
| | |  צפה במקור ב-GitHub צפה במקור ב-GitHub |
תיעוד API: tf.RaggedTensor tf.ragged
להכין
import math
import tensorflow as tf
סקירה כללית
הנתונים שלך מגיעים בצורות רבות; גם הטנסורים שלך צריכים. טנזורים מרופטים הם המקבילה של TensorFlow לרשימות מקוננות באורך משתנה. הם מקלים על אחסון ועיבוד נתונים עם צורות לא אחידות, כולל:
- תכונות באורך משתנה, כגון סט השחקנים בסרט.
- קבוצות של כניסות עוקבות באורך משתנה, כגון משפטים או קטעי וידאו.
- קלט היררכי, כגון מסמכי טקסט המחולקים לחלקים, פסקאות, משפטים ומילים.
- שדות בודדים בתשומות מובנות, כגון מאגרי פרוטוקול.
מה אתה יכול לעשות עם טנזור מרופט
טנזורים מרופטים נתמכים על ידי יותר ממאה פעולות TensorFlow, כולל פעולות מתמטיות (כגון tf.add ו- tf.reduce_mean ), פעולות מערך (כגון tf.concat ו- tf.tile ), פעולות למניפולציה של מחרוזות (כגון tf.substr ), בקרה על פעולות זרימה (כגון tf.while_loop ו- tf.map_fn ), ועוד רבים אחרים:
digits = tf.ragged.constant([[3, 1, 4, 1], [], [5, 9, 2], [6], []])
words = tf.ragged.constant([["So", "long"], ["thanks", "for", "all", "the", "fish"]])
print(tf.add(digits, 3))
print(tf.reduce_mean(digits, axis=1))
print(tf.concat([digits, [[5, 3]]], axis=0))
print(tf.tile(digits, [1, 2]))
print(tf.strings.substr(words, 0, 2))
print(tf.map_fn(tf.math.square, digits))
<tf.RaggedTensor [[6, 4, 7, 4], [], [8, 12, 5], [9], []]> tf.Tensor([2.25 nan 5.33333333 6. nan], shape=(5,), dtype=float64) <tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9, 2], [6], [], [5, 3]]> <tf.RaggedTensor [[3, 1, 4, 1, 3, 1, 4, 1], [], [5, 9, 2, 5, 9, 2], [6, 6], []]> <tf.RaggedTensor [[b'So', b'lo'], [b'th', b'fo', b'al', b'th', b'fi']]> <tf.RaggedTensor [[9, 1, 16, 1], [], [25, 81, 4], [36], []]>
ישנן גם מספר שיטות ופעולות הספציפיות לטנזורים מרופטים, כולל שיטות מפעל, שיטות המרה ופעולות מיפוי ערך. לרשימה של פעולות נתמכות, עיין בתיעוד החבילה tf.ragged .
טנזורים מרופטים נתמכים על ידי ממשקי API רבים של TensorFlow, כולל Keras , Datasets , tf.function , SavedModels ו- tf.Example . למידע נוסף, עיין בסעיף על ממשקי API של TensorFlow למטה.
כמו בטנסור רגיל, אתה יכול להשתמש באינדקס בסגנון Python כדי לגשת לפרוסות ספציפיות של טנזור מרופט. למידע נוסף, עיין בסעיף על יצירת אינדקס להלן.
print(digits[0]) # First row
tf.Tensor([3 1 4 1], shape=(4,), dtype=int32)
print(digits[:, :2]) # First two values in each row.
<tf.RaggedTensor [[3, 1], [], [5, 9], [6], []]>
print(digits[:, -2:]) # Last two values in each row.
<tf.RaggedTensor [[4, 1], [], [9, 2], [6], []]>
ובדיוק כמו טנסורים רגילים, אתה יכול להשתמש בחשבון Python ואופרטורים להשוואה כדי לבצע פעולות אלמנטריות. למידע נוסף, עיין בסעיף על מפעילי עומס יתר למטה.
print(digits + 3)
<tf.RaggedTensor [[6, 4, 7, 4], [], [8, 12, 5], [9], []]>
print(digits + tf.ragged.constant([[1, 2, 3, 4], [], [5, 6, 7], [8], []]))
<tf.RaggedTensor [[4, 3, 7, 5], [], [10, 15, 9], [14], []]>
אם אתה צריך לבצע טרנספורמציה אלמנטרית לערכים של RaggedTensor , אתה יכול להשתמש ב- tf.ragged.map_flat_values , שלוקח פונקציה בתוספת ארגומנט אחד או יותר, ומחיל את הפונקציה כדי להפוך את הערכים של RaggedTensor .
times_two_plus_one = lambda x: x * 2 + 1
print(tf.ragged.map_flat_values(times_two_plus_one, digits))
<tf.RaggedTensor [[7, 3, 9, 3], [], [11, 19, 5], [13], []]>
ניתן להמיר טנזורים מרופטים list פייתונים מקוננות ולמערכי array :
digits.to_list()
[[3, 1, 4, 1], [], [5, 9, 2], [6], []]
digits.numpy()
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/ops/ragged/ragged_tensor.py:2063: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
return np.array(rows)
array([array([3, 1, 4, 1], dtype=int32), array([], dtype=int32),
array([5, 9, 2], dtype=int32), array([6], dtype=int32),
array([], dtype=int32)], dtype=object)
בניית טנזור מרופט
הדרך הפשוטה ביותר לבנות טנסור מרופט היא שימוש ב- tf.ragged.constant , שבונה את ה- RaggedTensor המתאים list Python מקוננת או array NumPy:
sentences = tf.ragged.constant([
["Let's", "build", "some", "ragged", "tensors", "!"],
["We", "can", "use", "tf.ragged.constant", "."]])
