
 GitHub에서 소스 보기 GitHub에서 소스 보기 |
TF-허브는 재사용 가능한 리소스, 특히 사전 훈련된 모듈 형태로 머신러닝에 대한 전문 지식을 공유하는 플랫폼입니다. 이 튜토리얼에서는 TF-허브 텍스트 임베딩 모듈을 사용하여 합리적인 기준 정확성으로 간단한 감정 분류자를 훈련합니다. 그런 다음 Kaggle에 예측을 제출합니다.
TF-허브를 사용한 텍스트 분류에 대한 자세한 튜토리얼과 정확성 향상을 위한 추가 단계는 TF-허브를 이용한 텍스트 분류를 살펴보세요.
설정
pip install -q kaggleimport tensorflow as tf
import tensorflow_hub as hub
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
import zipfile
from sklearn import model_selection
2022-12-14 20:31:36.899820: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory 2022-12-14 20:31:36.899919: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory 2022-12-14 20:31:36.899928: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
이 튜토리얼에서는 Kaggle의 데이터세트를 사용하기 때문에 Kaggle 계정에 대한 API 토큰을 만들고 Colab 환경에 토큰을 업로드해야 합니다.
import os
import pathlib
# Upload the API token.
def get_kaggle():
try:
import kaggle
return kaggle
except OSError:
pass
token_file = pathlib.Path("~/.kaggle/kaggle.json").expanduser()
token_file.parent.mkdir(exist_ok=True, parents=True)
try:
from google.colab import files
except ImportError:
raise ValueError("Could not find kaggle token.")
uploaded = files.upload()
token_content = uploaded.get('kaggle.json', None)
if token_content:
token_file.write_bytes(token_content)
token_file.chmod(0o600)
else:
raise ValueError('Need a file named "kaggle.json"')
import kaggle
return kaggle
kaggle = get_kaggle()
시작하기
데이터
Kaggle의 영화 리뷰에 대한 감정 분석 작업을 해결해 보려고 합니다. 데이터세트는 Rotten Tomatoes 영화 리뷰의 구문론적 하위 문구로 구성됩니다. 여기서 해야 할 작업은 문구에 1에서 5까지의 척도로 부정적 또는 긍정적 레이블을 지정하는 것입니다.
API를 사용하여 데이터를 다운로드하려면 먼저 경쟁 규칙을 수락해야 합니다.
SENTIMENT_LABELS = [
"negative", "somewhat negative", "neutral", "somewhat positive", "positive"
]
# Add a column with readable values representing the sentiment.
def add_readable_labels_column(df, sentiment_value_column):
df["SentimentLabel"] = df[sentiment_value_column].replace(
range(5), SENTIMENT_LABELS)
# Download data from Kaggle and create a DataFrame.
def load_data_from_zip(path):
with zipfile.ZipFile(path, "r") as zip_ref:
name = zip_ref.namelist()[0]
with zip_ref.open(name) as zf:
return pd.read_csv(zf, sep="\t", index_col=0)
# The data does not come with a validation set so we'll create one from the
# training set.
def get_data(competition, train_file, test_file, validation_set_ratio=0.1):
data_path = pathlib.Path("data")
kaggle.api.competition_download_files(competition, data_path)
competition_path = (data_path/competition)
competition_path.mkdir(exist_ok=True, parents=True)
competition_zip_path = competition_path.with_suffix(".zip")
with zipfile.ZipFile(competition_zip_path, "r") as zip_ref:
zip_ref.extractall(competition_path)
train_df = load_data_from_zip(competition_path/train_file)
test_df = load_data_from_zip(competition_path/test_file)
# Add a human readable label.
add_readable_labels_column(train_df, "Sentiment")
# We split by sentence ids, because we don't want to have phrases belonging
# to the same sentence in both training and validation set.
train_indices, validation_indices = model_selection.train_test_split(
np.unique(train_df["SentenceId"]),
test_size=validation_set_ratio,
random_state=0)
validation_df = train_df[train_df["SentenceId"].isin(validation_indices)]
train_df = train_df[train_df["SentenceId"].isin(train_indices)]
print("Split the training data into %d training and %d validation examples." %
(len(train_df), len(validation_df)))
return train_df, validation_df, test_df
train_df, validation_df, test_df = get_data(
"sentiment-analysis-on-movie-reviews",
"train.tsv.zip", "test.tsv.zip")
Split the training data into 140315 training and 15745 validation examples.
