
| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub |
Документация API: tf.RaggedTensor tf.ragged
Настраивать
import math
import tensorflow as tf
Обзор
Ваши данные бывают разных форм; ваши тензоры тоже должны. Рваные тензоры — это эквивалент TensorFlow вложенных списков переменной длины. Они упрощают хранение и обработку данных неоднородной формы, в том числе:
- Элементы переменной длины, такие как набор актеров в фильме.
- Пакеты последовательных входных данных переменной длины, такие как предложения или видеоклипы.
- Иерархические входные данные, такие как текстовые документы, разделенные на разделы, абзацы, предложения и слова.
- Отдельные поля в структурированных входных данных, таких как буферы протоколов.
Что можно сделать с рваным тензором
Рваные тензоры поддерживаются более чем сотней операций TensorFlow, включая математические операции (такие как tf.add и tf.reduce_mean ), операции с массивами (такие как tf.concat и tf.tile ), операции манипулирования строками (такие как tf.substr ), операции управления потоком (такие как tf.while_loop и tf.map_fn ) и многие другие:
digits = tf.ragged.constant([[3, 1, 4, 1], [], [5, 9, 2], [6], []])
words = tf.ragged.constant([["So", "long"], ["thanks", "for", "all", "the", "fish"]])
print(tf.add(digits, 3))
print(tf.reduce_mean(digits, axis=1))
print(tf.concat([digits, [[5, 3]]], axis=0))
print(tf.tile(digits, [1, 2]))
print(tf.strings.substr(words, 0, 2))
print(tf.map_fn(tf.math.square, digits))
<tf.RaggedTensor [[6, 4, 7, 4], [], [8, 12, 5], [9], []]> tf.Tensor([2.25 nan 5.33333333 6. nan], shape=(5,), dtype=float64) <tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9, 2], [6], [], [5, 3]]> <tf.RaggedTensor [[3, 1, 4, 1, 3, 1, 4, 1], [], [5, 9, 2, 5, 9, 2], [6, 6], []]> <tf.RaggedTensor [[b'So', b'lo'], [b'th', b'fo', b'al', b'th', b'fi']]> <tf.RaggedTensor [[9, 1, 16, 1], [], [25, 81, 4], [36], []]>
Существует также ряд методов и операций, специфичных для неоднородных тензоров, включая фабричные методы, методы преобразования и операции сопоставления значений. Список поддерживаемых операций см. в документации пакета tf.ragged .
Рваные тензоры поддерживаются многими API-интерфейсами TensorFlow, включая Keras , Datasets , tf.function , SavedModels и tf.Example . Для получения дополнительной информации см. раздел об API TensorFlow ниже.
Как и в случае с обычными тензорами, вы можете использовать индексацию в стиле Python для доступа к определенным фрагментам неоднородного тензора. Дополнительные сведения см. в разделе об индексировании ниже.
print(digits[0]) # First row
tf.Tensor([3 1 4 1], shape=(4,), dtype=int32)
print(digits[:, :2]) # First two values in each row.
<tf.RaggedTensor [[3, 1], [], [5, 9], [6], []]>
print(digits[:, -2:]) # Last two values in each row.
<tf.RaggedTensor [[4, 1], [], [9, 2], [6], []]>
И точно так же, как обычные тензоры, вы можете использовать арифметические операторы Python и операторы сравнения для выполнения поэлементных операций. Для получения дополнительной информации см. раздел « Перегруженные операторы » ниже.
print(digits + 3)
<tf.RaggedTensor [[6, 4, 7, 4], [], [8, 12, 5], [9], []]>
print(digits + tf.ragged.constant([[1, 2, 3, 4], [], [5, 6, 7], [8], []]))
<tf.RaggedTensor [[4, 3, 7, 5], [], [10, 15, 9], [14], []]>
Если вам нужно выполнить поэлементное преобразование значений RaggedTensor , вы можете использовать tf.ragged.map_flat_values , который принимает функцию плюс один или несколько аргументов и применяет функцию для преобразования RaggedTensor .
times_two_plus_one = lambda x: x * 2 + 1
print(tf.ragged.map_flat_values(times_two_plus_one, digits))
<tf.RaggedTensor [[7, 3, 9, 3], [], [11, 19, 5], [13], []]>
Рваные тензоры можно преобразовать во вложенные list Python и array NumPy:
digits.to_list()
[[3, 1, 4, 1], [], [5, 9, 2], [6], []]
digits.numpy()
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/ops/ragged/ragged_tensor.py:2063: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
return np.array(rows)
array([array([3, 1, 4, 1], dtype=int32), array([], dtype=int32),
array([5, 9, 2], dtype=int32), array([6], dtype=int32),
array([], dtype=int32)], dtype=object)
Построение рваного тензора
Самый простой способ построить неоднородный тензор — использовать tf.ragged.constant , который создает RaggedTensor , соответствующий заданному вложенному list Python или array NumPy:
sentences = tf.ragged.constant([
["Let's", "build", "some", "ragged", "tensors", "!"],
["We", "can", "use", "tf.ragged.constant", "."]])
print(sentences)
<tf.RaggedTensor [[b"Let's", b'build', b'some', b'ragged', b'tensors', b'!'], [b'We', b'can', b'use', b'tf.ragged.constant', b'.']]>
paragraphs = tf.ragged.constant([
[['I', 'have', 'a', 'cat'], ['His', 'name', 'is', 'Mat']],
[['Do', 'you', 'want', 'to', 'come', 'visit'], ["I'm", 'free', 'tomorrow']],
])
print(paragraphs)
<tf.RaggedTensor [[[b'I', b'have', b'a', b'cat'], [b'His', b'name', b'is', b'Mat']], [[b'Do', b'you', b'want', b'to', b'come', b'visit'], [b"I'm", b'free', b'tomorrow']]]>
Рваные тензоры также могут быть созданы путем объединения тензоров плоских значений с тензорами разделения строк, указывающими, как эти значения должны быть разделены на строки, с использованием методов фабричных классов, таких как tf.RaggedTensor.from_value_rowids , tf.RaggedTensor.from_row_lengths и tf.RaggedTensor.from_row_splits .