print(sentences)
<tf.RaggedTensor [[b"Let's", b'build', b'some', b'ragged', b'tensors', b'!'], [b'We', b'can', b'use', b'tf.ragged.constant', b'.']]>
paragraphs = tf.ragged.constant([
[['I', 'have', 'a', 'cat'], ['His', 'name', 'is', 'Mat']],
[['Do', 'you', 'want', 'to', 'come', 'visit'], ["I'm", 'free', 'tomorrow']],
])
print(paragraphs)
<tf.RaggedTensor [[[b'I', b'have', b'a', b'cat'], [b'His', b'name', b'is', b'Mat']], [[b'Do', b'you', b'want', b'to', b'come', b'visit'], [b"I'm", b'free', b'tomorrow']]]>
ניתן לבנות טנסורים מרופטים גם על ידי התאמה של טנסורים של ערכים שטוחים עם טנסורים tf.RaggedTensor.from_row_splits שורות , המציינים כיצד יש לחלק את הערכים הללו לשורות, תוך שימוש בשיטות כיתות מפעל כגון tf.RaggedTensor.from_value_rowids , tf.RaggedTensor.from_row_lengths
tf.RaggedTensor.from_value_rowids
אם אתה יודע לאיזו שורה שייך כל ערך, אז אתה יכול לבנות RaggedTensor באמצעות טנסור מפריד שורות של value_rowids :
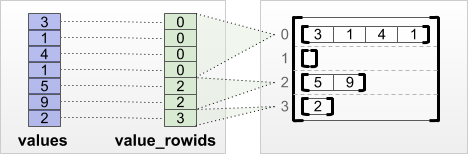
print(tf.RaggedTensor.from_value_rowids(
values=[3, 1, 4, 1, 5, 9, 2],
value_rowids=[0, 0, 0, 0, 2, 2, 3]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
tf.RaggedTensor.from_row_lengths
אם אתה יודע כמה אורכה כל שורה, אז אתה יכול להשתמש row_lengths למחיצות שורות:
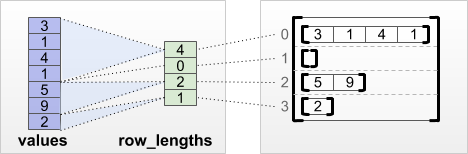
print(tf.RaggedTensor.from_row_lengths(
values=[3, 1, 4, 1, 5, 9, 2],
row_lengths=[4, 0, 2, 1]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
tf.RaggedTensor.from_row_splits
אם אתה יודע את האינדקס שבו כל שורה מתחילה ומסתיימת, אז אתה יכול להשתמש row_splits שורות:
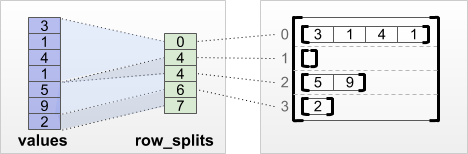
print(tf.RaggedTensor.from_row_splits(
values=[3, 1, 4, 1, 5, 9, 2],
row_splits=[0, 4, 4, 6, 7]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
עיין בתיעוד מחלקה tf.RaggedTensor לקבלת רשימה מלאה של שיטות המפעל.
מה שאתה יכול לאחסן בטנזור מרופט
כמו ב- Tensor s רגיל, הערכים ב- RaggedTensor חייבים להיות כולם באותו סוג; והערכים חייבים להיות כולם באותו עומק קינון ( דרגת הטנזור):
print(tf.ragged.constant([["Hi"], ["How", "are", "you"]])) # ok: type=string, rank=2
<tf.RaggedTensor [[b'Hi'], [b'How', b'are', b'you']]>
print(tf.ragged.constant([[[1, 2], [3]], [[4, 5]]])) # ok: type=int32, rank=3
<tf.RaggedTensor [[[1, 2], [3]], [[4, 5]]]>
try:
tf.ragged.constant([["one", "two"], [3, 4]]) # bad: multiple types
except ValueError as exception:
print(exception)
Can't convert Python sequence with mixed types to Tensor.
try:
tf.ragged.constant(["A", ["B", "C"]]) # bad: multiple nesting depths
except ValueError as exception:
print(exception)
all scalar values must have the same nesting depth
מקרה שימוש לדוגמה
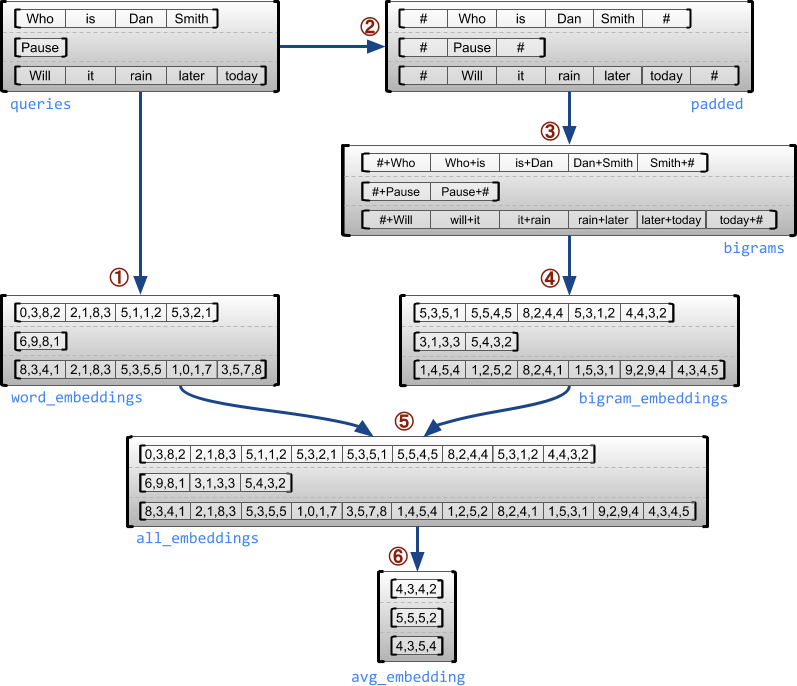
הדוגמה הבאה מדגימה כיצד ניתן להשתמש ב- RaggedTensor כדי לבנות ולשלב הטבעות של unigram ו-bigram עבור אצווה של שאילתות באורך משתנה, תוך שימוש בסמנים מיוחדים להתחלה ולסוף של כל משפט. לפרטים נוספים על האופציות המשמשות בדוגמה זו, עיין בתיעוד החבילה tf.ragged .
queries = tf.ragged.constant([['Who', 'is', 'Dan', 'Smith'],
['Pause'],
['Will', 'it', 'rain', 'later', 'today']])
# Create an embedding table.
num_buckets = 1024
embedding_size = 4
embedding_table = tf.Variable(
tf.random.truncated_normal([num_buckets, embedding_size],
stddev=1.0 / math.sqrt(embedding_size)))
# Look up the embedding for each word.
word_buckets = tf.strings.to_hash_bucket_fast(queries, num_buckets)
word_embeddings = tf.nn.embedding_lookup(embedding_table, word_buckets) # ①
# Add markers to the beginning and end of each sentence.
marker = tf.fill([queries.nrows(), 1], '#')
padded = tf.concat([marker, queries, marker], axis=1) # ②
# Build word bigrams and look up embeddings.
bigrams = tf.strings.join([padded[:, :-1], padded[:, 1:]], separator='+') # ③
bigram_buckets = tf.strings.to_hash_bucket_fast(bigrams, num_buckets)
bigram_embeddings = tf.nn.embedding_lookup(embedding_table, bigram_buckets) # ④
# Find the average embedding for each sentence
all_embeddings = tf.concat([word_embeddings, bigram_embeddings], axis=1) # ⑤
avg_embedding = tf.reduce_mean(all_embeddings, axis=1) # ⑥
print(avg_embedding)
tf.Tensor( [[-0.14285272 0.02908629 -0.16327512 -0.14529026] [-0.4479212 -0.35615516 0.17110227 0.2522229 ] [-0.1987868 -0.13152348 -0.0325102 0.02125177]], shape=(3, 4), dtype=float32)
מידות מרופטות ואחידות
מימד מרופט הוא מימד שאורכים שונים לפרוסות שלו. לדוגמה, הממד הפנימי (העמודה) של rt=[[3, 1, 4, 1], [], [5, 9, 2], [6], []] הוא מרופט, מכיוון שהעמודה פרוסות ( rt[0, :] , ..., rt[4, :] ) יש אורכים שונים. מידות שלכל הפרוסות שלהן אותו אורך נקראות מידות אחידות .