참고: 이 경쟁에서 주어진 과제는 전체 리뷰를 평가하는 것이 아니라 리뷰 내의 개별 문구를 평가하는 것입니다. 이것은 훨씬 더 어려운 작업입니다.
train_df.head(20)
모델 훈련하기
참고: 이 작업을 회귀로 모델링할 수도 있습니다(TF-허브를 사용한 텍스트 분류 참조).
class MyModel(tf.keras.Model):
def __init__(self, hub_url):
super().__init__()
self.hub_url = hub_url
self.embed = hub.load(self.hub_url).signatures['default']
self.sequential = tf.keras.Sequential([
tf.keras.layers.Dense(500),
tf.keras.layers.Dense(100),
tf.keras.layers.Dense(5),
])
def call(self, inputs):
phrases = inputs['Phrase'][:,0]
embedding = 5*self.embed(phrases)['default']
return self.sequential(embedding)
def get_config(self):
return {"hub_url":self.hub_url}
model = MyModel("https://tfhub.dev/google/nnlm-en-dim128/1")
model.compile(
loss = tf.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.optimizers.Adam(),
metrics = [tf.keras.metrics.SparseCategoricalAccuracy(name="accuracy")])
history = model.fit(x=dict(train_df), y=train_df['Sentiment'],
validation_data=(dict(validation_df), validation_df['Sentiment']),
epochs = 25)
Epoch 1/25 4385/4385 [==============================] - 15s 3ms/step - loss: 1.0237 - accuracy: 0.5863 - val_loss: 0.9914 - val_accuracy: 0.5903 Epoch 2/25 4385/4385 [==============================] - 13s 3ms/step - loss: 1.0000 - accuracy: 0.5937 - val_loss: 0.9905 - val_accuracy: 0.5897 Epoch 3/25 4385/4385 [==============================] - 13s 3ms/step - loss: 0.9949 - accuracy: 0.5967 - val_loss: 0.9798 - val_accuracy: 0.6018 Epoch 4/25 4385/4385 [==============================] - 13s 3ms/step - loss: 0.9931 - accuracy: 0.5967 - val_loss: 0.9780 - val_accuracy: 0.5986 Epoch 5/25 4385/4385 [==============================] - 13s 3ms/step - loss: 0.9908 - accuracy: 0.5988 - val_loss: 0.9797 - val_accuracy: 0.5990 Epoch 6/25 4385/4385 [==============================] - 13s 3ms/step - loss: 0.9903 - accuracy: 0.5979 - val_loss: 0.9803 - val_accuracy: 0.5962 Epoch 7/25 4385/4385 [==============================] - 13s 3ms/step - loss: 0.9899 - accuracy: 0.5986 - val_loss: 0.9774 - val_accuracy: 0.6006 Epoch 8/25 4385/4385 [==============================] - 13s 3ms/step - loss: 0.9893 - accuracy: 0.5983 - val_loss: 0.9785 - val_accuracy: 0.5982 Epoch 9/25 4385/4385 [==============================] - 13s 3ms/step - loss: 0.9883 - accuracy: 0.5983 - val_loss: 0.9846 - val_accuracy: 0.5921 Epoch 10/25 4385/4385 [==============================] - 13s 3ms/step - loss: 0.9880 - accuracy: 0.5991 - val_loss: 0.9756 - val_accuracy: 0.6001 Epoch 11/25 4385/4385 [==============================] - 13s 3ms/step - loss: 0.9878 - accuracy: 0.5989 - val_loss: 0.9842 - val_accuracy: 0.5972 Epoch 12/25 4385/4385 [==============================] - 13s 3ms/step - loss: 0.9877 - accuracy: 0.5993 - val_loss: 0.9835 - val_accuracy: 0.6025 Epoch 13/25 4385/4385 [==============================] - 13s 3ms/step - loss: 0.9874 - accuracy: 0.5997 - val_loss: 0.9801 - val_accuracy: 0.5947 Epoch 14/25 4385/4385 [==============================] - 13s 3ms/step - loss: 0.9871 - accuracy: 0.5991 - val_loss: 0.9821 - val_accuracy: 0.5901 Epoch 15/25 4385/4385 [==============================] - 13s 3ms/step - loss: 0.9870 - accuracy: 0.5993 - val_loss: 0.9791 - val_accuracy: 0.5945 Epoch 16/25 4385/4385 [==============================] - 13s 3ms/step - loss: 0.9868 - accuracy: 0.5995 - val_loss: 0.9761 - val_accuracy: 0.6012 Epoch 17/25 4385/4385 [==============================] - 13s 3ms/step - loss: 0.9867 - accuracy: 0.5996 - val_loss: 0.9761 - val_accuracy: 0.6004 Epoch 18/25 4385/4385 [==============================] - 13s 3ms/step - loss: 0.9863 - accuracy: 0.6003 - val_loss: 0.9752 - val_accuracy: 0.6003 Epoch 19/25 4385/4385 [==============================] - 13s 3ms/step - loss: 0.9863 - accuracy: 0.5992 - val_loss: 0.9804 - val_accuracy: 0.5942 Epoch 20/25 4385/4385 [==============================] - 13s 3ms/step - loss: 0.9863 - accuracy: 0.5999 - val_loss: 0.9781 - val_accuracy: 0.5972 Epoch 21/25 4385/4385 [==============================] - 13s 3ms/step - loss: 0.9864 - accuracy: 0.5993 - val_loss: 0.9783 - val_accuracy: 0.5966 Epoch 22/25 4385/4385 [==============================] - 13s 3ms/step - loss: 0.9866 - accuracy: 0.5991 - val_loss: 0.9743 - val_accuracy: 0.5981 Epoch 23/25 4385/4385 [==============================] - 13s 3ms/step - loss: 0.9859 - accuracy: 0.5991 - val_loss: 0.9819 - val_accuracy: 0.5928 Epoch 24/25 4385/4385 [==============================] - 13s 3ms/step - loss: 0.9860 - accuracy: 0.5999 - val_loss: 0.9817 - val_accuracy: 0.5924 Epoch 25/25 4385/4385 [==============================] - 13s 3ms/step - loss: 0.9860 - accuracy: 0.6001 - val_loss: 0.9806 - val_accuracy: 0.5937
예측
검증 세트 및 훈련 세트에 대한 예측을 실행합니다.
