ויגרום לאירועי הצעד להופיע במציג המעקב.
ודא שאתה כולל את איטרטור הנתונים בתוך ההקשר tf.profiler.experimental.Trace לניתוח מדויק של צינור הקלט.
קטע הקוד שלהלן הוא אנטי דפוס:
for step, train_data in enumerate(dataset):
with tf.profiler.experimental.Trace('train', step_num=step, _r=1):
train_step(train_data)
מקרי שימוש בפרופילים
הפרופיל מכסה מספר מקרי שימוש לאורך ארבעה צירים שונים. חלק מהשילובים נתמכים כעת ואחרים יתווספו בעתיד. חלק ממקרי השימוש הם:
- פרופיל מקומי לעומת מרוחק : אלו הן שתי דרכים נפוצות להגדרת סביבת הפרופיל שלך. ביצירת פרופיל מקומי, ממשק ה-API לפרופילים נקרא באותו מכונה שהדגם שלך מפעיל, למשל, תחנת עבודה מקומית עם GPUs. ביצירת פרופילים מרחוק, ממשק ה-API של פרופילים נקרא במכונה אחרת מהמקום שבו המודל שלך מבצע, למשל, ב-Cloud TPU.
- יצירת פרופיל של מספר עובדים : ניתן ליצור פרופיל של מספר מכונות בעת שימוש ביכולות ההדרכה המבוזרות של TensorFlow.
- פלטפורמת חומרה : מעבדי פרופילים, GPUs ו-TPUs.
הטבלה שלהלן מספקת סקירה מהירה של מקרי השימוש הנתמכים ב- TensorFlow שהוזכרו לעיל:
| API לפרופילים | מְקוֹמִי | מְרוּחָק | מספר עובדים | פלטפורמות חומרה |
|---|---|---|---|---|
| TensorBoard Keras Callback | נתמך | לא נתמך | לא נתמך | מעבד, GPU |
tf.profiler.experimental start/stop API | נתמך | לא נתמך | לא נתמך | מעבד, GPU |
tf.profiler.experimental client.trace API | נתמך | נתמך | נתמך | מעבד, GPU, TPU |
| ממשק API של מנהל הקשר | נתמך | לא נתמך | לא נתמך | מעבד, GPU |
שיטות עבודה מומלצות לביצועי מודל מיטביים
השתמש בהמלצות הבאות בהתאם לדגמי TensorFlow שלך כדי להשיג ביצועים מיטביים.
באופן כללי, בצע את כל השינויים במכשיר וודא שאתה משתמש בגרסה התואמת האחרונה של ספריות כמו cuDNN ו-Intel MKL עבור הפלטפורמה שלך.
בצע אופטימיזציה של צינור נתוני הקלט
השתמש בנתונים מה-[#input_pipeline_analyzer] כדי לייעל את צינור קלט הנתונים שלך. צינור קלט נתונים יעיל יכול לשפר באופן דרסטי את מהירות ביצוע המודל שלך על ידי הפחתת זמן סרק המכשיר. נסה לשלב את שיטות העבודה המומלצות המפורטות ב- Ber Performance with the tf.data API Guide ומטה כדי להפוך את צינור הזנת הנתונים שלך ליעיל יותר.
באופן כללי, הקבילה של כל פעולות שאין צורך לבצע ברצף יכולה לייעל באופן משמעותי את צינור קלט הנתונים.
במקרים רבים, זה עוזר לשנות את הסדר של כמה שיחות או לכוון את הטיעונים כך שיעבדו בצורה הטובה ביותר עבור הדגם שלך. תוך כדי אופטימיזציה של צינור נתוני הקלט, השוואת רק את מטעין הנתונים ללא שלבי ההדרכה וההפצה לאחור כדי לכמת את השפעת האופטימיזציות באופן עצמאי.
נסה להפעיל את המודל שלך עם נתונים סינתטיים כדי לבדוק אם צינור הקלט הוא צוואר בקבוק ביצועים.
השתמש ב-
tf.data.Dataset.shardלאימון ריבוי GPU. הקפד לרסיס מוקדם מאוד בלולאת הקלט כדי למנוע הפחתה בתפוקה. כשאתה עובד עם TFRecords, ודא שאתה מפציץ את רשימת ה-TFRecords ולא את התוכן של TFRecords.מקביל למספר פעולות על ידי הגדרה דינמית של הערך של
num_parallel_callsבאמצעותtf.data.AUTOTUNE.שקול להגביל את השימוש ב-
tf.data.Dataset.from_generatorכיוון שהוא איטי יותר בהשוואה לאופס טהור של TensorFlow.שקול להגביל את השימוש ב-
tf.py_functionמכיוון שלא ניתן לבצע אותו בסידרה ואינו נתמך להפעלה ב- TensorFlow מבוזר.השתמש ב-
tf.data.Optionsכדי לשלוט באופטימיזציות סטטיות לצינור הקלט.
קרא גם את המדריך לניתוח ביצועים tf.data לקבלת הדרכה נוספת על אופטימיזציה של צינור הקלט שלך.
