| | |  Lihat sumber di GitHub Lihat sumber di GitHub | |
Ringkasan
Salah satu tantangan terbesar dalam Pengenalan Ucapan Otomatis adalah persiapan dan peningkatan data audio. Analisis data audio bisa dalam domain waktu atau frekuensi, yang menambah kompleks tambahan dibandingkan dengan sumber data lain seperti gambar.
Sebagai bagian dari ekosistem TensorFlow, tensorflow-io paket menyediakan beberapa API yang berhubungan dengan audio yang berguna yang membantu meringankan persiapan dan augmentasi data audio.
Mempersiapkan
Instal Paket yang diperlukan, dan mulai ulang runtime
pip install tensorflow-io
Penggunaan
Baca File Audio
Dalam TensorFlow IO, kelas tfio.audio.AudioIOTensor memungkinkan Anda untuk membaca file audio menjadi malas-dimuat IOTensor :
import tensorflow as tf
import tensorflow_io as tfio
audio = tfio.audio.AudioIOTensor('gs://cloud-samples-tests/speech/brooklyn.flac')
print(audio)
<AudioIOTensor: shape=[28979 1], dtype=<dtype: 'int16'>, rate=16000>
Dalam contoh di atas, Flac file yang brooklyn.flac adalah dari klip audio yang dapat diakses publik di google cloud .
GCS alamat gs://cloud-samples-tests/speech/brooklyn.flac digunakan langsung karena GCS adalah sistem file yang didukung di TensorFlow. Selain Flac Format, WAV , Ogg , MP3 , dan MP4A juga didukung oleh AudioIOTensor dengan deteksi format file otomatis.
AudioIOTensor malas-dimuat sehingga hanya bentuk, dtype, dan sample rate ditunjukkan pada awalnya. Bentuk AudioIOTensor direpresentasikan sebagai [samples, channels] , yang berarti klip audio Anda dimuat adalah mono channel dengan 28979 sampel di int16 .
Isi dari klip audio hanya akan dibaca sebagai dibutuhkan, baik dengan mengkonversi AudioIOTensor untuk Tensor melalui to_tensor() , atau meskipun mengiris. Mengiris sangat berguna ketika hanya sebagian kecil dari klip audio besar yang diperlukan:
audio_slice = audio[100:]
# remove last dimension
audio_tensor = tf.squeeze(audio_slice, axis=[-1])
print(audio_tensor)
tf.Tensor([16 39 66 ... 56 81 83], shape=(28879,), dtype=int16)
Audio dapat diputar melalui:
from IPython.display import Audio
Audio(audio_tensor.numpy(), rate=audio.rate.numpy())
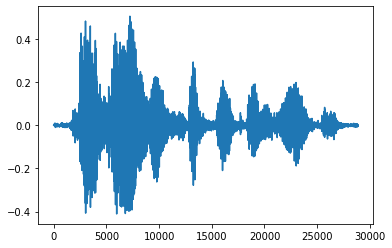
Lebih mudah untuk mengubah tensor menjadi angka float dan menampilkan klip audio dalam grafik:
import matplotlib.pyplot as plt
tensor = tf.cast(audio_tensor, tf.float32) / 32768.0
plt.figure()
plt.plot(tensor.numpy())
[<matplotlib.lines.Line2D at 0x7fbdd3eb72d0>]
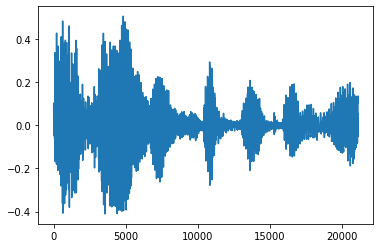
Kurangi kebisingan
Kadang-kadang masuk akal untuk memangkas suara dari audio, yang dapat dilakukan melalui API tfio.audio.trim . Kembali dari API adalah sepasang [start, stop] posisi segement yang:
position = tfio.audio.trim(tensor, axis=0, epsilon=0.1)
print(position)
start = position[0]
stop = position[1]
print(start, stop)
processed = tensor[start:stop]
plt.figure()
plt.plot(processed.numpy())