tf.RaggedTensor.from_value_rowids
Если вы знаете, к какой строке принадлежит каждое значение, вы можете построить RaggedTensor , используя тензор разделения строк value_rowids :
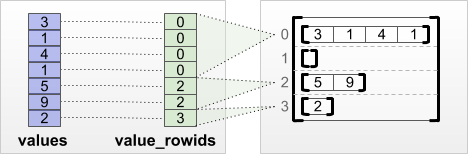
print(tf.RaggedTensor.from_value_rowids(
values=[3, 1, 4, 1, 5, 9, 2],
value_rowids=[0, 0, 0, 0, 2, 2, 3]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
tf.RaggedTensor.from_row_lengths
Если вы знаете длину каждой строки, вы можете использовать тензор разделения строк row_lengths :
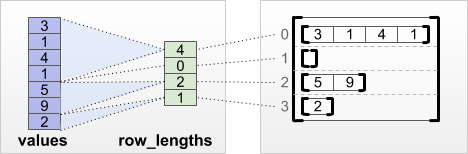
print(tf.RaggedTensor.from_row_lengths(
values=[3, 1, 4, 1, 5, 9, 2],
row_lengths=[4, 0, 2, 1]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
tf.RaggedTensor.from_row_splits
Если вы знаете индекс, где начинается и заканчивается каждая строка, вы можете использовать тензор разделения строк row_splits :
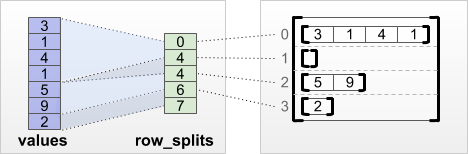
print(tf.RaggedTensor.from_row_splits(
values=[3, 1, 4, 1, 5, 9, 2],
row_splits=[0, 4, 4, 6, 7]))
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
Полный список фабричных методов см. в документации по классу tf.RaggedTensor .
Что можно хранить в рваном тензоре
Как и в случае с обычными Tensor , все значения в RaggedTensor должны иметь один и тот же тип; и все значения должны иметь одинаковую глубину вложенности ( ранг тензора):
print(tf.ragged.constant([["Hi"], ["How", "are", "you"]])) # ok: type=string, rank=2
<tf.RaggedTensor [[b'Hi'], [b'How', b'are', b'you']]>
print(tf.ragged.constant([[[1, 2], [3]], [[4, 5]]])) # ok: type=int32, rank=3
<tf.RaggedTensor [[[1, 2], [3]], [[4, 5]]]>
try:
tf.ragged.constant([["one", "two"], [3, 4]]) # bad: multiple types
except ValueError as exception:
print(exception)
Can't convert Python sequence with mixed types to Tensor.
try:
tf.ragged.constant(["A", ["B", "C"]]) # bad: multiple nesting depths
except ValueError as exception:
print(exception)
all scalar values must have the same nesting depth
Пример использования
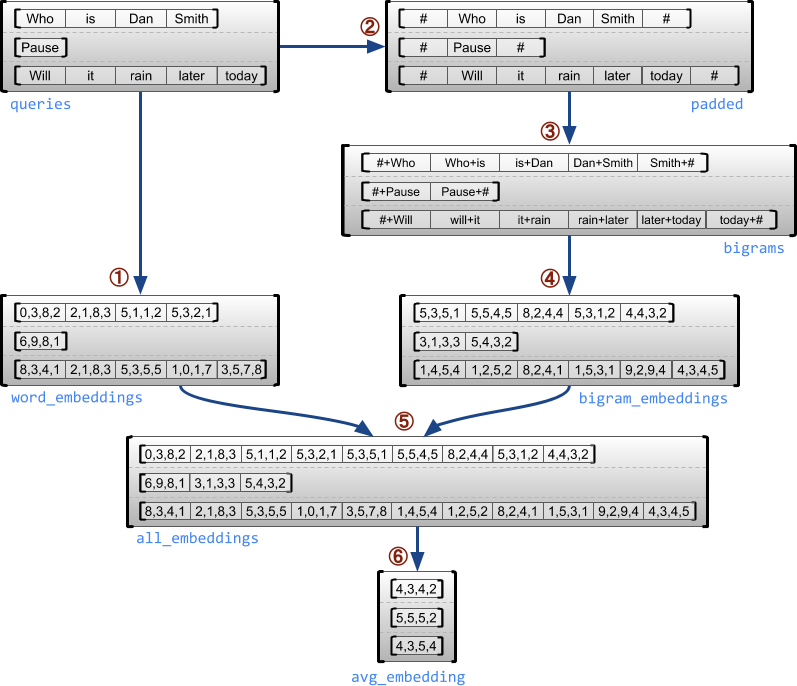
В следующем примере показано, как RaggedTensor можно использовать для создания и объединения вложений униграмм и биграмм для пакета запросов переменной длины с использованием специальных маркеров для начала и конца каждого предложения. Дополнительные сведения об операциях, используемых в этом примере, см. в документации по пакету tf.ragged .
queries = tf.ragged.constant([['Who', 'is', 'Dan', 'Smith'],
['Pause'],
['Will', 'it', 'rain', 'later', 'today']])
# Create an embedding table.
num_buckets = 1024
embedding_size = 4
embedding_table = tf.Variable(
tf.random.truncated_normal([num_buckets, embedding_size],
stddev=1.0 / math.sqrt(embedding_size)))
# Look up the embedding for each word.
word_buckets = tf.strings.to_hash_bucket_fast(queries, num_buckets)
word_embeddings = tf.nn.embedding_lookup(embedding_table, word_buckets) # ①
# Add markers to the beginning and end of each sentence.
marker = tf.fill([queries.nrows(), 1], '#')
padded = tf.concat([marker, queries, marker], axis=1) # ②
# Build word bigrams and look up embeddings.
bigrams = tf.strings.join([padded[:, :-1], padded[:, 1:]], separator='+') # ③
bigram_buckets = tf.strings.to_hash_bucket_fast(bigrams, num_buckets)
bigram_embeddings = tf.nn.embedding_lookup(embedding_table, bigram_buckets) # ④
# Find the average embedding for each sentence
all_embeddings = tf.concat([word_embeddings, bigram_embeddings], axis=1) # ⑤
avg_embedding = tf.reduce_mean(all_embeddings, axis=1) # ⑥
print(avg_embedding)
tf.Tensor( [[-0.14285272 0.02908629 -0.16327512 -0.14529026] [-0.4479212 -0.35615516 0.17110227 0.2522229 ] [-0.1987868 -0.13152348 -0.0325102 0.02125177]], shape=(3, 4), dtype=float32)
Рваные и однородные размеры
Неровное измерение — это измерение, срезы которого могут иметь разную длину. Например, внутреннее (столбцовое) измерение rt=[[3, 1, 4, 1], [], [5, 9, 2], [6], []] неравномерно, поскольку срезы столбца ( rt[0, :] , ..., rt[4, :] ) имеют разную длину. Измерения, все срезы которых имеют одинаковую длину, называются однородными измерениями .