הממד החיצוני ביותר של טנזור מרופט הוא תמיד אחיד, מכיוון שהוא מורכב מפרוסה אחת (ולכן, אין אפשרות לאורכי פרוסה שונים). שאר הממדים עשויים להיות מרופטים או אחידים. לדוגמה, אתה יכול לאחסן את ההטמעות של המילה עבור כל מילה בקבוצת משפטים באמצעות טנזור מרופט עם צורה [num_sentences, (num_words), embedding_size] , כאשר הסוגריים מסביב (num_words) מציינים שהממד הוא מרופט.
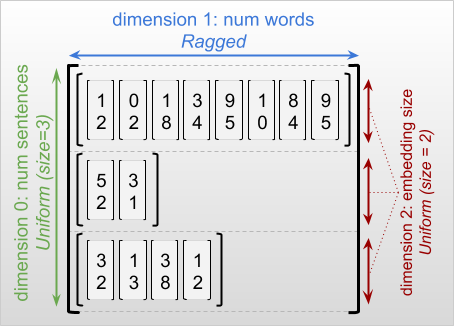
לטנזורים מרופטים עשויים להיות מידות מרופטות מרובות. לדוגמה, תוכל לאחסן אצווה של מסמכי טקסט מובנים באמצעות טנזור עם צורה [num_documents, (num_paragraphs), (num_sentences), (num_words)] (כאשר שוב משתמשים בסוגריים לציון ממדים מרופטים).
כמו ב- tf.Tensor , הדרגה של טנזור מרופט היא מספר הממדים הכולל שלו (כולל מידות מרופטות ואחידות כאחד). טנסור שעלול להיות מרופט הוא ערך שעשוי להיות tf.Tensor או tf.RaggedTensor .
כאשר מתארים את הצורה של RaggedTensor, מידות מרופטות מסומנות באופן קונבנציונלי על ידי הוספתם בסוגריים. לדוגמה, כפי שראית למעלה, ניתן לכתוב את הצורה של RaggedTensor תלת-ממדית המאחסנת הטמעות מילים עבור כל מילה בקבוצת משפטים כ- [num_sentences, (num_words), embedding_size] .
התכונה RaggedTensor.shape מחזירה tf.TensorShape עבור טנזור מרופט שבו לממדים מרופטים יש גודל None :
tf.ragged.constant([["Hi"], ["How", "are", "you"]]).shape
TensorShape([2, None])
ניתן להשתמש בשיטה tf.RaggedTensor.bounding_shape כדי למצוא צורת תוחמת הדוקה עבור RaggedTensor נתון:
print(tf.ragged.constant([["Hi"], ["How", "are", "you"]]).bounding_shape())
tf.Tensor([2 3], shape=(2,), dtype=int64)
מרופט מול דליל
אין לחשוב על טנזור מרופט כסוג של טנסור דליל. במיוחד, טנזורים דלילים הם קידודים יעילים עבור tf.Tensor את אותם נתונים בפורמט קומפקטי; אבל טנסור מרופט הוא הרחבה ל- tf.Tensor מחלקה מורחבת של נתונים. הבדל זה חיוני בעת הגדרת פעולות:
- החלת אופ על טנזור דליל או צפוף אמורה לתת תמיד את אותה תוצאה.
- החלת אופציה על טנזור מרופט או דליל עשויה לתת תוצאות שונות.
כדוגמה להמחשה, שקול כיצד פעולות מערך כגון concat , stack ו- tile מוגדרות עבור טנזורים מרופטים לעומת דלילים. שרשור טנזורים מרופטים מצטרפים לכל שורה ויוצרים שורה אחת עם האורך המשולב:

ragged_x = tf.ragged.constant([["John"], ["a", "big", "dog"], ["my", "cat"]])
ragged_y = tf.ragged.constant([["fell", "asleep"], ["barked"], ["is", "fuzzy"]])
print(tf.concat([ragged_x, ragged_y], axis=1))
<tf.RaggedTensor [[b'John', b'fell', b'asleep'], [b'a', b'big', b'dog', b'barked'], [b'my', b'cat', b'is', b'fuzzy']]>
עם זאת, שרשור טנסורים דלילים שווה ערך לשרשור טנסורים צפופים תואמים, כפי שמודגם בדוגמה הבאה (כאשר Ø מציין ערכים חסרים):
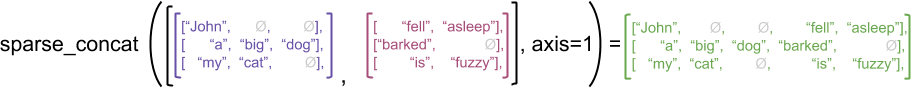
sparse_x = ragged_x.to_sparse()
sparse_y = ragged_y.to_sparse()
sparse_result = tf.sparse.concat(sp_inputs=[sparse_x, sparse_y], axis=1)
print(tf.sparse.to_dense(sparse_result, ''))
tf.Tensor( [[b'John' b'' b'' b'fell' b'asleep'] [b'a' b'big' b'dog' b'barked' b''] [b'my' b'cat' b'' b'is' b'fuzzy']], shape=(3, 5), dtype=string)
לדוגמא נוספת מדוע הבחנה זו חשובה, שקול את ההגדרה של "הערך הממוצע של כל שורה" עבור אופציה כגון tf.reduce_mean . עבור טנזור מרופט, הערך הממוצע לשורה הוא סכום ערכי השורה חלקי רוחב השורה. אבל עבור טנזור דליל, הערך הממוצע לשורה הוא סכום ערכי השורה חלקי הרוחב הכולל של הטנזור הדליל (שגדול או שווה לרוחב השורה הארוכה ביותר).
ממשקי API של TensorFlow
קראס
tf.keras הוא ה-API ברמה גבוהה של TensorFlow לבניית והדרכה של מודלים של למידה עמוקה. ניתן להעביר טנזורים מרופטים כקלטים לדגם Keras על ידי הגדרת ragged ragged=True ב- tf.keras.Input או tf.keras.layers.InputLayer . טנסורים מרופטים עשויים לעבור בין שכבות קרס, ולהחזיר אותם על ידי דגמי קרס. הדוגמה הבאה מציגה דגם LSTM של צעצוע שאומן באמצעות טנזורים מרופטים.