בצע אופטימיזציה של הגדלת נתונים
כשאתה עובד עם נתוני תמונה, הפוך את הגדלת הנתונים שלך ליעילה יותר על ידי העברה לסוגי נתונים שונים לאחר החלת טרנספורמציות מרחביות, כגון היפוך, חיתוך, סיבוב וכו'.
השתמש ב-NVIDIA® DALI
במקרים מסוימים, כגון כאשר יש לך מערכת עם יחס GPU למעבד גבוה, ייתכן שכל האופטימיזציות לעיל לא יספיקו כדי לבטל צווארי בקבוק בטעינת הנתונים שנגרמו עקב מגבלות של מחזורי CPU.
אם אתה משתמש ב-NVIDIA® GPUs עבור יישומי ראייה ממוחשבת ושמע למידה עמוקה, שקול להשתמש בספריית טעינת הנתונים ( DALI ) כדי להאיץ את צינור הנתונים.
עיין בתיעוד NVIDIA® DALI: פעולות לקבלת רשימה של פעולות DALI נתמכות.
השתמש בהברגה ובביצוע מקביל
הפעל פעולות על שרשורי CPU מרובים עם ה-API של tf.config.threading כדי להפעיל אותם מהר יותר.
TensorFlow מגדיר אוטומטית את מספר השרשורים המקבילים כברירת מחדל. מאגר השרשורים הזמין להפעלת TensorFlow ops תלוי במספר שרשורי המעבד הזמינים.
שלוט במהירות המקבילה המקסימלית עבור הפעלה בודדת באמצעות tf.config.threading.set_intra_op_parallelism_threads . שימו לב שאם תפעילו מספר פעולות במקביל, כולם ישתפו את מאגר השרשורים הזמין.
אם יש לך פעולות עצמאיות שאינן חוסמות (אופס ללא נתיב מכוון ביניהן בגרף), השתמש ב- tf.config.threading.set_inter_op_parallelism_threads כדי להפעיל אותם במקביל באמצעות מאגר השרשורים הזמין.
שונות
כאשר עובדים עם דגמים קטנים יותר על NVIDIA® GPUs, אתה יכול להגדיר את tf.compat.v1.ConfigProto.force_gpu_compatible=True כדי לאלץ את כל טנסור ה-CPU להקצות עם זיכרון מוצמד CUDA כדי לתת דחיפה משמעותית לביצועי המודל. עם זאת, היזהר בעת השימוש באפשרות זו עבור דגמים לא ידועים/גדולים מאוד, שכן הדבר עלול להשפיע לרעה על ביצועי המארח (CPU).
שפר את ביצועי המכשיר
עקוב אחר השיטות המומלצות המפורטות כאן ובמדריך אופטימיזציית ביצועי GPU כדי לייעל את ביצועי מודל TensorFlow במכשיר.
אם אתה משתמש ב-NVIDIA GPUs, רישום את ה-GPU ואת ניצול הזיכרון לקובץ CSV על ידי הפעלת:
nvidia-smi
--query-gpu=utilization.gpu,utilization.memory,memory.total,
memory.free,memory.used --format=csv
הגדר פריסת נתונים
כאשר עובדים עם נתונים המכילים מידע על ערוצים (כמו תמונות), בצע אופטימיזציה של פורמט פריסת הנתונים כדי להעדיף את הערוצים האחרונים (NHWC על פני NCHW).
פורמטים של נתוני ערוץ אחרונים משפרים את ניצול ליבת Tensor ומספקים שיפורי ביצועים משמעותיים במיוחד במודלים קונבולוציוניים בשילוב עם AMP. ניתן עדיין להפעיל פריסות נתונים של NCHW על ידי Tensor Cores, אך מציגים תקורה נוספת עקב פעולות טרנספוזיציה אוטומטיות.
אתה יכול לייעל את פריסת הנתונים כדי להעדיף פריסות NHWC על ידי הגדרת data_format="channels_last" עבור שכבות כגון tf.keras.layers.Conv2D , tf.keras.layers.Conv3D ו- tf.keras.layers.RandomRotation .
השתמש ב- tf.keras.backend.set_image_data_format כדי להגדיר את פורמט פריסת הנתונים המוגדר כברירת מחדל עבור ממשק ה-API העורפי של Keras.
למקסם את המטמון L2
בעת עבודה עם NVIDIA® GPUs, הפעל את קטע הקוד למטה לפני לולאת האימון כדי למקסם את רמת הפירוט של L2 ל-128 בתים.
import ctypes
_libcudart = ctypes.CDLL('libcudart.so')
# Set device limit on the current device
# cudaLimitMaxL2FetchGranularity = 0x05
pValue = ctypes.cast((ctypes.c_int*1)(), ctypes.POINTER(ctypes.c_int))
_libcudart.cudaDeviceSetLimit(ctypes.c_int(0x05), ctypes.c_int(128))
_libcudart.cudaDeviceGetLimit(pValue, ctypes.c_int(0x05))
assert pValue.contents.value == 128
הגדר שימוש בחוט GPU
מצב פתיל GPU מחליט כיצד נעשה שימוש בשרשורי GPU.
