
| |
 GitHub에서 보기 GitHub에서 보기 |
|
이 노트북은 Universal Sentence Encoder에 액세스하고 이를 문장 유사성 및 문장 분류 작업에 사용하는 방법을 보여줍니다.
Universal Sentence Encoder를 사용하면 기존에 개별 단어에 대한 임베딩을 조회하는 것처럼 쉽게 문장 수준 임베딩을 얻을 수 있습니다. 그러면 문장 임베딩을 간단히 사용하여 문장 수준의 의미론적 유사성을 계산할 수 있을 뿐만 아니라 감독되지 않은 더 적은 훈련 데이터를 사용하여 다운스트림 분류 작업의 성능을 높일 수 있습니다.
설정
이 섹션에서는 TF 허브의 Universal Sentence Encoder에 액세스하기 위한 환경을 설정하고 인코더를 단어, 문장 및 단락에 적용하는 예를 제공합니다.
%%capture
!pip3 install seaborn
Tensorflow 설치에 대한 자세한 내용은 https://www.tensorflow.org/install/에서 찾을 수 있습니다.
Load the Universal Sentence Encoder's TF Hub module
from absl import logging
import tensorflow as tf
import tensorflow_hub as hub
import matplotlib.pyplot as plt
import numpy as np
import os
import pandas as pd
import re
import seaborn as sns
module_url = "https://tfhub.dev/google/universal-sentence-encoder/4"
model = hub.load(module_url)
print ("module %s loaded" % module_url)
def embed(input):
return model(input)
2022-12-14 21:24:27.591064: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory 2022-12-14 21:24:27.591163: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory 2022-12-14 21:24:27.591174: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly. module https://tfhub.dev/google/universal-sentence-encoder/4 loaded
Compute a representation for each message, showing various lengths supported.
word = "Elephant"
sentence = "I am a sentence for which I would like to get its embedding."
paragraph = (
"Universal Sentence Encoder embeddings also support short paragraphs. "
"There is no hard limit on how long the paragraph is. Roughly, the longer "
"the more 'diluted' the embedding will be.")
messages = [word, sentence, paragraph]
# Reduce logging output.
logging.set_verbosity(logging.ERROR)
message_embeddings = embed(messages)
for i, message_embedding in enumerate(np.array(message_embeddings).tolist()):
print("Message: {}".format(messages[i]))
print("Embedding size: {}".format(len(message_embedding)))
message_embedding_snippet = ", ".join(
(str(x) for x in message_embedding[:3]))
print("Embedding: [{}, ...]\n".format(message_embedding_snippet))
Message: Elephant Embedding size: 512 Embedding: [0.008344466798007488, 0.00048083445290103555, 0.06595246493816376, ...] Message: I am a sentence for which I would like to get its embedding. Embedding size: 512 Embedding: [0.050808608531951904, -0.01652432791888714, 0.015737827867269516, ...] Message: Universal Sentence Encoder embeddings also support short paragraphs. There is no hard limit on how long the paragraph is. Roughly, the longer the more 'diluted' the embedding will be. Embedding size: 512 Embedding: [-0.028332678601145744, -0.055862151086330414, -0.012941485270857811, ...]
의미론적 텍스트 유사성 작업 예
Universal Sentence Encoder에 의해 생성된 임베딩은 대략적으로 정규화됩니다. 두 문장의 의미론적 유사성은 인코딩의 내적으로 간편하게 계산될 수 있습니다.
def plot_similarity(labels, features, rotation):
corr = np.inner(features, features)
sns.set(font_scale=1.2)
g = sns.heatmap(
corr,
xticklabels=labels,
yticklabels=labels,
vmin=0,
vmax=1,
cmap="YlOrRd")