# Task: predict whether each sentence is a question or not.
sentences = tf.constant(
['What makes you think she is a witch?',
'She turned me into a newt.',
'A newt?',
'Well, I got better.'])
is_question = tf.constant([True, False, True, False])
# Preprocess the input strings.
hash_buckets = 1000
words = tf.strings.split(sentences, ' ')
hashed_words = tf.strings.to_hash_bucket_fast(words, hash_buckets)
# Build the Keras model.
keras_model = tf.keras.Sequential([
tf.keras.layers.Input(shape=[None], dtype=tf.int64, ragged=True),
tf.keras.layers.Embedding(hash_buckets, 16),
tf.keras.layers.LSTM(32, use_bias=False),
tf.keras.layers.Dense(32),
tf.keras.layers.Activation(tf.nn.relu),
tf.keras.layers.Dense(1)
])
keras_model.compile(loss='binary_crossentropy', optimizer='rmsprop')
keras_model.fit(hashed_words, is_question, epochs=5)
print(keras_model.predict(hashed_words))
WARNING:tensorflow:Layer lstm will not use cuDNN kernels since it doesn't meet the criteria. It will use a generic GPU kernel as fallback when running on GPU.
Epoch 1/5
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/framework/indexed_slices.py:449: UserWarning: Converting sparse IndexedSlices(IndexedSlices(indices=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/boolean_mask_1/GatherV2:0", shape=(None,), dtype=int32), values=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/boolean_mask/GatherV2:0", shape=(None, 16), dtype=float32), dense_shape=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/Shape:0", shape=(2,), dtype=int32))) to a dense Tensor of unknown shape. This may consume a large amount of memory.
"shape. This may consume a large amount of memory." % value)
1/1 [==============================] - 2s 2s/step - loss: 3.1269
Epoch 2/5
1/1 [==============================] - 0s 18ms/step - loss: 2.1197
Epoch 3/5
1/1 [==============================] - 0s 19ms/step - loss: 2.0196
Epoch 4/5
1/1 [==============================] - 0s 20ms/step - loss: 1.9371
Epoch 5/5
1/1 [==============================] - 0s 18ms/step - loss: 1.8857
[[0.02800461]
[0.00945962]
[0.02283431]
[0.00252927]]
tf.דוגמה
tf.Example הוא קידוד פרוטובוף סטנדרטי עבור נתוני TensorFlow. נתונים המקודדים באמצעות tf.Example s כוללים לרוב תכונות באורך משתנה. לדוגמה, הקוד הבא מגדיר אצווה של ארבע הודעות tf.Example עם אורכי תכונה שונים:
import google.protobuf.text_format as pbtext
def build_tf_example(s):
return pbtext.Merge(s, tf.train.Example()).SerializeToString()
example_batch = [
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["red", "blue"]} } }
feature {key: "lengths" value {int64_list {value: [7]} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["orange"]} } }
feature {key: "lengths" value {int64_list {value: []} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["black", "yellow"]} } }
feature {key: "lengths" value {int64_list {value: [1, 3]} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["green"]} } }
feature {key: "lengths" value {int64_list {value: [3, 5, 2]} } } }''')]
אתה יכול לנתח את הנתונים המקודדים האלה באמצעות tf.io.parse_example , שלוקח טנסור של מחרוזות מסודרות ומילון מפרט תכונות, ומחזיר מילון מיפוי שמות תכונות לטנזורים. כדי לקרוא את התכונות באורך משתנה לתוך טנזורים מרופטים, אתה פשוט משתמש ב- tf.io.RaggedFeature במילון מפרט התכונות:
feature_specification = {
'colors': tf.io.RaggedFeature(tf.string),
'lengths': tf.io.RaggedFeature(tf.int64),
}
feature_tensors = tf.io.parse_example(example_batch, feature_specification)
for name, value in feature_tensors.items():
print("{}={}".format(name, value))
colors=<tf.RaggedTensor [[b'red', b'blue'], [b'orange'], [b'black', b'yellow'], [b'green']]> lengths=<tf.RaggedTensor [[7], [], [1, 3], [3, 5, 2]]>
ניתן להשתמש ב- tf.io.RaggedFeature גם לקריאת תכונות עם מימדים מרופטים מרובים. לפרטים, עיין בתיעוד ה-API .
מערכי נתונים
tf.data הוא API המאפשר לך לבנות צינורות קלט מורכבים מחלקים פשוטים הניתנים לשימוש חוזר. מבנה הנתונים הליבה שלו הוא tf.data.Dataset , המייצג רצף של אלמנטים, שבהם כל אלמנט מורכב ממרכיב אחד או יותר.
# Helper function used to print datasets in the examples below.
def print_dictionary_dataset(dataset):
for i, element in enumerate(dataset):
print("Element {}:".format(i))
for (feature_name, feature_value) in element.items():
print('{:>14} = {}'.format(feature_name, feature_value))
בניית מערכי נתונים עם טנזורים מרופטים
ניתן לבנות מערכי נתונים מטנזורים מרופטים באותן שיטות המשמשות לבנייתם מ- tf.Tensor s או array slices, כגון Dataset.from_tensor_slices :
dataset = tf.data.Dataset.from_tensor_slices(feature_tensors)
print_dictionary_dataset(dataset)
Element 0:
colors = [b'red' b'blue']
lengths = [7]
Element 1:
colors = [b'orange']
lengths = []
Element 2:
colors = [b'black' b'yellow']
lengths = [1 3]
Element 3:
colors = [b'green']
lengths = [3 5 2]
אצווה וביטול אצווה מערכי נתונים עם טנזורים מרופטים
ניתן לקבץ מערכי נתונים עם טנזורים מרופטים (המשלב n אלמנטים עוקבים לרכיב בודד) באמצעות שיטת Dataset.batch .
batched_dataset = dataset.batch(2)
print_dictionary_dataset(batched_dataset)
Element 0:
colors = <tf.RaggedTensor [[b'red', b'blue'], [b'orange']]>
lengths = <tf.RaggedTensor [[7], []]>
Element 1:
colors = <tf.RaggedTensor [[b'black', b'yellow'], [b'green']]>
lengths = <tf.RaggedTensor [[1, 3], [3, 5, 2]]>
לעומת זאת, ניתן להפוך מערך נתונים אצווה למערך נתונים שטוח באמצעות Dataset.unbatch .