Самое внешнее измерение рваного тензора всегда однородно, поскольку он состоит из одного среза (и, следовательно, нет возможности для разных длин срезов). Остальные размеры могут быть как рваными, так и равномерными. Например, вы можете хранить вложения слов для каждого слова в пакете предложений, используя неоднородный тензор с формой [num_sentences, (num_words), embedding_size] , где круглые скобки вокруг (num_words) указывают, что размерность неоднородная.
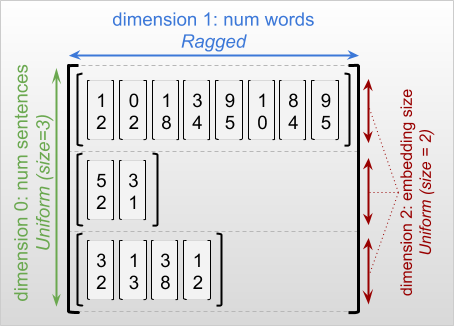
Рваные тензоры могут иметь несколько рваных измерений. Например, вы можете сохранить пакет структурированных текстовых документов, используя тензор с формой [num_documents, (num_paragraphs), (num_sentences), (num_words)] (где снова используются круглые скобки для обозначения неравномерных измерений).
Как и в случае с tf.Tensor , ранг неоднородного тензора — это его общее количество измерений (включая как неоднородные, так и однородные измерения). Потенциально рваный тензор — это значение, которое может быть либо tf.Tensor , либо tf.RaggedTensor .
При описании формы RaggedTensor неравномерные размеры обычно указываются путем заключения их в круглые скобки. Например, как вы видели выше, форма 3D RaggedTensor, которая хранит вложения слов для каждого слова в пакете предложений, может быть записана как [num_sentences, (num_words), embedding_size] .
RaggedTensor.shape возвращает tf.TensorShape для рваного тензора, где рваные измерения имеют размер None :
tf.ragged.constant([["Hi"], ["How", "are", "you"]]).shape
TensorShape([2, None])
Метод tf.RaggedTensor.bounding_shape можно использовать для поиска жесткой ограничивающей формы для данного RaggedTensor :
print(tf.ragged.constant([["Hi"], ["How", "are", "you"]]).bounding_shape())
tf.Tensor([2 3], shape=(2,), dtype=int64)
Рваный против редкого
Неровный тензор не следует рассматривать как разновидность разреженного тензора. В частности, разреженные тензоры являются эффективными кодировками для tf.Tensor , которые моделируют одни и те же данные в компактном формате; но рваный тензор является расширением tf.Tensor , которое моделирует расширенный класс данных. Это различие имеет решающее значение при определении операций:
- Применение операции к разреженному или плотному тензору всегда должно давать один и тот же результат.
- Применение операции к неоднородному или разреженному тензору может дать разные результаты.
В качестве наглядного примера рассмотрим, как операции с массивами, такие как concat , stack и tile , определяются для рваных и разреженных тензоров. Объединение рваных тензоров объединяет каждую строку, чтобы сформировать одну строку с объединенной длиной:

ragged_x = tf.ragged.constant([["John"], ["a", "big", "dog"], ["my", "cat"]])
ragged_y = tf.ragged.constant([["fell", "asleep"], ["barked"], ["is", "fuzzy"]])
print(tf.concat([ragged_x, ragged_y], axis=1))
<tf.RaggedTensor [[b'John', b'fell', b'asleep'], [b'a', b'big', b'dog', b'barked'], [b'my', b'cat', b'is', b'fuzzy']]>
Однако объединение разреженных тензоров эквивалентно объединению соответствующих плотных тензоров, как показано в следующем примере (где Ø указывает пропущенные значения):
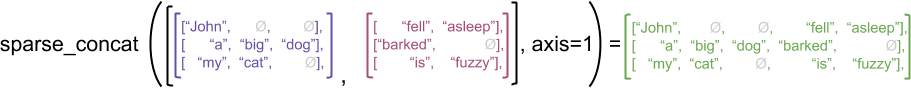
sparse_x = ragged_x.to_sparse()
sparse_y = ragged_y.to_sparse()
sparse_result = tf.sparse.concat(sp_inputs=[sparse_x, sparse_y], axis=1)
print(tf.sparse.to_dense(sparse_result, ''))
tf.Tensor( [[b'John' b'' b'' b'fell' b'asleep'] [b'a' b'big' b'dog' b'barked' b''] [b'my' b'cat' b'' b'is' b'fuzzy']], shape=(3, 5), dtype=string)
В качестве другого примера того, почему это различие важно, рассмотрим определение «среднего значения каждой строки» для такой операции, как tf.reduce_mean . Для неоднородного тензора среднее значение для строки представляет собой сумму значений строки, деленную на ширину строки. Но для разреженного тензора среднее значение для строки представляет собой сумму значений строки, деленную на общую ширину разреженного тензора (которая больше или равна ширине самой длинной строки).
API-интерфейсы TensorFlow
Керас
tf.keras — это высокоуровневый API TensorFlow для создания и обучения моделей глубокого обучения. Рваные тензоры могут быть переданы в качестве входных данных для модели Keras, установив ragged=True в tf.keras.Input или tf.keras.layers.InputLayer . Рваные тензоры также могут передаваться между слоями Keras и возвращаться моделями Keras. В следующем примере показана игрушечная модель LSTM, обученная с использованием неоднородных тензоров.
# Task: predict whether each sentence is a question or not.
sentences = tf.constant(
['What makes you think she is a witch?',
'She turned me into a newt.',
'A newt?',
'Well, I got better.'])
is_question = tf.constant([True, False, True, False])
# Preprocess the input strings.
hash_buckets = 1000
words = tf.strings.split(sentences, ' ')
hashed_words = tf.strings.to_hash_bucket_fast(words, hash_buckets)
# Build the Keras model.
keras_model = tf.keras.Sequential([
tf.keras.layers.Input(shape=[None], dtype=tf.int64, ragged=True),
tf.keras.layers.Embedding(hash_buckets, 16),
tf.keras.layers.LSTM(32, use_bias=False),
tf.keras.layers.Dense(32),
tf.keras.layers.Activation(tf.nn.relu),
tf.keras.layers.Dense(1)
])
keras_model.compile(loss='binary_crossentropy', optimizer='rmsprop')
keras_model.fit(hashed_words, is_question, epochs=5)
print(keras_model.predict(hashed_words))
WARNING:tensorflow:Layer lstm will not use cuDNN kernels since it doesn't meet the criteria. It will use a generic GPU kernel as fallback when running on GPU.