g.set_xticklabels(labels, rotation=rotation)
g.set_title("Semantic Textual Similarity")
def run_and_plot(messages_):
message_embeddings_ = embed(messages_)
plot_similarity(messages_, message_embeddings_, 90)
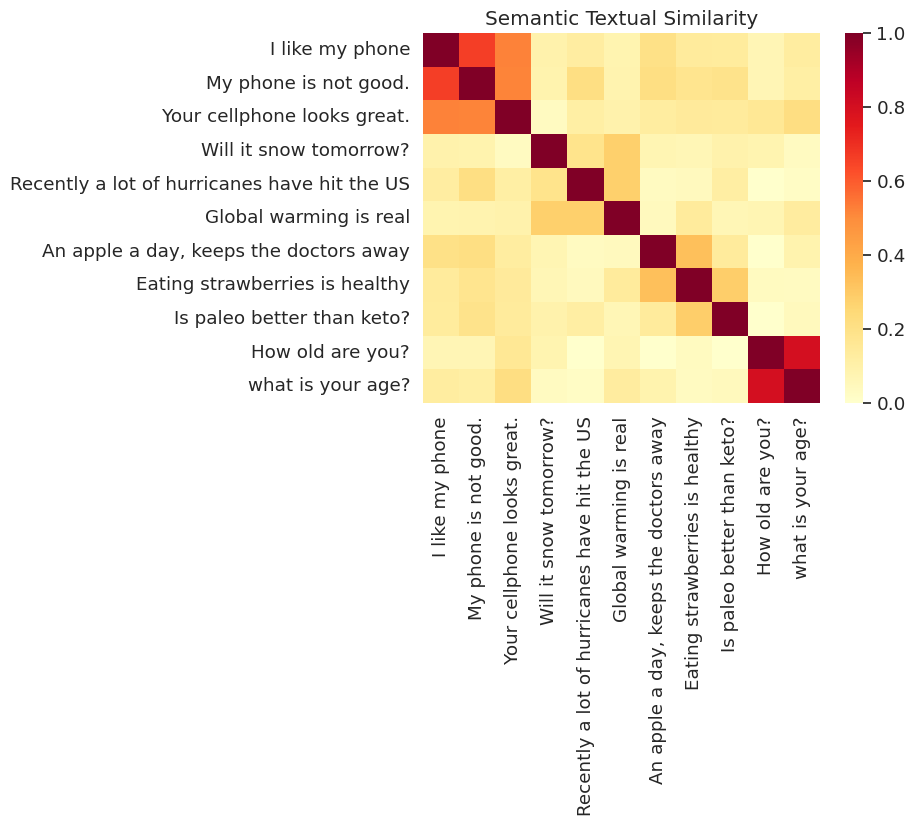
시각화된 유사성
여기서는 히트 맵으로 유사성을 나타냅니다. 최종 그래프는 9x9 행렬이며, 각 항 [i, j]는 문장 i 및 j에 대한 인코딩의 내적을 바탕으로 색상이 지정됩니다.
messages = [
# Smartphones
"I like my phone",
"My phone is not good.",
"Your cellphone looks great.",
# Weather
"Will it snow tomorrow?",
"Recently a lot of hurricanes have hit the US",
"Global warming is real",
# Food and health
"An apple a day, keeps the doctors away",
"Eating strawberries is healthy",
"Is paleo better than keto?",
# Asking about age
"How old are you?",
"what is your age?",
]
run_and_plot(messages)
평가: 의미론적 텍스트 유사성(STS) 벤치마크
STS 벤치마크는 문장 임베딩을 사용하여 계산된 유사성 점수가 사람의 판단과 일치하는 정도에 대한 내재적 평가를 제공합니다. 벤치마크를 위해 시스템이 다양한 문장 쌍 선택에 대한 유사성 점수를 반환해야 합니다. 그런 다음 Pearson 상관 관계를 사용하여 사람의 판단에 대한 머신 유사성 점수의 품질을 평가합니다.
데이터 다운로드하기
import pandas
import scipy
import math
import csv
sts_dataset = tf.keras.utils.get_file(
fname="Stsbenchmark.tar.gz",
origin="http://ixa2.si.ehu.es/stswiki/images/4/48/Stsbenchmark.tar.gz",
extract=True)
sts_dev = pandas.read_table(
os.path.join(os.path.dirname(sts_dataset), "stsbenchmark", "sts-dev.csv"),
error_bad_lines=False,
skip_blank_lines=True,
usecols=[4, 5, 6],
names=["sim", "sent_1", "sent_2"])
sts_test = pandas.read_table(
os.path.join(
os.path.dirname(sts_dataset), "stsbenchmark", "sts-test.csv"),
error_bad_lines=False,
quoting=csv.QUOTE_NONE,
skip_blank_lines=True,
usecols=[4, 5, 6],
names=["sim", "sent_1", "sent_2"])
# cleanup some NaN values in sts_dev
sts_dev = sts_dev[[isinstance(s, str) for s in sts_dev['sent_2']]]
/tmpfs/tmp/ipykernel_75608/543224606.py:10: FutureWarning: The error_bad_lines argument has been deprecated and will be removed in a future version. Use on_bad_lines in the future. sts_dev = pandas.read_table( /tmpfs/tmp/ipykernel_75608/543224606.py:16: FutureWarning: The error_bad_lines argument has been deprecated and will be removed in a future version. Use on_bad_lines in the future. sts_test = pandas.read_table(
문장 임베딩 평가하기
sts_data = sts_dev
def run_sts_benchmark(batch):
sts_encode1 = tf.nn.l2_normalize(embed(tf.constant(batch['sent_1'].tolist())), axis=1)
sts_encode2 = tf.nn.l2_normalize(embed(tf.constant(batch['sent_2'].tolist())), axis=1)
cosine_similarities = tf.reduce_sum(tf.multiply(sts_encode1, sts_encode2), axis=1)
clip_cosine_similarities = tf.clip_by_value(cosine_similarities, -1.0, 1.0)
scores = 1.0 - tf.acos(clip_cosine_similarities) / math.pi
"""Returns the similarity scores"""
return scores
dev_scores = sts_data['sim'].tolist()
scores = []
for batch in np.array_split(sts_data, 10):
scores.extend(run_sts_benchmark(batch))
pearson_correlation = scipy.stats.pearsonr(scores, dev_scores)
print('Pearson correlation coefficient = {0}\np-value = {1}'.format(
pearson_correlation[0], pearson_correlation[1]))
Pearson correlation coefficient = 0.803639689922767 p-value = 0.0