unbatched_dataset = batched_dataset.unbatch()
print_dictionary_dataset(unbatched_dataset)
Element 0:
colors = [b'red' b'blue']
lengths = [7]
Element 1:
colors = [b'orange']
lengths = []
Element 2:
colors = [b'black' b'yellow']
lengths = [1 3]
Element 3:
colors = [b'green']
lengths = [3 5 2]
ערכות נתונים אצווה עם טנזורים באורך משתנה שאינם מרופטים
אם יש לך ערכת נתונים שמכילה טנזורים לא מרופטים, ואורכי הטנזורים משתנים בין אלמנטים, אז אתה יכול לקבץ את הטנזורים הלא מרופטים האלה לטנזורים מרופטים על ידי החלת הטרנספורמציה dense_to_ragged_batch :
non_ragged_dataset = tf.data.Dataset.from_tensor_slices([1, 5, 3, 2, 8])
non_ragged_dataset = non_ragged_dataset.map(tf.range)
batched_non_ragged_dataset = non_ragged_dataset.apply(
tf.data.experimental.dense_to_ragged_batch(2))
for element in batched_non_ragged_dataset:
print(element)
<tf.RaggedTensor [[0], [0, 1, 2, 3, 4]]> <tf.RaggedTensor [[0, 1, 2], [0, 1]]> <tf.RaggedTensor [[0, 1, 2, 3, 4, 5, 6, 7]]>
שינוי מערכי נתונים עם טנזורים מרופטים
אתה יכול גם ליצור או לשנות טנזורים מרופטים במערכים נתונים באמצעות Dataset.map :
def transform_lengths(features):
return {
'mean_length': tf.math.reduce_mean(features['lengths']),
'length_ranges': tf.ragged.range(features['lengths'])}
transformed_dataset = dataset.map(transform_lengths)
print_dictionary_dataset(transformed_dataset)
Element 0: mean_length = 7 length_ranges = <tf.RaggedTensor [[0, 1, 2, 3, 4, 5, 6]]> Element 1: mean_length = 0 length_ranges = <tf.RaggedTensor []> Element 2: mean_length = 2 length_ranges = <tf.RaggedTensor [[0], [0, 1, 2]]> Element 3: mean_length = 3 length_ranges = <tf.RaggedTensor [[0, 1, 2], [0, 1, 2, 3, 4], [0, 1]]>
tf.function
tf.function הוא מעצב שמחשב מראש גרפים של TensorFlow עבור פונקציות Python, מה שיכול לשפר משמעותית את הביצועים של קוד TensorFlow שלך. ניתן להשתמש בטנסורים מרופטים בשקיפות עם @tf.function . לדוגמה, הפונקציה הבאה פועלת עם טנזורים מרופטים וגם עם טנזורים לא מרופטים:
@tf.function
def make_palindrome(x, axis):
return tf.concat([x, tf.reverse(x, [axis])], axis)
make_palindrome(tf.constant([[1, 2], [3, 4], [5, 6]]), axis=1)
<tf.Tensor: shape=(3, 4), dtype=int32, numpy=
array([[1, 2, 2, 1],
[3, 4, 4, 3],
[5, 6, 6, 5]], dtype=int32)>
make_palindrome(tf.ragged.constant([[1, 2], [3], [4, 5, 6]]), axis=1)
2021-09-22 20:36:51.018367: W tensorflow/core/grappler/optimizers/loop_optimizer.cc:907] Skipping loop optimization for Merge node with control input: RaggedConcat/assert_equal_1/Assert/AssertGuard/branch_executed/_9 <tf.RaggedTensor [[1, 2, 2, 1], [3, 3], [4, 5, 6, 6, 5, 4]]>
אם אתה רוצה לציין במפורש את input_signature עבור הפונקציה tf.function ., אז אתה יכול לעשות זאת באמצעות tf.RaggedTensorSpec .
@tf.function(
input_signature=[tf.RaggedTensorSpec(shape=[None, None], dtype=tf.int32)])
def max_and_min(rt):
return (tf.math.reduce_max(rt, axis=-1), tf.math.reduce_min(rt, axis=-1))
max_and_min(tf.ragged.constant([[1, 2], [3], [4, 5, 6]]))
(<tf.Tensor: shape=(3,), dtype=int32, numpy=array([2, 3, 6], dtype=int32)>, <tf.Tensor: shape=(3,), dtype=int32, numpy=array([1, 3, 4], dtype=int32)>)
פונקציות קונקרטיות
פונקציות קונקרטיות עוטפות גרפים בודדים שנבנו על ידי tf.function . ניתן להשתמש בטנסורים מרופטים בשקיפות עם פונקציות בטון.
@tf.function
def increment(x):
return x + 1
rt = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
cf = increment.get_concrete_function(rt)
print(cf(rt))
<tf.RaggedTensor [[2, 3], [4], [5, 6, 7]]>
מודלים שמורים
A SavedModel היא תוכנית TensorFlow מסודרת, הכוללת גם משקלים וגם חישובים. ניתן לבנות אותו מדגם קרס או מדגם מותאם אישית. בכל מקרה, ניתן להשתמש בטנזורים מרופטים בשקיפות עם הפונקציות והשיטות המוגדרות על ידי SavedModel.
דוגמה: שמירת דגם של קרס
import tempfile
keras_module_path = tempfile.mkdtemp()
tf.saved_model.save(keras_model, keras_module_path)
imported_model = tf.saved_model.load(keras_module_path)
imported_model(hashed_words)
2021-09-22 20:36:52.069689: W tensorflow/python/util/util.cc:348] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
WARNING:absl:Function `_wrapped_model` contains input name(s) args_0 with unsupported characters which will be renamed to args_0_1 in the SavedModel.
INFO:tensorflow:Assets written to: /tmp/tmp114axtt7/assets
INFO:tensorflow:Assets written to: /tmp/tmp114axtt7/assets
<tf.Tensor: shape=(4, 1), dtype=float32, numpy=
array([[0.02800461],
[0.00945962],
[0.02283431],
[0.00252927]], dtype=float32)>
דוגמה: שמירת דגם מותאם אישית
class CustomModule(tf.Module):
def __init__(self, variable_value):
super(CustomModule, self).__init__()
self.v = tf.Variable(variable_value)
@tf.function
def grow(self, x):
return x * self.v
module = CustomModule(100.0)
# Before saving a custom model, you must ensure that concrete functions are
# built for each input signature that you will need.
module.grow.get_concrete_function(tf.RaggedTensorSpec(shape=[None, None],
dtype=tf.float32))
custom_module_path = tempfile.mkdtemp()
tf.saved_model.save(module, custom_module_path)
imported_model = tf.saved_model.load(custom_module_path)
imported_model.grow(tf.ragged.constant([[1.0, 4.0, 3.0], [2.0]]))
INFO:tensorflow:Assets written to: /tmp/tmpnn4u8dy5/assets INFO:tensorflow:Assets written to: /tmp/tmpnn4u8dy5/assets <tf.RaggedTensor [[100.0, 400.0, 300.0], [200.0]]>
מפעילים עמוסים מדי
המחלקה RaggedTensor יתר על המידה את אופרטורי החשבון וההשוואה הסטנדרטיים של Python, מה שמקל על ביצוע מתמטיקה בסיסית אלמנטרית:
x = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
y = tf.ragged.constant([[1, 1], [2], [3, 3, 3]])
print(x + y)
<tf.RaggedTensor [[2, 3], [5], [7, 8, 9]]>
מכיוון שהאופרטורים העמוסים מבצעים חישובים אלמנטריים, הקלט לכל הפעולות הבינאריות חייבות להיות באותה צורה או להיות ניתנות לשידור לאותה צורה. במקרה השידור הפשוט ביותר, סקלאר בודד משולב באופן אלמנטרי עם כל ערך בטנזור מרופט:
x = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
print(x + 3)
<tf.RaggedTensor [[4, 5], [6], [7, 8, 9]]>
לדיון על מקרים מתקדמים יותר, עיין בסעיף על שידורים .