Epoch 1/5
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/framework/indexed_slices.py:449: UserWarning: Converting sparse IndexedSlices(IndexedSlices(indices=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/boolean_mask_1/GatherV2:0", shape=(None,), dtype=int32), values=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/boolean_mask/GatherV2:0", shape=(None, 16), dtype=float32), dense_shape=Tensor("gradient_tape/sequential/lstm/RaggedToTensor/Shape:0", shape=(2,), dtype=int32))) to a dense Tensor of unknown shape. This may consume a large amount of memory.
"shape. This may consume a large amount of memory." % value)
1/1 [==============================] - 2s 2s/step - loss: 3.1269
Epoch 2/5
1/1 [==============================] - 0s 18ms/step - loss: 2.1197
Epoch 3/5
1/1 [==============================] - 0s 19ms/step - loss: 2.0196
Epoch 4/5
1/1 [==============================] - 0s 20ms/step - loss: 1.9371
Epoch 5/5
1/1 [==============================] - 0s 18ms/step - loss: 1.8857
[[0.02800461]
[0.00945962]
[0.02283431]
[0.00252927]]
tf.Пример
tf.Example — стандартная кодировка protobuf для данных TensorFlow. Данные, закодированные с помощью tf.Example часто содержат функции переменной длины. Например, следующий код определяет пакет из четырех сообщений tf.Example с разной длиной функции:
import google.protobuf.text_format as pbtext
def build_tf_example(s):
return pbtext.Merge(s, tf.train.Example()).SerializeToString()
example_batch = [
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["red", "blue"]} } }
feature {key: "lengths" value {int64_list {value: [7]} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["orange"]} } }
feature {key: "lengths" value {int64_list {value: []} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["black", "yellow"]} } }
feature {key: "lengths" value {int64_list {value: [1, 3]} } } }'''),
build_tf_example(r'''
features {
feature {key: "colors" value {bytes_list {value: ["green"]} } }
feature {key: "lengths" value {int64_list {value: [3, 5, 2]} } } }''')]
Вы можете проанализировать эти закодированные данные с помощью tf.io.parse_example , который принимает тензор сериализованных строк и словарь спецификаций функций и возвращает словарь, отображающий имена функций в тензоры. Чтобы прочитать функции переменной длины в рваные тензоры, вы просто используете tf.io.RaggedFeature в словаре спецификации функций:
feature_specification = {
'colors': tf.io.RaggedFeature(tf.string),
'lengths': tf.io.RaggedFeature(tf.int64),
}
feature_tensors = tf.io.parse_example(example_batch, feature_specification)
for name, value in feature_tensors.items():
print("{}={}".format(name, value))
colors=<tf.RaggedTensor [[b'red', b'blue'], [b'orange'], [b'black', b'yellow'], [b'green']]> lengths=<tf.RaggedTensor [[7], [], [1, 3], [3, 5, 2]]>
tf.io.RaggedFeature также можно использовать для чтения объектов с несколькими рваными измерениями. Подробности смотрите в документации по API .
Наборы данных
tf.data — это API, который позволяет создавать сложные конвейеры ввода из простых, повторно используемых частей. Его основная структура данных — tf.data.Dataset , которая представляет собой последовательность элементов, в которой каждый элемент состоит из одного или нескольких компонентов.
# Helper function used to print datasets in the examples below.
def print_dictionary_dataset(dataset):
for i, element in enumerate(dataset):
print("Element {}:".format(i))
for (feature_name, feature_value) in element.items():
print('{:>14} = {}'.format(feature_name, feature_value))
Создание наборов данных с неоднородными тензорами
Наборы данных могут быть построены из неоднородных тензоров с использованием тех же методов, которые используются для их построения из array tf.Tensor или NumPy, таких как Dataset.from_tensor_slices :
dataset = tf.data.Dataset.from_tensor_slices(feature_tensors)
print_dictionary_dataset(dataset)
Element 0:
colors = [b'red' b'blue']
lengths = [7]
Element 1:
colors = [b'orange']
lengths = []
Element 2:
colors = [b'black' b'yellow']
lengths = [1 3]
Element 3:
colors = [b'green']
lengths = [3 5 2]
Пакетирование и разделение наборов данных с неоднородными тензорами
Наборы данных с неравномерными тензорами могут быть объединены в пакеты (которые объединяют n последовательных элементов в один элемент) с использованием метода Dataset.batch .
batched_dataset = dataset.batch(2)
print_dictionary_dataset(batched_dataset)
Element 0:
colors = <tf.RaggedTensor [[b'red', b'blue'], [b'orange']]>
lengths = <tf.RaggedTensor [[7], []]>
Element 1:
colors = <tf.RaggedTensor [[b'black', b'yellow'], [b'green']]>
lengths = <tf.RaggedTensor [[1, 3], [3, 5, 2]]>
И наоборот, пакетный набор данных можно преобразовать в плоский набор данных с помощью Dataset.unbatch .