הגדר את מצב השרשור ל- gpu_private כדי לוודא כי עיבוד מקדים לא גונב את כל חוטי ה- GPU. זה יפחית את עיכוב ההשקה של הגרעין במהלך האימונים. אתה יכול גם להגדיר את מספר האשכולות לכל GPU. הגדר ערכים אלה באמצעות משתני סביבה.
import os
os.environ['TF_GPU_THREAD_MODE']='gpu_private'
os.environ['TF_GPU_THREAD_COUNT']='1'
הגדר אפשרויות זיכרון GPU
באופן כללי, הגדילו את גודל האצווה וסדרנו את הדגם כדי לנצל טוב יותר GPUs ולקבל תפוקה גבוהה יותר. שים לב שהגדלת גודל האצווה תשנה את דיוק המודל כך שצריך להדרג את המודל על ידי כוונון היפר -פרמטרים כמו קצב הלמידה כדי לענות על דיוק היעד.
כמו כן, השתמש ב- tf.config.experimental.set_memory_growth כדי לאפשר לזיכרון GPU לצמוח כדי למנוע את כל הזיכרון הזמין הקצאתו במלואה ל- OPs הדורשים רק חלק מהזיכרון. זה מאפשר לתהליכים אחרים הצורכים זיכרון GPU להפעלה באותו מכשיר.
למידע נוסף, עיין בהנחיות גידול זיכרון ה- GPU המגביל במדריך GPU למידע נוסף.
שונות
הגדל את גודל המיני-אצווה של האימונים (מספר דגימות אימונים המשמשות לכל מכשיר באיטרציה אחת של לולאת האימונים) לכמות המרבית שמתאימה ללא שגיאה מחוץ לזיכרון (OOM) ב- GPU. הגדלת גודל האצווה משפיעה על דיוק הדגם - לכן הקפידו על גודל המודל על ידי כוונון היפר -פרמטרים כדי לעמוד ברמת הדיוק.
השבת דיווח על שגיאות OOM במהלך הקצאת טנזור בקוד הייצור. הגדר
report_tensor_allocations_upon_oom=Falseב-tf.compat.v1.RunOptions.עבור דגמים עם שכבות התפתחות, הסר את תוספת ההטיה אם משתמשים בנורמליזציה של אצווה. נורמליזציה של אצווה מעבירה ערכים לפי הממוצע שלהם וזה מסיר את הצורך למונח הטיה קבוע.
השתמש בסטטיסטיקה של TF כדי לגלות עד כמה OPS ON-DEVICE פועלים.
השתמש ב-
tf.functionכדי לבצע חישובים ובאופן אופציונלי, הפעל אתjit_compile=True(tf.function(jit_compile=True). למידע נוסף, עבור לשימוש xla tf.function .צמצם את פעולות הפיתון המארחות בין שלבים והפחתת התקשרות חוזרת. חישוב מדדים כל כמה צעדים במקום בכל שלב.
שמור על יחידות מחשוב המכשיר.
שלח נתונים למספר מכשירים במקביל.
שקול להשתמש בייצוגים מספריים של 16 סיביות , כמו
fp16פורמט הנקודה הצפה של חצי דיוק שצוין על ידי IEEE-או פורמט BFLOAT16 של נקודת המוח.
משאבים נוספים
- TensorFlow Profiler: הדרכת ביצועי מודל פרופיל עם Keras ו- Tensorboard שם תוכלו להחיל את העצות במדריך זה.
- פרופיל הביצועים ב- TensorFlow 2 שיחה מתוך פסגת ה- Tensorflow Dev 2020.
- ההדגמה של Tensorflow Profiler מפסגת Tensorflow Dev 2020.
מגבלות ידועות
פרופילציה של GPUs מרובים ב- TensorFlow 2.2 ו- TensorFlow 2.3
TensorFlow 2.2 ו- 2.3 תומכים בפרופיל GPU מרובה למערכות מארח בודדות בלבד; פרופילציה של GPU מרובה עבור מערכות מרובות מארחות אינה נתמכת. כדי לפרופיל תצורות GPU רב-עבודה, יש לתאר את כל העובד באופן עצמאי. מ- TensorFlow 2.4 ניתן לתאר את מספר העובדים באמצעות ה- tf.profiler.experimental.client.trace API.
Cuda® Toolkit 10.2 ואילך נדרש לפרופיל GPUs מרובים. כ- TensorFlow 2.2 ו- 2.3 תומכים בגרסאות ערכת הכלים של CUDA® רק עד 10.1, עליך ליצור קישורים סמלים ל- libcudart.so.10.1 ו- libcupti.so.10.1 :
sudo ln -s /usr/local/cuda/lib64/libcudart.so.10.2 /usr/local/cuda/lib64/libcudart.so.10.1
sudo ln -s /usr/local/cuda/extras/CUPTI/lib64/libcupti.so.10.2 /usr/local/cuda/extras/CUPTI/lib64/libcupti.so.10.1