
시작하기
TensorFlow Hub는 어디서나 미세 조정 및 배포 가능한 선행 학습된 모델의 포괄적인 저장소입니다. tensorflow_hub 라이브러리를 사용하여 학습된 최신 모델을 최소한의 코드로 다운로드합니다.
다음 튜토리얼을 사용하면 필요에 따라 TF Hub의 모델을 사용하고 적용할 수 있습니다. 대화형 튜토리얼을 통해 변경사항에 따라 수정하여 실행할 수 있습니다. 대화형 튜토리얼 상단의 Google Colab에서 실행 버튼을 클릭하여 직접 조작해 보세요.
초보자용
머신러닝과 TensorFlow에 익숙하지 않은 경우 먼저 이미지 및 텍스트를 분류하는 방법에 관한 개요를 확인하거나, 이미지에서 객체를 감지하거나, 유명한 예술작품처럼 나만의 그림을 스타일링하여 시작할 수 있습니다.

이미지 분류
사전 학습된 이미지 분류기를 기반으로 Keras 모델을 빌드하여 꽃을 구분합니다.
BERT로 텍스트 분류
BERT를 사용하여 텍스트 분류 감정 분석 작업을 처리하는 Keras 모델을 빌드합니다.스타일 전이
신경망이 피카소, 반 고흐의 스타일이나 나만의 스타일로 이미지를 다시 그리도록 합니다.
객체 감지
FasterRCNN 또는 SSD와 같은 모델을 사용하여 이미지에서 객체를 감지합니다.숙련된 개발자의 경우
TensorFlow Hub에서 NLP, 이미지, 오디오, 동영상 모델을 사용하는 방법을 설명하는 고급 튜토리얼을 확인하세요.
NLP 튜토리얼
TensorFlow Hub의 모델을 사용하여 일반적인 NLP 작업을 처리합니다. 왼쪽 탐색에서 사용 가능한 NLP 튜토리얼을 모두 확인하세요.