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
[<matplotlib.lines.Line2D at 0x7f71fc4799a0>]
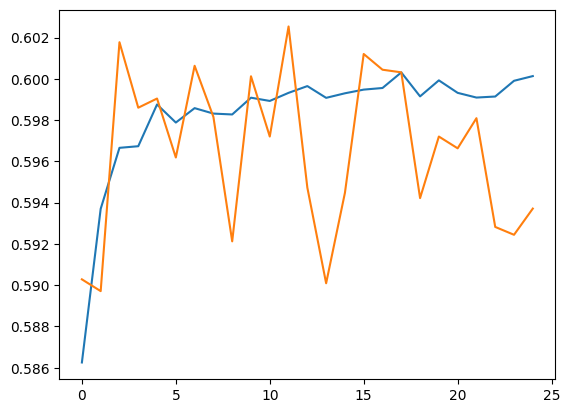
train_eval_result = model.evaluate(dict(train_df), train_df['Sentiment'])
validation_eval_result = model.evaluate(dict(validation_df), validation_df['Sentiment'])
print(f"Training set accuracy: {train_eval_result[1]}")
print(f"Validation set accuracy: {validation_eval_result[1]}")
4385/4385 [==============================] - 12s 3ms/step - loss: 0.9827 - accuracy: 0.6005 493/493 [==============================] - 1s 2ms/step - loss: 0.9806 - accuracy: 0.5937 Training set accuracy: 0.6005487442016602 Validation set accuracy: 0.5937122702598572
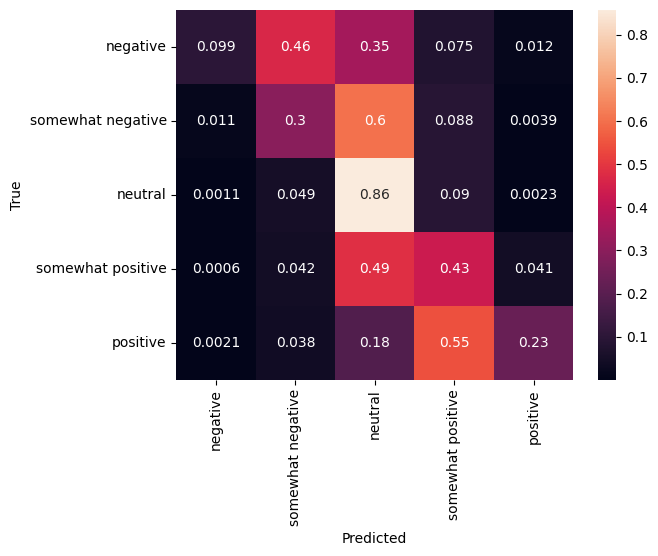
혼동 행렬
특히 다중 클래스 문제에 대한 또 다른 매우 흥미로운 통계는 혼동 행렬입니다. 혼동 행렬을 사용하면 레이블이 올바르게 지정된 예와 그렇지 않은 예의 비율을 시각화할 수 있습니다. 분류자의 편향된 정도와 레이블 분포가 적절한지 여부를 쉽게 확인할 수 있습니다. 예측값의 가장 큰 부분이 대각선을 따라 분포되는 것이 이상적입니다.
predictions = model.predict(dict(validation_df))
predictions = tf.argmax(predictions, axis=-1)
predictions
493/493 [==============================] - 1s 2ms/step <tf.Tensor: shape=(15745,), dtype=int64, numpy=array([1, 2, 2, ..., 2, 2, 2])>
cm = tf.math.confusion_matrix(validation_df['Sentiment'], predictions)
cm = cm/cm.numpy().sum(axis=1)[:, tf.newaxis]
sns.heatmap(
cm, annot=True,
xticklabels=SENTIMENT_LABELS,
yticklabels=SENTIMENT_LABELS)
plt.xlabel("Predicted")
plt.ylabel("True")
Text(50.72222222222221, 0.5, 'True')
다음 코드를 코드 셀에 붙여넣고 실행하여 예측을 Kaggle에 쉽게 다시 제출할 수 있습니다.
test_predictions = model.predict(dict(test_df))
test_predictions = np.argmax(test_predictions, axis=-1)
result_df = test_df.copy()
result_df["Predictions"] = test_predictions
result_df.to_csv(
"predictions.csv",
columns=["Predictions"],
header=["Sentiment"])
kaggle.api.competition_submit("predictions.csv", "Submitted from Colab",
"sentiment-analysis-on-movie-reviews")
제출 후에 리더보드를 점검하여 작업한 내용의 결과를 확인하세요.