unbatched_dataset = batched_dataset.unbatch()
print_dictionary_dataset(unbatched_dataset)
Element 0:
colors = [b'red' b'blue']
lengths = [7]
Element 1:
colors = [b'orange']
lengths = []
Element 2:
colors = [b'black' b'yellow']
lengths = [1 3]
Element 3:
colors = [b'green']
lengths = [3 5 2]
Пакетная обработка наборов данных с неравномерными тензорами переменной длины
Если у вас есть набор данных, содержащий тензоры без рваных фрагментов, а длина тензоров различается для разных элементов, вы можете объединить эти тензоры без рваных фрагментов в тензоры из рваных фрагментов, применив преобразование « dense_to_ragged_batch :
non_ragged_dataset = tf.data.Dataset.from_tensor_slices([1, 5, 3, 2, 8])
non_ragged_dataset = non_ragged_dataset.map(tf.range)
batched_non_ragged_dataset = non_ragged_dataset.apply(
tf.data.experimental.dense_to_ragged_batch(2))
for element in batched_non_ragged_dataset:
print(element)
<tf.RaggedTensor [[0], [0, 1, 2, 3, 4]]> <tf.RaggedTensor [[0, 1, 2], [0, 1]]> <tf.RaggedTensor [[0, 1, 2, 3, 4, 5, 6, 7]]>
Преобразование наборов данных с помощью рваных тензоров
Вы также можете создавать или преобразовывать рваные тензоры в наборах данных, используя Dataset.map :
def transform_lengths(features):
return {
'mean_length': tf.math.reduce_mean(features['lengths']),
'length_ranges': tf.ragged.range(features['lengths'])}
transformed_dataset = dataset.map(transform_lengths)
print_dictionary_dataset(transformed_dataset)
Element 0: mean_length = 7 length_ranges = <tf.RaggedTensor [[0, 1, 2, 3, 4, 5, 6]]> Element 1: mean_length = 0 length_ranges = <tf.RaggedTensor []> Element 2: mean_length = 2 length_ranges = <tf.RaggedTensor [[0], [0, 1, 2]]> Element 3: mean_length = 3 length_ranges = <tf.RaggedTensor [[0, 1, 2], [0, 1, 2, 3, 4], [0, 1]]>
tf.функция
tf.function — это декоратор, который предварительно вычисляет графики TensorFlow для функций Python, что может существенно повысить производительность вашего кода TensorFlow. Рваные тензоры можно прозрачно использовать с @tf.function функциями. Например, следующая функция работает как с рваными, так и с обычными тензорами:
@tf.function
def make_palindrome(x, axis):
return tf.concat([x, tf.reverse(x, [axis])], axis)
make_palindrome(tf.constant([[1, 2], [3, 4], [5, 6]]), axis=1)
<tf.Tensor: shape=(3, 4), dtype=int32, numpy=
array([[1, 2, 2, 1],
[3, 4, 4, 3],
[5, 6, 6, 5]], dtype=int32)>
make_palindrome(tf.ragged.constant([[1, 2], [3], [4, 5, 6]]), axis=1)
2021-09-22 20:36:51.018367: W tensorflow/core/grappler/optimizers/loop_optimizer.cc:907] Skipping loop optimization for Merge node with control input: RaggedConcat/assert_equal_1/Assert/AssertGuard/branch_executed/_9 <tf.RaggedTensor [[1, 2, 2, 1], [3, 3], [4, 5, 6, 6, 5, 4]]>
Если вы хотите явно указать input_signature для tf.function , вы можете сделать это с помощью tf.RaggedTensorSpec .
@tf.function(
input_signature=[tf.RaggedTensorSpec(shape=[None, None], dtype=tf.int32)])
def max_and_min(rt):
return (tf.math.reduce_max(rt, axis=-1), tf.math.reduce_min(rt, axis=-1))
max_and_min(tf.ragged.constant([[1, 2], [3], [4, 5, 6]]))
(<tf.Tensor: shape=(3,), dtype=int32, numpy=array([2, 3, 6], dtype=int32)>, <tf.Tensor: shape=(3,), dtype=int32, numpy=array([1, 3, 4], dtype=int32)>)
Конкретные функции
Конкретные функции инкапсулируют отдельные отслеживаемые графы, построенные с помощью tf.function . Рваные тензоры можно прозрачно использовать с конкретными функциями.
@tf.function
def increment(x):
return x + 1
rt = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
cf = increment.get_concrete_function(rt)
print(cf(rt))
<tf.RaggedTensor [[2, 3], [4], [5, 6, 7]]>
Сохраненные модели
SavedModel — это сериализованная программа TensorFlow, включающая как веса, так и вычисления. Он может быть построен из модели Keras или из пользовательской модели. В любом случае неоднородные тензоры можно прозрачно использовать с функциями и методами, определенными в SavedModel.
Пример: сохранение модели Keras
import tempfile
keras_module_path = tempfile.mkdtemp()
tf.saved_model.save(keras_model, keras_module_path)
imported_model = tf.saved_model.load(keras_module_path)
imported_model(hashed_words)
2021-09-22 20:36:52.069689: W tensorflow/python/util/util.cc:348] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
WARNING:absl:Function `_wrapped_model` contains input name(s) args_0 with unsupported characters which will be renamed to args_0_1 in the SavedModel.
INFO:tensorflow:Assets written to: /tmp/tmp114axtt7/assets
INFO:tensorflow:Assets written to: /tmp/tmp114axtt7/assets
<tf.Tensor: shape=(4, 1), dtype=float32, numpy=
array([[0.02800461],
[0.00945962],
[0.02283431],
[0.00252927]], dtype=float32)>
Пример: сохранение пользовательской модели
class CustomModule(tf.Module):
def __init__(self, variable_value):
super(CustomModule, self).__init__()
self.v = tf.Variable(variable_value)
@tf.function
def grow(self, x):
return x * self.v
module = CustomModule(100.0)
# Before saving a custom model, you must ensure that concrete functions are
# built for each input signature that you will need.
module.grow.get_concrete_function(tf.RaggedTensorSpec(shape=[None, None],
dtype=tf.float32))
custom_module_path = tempfile.mkdtemp()
tf.saved_model.save(module, custom_module_path)
imported_model = tf.saved_model.load(custom_module_path)
imported_model.grow(tf.ragged.constant([[1.0, 4.0, 3.0], [2.0]]))
INFO:tensorflow:Assets written to: /tmp/tmpnn4u8dy5/assets INFO:tensorflow:Assets written to: /tmp/tmpnn4u8dy5/assets <tf.RaggedTensor [[100.0, 400.0, 300.0], [200.0]]>
Перегруженные операторы
Класс RaggedTensor перегружает стандартные арифметические операторы Python и операторы сравнения, упрощая выполнение основных поэлементных математических операций:
x = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
y = tf.ragged.constant([[1, 1], [2], [3, 3, 3]])
print(x + y)
<tf.RaggedTensor [[2, 3], [5], [7, 8, 9]]>
Поскольку перегруженные операторы выполняют поэлементные вычисления, входные данные для всех бинарных операций должны иметь одинаковую форму или быть транслируемыми в одну и ту же форму. В простейшем случае вещания один скаляр поэлементно комбинируется с каждым значением в неоднородном тензоре:
x = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
print(x + 3)
<tf.RaggedTensor [[4, 5], [6], [7, 8, 9]]>
Для обсуждения более сложных случаев загляните в раздел « Вещание ».
Рваные тензоры перегружают тот же набор операторов, что и обычные Tensor : унарные операторы - , ~ и abs() ; и бинарные операторы + , - , * , / , // , % , ** , & , | , ^ , == , < , <= , > и >= .
Индексация
Рваные тензоры поддерживают индексирование в стиле Python, включая многомерное индексирование и нарезку. В следующих примерах демонстрируется индексирование рваного тензора с помощью 2D и 3D рваного тензора.