טנזורים מרופטים מעמיסים את אותה קבוצת אופרטורים כמו Tensor s רגילים: האופרטורים האנריים - , ~ ו- abs() ; והאופרטורים הבינאריים + , - , * , / , // , % , ** , & , | , ^ , == , < , <= , > ו >= .
יצירת אינדקס
טנזורים מרופטים תומכים באינדקס בסגנון Python, כולל אינדקס וחתך רב ממדי. הדוגמאות הבאות מדגימות אינדקס טנזור מרופט עם טנזור מרופט דו-ממדי ותלת-ממדי.
דוגמאות לאינדקס: טנזור מרופט דו-ממדי
queries = tf.ragged.constant(
[['Who', 'is', 'George', 'Washington'],
['What', 'is', 'the', 'weather', 'tomorrow'],
['Goodnight']])
print(queries[1]) # A single query
tf.Tensor([b'What' b'is' b'the' b'weather' b'tomorrow'], shape=(5,), dtype=string)
print(queries[1, 2]) # A single word
tf.Tensor(b'the', shape=(), dtype=string)
print(queries[1:]) # Everything but the first row
<tf.RaggedTensor [[b'What', b'is', b'the', b'weather', b'tomorrow'], [b'Goodnight']]>
print(queries[:, :3]) # The first 3 words of each query
<tf.RaggedTensor [[b'Who', b'is', b'George'], [b'What', b'is', b'the'], [b'Goodnight']]>
print(queries[:, -2:]) # The last 2 words of each query
<tf.RaggedTensor [[b'George', b'Washington'], [b'weather', b'tomorrow'], [b'Goodnight']]>
דוגמאות לאינדקס: טנזור מרופט בתלת מימד
rt = tf.ragged.constant([[[1, 2, 3], [4]],
[[5], [], [6]],
[[7]],
[[8, 9], [10]]])
print(rt[1]) # Second row (2D RaggedTensor)
<tf.RaggedTensor [[5], [], [6]]>
print(rt[3, 0]) # First element of fourth row (1D Tensor)
tf.Tensor([8 9], shape=(2,), dtype=int32)
print(rt[:, 1:3]) # Items 1-3 of each row (3D RaggedTensor)
<tf.RaggedTensor [[[4]], [[], [6]], [], [[10]]]>
print(rt[:, -1:]) # Last item of each row (3D RaggedTensor)
<tf.RaggedTensor [[[4]], [[6]], [[7]], [[10]]]>
RaggedTensor תומכים באינדקס ובחיתוך רב מימדי עם הגבלה אחת: אינדקס לממד מרופט אסור. מקרה זה בעייתי מכיוון שהערך המצוין עשוי להתקיים בשורות מסוימות אך לא באחרות. במקרים כאלה, לא ברור אם עליך (1) להעלות IndexError ; (2) השתמש בערך ברירת מחדל; או (3) דלג על הערך הזה והחזר טנסור עם פחות שורות ממה שהתחלת איתו. בעקבות העקרונות המנחים של Python ("מול אי בהירות, סרב לפיתוי לנחש"), פעולה זו אסורה כרגע.
המרת סוג טנסור
המחלקה RaggedTensor מגדירה שיטות שניתן להשתמש בהן כדי להמיר בין RaggedTensor s ל- tf.Tensor s או tf.SparseTensors :
ragged_sentences = tf.ragged.constant([
['Hi'], ['Welcome', 'to', 'the', 'fair'], ['Have', 'fun']])
# RaggedTensor -> Tensor
print(ragged_sentences.to_tensor(default_value='', shape=[None, 10]))
tf.Tensor( [[b'Hi' b'' b'' b'' b'' b'' b'' b'' b'' b''] [b'Welcome' b'to' b'the' b'fair' b'' b'' b'' b'' b'' b''] [b'Have' b'fun' b'' b'' b'' b'' b'' b'' b'' b'']], shape=(3, 10), dtype=string)
# Tensor -> RaggedTensor
x = [[1, 3, -1, -1], [2, -1, -1, -1], [4, 5, 8, 9]]
print(tf.RaggedTensor.from_tensor(x, padding=-1))
<tf.RaggedTensor [[1, 3], [2], [4, 5, 8, 9]]>
#RaggedTensor -> SparseTensor
print(ragged_sentences.to_sparse())
SparseTensor(indices=tf.Tensor( [[0 0] [1 0] [1 1] [1 2] [1 3] [2 0] [2 1]], shape=(7, 2), dtype=int64), values=tf.Tensor([b'Hi' b'Welcome' b'to' b'the' b'fair' b'Have' b'fun'], shape=(7,), dtype=string), dense_shape=tf.Tensor([3 4], shape=(2,), dtype=int64))
# SparseTensor -> RaggedTensor
st = tf.SparseTensor(indices=[[0, 0], [2, 0], [2, 1]],
values=['a', 'b', 'c'],
dense_shape=[3, 3])
print(tf.RaggedTensor.from_sparse(st))
<tf.RaggedTensor [[b'a'], [], [b'b', b'c']]>
הערכת טנזורים מרופטים
כדי לגשת לערכים בטנזור מרופט, אתה יכול:
- השתמש
tf.RaggedTensor.to_listכדי להמיר את הטנזור המרופט לרשימת Python מקוננת. - השתמש
tf.RaggedTensor.numpyכדי להמיר את הטנזור המרופט למערך NumPy שהערכים שלו הם מערכי NumPy מקוננים. - לפרק את הטנזור המרופט למרכיביו, באמצעות המאפיינים
tf.RaggedTensor.valuesו-tf.RaggedTensor.row_splits, או שיטות חלוקת שורות כגוןtf.RaggedTensor.row_lengthsו-tf.RaggedTensor.value_rowids. - השתמש באינדקס של Python כדי לבחור ערכים מהטנזור המרופט.
rt = tf.ragged.constant([[1, 2], [3, 4, 5], [6], [], [7]])
print("Python list:", rt.to_list())
print("NumPy array:", rt.numpy())
print("Values:", rt.values.numpy())
print("Splits:", rt.row_splits.numpy())
print("Indexed value:", rt[1].numpy())
Python list: [[1, 2], [3, 4, 5], [6], [], [7]] NumPy array: [array([1, 2], dtype=int32) array([3, 4, 5], dtype=int32) array([6], dtype=int32) array([], dtype=int32) array([7], dtype=int32)] Values: [1 2 3 4 5 6 7] Splits: [0 2 5 6 6 7] Indexed value: [3 4 5] /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/ops/ragged/ragged_tensor.py:2063: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray return np.array(rows)
שידור
שידור הוא תהליך של הפיכת טנסור עם צורות שונות לצורות תואמות לפעולות אלמנטיות. לרקע נוסף על שידור, עיין ב:
השלבים הבסיסיים לשידור של שני כניסות x ו- y כדי לקבל צורות תואמות הם:
אם ל-
xול-yאין אותו מספר של מידות, הוסף מידות חיצוניות (עם מידה 1) עד שיהיו.עבור כל מימד שבו ל-
xול-yיש גדלים שונים:
- אם ל-
xאוyיש גודל1בממדd, אז חזור על הערכים שלו על פני ממדdכדי להתאים לגודל הקלט האחר. - אחרת, העלה חריגה (
xו-yאינם תואמים לשידור).