tf.Tensor([ 2398 23546], shape=(2,), dtype=int64) tf.Tensor(2398, shape=(), dtype=int64) tf.Tensor(23546, shape=(), dtype=int64) [<matplotlib.lines.Line2D at 0x7fbdd3dce9d0>]
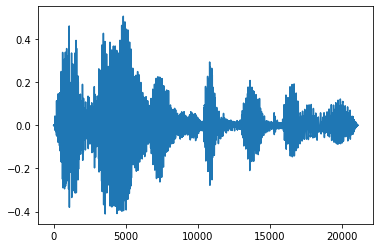
Fade In dan Fade Out
Salah satu teknik rekayasa audio yang berguna adalah fade, yang secara bertahap menambah atau mengurangi sinyal audio. Hal ini dapat dilakukan melalui tfio.audio.fade . tfio.audio.fade mendukung berbagai bentuk memudar seperti linear , logarithmic , atau exponential :
fade = tfio.audio.fade(
processed, fade_in=1000, fade_out=2000, mode="logarithmic")
plt.figure()
plt.plot(fade.numpy())
[<matplotlib.lines.Line2D at 0x7fbdd00d9b10>]
Spektogram
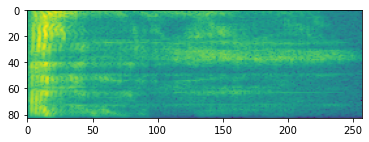
Pemrosesan audio tingkat lanjut sering kali bekerja pada perubahan frekuensi dari waktu ke waktu. Dalam tensorflow-io bentuk gelombang dapat dikonversi ke spektogram melalui tfio.audio.spectrogram :
# Convert to spectrogram
spectrogram = tfio.audio.spectrogram(
fade, nfft=512, window=512, stride=256)
plt.figure()
plt.imshow(tf.math.log(spectrogram).numpy())
<matplotlib.image.AxesImage at 0x7fbdd005add0>
Transformasi tambahan ke skala yang berbeda juga dimungkinkan:
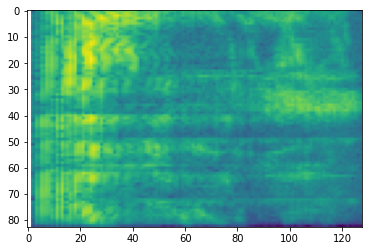
# Convert to mel-spectrogram
mel_spectrogram = tfio.audio.melscale(
spectrogram, rate=16000, mels=128, fmin=0, fmax=8000)
plt.figure()
plt.imshow(tf.math.log(mel_spectrogram).numpy())
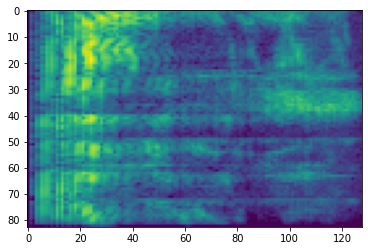
# Convert to db scale mel-spectrogram
dbscale_mel_spectrogram = tfio.audio.dbscale(
mel_spectrogram, top_db=80)
plt.figure()
plt.imshow(dbscale_mel_spectrogram.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb20bd10>
SpecAugment
Selain yang disebutkan di atas persiapan data dan pembesaran API, tensorflow-io paket juga menyediakan augmentations spektogram canggih, terutama Frekuensi dan Waktu Masking dibahas dalam SpecAugment: (. Taman et al, 2019) Metode data Augmentation sederhana untuk Automatic Speech Recognition .
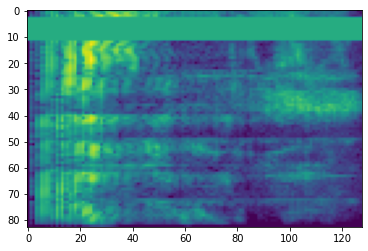
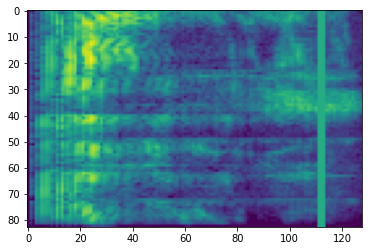
Penyembunyian Frekuensi
Di masking frekuensi, saluran frekuensi [f0, f0 + f) yang bertopeng di mana f dipilih dari distribusi seragam dari 0 ke topeng frekuensi parameter F , dan f0 dipilih dari (0, ν − f) dimana ν adalah jumlah saluran frekuensi.
# Freq masking
freq_mask = tfio.audio.freq_mask(dbscale_mel_spectrogram, param=10)
plt.figure()
plt.imshow(freq_mask.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb155cd0>
Penyembunyian Waktu
Dalam waktu masking, t langkah waktu berturut-turut [t0, t0 + t) yang bertopeng di mana t dipilih dari distribusi seragam dari 0 ke waktu topeng parameter T , dan t0 dipilih dari [0, τ − t) di mana τ adalah langkah waktu.
# Time masking
time_mask = tfio.audio.time_mask(dbscale_mel_spectrogram, param=10)
plt.figure()
plt.imshow(time_mask.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb0d9bd0>