Примеры индексации: 2D рваный тензор
queries = tf.ragged.constant(
[['Who', 'is', 'George', 'Washington'],
['What', 'is', 'the', 'weather', 'tomorrow'],
['Goodnight']])
print(queries[1]) # A single query
tf.Tensor([b'What' b'is' b'the' b'weather' b'tomorrow'], shape=(5,), dtype=string)
print(queries[1, 2]) # A single word
tf.Tensor(b'the', shape=(), dtype=string)
print(queries[1:]) # Everything but the first row
<tf.RaggedTensor [[b'What', b'is', b'the', b'weather', b'tomorrow'], [b'Goodnight']]>
print(queries[:, :3]) # The first 3 words of each query
<tf.RaggedTensor [[b'Who', b'is', b'George'], [b'What', b'is', b'the'], [b'Goodnight']]>
print(queries[:, -2:]) # The last 2 words of each query
<tf.RaggedTensor [[b'George', b'Washington'], [b'weather', b'tomorrow'], [b'Goodnight']]>
Примеры индексации: 3D рваный тензор
rt = tf.ragged.constant([[[1, 2, 3], [4]],
[[5], [], [6]],
[[7]],
[[8, 9], [10]]])
print(rt[1]) # Second row (2D RaggedTensor)
<tf.RaggedTensor [[5], [], [6]]>
print(rt[3, 0]) # First element of fourth row (1D Tensor)
tf.Tensor([8 9], shape=(2,), dtype=int32)
print(rt[:, 1:3]) # Items 1-3 of each row (3D RaggedTensor)
<tf.RaggedTensor [[[4]], [[], [6]], [], [[10]]]>
print(rt[:, -1:]) # Last item of each row (3D RaggedTensor)
<tf.RaggedTensor [[[4]], [[6]], [[7]], [[10]]]>
RaggedTensor поддерживает многомерное индексирование и нарезку с одним ограничением: индексирование в неравномерном измерении не допускается. Этот случай проблематичен, поскольку указанное значение может существовать в одних строках, но не существовать в других. В таких случаях не очевидно, следует ли вам (1) вызывать IndexError ; (2) использовать значение по умолчанию; или (3) пропустить это значение и вернуть тензор с меньшим количеством строк, чем вы начали. Следуя руководящим принципам Python («Перед лицом двусмысленности, откажитесь от искушения угадать»), эта операция в настоящее время запрещена.
Преобразование типа тензора
Класс RaggedTensor определяет методы, которые можно использовать для преобразования между RaggedTensor s и tf.Tensor s или tf.SparseTensors :
ragged_sentences = tf.ragged.constant([
['Hi'], ['Welcome', 'to', 'the', 'fair'], ['Have', 'fun']])
# RaggedTensor -> Tensor
print(ragged_sentences.to_tensor(default_value='', shape=[None, 10]))
tf.Tensor( [[b'Hi' b'' b'' b'' b'' b'' b'' b'' b'' b''] [b'Welcome' b'to' b'the' b'fair' b'' b'' b'' b'' b'' b''] [b'Have' b'fun' b'' b'' b'' b'' b'' b'' b'' b'']], shape=(3, 10), dtype=string)
# Tensor -> RaggedTensor
x = [[1, 3, -1, -1], [2, -1, -1, -1], [4, 5, 8, 9]]
print(tf.RaggedTensor.from_tensor(x, padding=-1))
<tf.RaggedTensor [[1, 3], [2], [4, 5, 8, 9]]>
#RaggedTensor -> SparseTensor
print(ragged_sentences.to_sparse())
SparseTensor(indices=tf.Tensor( [[0 0] [1 0] [1 1] [1 2] [1 3] [2 0] [2 1]], shape=(7, 2), dtype=int64), values=tf.Tensor([b'Hi' b'Welcome' b'to' b'the' b'fair' b'Have' b'fun'], shape=(7,), dtype=string), dense_shape=tf.Tensor([3 4], shape=(2,), dtype=int64))
# SparseTensor -> RaggedTensor
st = tf.SparseTensor(indices=[[0, 0], [2, 0], [2, 1]],
values=['a', 'b', 'c'],
dense_shape=[3, 3])
print(tf.RaggedTensor.from_sparse(st))
<tf.RaggedTensor [[b'a'], [], [b'b', b'c']]>
Оценка рваных тензоров
Чтобы получить доступ к значениям в неоднородном тензоре, вы можете:
- Используйте
tf.RaggedTensor.to_listдля преобразования неоднородного тензора во вложенный список Python. - Используйте
tf.RaggedTensor.numpyдля преобразования неоднородного тензора в массив NumPy, значения которого являются вложенными массивами NumPy. - Разложите неоднородный тензор на его компоненты, используя свойства
tf.RaggedTensor.valuesиtf.RaggedTensor.row_splitsили методы разделения строк, такие какtf.RaggedTensor.row_lengthsиtf.RaggedTensor.value_rowids. - Используйте индексацию Python для выбора значений из неоднородного тензора.
rt = tf.ragged.constant([[1, 2], [3, 4, 5], [6], [], [7]])
print("Python list:", rt.to_list())
print("NumPy array:", rt.numpy())
print("Values:", rt.values.numpy())
print("Splits:", rt.row_splits.numpy())
print("Indexed value:", rt[1].numpy())
Python list: [[1, 2], [3, 4, 5], [6], [], [7]] NumPy array: [array([1, 2], dtype=int32) array([3, 4, 5], dtype=int32) array([6], dtype=int32) array([], dtype=int32) array([7], dtype=int32)] Values: [1 2 3 4 5 6 7] Splits: [0 2 5 6 6 7] Indexed value: [3 4 5] /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/ops/ragged/ragged_tensor.py:2063: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray return np.array(rows)
Вещание
Вещание — это процесс создания тензоров разной формы, имеющих совместимые формы для поэлементных операций. Для получения дополнительной информации о вещании см.:
Основные шаги для передачи двух входных данных x и y для получения совместимых форм:
Если
xиyне имеют одинакового количества измерений, то добавляйте внешние измерения (с размером 1), пока они не станут одинаковыми.Для каждого измерения, где
xиyимеют разные размеры:
- Если
xилиyимеют размер1в измеренииd, затем повторите его значения в измеренииd, чтобы соответствовать размеру другого входа. - В противном случае создайте исключение (
xиyнесовместимы с широковещательной передачей).
Где размер тензора в едином измерении представляет собой одно число (размер срезов в этом измерении); а размер тензора в рваном измерении — это список длин срезов (для всех срезов в этом измерении).