כאשר גודלו של טנזור בממד אחיד הוא מספר בודד (גודל הפרוסות על פני הממד הזה); והגודל של טנזור בממד מרופט הוא רשימה של אורכי פרוסה (עבור כל הפרוסות על פני הממד הזה).
דוגמאות לשידור
# x (2D ragged): 2 x (num_rows)
# y (scalar)
# result (2D ragged): 2 x (num_rows)
x = tf.ragged.constant([[1, 2], [3]])
y = 3
print(x + y)
<tf.RaggedTensor [[4, 5], [6]]>
# x (2d ragged): 3 x (num_rows)
# y (2d tensor): 3 x 1
# Result (2d ragged): 3 x (num_rows)
x = tf.ragged.constant(
[[10, 87, 12],
[19, 53],
[12, 32]])
y = [[1000], [2000], [3000]]
print(x + y)
<tf.RaggedTensor [[1010, 1087, 1012], [2019, 2053], [3012, 3032]]>
# x (3d ragged): 2 x (r1) x 2
# y (2d ragged): 1 x 1
# Result (3d ragged): 2 x (r1) x 2
x = tf.ragged.constant(
[[[1, 2], [3, 4], [5, 6]],
[[7, 8]]],
ragged_rank=1)
y = tf.constant([[10]])
print(x + y)
<tf.RaggedTensor [[[11, 12], [13, 14], [15, 16]], [[17, 18]]]>
# x (3d ragged): 2 x (r1) x (r2) x 1
# y (1d tensor): 3
# Result (3d ragged): 2 x (r1) x (r2) x 3
x = tf.ragged.constant(
[
[
[[1], [2]],
[],
[[3]],
[[4]],
],
[
[[5], [6]],
[[7]]
]
],
ragged_rank=2)
y = tf.constant([10, 20, 30])
print(x + y)
<tf.RaggedTensor [[[[11, 21, 31], [12, 22, 32]], [], [[13, 23, 33]], [[14, 24, 34]]], [[[15, 25, 35], [16, 26, 36]], [[17, 27, 37]]]]>
הנה כמה דוגמאות לצורות שאינן משודרות:
# x (2d ragged): 3 x (r1)
# y (2d tensor): 3 x 4 # trailing dimensions do not match
x = tf.ragged.constant([[1, 2], [3, 4, 5, 6], [7]])
y = tf.constant([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 1 b'lengths=' 4 b'dim_size=' 2, 4, 1
# x (2d ragged): 3 x (r1)
# y (2d ragged): 3 x (r2) # ragged dimensions do not match.
x = tf.ragged.constant([[1, 2, 3], [4], [5, 6]])
y = tf.ragged.constant([[10, 20], [30, 40], [50]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 1 b'lengths=' 2, 2, 1 b'dim_size=' 3, 1, 2
# x (3d ragged): 3 x (r1) x 2
# y (3d ragged): 3 x (r1) x 3 # trailing dimensions do not match
x = tf.ragged.constant([[[1, 2], [3, 4], [5, 6]],
[[7, 8], [9, 10]]])
y = tf.ragged.constant([[[1, 2, 0], [3, 4, 0], [5, 6, 0]],
[[7, 8, 0], [9, 10, 0]]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 2 b'lengths=' 3, 3, 3, 3, 3 b'dim_size=' 2, 2, 2, 2, 2
קידוד RaggedTensor
טנזורים Ragged מקודדים באמצעות מחלקה RaggedTensor . באופן פנימי, כל RaggedTensor מורכב מ:
- טנסור
values, המשרשר את השורות באורך משתנה לרשימה שטוחה. -
row_partition, אשר מציינת כיצד אותם ערכים שטוחים מחולקים לשורות.
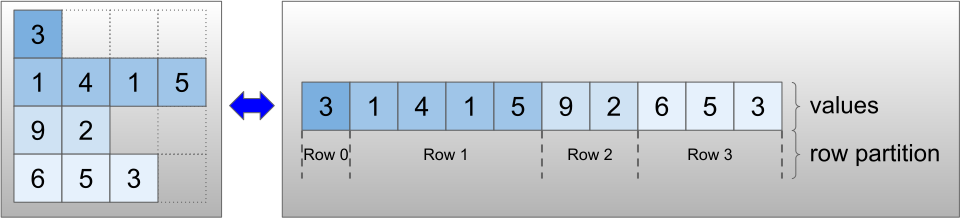
ניתן לאחסן את row_partition באמצעות ארבעה קידודים שונים:
-
row_splitsהוא וקטור שלם המציין את נקודות הפיצול בין שורות. -
value_rowidsהוא וקטור שלם המציין את אינדקס השורה עבור כל ערך. -
row_lengthsהוא וקטור שלם המציין את אורך כל שורה. -
uniform_row_lengthהוא סקלאר שלם המציין אורך בודד עבור כל השורות.
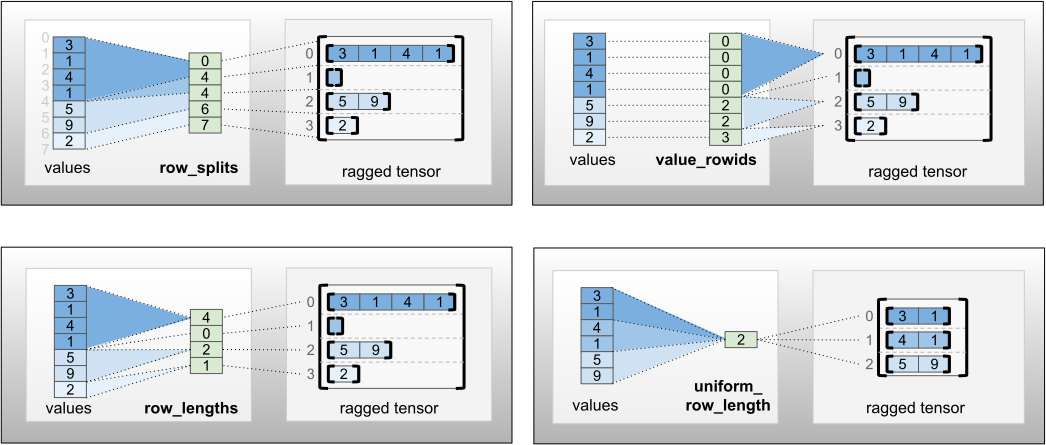
ניתן לכלול צמצום סקלרי של מספר שלם בקידוד nrows כדי row_partition בחשבון שורות עוקבות ריקות עם value_rowids או שורות ריקות עם uniform_row_length .