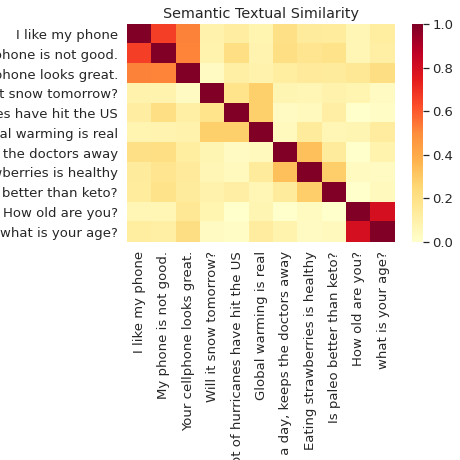
의미론적 유사도
Universal Sentence Encoder로 문장을 분류하고 의미론적으로 비교합니다.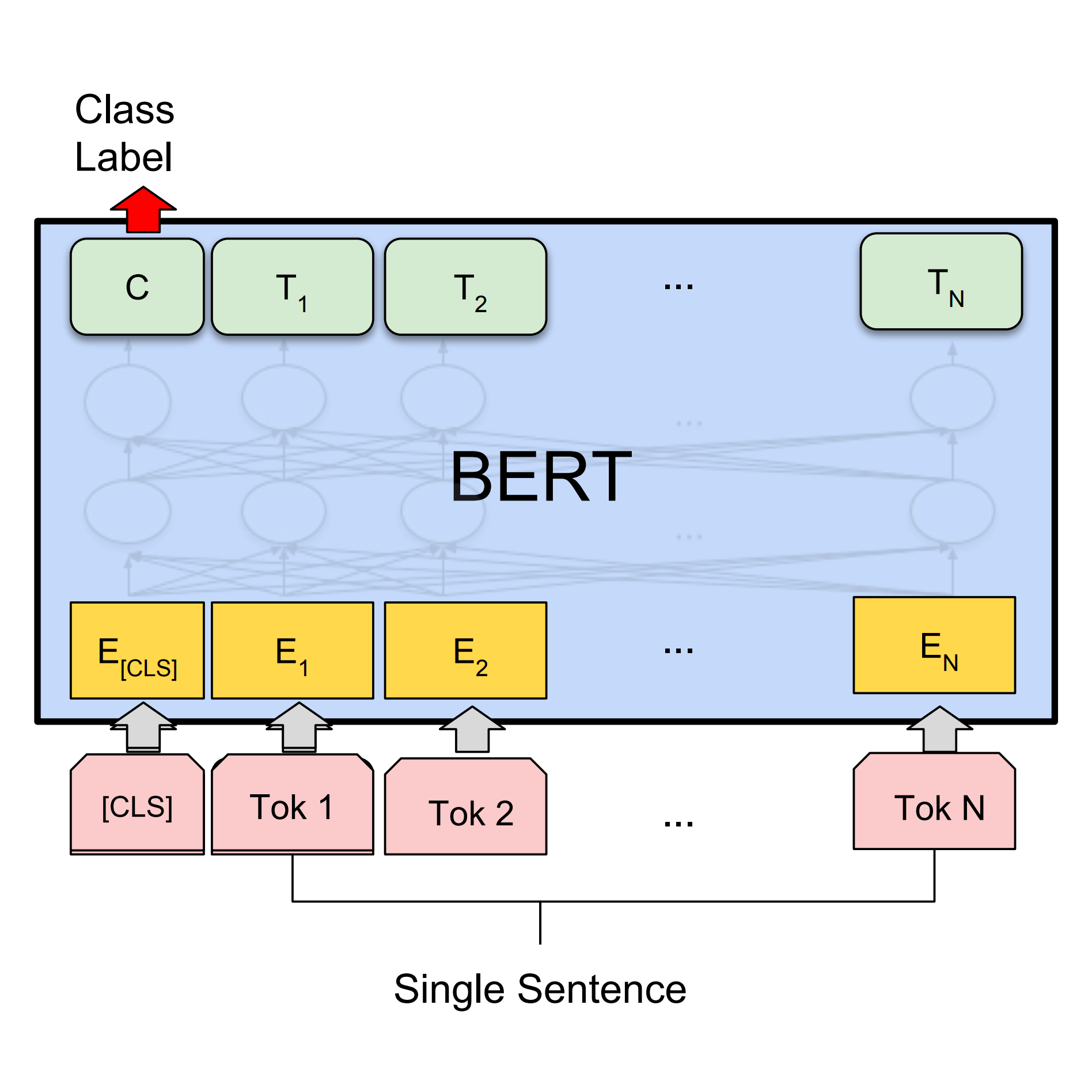
TPU에서의 BERT
BERT를 사용하여 TPU에서 실행 중인 GLUE 벤치마크 작업을 처리합니다.다국어 Universal Sentence Encoder Q&A
다국어 Universal Sentence Encoder Q&A 모델을 사용하여 SQuAD 데이터 세트에서 교차 언어 질문에 답변합니다.이미지 튜토리얼
GAN, 초해상도 모델 등을 사용하는 방법을 알아보세요. 왼쪽 탐색에서 사용 가능한 이미지 튜토리얼을 모두 확인하세요.

이미지 생성을 위한 GAN
GAN을 사용하여 인공적인 얼굴을 생성하고 얼굴 간에 보간 처리합니다.
초해상도
다운샘플링된 이미지의 해상도를 향상합니다.
이미지 광고 확장
특정 이미지의 마스크된 부분을 채우세요.오디오 튜토리얼
학습된 모델을 음조 인식, 음성 분류와 같은 오디오 데이터에 사용하는 방법을 설명하는 튜토리얼입니다.

동영상 튜토리얼
동영상 데이터에 관해 학습된 ML 모델을 동작 인식, 동영상 보간 등에 사용해 보세요.

행동 인식
확장된 3D ConvNet 모델을 사용하여 동영상에서 400개의 행동 중 하나를 감지합니다.
동영상 보간 유형
3D 컨볼루션을 통한 인비트위닝을 사용하여 동영상 프레임 간에 보간 처리합니다.