Примеры вещания
# x (2D ragged): 2 x (num_rows)
# y (scalar)
# result (2D ragged): 2 x (num_rows)
x = tf.ragged.constant([[1, 2], [3]])
y = 3
print(x + y)
<tf.RaggedTensor [[4, 5], [6]]>
# x (2d ragged): 3 x (num_rows)
# y (2d tensor): 3 x 1
# Result (2d ragged): 3 x (num_rows)
x = tf.ragged.constant(
[[10, 87, 12],
[19, 53],
[12, 32]])
y = [[1000], [2000], [3000]]
print(x + y)
<tf.RaggedTensor [[1010, 1087, 1012], [2019, 2053], [3012, 3032]]>
# x (3d ragged): 2 x (r1) x 2
# y (2d ragged): 1 x 1
# Result (3d ragged): 2 x (r1) x 2
x = tf.ragged.constant(
[[[1, 2], [3, 4], [5, 6]],
[[7, 8]]],
ragged_rank=1)
y = tf.constant([[10]])
print(x + y)
<tf.RaggedTensor [[[11, 12], [13, 14], [15, 16]], [[17, 18]]]>
# x (3d ragged): 2 x (r1) x (r2) x 1
# y (1d tensor): 3
# Result (3d ragged): 2 x (r1) x (r2) x 3
x = tf.ragged.constant(
[
[
[[1], [2]],
[],
[[3]],
[[4]],
],
[
[[5], [6]],
[[7]]
]
],
ragged_rank=2)
y = tf.constant([10, 20, 30])
print(x + y)
<tf.RaggedTensor [[[[11, 21, 31], [12, 22, 32]], [], [[13, 23, 33]], [[14, 24, 34]]], [[[15, 25, 35], [16, 26, 36]], [[17, 27, 37]]]]>
Вот несколько примеров фигур, которые не транслируются:
# x (2d ragged): 3 x (r1)
# y (2d tensor): 3 x 4 # trailing dimensions do not match
x = tf.ragged.constant([[1, 2], [3, 4, 5, 6], [7]])
y = tf.constant([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 1 b'lengths=' 4 b'dim_size=' 2, 4, 1
# x (2d ragged): 3 x (r1)
# y (2d ragged): 3 x (r2) # ragged dimensions do not match.
x = tf.ragged.constant([[1, 2, 3], [4], [5, 6]])
y = tf.ragged.constant([[10, 20], [30, 40], [50]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 1 b'lengths=' 2, 2, 1 b'dim_size=' 3, 1, 2
# x (3d ragged): 3 x (r1) x 2
# y (3d ragged): 3 x (r1) x 3 # trailing dimensions do not match
x = tf.ragged.constant([[[1, 2], [3, 4], [5, 6]],
[[7, 8], [9, 10]]])
y = tf.ragged.constant([[[1, 2, 0], [3, 4, 0], [5, 6, 0]],
[[7, 8, 0], [9, 10, 0]]])
try:
x + y
except tf.errors.InvalidArgumentError as exception:
print(exception)
Expected 'tf.Tensor(False, shape=(), dtype=bool)' to be true. Summarized data: b'Unable to broadcast: dimension size mismatch in dimension' 2 b'lengths=' 3, 3, 3, 3, 3 b'dim_size=' 2, 2, 2, 2, 2
Кодировка RaggedTensor
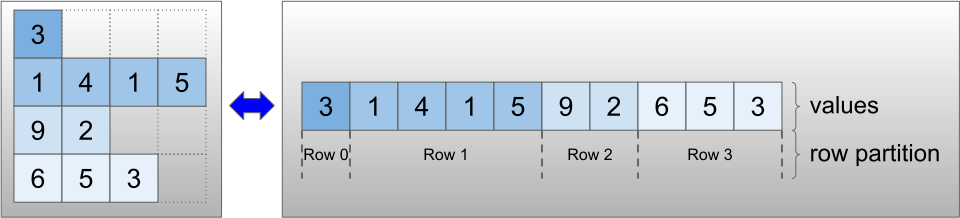
Рваные тензоры кодируются с использованием класса RaggedTensor . Внутри каждый RaggedTensor состоит из:
- Тензор
values, который объединяет строки переменной длины в плоский список. -
row_partition, который указывает, как эти сглаженные значения делятся на строки.
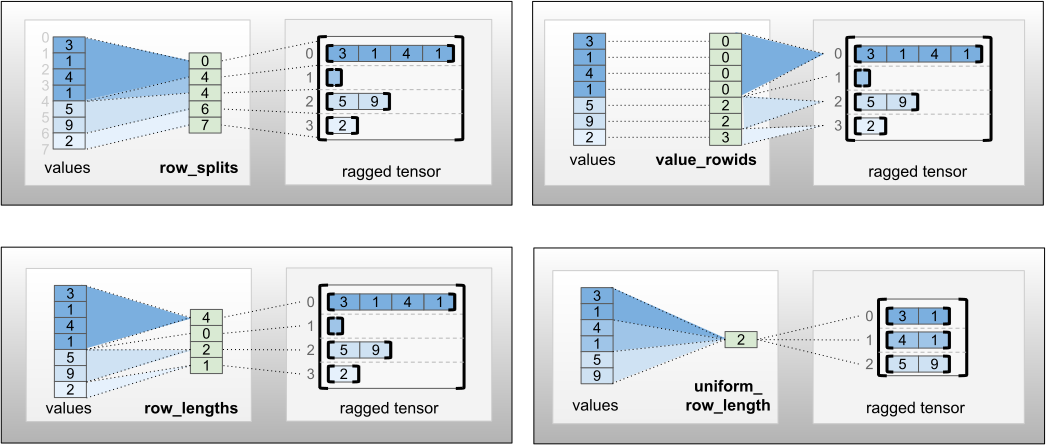
Раздел row_partition можно хранить в четырех различных кодировках:
-
row_splits— целочисленный вектор, определяющий точки разделения строк. -
value_rowids— целочисленный вектор, указывающий индекс строки для каждого значения. -
row_lengths— целочисленный вектор, определяющий длину каждой строки. -
uniform_row_length— целочисленный скаляр, указывающий единую длину для всех строк.