rt = tf.RaggedTensor.from_row_splits(
values=[3, 1, 4, 1, 5, 9, 2],
row_splits=[0, 4, 4, 6, 7])
print(rt)
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
הבחירה באיזה קידוד להשתמש עבור מחיצות שורות מנוהלת באופן פנימי על ידי טנזורים מרופטים כדי לשפר את היעילות בהקשרים מסוימים. בפרט, כמה מהיתרונות והחסרונות של סכימות חלוקת השורות השונות הן:
- אינדקס יעיל : הקידוד
row_splitsמאפשר אינדקס בזמן קבוע וחיתוך לטנזורים מרופטים. - שרשור יעיל : קידוד
row_lengthsיעיל יותר בעת שרשור טנזורים מרופטים, מכיוון שאורכי השורות אינם משתנים כאשר שני טנסורים משורשרים יחדיו. - גודל קידוד קטן : הקידוד
value_rowidsיעיל יותר כאשר מאחסנים טנזורים מרופטים שיש להם מספר רב של שורות ריקות, מכיוון שגודל הטנזור תלוי רק במספר הערכים הכולל. מצד שני,row_splitsו-row_lengthsיעילים יותר בעת אחסון טנזורים מרופטים עם שורות ארוכות יותר, מכיוון שהם דורשים רק ערך סקלארי אחד עבור כל שורה. - תאימות : ערכת
value_rowidsתואמת את פורמט הפילוח המשמש בפעולות, כגוןtf.segment_sum. ערכתrow_limitsתואמת את הפורמט שבו משתמשים פעולות כגוןtf.sequence_mask. - מידות אחידות : כפי שנדון להלן, הקידוד
uniform_row_lengthמשמש לקידוד טנזורים מרופטים עם מידות אחידות.
מידות מרופטות מרובות
טנסור מרופט עם מימדים מרובים מקודד על ידי שימוש ב- RaggedTensor מקונן עבור טנסור values . כל RaggedTensor מקונן מוסיף מימד מרופט יחיד.
![]()
rt = tf.RaggedTensor.from_row_splits(
values=tf.RaggedTensor.from_row_splits(
values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
row_splits=[0, 3, 3, 5, 9, 10]),
row_splits=[0, 1, 1, 5])
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
<tf.RaggedTensor [[[10, 11, 12]], [], [[], [13, 14], [15, 16, 17, 18], [19]]]> Shape: (3, None, None) Number of partitioned dimensions: 2
ניתן להשתמש בפונקציית היצרן tf.RaggedTensor.from_nested_row_splits לבניית RaggedTensor עם מימדים מרופטים מרובים ישירות על ידי אספקת רשימה של טנזורים row_splits :
rt = tf.RaggedTensor.from_nested_row_splits(
flat_values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
nested_row_splits=([0, 1, 1, 5], [0, 3, 3, 5, 9, 10]))
print(rt)
<tf.RaggedTensor [[[10, 11, 12]], [], [[], [13, 14], [15, 16, 17, 18], [19]]]>
דרגה מרופדת וערכים שטוחים
הדירוג המרופט של טנסור מרופט הוא מספר הפעמים values הבסיסיים טנזור חולקו (כלומר עומק הקינון של אובייקטים RaggedTensor ). טנסור values הפנימיים ביותר ידוע בתור flat_values שלו. בדוגמה הבאה, conversations יש ragged_rank=3, וה- flat_values שלה הוא Tensor 1D עם 24 מחרוזות:
# shape = [batch, (paragraph), (sentence), (word)]
conversations = tf.ragged.constant(
[[[["I", "like", "ragged", "tensors."]],
[["Oh", "yeah?"], ["What", "can", "you", "use", "them", "for?"]],
[["Processing", "variable", "length", "data!"]]],
[[["I", "like", "cheese."], ["Do", "you?"]],
[["Yes."], ["I", "do."]]]])
conversations.shape
TensorShape([2, None, None, None])
assert conversations.ragged_rank == len(conversations.nested_row_splits)
conversations.ragged_rank # Number of partitioned dimensions.
3
conversations.flat_values.numpy()
array([b'I', b'like', b'ragged', b'tensors.', b'Oh', b'yeah?', b'What',
b'can', b'you', b'use', b'them', b'for?', b'Processing',
b'variable', b'length', b'data!', b'I', b'like', b'cheese.', b'Do',
b'you?', b'Yes.', b'I', b'do.'], dtype=object)
מידות פנימיות אחידות
טנזורים מרופטים בעלי ממדים פנימיים אחידים מקודדים על ידי שימוש ב- tf.Tensor רב ממדי עבור ה-flat_values (כלומר, values הפנימיים ביותר).
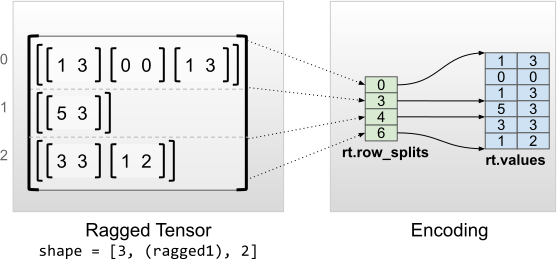
rt = tf.RaggedTensor.from_row_splits(
values=[[1, 3], [0, 0], [1, 3], [5, 3], [3, 3], [1, 2]],
row_splits=[0, 3, 4, 6])
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
print("Flat values shape: {}".format(rt.flat_values.shape))
print("Flat values:\n{}".format(rt.flat_values))
<tf.RaggedTensor [[[1, 3], [0, 0], [1, 3]], [[5, 3]], [[3, 3], [1, 2]]]> Shape: (3, None, 2) Number of partitioned dimensions: 1 Flat values shape: (6, 2) Flat values: [[1 3] [0 0] [1 3] [5 3] [3 3] [1 2]]
מידות לא פנימיות אחידות
טנזורים מרופטים עם ממדים אחידים שאינם פנימיים מקודדים על ידי חלוקת שורות עם uniform_row_length .
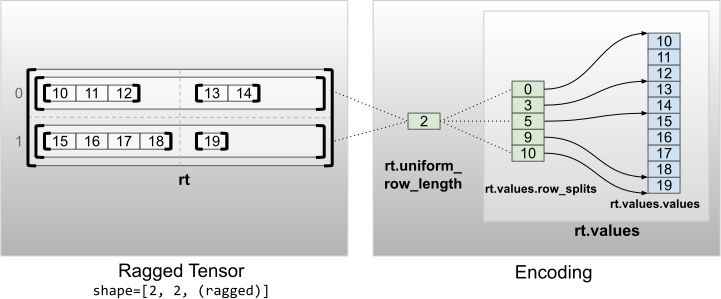
rt = tf.RaggedTensor.from_uniform_row_length(
values=tf.RaggedTensor.from_row_splits(
values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
row_splits=[0, 3, 5, 9, 10]),
uniform_row_length=2)
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
<tf.RaggedTensor [[[10, 11, 12], [13, 14]], [[15, 16, 17, 18], [19]]]> Shape: (2, 2, None) Number of partitioned dimensions: 2