Целочисленные скалярные nrows также могут быть включены в кодировку row_partition для учета пустых завершающих строк с value_rowids или пустых строк uniform_row_length .
rt = tf.RaggedTensor.from_row_splits(
values=[3, 1, 4, 1, 5, 9, 2],
row_splits=[0, 4, 4, 6, 7])
print(rt)
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
Выбор того, какую кодировку использовать для разделов строк, управляется внутренне с помощью неоднородных тензоров для повышения эффективности в некоторых контекстах. В частности, некоторые из преимуществ и недостатков различных схем разбиения строк:
- Эффективное индексирование : кодировка
row_splitsобеспечивает индексирование с постоянным временем и нарезку на неоднородные тензоры. - Эффективная конкатенация : кодировка
row_lengthsболее эффективна при конкатенации неоднородных тензоров, поскольку длины строк не изменяются при конкатенации двух тензоров. - Небольшой размер кодировки : кодировка
value_rowidsболее эффективна при хранении рваных тензоров с большим количеством пустых строк, поскольку размер тензора зависит только от общего количества значений. С другой стороны, кодировкиrow_splitsиrow_lengthsболее эффективны при хранении рваных тензоров с более длинными строками, поскольку для каждой строки требуется только одно скалярное значение. - Совместимость : схема
value_rowidsсоответствует формату сегментации , используемому операциями, напримерtf.segment_sum. Схемаrow_limitsсоответствует формату, используемому такими операциями, какtf.sequence_mask. - Равномерные размеры : как обсуждается ниже,
uniform_row_lengthиспользуется для кодирования неравномерных тензоров с однородными размерами.
Несколько неравномерных измерений
Неровный тензор с несколькими неоднородными измерениями кодируется с помощью вложенного RaggedTensor для тензора values . Каждый вложенный RaggedTensor добавляет одно рваное измерение.
![]()
rt = tf.RaggedTensor.from_row_splits(
values=tf.RaggedTensor.from_row_splits(
values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
row_splits=[0, 3, 3, 5, 9, 10]),
row_splits=[0, 1, 1, 5])
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
<tf.RaggedTensor [[[10, 11, 12]], [], [[], [13, 14], [15, 16, 17, 18], [19]]]> Shape: (3, None, None) Number of partitioned dimensions: 2
Фабричная функция tf.RaggedTensor.from_nested_row_splits может использоваться для создания RaggedTensor с несколькими рваными измерениями напрямую, предоставляя список тензоров row_splits :
rt = tf.RaggedTensor.from_nested_row_splits(
flat_values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
nested_row_splits=([0, 1, 1, 5], [0, 3, 3, 5, 9, 10]))
print(rt)
<tf.RaggedTensor [[[10, 11, 12]], [], [[], [13, 14], [15, 16, 17, 18], [19]]]>
Рваный ранг и плоские значения
Неоднородный ранг неоднородного тензора — это количество раз, когда базовый тензор values был разделен (т. е. глубина вложенности объектов RaggedTensor ). Тензор самых внутренних values известен как flat_values . В следующем примере conversations =3, а flat_values — это одномерный Tensor с 24 строками:
# shape = [batch, (paragraph), (sentence), (word)]
conversations = tf.ragged.constant(
[[[["I", "like", "ragged", "tensors."]],
[["Oh", "yeah?"], ["What", "can", "you", "use", "them", "for?"]],
[["Processing", "variable", "length", "data!"]]],
[[["I", "like", "cheese."], ["Do", "you?"]],
[["Yes."], ["I", "do."]]]])
conversations.shape
TensorShape([2, None, None, None])
assert conversations.ragged_rank == len(conversations.nested_row_splits)
conversations.ragged_rank # Number of partitioned dimensions.
3
conversations.flat_values.numpy()
array([b'I', b'like', b'ragged', b'tensors.', b'Oh', b'yeah?', b'What',
b'can', b'you', b'use', b'them', b'for?', b'Processing',
b'variable', b'length', b'data!', b'I', b'like', b'cheese.', b'Do',
b'you?', b'Yes.', b'I', b'do.'], dtype=object)
Единые внутренние размеры
Рваные тензоры с однородными внутренними размерами кодируются с помощью многомерного tf.Tensor для flat_values (т. е. самых внутренних values ).
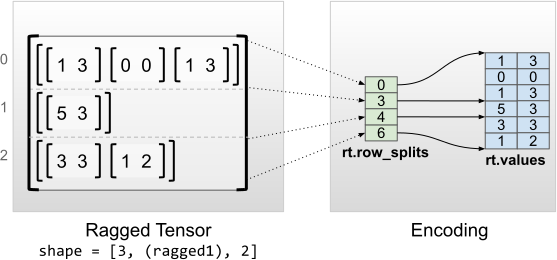
rt = tf.RaggedTensor.from_row_splits(
values=[[1, 3], [0, 0], [1, 3], [5, 3], [3, 3], [1, 2]],
row_splits=[0, 3, 4, 6])
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
print("Flat values shape: {}".format(rt.flat_values.shape))
print("Flat values:\n{}".format(rt.flat_values))
<tf.RaggedTensor [[[1, 3], [0, 0], [1, 3]], [[5, 3]], [[3, 3], [1, 2]]]> Shape: (3, None, 2) Number of partitioned dimensions: 1 Flat values shape: (6, 2) Flat values: [[1 3] [0 0] [1 3] [5 3] [3 3] [1 2]]
Единые не внутренние размеры
Рваные тензоры с равномерными невнутренними измерениями кодируются путем разделения строк с помощью uniform_row_length .
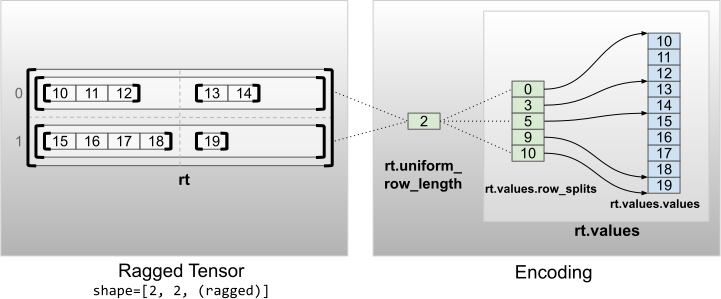
rt = tf.RaggedTensor.from_uniform_row_length(
values=tf.RaggedTensor.from_row_splits(
values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
row_splits=[0, 3, 5, 9, 10]),
uniform_row_length=2)
print(rt)
print("Shape: {}".format(rt.shape))
print("Number of partitioned dimensions: {}".format(rt.ragged_rank))
<tf.RaggedTensor [[[10, 11, 12], [13, 14]], [[15, 16, 17, 18], [19]]]> Shape: (2, 2, None) Number of partitioned dimensions: 2